マイクロソフト エバンジェリストがAzure 入門者に贈る―― 「Azureでビッグデータ」の基礎とこれから
2015.11.26

2015年9月18日、日本マイクロソフト品川本社で「Microsoft Azure 入門 ~クラウドの基礎から最新情報まで~ [PaaS編] 」と題するセミナーが開催されました。同セミナーはAzure初心者・アプリケーション開発者を対象にしたもので、「.NET」や「Java」などの開発環境から見たAzure、およびAzureのPaaS機能について日本マイクロソフトのエバンジェリストが解説。本稿では、日本マイクロソフト デベロッパーエバンジェリズム統括本部 エバンジェリスト 畠山大有氏のセッション「ラムダアーキテクチャを実現する Azure Data Services概要」の模様についてリポートします。
「ラムダアーキテクチャ」とは何者なのか?
ビッグデータ時代と言われる今日、オフィス文書やメール、Webコンテンツなどの非構造化データを中心にデータ量が増え続けています。ここに、「IoT(Internet of Things:モノのインターネット)」がもたらす膨大なストリームデータが加わり、もはやデータ量は爆発寸前。バッチ処理によるデータ分析は限界を迎えつつあります。
そうした中で注目を集めているのが、「ラムダアーキテクチャ」です。ラムダアーキテクチャとは、Twitterのリアルタイム分散処理システム「Storm」の開発者Nathan Marz氏が提唱したもの。ストレージに蓄積された大量データのバッチ処理と、ストリームデータのリアルタイム処理をそれぞれ別のレイヤーで実行させながら、データ利用者にはそれぞれを区別することなく集計・分析できる環境を提供するのが、このアーキテクチャの特色とされています。
畠山氏によれば、AzureのPaaS環境を成す「Azure Data Services」を利用すれば、ラムダアーキテクチャによるデータ分析基盤をほぼカバーできるそうです(下図参照)。
図:ラムダアーキテクチャとAzure Data Services
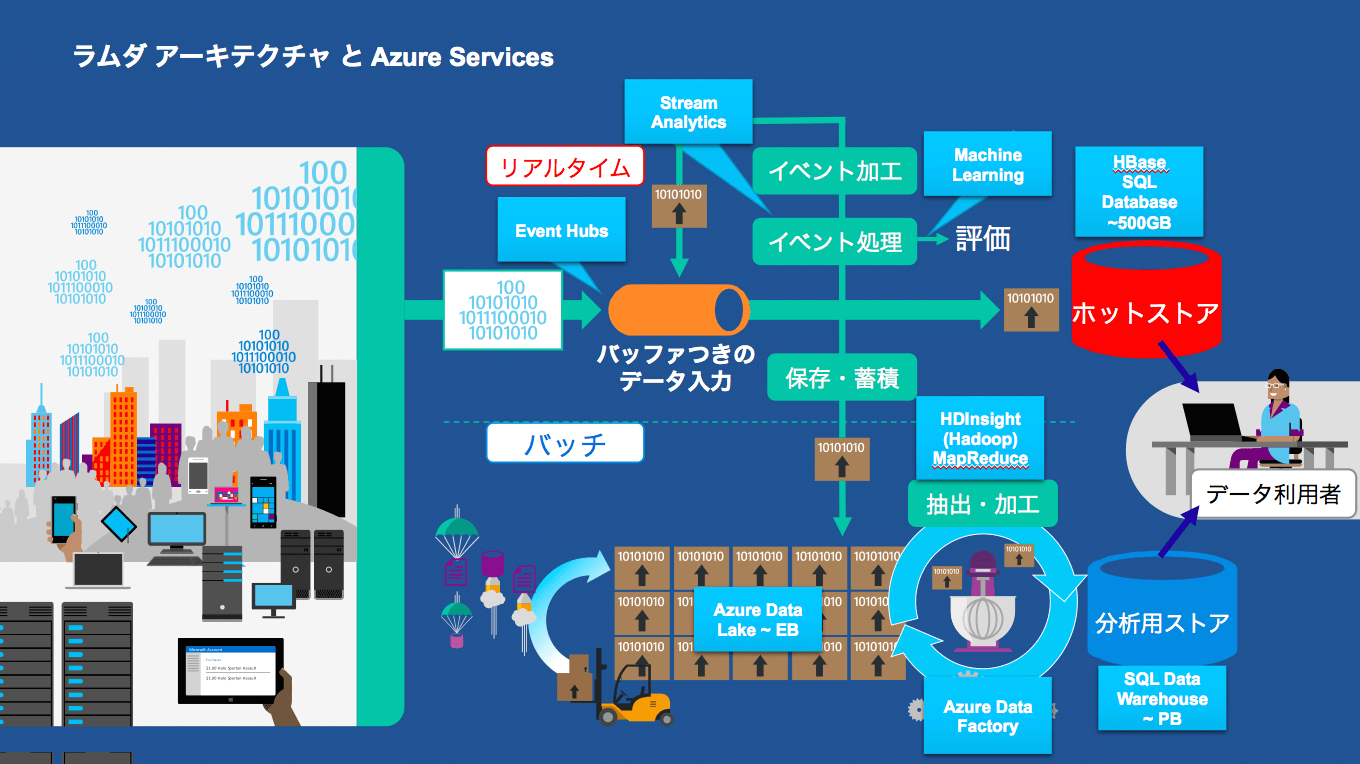
(資料:マイクロソフト)
スケーラブルなNoSQLデータベースと自然語検索
Azure Data Services のサービスとして、畠山氏がまず初めに紹介したのは「Azure DocumentDB」と「Azure Search」です。
このうち、Azure DocumentDBは、JSONをネイティブサポートするNoSQLデータベースサービス。
「このデータベースでは、JSONドキュメントのインデックスが自動的に生成されるため、スキーマを指定することなく一般的なSQL文を用いてクエリーが実行できます。また、複数のドキュメントを横断したトランザクションデータ処理機能を備えるほか、ニーズに合わせてスケールアウトで容易に拡張することが可能です」と、畠山氏は説明します。
これに対して、Azure Searchは開発者がインフラを構築することなく検索機能を組み込めるサービスです。BingやOfficeでも使用されているマイクロソフトの自然言語スタックによって検索結果をすばやく返すことが可能なほか、高度なランキングモデルを作成し、ビジネスの重要度に応じて、検索の優先度を調整することもできます。
データ分析用の多彩なサービス
講演では、上記2つのサービスに続いて、データ分析用に用意されている各種サービスも紹介されました。
その中の一つ、「Azure Data Lake」は、収集したあらゆる種類のデータを1個所にまとめて保存できるリポジトリです。このリポジトリでは、あらゆる構造・サイズのデータを無制限にストア・管理することができるほか、ペタ・バイト級の大容量ファイルのサポートや、高スループット・低レイテンシーといった特徴も備え、Apache Hadoop、Spark、HBase、Stormなどにも対応しています。
また、Azure上でスケーラブルなイベント送受を可能にするためのサービスが「Azure Event Hubs」です。数百万台のデバイスから送出されたイベントを、数百万イベント/秒のパフォーマンスで受信する能力を備えており、IoTで想定されているような超大規模のデータ送受信にも対応できるとのこと。
さらに、「Azure Stream Analytics」は、Azure上の大量のストリームデータをリアルタイムに処理・分析するためのサービス(クエリエンジン)です。
「Azure Stream Analyticsを用いることで、例えば、Azure Event Hubsから数百万のリアルタイムイベントを取得して分析処理を実行し、その結果をPower BIダッシュボードやデバイスに出力することが可能になります」と、畠山氏は説明します。
機械学習サービスの提供も
もう一つ、畠山氏が時間を割いて解説したのが機械学習サービス「Azure Machine Learning」です。Azure Machine Learningは、マイクロソフトが長年培ってきた機械学習の知見を基にしたもので、その活用により、「未来を予測して自律的な判断を下すアプリケーション」が素早く開発できると畠山氏は話します。
「Azure Machine Learningは、数学的・統計学的手法を使った分析予測や、データの関連性の解析など、さまざまな領域に適用できます。近い将来、Azure Machine LearningとAzure Stream Analytics、さらには、Azure上でのHadoop利用を可能にする『HDInsight』などを統合した『Cortana Analytics Suite』(下図参照)もリリースする予定です」(畠山氏)。
図:Cortana Analytics Suiteの全体像
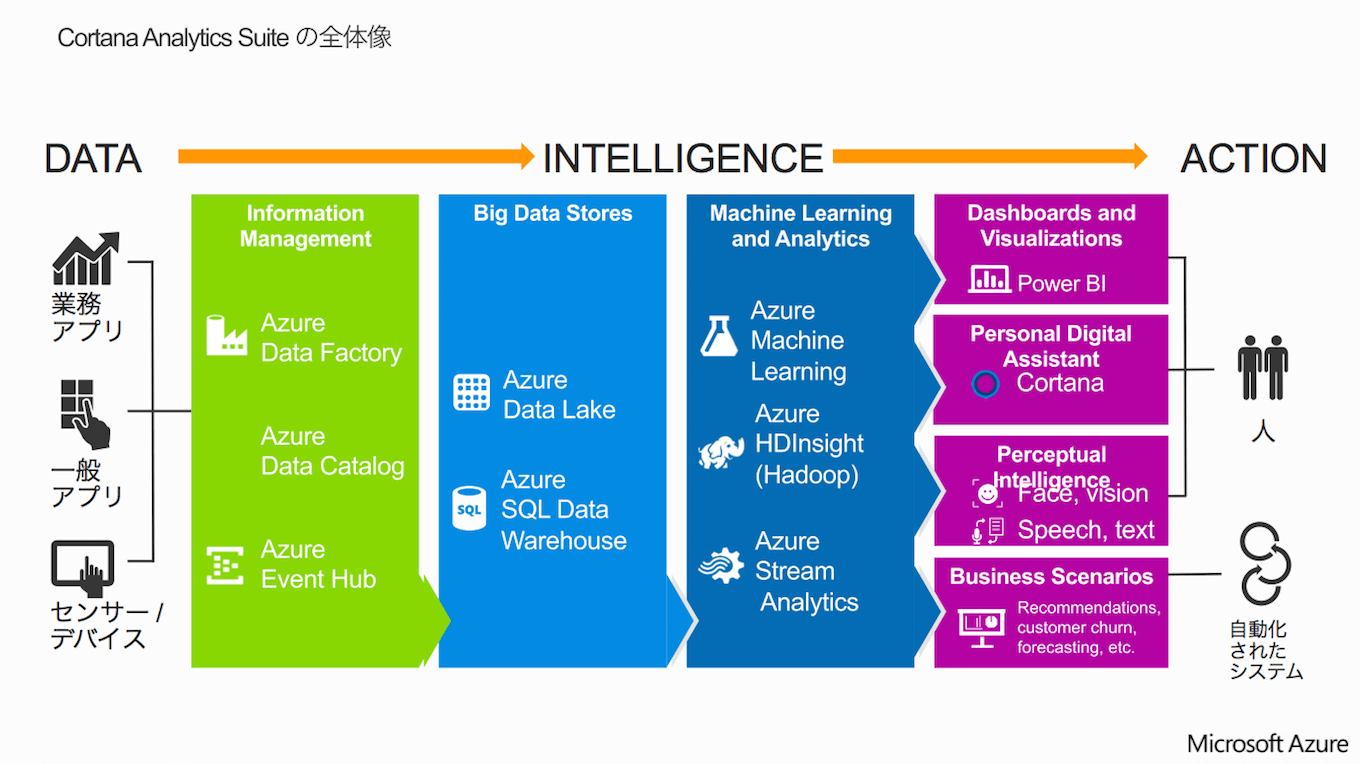
(資料:マイクロソフト)
ビッグデータの時代と言われて久しい昨今ですが、「その活用から得られる効果・実利が読みにくいにもかかわらず、関連ITソリューションが総じて高価」といった「投資対効果」の問題から、日本企業におけるビッグデータの利活用はあまり進展していません。
しかし、PaaSとして提供されるAzure Data Servicesなら、そうしたソリューション導入の敷居を引き下げてくれる可能性があります。そして機械学習などの高度な機能を用いたビッグデータ活用・分析の世界が、多くの企業にとって身近な存在へと変容するかもしれません。そうなれば、日本でのビッグデータ利活用も、大きく前進するのではないでしょうか。
本セミナーの資料は、以下に公開されています。ぜひご参考にご覧ください。
https://docs.com/cloudcamp/5239/2015-09-18-web-azure-devops

