【イベントレポート】Open Source Summit Japan 2024【②AI_DEV】

皆さんこんにちは。
SB C&Sの佐藤梨花です。
今回は2024年10月28日(月)~2024年10月29日(火)の2日間に渡り開催された「Open Source Summit 2024 JAPAN」の参加レポを3回に分けてお送りします。
第2回目は「AI_DEV」として、イベント内で開催されたAIに関するセッションを集めたAI_DEVから、私が参加したセッションの概要を紹介します。
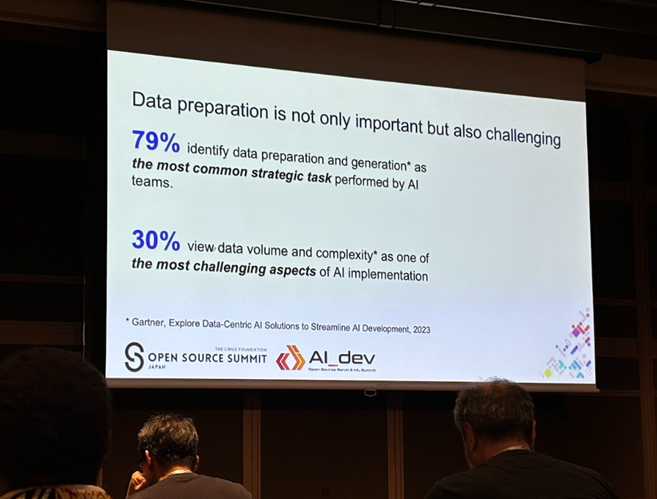
Data Prep Kit: A Comprehensive Cloud-Native Toolkit for Scalable Data Preparation in GenAI App
AIにおいて重要な「データ」をどのように扱っていくかについて解説されました。
その中でもデータ準備の重要性やデータ種別/保存されているプラットフォームの多様化、反復処理の多さにどう対応していくべきかという点が語られました。
そこに対応するために開発された「Data Prep Kit」はデータの収集、クリーニング、変換、統合を効率的に行うためのツールキットであり、このツールキットは、クラウド環境でのスケーラビリティと柔軟性を提供し、大規模なデータセットの処理を容易にします。データ準備のプロセスを効率化することで、スケーラブルなデータ処理を可能にし、データの準備にかかる時間を短縮することで、より迅速にインサイトを得ることができます。
またローコード/ノーコードオプションにより、データ処理の自動化やカスタマイズも可能であるという点も語られました。
Optimize Your AI Cloud Infrastructure: A Hardware Perspective
AIクラウドインフラの最適化に関するハードウェアの視点からの解説と、GPUクラウドサービスの効率改善、最適化の重要性について解説されました。特に、分散機械学習シナリオにおいてGPUクラウドがどのように利用されているかに焦点が当てられました。
セッションでは、AIインフラストラクチャの最適化に関する議論が通常アプリケーション層(機械学習タスクや分散ジョブスケジューラなど)に集中する一方で、GPUクラウドの内部構造に目を向けることの重要性が強調され、PODスケジューラ、デバイスプラグイン、GPU/NUMAトポロジー、ROCE/NCCLスタックなど、パフォーマンスに大きな影響を与える要素についても詳しく説明されました。
さらに、さまざまな機械学習モデル(CNN/RNN/Transformer)のチューニングについても取り上げ、モデルのパフォーマンスとノード内のデバイスオペレーター構成との相関関係を分析し、AIクラウド内の隠れた可能性を明らかにするための実験結果も解説されました。
AIクラウドインフラストラクチャの最適化に関心のある技術者や研究者にとって非常に有益な内容となっています。
A Next-generation IoT Platform for Edge AI Apps Leveraging Sensors and Wasm
Edge AIアプリケーションのための次世代IoTプラットフォームについて解説されました。
セッションでは、AIによる生成には多様なタイプのデータを渡すことが重要であり、そういったデータを集めるうえでIoTが重要な役割を果たすという点と、それを実現するためのEdge AIとセンサーを活用した包括的なプラットフォームの構築について紹介されました。このプラットフォームは、デバイスからクラウドまでをカバーし、センサーとAI制御の高度な連携を可能にします。また、WebAssembly(Wasm)を利用することで、AIモデルのシームレスかつ動的な置き換えが可能になります。
さらに、オープンソース化を通じてエコシステムを拡大し、技術コミュニティを形成することを目指しています。技術的な詳細や実際のシナリオを通じて、参加者が自身のプロジェクトに適用できるインサイトを提供していることも解説されました。
Edge AIインフラストラクチャの最適化に関心のある技術者や研究者にとって非常に有益な内容となっています。

Unlocking Local LLMs with Quantization
量子化技術を活用してローカルな大規模言語モデルを最適化する方法について詳しく解説されました。
セッションでは、量子化技術の歴史とその人気の高まり、そして現在のオープンソースコミュニティにおける状況について紹介されています。特に、Tim DettmersによるQLoRAやElias FrantarによるGPTQなどの重要な量子化論文が取り上げられています。さらに、量子化がモデル開発のさまざまな段階(事前学習、ファインチューニング、推論)でどのように適用されるかについても説明されました。
具体的には、1.58ビットモデルの事前学習、PEFT + QLoRAを使用したファインチューニング、torch.compileやカスタムカーネルを用いた推論性能の最適化についての経験が共有され、またコミュニティ内で量子化モデルをよりアクセスしやすくするための取り組みについても言及されました。例えば、transformersが最先端の量子化スキームをどのように取り入れているか、llama.cppからGGUFモデルを実行する方法などが紹介されました。
このセッションは、量子化技術を活用してAIモデルの効率を最大化したい技術者や研究者にとって非常に有益な内容となっています。
まとめ
今回は「AI_DEV」の中から私が参加したセッションについて、概要を紹介させていただきました。
それぞれのセッション内容を見ていただけるとわかるように、イベントではAI(モデル)そのものだけでなく、AI技術の最新動向や周辺技術への影響、AI技術の応用に関する多岐にわたるセッションが行われ、今後のAIの発展に大きな影響を与える内容が紹介されました。
モデルの精度はもちろん、それ以外の部分を注視することが現状のAI開発における注目ポイントであり、AI発展の次のキーポイントになるということが伺えますね。
今回ご紹介した以外のAI_DEVセッションや、他セッションでもAIを扱ったものが多数ありましたので、是非公式サイトから気になるセッションを確認してみてください!
そしてこれらのセッションから個人的には特に
- クラウドインフラの最適化
- Edge AIとIoTの連携
- データ準備の効率化
といった部分が、技術企画室が取り組んできたDevOpsやクラウドネイティブの取り組みに大きく関係してくる点に注目したいです。
これらのセッションから得られた知見を活かし、技術企画室としても今後のプロジェクトに積極的に取り入れていきたいと考えています。AI技術の進化は止まることなく、私たちの取り組みがその一翼を担うことを期待しています。
この記事の著者:佐藤梨花
勤怠管理システムの開発(使用言語:Java)に約8年間従事。
現在はエンジニア時の経験を活かしたDevOpsやDX推進のプリセールスとして業務に精励しています。

DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






