【Azure 基礎用語解説】


さまざまな機器やデバイスがインターネットにつながっていますが、ネットワークの高速化やクラウドの性能の向上により、デバイスから届くビッグデータをリアルタイムに処理できる環境が整ってきました。
機器や設備のリアルタイムな管理や監視、またモバイルや自動車などに備わったセンサーが収集するデータを分析して洞察を得るなど、IoTの活用によって、新たなビジネス価値の創出が期待されています。
そこで注目が集まるのがビッグデータの分散処理技術です。
分散処理フレームワークでは「Hadoop(ハドゥープ)」が有名ですが、Hadoopと同様に、分散処理によってビッグデータを高速処理できるフレームワークが「Apache Spark」です。そして、このApache SparkをAzure上で扱うことができるのが「Apache Spark for Azure HDInsight」です。
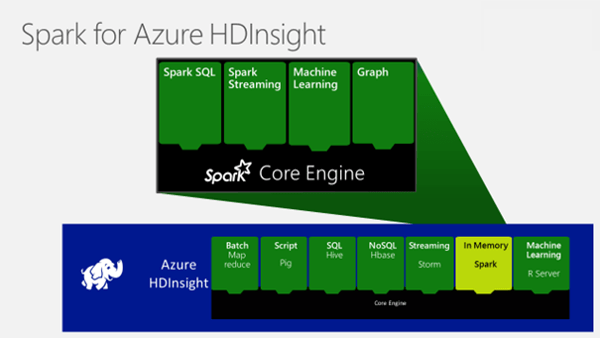
「Apache Spark for Azure HDInsight」の概念図
Apache Sparkは、Hadoopの後発となる、ビッグデータの分散処理基盤です。「インメモリ処理」によって大量のデータの入出力の高速化を図り、処理全体の実行速度を向上させることで、特定のアプリケーションに関する実行性能はHadoopの約100倍にも達するといわれています。
Apache Spark for Azure HDInsightは、エンタープライズ対応のソリューションとして、次のような特長があります。
- (1)99.9 %のサービス品質保証(SLA)
- (2)「Azure Data Lake Store」との統合による高いスケーラビリティ
- (3)強固なセキュリティ
また、Azureの利点を最大限、発揮することができるのも強みです。
たとえば、新しいハードウェアを購入したり他の初期費用をかけたりすることなく、簡単にセットアップでき、数分で使用を開始できます。さらに、実際に使用した計算やストレージに対してのみ課金されるため、ムダが発生しません。
さらに、ビジネスアナリスト向けには、「Power BI」をはじめとするBIツールと連携し、リアルタイムの分析結果をPower BI で可視化するという使い方も可能です。
Apache Spark for Azure HDInsightは、2016年6月に一般提供を開始しました。後発プロダクトであるSparkへの注目の高さから、インタラクティブなリアルタイム処理や機械学習などの領域において、今後ますます利用が拡大していくでしょう。
photo:Thinkstock / Getty Images
Azureの導入や運用に関するお悩みは SoftBankグループのSB C&Sにご相談ください
SoftBankグループのSB C&Sは、さまざまな分野のエキスパート企業との協力なパートナーシップによって、多岐にわたるAzure関連ソリューションをご提供しています。
「Azureのサービスを提供している企業が多すぎて、どの企業が自社にベストか分からない」
「Azure導入のメリット・デメリットを知りたい」
「Azureがどういう課題を解決してくれるのか知りたい」
など、Azureに関するお悩みならお気軽にお問い合わせください。
中立的な立場で、貴社に最適なソリューションをご提案いたします。
クラウドサーバーご検討中の方必見
お役立ち資料一覧

- クラウドサーバーの導入を検討しているがオンプレミスとどう違うのか
- AWSとAzureの違いについて知りたい
- そもそもAzureについて基礎から知りたい
- 今、話題の「WVD」って何?
そのようなお悩みはありませんか?
Azure相談センターでは、上記のようなお悩みを解決する
ダウンロード資料を豊富にご用意しています。
是非、ご覧ください。






Azureの導入・運用に役立つ資料を
無料でダウンロードしていただけますDOWNLOAD
オンプレミスからクラウドへの移行を検討している方のために、安心・スムーズな移行を実現する方法を解説し、
運用コストの削減に有効な「リザーブドインスタンス」もご紹介するホワイトペーパーです。
- Azure OpenAI Serviceの概要と活用例
- Azure伝道師 五味ちゃんが徹底解説! Azure移行編
- 中小企業がデジタルトランスフォーメーションを取り入れるには
- パブリッククラウド導入活用に関する調査結果 ~2022年版~
- プライベートクラウドを Azureで実現!「Azure VMware Solution」とは?
- Azure へのスムーズな移行で社員の生産性を上げる、経営者の選択とは
- 簡単にクラウドセキュリティを実現する 「Azure Security Center」の機能をわかりやすく解説!
- トータルサポートでAzure移行・活用を促進 -基幹システム・SAPクラウド化の課題と解決事例
- ゼロトラストとは?概要から、Azureでできる解決策まで資料で解説
- Azure 導入事例集
- Azure 伝道師 五味ちゃんが徹底解説!AVD(旧:WVD)編
- Azureによるリモートワークの実現 -DaaSならではの柔軟なVDIの構築事例
- Microsoft Azure活用事例 - 株式会社クレオ様
- Azureだからこそ可能になる、快適で安全な仮想デスクトップ環境
- Azure 伝道師 五味ちゃんが徹底解説!Microsoft Azure
- 数あるクラウドから Azureを選択するキーポイントとは
- 「働き方改革」、 Azure VDI + Microsoft 365で実現
- オンプレミスからクラウドへのスムーズな移行とコストダウンを実現する方法
- オンプレミスのIT基盤を Azure IaaSでクラウド化する、 そのメリットとポイント
- 吉田パクえ氏が説く !失敗しないクラウドの使い方!
- クラウド vs オンプレミス 徹底比較!
- Microsoft Azure vs Amazon Web Services 徹底比較!
- Microsoft Azure製品紹介資料
- ダイレクトアクセス for Microsoft Azure ご紹介資料
- DevOpsにはAzure!その理由を徹底解説



Azureのことなら、
SB C&Sにご相談を!
導入から活用まで専門スタッフが回答いたします。
お気軽にお問い合わせください。