Splunk Infrastructure Monitoringを触ってみた
オブザーバビリティとは何か?まずはその概念を理解しよう
Splunkが実現するクラウドネイティブ環境のオブザーバビリティ
Splunk Infrastructure Monitoring を触ってみた←本記事です
はじめに
みなさんこんにちは 。SB C&Sで事業開発を行っている佐藤です。前回、前々回の記事でSplunk社の池山氏に「オブザーバビリティ」の概念とSplunkが実現するソリューションとして「Splunk Infrastructure Monitoring 」「Splunk APM」の概要について解説していただきました。
ここでは「Splunk Infrastructure Monitoring 」を実際に触りご紹介したいと思います。
検証環境について
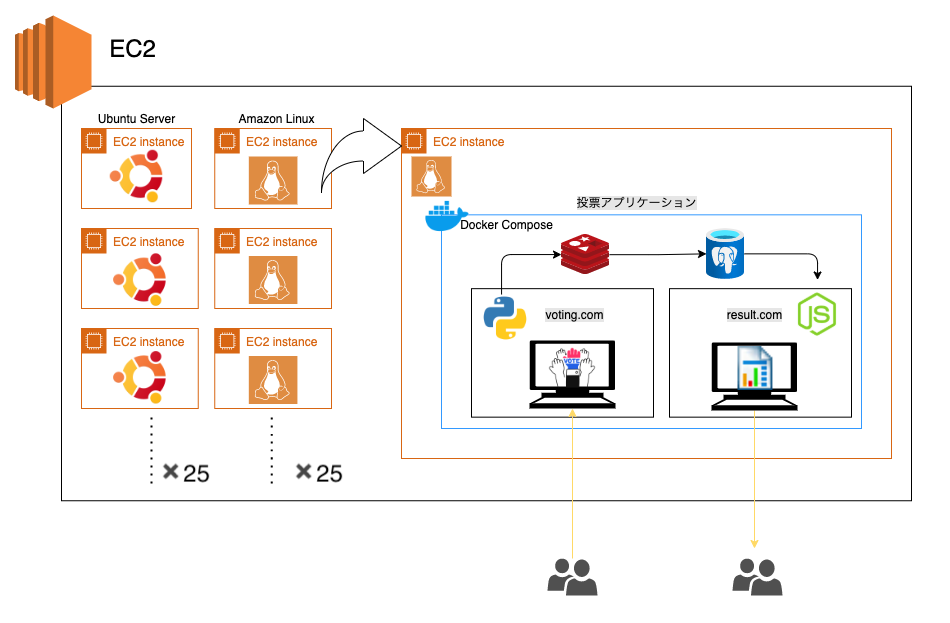
今回、検証に用いた環境は以下になります。
AWS EC2より以下のインスタンスを作成。
・Ubuntu Server (25個分)
・Amazon Linux2 (25個分)
実際は複雑なシステムの管理に「Splunk g Infrastructure Monitoring」を活用することと思いますが、今回は合計50個ほどインスタンスを構築してみました。
また、それぞれのAmazon Linux2の中には以下をインストールし、簡単なWebアプリケーションを作成しています。
・Docker version 19.03をインストール
・サンプルとして投票アプリケーションを作成
(参照:https://docs.docker.jp/desktop/dashboard.html)
こちらがシステムの構成図になります。
実際に触ってみた
今回は「Splunk Infrastructure Monitoring」をインストールし、どのように使うことができるのか検証した内容をご紹介します。
1.インストールしてみた
(公式HP:https://www.splunk.com/ja_jp/software/infrastructure-monitoring.html)
アカウント登録が完了するとメールでURLが送付され、アクセスすると下記のWebダッシュボード画面に遷移します。これは、「Splunk Infrastructure Monitoring」が連携しているサービスの一例になります。様々なサービスに連携していることがわかりますね。

(図:Splunk Infrastructure Monitoring が連携しているサービスの一例)
公式ドキュメントを参考にEC2で作成したインスタンスにエージェント(SignalFx SmartAgentと呼ばれます。)をインストールしていきます。
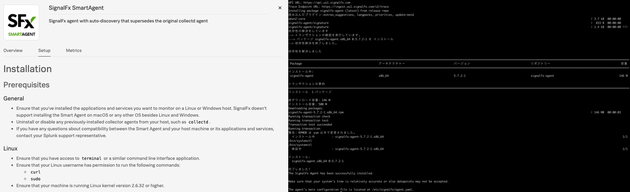
(図:左インストール方法の説明 右:Terminalにてインストールが完了した様子)
説明に従って、Terminalにコマンドを入力するだけでインストールが完了するのでとても簡単です。個人的に公式ドキュメントの「15分クイックスタート」の解説がわかりやく親切だなと感じました。
(公式ドキュメント:https://docs.signalfx.com/en/latest/getting-started/quick-start.html)
同じ作業を残りのインスタンスにも行います。
2.Webダッシュボードを触ってみた
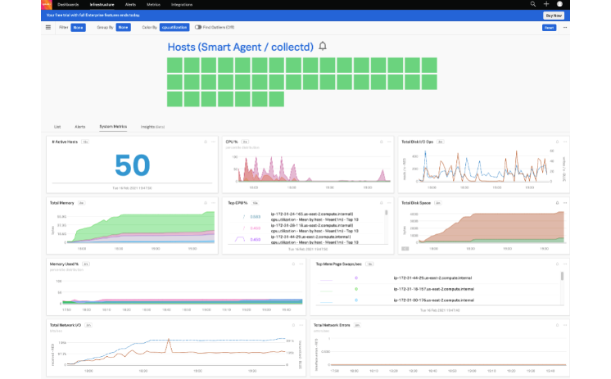
それでは、ホストの稼働状況を見ていきましょう。
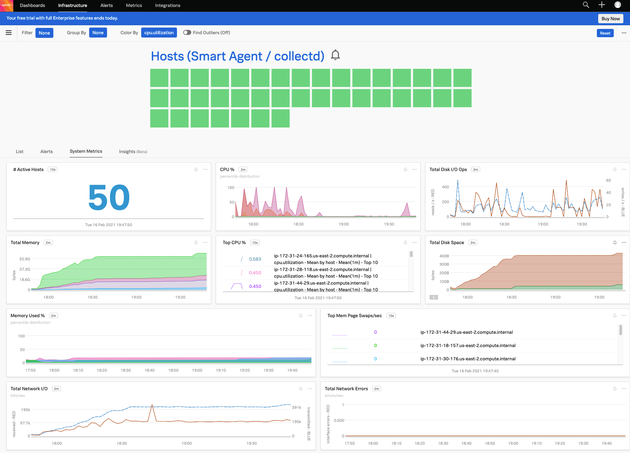
この画面から
- 稼働しているホストの数
- CPU使用率
- メモリ使用率
- ディスク使用率
- 合計ネットワークトラフィック
- 合計ディスク操作
- ネットワークエラー
が一目でわかります。
各項目をドリルダウンすることで、システムの詳細についてみることができます。シンプルな操作で分かりやすいです。
3.アラート上げてみた
システムに問題が発生したに際に知らせてくれるようアラート設定をしてみます。まずはどのような状況でアラートが上がるのか、しきい値を設定します。
今回は、
・CPU使用率80%以上が3分以上続いた場合、少し注意レベル(Major)の知らせ
・CPU使用率95%を超えた瞬間、危険レベル(Critical)の知らせ
といった意味合いで、アラートのレベルを2つに分けて設定しました。以下の画面からアラートを設定するのですが、最大値・最小値だけでなく、過去の同時刻との比較や、値が増減した際の振れ幅など様々な観点からアラートの設定ができ、カスタマイズ性があると感じました。
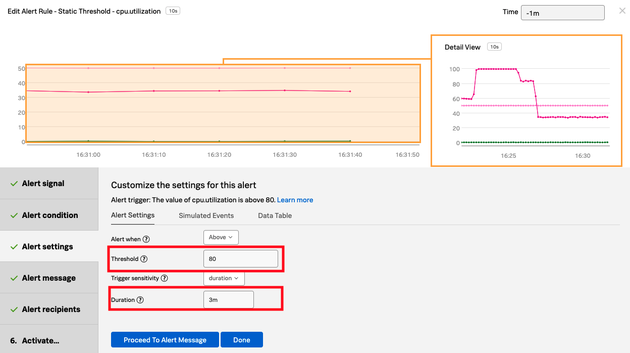
(図:アラートのしきい値の設定画面)
アラートを上げる方法として、Webhookを用いてSlack等に連携することも可能です。今回はシンプルにメールで知らせてくれるように設定しました。また、アラートのメッセージ(今回でいうとメールの件名と本文)をカスタムできるので、危険レベルの知らせについて件名を"Critical DangerAlert"にしてみました。
それでは準備ができたので、
・Amazon Linux2
のインスタンス 一つに負荷をかけていきます。
(ちなみにyes > /dev/nullコマンドを使いました。)
Webダッシュボード上のホストの色が元々の緑色から黄色になり、CPU使用率50%に増加していることがわかります。
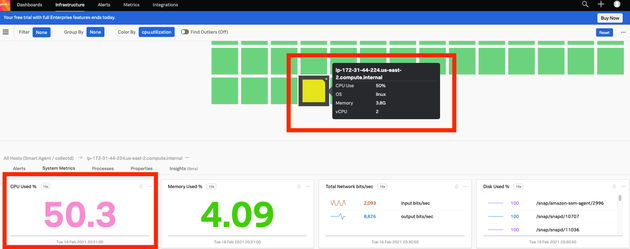

(図:CPUの負荷が徐々に大きくなっています)
CPU使用率80%以上が3分以上続いたので登録したメールアドレス宛に少し注意のアラートが飛びました。
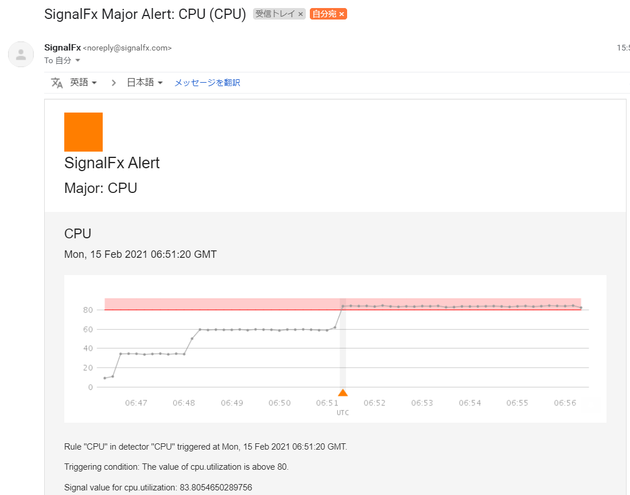
(図:メールで少し注意レベル(Major)の知らせ)
引き続き負荷をかけていき、CPU使用率を100%にしてみました。
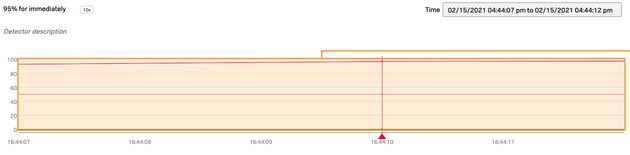
細かく見てみると、16:44:10になった際にCPU使用率が95%を超えたことがわかります。さらに "Critical DangerAlert"のメールが飛んできたことも確認できました。
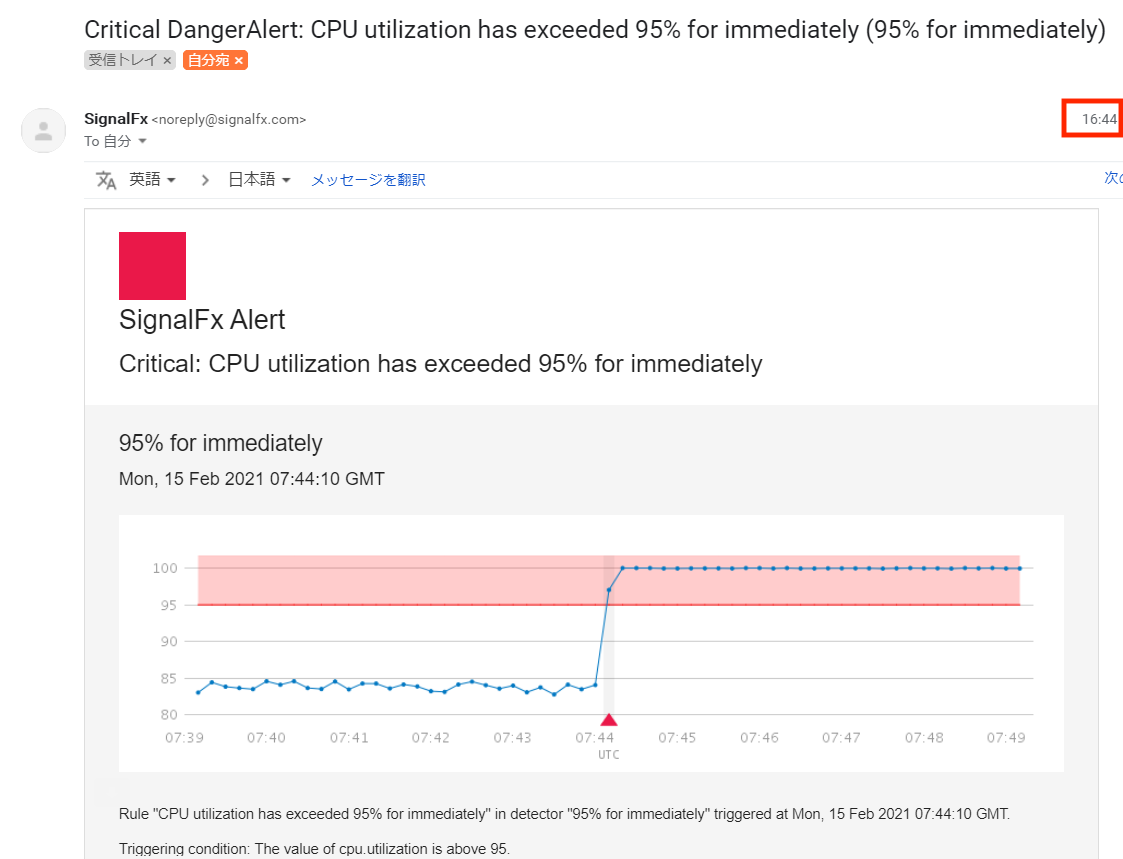
(図:メールで危険レベル(Critical)の知らせ)
まとめ
昨今の複雑なシステムでは数十秒、あるいは数秒の間に様々なことが起きます。それにも関わらず、「1分ごとにしかメトリクスを取得できない。」となると、どのような問題が生じていたのか見逃してしまいます。「Splunk Infrastructure Monitoring」では上記のように1秒単位でメトリクスを取得することができます。このため些細なシステムの変化を見逃すことなく対応することができます。
実際に触ってみると、Webダッシュボードが充実しており操作が容易であるように感じました。アラートやチャート、グラフを作る際に、設定項目としてかなり作り込めるので自分好みのオブザーバビリティ環境を構築することができます。
ご興味のある方はぜひ無料トライアルを触ってみてください!
関連ページ
公式HP:こちら
公式ドキュメント:こちら
「Splunk Observabirity Suite」紹介資料

DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






