【中編】XplentyのMongoDBコネクタ

【前編】MongoDBのETL処理をシンプルに
【中編】XplentyのMongoDBコネクタ←本記事です。
【後編】MongoDB × Hadoop × Xplenty
はじめに
前回に続きXplentyとMongoDBの連携について記事にしております。
この記事では、Xplentyを使ったETLパイプラインでMongoDBを活用する方法を紹介します。
MongoDBは、人気のある非リレーショナル(別名NoSQL)データベースです。ドキュメント指向で、分散型の性質を持っています。MongoDBは、高い拡張性と柔軟性を持つことで知られています。まず始めに、他のリレーショナルデータベースではなく、MongoDBを使いたいと思う理由とケースについて簡単に説明します。
目次
- MongoDBとリレーショナルデータベースの違い
- XplentyをMongoDBと一緒に使うメリット
- XplentyのパイプラインでMongoDBを使う
- パイプラインの実装
- まとめ
MongoDBとリレーショナルデータベースの違い
リレーショナルデータベースでは、データをテーブル、カラム、テーブル間のリレーションシップでモデル化します。MongoDBでは、情報をドキュメントのコレクションとして表現します。これらのドキュメントは JSON オブジェクトのようなもので、デフォルトではいかなる構造も強制することはありません。これにより、データモデリングの柔軟性が高まります。
MongoDBでドキュメントの構造を決める際の一般的な経験則として、「一緒に使われるものは一緒に保存すべき」というものがあります。一対多数(または多数対多数)のリレーションシップを同じドキュメントの配列フィールドに格納することができます。この「埋め込み」というアプローチにより、クエリのパフォーマンスが高くなり、高コストなJOINオペレーション(SORT MERGE JOINといった作業)が必要なくなります。ドキュメントが自己完結型であるため、MongoDBはシャーディング、同期、レプリケーションといった分散型データベースの優れた機能を提供し、複数のマシンにまたがるスケーラビリティを可能にしています。
もちろん、このような方法でデータを表現すると、より多くのストレージスペースが必要になりますが、活用方法次第でコストを上回るメリットがあります。
XplentyをMongoDBと一緒に使うメリット
企業がXplentyをMongoDBと一緒に使う理由はいくつかあります。
- データフローの両方向をサポート: Xplentyでは、データソースとしてもデータデスティネーションとしても、パイプラインでMongoDB接続を使用することができます。
- 他のコンポーネントとの互換性: XplentyとMongoDBコンポーネントの既存機能を組み合わせて、非常に複雑なパイプラインを構成することができます。例えば、他のデータベースからMongoDBにデータを移行することができます。またデータの変換や、Salesforceのような他のXplentyの統合対象からデータを引き出したり、外部APIを呼び出してデータを補強することも可能です。
- データのセキュリティ: Xplentyはデータベース接続にSSLをサポートしているので、データは安全なプロトコルで転送されます。さらに、データベースがお客様のオンプレ環境にあることで、お客様がデータを所有することになります。
- 一般的に使用されるMongoデータタイプのサポート: Xplentyは、文字列、数値型(int、float、double)、BSON(binary JSON)など、一般的に使用されているMongoDBのデータ型をすべてサポートしています。
ここからは、XplentyのパイプラインでMongoDBを使用する方法を解説いたします。
XplentyのパイプラインでMongoDBを使う
Xplentyで任意のデータベースを使用するには、データベース接続の設定と、データベースコンポーネントのパイプラインへの追加という2つのステップが必要になります。
MongoDB接続の設定
XplentyパイプラインでMongoDBを使用するには、まずXplentyダッシュボードでMongoDB接続を追加します。XplentyのMongoDB接続は、SSLをサポートしていますので、MongoDBとのデータのやり取りは安全なプロトコルで行われます。
ほとんどのデータベースサービスと同様に、MongoDBをセットアップするには、セルフホスト型(オンプレ)とマネージド型(SaaS)の2つの方法があります。セルフホスト型では、MongoDBを自分でマシンにインストールする必要があります。一方、マネージド型では、すぐにデータベースに接続できるようなセットアップが用意されています。MongoDBチームが提供するマネージド型はMongoDB Atlasと呼ばれています。オートスケーリング、モニタリング、アラート、バックアップ、データレイクなどの他のツールとの統合など、いくつかの優れた機能を備えています。
データベースコンポーネントの使用
Xplentyは、MongoDBのソースコンポーネントとデスティネーションコンポーネントの両方を提供しています。つまり、パイプライン内のMongoDB接続からデータを抽出したり、データを保存したりすることができます。これらのコンポーネントは、Select変換、フィルタ変換、Curl関数などのXplentyの他の機能と組み合わせることで、データを加工する点において多くの柔軟性を提供します。
ソースコンポーネントとデスティネーションコンポーネントは、主要なMongoDBデータタイプをサポートしています。次の表は、これらのデータタイプとXplentyのネイティブデータタイプの対応を示しています。
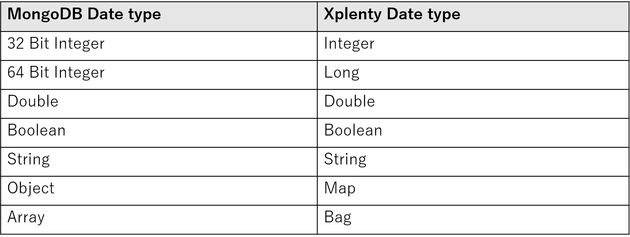
ObjectとArrayのデータタイプをサポートしているのは特に便利なポイントです。これらのデータはBSON(Binary JSON)として保存され、インデックス作成やクエリの最適化など、高度な設定が可能になります。
事例
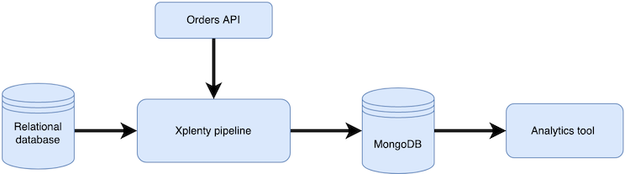
あるオンラインコマース企業が、顧客に関する情報をリレーショナルデータベースのテーブルに保存しています(この例では、MySQLデータベースを使用します)。この企業は、データの分析を行い、顧客ごとにさまざまな指標を算出したいと考えています。そのためには、まず顧客の注文データを追加する必要がありますが、これはRESTful APIを通じて利用できます。注文データを顧客情報と組み合わせると、要件に応じて変換され、MongoDBのコレクションに取り込まれます。このコレクションは、任意の分析ツール/エンジンのデータソースとして使用でき、その上で分析を行うことができます。
顧客の注文詳細を取得するには、POST HTTPメソッドで/ordersリソースエンドポイントに問い合わせ、リクエストのペイロードに顧客のEメールを指定する必要があります。特定の顧客の「Orders」エンドポイントに対してAPIが返すJSONレスポンスは以下のようになります。
{
"orders": [
...
{
"id": 29393,
"total_price": 100,
"tax_lines": [
// These objects themselves are nested and so on.
]
...
},
{
...
},
...
]
}レスポンス結果はこちらを参照ください。
パイプラインの実装
要件が定義されたので、実際のパイプラインをXplentyでどのように実装するかを見てみましょう。
MongoDB接続の追加
XplentyダッシュボードでMongoDB接続を設定するには、MongoDBから以下の情報を用意していることを確認してください。
- ホスト名
- ユーザー名とパスワード
- データベース名
この例では、MongoDB Atlas(マネージド型)で設定された無料クラスタの情報を使用します。Atlasを使用している場合は、ダッシュボードのクラスタタブで接続ボタンをクリックするとホスト名が表示されます。
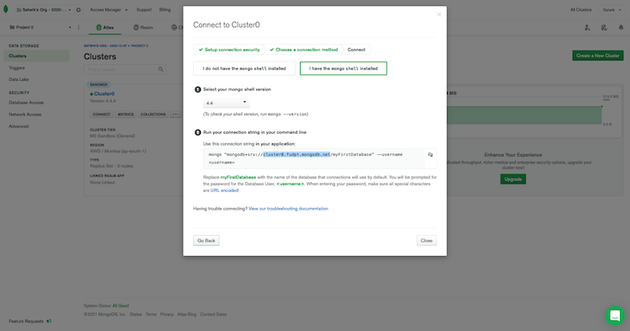
次に、「データベースアクセス」タブでユーザーとパスワードの詳細を確認します。新しいユーザーを作成し、ユーザー名とパスワードをメモします。これらの値をXplentyの新規コネクション設定に入力します。XplentyがAtlasクラスタに安全な方法で接続できるように、必ず「Connect using SSL」オプションをチェックしてください。デフォルトでは、アトラスクラスターにはmyFirstDatbaseという名前のデータベースが付属しています。別のデータベースを使用したい場合は、Mongoシェルで作成することができます。最後に、保存する前に接続をテストして、すべてが動作することを確認します。
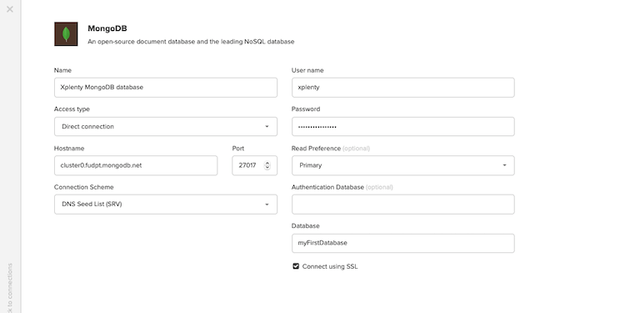
Xplentyは、Read Preferenceの指定、認証データベース、クラスタのレプリカセットメンバーへの直接接続など、いくつかの高度な設定もサポートしています。これらについては、弊社のヘルプドキュメントの Allowing Xplenty access to MongoDBで詳しく説明しています。
リレーショナルデータベースへの接続の追加
MongoDBをソースデータベースとして使用する場合は、別途設定する必要があります。この例では、ローカルでホストされているMySQLデータベースを使用します (ngrokトンネルを通じて公開します)。
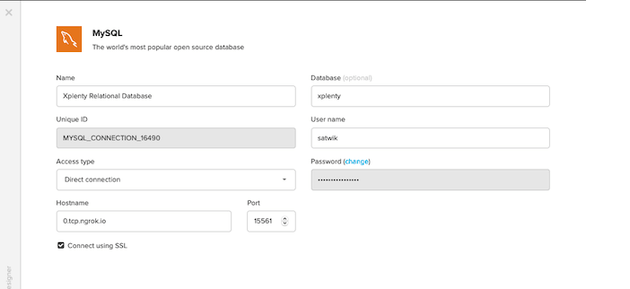
ETL パイプラインの設定
データ接続が完了したので、パイプラインの作業を開始します。
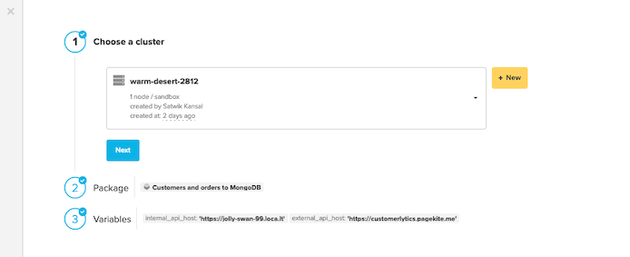
ダッシュボードから新しいデータフローパッケージを作成し、"Customers and Orders to MongoDB "のような分かりやすい名前をつけます。
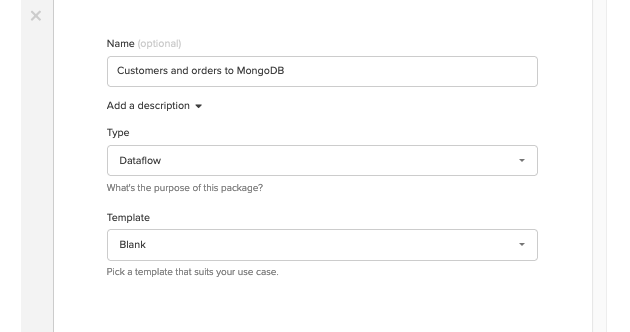
パイプラインの実装には3つのコンポーネントがあります。
- MySQLデータベース(ソース):このコンポーネントは、MySQLデータベースから関連する顧客のレコードを抽出します。
- Select変換:このコンポーネントでは、XplentyのCurl関数を使用して、REST APIから顧客の注文に関する情報を取り込みます。
- MongoDBデータベース(デスティネーション):このコンポーネントは、データをMongoDBコレクションに書き込み、後で目的に応じて使えるようにします。
それでは、それぞれのコンポーネントを詳しく見ていきましょう:
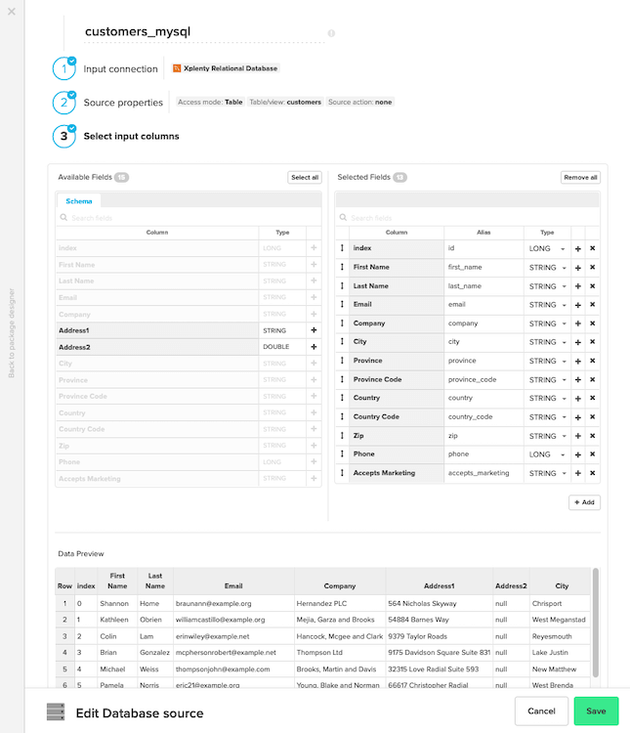
MySQLデータベース(ソース)コンポーネント: 入力接続の設定では、先ほど作成したコネクションを選択します。次に、テーブル名(ここではcustomers)を指定します。その後、Xplentyは自動的にデータプレビュー付きのスキーマを引き出します。使用したいフィールドを選択し、エイリアスを与え、データタイプを確認した後、保存します。
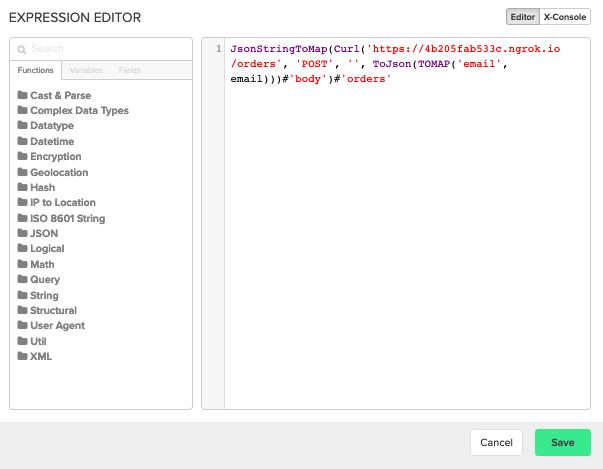
Select変換コンポーネント: selectコンポーネントでは、XplentyのCurlメソッドを使用して顧客の注文詳細を取得し、レスポンスボディをフィールドに割り当てる式を追加します。
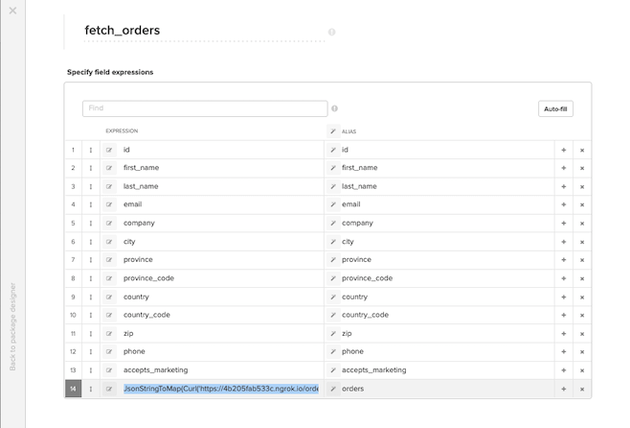
ダイアログボックス内のフィールドで式を作成するのは不便なので、左の鉛筆アイコンをクリックして式エディタを開き、そこで式を作成しています。ご覧の通り、TOMAPおよびToJson関数を使ってリクエストのJSONボディを構築しています:
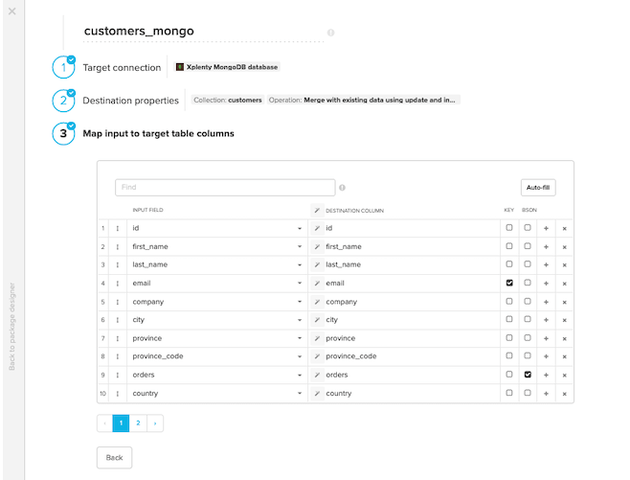
データベース (ディスティネーション)コンポーネント: 次に、すべてのデータをMongoDBコレクションに取り込みたいと思います。ここでは、操作タイプを「updateとinsert を使って既存のデータと結合する」と指定しています。データベースに書き込むカラムは、「Auto-Fill」オプションを使って自動で設定可能です。主キーまたは複合キーを構成する列を選択して、データベーステーブルのエントリを一意に識別する必要があります。マップやバッグのフィールドを文字列ではなくBSONとして保存したい場合は、BSONのチェックボックスをオンにします。
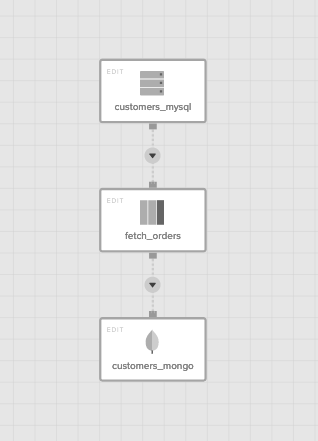
完成後のパイプラインのイメージはこのような形です。
パイプラインの動作
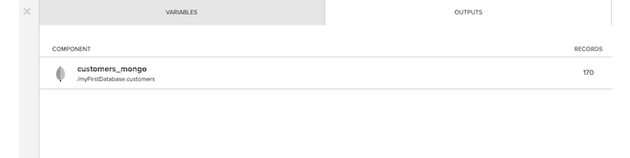
実装が完了したら、ジョブを作成することでパッケージを検証してから実行します。ジョブのステータスは、Xplentyのダッシュボードからモニターできます。
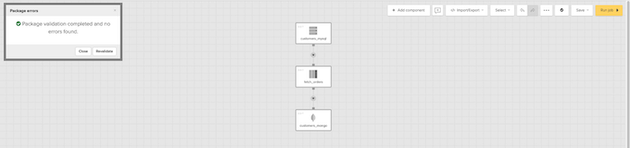
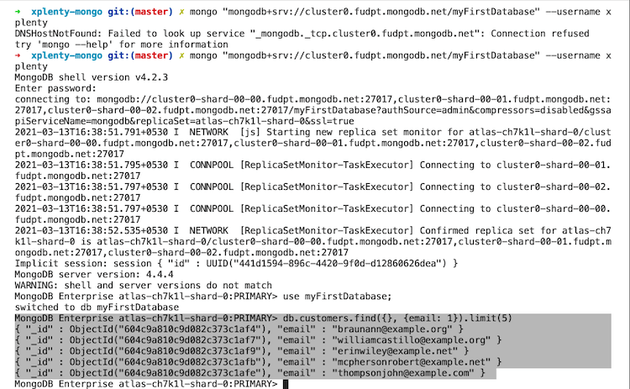
ジョブが終了したら、MongoDBのシェルでクエリを実行して、データが正しく保存されているかどうかを確認します。
まとめ
この記事では基本的な機能にしか触れていませんが、XplentyでMongoDBを使って、もっと高度な操作も可能です。より複雑な使用例については、ナレッジベースをご覧ください。
次回の記事ではXplentyとMongoDB、さらに大規模なデータを高速に処理出来るプラットフォームであるHadoopとの統合について詳しくお伝えしていきます。
関連ページ
【後編】MongoDB × Hadoop × Xplenty
この記事の著者:山本心
Cognos(IBM)、SAP、

DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






