


はじめに
みなさん、こんにちは。SB C&Sの加藤です。
本連載記事ではデータを活用するためのノウハウについてご紹介させていただきます。
==========================================================
□DataOps 第1回 「The DataOps 18の原則」
□DataOps 第2回 「2019年のDataOpsサーベイから見た課題」
□DataOps 第3回 「データ分析の8つのチャレンジ」(前編)
□DataOps 第4回 「データ分析の8つのチャレンジ」(後編)
■DataOps 第5回 「 DataOpsを実践するための7つのステップ」(前編) ※本記事です!
□DataOps 第6回 「DataOpsを実践するための7つのステップ」(後編)
==========================================================
前回までは、問題提起という感じが強かったですが、今回はそれらの課題を解決する方法について解説していきます。
データ分析チームが、DataOpsを実践することで、顧客からの絶え間ない要求への変更を迅速にかつ効率的に行うための7つのステップについて前後編にわたってご紹介していきたいと思います。
DataOpsを実現するための7つのステップ
Step1. データを追加したらテストも追加する
分析パイプラインに変更を加えた場合、何かを壊していないことをどのようにして把握しますか?
自動化されたテストは、時間のかかる手動テストを必要とせずに、高品質な機能のリリースを保証します。DataOpsの考え方は、データ分析チームのメンバーが変更を加えるたびに、その変更に対するテストを追加するというものです。
テストは、各機能が追加されるたびに段階的に追加されるため、テストは徐々に改善されていきます。大規模な環境では、パイプラインの各段階で何百ものテストが存在する可能性があります。
データ分析でテストを追加することは、製造オペレーションフローに実装されている統計的プロセス制御(Statistical Process Control)に似ています。テストは、進行中の作業(パイプラインの中間ステップの結果)が期待値と一致していることを検証することで、最終出力の完全性を保証します。テストは、データ、モデル、ロジックに適用することができます。下図1は、データ分析パイプラインにおけるテストの例を示しています。データ分析パイプラインの各ステップには、少なくとも1つのテストが必要です。
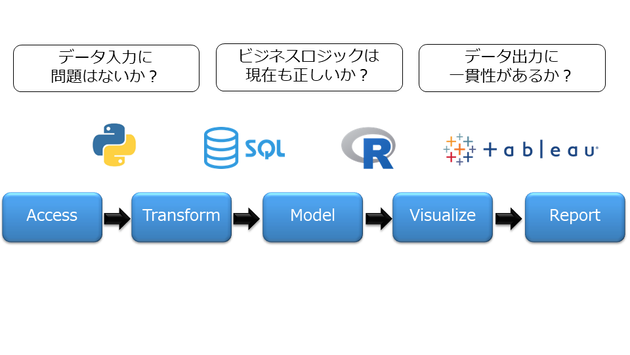
(図1.分析パイプラインに追加するテストの例)
まずは、シンプルなテストから始めて、時間をかけて成長させていくことです。単純なテストであっても、最終的には顧客に公開される前にエラーをキャッチします。例えば、行数がプロセスを通して一貫していることを確認するだけでも、非常に強力なテストになります。DataOpsは完璧であることを求めているわけではなく、実際、コードが不完全であることを認めています。データ分析チームが最善の努力をしても、何かを見逃してしまうのは当然のことです。その場合は、問題の原因を特定し、二度と起こらないようにテストを追加すればよいわけです。DataOpsでは、変更を加えてすぐにテストスイートを再実行できるため、迅速に作業を進めることができます。変更がテストに合格すれば、データ分析チームのメンバーは自信を持ってリリースすることができます。
Step2. バージョンコントロールを行う
生データを利害関係者にとって有用な情報に変換するためには、多くの処理ステップがあります。データは、前処理、クリーニング、チェック、変換、結合、分析、報告といったステップをとります。データ分析パイプラインは、ETLツール、データサイエンスツール、セルフサービスデータ前処理ツール、レポートツール、可視化ツールなどを含む様々なツールを使用して実装されたステージのセットとなります。ステージは連続的に実行されることもありますが、多くのステージは並列化することができます。パイプラインのステージはスクリプト、ソースコード、アルゴリズム、html、設定ファイル、パラメータファイル、コンテナ、その他のファイルによって定義され、これらの項目はすべて、本質的には単なるコードです。コードは、再現性のある方法でデータ分析パイプライン全体を端から端まで制御します。この再現性を可能にする成果物(ファイル)は、通常、継続的な改善の対象となります。他のソフトウェア・プロジェクトと同様に、データ・パイプラインに関連するソース・ファイルは、Gitなどのバージョン管理(ソース・コントロール)システムで管理する必要があります。バージョン管理ツールは、個人のチームがコードの変更やリビジョンを整理して管理するのに役立ちます。また、コードを既知のリポジトリに保持し、ディザスタリカバリを容易にします。しかし、バージョン管理の最も重要な利点は、データ分析チームのメンバー によるプロセスの柔軟な変更管理です。
Step3. バージョン管理によって、ブランチ(分岐)とマージ(統合)を活用する
典型的なソフトウェアプロジェクトでは、開発者は様々なソースコードファイルを継続的に更新しています。開発者がある機能に取り組みたい場合、開発者はバージョン管理ツールから関連するすべてのコードのコピーを取り出し、ローカルコピー上で変更を開発し始めます。このローカルコピーはブランチと呼ばれます(図2)。このアプローチは、データ分析チームがデータ分析パイプラインへの多数のコーディング変更を並行して維持するのに役立ちます。ブランチへの変更が完了してテストが行われると、ブランチからのコードは、コードの元となったトランクにマージされます。ブランチとマージは、データ分析の生産性を大きく向上させることができます。なぜなら、チームがお互いのペースを落とすことなく、同じソースコードファイルに並行して変更を加えることができるからです。各チームメンバーは自分の作業環境をコントロールすることができます。自分でテストを実行したり、変更を加えたり、リスクを取ったり、実験したりすることができます。望むならば、変更を破棄して最初からやり直すこともできます。チームメンバーが並行して作業できるようにするためのもう一つの鍵は、分離されたマシン環境を提供することに関係しています。
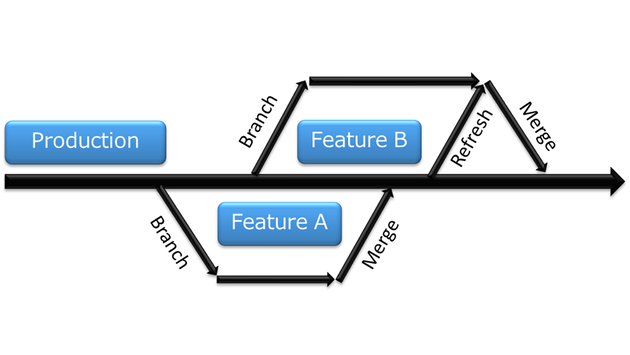
(図2.ブランチとマージ)
Step4. 複数のマシン環境を使用する
データ分析チームの各メンバーは、自分のラップトップに自分の開発ツールを持っています。バージョン管理ツールを使用することで、チームメンバーは他のチームとの連携を保ちながら、自分だけのソースコードのコピーで作業することができます。データ分析では、チームメンバーが必要なデータのコピーも持っていなければ、生産性を上げることはできません。ほとんどのユースケースは、1テラバイト(TB)以下でカバーできます。歴史的にディスクスペースは法外に高価でしたが、今日では、1TBあたり月額25ドル以下(クラウドストレージ)で、コストはチームメンバーの単価よりも重要ではなくなりました。データセットがまだ大きすぎる場合、チームメンバーは必要なデータのサブセットだけを取ることができます。多くの場合、チームメンバーは、テストや機能の1セットを開発するためにデータの代表的なコピーだけを必要とします。多くのチームメンバーが本番用データベースで作業すると、競合が発生する可能性があります。データベースエンジニアがスキーマを変更すると、レポートが壊れてしまうことがあります。新しいモデルを開発しているデータサイエンティストは、新しいデータが流入してくると混乱するかもしれません。チームメンバーに独自の環境を与えることで、組織の他のメンバーの作業に影響を受けないようにすることができます。
他のおすすめの記事はこちら
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部
加藤 学
