


Deep Learning, AI, HPC を加速し、変革を実現するパワフルなエンジン ”GPU” と ”DGX”、そして "AI Enterprise"
AI や Deep Learning , HPC をより加速するために最適なツールこそが GPU であり、DGX です。
大きな変革と課題解決に向けたエンジンとして、画期的なスピードとスケールを実現します。
さらに AI Enterprise は、AI/HPC のワークロードに高い拡張性と管理性、そしてアプリケーション開発・公開の迅速性をもたらします。
製品一覧
NVIDIA AI Enterprise
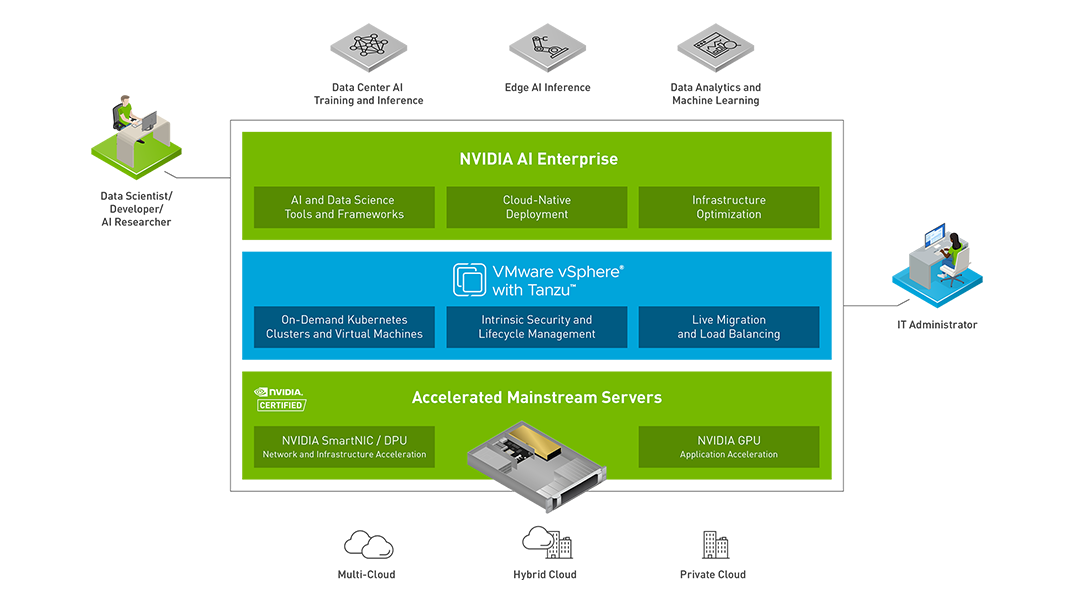
NVIDIA AI Enterprise は、AI/HPC ワークロードに高い管理性・拡張性・俊敏性をもたらします。Kubernetes ベースのクラウドネイティブ環境は、エンタープライズでの導入実績が豊富で、多くのエンジニアがスキルを保有する VMware vSphere をベースとした VMware Tanzu 上で稼働します。また、これら全体は NVIDIA によってサポートされるため、商用のハイブリッドクラウド構成の基点として理想的な環境といえます。
主な機能と特長
-
 ベアメタルとほぼ変わらない性能
ベアメタルとほぼ変わらない性能AI Enterprise による GPU の仮想化は、非仮想化の場合と比べて AI/HPC のワークロードの性能劣化がほぼ発生せず、ノードを跨いだ高速な処理を実現します。
-
明確に示されるサポートハードウェア
AI Enterprise の構成に用いるハードウェアは、NVIDIA から NVIDIA-Certified System として明確に示されるため、機器選定のプロセスを単純化することが可能です。
-
シンプルで迅速なコンテナ環境
Kubernetes によるコンテナ環境の構成自動化により、開発者は迅速かつシンプルに多様な開発環境を入手できます。また、本番環境の大規模な展開にも同様の迅速性と運用性、そして高い可用性を提供します。
-
vSphere の高い管理性
仮想化のスタンダードともいえる VMware vSphere をベースとします。VMware Tanzu が提供する Kubernetes 環境も含めて、 IT 管理者は使い慣れたインターフェースから可視性の高い管理を実行可能です。
NVIDIA A100

NVIDIA A100 は ディープラーニングに代表される機械学習、日々大規模化し性能要求が高まるビッグデータ解析、そして高度な学術研究におけるHPC領域の演算を高速化する、史上最高のデータセンター向け GPU です。最新の NVIDIA Ampere アーキテクチャにより、かつては不可能と考えられていた課題に取り組むデータサイエンティスト、研究者、エンジニアを強力に支援します。
主な機能と特長
-
NVIDIA Ampere アーキテクチャ
CUDA コアに加え、第3世代となったTensor コアを搭載することにより、簡素化された効率的な演算による高速化と、極めて高い精度での演算の高速化を両立します。
-
MIG - Multi Instance GPU
GPUインスタンスを複数に分割する機能です。分割後はそれぞれが完全に独立して動作し、コアだけでなくメモリやキャッシュも専用の領域が与えられます。
-
メモリ領域は 80 GB
A100 初期モデルの 40 GBから更に拡張されたメモリ領域は、容量の大きさに加えて約2TB/秒のメモリ帯域幅を持ちます。大規模な演算を高速に処理するための条件を満たしています。
-
スパース (疎) な演算による高速化
数百万〜数十億ものパラメーターを持つAIモデルのネットワークですが、このパラメーターを適切にスパース(疎)にすることで処理の高速化が可能です。A100のTensorコアはスパースな構造に対応し、最大で2倍以上の高速化を実現します。
NVIDIA DGX Station A100

オフィス向けに設計された NVIDIA DGX Station は、最先端の AI 技術を搭載した世界初の個人/中小規模向けスーパーコンピューターです。あらゆる NVIDIA DGX Systems の動力源となっている NVIDIA GPU Cloud Deep Learning Stack を基盤としており、ご自身のデスクで行った作業を DGX Systems やクラウドに拡張できます。
主な機能と特長
-
GPU 水冷システムによる圧倒的な静音性
オフィスへの設置のため、他ワークステーションの 1/10 の騒音レベルと、ディープラーニングや分析における高いパフォーマンスを実現しています。
-
NVIDIA A100 ×4基搭載
ハイエンドのGPU である A100 を4基搭載することで、最大 2.5 pata FLOPS の高性能を実現します。また、GPUメモリは 320 GBという大容量をもちます。
-
NVLink による GPU 間の高速接続
GPU 間の接続帯域は、規模の大きい処理において特に重要なファクターとなります。DGX Station は4基のGPUを高速なNVLinkによって完全に相互接続しています。
-
オフィスの100V電源で動作可能
最大消費電力は1500Wです。パワーサプライの増設などは一切なしに、オフィス内の標準的な100V電源で動作させることが可能です。
-
インストール済の最適化されたソフトウェアスタック
OSにはUbuntu を採用し、ドライバーやCUDA, コンテナ動作環境など、最適なソフトウェアスタックがあらかじめ構成された状態で出荷されます。導入における作業コストとリードタイムを大きく圧縮できます。
-
NVIDIA によるエンタープライズサポート
Deep Learning のノウハウ、専門的なトレーニング、アップグレードと更新、重要な問題の優先的な解決など、エンタープライズグレードのサポートが提供されます。
NVIDIA DGX A100

NVIDIA DGX A100 は、最適化された演算性能、ソフトウェア、ディープラーニング パフォーマンスの組み合わせにより、AI 研究への取り組みをサポートする統合ソフトウェアおよびハードウェアシステムです。
主な機能と特長
-
NVIDIA A100 を 8 基搭載
ハイエンドのGPU である A100 を 8 基搭載することで、5 pata FLOPS の高性能を実現します。また、GPUメモリは最大で 640 GBという大容量をもちます。
-
クラスター構成における高速通信
クラスター間の接続用に、最大 200 Gb/秒の速度をもつ Mellanox ConnectX-6 HDR InfiniBand インタフェースを 8 ポート備えています。ストレージ接続等の用途向けにも、同等の速度の Ethernet アダプタが搭載されています。
-
NVLink による GPU 間の高速接続
DGX A100 は 8 基のGPUを、600GB/秒もの帯域幅をもつ高速なNVLinkによって完全に相互接続しています。さらに複数のNVLinkを組み合わせるNVSwitchも、前世代の2倍の性能で実装されています。
-
インストール済の最適化されたソフトウェアスタック
OSにはUbuntu を採用し、ドライバーやCUDA, コンテナ動作環境など、最適なソフトウェアスタックがあらかじめ構成された状態で出荷されます。導入における作業コストとリードタイムを大きく圧縮できます。
-
NVIDIA によるエンタープライズサポート
Deep Learning のノウハウ、専門的なトレーニング、アップグレードと更新、重要な問題の優先的な解決など、エンタープライズグレードのサポートが提供されます。