皆様こんにちは。
SB C&SでAIソリューション全般のプリセールスを担当している下山と申します。
本日はNVIDIA GPU Cloud(以下、NGC)並びにNGCカタログについて簡単にご紹介させていただきます。また、NGCカタログに掲載されているソフトウェアを用いてディープラーニングを簡単にお試しいただける手順についてもご案内します。
NGC(NVIDIA GPU Cloud)とは?
NGCはNVIDIAが提供するすべての企業向けソフトウエア、ハードウェアおよびクラウドサービスへのポータルサイトです。具体的には、NVIDIA GPUに向けて最適化されたAIソフトウェア、Helmチャート、トレーニング済みのモデル、各種のドキュメントやコンテンツが掲載されています。これらのソフトウェアやコンテンツはNGC内の「NGCカタログ」、NVIDIA AI Enterprise(※)をご購入いただいたお客様のみがご利用いただける「NGC Enterpriseカタログ」から入手いただけます。直近では「AI Foundationモデル」という新しいラインナップが追加され注目を集めております。AI Foundationモデルについて、詳しくはこちらをご覧ください。
※NVIDIA AI Enterpriseとは?一言で表すと、「NVIDIAによって検証済みのAI開発および運用が行なえるソフトウェアスイート」です。NVIDIA AI EnterpriseではAIソフトウェアや暗号化されていない事前トレーニング済みのモデルなどがパッケージ化された上で提供されており、これらを活用いただくことで様々なワークロードに対応したAI環境を容易に構築していただけます。たとえば、高品質なデータで事前にトレーニングされたモデルの重み付けパラメータを調整し、お客様固有のユースケースに向けて最適化されたモデルを迅速に構築するといったことも実現可能です。暗号化されていないモデル以外にも、AI EnterpriseサービスはAI開発の実務においてお客様へ様々なメリットをもたらします。 NVIDIA AI EnterpriseはNVIDIA GPUを導入いただいたお客様に向けてNGCを通して提供され、それらのサービスの一部は無償でお試しいただくことが可能です。ご興味のある方はこちらのページも併せてご参照ください。 |
NGCカタログを試す
はじめに
それでは実際にNGCカタログからコンテナを入手し、オンプレミスのGPU搭載環境で動作させてみましょう。なお、以降の手順を試すにあたっては、次の3つの条件を満たしている必要があります。また、別途Dockerのセットアップが必要となりますが本稿では詳細を割愛させていただきます。
- お使いのPCもしくはサーバーにNVIDIA GPUが搭載されていること
- お使いのPCもしくはサーバーにCUDAドライバが正しくインストールされていること
- お使いのPCもしくはサーバーに「NVIDIA Container Toolkit」が正しくインストールされていること
ドライバ、Container Toolkitに関しては後日解説記事を公開させていただく予定です。よろしければそちらも併せてご参照ください。
本稿では、コンテナイメージとして「DIGITS」を、データセットとして「MNIST」を使用していきます。
|
テスト用サーバ構成: OS: Ubuntu 22.04.4 LTS CUDA Driver Version: 545.23.08 Docker Version: 25.0.3 |
MNISTのダウンロード・下準備
ディープラーニングや機械学習を扱うにあたって、まずは学習に用いるデータを用意しなければなりません。世の中にはそのような用途に用いることのできるいくつかのオープンなデータセットが存在しますが、その中の一つに「MNIST」があります。MNISTは1990年代に整備され今日に至るまでに広く用いられており、0から9までの手書き数字の画像データ7万枚から構成されています。(内、訓練用データ6万枚、テスト用データ1万枚)
公式ページで配布されているデータは一般的なJPGやPNGなどのフォーマットではありません。従って、利用の際には自らがDIGITSで扱えるPNG形式などに変換する必要があります。※なお、2024年3月の記事作成時点では公式ページが閲覧できない状態にあるため、次に挙げる方法を用いて学習に必要なデータセットを入手します。
Pytorchを用いる
いくつかの機械学習ライブラリがMNISTへのアクセスを提供しており、ここではPytorchを用いてデータセットを入手することとします。Pytorch以外にKerasやTensorFlowなどでも同様に入手が可能ですので、お好みの方法でMNISTをご用意いただければ問題ありません。
先ずはMNISTの配置先ディレクトリを作成します。
続いて、MNISTデータセットを入手するためのコードを実行しますが、前提条件としてPytorchはセットアップが完了しているものとします。(Pytorchについての詳細は割愛)
from torchvision import datasets
rootdir = "/home/hoge/..."
traindir = rootdir + "/train"
testdir = rootdir + "/test"
train_dataset = datasets.MNIST(root=rootdir, train=True, download=True)
test_dataset = datasets.MNIST(root=rootdir, train=False, download=True)
number = 0
for img, label in train_dataset:
savedir = traindir + "/" + str(label)
os.makedirs(savedir, exist_ok=True)
savepath = savedir + "/" + str(number).zfill(5) + ".png"
img.save(savepath)
number = number + 1
print(savepath)
number = 0
for img, label in test_dataset:
savedir = testdir + "/" + str(label)
os.makedirs(savedir, exist_ok=True)
savepath = savedir + "/" + str(number).zfill(5) + ".png"
img.save(savepath)
number = number + 1
print(savepath)
rootdirで指定したディレクトリ配下にデータが生成されます。任意のパスに書き換えたうえでコードを実行してください。 ここではPythonの対話型シェルを起動しコードを実行します。
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>>
>>> import os
>>> from torchvision import datasets
rootdir = "/home/user01/DATA"
traindir = rootdir + "/train"
testdir = rootdir + "/test"
(中略)
/home/user01/DATA/test/5/09998.png
/home/user01/DATA/test/6/09999.png
>>>
>>>
user01@aiub01:~$ ls ./DATA/
MNIST test train
user01@aiub01:~$
コードの実行後、rootdirで指定したディレクトリ配下にデータが生成されています。生成される各画像データは28 x 28px、8bitグレースケールのPNGです。
- MNIST: 変換前のデータ
- test: テスト用PNG画像
- train: 訓練用PNG画像
test / trainディレクトリの内容は以下の通りです。各サブディレクトリ名に対応する様々な筆跡の数字が格納されています。
0 1 2 3 4 5 6 7 8 9
user01@aiub01:~/DATA$
user01@aiub01:~/DATA$ ls ./train/
0 1 2 3 4 5 6 7 8 9
user01@aiub01:~/DATA$
これでお手元にMNISTデータセットを準備することができました。続いてDIGITSのコンテナイメージをNGCカタログから入手し、起動します。
DIGITSコンテナのダウンロード・起動
DIGITSとは、画像認識など特定のディープラーニングタスクに関するディープ ニューラル ネットワーク (DNN) を簡単かつ高速にトレーニングできる機能を提供するツールです。すべてのツール操作がWebブラウザ上のUIで完結するため、AI開発者はネットワーク設計とモデルトレーニングの際にプログラミングやデバッグの手間を気にする必要がなくなります。なお、DIGITSはAI開発の実務において活用されることを主眼として開発されたソフトウェアではなく、主にデモで用いられることを想定している点をご留意いただけますと幸いです。
①NGCカタログへのアクセス
WebブラウザでNGCカタログ(https://catalog.ngc.nvidia.com/)へアクセスして下さい。
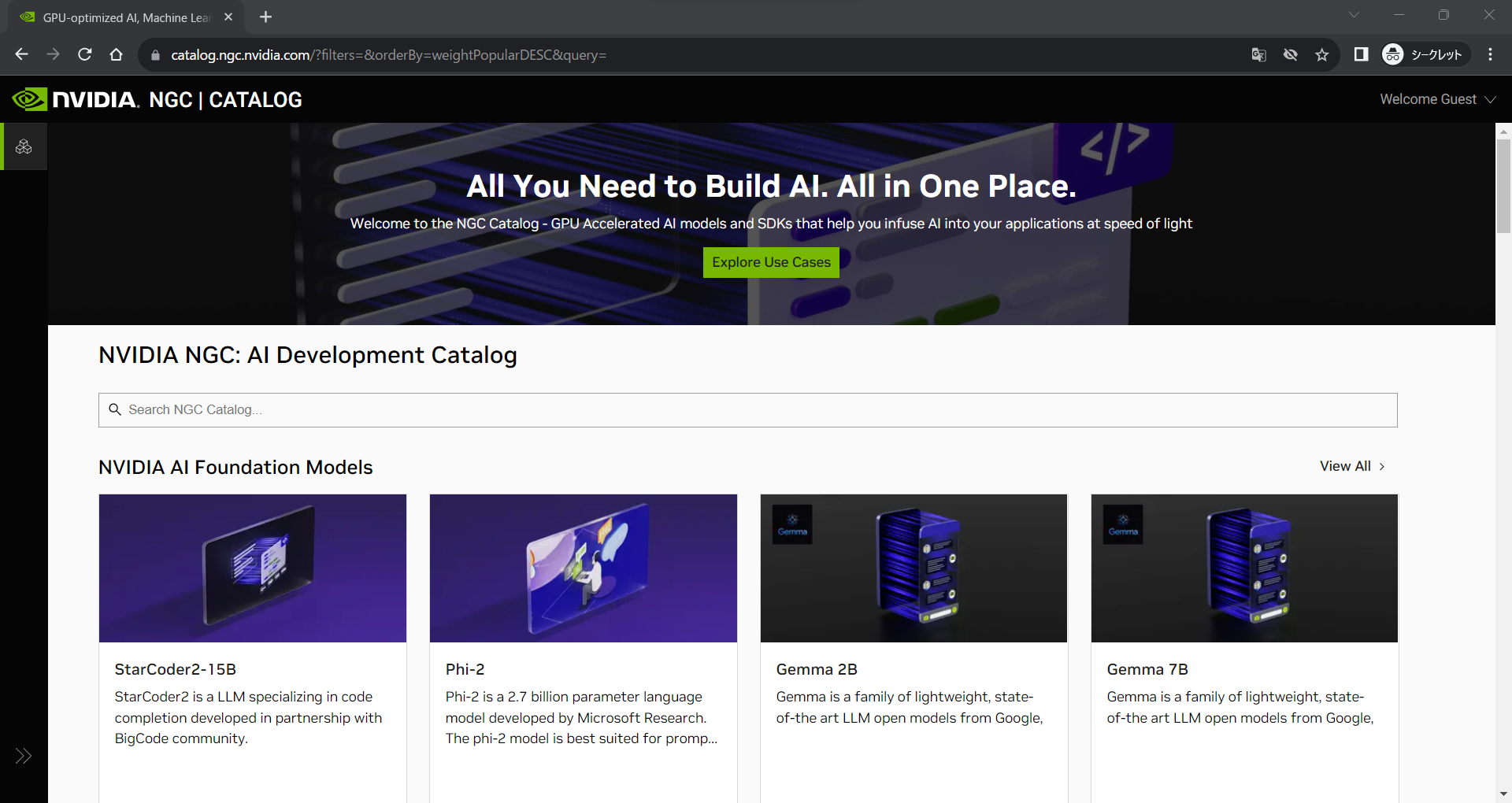
②DIGITSコンテナイメージの検索
検索欄にDIGITSと入力するとDIGITSコンテナが表示されます。「Learn More」をクリックしてください。
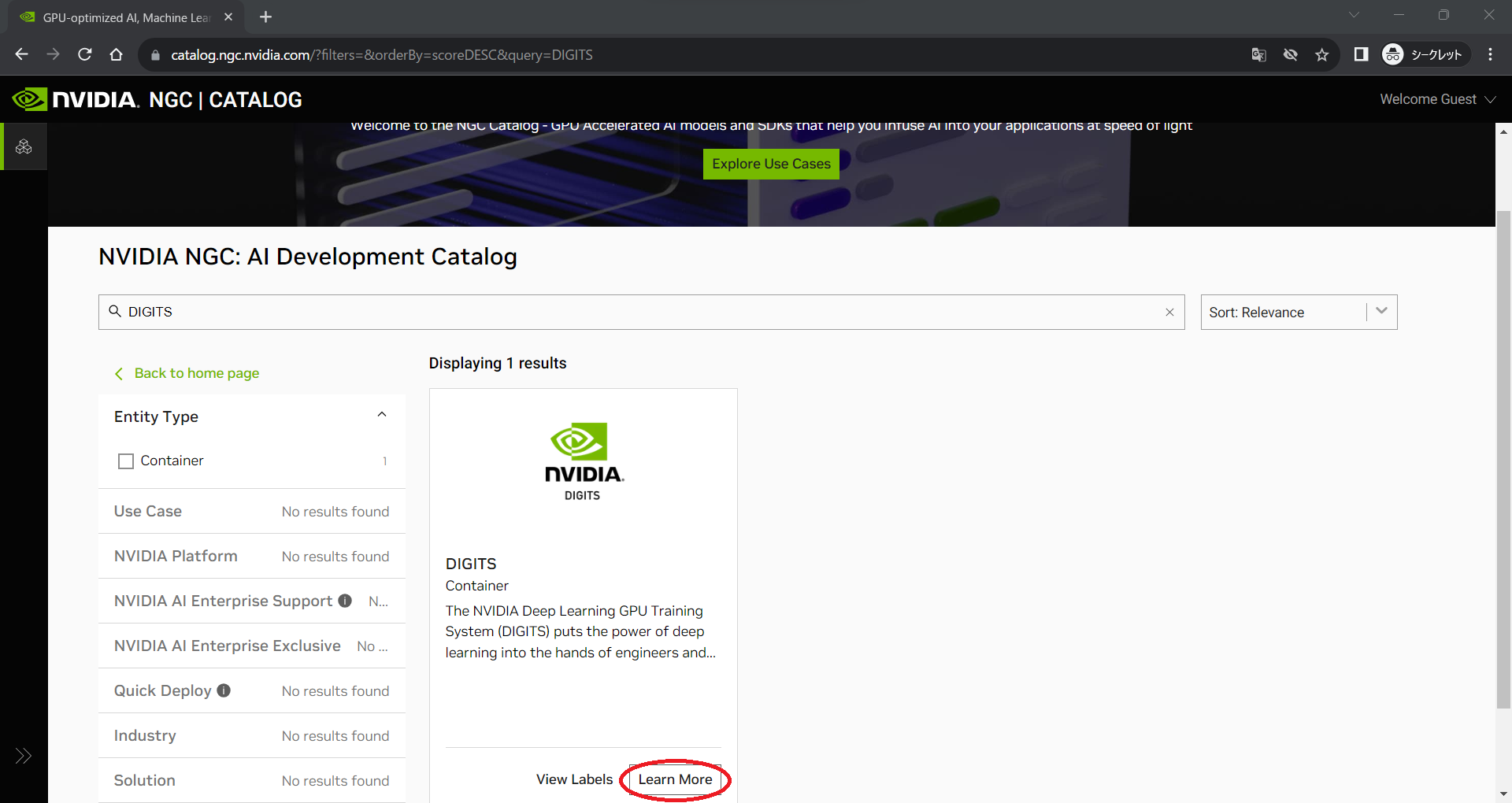
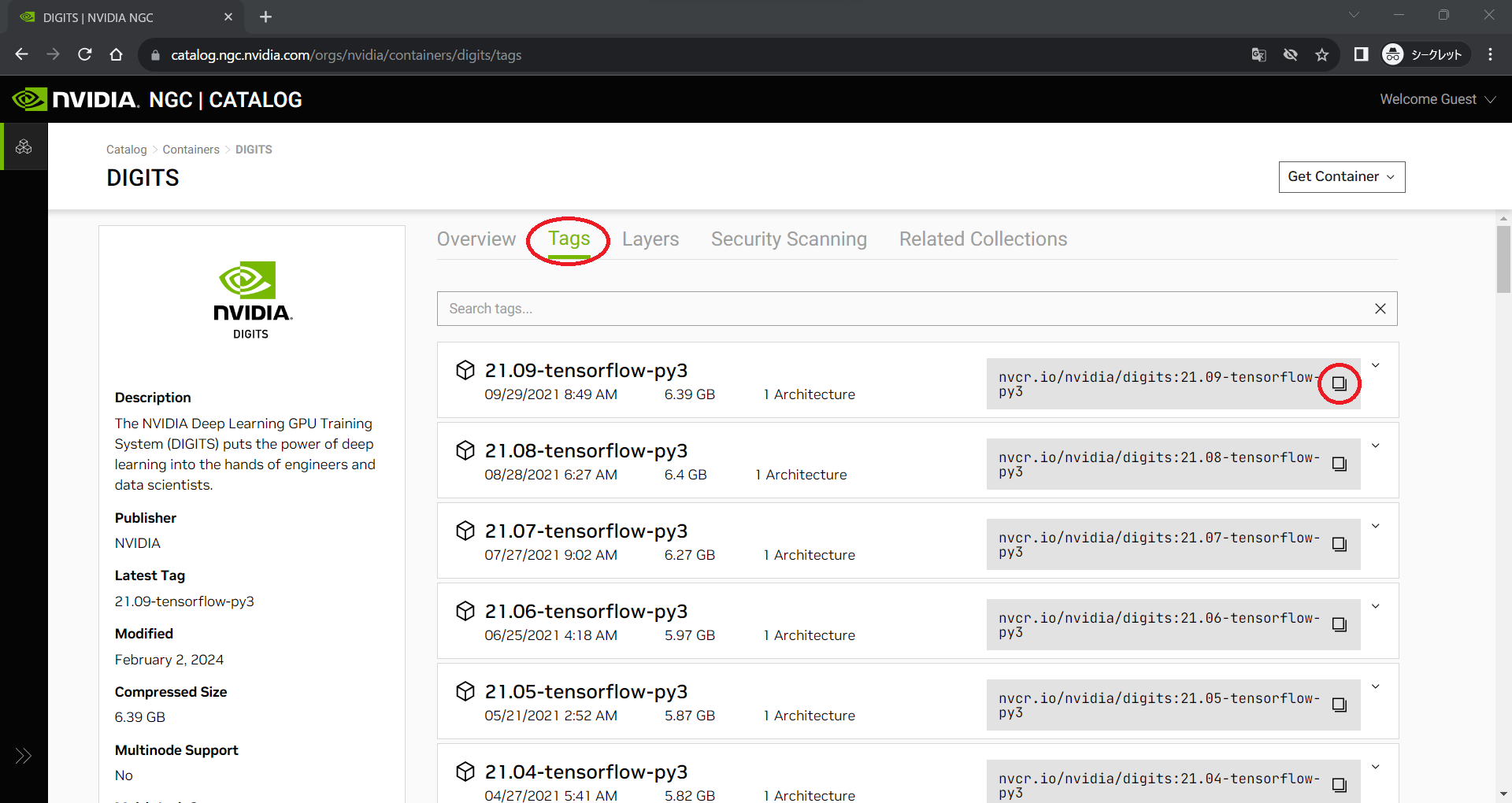
③タグの選択
次に、ダウンロードするコンテナイメージのイメージタグを選択します。Tagsタブへ移動し、目的のものをコピーします。ここでは、特別な事情がない限り、最新のものを選択してください。
④イメージプルとDIGITSコンテナの起動
21.09-tensorflow-py3: Pulling from nvidia/digits
(略)
0389cf05e4e1: Pull complete
32c56beb2f51: Pull complete
Digest: sha256:2cd85ac9a8373804ae5242aeb36d2a438aabe2d349d07851b02ab0bb2309574d
Status: Downloaded newer image for nvcr.io/nvidia/digits:21.09-tensorflow-py3
nvcr.io/nvidia/digits:21.09-tensorflow-py3
user01@aiub01:~$
REPOSITORY TAG IMAGE ID CREATED SIZE
nvcr.io/nvidia/digits 21.09-tensorflow-py3 22d4b7c5ed49 2 years ago 14.6GB
user01@aiub01:~$
--gpus
19.03以降のDockerで利用できるオプションで、このオプションが指定されることによりコンテナはホスト上のGPUリソースへアクセスすることができるようになります。Dockerホスト上に複数のGPUが実装されている場合、"--gpus all"を指定することでコンテナはホスト上のすべてのGPUを利用することができます。
-v
MNISTデータセットの配置を目的とし、Dockerホスト上の"/home/user01/DIGITS/data"をDIGITSコンテナの"/data"としてマウントしています。コマンドを実行する際はMNISTデータセットが配置されているディレクトリパスとして読み替えてください。
-p
DIGITSコンテナは5000番ポートにてWeb UIへの接続を待ち受けており、これをホストの8800番ポートへマッピングしています。これにより、外部環境から<Dockerホストのip addr>:8800へアクセスすることでDIGITS Web UIを利用することができるようになります。なお、ここで指定するポート番号は任意の値をご利用いただいても問題ありません。
4532834fa86abdffa93e2ebf1a58326d7ea4cdcf5def25079ce0235819d100cb
user01@aiub01:~$
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4532834fa86a nvcr.io/nvidia/digits:21.09-tensorflow-py3 "/usr/local/bin/nvid..." About a minute ago Up About a minute 6006/tcp, 6064/tcp, 8888/tcp, 0.0.0.0:8800->5000/tcp, :::8800->5000/tcp digits
user01@aiub01:~$
⑤データセットの配置
取得したMNISTデータセットのうち、trainディレクトリ配下の内容をDIGITSコンテナへマウントしたディレクトリへコピーもしくは移動してください。
DIGITS Web UIの利用
これまでのステップを完了することでDIGITSを用いてディープラーニングを始める準備が整いました。それでは早速DIGITS Web UIにアクセスしてみましょう。
検証を実施しているUbuntuホストのIPアドレスは10.1.3.81となっているため、Webブラウザのアドレスバーに10.1.3.81:8800と入力します。
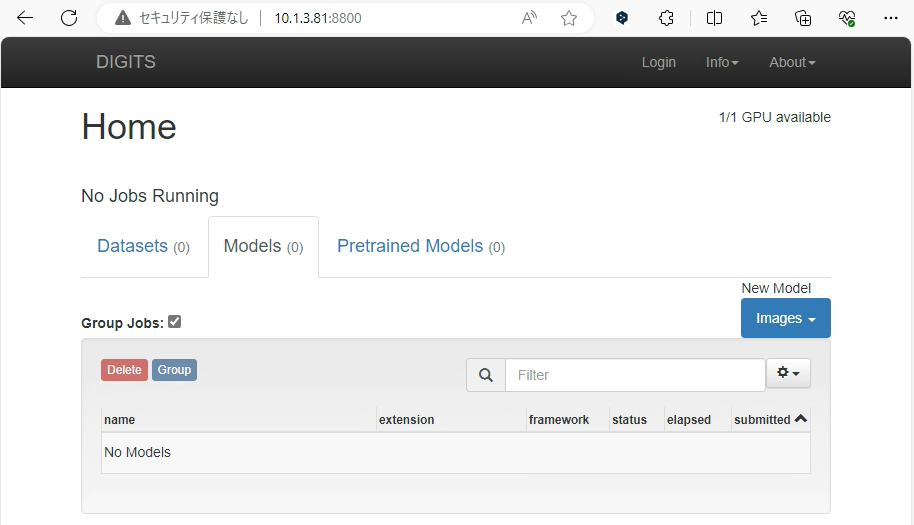
Web UIが表示されました。
まず手始めにログインを行います。画面右上の「Login」を押下して下さい。
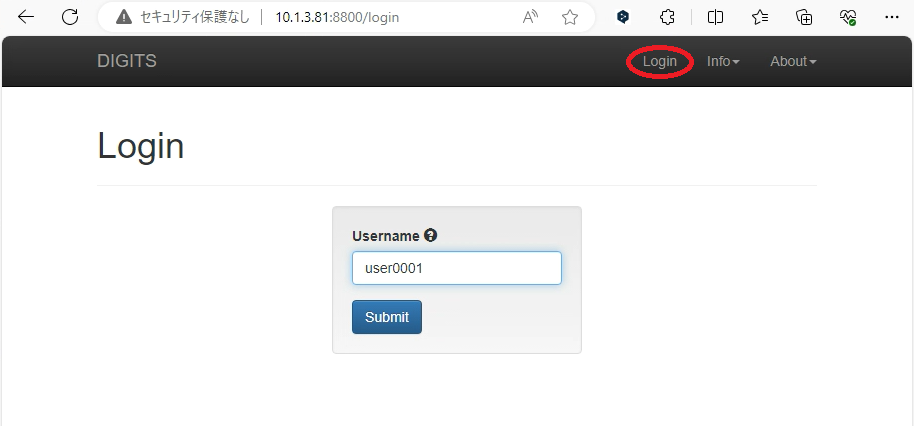
任意のUsernameを入力し「Submit」を押下します。
それでは実際にディープラーニングの一連の流れを試していきましょう。
①データセットの取り込み
.1 Datasetsタブへ移動
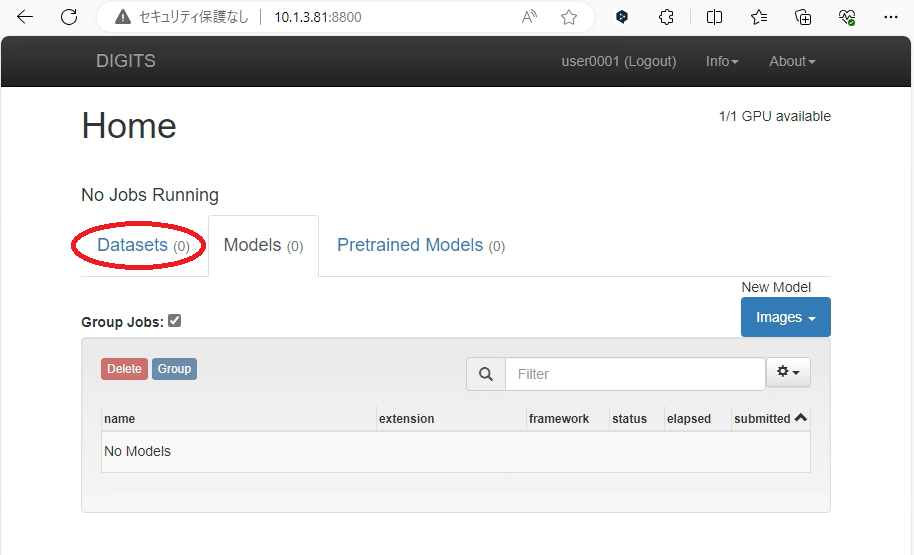
画面上のDatasetsタブをクリックします。
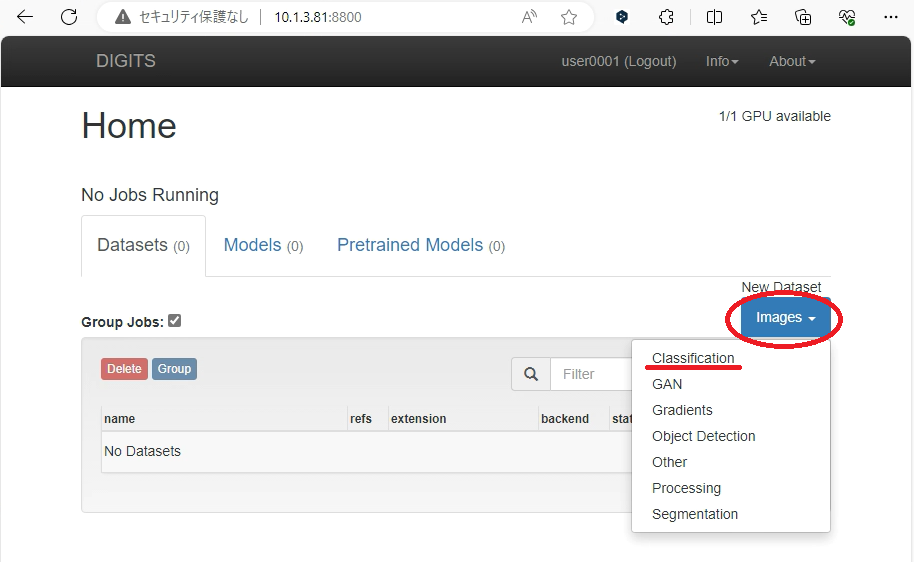
.2 Images > Classificationを選択
.3 パラメータの入力
データセットの登録に必要な各パラメータを入力していきます。
MNISTデータセットの取り込みに必要なパラメータは次の通りです。
- Image Type: Grayscale
- Image size (Width x Height) : 28 x 28
- Training Images: (ユーザによって異なる)
MNISTの訓練用PNG画像が格納されているディレクトリを指定します。本稿の場合、MNISTが格納されている"/home/user01/DATA/"はDIGITSコンテナの"/data"としてマウントされているため、Training Imagesには"/data/train"と入力します。この項目はユーザによって入力値が異なることに注意してください。 - Dataset Name: (任意)
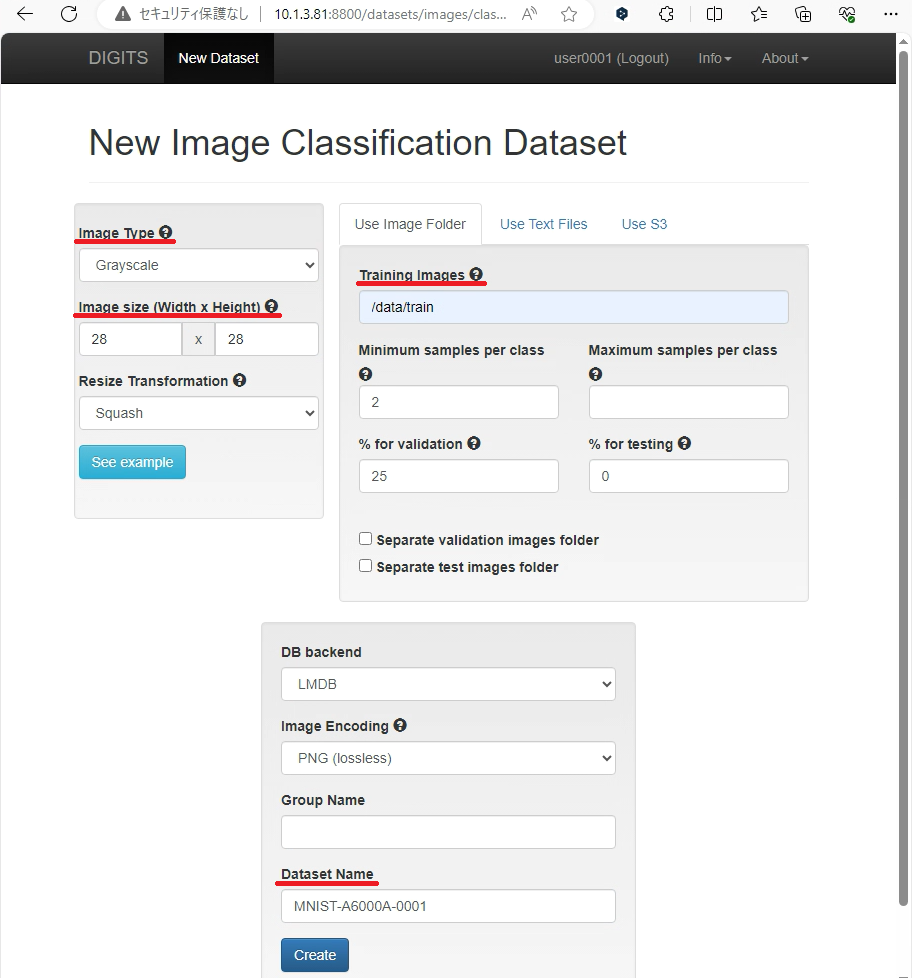
.4 Createボタン押下
Dataset Nameの下部にあるCreateボタン押下後、画面が遷移しジョブが開始されます。
遷移後の画面は自動的に更新されませんので、適宜画面を更新しジョブの進捗を確認してください。
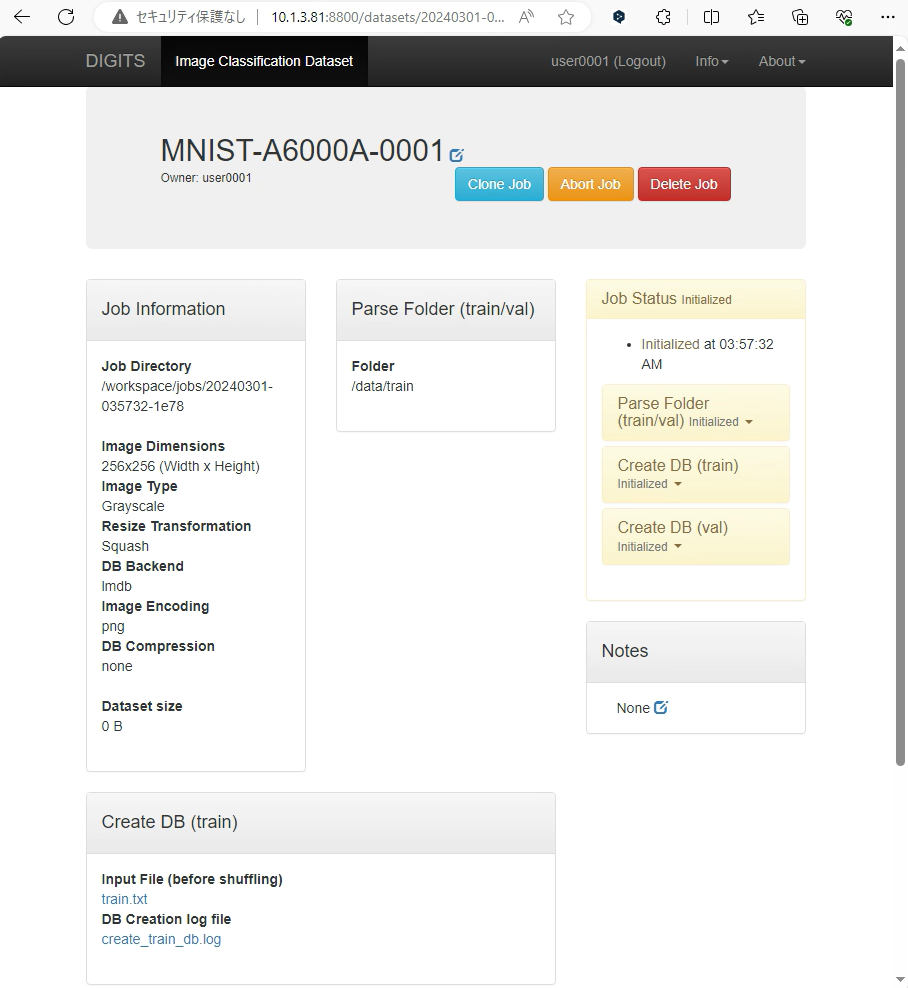
ジョブ完了後の画面表示内容
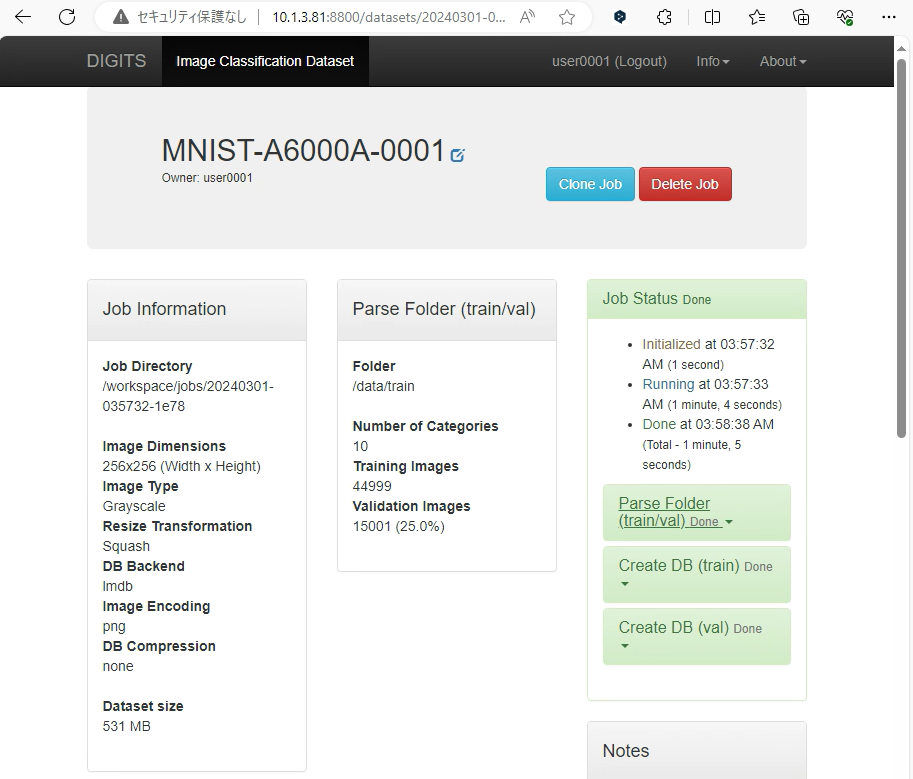
ジョブの完了後、画面左上の「DIGITS」を押下しWeb UIのトップページへ戻ります。
②ディープラーニングモデルの作成
.1 Modelsタブへの移動
データセットに続いてモデルの作成を行っていきます。
Web UIのトップページへアクセスし、Modelsタブが選択されていることを確認してください。
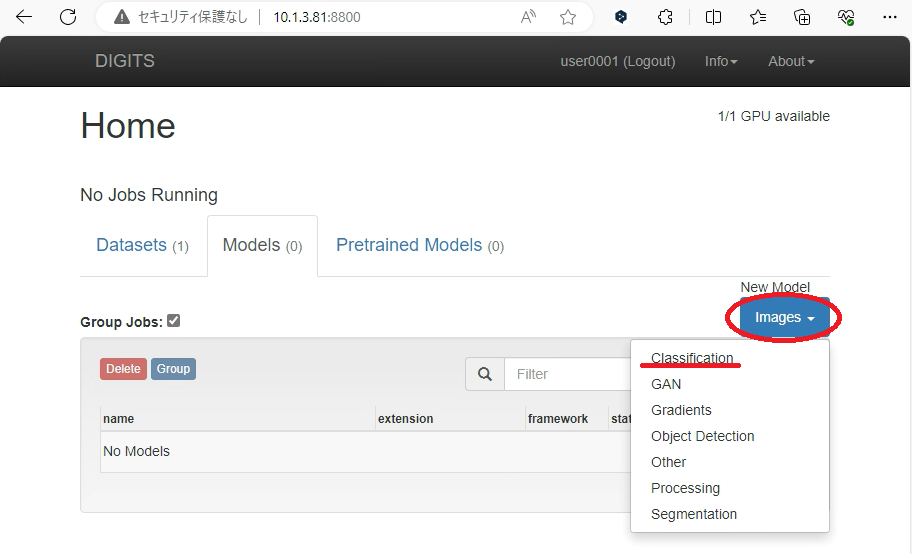
.2 青いプルダウン「New Model」のImages > Classificationを選択
.3 パラメータの入力
モデルの作成に必要なパラメータを入力していきます。
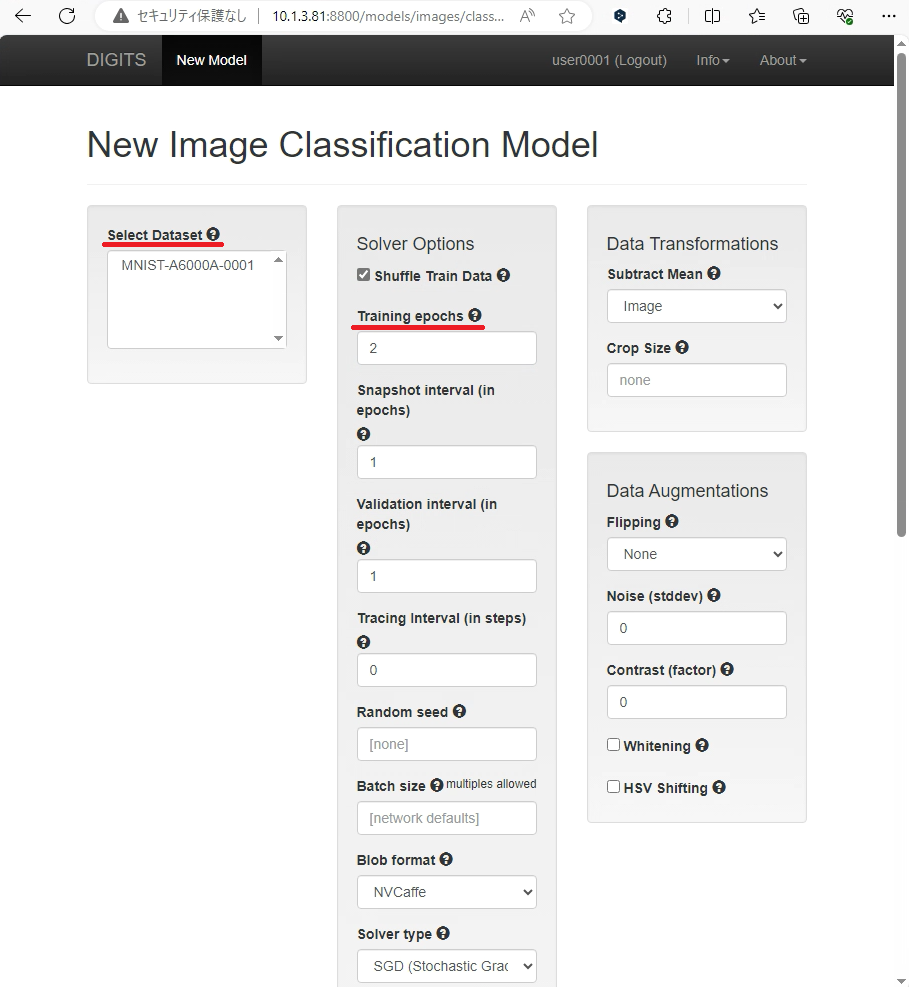
- Selecet Dataset: (ユーザによって異なる)
ここでは先ほど作成したデータセットである「MNIST-A6000A-0001」を選択します。 - Training epochs: (任意)
指定するエポック数が多すぎる場合、実装されているGPUによっては学習に多くの時間を費やしてしまう恐れがあります。ここでは検証のため、あえて2という小さい値を指定しています。 - Standard Networks > TensorFlow > Network: (任意)
学習に用いるネットワークを指定します。ここではもっとも単純で軽量なLeNetを指定します。 - Model Name: (任意)
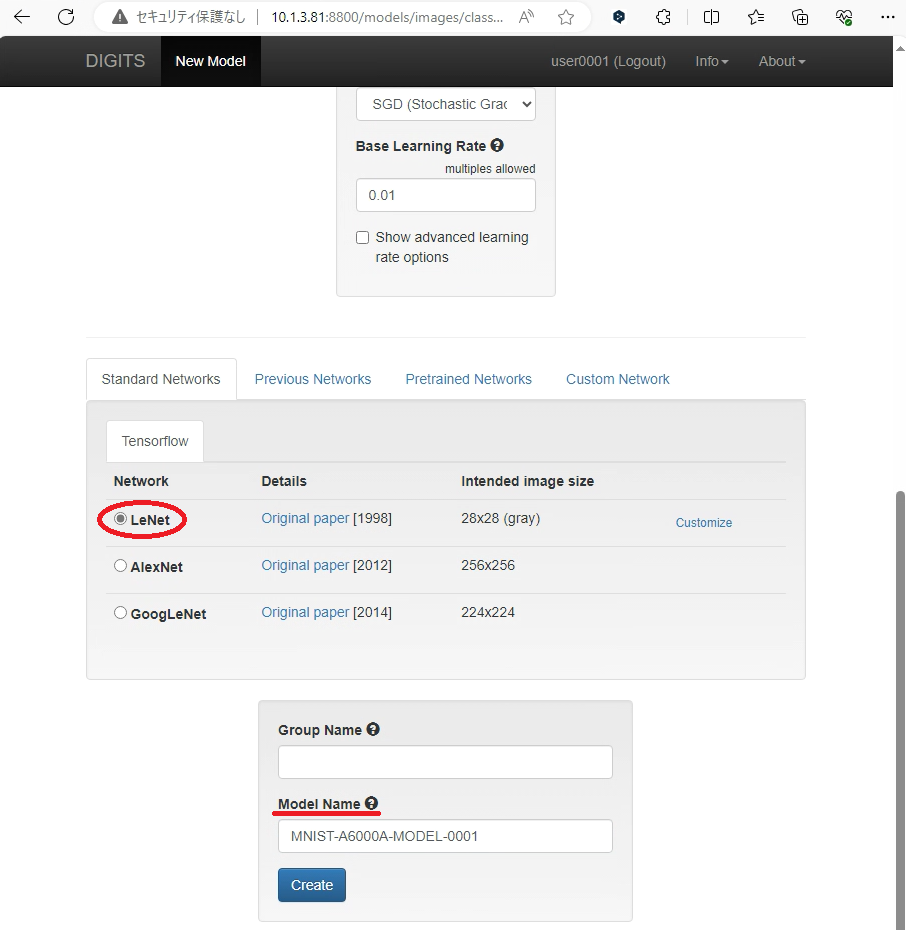
.4 Createボタン押下
Model Nameの下部にあるCreateボタン押下後、画面が遷移しジョブが開始されます。
遷移後の画面は自動的に更新されませんので、適宜画面を更新しジョブの進捗を確認してください。
学習中の画面例:
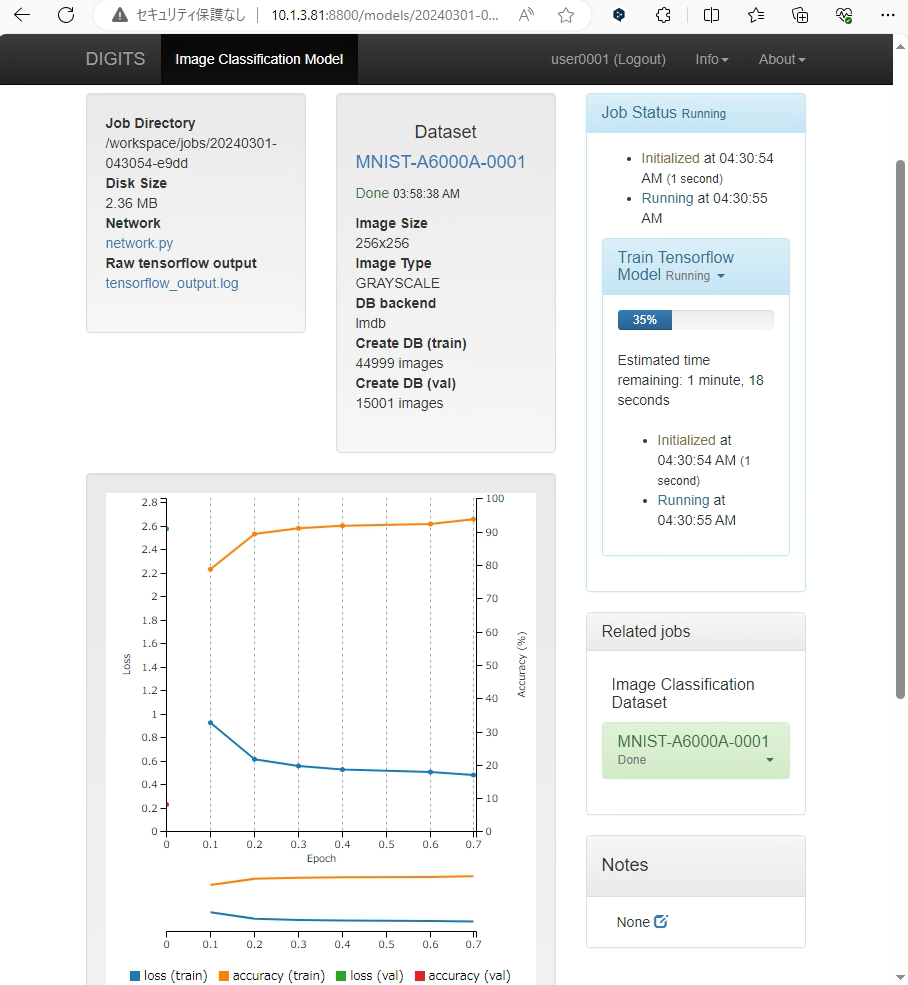
ジョブ完了後の画面表示内容:
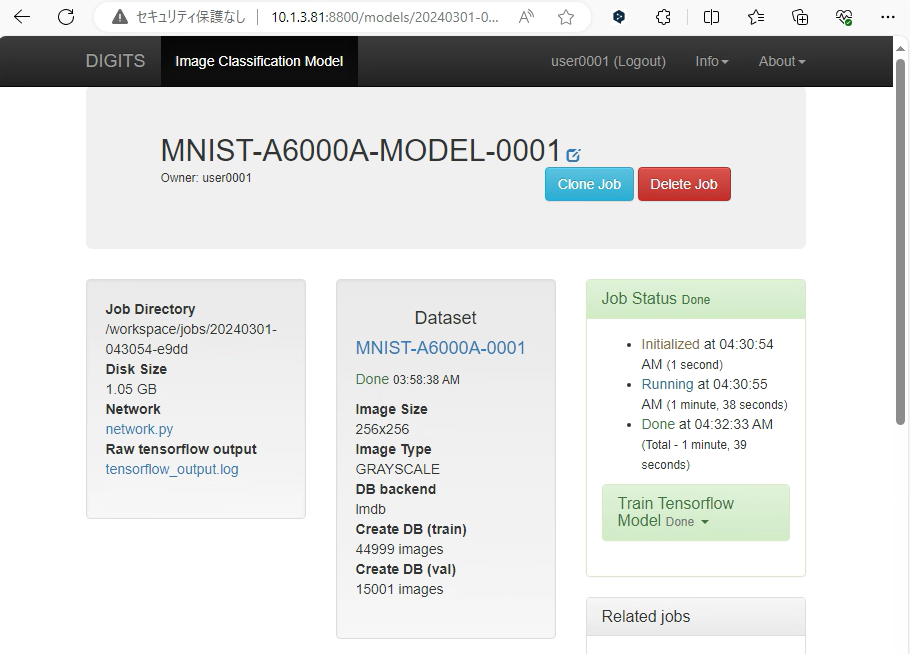
ジョブの完了後、画面左上の「DIGITS」を押下しWeb UIのトップページへ戻ります。
なお、本稿で用いているA6000 Adaの環境では、用意したMNISTデータセットの学習に1分39秒を要していました。
③作成したモデルを用いた画像認識のテスト
これまでに用意したデータセットとディープラーニングモデルを用い、実際に画像認識を試してみましょう。指定した画像をトレーニング済みのモデルで認識させ、その結果を確認します。
.1 モデルの選択
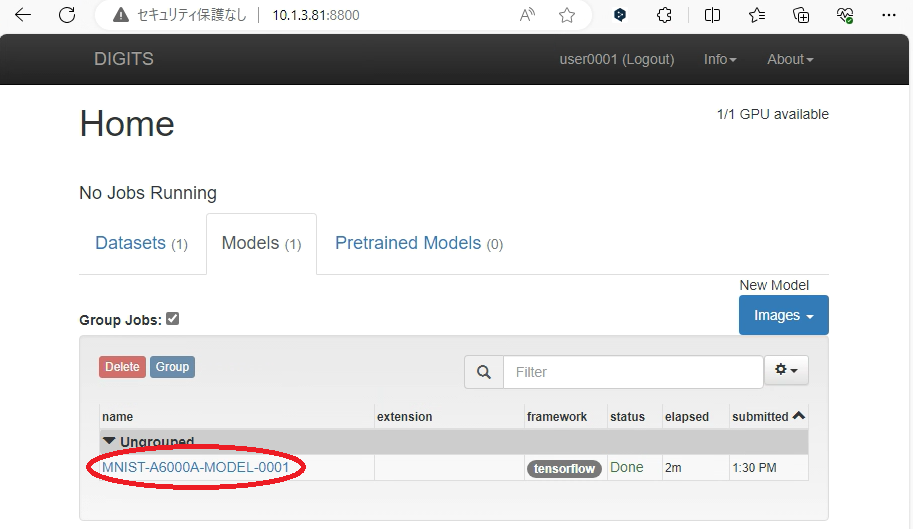
トップページのModelsタブ内、Ungroupedから先ほど作成したモデルを選択します。
.2 認識させる画像の指定
MNISTデータセットのテスト用PNG画像を用いていただいても、ご自身で28x28pxの画像をご用意いただいても構いません。
ここではテスト用PNG画像を認識させてみることとします。
Trained Models > Test a single image > image path:
DIGITSコンテナホスト上の画像データを認識に用いる場合、ファイルのフルパスを入力します。
Trained Models > Test a single image > Upload image:
Web UIを操作している端末上の画像を認識に用いる場合、こちらの項目でファイルを選択します。
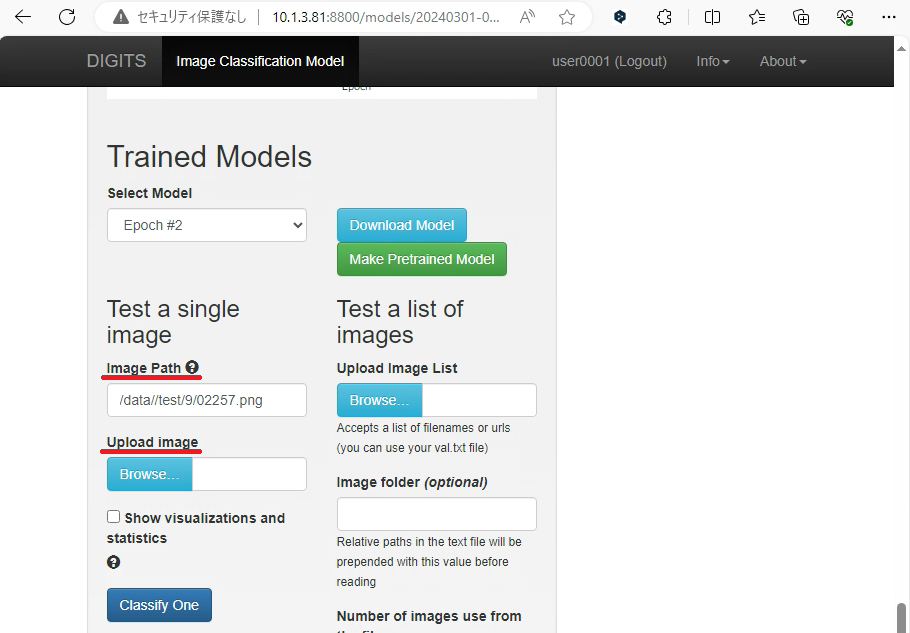
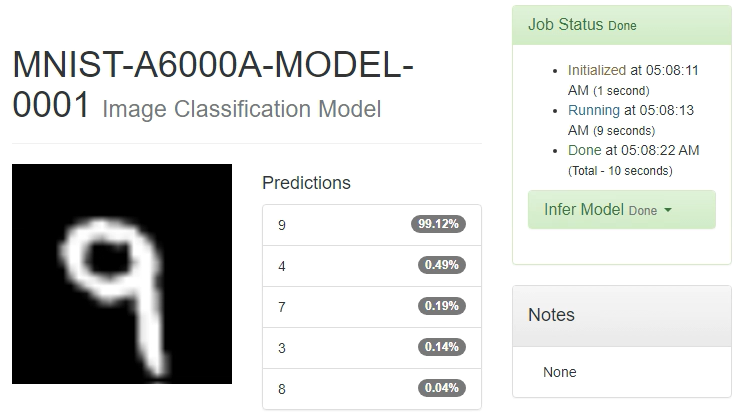
認識に用いる/data/test/9/02257.png:

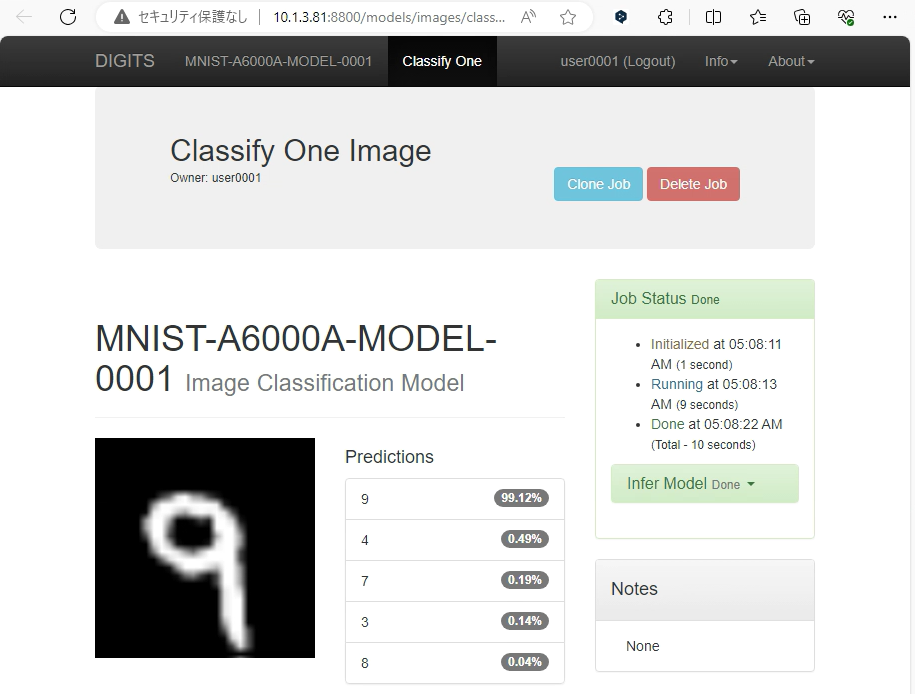
.3 Classify Oneボタン押下
ボタン押下後、認識結果が表示されます。
この例では数字の9である確率が99.12%であると表示されており、非常に良好な結果が得られたようです。
さいごに
本稿の内容はいかがでしたでしょうか。NGC並びにNGCカタログを活用することによって、いかに容易にディープラーニングを始めることができるかをご体験いただけたのではないかと思います。記事の中で取り上げたDIGITSはその取扱いの容易さから、非エンジニアの方へのデモやAI人材のオンボーディング・新人教育など様々な場面でご活用いただけるソフトウェアとなっております。NVIDIA GPU並びにDIGITSを皆様の業務でお役立ていただけますと幸いです。
また、本ブログでは引き続きNVIDIA GPUおよびその他製品についてご紹介してまいりますので、今後の記事にもぜひご期待ください。
"The MNIST database(Modified National Institute of Standards and Technology database)"
作成者: Yann LeCun, Corinna Cortes and Christopher J.C. Burges.
タイトル: THE MNIST DATABASE of handwritten digits
公開日: Nov, 1998
論文: Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, "Gradient-based learning applied to document recognition," in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
URL: http://yann.lecun.com/exdb/mnist/(2024年3月現在閲覧不可)
関連ページはこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。