Splunkが実現するクラウドネイティブ環境のオブザーバビリティ
オブザーバビリティとは何か?まずはその概念を理解しよう
Splunkが実現するクラウドネイティブ環境のオブザーバビリティ←本記事です
はじめに
前回の記事でも触れましたが、セキュリティやIT運用のためのログ管理と知られてきたSplunkですが、2019年にSignalFxとOmnitionの買収をきっかけに本格的にクラウドのオブザーバビリティという領域に参入しました。
この記事では、Splunkが取り組むオブザーバビリティのポイントと製品の概要について触れたいと思います。
オブザーバビリティには何が求められるのか?
流動的でダイナミックに変化するインフラや短命なリソースといったクラウドネイティブ環境では、Zabbix等のツールをベースとした従来の運用監視のようにホスト単位で監視するという手法は通用しません。では、何がポイントとなるのでしょうか?
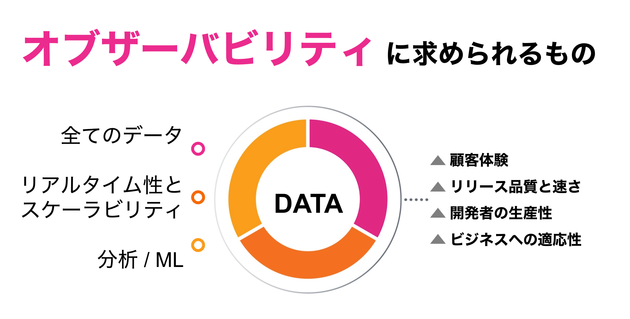
ダイナミックに変化する環境において、1秒後に何が起きるのかということですら非常に難しいものとなります。何か問題が起きたとき、どこに異常があったのか、また、原因は何だったのかを正確に特定し適切なアクションにつなげるためには、秒単位で変化するデータ全てを捕捉し、リアルタイムにアラート検知や可視化することが必須の要件となります。
また、Kubernetesに代表されるコンテナ環境では、各メトリクスにPod名やコンテナID、ノード名といった非常に多くのメタデータが付与されます。クラウド特有のスケーラビリティを持つ環境で発生する高カーディナリティなデータを秒単位で保持するためには監視ツール自体にもスケーラビリティが求められます。
サービスが稼働している環境の規模が大きくなるほど、そのような大量のデータを手作業で集計し分析することは困難なものとなります。対処すべき異常を逃さないために、機械学習を使った異常検知と自動化もまた重要な要件となります。
Splunk Infrastructure Monitoring / Splunk APM
そのような課題を解決するため、Splunkが提供するオブザーバビリティ製品がSplunk Infrastructure MonitoringとSplunk APMです。これは2019年に買収したSignalFxをベースとしたSaaSで、主にクラウドで稼働するマイクロサービスをリアルタイムに監視・観測することを実現する製品です。
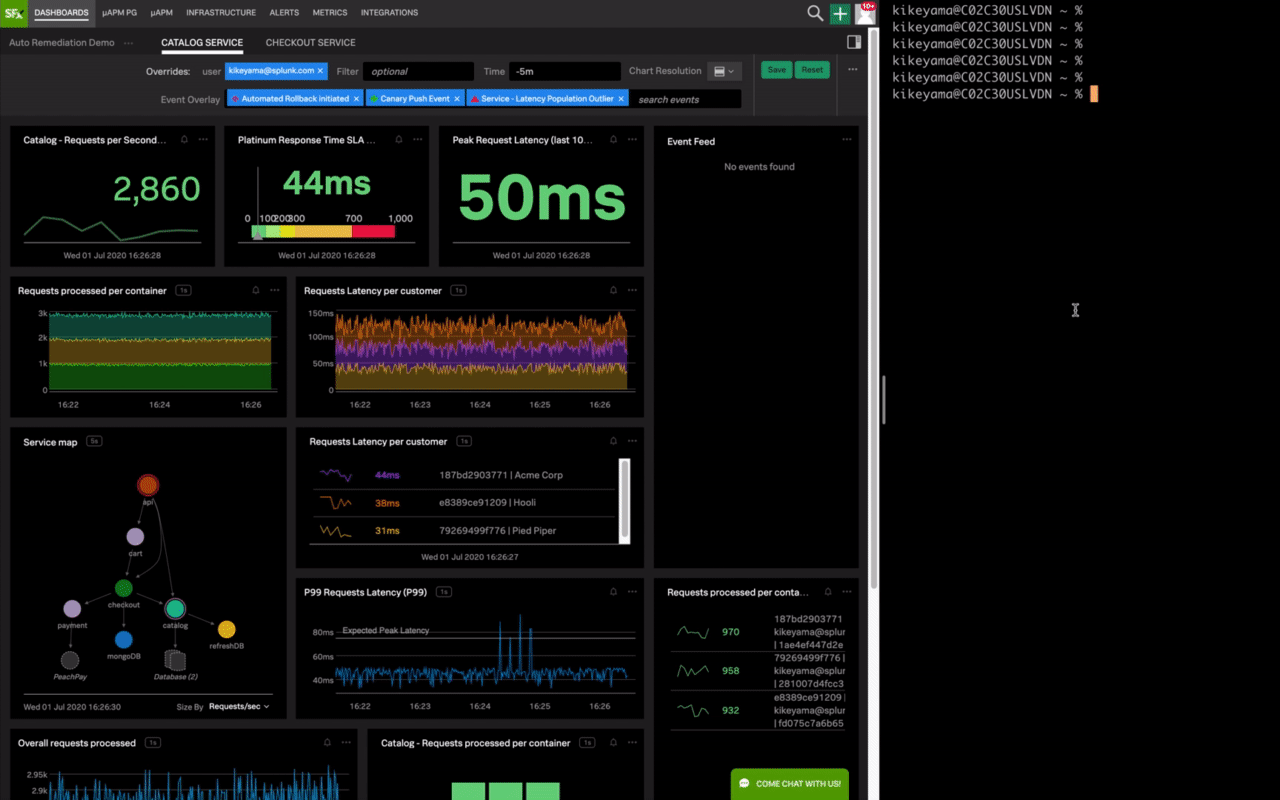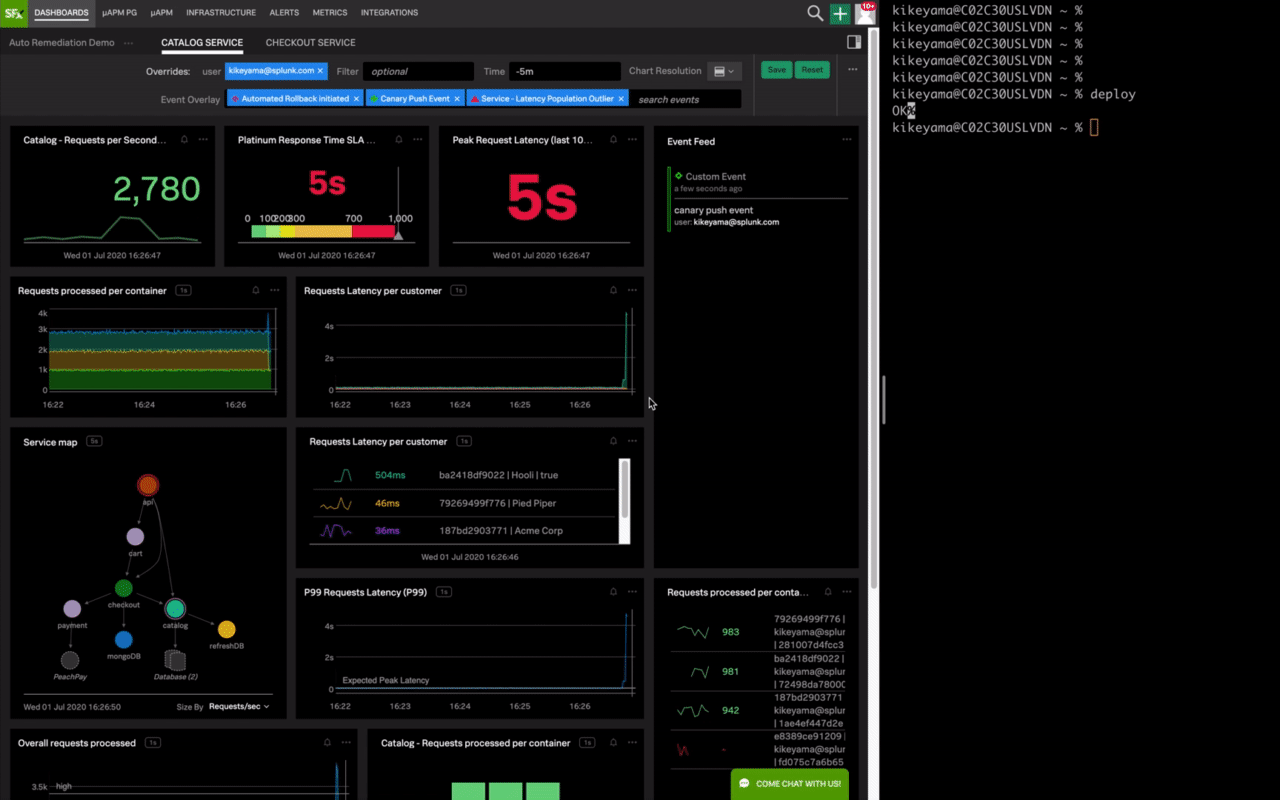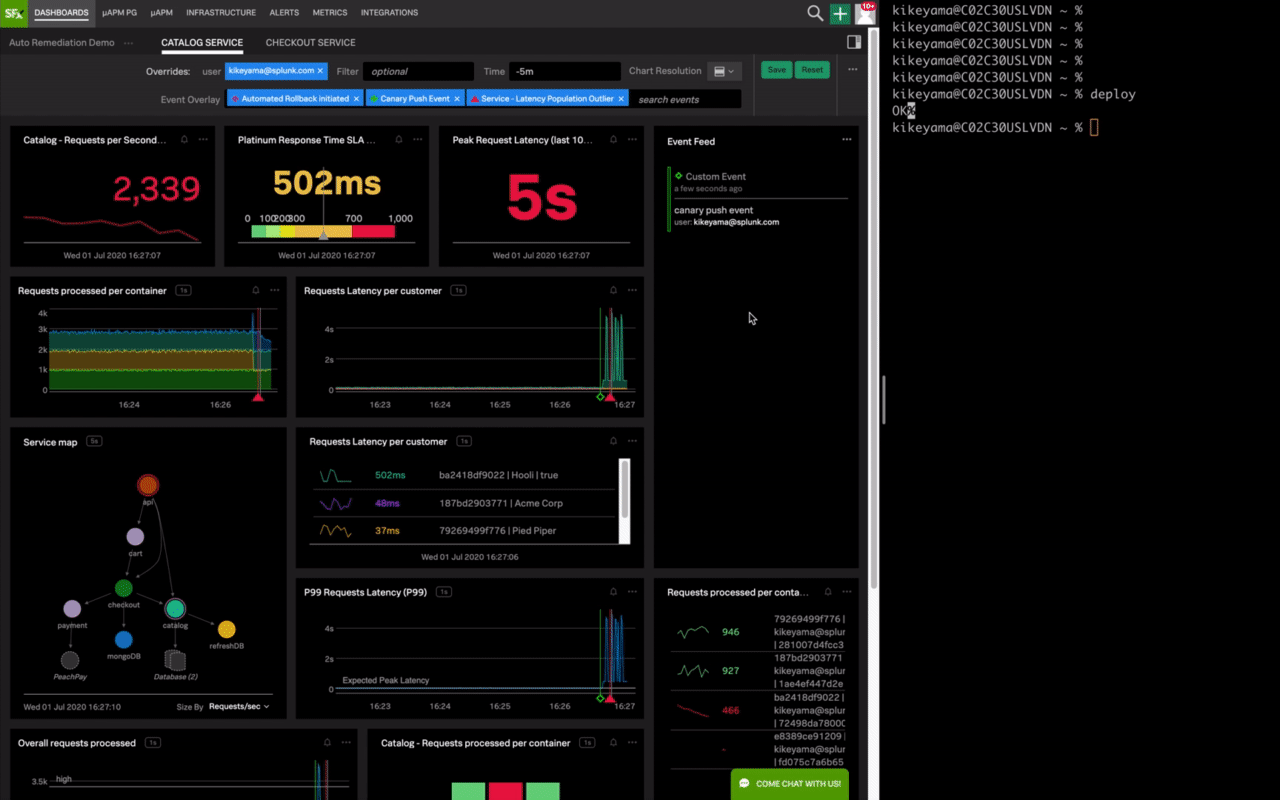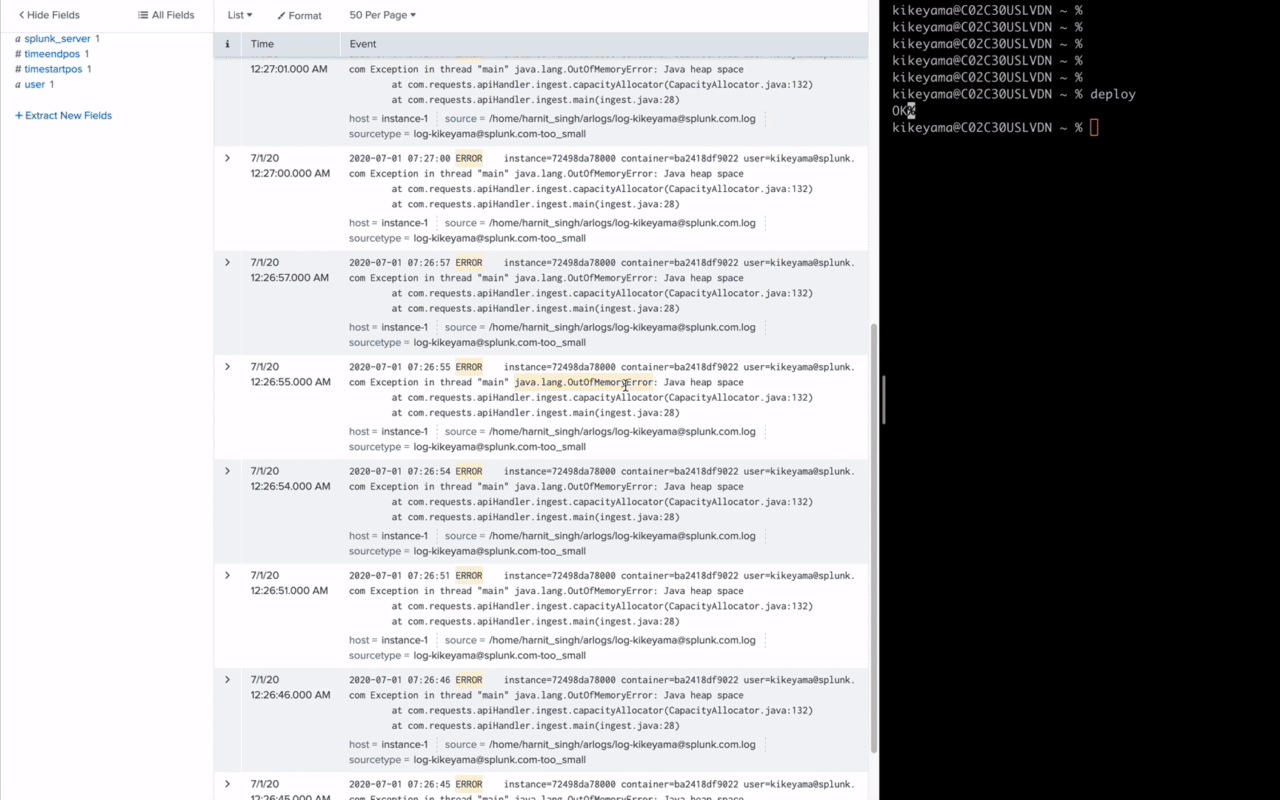
この図のデモでは、右側のコマンド入力でサービスの最新バージョンをカナリアデプロイしています。その後数秒でサービスのレスポンスが大幅に遅延しアラート検知し、アラートからコンテナIDをキーにSplunk Enterpriseでログを検索してOut of memoryエラーを特定するというシームレスなワークフローを実現しています。
このように、リアルタイムでのデータ投入、秒単位でのアラート検知から問題判別、原因の特定までを様々なデータを結び付けて連携することにより、ロールバックや再起動といった適切な対処につなげてサービスレベルの維持を可能とするのです。
クラウドインフラ監視
Splunk Infrastructure Monitoringでは、複雑化するクラウド環境において、あらゆるレイヤーにおけるフルスタックな監視を実現します。

- AWSやAzure、GCPといったパブリッククラウドからエージェントレスで取得するメトリクス
- エージェント経由で取得できるシステムメトリクスやミドルウェアのパフォーマンスメトリクス
- サーバーレスファンクションやアプリケーションのカスタムメトリクス
これら収集したメトリクスをビルトインのダッシュボードで可視化し、テンプレート化されたアラートを活用することで、すぐにインフラ監視を始めることができるのです。
Kubernetes Navigator
近年利用が拡大しているKubernetesですが、運用や監視における複雑さは常に課題の上位として挙げられています。複雑に入り組むコンポーネントやライフサイクルの短いコンテナリソース等、サービス規模が拡大するほどにその複雑さは増していきます。その状態を正確に把握して運用するためには監視ツールや運用方法の見直しに迫られることになるでしょう。
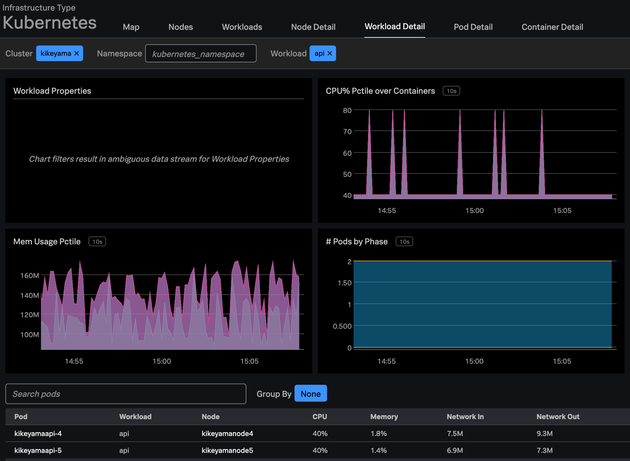
Splunk Infrastructure Monitoringの中でもKubernetesの監視に特化したKubernetes Navigatorは、そのような複雑化するKubernetes環境をリアルタイムに可視化し、さらに機械学習を使って異常と思われるリソースの抽出まで自動化するものとなります。
エージェント経由で取得したKubernetesのメトリクスやイベントを自動的に可視化するため、わずか数分でKubernetesの監視を始めて運用に活用することができます。
アプリケーションパフォーマンス監視
マイクロサービス化された分散環境では、サービス間の依存関係は複雑なものとなり、障害の根本原因の特定やパフォーマンスのボトルネックを検出することが困難となります。
アプリケーションパフォーマンスを監視する際、特定のマイクロサービスのみ注視するのではなく、関連するサービスも含めて全体を見ることが重要となります。そのための仕組みが分散トレーシングであり、Splunk APMもこの分散トレーシングをベースにしたアプリケーションパフォーマンスの監視を提供しています。
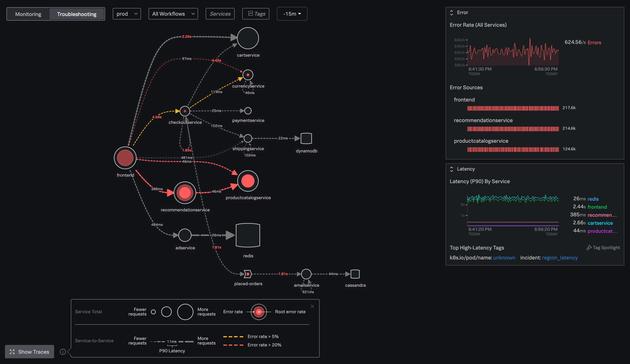
DBやPub/Subも含めた各サービスを依存関係含めてサービスマップ上に表示し、エラーが出ているサービスや、その根本原因となっているサービス、各サービスのレイテンシを俯瞰して確認することができます。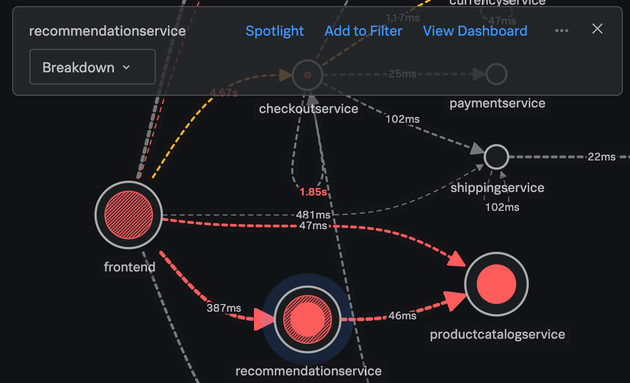
上図のサービスマップでは塗り潰しの赤がエラーを引き起こしているサービスを、網掛けの赤が連携先サービスに影響を受けたエラーとなっているサービスを示しています。recommendationservice では塗り潰しと網掛けの両方が混在しており、このままでは何が問題なのか、どう対処すればいいのかということはわかりません。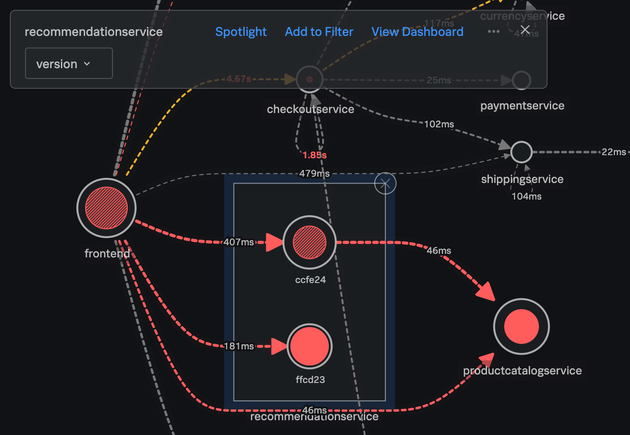
Splunk APMではトレースデータのタグ情報(Pod名やノード名、バージョン等)でブレイクダウンすることで、サービスマップでの全体俯瞰を維持したまま問題の判別を行うことができます。
この例では recommendationservice をバージョンごとにブレイクダウンすると、新しくカナリアデプロイしたバージョン ffcd23 において、根本原因となるエラーを引き起こしていることがわかります。バージョン ccfe24 でもエラーが発生しているものの、連携先のサービスによって引き起こされたエラーだとわかるので、まずは ffcd23 から ccfe24 にロールバックすることが必要なアクションであるとわかります。
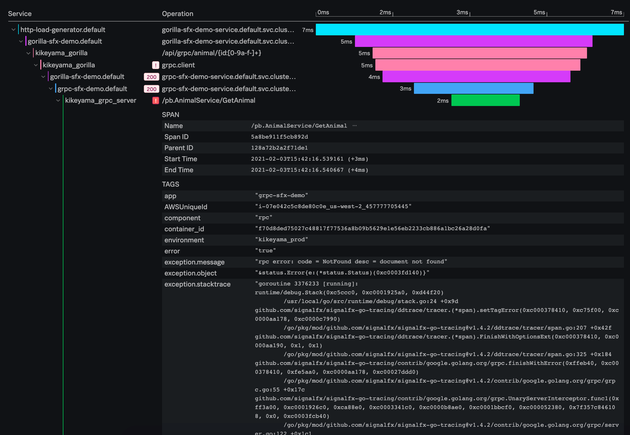
さらに根本原因を特定する際は各トレースからサービスごとの処理時間やエラーの詳細、スタックトレースを確認することができます。わずかに発生する異常も逃さないために、Splunk APMではこれらトレースデータをサンプリングせず100%捕捉しています。
様々な言語やフレームワークによって構成されるマイクロサービス環境において、各サービスのパフォーマンス情報を普遍的なデータとして取得・可視化し、依存関係も含めて全体俯瞰しながら素早く問題を切り分けすることがポイントとなります。
Splunkの今後の取り組み
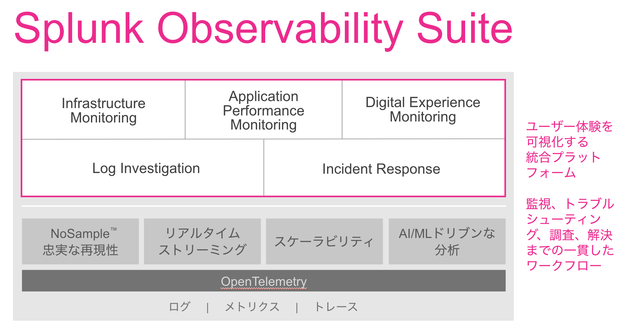
Splunkではオブザーバビリティへの取り組みを強化し続けています。Infrastructure MonitoringやAPMだけではなく、DIgital Experience MonitoringとしてRUM (Real User Monitoring) や外形監視 (Synthetics Monitoring) に取り組んでおり、近日中にリリースする予定です(2021年2月現在)。
クラウド環境の運用に取り組む際、オブザーバビリティの実現に向けて是非Splunkをお試しいただければと思います。
関連ページ
この記事の著者:池山邦彦
前職ではクラウドモニタリングSaaS製品を扱うスタートアップ企業にて、日本オフィス立ち上げメンバーとしてマーケティング活動やお客様を技術支援するプリセールス活動に従事。その後Splunkに転職し、クラウドネイティブ環境のユースケースを中心にSplunk製品群をお客様に提案し世に伝える仕事に取り組んでいる。

DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






