本記事では、GPUリソースの効率活用を可能にするエフサステクノロジーズ様の「PRIMERGY CDI (Composable Disaggregated Infrastructure、以下CDI)」について解説します。CDIのアーキテクチャや動的リソース割当の仕組み、従来のHCIやベアメタル構成との違いを整理し、AIワークロードに適した次世代インフラの要件を探ります。
目次
1.GPUが主役になる時代、インフラはどう変わる?
1.1 生成AIの波に乗るには「GPU前提」の設計が必須
2. CDIで広がる、これからのインフラ設計
2.1 CDIという新しいインフラアプローチと出会う
2.2 スケールも運用も"自動"でスマートに!
3. なぜ今、 CDIが求められるのか?
3.1 ベアメタルやHCI(Hyper Converged Infrastructure、以下HCI)では限界!? CDIが変える柔軟性
3.2 GPUの"ムダ使い"を防げ!
3.3 利用率もコストも、CDIが最適化する理由
4. 中身をのぞこう!CDIの仕組みと構成
4.1 ノードは分かれているのに、つながっている
5. 次回:実機でCDIをさわってみた(検証編)
- 実際にさわってみたら、驚きの連続!?
- CDI の使い心地をリアルに解説予定!
1. GPUが主役になる時代、インフラはどう変わる?
1.1 生成AIの波に乗るには「GPU前提」の設計が必須
生成AIは、膨大なデータを高速に処理・生成する能力を持ち、画像生成や自然言語処理、音声認識など、あらゆる分野に革新をもたらしています。これらの処理は、CPUでは到底対応しきれない計算量を必要とするため、高度な並列処理を得意とするGPUの活用が必須となっています。しかし、多くの企業では依然としてCPU中心のインフラ設計が主流であり、GPUを後付けで導入しているケースが少なくありません。これでは十分な性能を引き出すことができず、せっかくのAI投資が成果に結びつかないという事態にもなりかねません。生成AIの波に本格的に乗るためには、最初から「GPUありき」でインフラ全体を設計する発想が求められます。GPUの高密度実装やリソースの共有・再配置といった運用も視野に入れた「GPU前提のインフラ」の設計が必須です。
2. CDIで広がる、これからのインフラ設計
2.1 CDIという新しいインフラアプローチと出会う
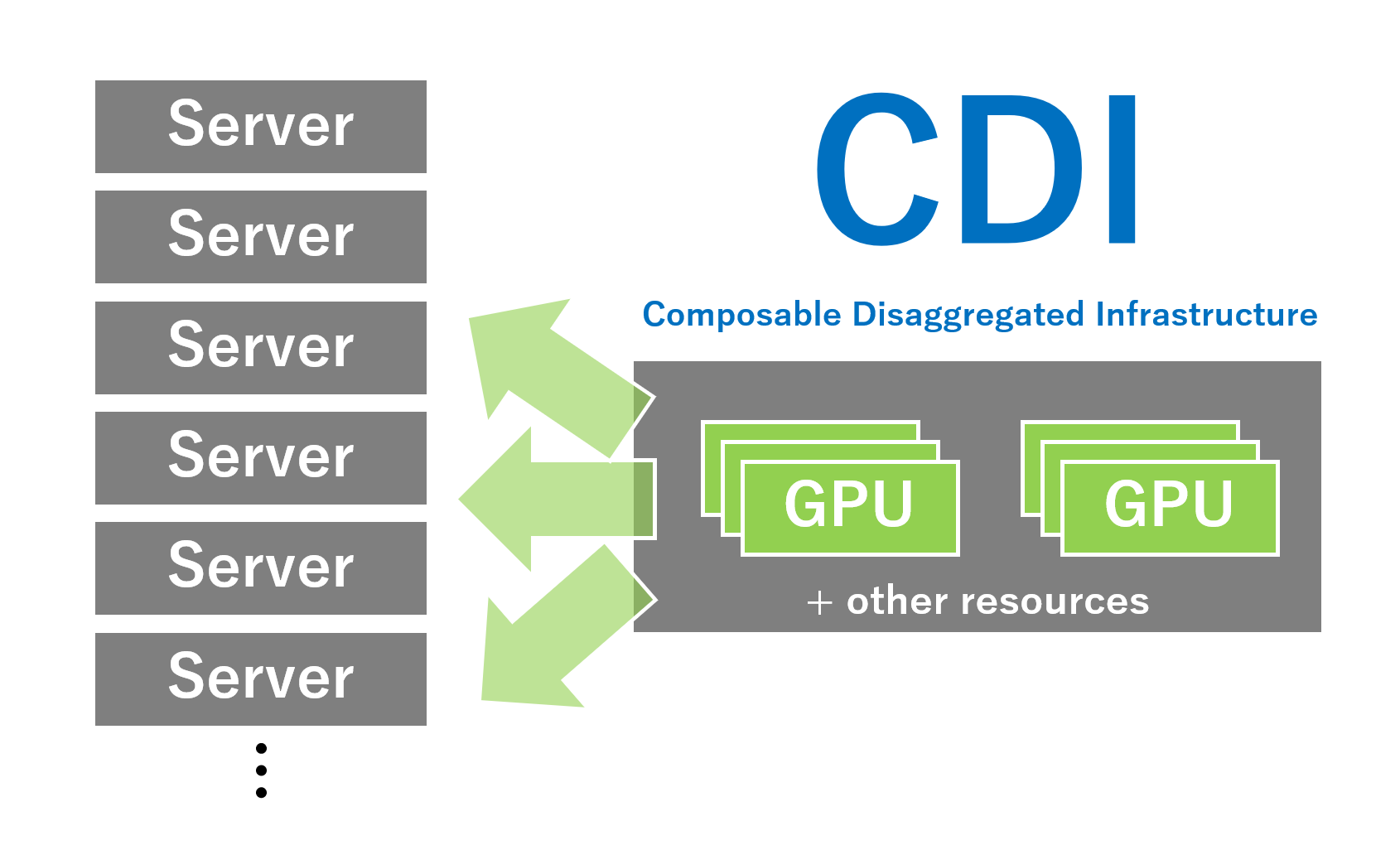
これまでのインフラ設計では、GPUは特定のサーバーに物理的に固定されるのが一般的でした。しかし、生成AIや深層学習など高度なAIワークロードに対応するためには、必要なときに必要なだけGPUリソースを使える柔軟性が求められます。CDIは、この課題を解決する新しいアプローチです。GPUを含む各種リソースをプール化し、ワークロードの内容や利用状況に応じて"必要なときに・必要な分だけ"動的に割り当てることが可能です。これにより、リソースの全体最適な活用が実現します。限られたGPU資源を最大限に活用でき、コスト効率の面でも大きなメリットがあります。さらに、複数のプロジェクト間でリソースを柔軟にシェアできるため、AI開発や実験のスピードを加速させ、組織全体のインフラ基盤として大きな力を発揮します。
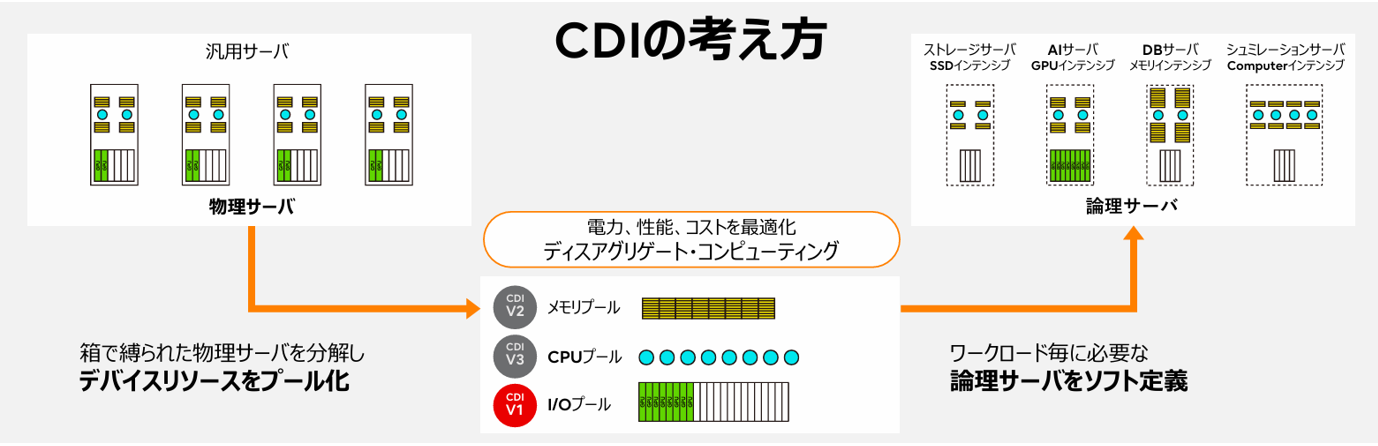
2.2 スケールも運用も"自動"でスマートに!
AIワークロードは急速に進化しており、それに追従するインフラにも高い柔軟性とスピードが求められます。従来のシステムでは、構成変更や拡張のたびに物理作業や複雑な設定が必要でしたが、CDIはその常識を覆します。CDIでは、CPU、GPU、ストレージ等といったリソースを分離して管理し、必要に応じて動的に構成を変更できます。停止時間を最小限に抑えたスケーリング、構成変更、監視による自動構成変更をソフトウェアで実現できるため、従来に比べて圧倒的に俊敏かつ効率的です。変化の激しいAI時代において、CDIは"動き続ける"インフラとして運用を支えます。
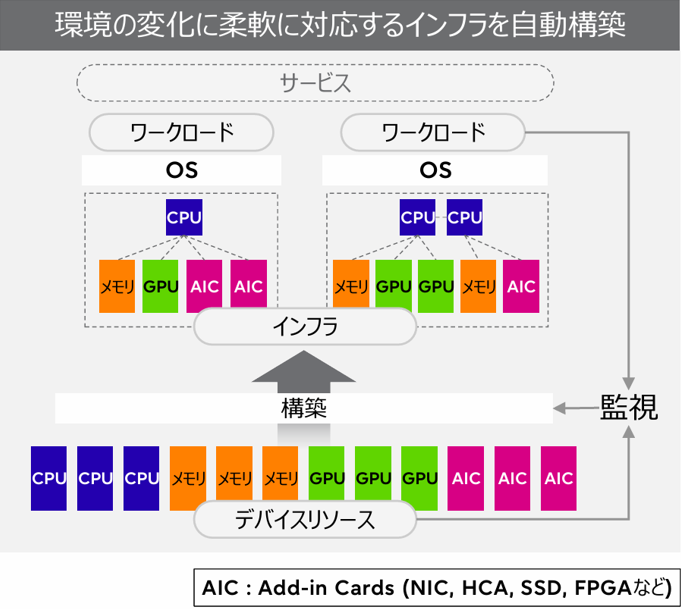
3. なぜ今、CDIが求められるのか?
3.1 ベアメタルやHCIでは限界!? CDIが変える柔軟性
従来のベアメタルサーバーやHCIは、高性能な環境を提供する一方で、構成が固定的で拡張や再構成に柔軟性が乏しく、AIのようなリソース変動の激しいワークロードには不向きな面があります。例えば、GPUを一部のベアメタルサーバーやHCIに固定してしまうと、使われない時間帯は遊休リソースとなります。CDIは、こうした課題を根本から解決します。CPUやGPU、ストレージ等といったハードウェアリソースを分離してプール化し、ニーズに応じて動的に構成可能なため、リソースの無駄を排除します。また、拡張もスムーズで、将来的な需要変化にも柔軟に対応可能です。ハードウェア投資の最適化と、迅速なサービス展開の両立を実現するインフラとして、CDIは次世代の標準となる可能性を秘めています。
3.2 GPUの"ムダ使い"を防げ!
生成AIや大規模言語モデル(LLM)の活用が進む中で、AIワークロードは常に一定というわけではありません。モデルの学習や推論処理において、GPUなどの計算リソースを一時的に大量に消費することがあり、その負荷はプロジェクトやフェーズごとに大きく変動します。しかし、従来のインフラではこうした変動に柔軟に対応することが難しく、「使っていないGPUが眠っている」「必要なときにGPUが足りない」といった状況が発生しがちです。こうした課題に対し、リソースを固定せず、ニーズに応じて柔軟に割り当て・再配置できる「動く」インフラを実装することで"ムダ使い"をなくし、最適利用が可能となります。
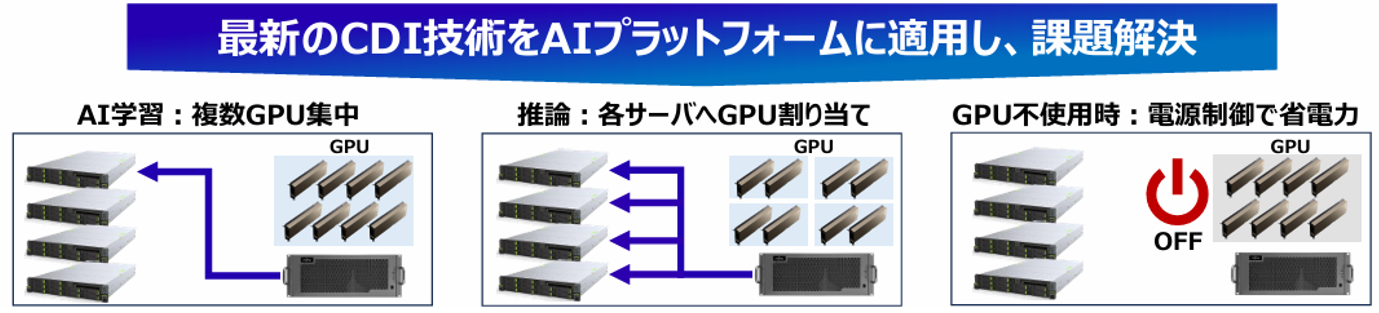
3.3 利用率もコストも、CDIが最適化する理由
AIサービスの種類やワークロードが増える一方で、「リソースの利用率が低くコストだけが膨らむ」、これは多くの現場で見られる課題です。従来のインフラでは、GPUやCPU、ストレージといったリソースがサーバー単位で固定されるため、「あるサーバーではGPUが余っているのに、別のサーバーでは足りない」といった非効率が発生します。 CDIは、この"固定のムダ"をなくします。ハードウェアのリソースをプール化し、ワークロードに応じて必要な分だけ柔軟に割り当てることで、リソースの稼働率を最大化します。遊休リソースを限りなくゼロに近づけ、TCO(総所有コスト)の最適化を実現します。さらに、将来の拡張時も必要なリソースだけを個別に追加できるため、初期投資も抑制可能です。CDIは、インフラの使い方そのものを変え、利用効率とコスト効率の両立を支える革新的な仕組みです。
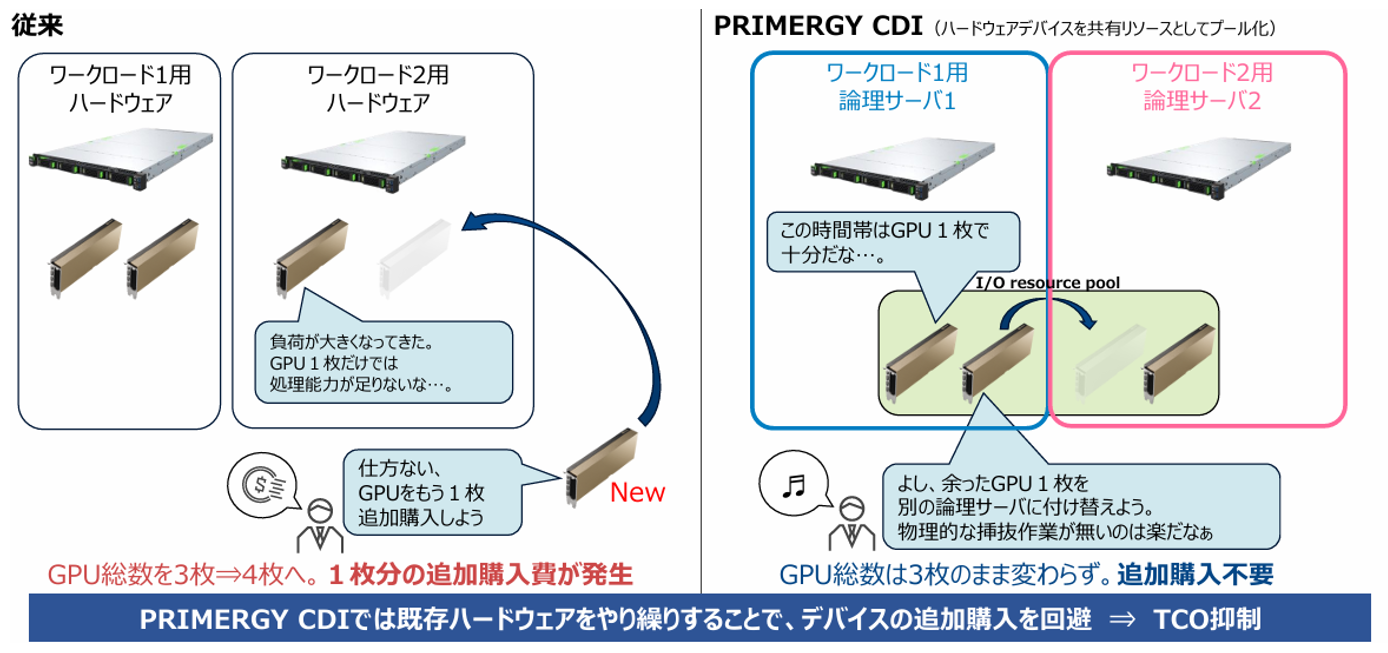
4. 中身をのぞこう! CDIのしくみと構成
4.1 ノードは分かれているのに、つながっている
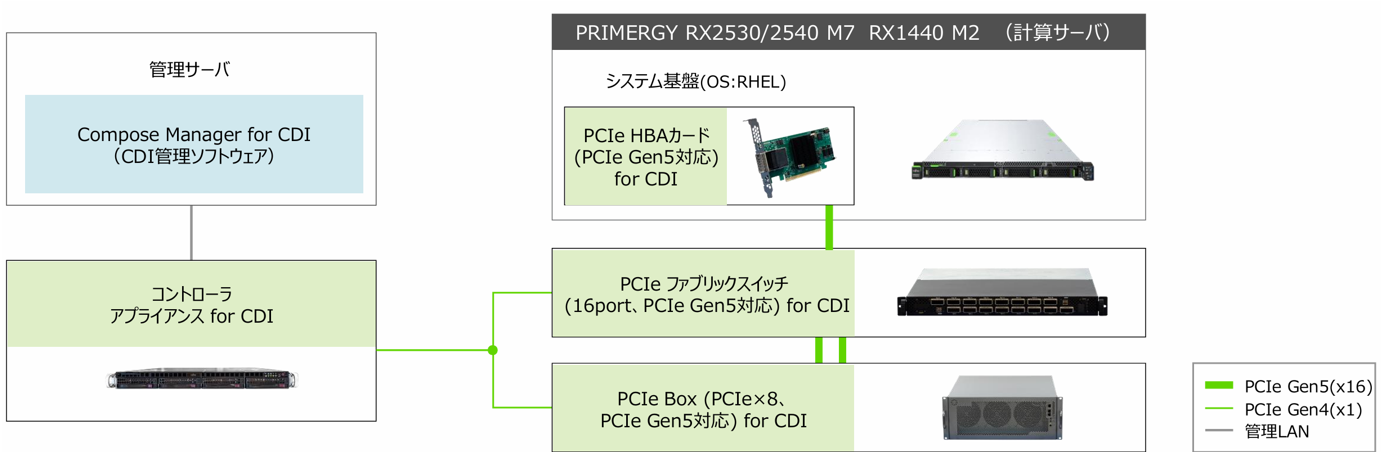
CDIのアーキテクチャは、計算ノード(サーバー)、PCIe Box(GPUやSSDなどのリソースを搭載)、PCIeファブリックスイッチ、コントローラアプライアンス(管理装置)と管理サーバーで構成されます。これらは物理的には分かれた装置ですが、PCIeファブリックで高速に接続され、コントローラアプライアンスを通じて論理的に連携します。たとえば、1台の計算ノードに対して複数のGPUを動的に割り当てたり、別のノードへ再構成したりといった操作が可能です。リソースは用途や負荷に応じて柔軟に組み替えられるため、インフラ全体として高い効率と拡張性を両立できます。このように、「分かれているが、連携している」構造が、CDIの柔軟な運用の土台となっています。
5. 次回:実機でCDIをさわってみた(検証編)
- 実際に触ってみたら、驚きの連続!?
- CDI の使い心地をリアルに解説予定
製品ページはこちら
著者紹介

SB C&S株式会社
C&S Engineer Voice運営事務局
最新の技術情報をお届けします!