GraphQLって何?そして生成AIがGraphQLサーバーを生成可能か検証する

はじめに
こんにちは、株式会社カサレアルの越智と申します。今回はカサレアルの新コース「Spring for GraphQL ではじめるGraphQLアプリケーション開発入門」の紹介をしたくてブログを書いています。単なる宣伝ではなく、読者の皆さんにとって読んで価値がある記事にしたいので、GraphQLについて少し深堀した事や、面白味があるものを書いていきたいと思います。
GraphQLって何?それって必要なの?
GraphQLは、クライアントが必要するデータをWeb APIに要求するための問い合わせ言語です。ちょうどリレーショナルデータベースへの問い合わせがSQLで行われるのと同じように、Web APIに対しての問い合わせをGraphQLという言語で行います。
RESTful で作成されたWeb APIと異なり、GraphQLでは事前に形が決定されたデータをただ取得するのではなく、クライアントが必要とするデータを指定して柔軟にデータを取得できます。
RESTful Web APIでは、各リソースが固有のURIで識別され、そのURIに対してリクエストを送信することで、そのリソースに関するすべてのデータを取得します。このため、クライアントが必要のないデータまで取得してしまうオーバーフェッチが発生することがあります。
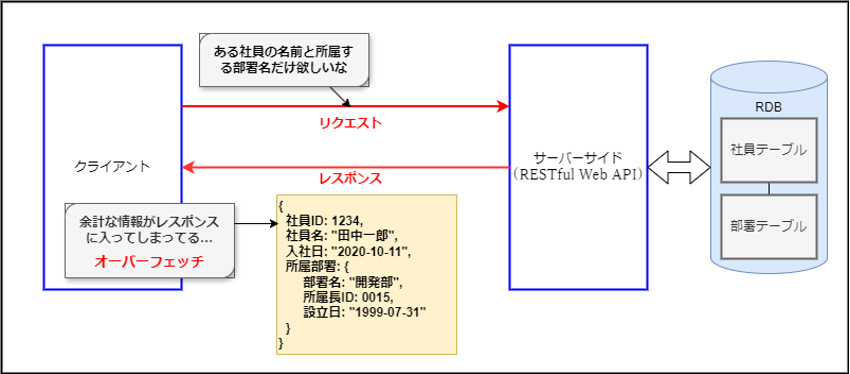
また、複数のリソースを取得する場合、それぞれに対して個別のリクエストを送信する必要があり、アンダーフェッチが発生する可能性があります。
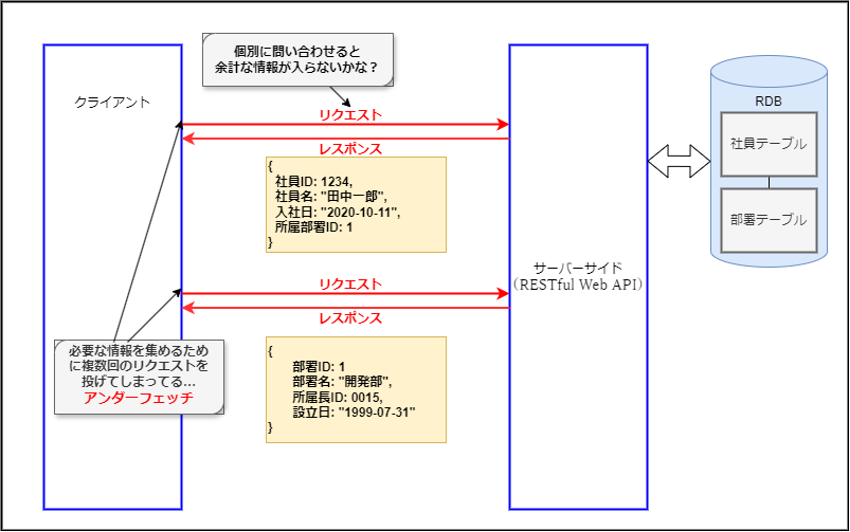
GraphQLでは、単一のエンドポイントに対して、クライアントが必要なデータの構造を記述したクエリーを送信します。サーバーは、そのクエリーに基づいて必要なデータだけを返します。これにより、オーバーフェッチとアンダーフェッチの問題を解消し、ネットワークトラフィックを削減することができます。
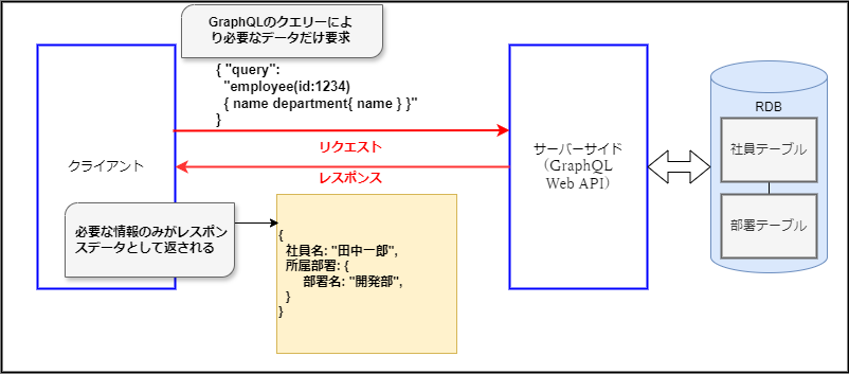
GraphQLは、クライアントとサーバー間のやり取りで、複雑なデータ構造を扱う場合や、頻繁に変化するデータを扱う場合において真価を発揮します。一方でクエリーの書き方などを学習する必要があり、若干の学習コストの高さを考慮する必要があるでしょう。
SpringでGraphQLサーバーはどうやって作成する?
Spring for GraphQLを使ってGraphQLサーバーをどのように作成するのか簡単に説明します。
- GraphQLのSchema
- コントローラークラス
1.のGraphQLのSchemaは、GraphQLサーバーに対してどのような問い合わせが出来るかと、その際の返答としてどのような形のデータを取り扱うのかを定義するファイルです。例としては下記のようになります。
type Query {
employees: [Employee]
employee(id: ID): Employee
}
type Employee {
id: ID
name: String
joinedDate: String
departmentId: Int
email: String
birthDay: String
}
この例では、Employeeという六つのフィールドを持ったデータ形を定義しています。Queryには全件検索を実行するemployeesとID検索を行うemployee(id: ID)という二つの検索操作を定義しています。
ファイル名の拡張子は*.graphqlsもしくは*.gqlsにします。
2. のコントローラークラスは通常のSpring MVCにおけるコントローラーと同じです。異なるのは"@QueryMapping"アノテーションを使って、GraphQLのSchema内のQueryで定義した操作を、コントローラーメソッドと関連付ける点です。例としては次のようになります。
package com.example.web.controller;
import com.example.persistence.entity.Employee;
import com.example.service.EmployeeService;
import org.springframework.graphql.data.method.annotation.Argument;
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;
import java.util.List;
@Controller
public class EmployeeController {
private final EmployeeService employeeService;
public EmployeeController(EmployeeService employeeService) {
this.employeeService = employeeService;
}
@QueryMapping
public List employees() {
return employeeService.findAll();
}
@QueryMapping
public Employee employee(@Argument Integer id) {
return employeeService.findById(id);
}
}
"@QueryMapping"アノテーションを付与したメソッドの名前をGraphQLのSchema内のQuery名と完全一致させることで、GraphQLの問い合わせ処理に対して自動的に利用されます。メソッドの戻り値はこの例ではEmployee型となっていますが、実際には、クライアントからのリクエストに応じて、必要な項目に絞り込まれた上でレスポンスされます。
コントローラー以降のレイヤ(たとえばサービスクラスやリポジトリクラス)は、通常のSpringアプリケーションと同じような構成物を作成していきます。
完成したGraphQLサーバーに対しては、例えばJavaScriptクライアントから次のように利用します。
// 全EmployeeデータをGraphQLサーバーより取得する関数
const getAllEmployees = async () => {
//GraphQLによる問い合わせの内容
const query = `
query {
employees {
id
name
email
departmentId
joinedDate
birthDay
}
}
`;
try {
//GraphQLサーバーのエンドポイントは"http://サーバーアドレス/graphql"で固定。
//このエンドポイントには必ずPOSTでアクセスする。
const response = await fetch('http://localhost:8080/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json', },
body: JSON.stringify(query)
});
if (!response.ok) throw new Error(`HTTP error! status: ${response.status}`);
const data = await response.json();
return data.data;
} catch (error) {
console.error('Error fetching employees:', error);
throw error;
}
};
GraphQLサーバーを生成AIで自動生成してみる
GraphQLの分野においては、Schemaファイル等を元にしてコードを自動生成することが盛んです。("graphql codegen"といったキーワードでインターネットを検索すると様々な情報が手に入ります。)
ここではGraphQL専門の自動生成の仕組みではなく、一般的な生成AIを使って、GraphQLのコードを自動生成できるか試してみたいと思います。利用する生成AIはChatGPT、Gemini、Claudeの三つです。いずれも無料で利用できる範囲で利用しています。
一般的にはChatGPTがどんな分野に対しても平均的に強いとされています。Claudeはスペック的に長文に対する処理能力が高く、Geminiはあまりプログラミングは得意ではないとの噂です。果たして結果はどうなるでしょうか?
なおこれらの生成AIに投げるプロンプトは下記のとおりです。
下記のSchemaファイルから、GraphQLサーバーのコードを生成してください。
type Query {
employees: [Employee]
employee(id: ID): Employee
}
type Employee {
id: ID
name: String
joinedDate: String
departmentId: Int
email: String
birthDay: String
}
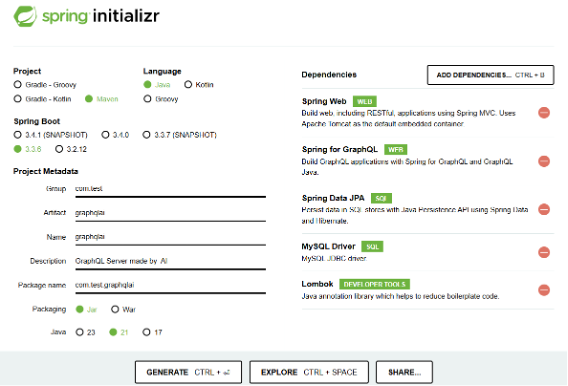
利用するライブラリは下記のとおりです。
・Spring for GraphQL
・Spring Web
・Spring Data JPA
・MySQL Driver
作成するコードはJavaで記述するものとし、下記のような三層構造を持つものとします。
・コントローラー
・サービスクラス
・レポジトリ
このプロンプトから生成AIによって生成されたコードを、Spring Initializrで準備したSpringアプリケーションに張り付け、動作するかどうかを試していきます。Spring Initializrの設定は次のようにしています。
■Claude
まずはClaudeです。結論から先に言うと生成されたコードはほぼそのまま動作しました。
こちらはClaudeが生成した全コードです。
// Entity class
package com.example.demo.entity;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
import lombok.Data;
@Data
@Entity
@Table(name = "employees")
public class Employee {
@Id
private String id;
private String name;
private String joinedDate;
private Integer departmentId;
private String email;
private String birthDay;
}
// Repository interface
package com.example.demo.repository;
import com.example.demo.entity.Employee;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface EmployeeRepository extends JpaRepository<Employee, String> {
}
// Service class
package com.example.demo.service;
import com.example.demo.entity.Employee;
import com.example.demo.repository.EmployeeRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Optional;
@Service
public class EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
public List getAllEmployees() {
return employeeRepository.findAll();
}
public Optional getEmployeeById(String id) {
return employeeRepository.findById(id);
}
}
// Controller class
package com.example.demo.controller;
import com.example.demo.entity.Employee;
import com.example.demo.service.EmployeeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.graphql.data.method.annotation.Argument;
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;
import java.util.List;
@Controller
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@QueryMapping
public List employees() {
return employeeService.getAllEmployees();
}
@QueryMapping
public Employee employee(@Argument String id) {
return employeeService.getEmployeeById(id).orElse(null);
}
}
// Application properties
# src/main/resources/application.properties
spring.datasource.url=jdbc:mysql://localhost:3306/employee_db
spring.datasource.username=root
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.graphql.graphiql.enabled=true
application.propertiesに書くべきデータベース接続設定も丁寧に教えてくれています。 コードに関する説明も行ってくれています。
このコードの主な特徴は以下の通りです:
エンティティクラス(Employee):
・JPA エンティティとしてマッピング
・Lombok の @Data アノテーションでボイラープレートコードを削減
リポジトリ(EmployeeRepository):
JpaRepository を継承して基本的な CRUD 操作を提供
カスタムクエリが必要な場合は追加可能
サービスクラス(EmployeeService):
・リポジトリを使用してビジネスロジックを実装
・全従業員の取得と ID による従業員の取得をサポート
コントローラー(EmployeeController):
・GraphQL クエリーをハンドリング
・@QueryMapping アノテーションで GraphQL クエリーとメソッドをマッピング
アプリケーションプロパティ:
・MySQL データベース接続の設定
・JPA の設定
・GraphiQL(開発用 GraphQL クライアント)の有効化
ただしエンティティクラス内のフィールドの型については、本来であればLocalDate型にしたいところも、Schemaファイルの設定に引きずられてかString型になってしまっています。(joinedDateなど)
//エンティティクラス(細かい所は...で省略)
...
public class Employee {
...
...
...
private String joinedDate; //本当はLocalDate型にしたいフィールド
...
...
private String birthDay; //本当はLocalDate型にしたいフィールド
}
またプロンプトで指示していなかったLombokを利用している点も個人的にマイナスです。
■Gemini
次にGeminiです。こちらもおおむね修正なしで動作しました。(生成されたコード全体を掲載するのは、さすがに冗長ですので割愛します。基本的にClaudeのものとほぼ変わりませんでした。)
気になる点としては、生成されたコードにpackage文やimport文、そしてファイル名の指示がないところです。そのあたりはJavaエンジニアならだれでも自分で書けるでしょうという判断なのかもしれません。あとはやっぱり勝手にLombokが導入されています。
//本来必要なpackage文やimport文がない...
@Entity
@Data //←Lombok用のアノテーション
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private LocalDate joinedDate; //LocalDate型にしてくれてるのは嬉しい
private Integer departmentId;
private String email;
private LocalDate birthDay; //LocalDate型にしてくれてるのは嬉しい
}
フィールド名から判断しているのか、ClaudeでString型とされていたフィールド(joinedDateなど)はLocalDate型になっています。 その他、全体的にコードの説明がClaudeより丁寧でした。実際に生成された説明文章は、長くなるので割愛しますが、Geminiは聞かれた事に応える多くの場合に、ポイントとなる考え方や注意点、改善点などを最後にまとめてくれます。冗長といえば冗長ですが、生成AIはあくまで人間の補助として使われるもので、答えそのものを出す存在ではないという考えなのかもしれませんね。
■ChatGPT
最後はChatGPTです。こちらも生成されたコードをそのまま使って動作させることができました。 生成されたコードには、packageやimport、そしてファイル名の指示があります。Lombokも使っていません。ただ各フィールドのためのgetterとsetterはコメントで"Getters and Setters"と書かれてあるのみで省略されてしまっています。
package com.example.graphql.model;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import java.time.LocalDate;
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private LocalDate joinedDate;
private Integer departmentId;
private String email;
private LocalDate birthDay;
// Getters and Setters
}
それ以外の所は、他の生成AIが生成したコードと変わりがありませんでした。そして意外にもコードに関する説明がほぼありませんでした。
おわりに
最後にまとめですが、GraphQLはSchemaファイルという定義ファイルがあるおかげか、生成AIたちはどれも割と的確にコードを生成してくれています。ただしどれも動作することが目的のコードになっているので、エラー処理などは適宜、人間側が入れていく必要があります。またこれはよく言われる事ですが、やはり正解となるコードが分かっている状態でないと、生成されたコードが正しいか判断できませんし、そのまま使おうとして、ファイル名や配置場所が分からずに動作させることができないといった事も起きそうです。生成AIは便利な存在ですが、うまくこれからも付き合っていきたいところです。
トレーニングのご紹介
弊社カサレアルでは、本ブログで説明した"SpringでGraphQLサーバーを作成する方法"について、専門の講師の元、詳細に学べるトレーニングが用意されています。このトレーニングを使って正しいGraphQLサーバーのコードがどんなものかを学べます。
「Spring for GraphQL ではじめるGraphQLアプリケーション開発入門」 (https://www.casareal.co.jp/ls/service/openseminar/1009-online)
このトレーニングは2日間コースで、Spring BootやRESTful Web Service開発の経験がある方を対象に、「Spring for GraphQL」を基礎から学びます。ハンズオンを多数行い実践的に学ぶことができます。
このトレーニングで学べることは次の通りです。
- GraphQLの基本操作
GraphQLの基本構文やクエリーの実行方法等を学習します。
- Spring for GraphQLの導入と実践
Spring for GraphQLを使ったデータ取得や更新の方法を学習します。
他にもSpring Data JPAを利用したデータベース操作もカバーします。
- 実用的な機能
ページネーションの実装や、エラーハンドリングの方法を学習します。
その他にも実際の開発の際に役に立つTIPSを集めた付録も用意しております。基本的なSpringの知識と、なんらかWeb APIを作成した経験があれば問題なく受講できますので、ぜひご受講を検討してください。よろしくお願いいたします。
関連リンク
この記事の著者:越智理夫
様々な研修コースの開発および実施を担当。研修コンテンツへのゲーミフィケーション導入を日夜、探求している。

DevOps Hubのアカウントをフォローして
更新情報を受け取る
-
Like on Facebook
-
Like on Feedly






