LLM を簡単にローカルで実行できる Docker Model Runner 〜Docker が提案する新しい生成AIアプリ開発体験〜

はじめに
はじめまして、Docker でソリューションエンジニアをしています、根本 征です。
2024年8月に Docker に入社し、日本のお客様を中心に技術支援・情報発信をしています。Docker は現在生成AIアプリ開発の効率化に注力しており、今回は Docker Desktop において新たにリリースした「Docker Model Runner」について紹介します。
目次
- Docker Model Runner とは
- Docker Model Runner を使って LLM を実行する
- Docker Model Runner を使って生成 AI アプリを開発する
- おわりに
Docker Model Runner とは
Docker Model Runner は弊社 COO Mark Cavage が Java One 2025 の基調講演にて発表を行い、Docker Desktop 4.40 にてベータ版としてリリースされました。

Java One 2025 での Docker Model Runner の発表
Docker Model Runner は 大規模言語モデル(LLM) を簡単にローカル環境で実行することができる、Docker Desktop の新たな機能です。
llama.cpp をバックエンドとし、GPUアクセラレーション(Mac では Apple Silicon GPU をサポート、Windows では NVIDIA GPU を今後サポート予定)によって最適なパフォーマンスで LLM を実行することができる他、OpenAI API との互換性があります。
Docker Model Runner の大きな特徴として、Docker を使ったコンテナ開発と同じ体験で ローカル環境で LLM を扱うことができます。
一般的に LLM をローカル環境で実行するとなると別途スクリプトや手順が必要になることが多く、また LLM を切り替える際にも複雑になりがちです。
Docker Model Runner では Docker Hub にあるモデル(OCIアーティファクトとして保存)をダウンロード(`docker model pull`) し、`docker model` コマンドを利用して簡単にモデルの起動・操作を行うことができます。
Docker Model Runner はローカル環境で実行することになるのですが、これには外部のAPIやクラウドを使ったLLM実行環境と比較し、以下のメリットがあります。
- セキュリティ: ローカル環境で完結することができるため、データなどが外部に渡ることを気にする必要がなく安全に開発を行うことができます。
- 開発スピード: LLM実行環境 ⇔ 開発中の生成AIアプリが同じローカル環境にあるため、セットアップがしやすいかつレイテンシ・レスポンスがとても速いため、開発スピード・開発生産性を上げることができます。
- コスト: 外部のAPIやクラウドを使用したLLM実行環境では別途コストが必要になりますが、Docker Model Runner はローカルのリソースを利用して LLM を動作させるため、それらの費用は必要ありません。
Docker Model Runner を使って LLM を実行する
では実際に Docker Desktop を使って Docker Model Runner を動かしてみましょう。
Docker Desktop 4.40 では、 Apple Silicon が搭載された Mac でのみサポートされています。
Docker Desktop を 4.40 以降にアップデートした後に以下のコマンドを実行し、Docker Model Runner が利用可能な状態か確認して下さい。
$ docker model status
Docker Model Runner is running
次に Docker Hub からモデルをダウンロード(Pull)します。
こちらの Docker Hub のページから、ダウンロードすることができるモデルを確認することができます。
Docker Hub からモデルをダウンロード
現在は限られたモデルのみの提供になっていますが、今後はこのモデルが増えていく他、通常の Docker Hub と同様にユーザーからのモデルのアップロード(Push)にも対応していく予定です。
今回は Meta が公開しているモデル llama(ai/llama3.2:1B-Q8_0)を利用します。
$ docker model pull ai/llama3.2:1B-Q8_0
Model ai/llama3.2:1B-Q8_0 pulled successfully
`docker model run` コマンドを利用し、プロンプトを渡します。
$ docker model run ai/llama3.2:1B-Q8_0 '鯨について30字以内で教えて下さい'
鯨は、巨大な哺乳動物の家族の一つであり、頭から大きな鯨頭を持ち、体は水中で自由に泳いだり水中で泳ぐことができる。頭部と胸部は魚の体に似ているが、尾部は長い、薄い鯨の尾で構成されている。
また、インタラクティブに実行することもできます。
$ docker model run ai/llama3.2:1B-Q8_0
Interactive chat mode started. Type '/bye' to exit.
> 鯨について30字以内で教えて下さい
鯨は、巨大な哺乳動物の家族の一つであり、頭から大きな鯨頭を持ち、体は水中で自由に泳いだり水中で泳ぐことができる。頭部と胸部は魚の体に似ているが、尾部は長い、薄い鯨の尾で構成されている。
>
Docker Model Runner 使って生成AIアプリを開発する
次にサンプルアプリ(チャットアプリ)を用いて、Docker Model Runner を使った生成AIアプリ開発を体験していきましょう。バックエンド Go + フロントエンド React で構成されており、Docker Compose を利用して立ち上げることができます。
はじめにサンプルアプリのコードを取得します。
git clone https://github.com/dockersamples/genai-app-demo
cd genai-app-demo
次に `backend.env` を確認します。
BASE_URL: http://model-runner.docker.internal/engines/llama.cpp/v1/
MODEL: ai/llama3.2:1B-Q8_0
API_KEY: ${API_KEY:-ollama}
http://model-runner.docker.internal/engines/llama.cpp/v1/ がコンテナからアクセスすることができる Docker Model Runner の URL になります。
では、 docker compose コマンドを使ってバックエンドアプリとフロントエンドアプリを起動します。
docker compose up -d
http://localhost:3000 にアクセスするとチャットアプリが表示され、Docker Model Runner で実行されているモデルを利用してチャットの応答が可能になります。
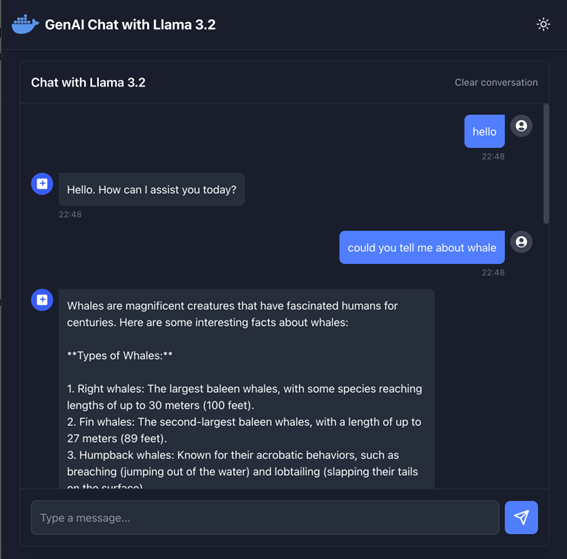
Docker Model Runner と連携したチャットアプリ
おわりに
今回は、LLM を簡単にローカル環境で実行することができる Docker Desktop の新しい機能 Docker Model Runner について紹介しました。
今後は以下のサポートを予定しています。
- Windows(NVIDIA GPU)サポート
- より多くのモデルを Docker Hub で提供
- Docker Hub に自身のモデルをアップロード
- docker model コマンドの充実
- Docker Compose・Testcontainers との連携の充実
- CI/CD パイプラインとの連携
Docker Model Runner は 生成 AI アプリ開発における強力なツール・エコシステムになると考えています。
今後のアップデートに是非ご期待ください。
関連リンク
https://www.docker.com/blog/introducing-docker-model-runner/
この記事の著者:根本 征 (Tadashi Nemoto)
Strategic Solutions Engineer
複数の日系企業でテスト自動化エンジニア・DevOpsエンジニアとして活動した後、プリセールスエンジニアとして DevOps、CI/CD、自動テストを中心にお客様の技術支援や技術発信を行ってきました。2024年日本拠点1人目のプリセールスエンジニアとして Docker に入社。
DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






