こんにちは。SB C&Sの幸田です。
AI基盤で利用されるネットワークについてご紹介しているブログ連載、今回と次回はEthernetについてのご紹介でございます。
多くのエンジニアにとってなじみ深いEthernetですが、AI基盤において利用する際に用いられる要素技術についてご説明できればと思います。
また、EthernetがAI基盤の利用において直面している課題についてもご紹介しており、これは次回記事の「NVIDIAがそれをどのように解決しているか」のお話につながります。
EthernetはAI基盤のNorth-South, East-Westどちらにも採用される
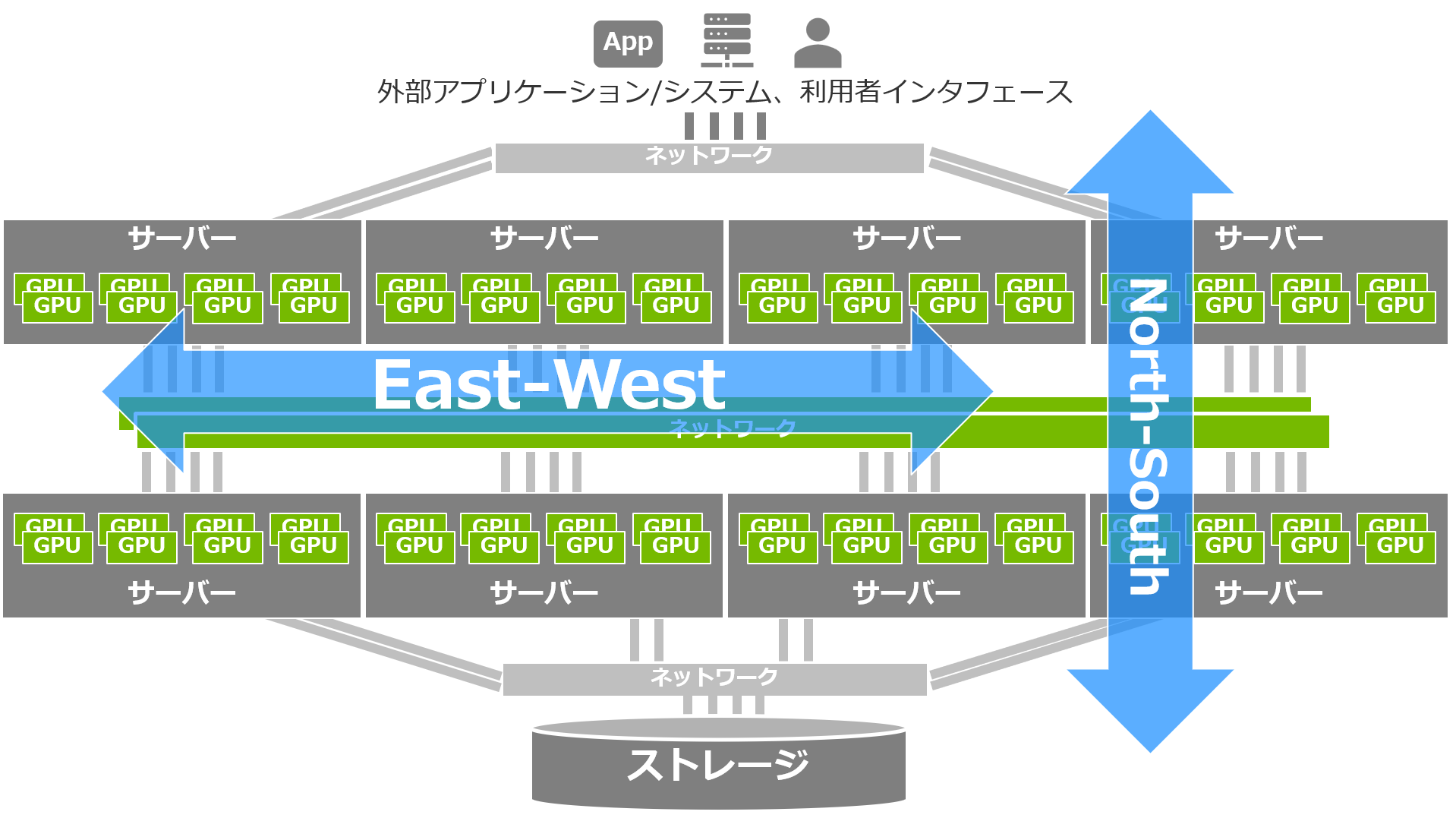
Ethernet は、AI基盤のNorth-Southネットワークにおいてはごく当たり前に利用されています。
ストレージとの接続や、アプリケーションやモデルなどを外部の保管場所 (例えばコンテナレジストリ等) から取得するためのネットワーク接続、そしてアプリケーションを利用者に公開したい場合のアクセス経路などは、既存のシステムとの接続性・親和性が保証されているEthernetを利用することで、低コストかつ安全に、利便性・接続性を維持してネットワークを構成することが可能であるといえます 。
注目すべきは East-West 大規模演算ネットワークでの採用が増加中
一方でEast-West、つまり複数ノードにまたがる大規模な演算の際のノード間(≒GPU間)通信ではどうかというと、こちらにも採用されるケースがこのところ一気に増加しています。
InfiniBandと比較すると既存のシステムとの親和性が高く、スキルを保有するエンジニアも多いうえ、純粋な通信速度の向上によってInfiniBandに勝るとも劣らない性能が実現されていることも大きな要因ですが、それ以外にも先端的な要素技術が取り入れられていることがその理由です。
特にNVIDIAが独自に実装しているテクノロジーは、スイッチからネットワークアダプタにかけて統合的にプロダクトを提供しているからこそ可能なもので、特に大規模環境においては業界をリードする高いシェアをもつソリューションを擁しています。
AI基盤のEast-West通信に利用されるEthernetの特長
以下、代表的なものをピックアップして、AI基盤のEast-West通信でのEthernet利用で用いられる要素技術をご紹介します。
RoCEによる低遅延・高速ネットワーク
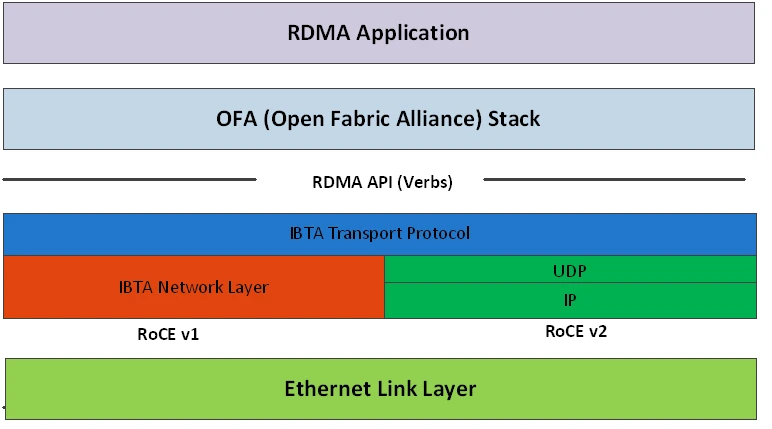
https://docs.nvidia.com/doca/sdk/rdma-over-converged-ethernet.pdf より
RoCE (RDMA over Converged Ethernet) は、AI基盤のEast-WestでEthernet通信を行ううえでの大前提ともいえる、最も中核的な要素技術です。
第2回の記事にてInfiniBandの特長として挙げた要素技術のひとつ RDMA (Remote Direct Memory Access) を、Ethernet上で実現するテクノロジーです。RDMAと同様に、OSとそのKernelを介さずメモリ間で直接データをやりとりすることができる機能です。なお一般に「ロッキー」と読まれます。
InfiniBand同様、GPUのメモリ内のデータにこのRDMAのテクノロジーを適用する GPUDirect によって、AI基盤の East-Westの通信を大幅に高速化することが可能です。
なお2025年7月時点では RoCE v1 と RoCE v2 があり、v1 はInfiniBandパケットをEthernetフレームで直接カプセル化している一方、v2 はInfiniBandパケットをUDPでカプセル化しているためIPルーティングが可能である、という違いがあります。
マルチテナント対応
AI基盤は、単一のユーザー(組織・企業などの利用主体)だけではなく、複数のユーザーに利用させるケースも多くあります。複数ユーザーの共同開発・検証基盤として利用するケースや、クラウドサービスとして提供するケース、あるいは単一の組織・企業内で利用するAI基盤を部署などの単位ごとに分割して利用する、いわゆるプライベートクラウドとしての利用ケースも存在します。
いずれの場合も、利用ユーザーごとにネットワークを論理的に分割する要件が出てくる可能性があります。具体的には、セキュリティの観点からユーザーごとにトラフィックを分離したいという要件や、それぞれのユーザーが一定の帯域幅を利用できるように "QoS" を設定せねばならないといった要件です。
ネットワークを論理的に分割するための代表的な、かつクラウド利用に十分な論理分割数の上限を持つテクノロジーとしてはVXLANがありますが、NVIDIAのEthernetスイッチおよびDPU(高性能・高機能NIC)はもちろんこれに対応しており、セキュリティ、QoSの要件を満たすネットワークを構成可能です。
暗号化
システムとネットワークのあらゆるポイントにセキュリティ対策を張り巡らすこと(ゼロトラスト)が一般的になっています 。特にAIに関連する通信は機微なデータを含みやすく、AI基盤のネットワークセキュリティ要件は今後さらに厳しくなっていくことも考えられます。
NVIDIAのEthernetでは、MACsec, VXLANsecといった、高速な通信と暗号の堅牢性(安全性)を両立できる低レイヤーの暗号化を含む標準規格をサポートしており、十分な性能を維持しながら安全性を確保することができるといえます。
RoCEに残る課題と、それを解決するNVIDIA Spectrum-X Ethernet (※次回紹介)
前述のとおり、RoCEはAI基盤のEast-West通信を行うための中核的な要素技術です。
実は単にこのRoCEを採用しただけでは、大規模なAIネットワークでの利用においていくつかの課題が残り、深刻なパフォーマンス低下の要因となり得てしまうのが昨今のAI基盤の実情です。
以下、本記事では、それらの課題の中で特に留意すべきものについて概要を記載しております。
そして次回の記事で、NVIDIAのプロダクトがこれらの問題へどのようにアプローチしているかについてご説明します。
帯域利用率の低下
Ethernetは元来、トラフィックの輻輳などによって発生するパケットの損失と、それをカバーするための再送が起こってしまうことを前提に設計されたプロトコルですが、RDMAではその仕様上、パケットの損失・再送は深刻なパフォーマンスの問題を招いてしまいます。
RoCEにおいて従来から利用されているECMP (Equal Cost Multi-Path) によって、トラフィックの輻輳をある程度回避し、パケットの損失・再送を避けることは従来から可能でした。
ですが昨今、生成AIをはじめとした新たなワークロードの登場によって、従来は発生し得なかった巨大なフロー(エレファントフロー)がみられるようになりました。
ECMPの仕組みではそれによって発生する特定の経路の輻輳を的確に分散することができないうえ、別の経路はほとんど使われていない状況が発生してしまうなど、ネットワークの利用効率を大幅に下げてしまうケースがみられていたのです。
パケットの到達順序の乱れ
パケットの「損失・再送」に加えて、RDMAの大敵となるのはパケットの「順序の乱れ(Out-of-Order, 略称OoO)・再送」です。AI基盤で頻繁に採用される多段でのSpine-Leaf構成のように、複数のパスをもつネットワークを経由してノード(GPU搭載サーバー)からノードへ送られるパケットは、通った経路の輻輳状況などの違いによって、送信された時とは異なる順序で宛先のノードに届いてしまうケースがあります。これも従来のRoCEネットワークにおいて再送を招くきっかけとなり、やはりRDMAのパフォーマンスに重大な影響を与えてしまうケースのひとつです。
以上、AI基盤のEthernetに求められる要件と、RoCEが直面する課題についてご紹介しました。
次回の第5回では、これらの課題を解決するためのソリューションである、NVIDIA Spectrum-X Ethernet についてご紹介します。
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
幸田 章 - Akira Koda -
NVIDIA製品を中心としたコンピューティング(グラフィックス, AI/HPC)とネットワーキング、VDI を含む仮想化、クラウド等のプリセールス・エンジニア業務に従事。
VMware vExpert 2015-2022