


本ブログ記事では、VMware Explore 2023 Las Vegasで発表された「VMware Private AI」をご紹介します。
VMware Explore 2023 Las Vegas開催時の速報レポートは下記のブログ記事でお伝えしておりますので是非ご覧ください。
また、本ブログ記事にはリリース前の製品・機能の紹介も含んでおり、具体的な実装等は今後変更される可能性があります。より正式な情報については、メーカーによるプレス リリースや、製品の正式リリース後のドキュメント等をご確認ください。
VMware Private AI
速報レポート でもご紹介しましたが、まずは発表の概要をご説明します。
今年は、いわゆる「生成AI」が非常に注目されています。大規模言語モデル(Large Language Model/LLM)を利用した、ChatGPTに代表されるチャット対話システムのインパクトは大きく、実際に大幅な業務効率改善が望めます。すでに業務にも導入を進めている企業も多いのではないでしょうか。
しかし、ChatGPTなどのアプリケーションはクラウド ベースで提供されるサービスであり、利用するうえで課題もあります。まず、セキュリティの面を考慮する必要があり、個人や企業独自のデータを入力することは避けるべきだとされています。また、より精度の高いアウトプットを求めて、機密となるデータを利用してAIモデルをトレーニングしたいといった要望も生まれます。
そこで新たなアプローチとして、AIの活用によるビジネス上の利益と、組織の持つデータのプライバシーやコンプライアンスとのバランスをとるべく「VMware Private AI」が発表されました。

今回はVMware Private AIに関連して、次の2つが発表されていました。
- VMware Private AI Foundation with NVIDIA
- VMware Private AI Reference Architecture for Open Source
VMware Private AI Foundation with NVIDIA
今回発表された「VMware Private AI Foundation with NVIDIA」は、企業自身が保有するセキュアな環境内で、LLMなどのAIワークロードを稼働させることができるソリューションです。例えば、自社向けのプライベートな生成AIを開発・稼働させることが可能になります。
これは、次のプロダクトがベースになると説明されていました。
- VMware Cloud Foundation
- NVIDIA AI Enterprise
ハードウェア プラットフォームとしては、Dell Technologies、Hewlett Packard Enterprise、Lenovoの3社がVMware Private AI Foundationに対応予定となっています。そして、採用するLLMとしては、NVIDIA AI Enterpriseの一部として提供される NVIDIA NeMo フレームワークやMeta社の Llama 2 などから選択することができます。
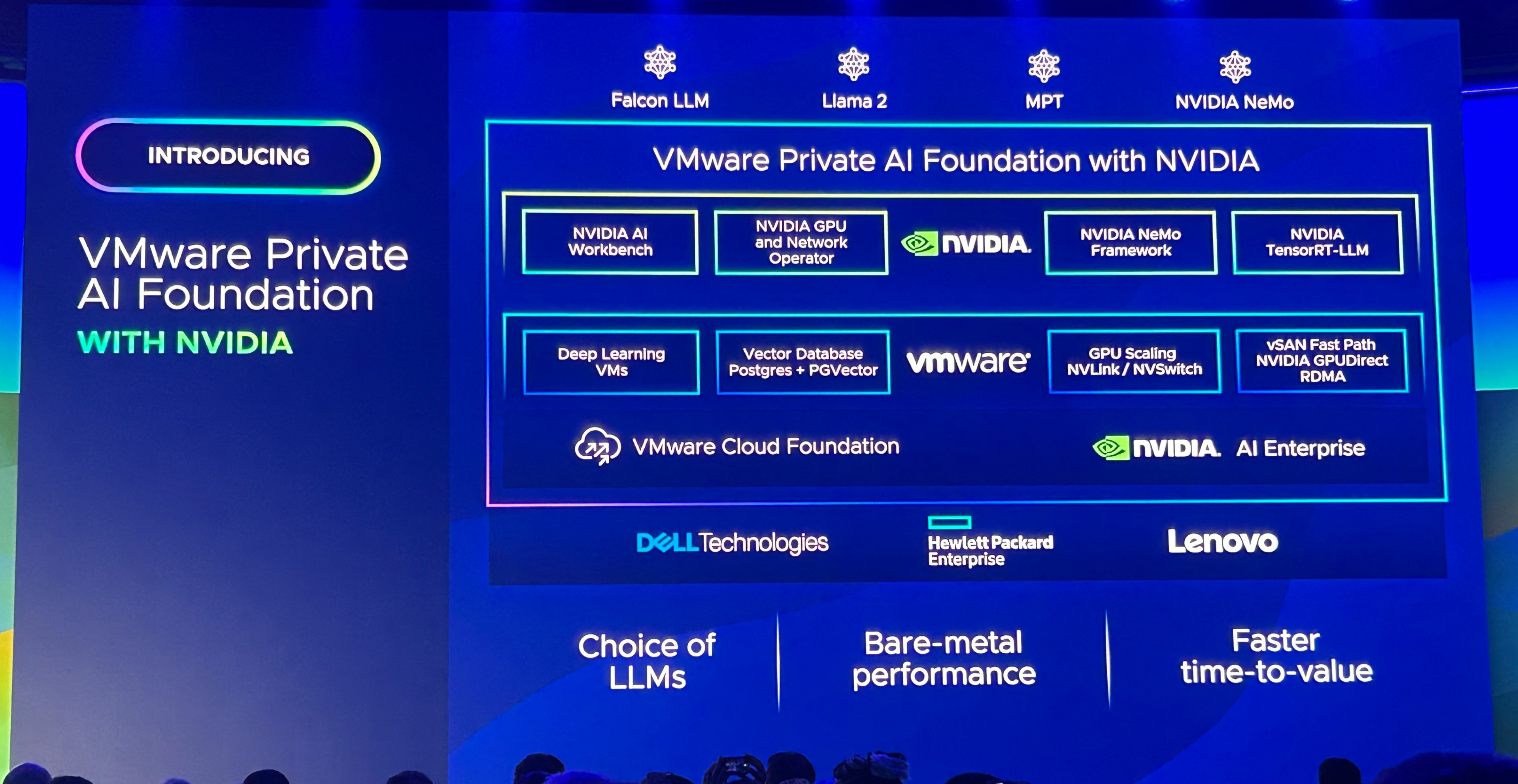
つまり、このソリューションにより、生成AIのワークロードを展開する際に必要となるサーバー・ストレージ・GPUなどを備えた、フルスタックのプラットフォームを提供できるようになります。
VMware Private AIおよびVMware Private AI Foundation with NVIDIAの詳細については、VMwareのブログもあわせてご確認ください。
- Announcing the launch of VMware Private AI: Democratize generative AI and ignite innovation for all enterprises
https://blogs.vmware.com/vsphere/2023/08/introducing-vmware-private-ai-foundation.html
なぜAIのプラットフォームでVMwareなのか
VMware Private AIは、「Any Enterprise」でAIワークロードを稼働させられるソリューションとして発表されました。これまでは「どこのクラウドであっても」といった意味合いで用いられることが多かったAnyという言葉が、今回は特にオンプレミス側を強く意識して利用されているように感じられます。
しかし、これまでVMwareの仮想化基盤を専門的としてきた方々にとって、AIワークロードやAIアプリケーションは必ずしも身近なものではないのではないかと考えられます。
そこで、AIプラットフォームがオンプレに必要になるシーンについて例をご紹介します。
まず、これまでのVMwareの視点からエンジニアを大きく分けると、インフラを担当するエンジニアと、アプリケーション開発者といった役割を想定することが多かったのではないかと思います。そしてAIに関わるシステムとなると、さらに「データ サイエンティスト」が登場します。
- インフラ エンジニア: vSphere仮想化基盤を含む、AIアプリケーションを展開するプラットフォームを構築/運用する。
- アプリケーションの開発者: トレーニングされたAIモデルを活用するアプリケーションを開発・デプロイする。利用するツールはIDEなど。
- データ サイエンティスト: インプットとなるデータの整理やプロトタイピング、AIモデルの開発・トレーニングなどを担当する。利用するツールはJupyter Notebookなど。
一方で、AIのワークロードを本番環境に展開するまでには、概ね次のような流れが考えられます。
- AIモデルの選択/開発(データ サイエンティストが主役)
- AIモデルのトレーニング / モデルの評価(データ サイエンティストが主役)
- AIアプリケーションの開発(アプリケーション開発者が主役)
- AIモデルを展開(サービング)して、AIアプリケーション(モデルによる推論)を実行する。
このうち、はじめのAIモデルの開発やトレーニングを実施する時点から、コンテナが利用されることになりますが、この時点ではKubernetesが必要とされるとは限りません。
AI導入プロジェクトの初期検討段階であったり、AIモデルのトレーニングにとりかかりはじめたような段階であれば、データ サイエンティスト自身のデスクトップ マシンでも作業を進められる状況もありえます。1台の物理マシンを用意してGPUハードウェアを搭載し、コンテナ実行のためのDocker Desktopがインストールされ、そこでJupyter Notebookでのプロトタイピングができれば十分かもしれません。
しかしプロジェクトが進み、大規模のモデル トレーニングや、トレーニング済みのモデルをサーバーに展開してAIアプリケーションで活用するようなフェーズとなると事情が変わります。アプリケーション利用が拡大するにしたがって物理マシン/仮想マシンの台数やコンテナの数も増え、そのなかでアプリケーションやAIモデルの迅速な展開が求められる状況になり、オーケストレーションや運用面からKubernetesが必要となるはずです。
このとき、利用するデータのロケーション、セキュリティやプライバシー、コスト、運用面などの事情により、AIプラットフォームをオンプレミスに構築するとなると、インフラ エンジニアには新しいワークロードのためのインフラをどのように用意するかといった課題が生まれます。前述のとおり、AIモデルを展開するワークロードのためのプラットフォームでは、Kubernetesと、GPUが必要になり、それらの運用面も考慮した上でオンプレミスで利用可能にする必要があります。
そこで、実績のあるサーバー仮想化基盤としてvSphere、エンタープライズ向けKubernetesディストリビューションであるTanzu Kubernetes Grid、NVIDIAによるvGPUを組み合わせたソリューションが選択肢となります。
vSphere上での仮想マシンでNVIDIAのvGPUを利用することで、GPUを複数の仮想マシンで共用して効率的に利用する、あるいは仮想マシンに複数のvGPUを接続して拡張性をもたせるといった柔軟な構成ができるようになります。そして、vGPUを接続した仮想マシンでのvMotionが実行できることで、数日に渡るような長時間のモデル トレーニング ジョブの実行中であっても、インフラ エンジニアによるホスト メンテンナスが可能になります。
ただし実際にプラットフォームを用意するとなると、VMware製品同士であっても、ただインストール作業を実施するだけでなく、互換性確認やバージョン選定、各種設計や運用検討など多くのタスクが必要になります。そこでVMware Cloud Foundationを採用することによって、vSphere、vSAN、NSX、Tanzu Kubernetes Gridといったソフトウェア スタックを一貫する、ベストプラクティスをもとに設計され運用性も考慮されたプラットフォームを構築することができます。
あらためてvSphereへのAIワークロードの展開について
VMware Private AI Foundation with NVIDIAは2024年初頭に提供予定とのことで、具体的な実装の詳細が発表されるのも少し先になるかもしれません。そこで、ここではベースとなる既存ソリューションであるNVIDIA AI EnterpriseとVMware Cloud FoundationのAIワークロード展開について、あらためて関係性を簡単に紹介しておこうと思います。
前述のとおりVMware Cloud Foundationは、実体としてはvSphereなので、ここではvSphere(上のKubernetes)へのAIワークロードの展開の考え方としてご説明します。
まずNVIDIA AI Enterpriseでは、ソリューションに含まれるAIワークロードのライブラリやフレームワークのソフトウェア(例えばNVIDIA NeMo)を、NVIDIAによるコンテナ レジストリであるNGCからコンテナで提供しています。つまりAIワークロードを構成するコンテナの展開先として、GPUを利用可能なKubernetesが必要になります。
そのコンテナを起動するためのKubernetesクラスターをvSphere上に展開するには、vSphere with Tanzuのスーパーバイザー クラスターで管理される「Tanzu Kubernetes Grid Service」が利用されます。これは、単体でも利用可能なTanzu Kubernetes Gridを、vSphere上で利用しやすくした機能です。vSphere上にLinux仮想マシンとしてKubernetesクラスターのノードを作成するものであり、vSphere with Tanzu独自の「vSphere Pod」は利用しません。
つまり、ESXi側のvGPUのセットアップとしては、一般的なLinux仮想マシンがvGPUを利用できるように準備(NVIDIA vGPUのためのハードウェア セットアップとドライバー インストール)を実施しておくことになります。
そして、vGPUのセットアップが完了しているESXiホスト上に、AIアプリケーションを起動するための「ワークロード クラスター」をTanzu Kubernetes Grid Serviceによって作成することになります。この手順が唯一、これまでvSphereやvGPUを扱ってきたエンジニアにとって新しい知識が必要となる部分となります。
このようにESXi側での準備などについては、これまでvSphereやvGPUを扱ってきたインフラ エンジニアにとっては、従来の知識や経験が活用できるものであり、それはVMware Cloud FoundationによってvSphere仮想化基盤を構築する場合であっても同様です。
今後VMware Private AI Foundation with NVIDIAが提供開始されることで、仮想化基盤からGPU利用可能なKubernetesクラスターまで一貫してインテグレーションされた、メーカーに認定されかつ実績があるエンタープライズ仕様のAIプラットフォームが採用できるようになると言えるでしょう。
AIワークロード展開のデモ - Ray on vSphere -
本番環境でAIアプリケーションを実行するまでには、前述のように、AIモデルの開発、トレーニング、展開(サービング)といった、AIモデルのライフサイクルが存在します。そこでは、AIモデルのライフサイクルを管理するためのフレームワーク(Kubeflow など)や、AIワークロードを分散実行するためのオーケストレーター(Anyscale社の Ray など)が利用されます。
「VMware Private AI Reference Architecture for Open Source」では、そういったソフトウェアをVMware Private AIソリューションの中で利用できるようリファレンス アーキテクチャが提供されます。

その中でも、vSphere上でRayを実行する様子のデモが、ソリューション キーノート「Technology Innovation Showcase」にて紹介されていました。これは、AIワークロードを扱うツールにvSphereのプラグインが提供されるという、インフラ エンジニアの役割を、データ サイエンティストにセルフサービス提供できるようになるようなインテグレーションと考えられます。
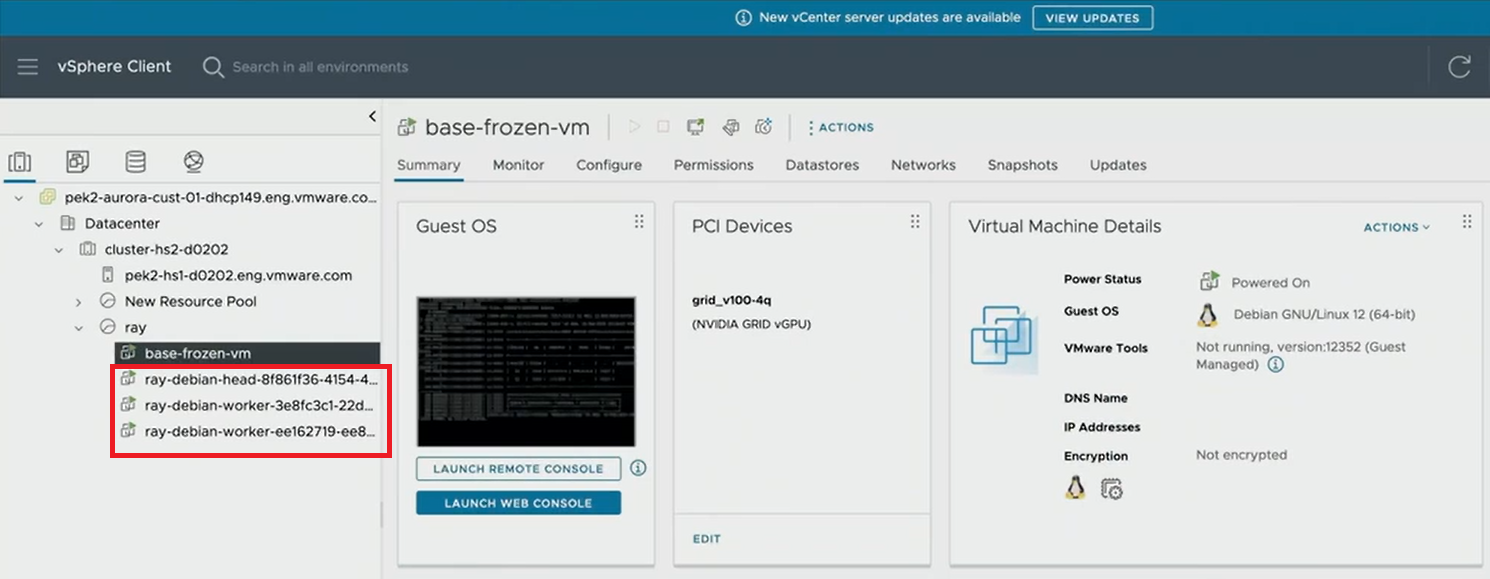
デモでは、まず「ray up」コマンドを実行して、Ray Clusterの仮想マシンがvSphere上に展開されます。
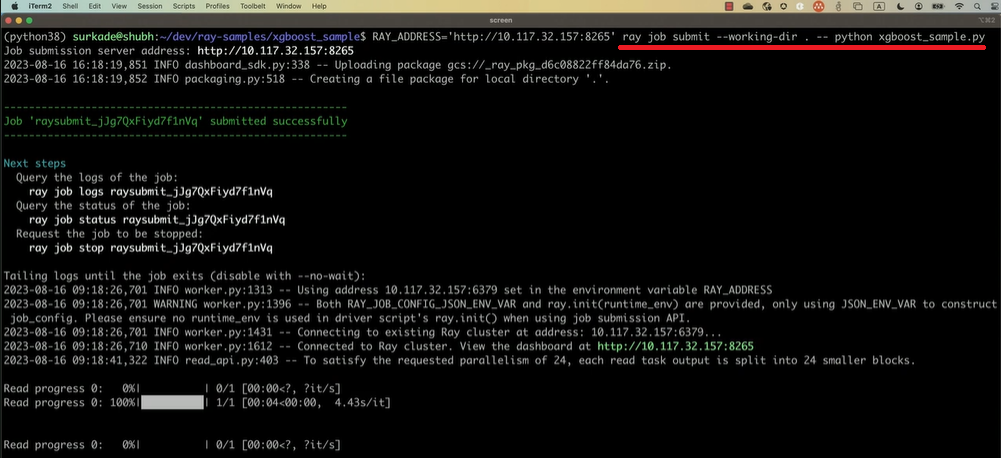
そして、展開されている仮想マシンにRay Jobs CLI(ray job submitコマンド)でPythonスクリプトによるモデル トレーニングのジョブを投入する様子が紹介されていました。
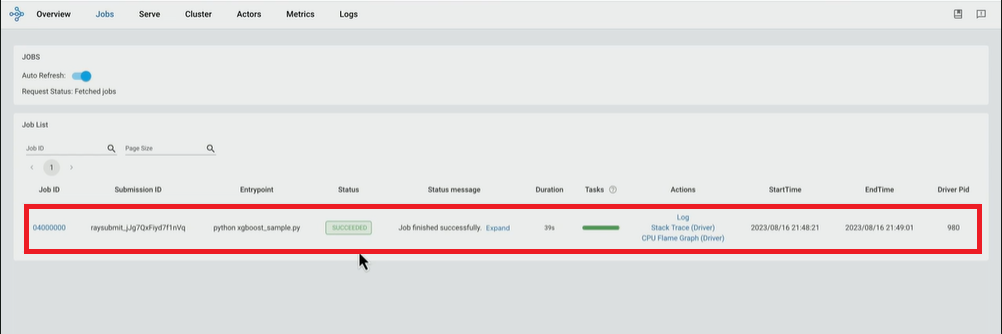
コマンドでのジョブが完了すると、Rayの提供するWeb UI側でも実行されたことが確認できます。
RayとvSphereプラグインについては、下記のVMwareブログでも紹介されているので、あわせてご確認ください。
- Enabling AI: Announcing the Ray on Open-Source Plugin
https://octo.vmware.com/enabling-ai-announcing-the-ray-on-open-source-plugin/
本ブログ記事ではVMware Explore 2023 Las Vegasで紹介された、VMware Private AIを中心としたアップデートをピックアップしてお届けしました。VMware Exploreで発表された様々なアップデートは 別ブログ記事 でもお伝えしていますので是非ご確認ください。
参考URL
- VMware and NVIDIA Unlock Generative AI for Enterprises
https://news.vmware.com/releases/nvidia-vmware-generative-ai - VMware、"Any Enterprise"に向けて生成AIの活用を支援
https://news.vmware.com/jp/releases/20230824_explore_ai_jp - Announcing the launch of VMware Private AI: Democratize generative AI and ignite innovation for all enterprises
https://blogs.vmware.com/vsphere/2023/08/introducing-vmware-private-ai-foundation.html - Enabling AI: Announcing the Ray on Open-Source Plugin
https://octo.vmware.com/enabling-ai-announcing-the-ray-on-open-source-plugin/
関連記事はこちら
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第1技術部
渡辺 剛 - Go Watanabe -
VMware vExpert
Nutanix Technology Champion




