こんにちは。SB C&Sの幸田です。
NVIDIA の年次イベントである GTC (GPU Technology Conference) は、近年では春と秋の2回に渡って開催されており、今回も2022年度秋の開催分として、9/19〜22 の期間でオンライン形式でのイベントが展開されました。
CEOの Jensen Huang 氏による基調講演 (Keynote) は、現地時間の 9/20 8:00 (日本時間24:00) から一時間半ほどライブ放映されました。YouTube に公開されており、以下のリンクからご視聴可能です。
GTC Sept 2022 Keynote with NVIDIA CEO Jensen Huang
★日本語字幕も完備しています。画面下の設定(歯車マーク)から表示可能です。
今回も基調講演の中で、そして基調講演と同時に発信されたプレスリリースによって、新しいテクノロジー、プロダクト、および先進的な事例が多数発表されました。
以下、さっそく簡単にまとめてみましたので、まずは参考までにご覧いただければと思います。詳細については実際に基調講演やプレスリリースをご覧になったり、NVIDIAからのより詳細な発表をお待ちいただくなどして頂ければと思います。
やや長くなりますが、ぜひ最後まで目を通していただけますと幸いです。
新GPUアーキテクチャ Ada Lovelace の発表

リアルタイム レンダリングや物理シミュレーション、さらにはNVIDIAがリードするデジタルツイン空間内でのAI処理のパフォーマンスを大きく向上させる新しいアーキテクチャ Ada Lovelace (エイダ ラブレス) が発表されました。
シェーダー性能は90TFLOPSを実現し、さらに新技術 "シェーダー実行リオーダリング" によって処理を瞬時に整理し効率化します。レイトレーシングの処理に特化したRTコアは、スループットの向上に加えて新たな Opacity Micro-Map エンジン、および Micro-Mesh エンジンを備えます。また、AIによってフレームを予測表示し、実際の描画処理の負荷を低減しつつ高いフレームレートを実現するテクノロジーである DLSS の最新バージョン DLSS 3 に対応しています。
GeForce RTX 4090/4080 の発表

Ada Lovelace を採用したコンシューマー向けGPUは、複数のモデルが発表されました。最も高性能なモデルである GeForce RTX 4090 は、従来のハイエンドGPUモデル Ti 3090 に比べて、Microsoft FlightSimulator で2倍、新たにRTXに対応した人気ゲーム Portal で3倍、NVIDIA Omniverse で構築されたカーレースのシミュレーション RaceX で4倍の高速化を実現します。
ワークステーション向け NVIDIA RTX 6000 Ada Generation GPU

https://www.nvidia.com/en-us/design-visualization/rtx-6000/
こちらはプレスリリースにて発表された、Ada Lovelace を採用したプロフェッショナル向けのワークステーション搭載用GPUです。48GBのGPUメモリを搭載した、高度なグラフィックスを扱う専門家の使用にも耐えられるモデルです。
データセンター向け NVIDIA L40 および最新の NVIDIA OVX

データセンターのサーバーに搭載するための Ada Lovelace 採用 GPU である NVIDIA L40 も発表されました。また同時に、この L40 を8基搭載する最新の NVIDIA OVX も発表されており、今後各ハードウェアメーカーなどから供給される予定です。
NVIDIA Omniverse Cloud の開始を発表

2022年3月開催のGTC Spring 2022ではコンセプチュアルな発表にとどまっていた Omniverse Cloud ですが、ついにサービスの提供開始が発表されました。現在はAWSにて、仮想空間内のAI学習のためのデータを合成するOmniverse Replicator, レンダリングやデータの合成/変換を行う Omniverse Farm と共に利用可能となっています。
Omniverse Cloud は、"Omniverse Cloud Computer" と呼ばれるアーキテクチャの上で提供されます。Omniverse Cloud Computer は、グラフィックスやシミュレーションに最適化された GPU 搭載サーバーである OVX, 同じくAIワークロードに特化した HGX, そして世界中に分散配置されコンテンツの高速ストリーミングを可能とするネットワーク GDN によって構成されます。GDNは動画などのWebコンテンツの高速配信のためによく利用されるCDN (Contents Delivery Network) に近い仕組みであり、いわば「Omniverse Cloud コンテンツ専用の CDN」といえます。
NVIDIA Omniverse のエコシステムのアップデートや、先進的な導入事例を多数発表

Omniverse は進化を続けています。3rd party ソフトウェアとのコラボレーションを実現するコネクターは新たに11種類が追加され、新規ツールやシミュレーター、SDK などが発表されました。特にフォーカスされたのは、Siemens が開発した JT とのコネクターです。JT は、NX, Creo, CATIA, InventorなどCADシステムの相互運用フォーマットです。この JT のモデルをOmniverseに取り込むアップデートは、製造業におけるOmniverseの活用を大きく広げることを意味します。

加えて、Omniverse を導入し、デジタルツインによるビジネスの変革を実現している企業/組織の事例が多数示されました。多種多様なツールを用いるエンジニアやデザイナーが連携し、効率的なワークフローを組んで推進しているさまざまな先進的な事例が紹介されました。ピックアップされていた事例としては、以下のようなものがあります。
・英国のVFX制作会社 DNEG
・NVIDIA が開発したカーレースのシミュレーション RaceX の開発チーム
・米国を代表する建築設計事務所である KPF(Kohn Pedersen Fox)
・世界有数の自動車会社 ゼネラルモーターズ
・米の大規模通信事業者 Charter と、GPU活用クエリやデータ視覚化の先端企業 HEAVY.AI
・世界最大級のホームセンター小売企業 Lowe's
・ドイツの鉄道会社 Deutsche Bahn
自動運転のプラットフォーム NVIDIA DRIVE Thor

NVIDIAのプロダクトは自動運転におけるコンピューティング全般をカバーしていますが、こちらの NVIDIA DRIVE Thor は車載コンピューターにあたるものです。タイムクリティカルな処理を行えるリアルタイムUnix系OSのQNXに加え、LinuxやAndroidも同時実行可能なこの Thor は、現状いくつかに分割されている車載コンピューターをセントラライズし、性能/機能の向上と、電力やコストの削減を両立します。
ロボティクスコンピューター Jetson Orin Nano - Orin を応用

ロボティクス用に開発されたプロセッサーである Orin を、小型のロボティクス向けコンピューターである Jetson に搭載した Jetson Orin Nano が発表されました。すでに一般向けに販売されて大人気を博している Jetson Nano の80倍にもなる性能を持ち、NVIDIA のロボティクス向けソフトウェアスタックである Isaac を実行可能です。またオープンソースのロボット用アプリケーションフレームワークである ROS 2 に対応しています。
Orin はエッジにも応用 - NVIDIA IGX Orin

さらに Orin は、エッジコンピューター AI 向けのプラットフォームである NVIDIA IGX にも応用されます。この IGX 上で動作するソフトウェアスタックである Metropolis は、アプリケーションのフレームワークおよび開発ツール、さらにはエコシステム構築のための標準としても機能しており、すでにアプリケーションパートナーが 1,000 社以上存在しています。カメラ、LiDAR, ほか IoT センサーを活用した Metropolis ベースのサービスやアプリケーションは、製造業、運輸業、小売業など様々な場面で活用されています。Metropolis と IGX Orin を Siemens 社が採用したことも同時に発表されました。
医療機器での Orin と NVIDIA Clara Horoscan の活用 - 新たに3つの手術用システム

Orin IGX 上では、医用画像プラットフォームである Clara Holoscan も実行可能で、現在 70 を超える医療機器メーカーや医療機関、スタートアップが Clara Holoscan で開発を行っています。今回の発表では Activ Surgical, Proximie, Moon Surgical の3社が、手術用ロボティクスシステムを構築することが明かされました。
ロボティクス向けソフトウェアスタック NVIDIA Isaac クラウド対応

ロボティクス用ソフトウェアスタックの Isaac が、クラウドで提供されることが発表されました。各種クラウドに対応した Omniverse の仮想マシンイメージを用意し、NGC (NVIDIA GPU Cloud) から Isaac コンテナを取得することで、各種パブリッククラウド(AWS, Azure, GCP, OCI)に Isaac を展開できます。さらに AWS では Marketplace のメニューから Omniverse の最適化済みマシンイメージと Isaac のコンテナを利用可能となっています。
各種 SDK, ライブラリ、フレームワークも、新たなリリース多数あり
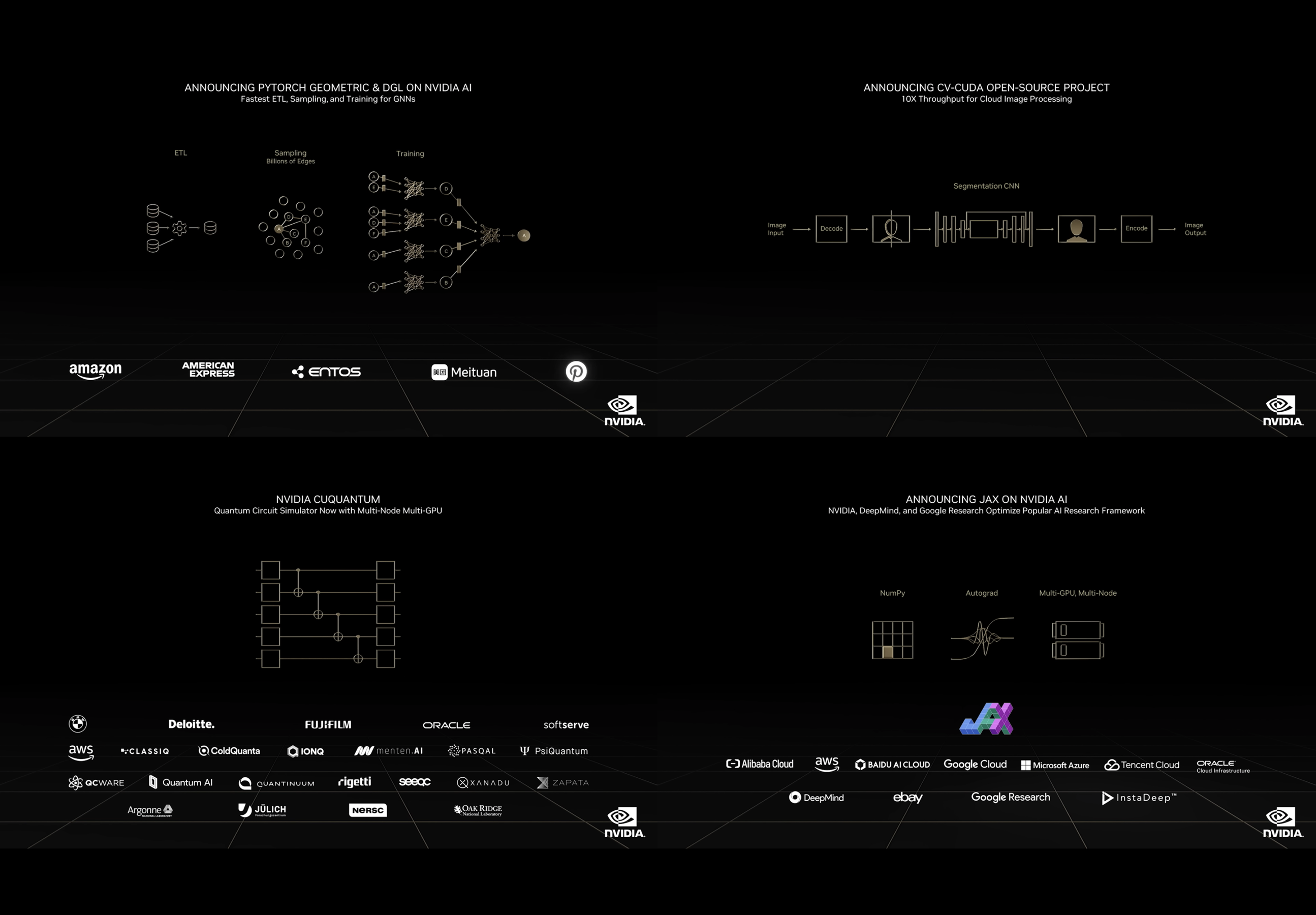
こちらは NVIDIA が特に力を入れている分野のひとつです。NVIDIA の提供する各種のハードウェア・ソフトウェアをベースとした開発者は、現在世界に350万人も存在しています。その中で、550を超えるライブラリが3,000以上のアプリケーションを高速化しています。SDK も過去12ヶ月で更新は100を超え, 新規開発は25にも上ります。今回の発表ではまず、データサイエンスを広範にカバーする SDK である RAPIDS や、AI 推論処理のハイパースケールが可能なソフトウェアスタックである Triton の活用の広がりが示されました。
新たな発表としては、まず最初にグラフ解析を応用したニューラルネットのフレームワークとして特に人気のある PyTorch Geometric と DGL の高速化が、NVIDIA の AI プラットフォームによって行われていることが明かされました。また Amazon や American Express, Piterest などがこのグラフ解析によるディープラーニング手法の主要ユーザーであることも紹介されました。
また、AI における画像処理を高速化するライブラリ CV-CUDA のオープンソース化が発表されました。主に機械学習における画像の前処理・後処理を高速化するもので、処理のパイプラインはエンドツーエンドで構築することが可能です。
さらに、量子コンピューターのシミュレーターである cuQuantum と、プログラミング環境 QODA にも触れられ、AWS の量子コンピューターサービス Bracket での cuQuantum 採用や、Oracle が OCI 向けに量子シミュレーション仮想マシンを開発中であることが明かされました。
そして最後に、自動微分とXLAを備えた機械学習用のPythonライブラリである JAX の高速化に向けて、NVIDIA がGoogle Research や DeepMind と協業して第4四半期に向けて開発を進めていることが発表されました。JAX on NVIDIA AI は、コンテナの形式で提供される予定です。
NVIDIA NeMo - 大規模言語モデル (LLM)
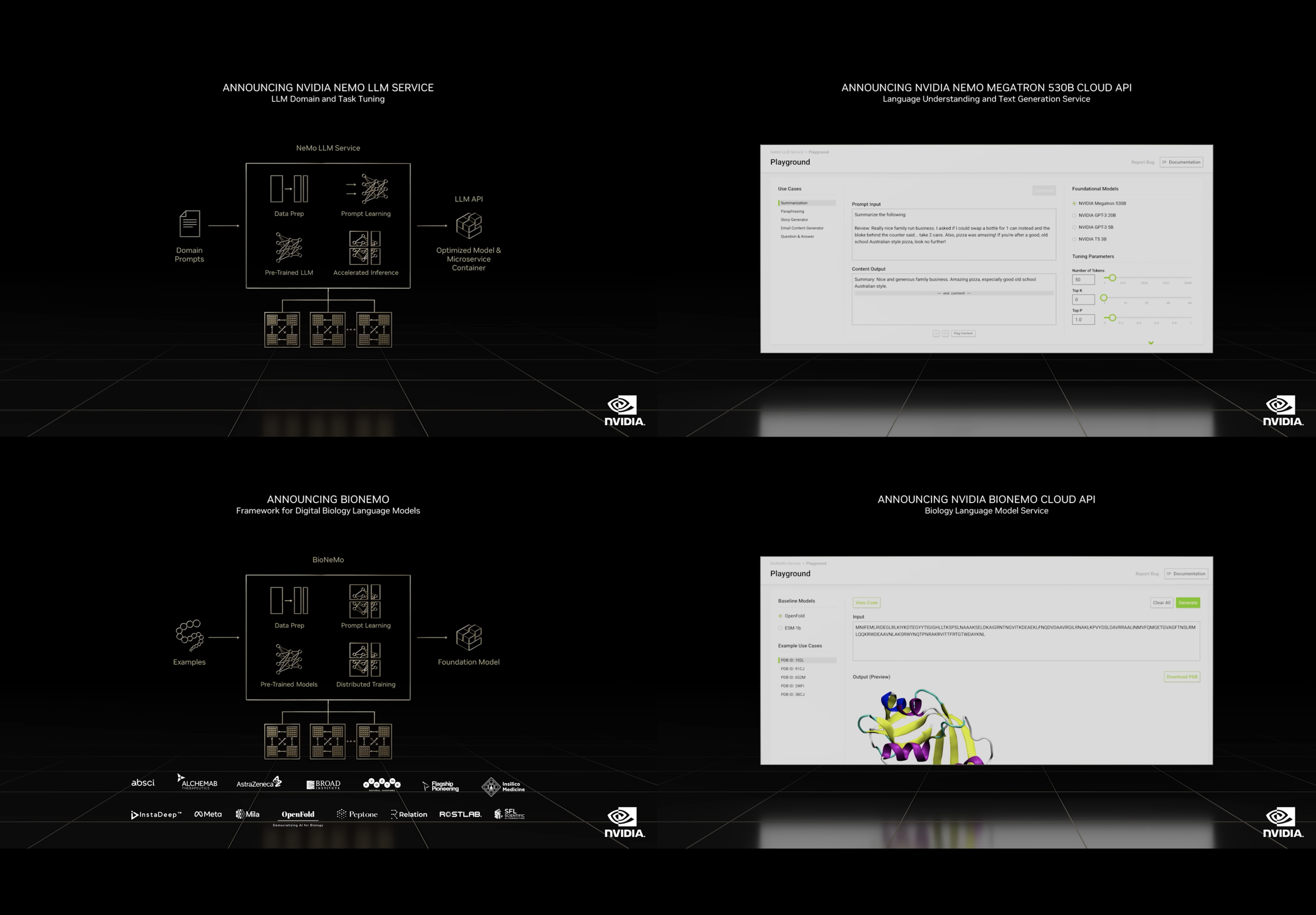
NVIDIA が開発した NeMo は、大規模言語モデルとその開発のためのフレームワークやツールを含んだプラットフォームの名称です。大規模な拡張が可能な学習フレームワークである Megatron や、世界最大規模の学習済み言語モデルである Megatron 530B などがすでに様々なサービスに活用されています。
今回の発表ではまず、追加の学習を行う際、モデル全体を変更する方法だけではなく、わずかなサンプルから特定のタスクに対応したモデルを生成する「プロンプト学習」が実行可能であることの紹介がありました。
このプロンプト学習を用いて、大規模言語モデルをベースとし、特定分野に特化したモデルを別個のコンテナ(マイクロサービス)として生成できる NeMo LLM Service が発表されました。10月からアーリーアクセスが利用可能となる予定です。
また、前述の 530B とこれをベースとした多様な学習済み言語モデルに、API でアクセス可能となる NeMo Megatron 530B Cloud API も同時に発表されました。こちらもアーリーアクセスは10月に開始される予定です。
さらに、このNeMoを生物化学領域に応用して、創薬分野でのタンパク質の合成パターンの生成・有用なものの選別などを行う BioNeMo と、すでに学習済みのBioNeMoのモデルと学習環境を提供する BioNeMo Cloud API が紹介されました。こちらのアーリーアクセスも10月開始予定です。
そして最後に、MITとハーバード大学、および関連する医療機関や研究所が共同設立した Broad Instituteでの NVIDIA プロダクトの活用事例が示されました。同研究所の Terra Cloud Platform において、医療 AI プラットフォームの NVIDIA Clara および BioNeMo が利用可能となっています。Terra は、生物医学研究のためのオープンなプラットフォームとして作られたクラウドで、Verily社とMicrosoft社が研究者のコミュニティに無償で提供しています。
最新GPU "Hopper" および NVIDIA 独自の高性能CPU "Grace"

最新の Hopper についての紹介では、その性能により大規模言語モデルの学習・推論どちらの処理についても大幅に高速化できることが示されました。Hopper ベースのGPUである NVIDIA H100 は10月から出荷開始、また H100 を搭載した DGX H100 はすでにオーダーが可能である旨が示されました。さらにパブリッククラウドでも数ヶ月後に H100 搭載インスタンスが提供開始される見込みであるとの旨が発表されています。
(※日本でも原則としてはこれらの発表に準じて出荷開始/オーダー受付開始となります。詳細はNVIDIAプロダクトの販売店へお問い合わせ下さい)
また、Hopper 採用の GPU と、ArmアーキテクチャによるNVIDIA独自のCPUである Grace をチップ間 NVLink で高速接続した Grace Hopper については、特に相性の良い処理として、EC システムなどで使われるレコメンダーシステムが紹介されました。Hopper のもつ GPU メモリ80GBに加え、Graceが直結する500GBの高速メモリも処理に利用することが可能であり、大容量のメモリ領域を必要とするレコメンダーの処理に対応可能であるためです。
Grace, および Grace Hopper を搭載する AI, HPC, Omniverse などに最適化された各種サーバーは、主要なハードウェアメーカーから2023年前半に提供開始予定です。
AI, Omniverse によるエンタープライズ向けの各種サービス
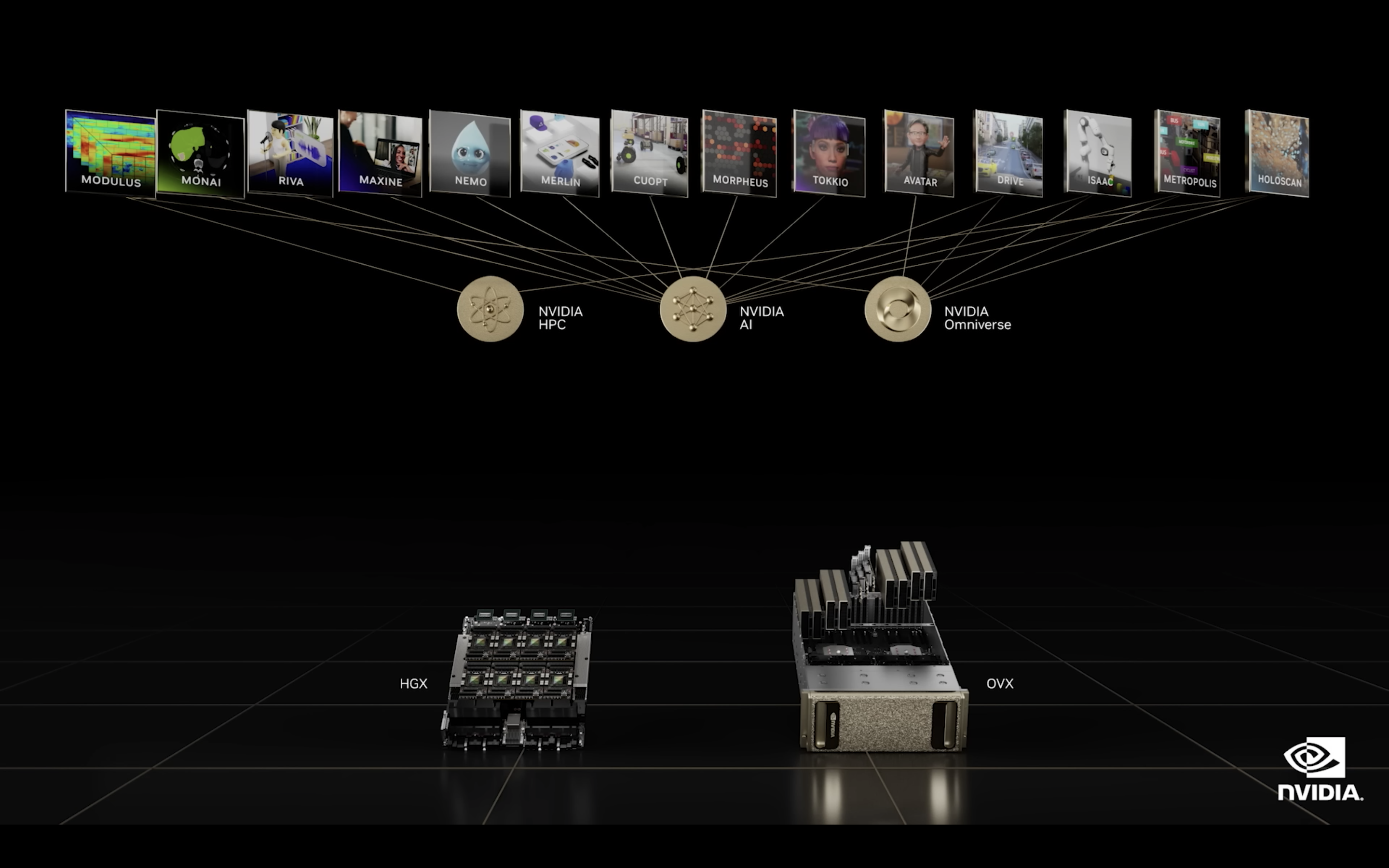
AI, HPC, Omniverse といったプラットフォームそれぞれを、あるいはそれらを横断的に活用し、様々な専門領域に特化したサービスが生み出されています。医用画像 AI フレームワークである NVIDIA MONAI や、レコメンダーシステム構築を容易にする NVIDIA Merlin, 工場や倉庫のロボティクスに応用されるオペレーションリサーチ最適化 API である NVIDIA cuOpt, さらにセキュリティ観点で膨大なリアルタイムデータを処理・分類して異常を検知する NVIDIA Morpheus などがその代表例として紹介されました。
(※本記事の前半で紹介した NVIDIA L40, および L40 を8基搭載した NVIDIA OVX はこのセクションで紹介されましたが、新アーキテクチャ Ada Lovelace を採用しているという性質上、Ada Lovelace のご紹介箇所である前半に掲載しました)
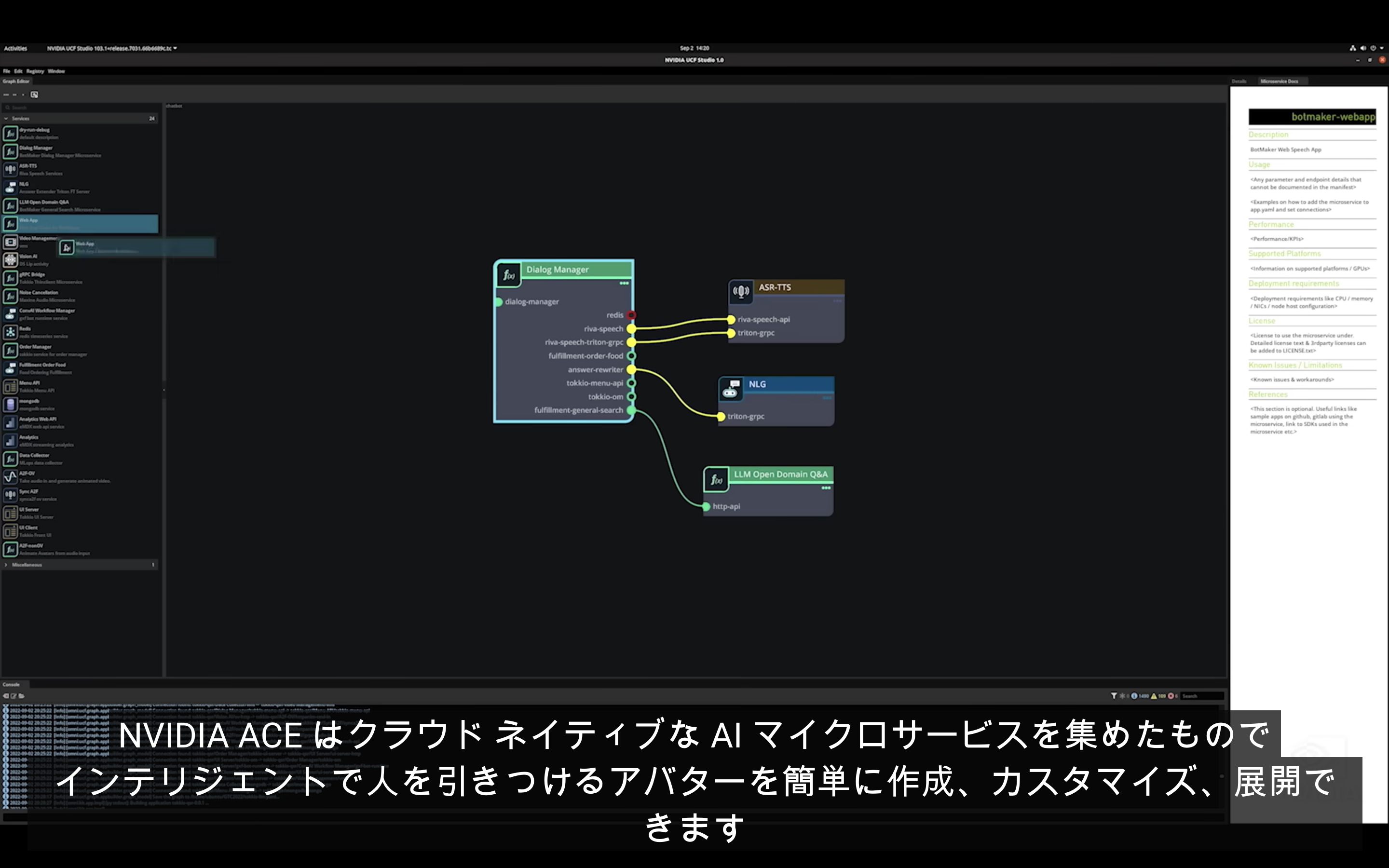

さらに今回、メタバースの世界で利用される様々なアプリケーションにおける、NVIDIA の先進的な取り組みも紹介されました。AI を搭載したアバターの開発では、カスタマーサポートに特化したアバターを生成するための Tokkio と呼ばれるリファレンスアプケーションがそのひとつです。さらにはAIアバターを構成するためのマイクロサービスを集めた環境である NVIDIA ACE (Avatar Cloud Engine) も紹介されています。ACE は NVIDIA の独自ユーザーインタフェース UCF (Universal Computing Framework) によって、コーディング無しに様々なマイクロサービスを組み合わせることで、AI アバターの生成を大幅に容易にします。さらには特定の専門知識を追加搭載したり、ビジュアルを自由に変更できる様子もデモによって示されました。
なお最後に、こうしたAI プラットフォームと Omniverse によるグラフィックスの組み合わせにより、事業の変革を行う「専門家」の必要性についても触れられ、デロイト社がこれらのプロフェッショナル サービスをスタートすることが発表されました。
以上、長くなりましたが NVIDIA GTC 2022 Fall のレポートは以上です。各プロダクトの詳細については、リンクをクリックしてご参照いただければ幸いです。
NVIDIA GTC 2022 Fall 主要なプレスリリースへのリンク集
NVIDIA のニュースアーカイブ
今回も幅広い領域に渡るソフトウェア・ハードウェア・サービスの先進的なテクノロジーと、その成果および活用事例が発表されました。デジタルツインやメタバースに代表されるデジタル空間のビジネス活用はいよいよ大きく広がり始めており、その中で当たり前のように AI が活用される時代が到来しつつあることを感じさせられる内容でした。
今後も NVIDIA の最新プロダクトと、それらが描くビジョンを追っていきたいと思います。
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
幸田 章 - Akira Koda -
NVIDIA製品を中心としたコンピューティング(グラフィックス, AI/HPC)とネットワーキング、VDI を含む仮想化、クラウド等のプリセールス・エンジニア業務に従事。
VMware vExpert 2015-2022