


みなさんこんにちは。 連載形式でPortworxの機能についてご紹介しています。(過去のPortworx関連ブログ記事のリンク集はこちらです。) 今回は第2回です。
前回のブログ記事(初級編)でPortworx (PX-Store)によるディスクやボリュームの管理についてご紹介しました。
前回ご紹介した内容は、ある単一のノード上の単一Storage Poolの中にボリュームがあるという構図が前提になっていました。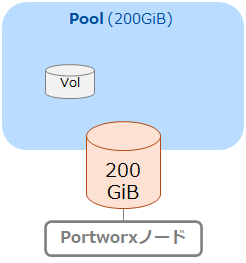
Portworxは最小3ノードでクラスタリングします。せっかくクラスタリングされたSDS (ソフトウェア・ディファインド・ストレージ)ですから、クラスター横断的にストレージを利用したいというご要望も当然あるかと思います。
そこで今回は「応用編」と題しましてクラスター横断的に利用できる機能をご紹介いたします。
検証環境
検証を行う環境は前回のブログ記事(初級編)と同様です。4台のUbuntu 20.04.4LTS仮想マシンで構成したKubernetesクラスター(Kubernetes 1.22, Docker 19.3.11)を利用します。Kubernetesクラスターには3つのWorkerノードがあり、その空きディスクでPortworxクラスター(Portworx Enterprise 2.11)を構成しています。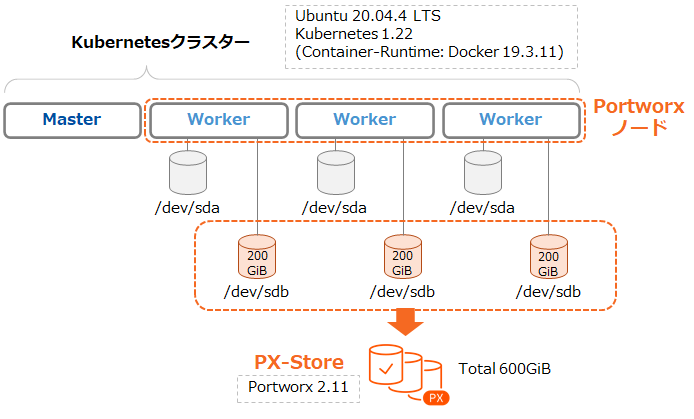 なお、動作確認前の"pxctl status"コマンドの実行結果は以下のようになっています。
なお、動作確認前の"pxctl status"コマンドの実行結果は以下のようになっています。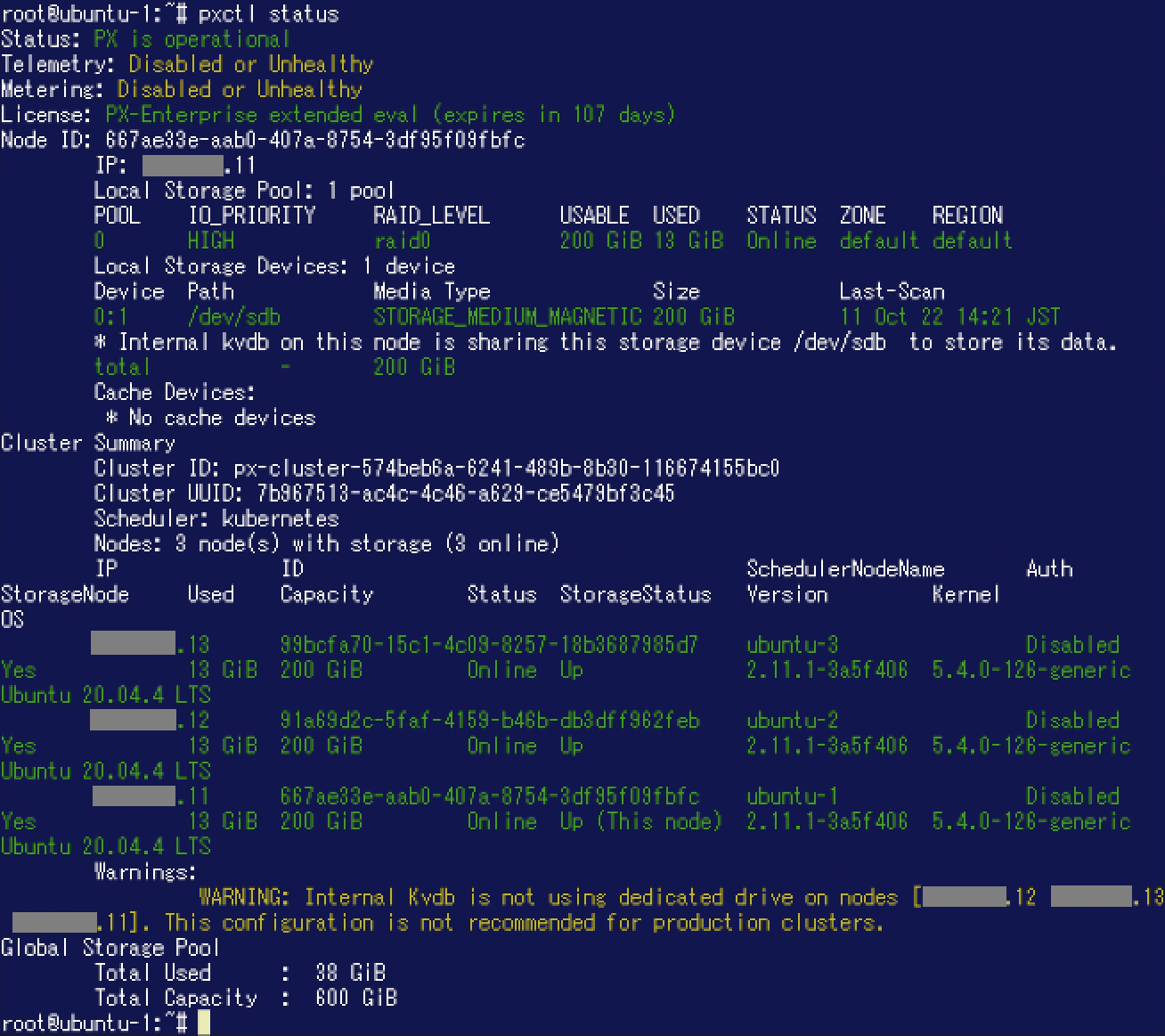 前回のブログ記事(初級編)と同様に各ノードに200GiBのStorage Poolがひとつ存在しています。
前回のブログ記事(初級編)と同様に各ノードに200GiBのStorage Poolがひとつ存在しています。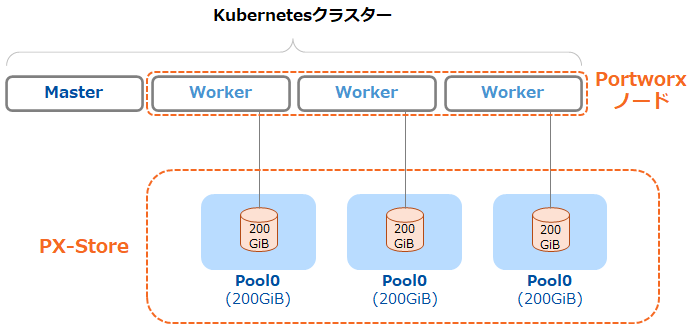
単一ノードのStorage Poolより大きいボリュームが欲しいときは...「Aggregation」
前回のブログ記事(初級編)でStorage Poolはノードごとに持つディスクで構成されていることをご紹介しましたが、それより大きい容量のボリュームが欲しくなった場合はどうすればよいでしょうか。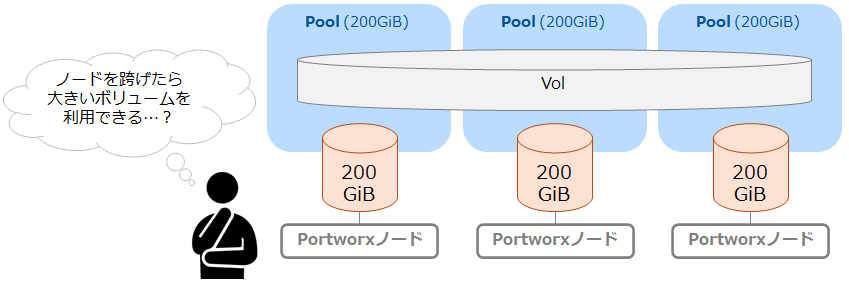
このような場合には「Aggregation」を利用することで複数のノード上のStorage Poolにまたがったボリュームを作成することが可能です。
ここからはAggregationにより300GiBのボリュームを作成し、(単一Storage Poolの容量である)200GiBを超えて書き込みができるか試してみたいと思います。
準備: 新たに作成されるボリュームがAggregation有効になるようにする
PXCTL("pxctl volume create"コマンド)を利用してAggregationが有効になっている新しいボリュームを手動で作成することもできますが、ここではPortworxの「Storage Policy」という機能を利用してみたいと思います。Storage Policyを設定しておくことで、Portworxクラスターに作成されるボリュームの仕様を予め指定することができます。(Storage Policyで指定できるパラメータについてはこちらをご参照ください。) ここでは3ノード(3つのStorage Pool)にまたがったボリュームを作成するためにAggregationレベルを3とするStorage Policyを作成し、新たに作成されるボリュームに対してデフォルトで適用されるようにしてみます。
Storage Policyの一覧を表示させるには"pxctl storage-policy list"コマンドを利用します。現時点ではStorage Policyが存在しないためリストが空になっています。![]()
今回は"pxctl storage-policy create"コマンドを利用し「agnpol」という名称のStorage Policyを作成しました。"-a 3"によりAggregationのレベルとして3を指定しています。
さらに"pxctl storage-policy set-default"コマンドにより「agnpol」をデフォルトのStorage Policyとして設定します。設定後に"pxctl storage-policy list"コマンドを実行するとポリシー名「agnpol」の先頭に「*」が付加されています。これはデフォルトのStorage Policyであることを示すものです。
Storage Policyの設定内容を確認するには"pxctl storage-policy inspect"コマンドを実行します。
これにより、このPortworxクラスターに作成されるボリュームはAggregationレベル: 3が設定されるようになりました。
なお、設定可能なAggregationレベルは最大で3です。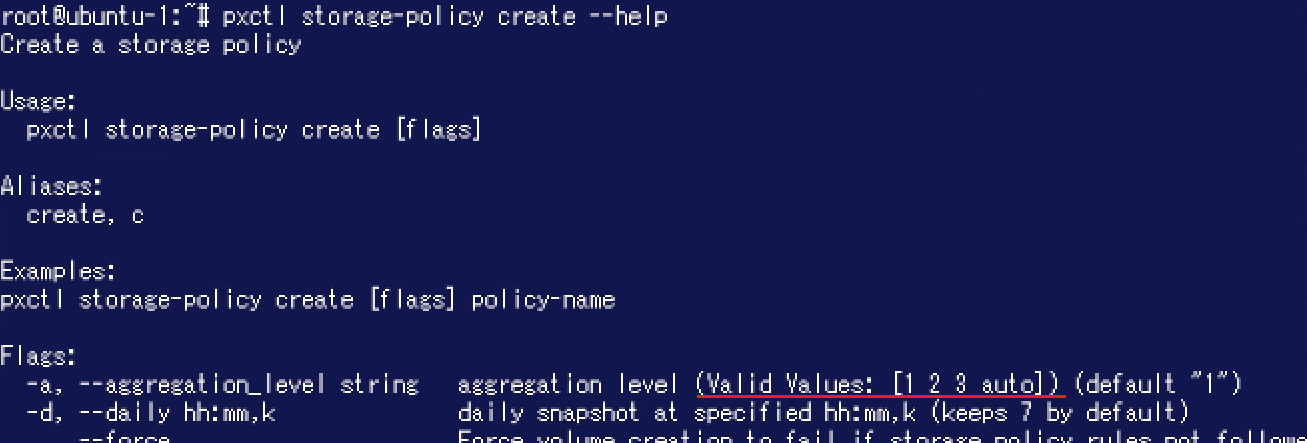
Aggregationが設定されたボリュームの作成・利用
300GiBのPVを利用することができるか確認するために以下のリソースを利用します。ここではNamespace「agn-test」を利用します。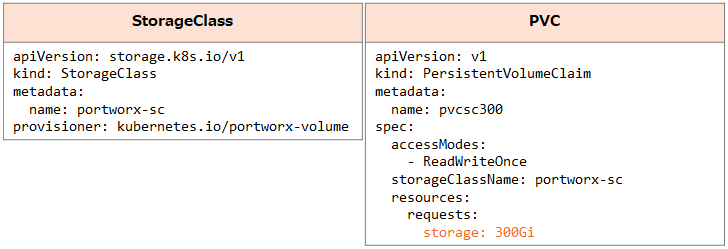
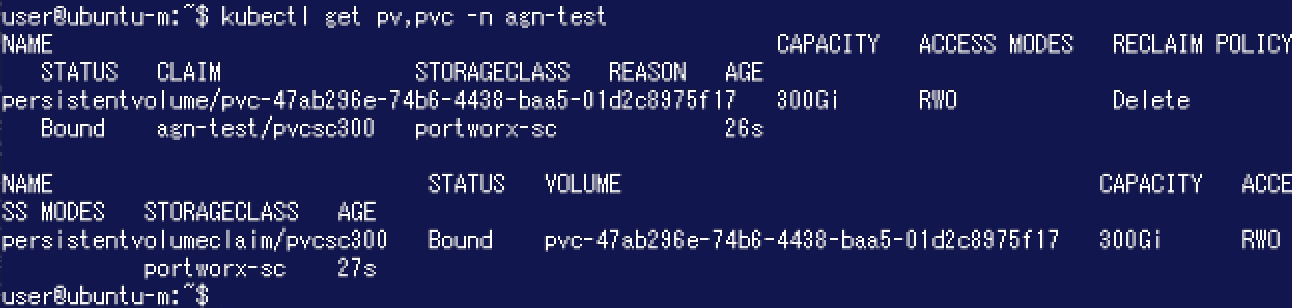 PVが作成されましたので、ここでPortworx側からボリュームの状態を確認してみます。"pxctl volume inspect"コマンドの実行結果を確認すると、"StoragePolicy"に先程作成した「agnpol」が表示されています。また、"Replica sets on nodes"には"Set"が3つ表示されており、各Set内に1つのノード / Storage Poolが存在しています。このことから3ノード(3つのStorage Pool)をまたがって利用できるボリュームであることが分かります。
PVが作成されましたので、ここでPortworx側からボリュームの状態を確認してみます。"pxctl volume inspect"コマンドの実行結果を確認すると、"StoragePolicy"に先程作成した「agnpol」が表示されています。また、"Replica sets on nodes"には"Set"が3つ表示されており、各Set内に1つのノード / Storage Poolが存在しています。このことから3ノード(3つのStorage Pool)をまたがって利用できるボリュームであることが分かります。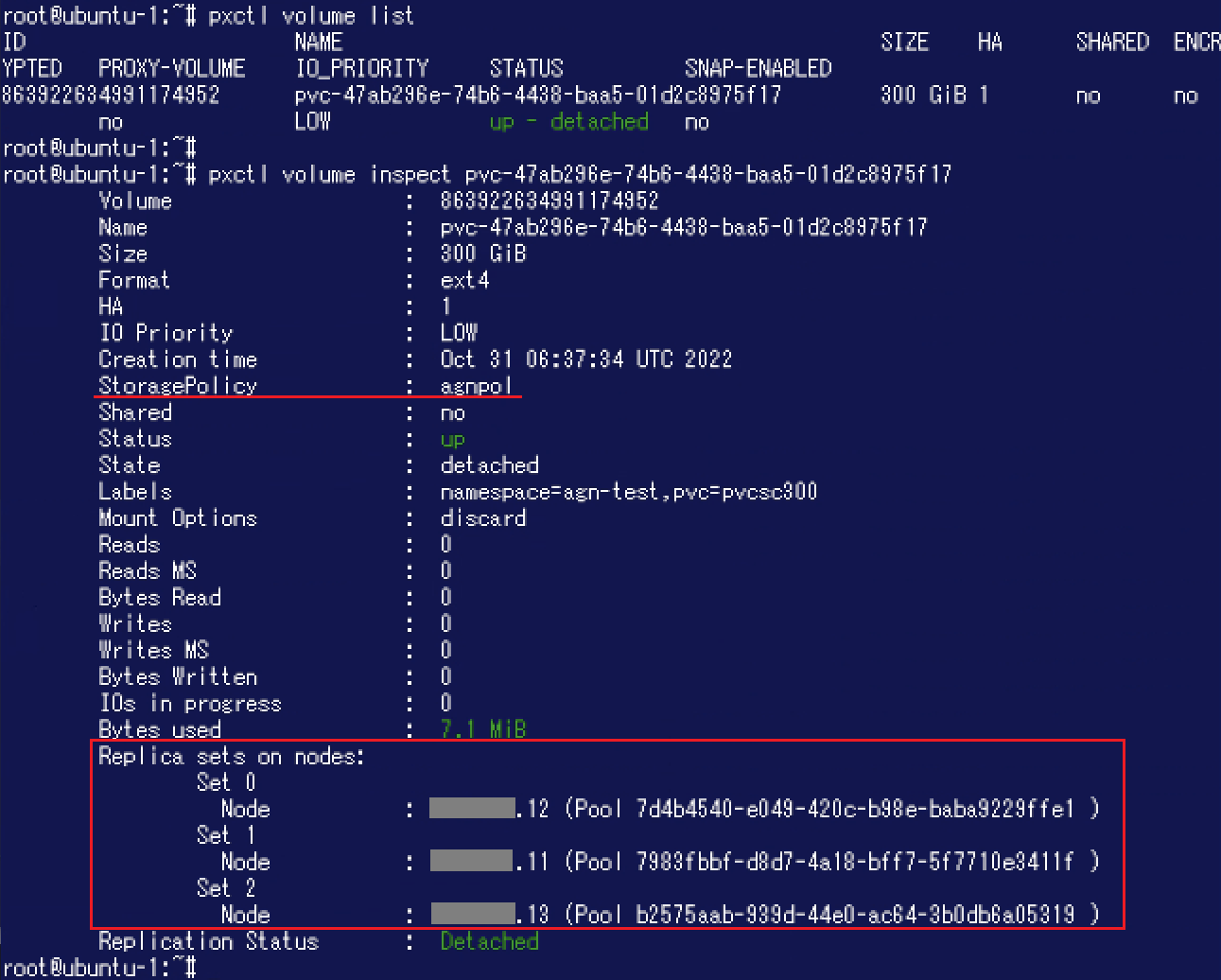 さらに以下のDeploymentを作成してAlpineのPodからこのボリュームを利用できるようにしました。
さらに以下のDeploymentを作成してAlpineのPodからこのボリュームを利用できるようにしました。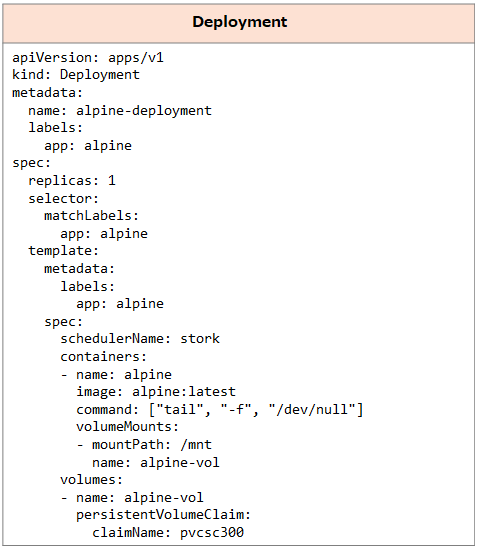
 このPodからPVに対してランダムなデータを書き込んでみました。lsコマンド実行結果では"total 293G"となっており、200GiBを超えた後もデータの書き込みができたようです。
このPodからPVに対してランダムなデータを書き込んでみました。lsコマンド実行結果では"total 293G"となっており、200GiBを超えた後もデータの書き込みができたようです。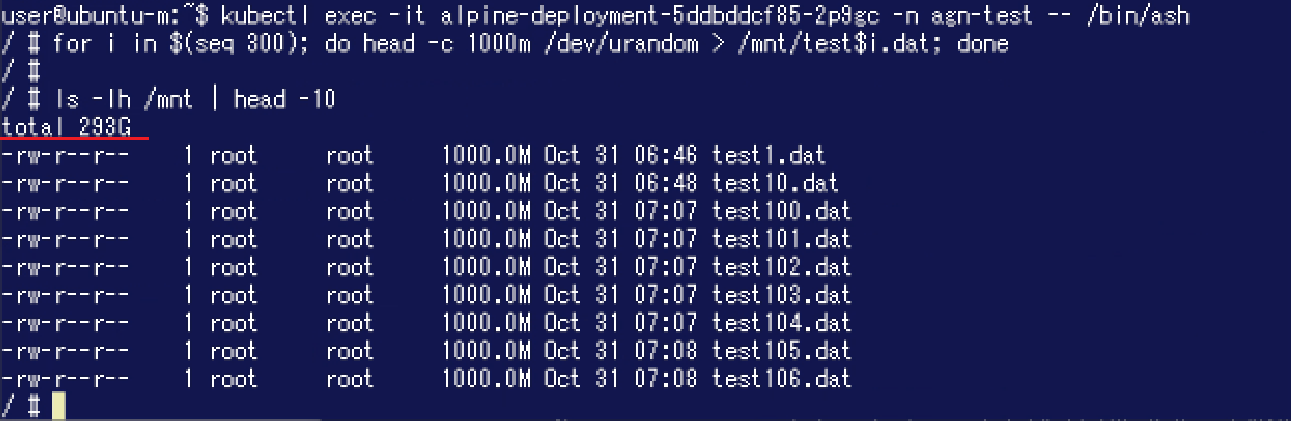 次に、ボリュームやディスク消費がどのようになっているかPortworx側から確認してみましょう。"pxctl volume inspect"コマンドでボリュームの詳細を確認します。"Bytes used"が293GiBになっており、Portworx側からもひとつのノード / Storage Poolのディスク容量200GiBを超えてデータを書き込むことができたことが確認できました。
次に、ボリュームやディスク消費がどのようになっているかPortworx側から確認してみましょう。"pxctl volume inspect"コマンドでボリュームの詳細を確認します。"Bytes used"が293GiBになっており、Portworx側からもひとつのノード / Storage Poolのディスク容量200GiBを超えてデータを書き込むことができたことが確認できました。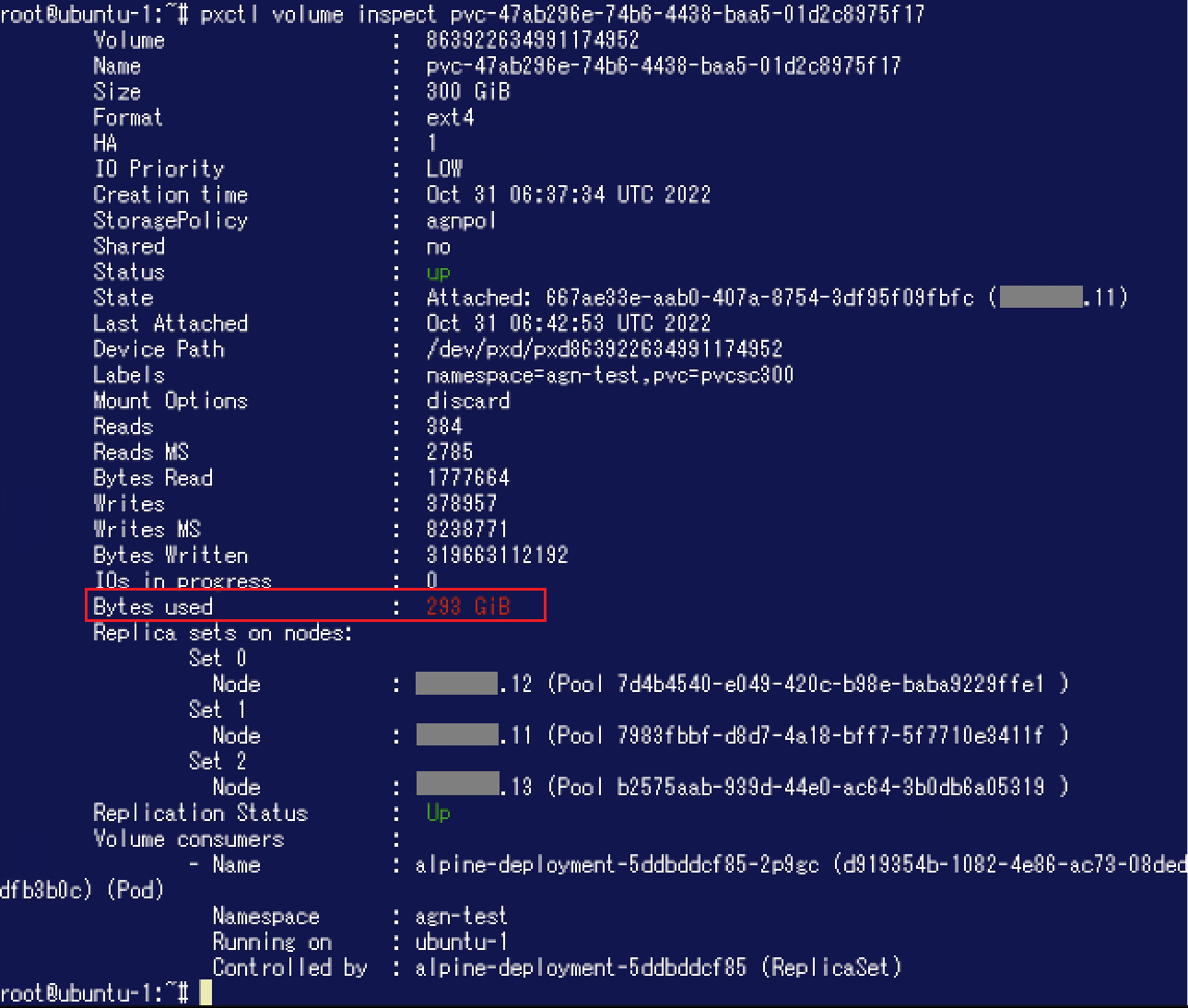 Aggregationを設定した場合、データはストライピングで書き込まれます。ここで各ノードでのディスク消費状況を確認するために"pxctl status"コマンドを実行します。"Used"がそれぞれ110GiBになっていることが分かります。
Aggregationを設定した場合、データはストライピングで書き込まれます。ここで各ノードでのディスク消費状況を確認するために"pxctl status"コマンドを実行します。"Used"がそれぞれ110GiBになっていることが分かります。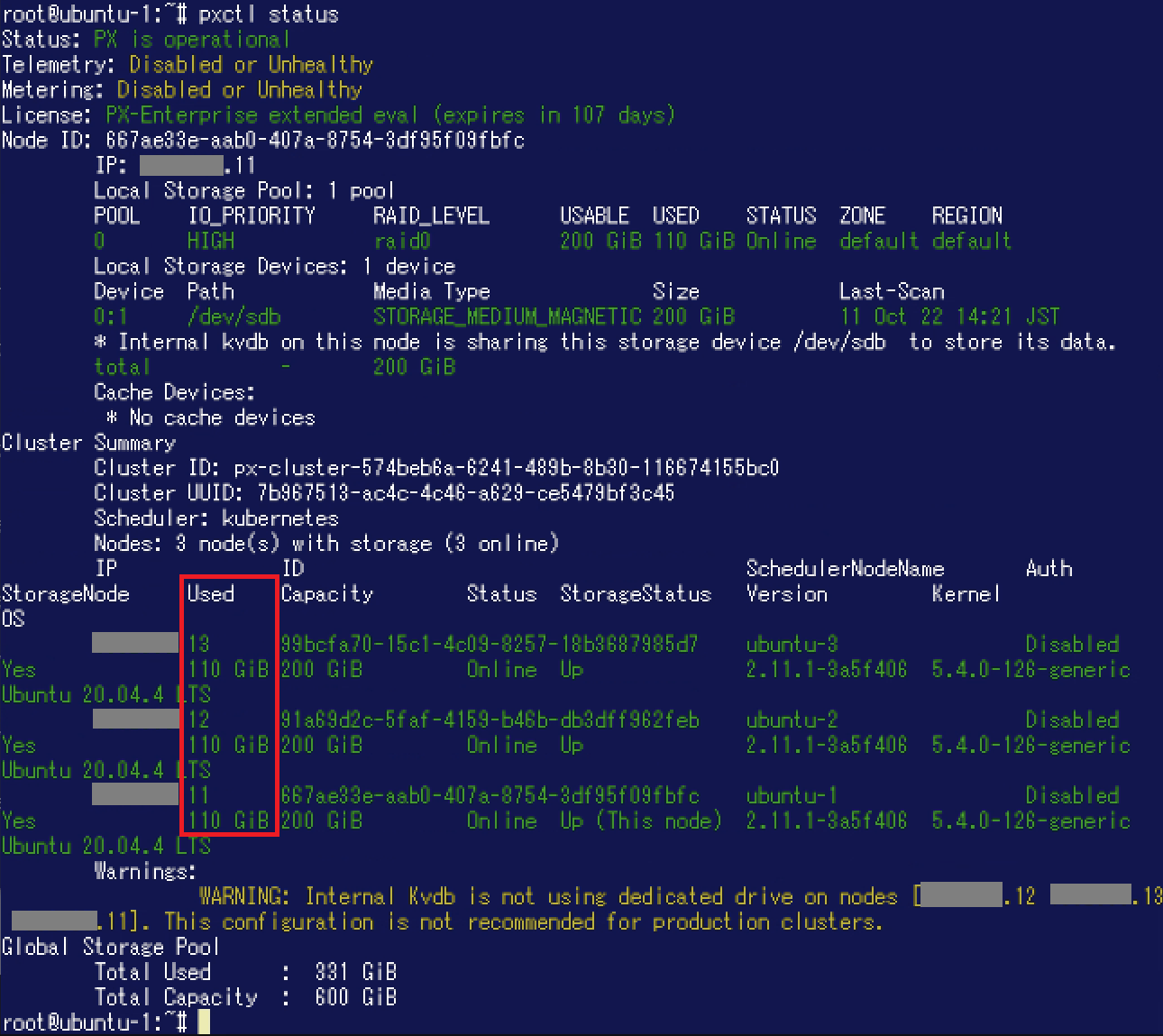 Aggregation設定により、Portworxノード / Storage Poolをまたがってデータを書き込めることが確認できました。
Aggregation設定により、Portworxノード / Storage Poolをまたがってデータを書き込めることが確認できました。
ボリュームに可用性を持たせたいときは...「Replication」
前述しましたようにPortworxは最小3ノードでクラスタリングします。今回利用している環境も3ノードでクラスタリングしていますが、データがひとつのノード上にのみ存在している場合、そのノードがダウンしてしまうとデータが利用できなくなってしまいます。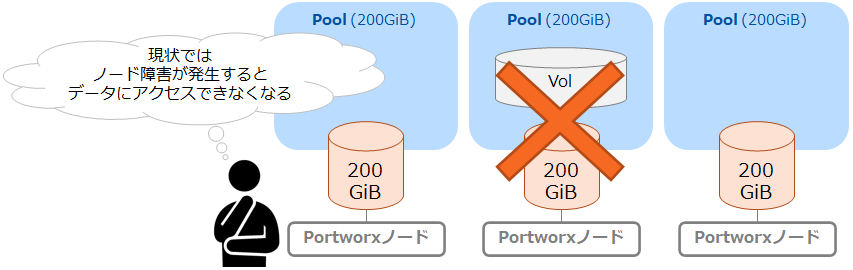
Portworxではボリュームに対して「Replication」を設定することができ、これによりボリュームの複製を作成することが可能です。(Replicationはメーカー資料によっては「Replication Sets」と表記されていることがあります。) 前述の通り、今回利用している環境では各ノードに1つずつStorage Poolが存在しています。ここからはReplicationを設定して別のノードにボリュームの複製を作成することによりボリュームの可用性向上を図ってみたいと思います。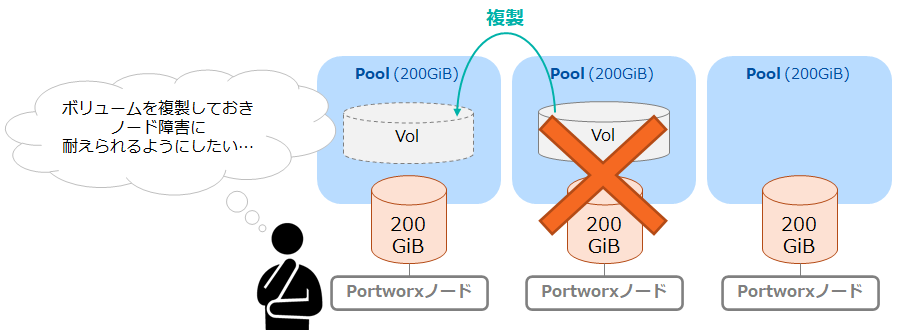
ここではReplication設定が有効になっている5GiBのボリュームを作成し、どのような動作になるか確認します。
なお、前述したAggregationのボリュームやStorage Policyが存在しない状態で操作を開始しています。
準備: 新たに作成されるボリュームがReplication有効になるようにする
今回もAggregationのときと同様にStorage Policyを利用して、新たに作成されるボリュームにReplicationが設定されるようにしてみます。メーカードキュメントによると一般的なReplication Factorの推奨値は2となっていますので、ここでは以下のようにReplication Factor: 2とするStorage Policyを作成し、新たに作成されるボリュームに対してデフォルトで適用されるようにしてみます。(コマンド実行結果の表示では、Replication Factorは"HA"と表示されます。)
これにより、このPortworxクラスターに作成されるボリュームはReplication Factor: 2が設定されるようになりました。
なお、メーカードキュメントに記載の通り設定可能なReplication Factorは最大で3です。
Replicationが設定されたボリュームの作成・利用
以下のリソースを利用し、5GiBのボリュームを作成します。ここではNamespace「rpl-test」を利用します。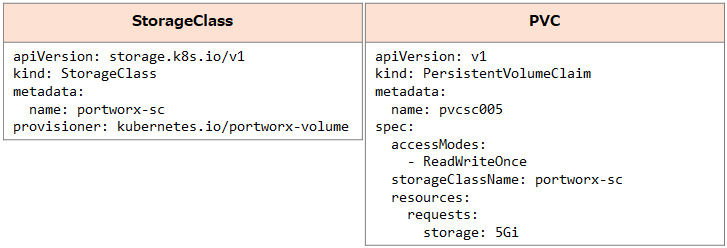
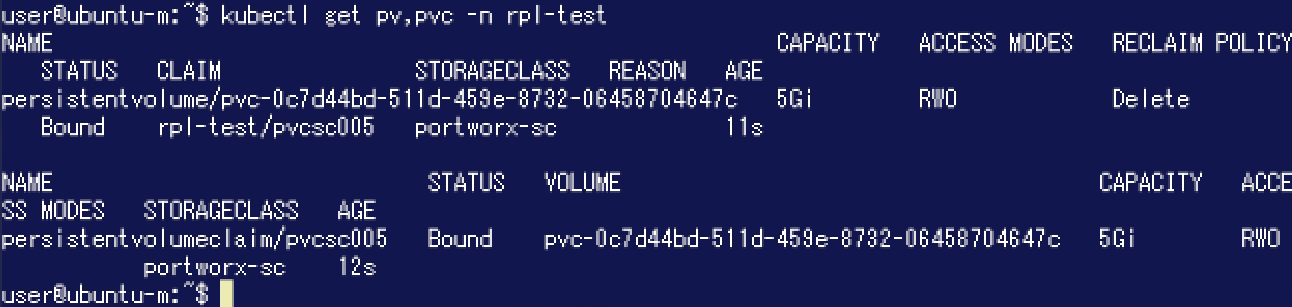 Portworx側からボリュームの状態を確認してみます。"pxctl volume list"コマンド実行結果を確認すると、"HA"がReplication Factorである"2"となっています。
Portworx側からボリュームの状態を確認してみます。"pxctl volume list"コマンド実行結果を確認すると、"HA"がReplication Factorである"2"となっています。 "pxctl volume inspect"コマンドの実行結果からもHAの値を確認することができます。また、"StoragePolicy"に先程作成した「rplpol」が表示されています。さらに"Replica sets on nodes"の"Set 0"の中に2つのノード / Storage Pool が表示されており、Replicaが配置されるノードやStorage Poolを確認することができます。
"pxctl volume inspect"コマンドの実行結果からもHAの値を確認することができます。また、"StoragePolicy"に先程作成した「rplpol」が表示されています。さらに"Replica sets on nodes"の"Set 0"の中に2つのノード / Storage Pool が表示されており、Replicaが配置されるノードやStorage Poolを確認することができます。
なお、前述のAggregationを有効にした際はレベル数分の"Set"(Aggregationレベル: 3なら3つのSet)が"Replica sets on nodes"内に存在していました。今回は単一のSet内にReplication Factor数分のノード / Storage Poolが表示されているというのが相違点です。Aggregationを有効にした際の"pxctl volume inspect"コマンド実行結果と見比べて頂ければと思います。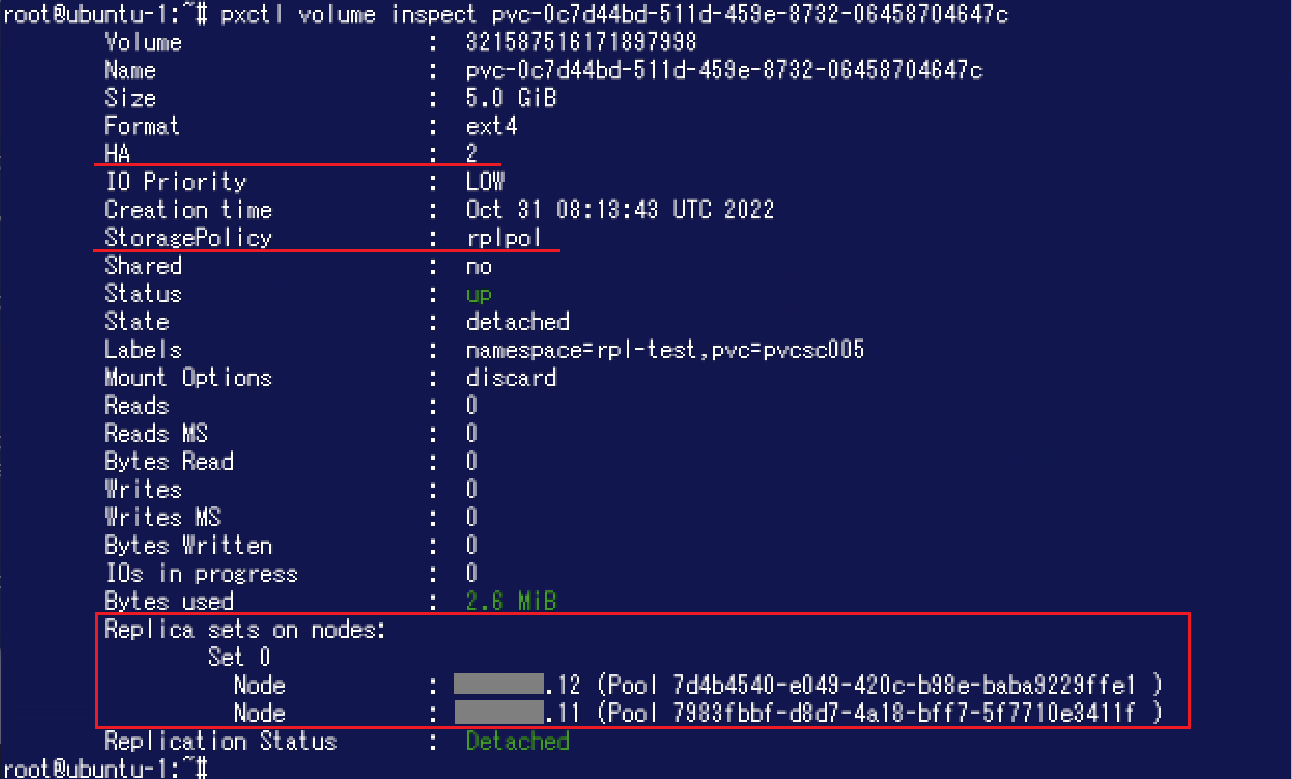 今回の構成とボリュームの配置を簡単な図にしたものが以下です。
今回の構成とボリュームの配置を簡単な図にしたものが以下です。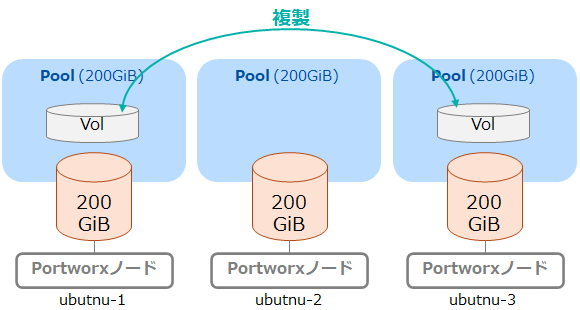 さらに以下のDeploymentを作成してAlpineのPodからこのボリュームを利用できるようにしました。
さらに以下のDeploymentを作成してAlpineのPodからこのボリュームを利用できるようにしました。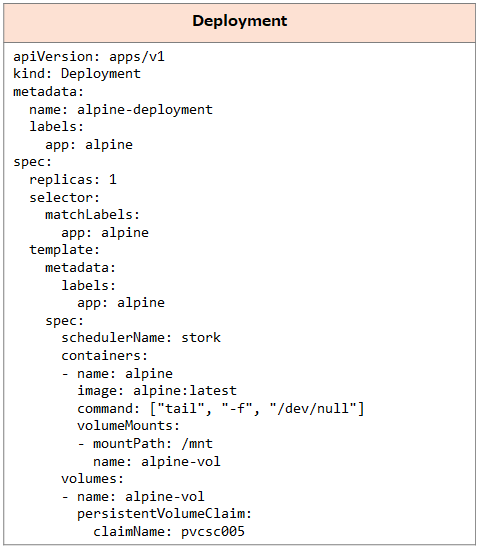 ここではノード「ubuntu-1」でPodが稼働しています。
ここではノード「ubuntu-1」でPodが稼働しています。 このノードからボリュームに対し、ランダムなデータを書き込みました。
このノードからボリュームに対し、ランダムなデータを書き込みました。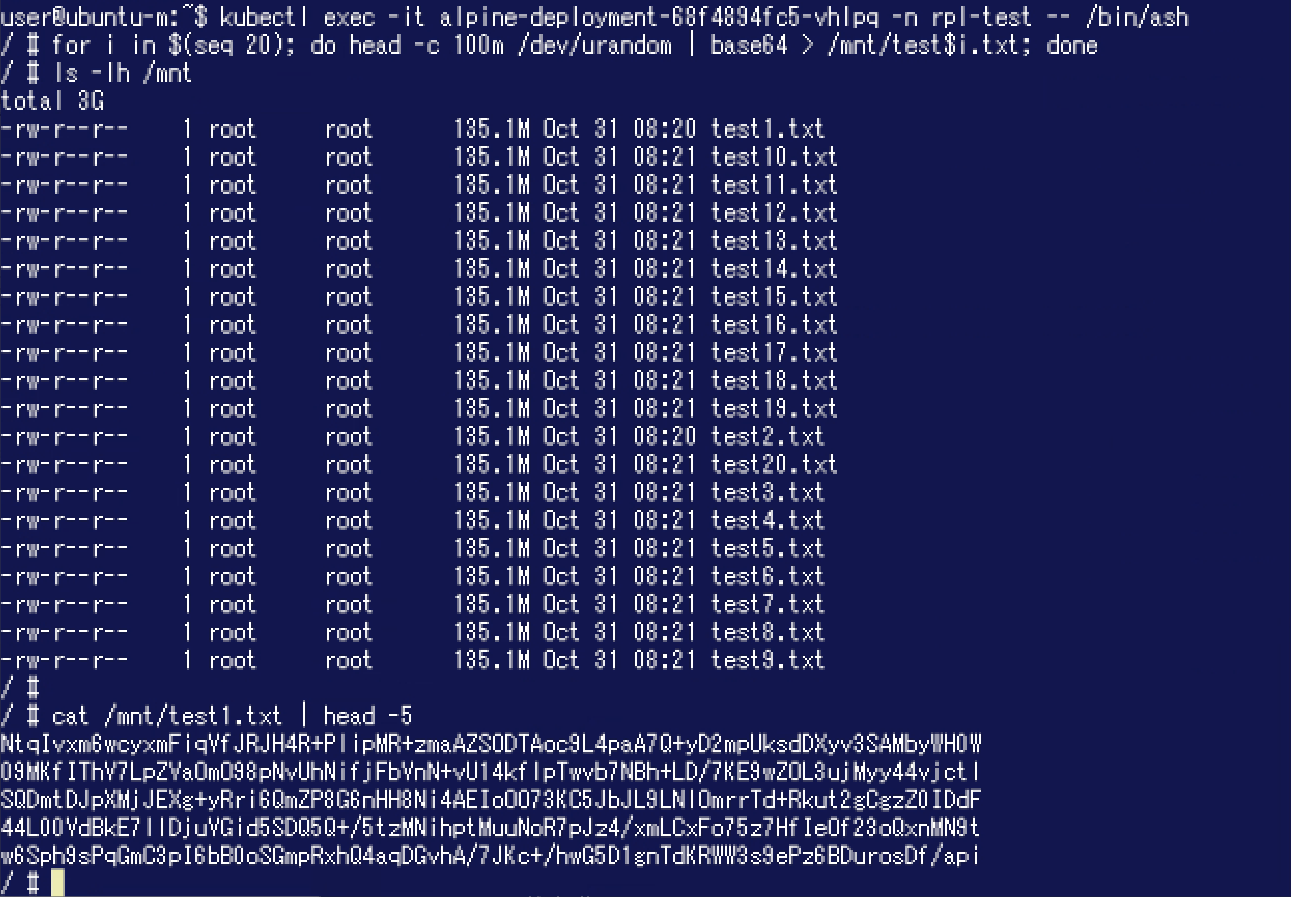
複製されたボリュームの動作確認
それではReplication Factor: 2により複製されたボリュームについて動作を確認してみたいと思います。 この時点でPodはノード「ubuntu-1」に存在していますので、ノード「ubuntu-1」にノード障害が発生した状態を模してみます。ここでは「ubuntu-1」についてOSをシャットダウンしました。その後、稼働しているノードで"pxctl status"コマンドを実行した結果が以下の通りです。「ubuntu-1」の"Status"が"Offline Down"になっています。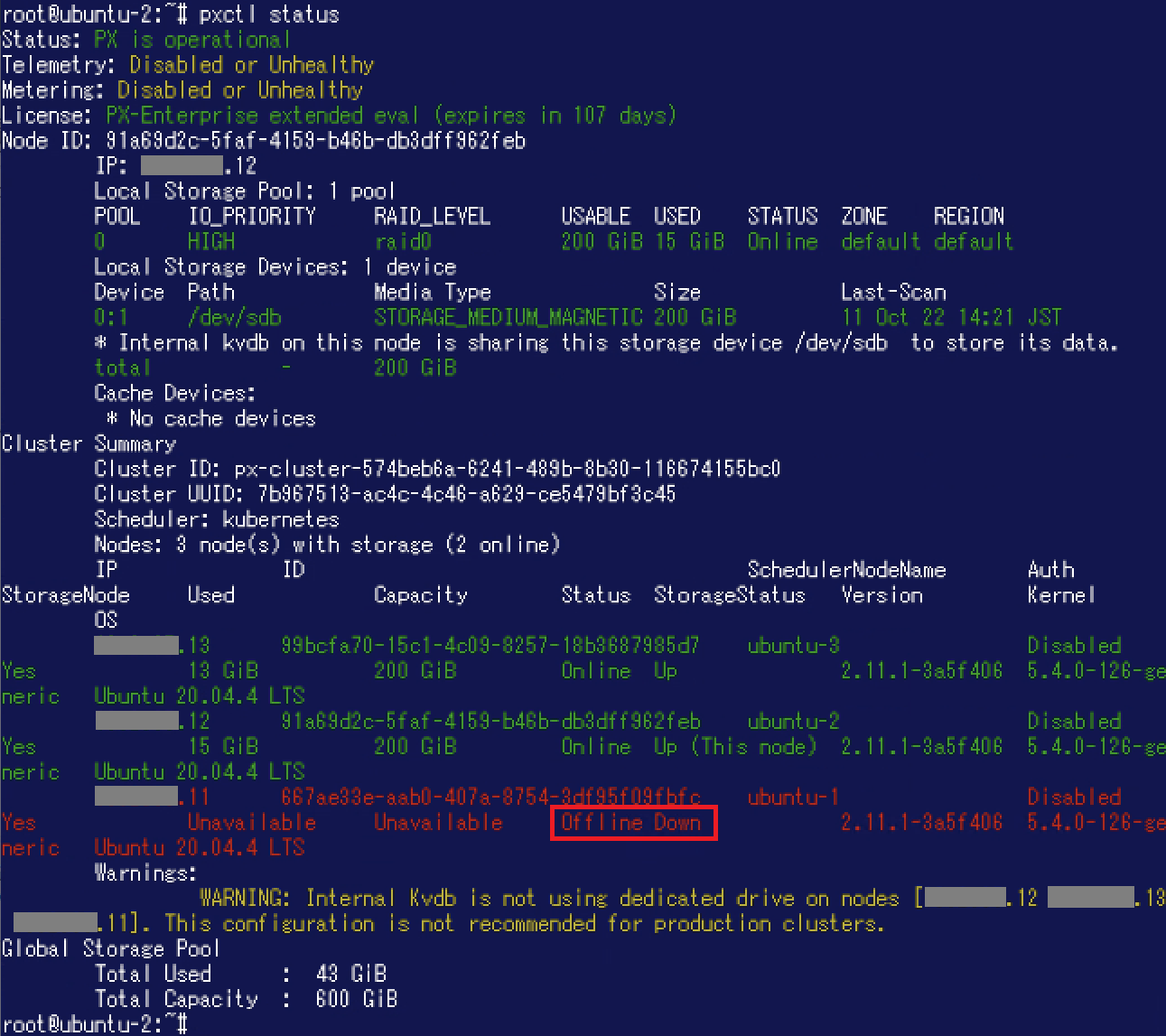 この状態で、Podが先程と同じデータを参照できるか確認してみます。新しいPodはノード「Ubuntu-2」で稼働しています。
この状態で、Podが先程と同じデータを参照できるか確認してみます。新しいPodはノード「Ubuntu-2」で稼働しています。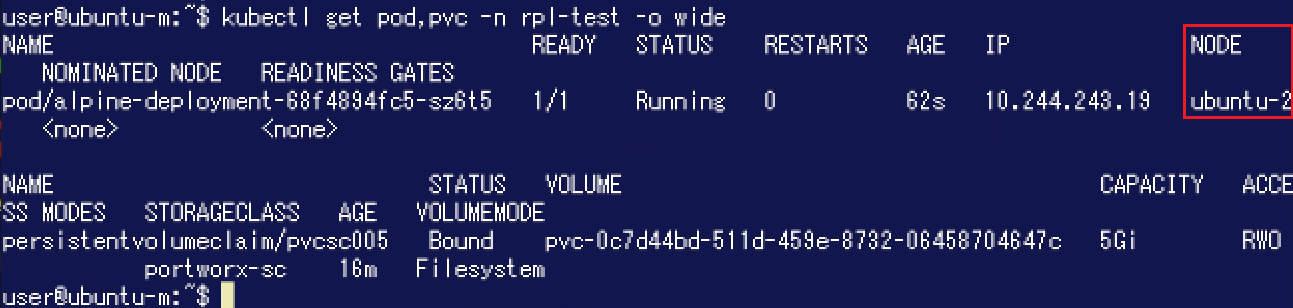 以下の通り、このPodでも先程と同様にデータを参照することができました。
以下の通り、このPodでも先程と同様にデータを参照することができました。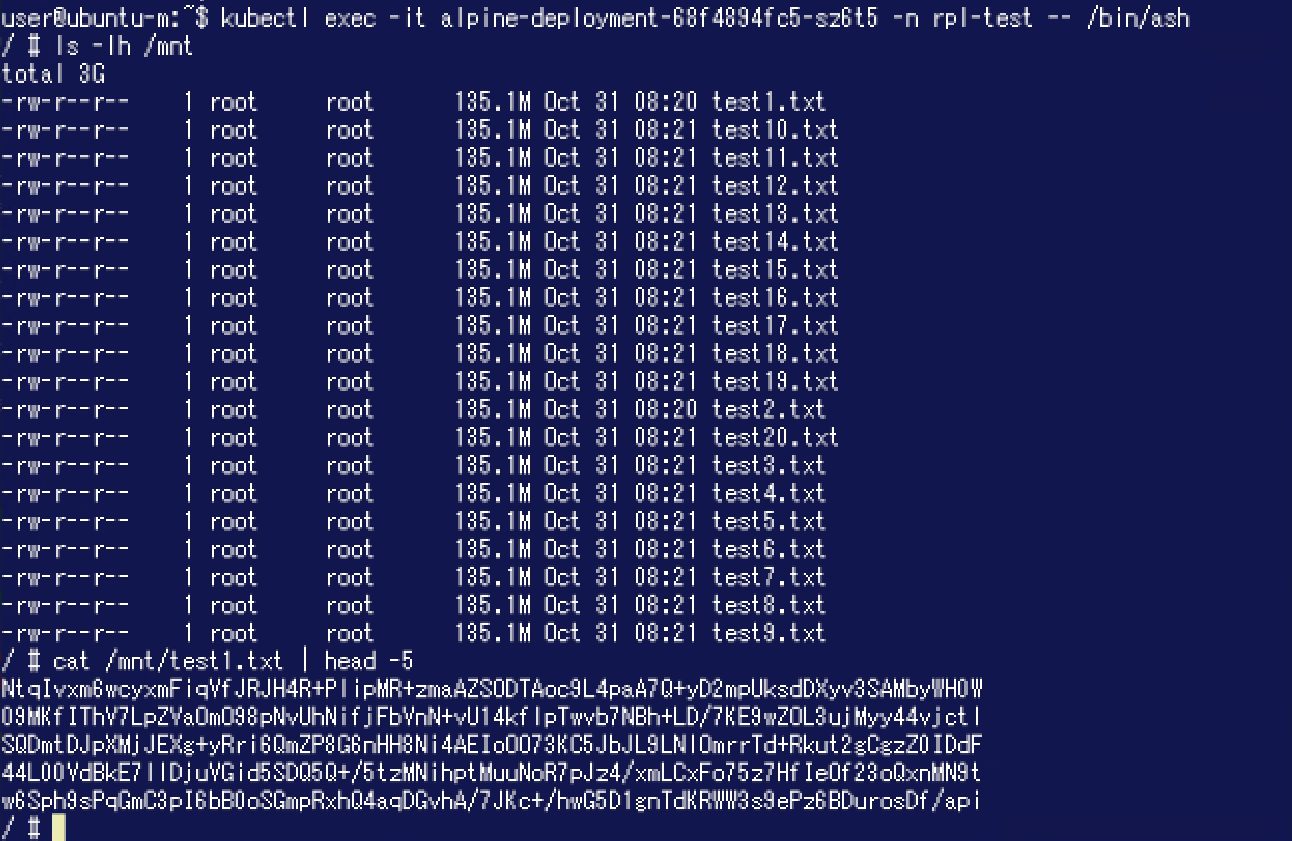
【補足】STORKによるスケジューリング
ここで「STORK」について簡単にご説明いたします。 STORKはStorage Operator Runtime for Kubernetesの略で、オープンソースで提供されているストレージ Kubernetes向けのスケジューラです。 STORKを利用することによりPodをデータと同じノードに配置することができ、I/O効率が上がるといったことが期待できます。(この他にも機能がございますが、そちらはまた改めてご紹介できればと思います。)
今回利用するPortworxクラスターには既にSTORKが導入されており、DeploymentでSTORKをスケジューラとして指定しています。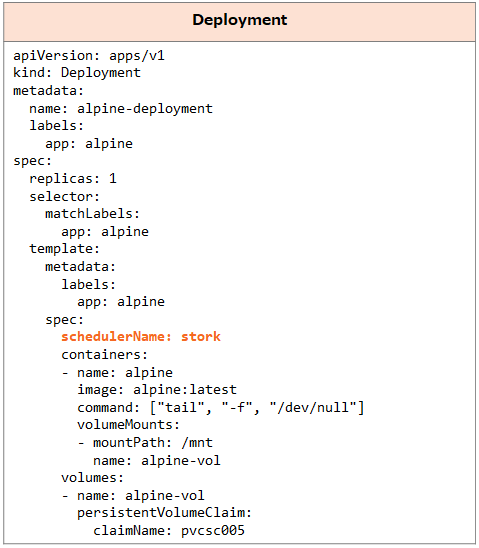 今回、動作確認のためにノードを停止しました。ボリュームのReplicaが配置されている「Ubuntu-2」にPodが再作成されましたが、これはSTORKによってデータがあるノードにPodが配置されるようになっているためです。
今回、動作確認のためにノードを停止しました。ボリュームのReplicaが配置されている「Ubuntu-2」にPodが再作成されましたが、これはSTORKによってデータがあるノードにPodが配置されるようになっているためです。
なお、PX-Centralを利用してPortworxを構成する際、"Customize"の"Advanced Settings"で"Enable Stork"にチェックを入れるとPortworxと共にSTORKがインストールされます。(PX-Centralを利用したPortworxの構成についてはこちらの記事をご参照ください。) 今回利用している環境でもこの方法でSTORKを導入しています。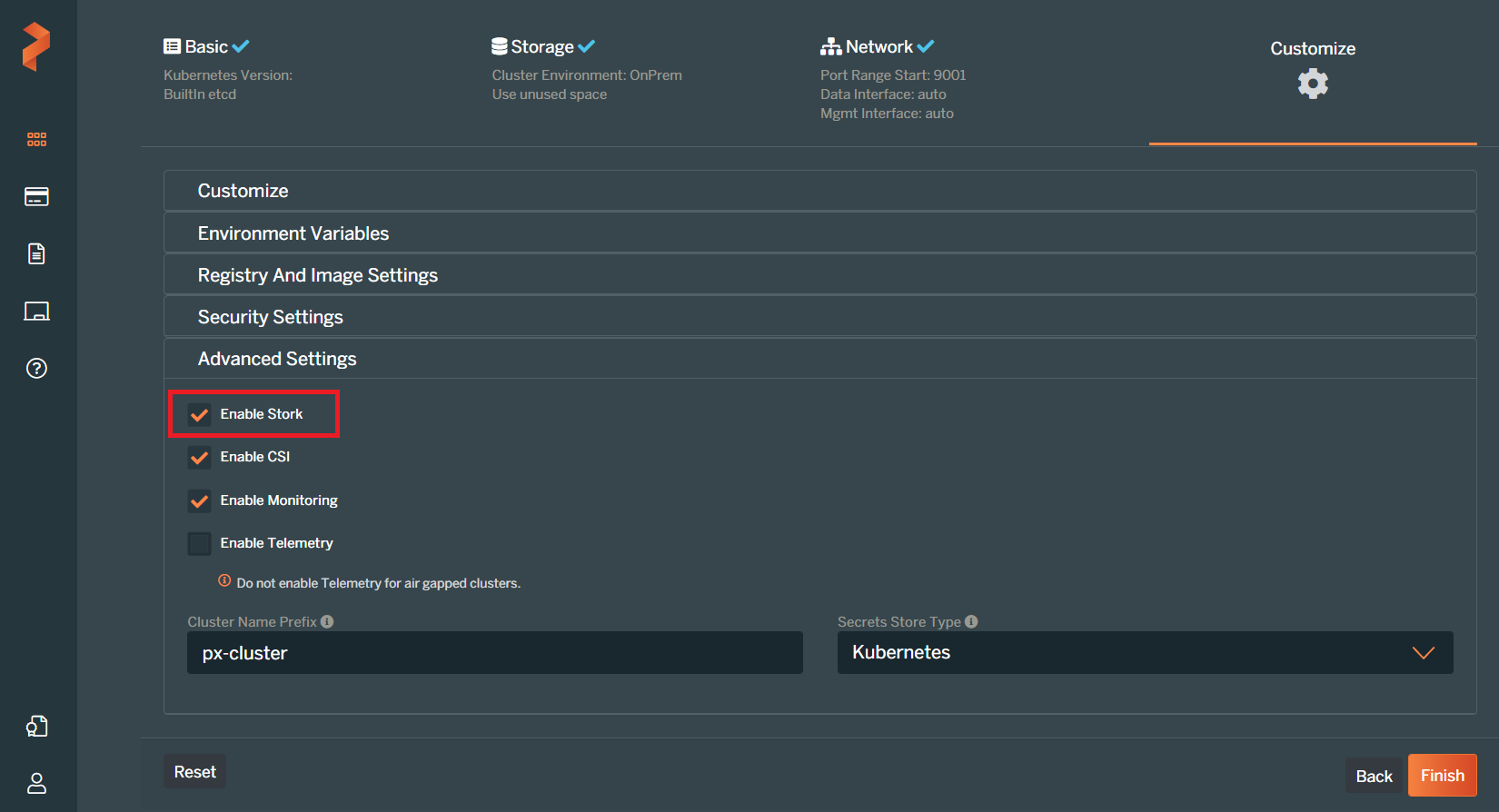
ボリュームを作成する様々な方法
今回はStorage Policyを作成しておくことで、作成されるボリュームにAggregationやReplicationが設定されるようにしていました。Storage Policyを利用せずにAggregationやReplicationを設定することも可能です。
ここからはその操作方法をご紹介いたします。(Storage Policyが設定されていない状態で操作を行っています。)
設定例1: PXCTL("pxctl volume create"コマンド)によるボリューム作成時に指定する
今回はKubernetes側でStorageClassを利用し動的にボリュームが作成されるようにしていましたが、Portworx側でPXCTLを利用し手動でボリュームを作成することも可能です。この際、オプションによりAggregationやReplicationを設定することも可能です。
今回は"pxctl volume create"コマンドを利用しAggregationレベル: 2、Replication Factor: 1が設定された「pxctl-vol」という名称のボリュームを作成してみます。(本コマンドで指定できるオプション等についてはこちらのドキュメントをご参照ください。)![]() 作成したボリュームを"pxctl volume inspect"コマンドで確認すると、HA: 1が設定されており(= Replication Factor: 1)、"Replica sets on nodes"にはSetが2つ表示されている(= Aggregationレベル: 2)ことが確認できます。
作成したボリュームを"pxctl volume inspect"コマンドで確認すると、HA: 1が設定されており(= Replication Factor: 1)、"Replica sets on nodes"にはSetが2つ表示されている(= Aggregationレベル: 2)ことが確認できます。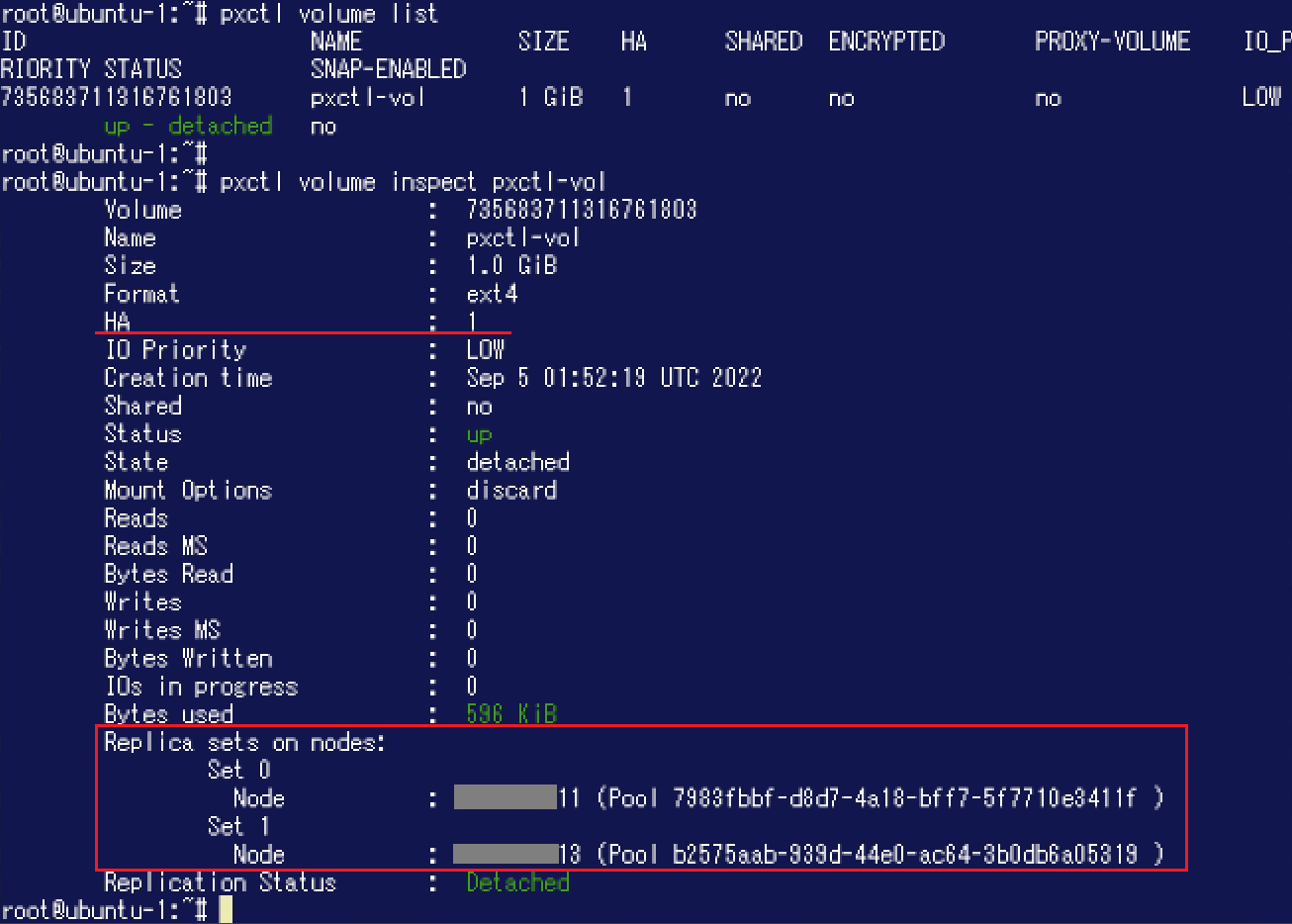
設定例2: StorageClassのパラメータで指定する
StorageClassのパラメータによりAggregationやReplicationを設定することも可能です。ここでもAggregationレベル: 2、Replication Factor: 1のボリュームを作成してみたいと思います。
Portworxのボリュームを作成するためのStorageClassではこちらのドキュメントに記載の通り、様々な設定を"parameters:"で指定することができます。ここではKubernetes側で以下のStorageClassを作成します。("parameters:"でAggregationレベル: 2、Replication Factor: 1を指定しています。) 次に以下のPVCを作成してPV(ボリューム)を払い出します。ここではNamespace「sc-test」を利用します。
次に以下のPVCを作成してPV(ボリューム)を払い出します。ここではNamespace「sc-test」を利用します。
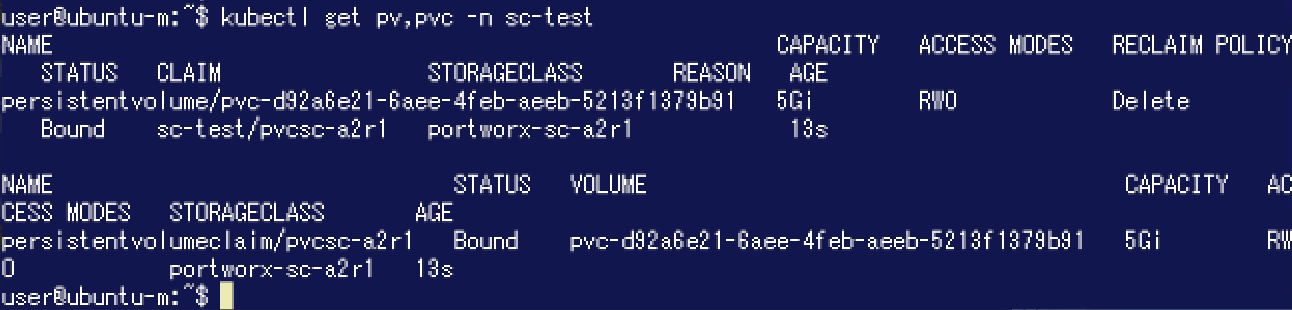 Portworx側でボリュームを確認してみましょう。こちらもHA: 1が設定されており、"Replica sets on nodes"にはSetが2つ表示されていることが分かります。
Portworx側でボリュームを確認してみましょう。こちらもHA: 1が設定されており、"Replica sets on nodes"にはSetが2つ表示されていることが分かります。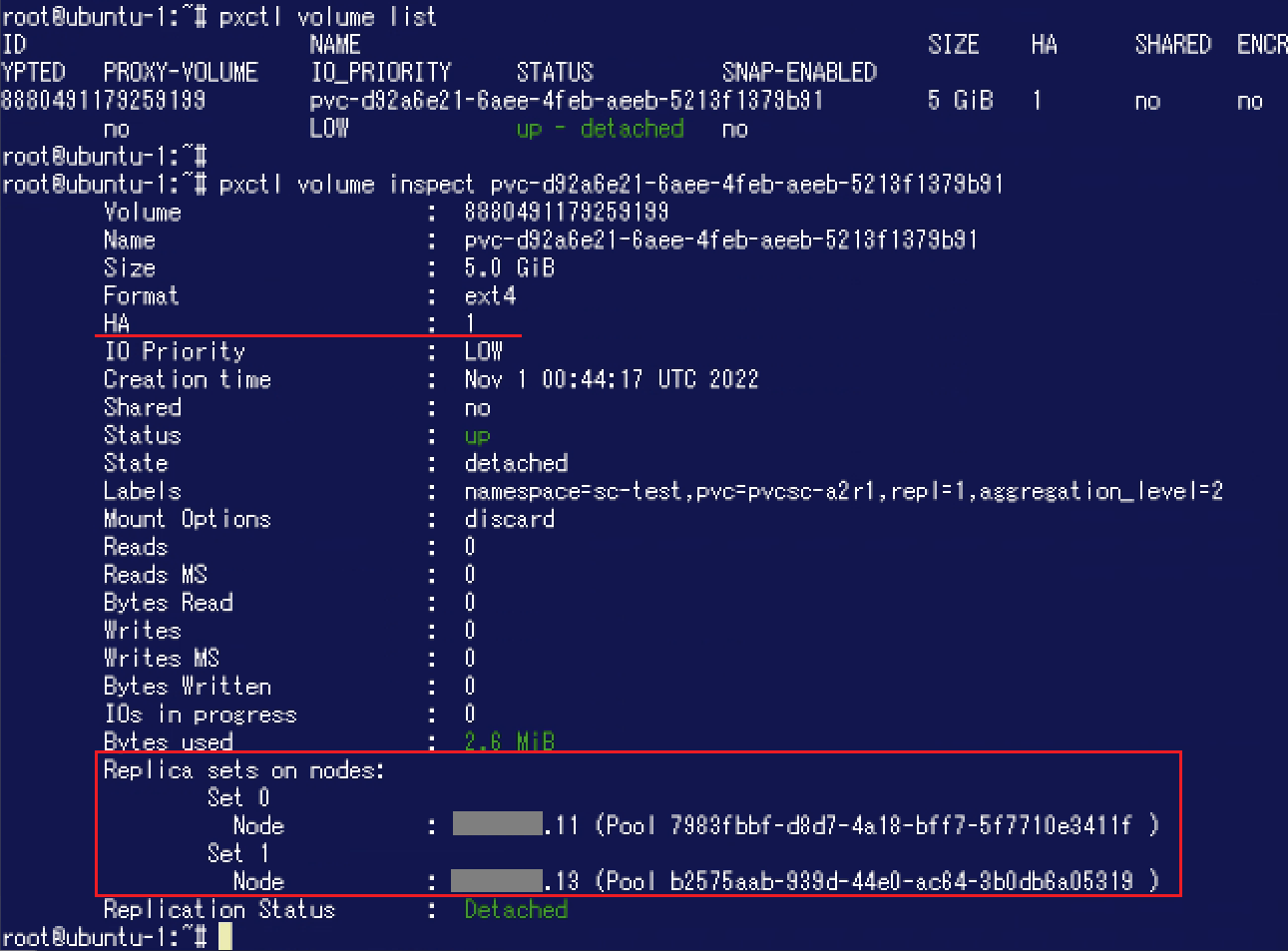 このように、Portworxでは様々な方法でボリュームの設定内容を指定できるようになっています。
このように、Portworxでは様々な方法でボリュームの設定内容を指定できるようになっています。
今回はAggregationならびにReplicationによりPortworxクラスターを構成するノード / Storage Poolをまたがった形でボリュームを利用する方法をご紹介しました。前回のブログ記事(初級編)と併せて、PX-Storeにおける基本的なボリュームの扱い方はご理解頂けたのではないかと思います。
今後もさらにPortworxの様々な機能をご紹介できればと思います。
※ 本ブログにおける記載はPortworx Enterprise 2.11の情報に基づいています。 異なるバージョンにおけるサポート範囲 / 仕様変更等についてはメーカードキュメントをご確認ください。
※ 本ブログは弊社にて把握、確認された内容を基に作成したものであり、お客さま環境での動作や製品機能の仕様について担保・保証するものではありません。サービスや製品の仕様ならびに動作に関しては、予告なく改変される場合があります。
※ 一部オブジェクトのマニフェストを変更しコマンド実行結果を更新しました。(2022/11)
Portworxに関するブログ記事一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄




