


みなさんこんにちは。
AzureのAI関連サービスを利用したRAG(Retrieval Augmented Generation、取得拡張生成)の事例などで「Azure AI Search」というワードを耳にされたことはないでしょうか。 Azure OpenAI Serviceのような言語モデルをAPIで利用できるサービスについて学習した後、Azure AI Searchを利用したRAGに挑戦してみようと思われる方もいらっしゃるかもしれません。
Microsoft LearnでAzure AI Searchの概要が紹介されていますが、こちらには「インデックス」をはじめAzure AI Searchの機能に関するさまざまな語句が登場します。 Azure AI Searchについてこれから学習される方は、ドキュメントを読むよりも実物に触れて頂くほうがイメージを掴みやすいかもしれません。 本ブログ記事では、ごく簡単な例を用いながらAzure AI Searchを利用する様子をご紹介します。
Azure AI Searchの基礎的な機能
「さまざまな種別のデータを統合的に検索する」、「言葉の『意味』に基づいて検索する」といったシナリオでAzure AI Searchが登場するケースを目にされたことがあるかもしれません。
Azure StorageやAzure SQL Databaseなどに格納されているお客様独自のデータに対し、検索の機能を提供するのがAzure AI Searchです。 Azure AI SearchはAzure StorageやAzure SQL Databaseのようなデータソースからデータを取り込んでインデックスを作成します。 これによりユーザーやアプリケーションがインデックスを用いてデータを検索(クエリを実行)できるようになります。 Azure AI Searchを利用することにより、このような処理をオフロードできるというのも嬉しいポイントでしょう。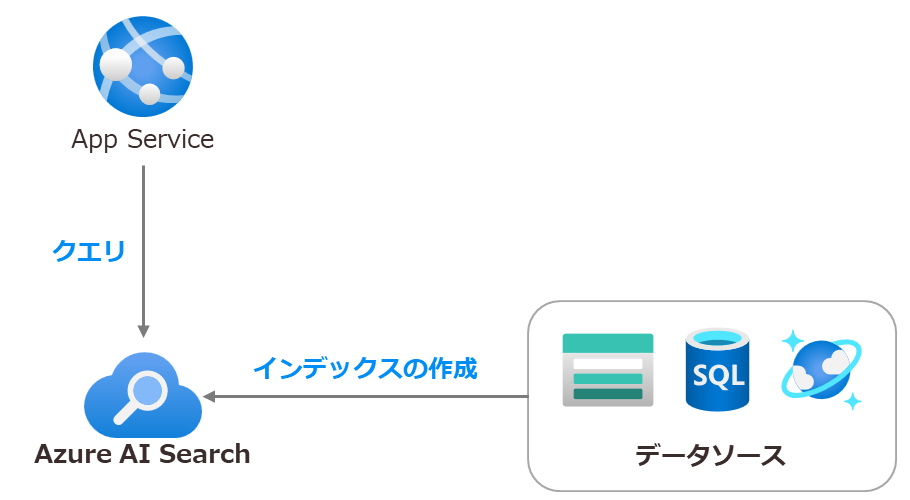
なおデータソースの例としてAzure StorageとAzure SQL Database を挙げましたが、Microsoft Learnに記載の通りAzure AI Searchはさまざまなデータソースに対応しています。
また、上図ではAzure App Serviceを掲載しておりますがこちらはあくまで一例です。 AzureにおけるアプリケーションのホスティングではAzure 仮想マシンなどさまざまなサービスを選択することが可能です。 Azure App Serviceの部分については適宜別のサービスに置き換えてお考え頂ければと思います。
動作確認用のデータ、データソース
今回は分かりやすいようにごく簡単なデータを利用します。 8種類のお手伝い券に関して、架空のアイテムIDと名称、説明を記述したCSVファイルを用意しました。 名称と説明は日本語で記述しています。 1行目はヘッダーです。 こちらをAzure StorageのBlobコンテナーにアップロードしました。
こちらをAzure StorageのBlobコンテナーにアップロードしました。 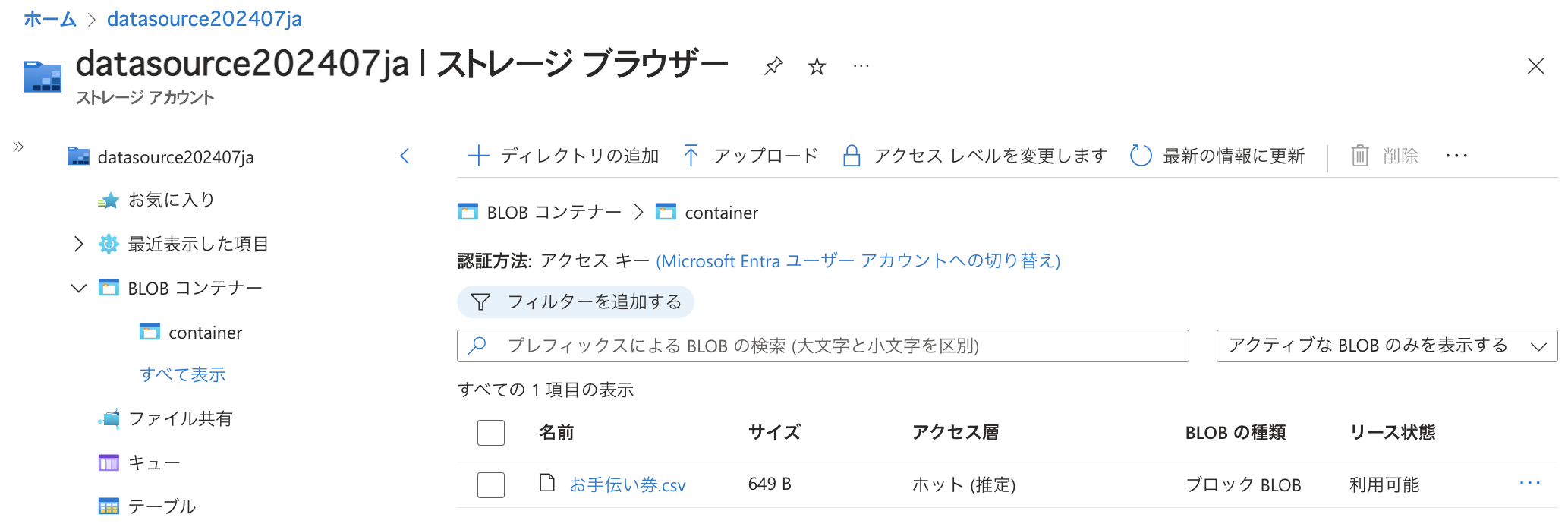
本ブログ記事ではAzure StorageのBlobコンテナーに格納されたCSVファイル対するインデックス作成をご紹介しますが、データソースの種別や格納されているデータの内容によって操作感など変わる部分がありますのでご留意ください。 また、CSVやJSONといったひとつのファイルで複数のアイテムに関するデータを扱うことができるデータ形式は「1対多のドキュメント」と呼ばれ、インデックスを作成する際に注意が必要です。(詳細は後述します。)
Azure AI Searchリソース作成
Azure PortalでAzure AI Searchリソースを作成します。 Azure AI Servicesの「AI Search」で「作成」をクリックします。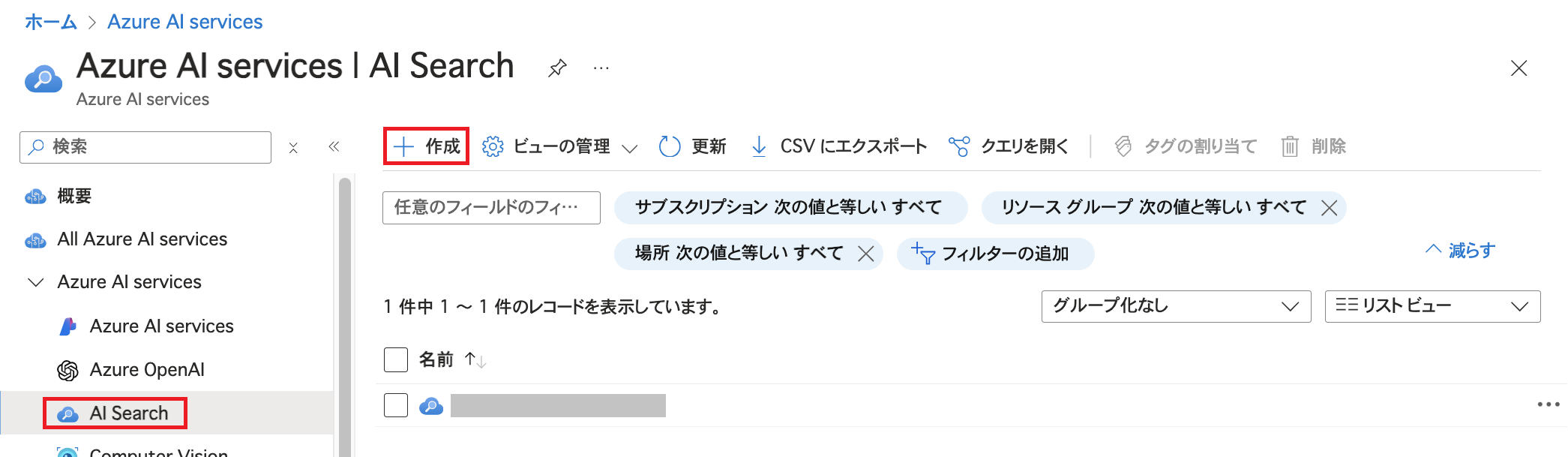
サービス名やリージョンなどを指定して「確認および作成」をクリックします。(今回はスケールやネットワークの設定はデフォルトのままにしています。)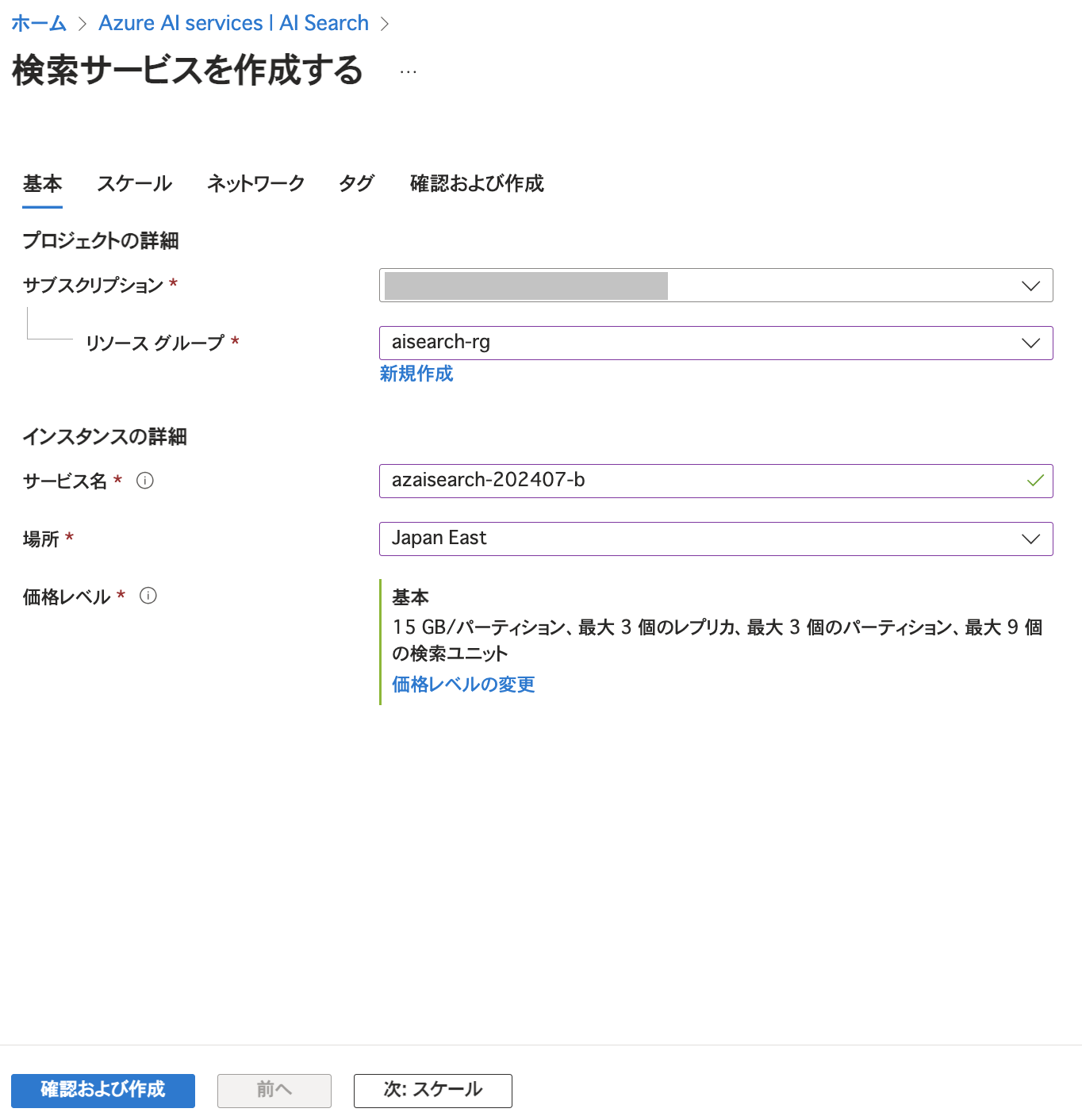 価格レベルについてはインデックス(後述します)などを考慮して指定します。 リソース作成後に価格レベルを変更することはできない点にご留意ください。 また、価格レベル「Free」もありますがFreeでは利用できない機能も存在します。 詳細についてはMicrosoft Learnをご参照ください。 今回はBasic(基本)を選択しています。
価格レベルについてはインデックス(後述します)などを考慮して指定します。 リソース作成後に価格レベルを変更することはできない点にご留意ください。 また、価格レベル「Free」もありますがFreeでは利用できない機能も存在します。 詳細についてはMicrosoft Learnをご参照ください。 今回はBasic(基本)を選択しています。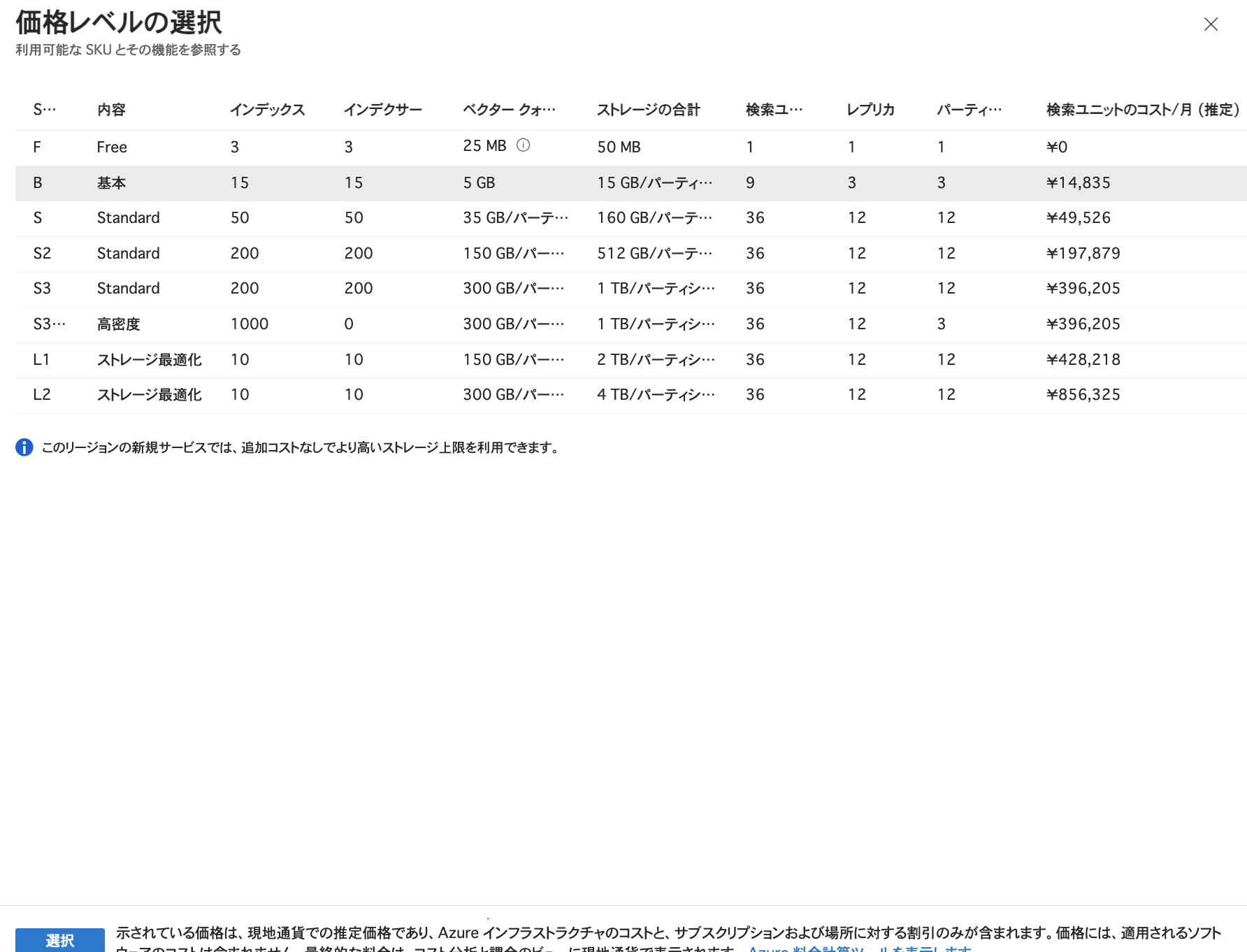
データのインポート・インデックス作成
データソースからインデックスを作成していきますが、その前に関連する語句を簡単に確認しておきましょう。 Azure AI Searchではデータソース上のデータを「インデクサー」により「インデックス」(Microsoft Learnでは「検索インデックス」と表記されている場合があります)の中に整理して保持し、クエリはインデックス内のデータに対して実行されます。 このためデータソース側でデータの更新がありそれを反映させたい場合はインデクサーを再実行します。 インデクサーの実行は1度のみにすることも可能ですし、スケジュールに従って実行させるということも可能です。 なお、インデックスの中ではデータを「ドキュメント」という単位で扱います。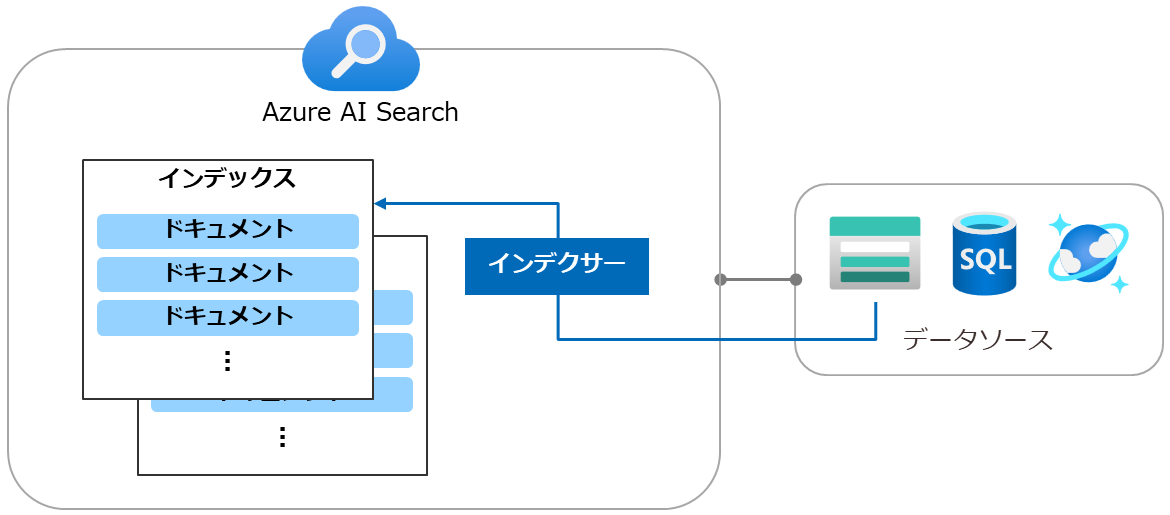
ここではAzure AI SearchにAzure Storageのデータをインポートしインデックスを作成します。 Azure AI Searchの「概要」画面にある「データのインポート」をクリックします。
この画面ではインポートするデータの在り処や解析モードなど指定します。 ここでは解析モードを「区切りテキスト」としています。 さらにCSVファイルの内容に合わせて、「最初の行にヘッダーが含まれています」にチェックを入れています。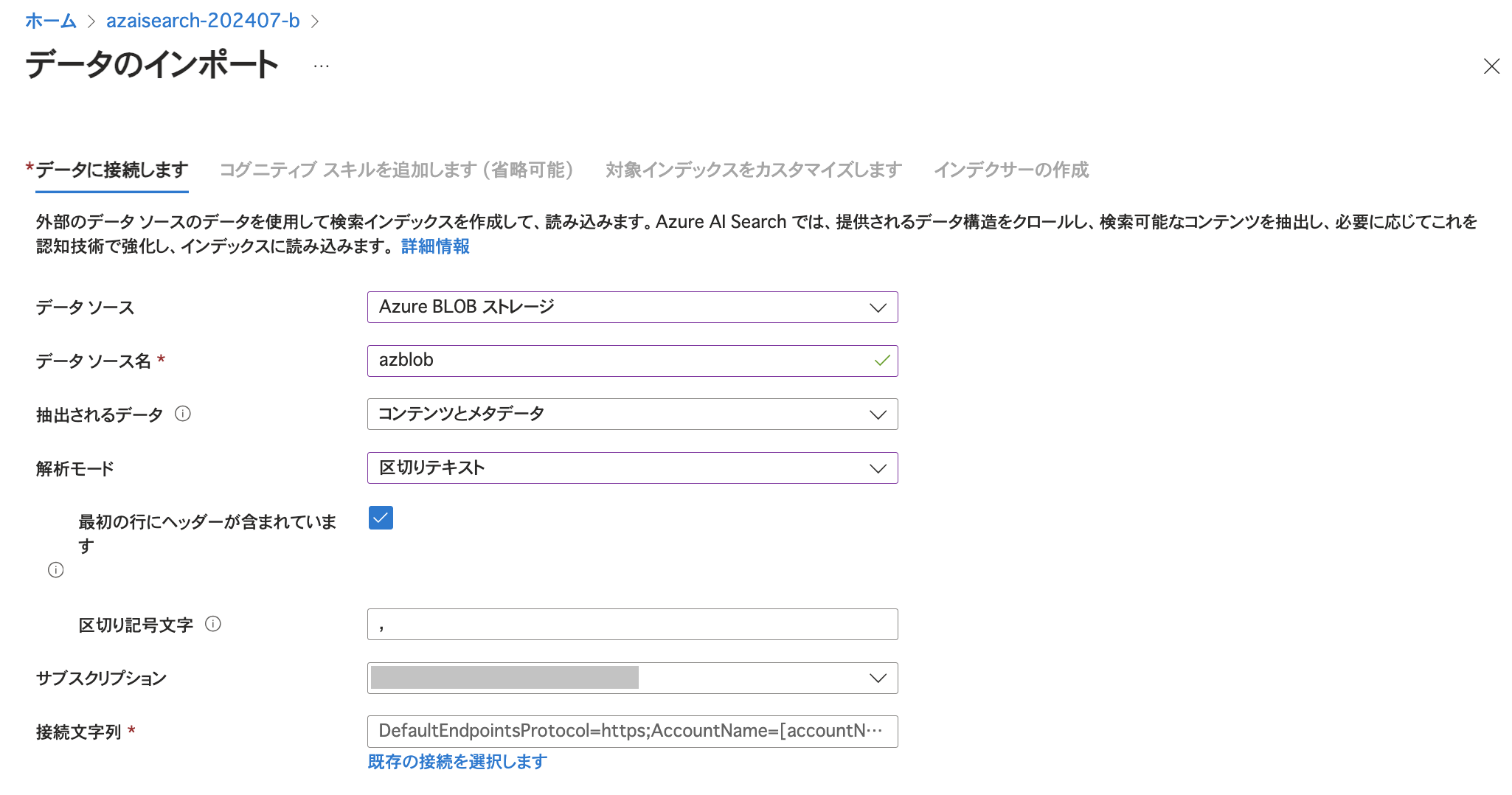
今回検索対象とするデータは先述の通り 「1対多のドキュメント」でありCSV形式です。 既定では、あるBlob / ファイルのコンテンツは単一のドキュメントとして扱われてしまいます(下図例1)。 ここではCSVの各行を別個のドキュメントとして扱いたいため(例2)、このような設定にしています。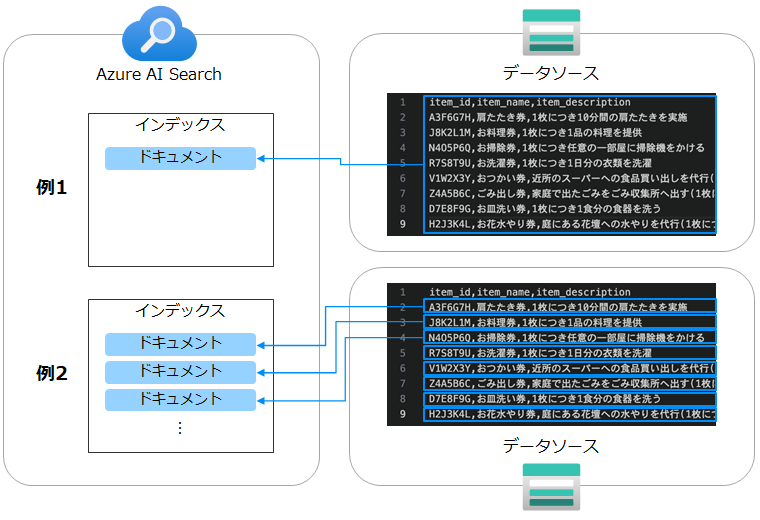
Azure Storageへの接続のため「既存の接続を選択します」をクリックします。
コンテナーを選び「選択」をクリックします。
「次:コグニティブスキルを追加します」をクリックします。
今回はコグニティブスキルの追加は行わずに「スキップ先: 対象インデックスをカスタマイズします」をクリックします。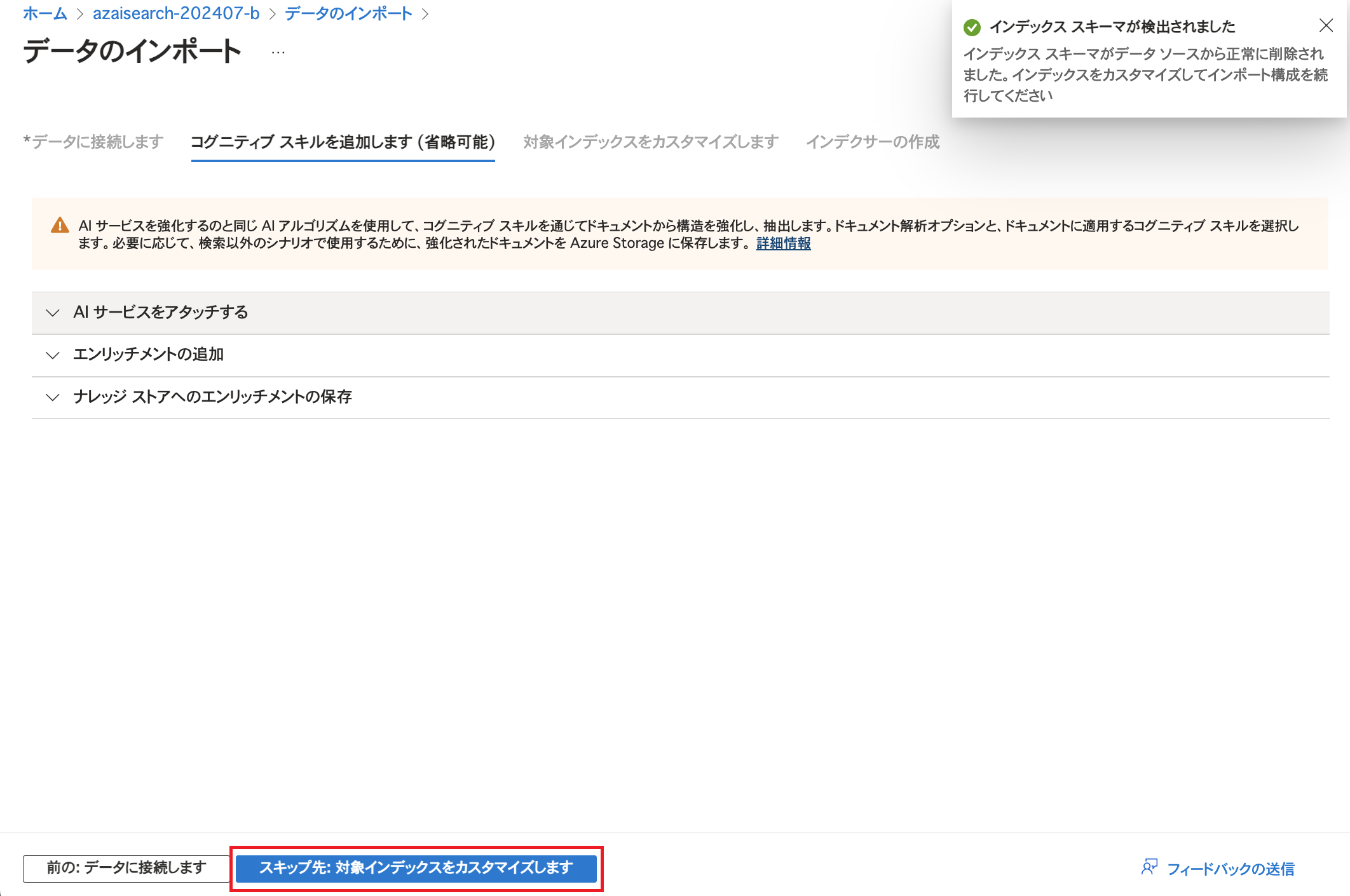 最初の3行のフィールドの名称はCSVファイルのヘッダーです。 それぞれ「取得可能」「検索可能」にチェックを入れています。 「検索可能」にチェックを入れるとそのフィールドに対して検索を行うことができるようになり、「取得可能」にチェックを入れると検索結果に当該フィールドのデータが表示されるようになります。(その他の項目についてはこちらをご参照ください。) 今回はアイテムのID / 名称 / 説明で検索できるようにし、検索結果にアイテムのID / 名称 / 説明をそれぞれ表示できるよう、このような設定にしています。 また、型(データ型)が「Edm.String」かつ「検索可能」にチェックが入っていると「アナライザー」を選択できるようになります。 ここでは日本語で記述されているフィールドのアナライザーを日本語対応のものに変更しています。(データ型やアナライザーについては詳細を後述します。)
最初の3行のフィールドの名称はCSVファイルのヘッダーです。 それぞれ「取得可能」「検索可能」にチェックを入れています。 「検索可能」にチェックを入れるとそのフィールドに対して検索を行うことができるようになり、「取得可能」にチェックを入れると検索結果に当該フィールドのデータが表示されるようになります。(その他の項目についてはこちらをご参照ください。) 今回はアイテムのID / 名称 / 説明で検索できるようにし、検索結果にアイテムのID / 名称 / 説明をそれぞれ表示できるよう、このような設定にしています。 また、型(データ型)が「Edm.String」かつ「検索可能」にチェックが入っていると「アナライザー」を選択できるようになります。 ここでは日本語で記述されているフィールドのアナライザーを日本語対応のものに変更しています。(データ型やアナライザーについては詳細を後述します。) 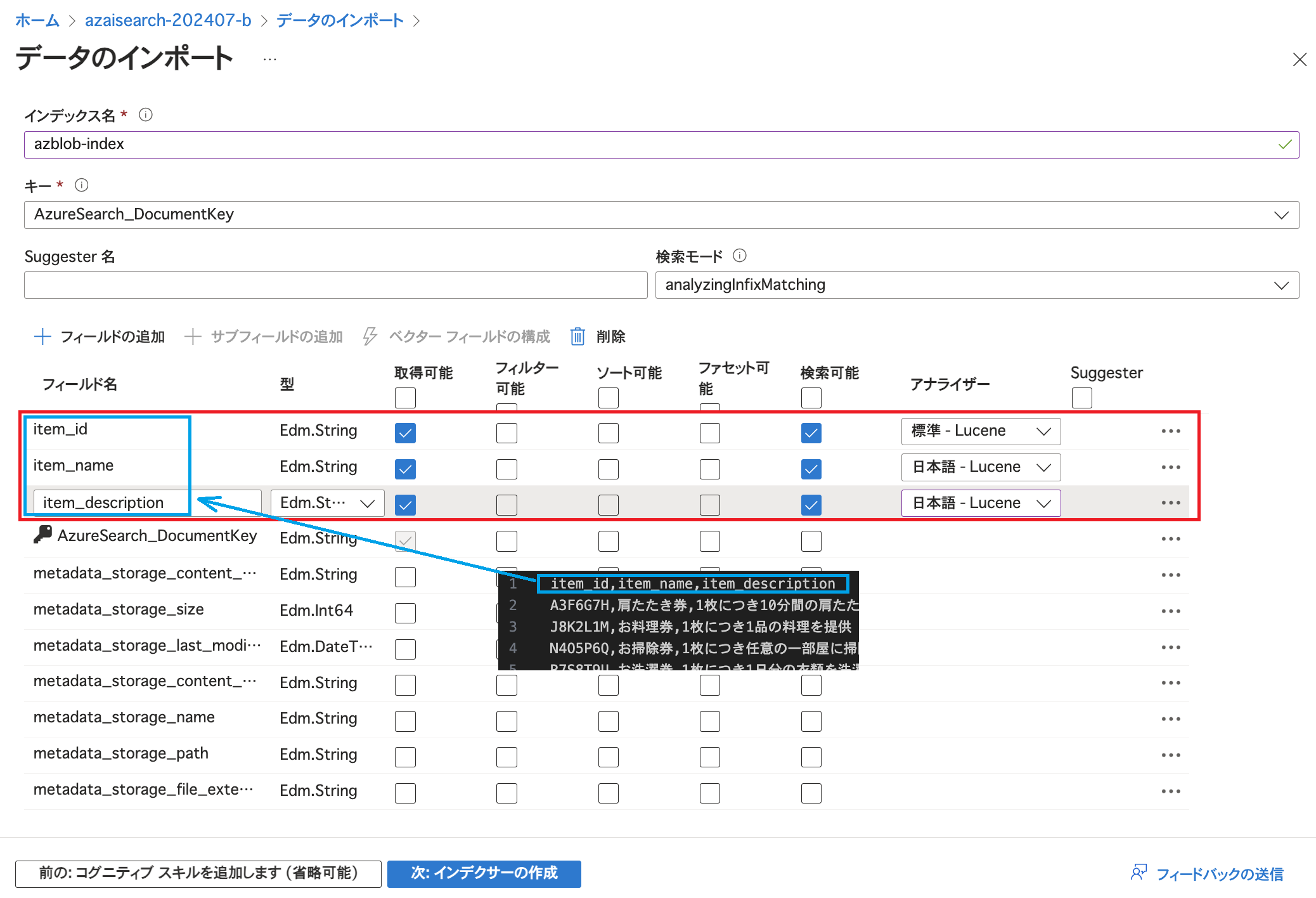 また、「AzureSearch_DocumentKey」というフィールドがあり「キー」として指定されています。 これはBlobに対して解析モードを「区切りテキスト」としたために、Azure AI Searchにより個々のエンティティに対して識別のためにドキュメントキーが生成されたものです。(この仕様についてはMicrosoft Learnにも記載がございます。)
また、「AzureSearch_DocumentKey」というフィールドがあり「キー」として指定されています。 これはBlobに対して解析モードを「区切りテキスト」としたために、Azure AI Searchにより個々のエンティティに対して識別のためにドキュメントキーが生成されたものです。(この仕様についてはMicrosoft Learnにも記載がございます。)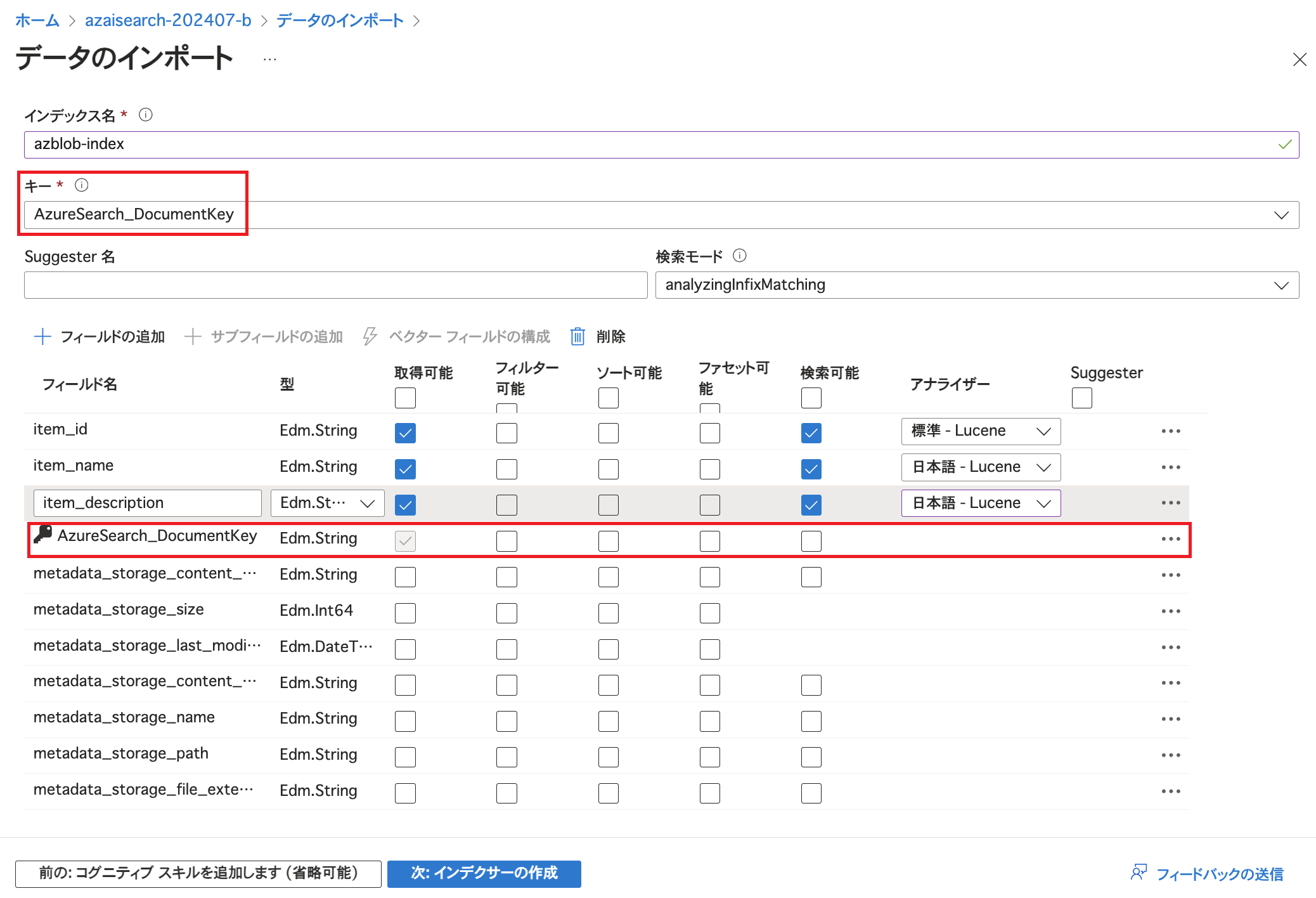
「次: インデクサーの作成」をクリックします。
この画面ではインデクサーが実行される(インデックスを作成する)タイミングを指定できます。 今回はBlobの更新予定がないためスケジュールを「1度」としていますが、定期実行させるように設定することも可能です。 「送信」をクリックするとインデクサーが実行されます。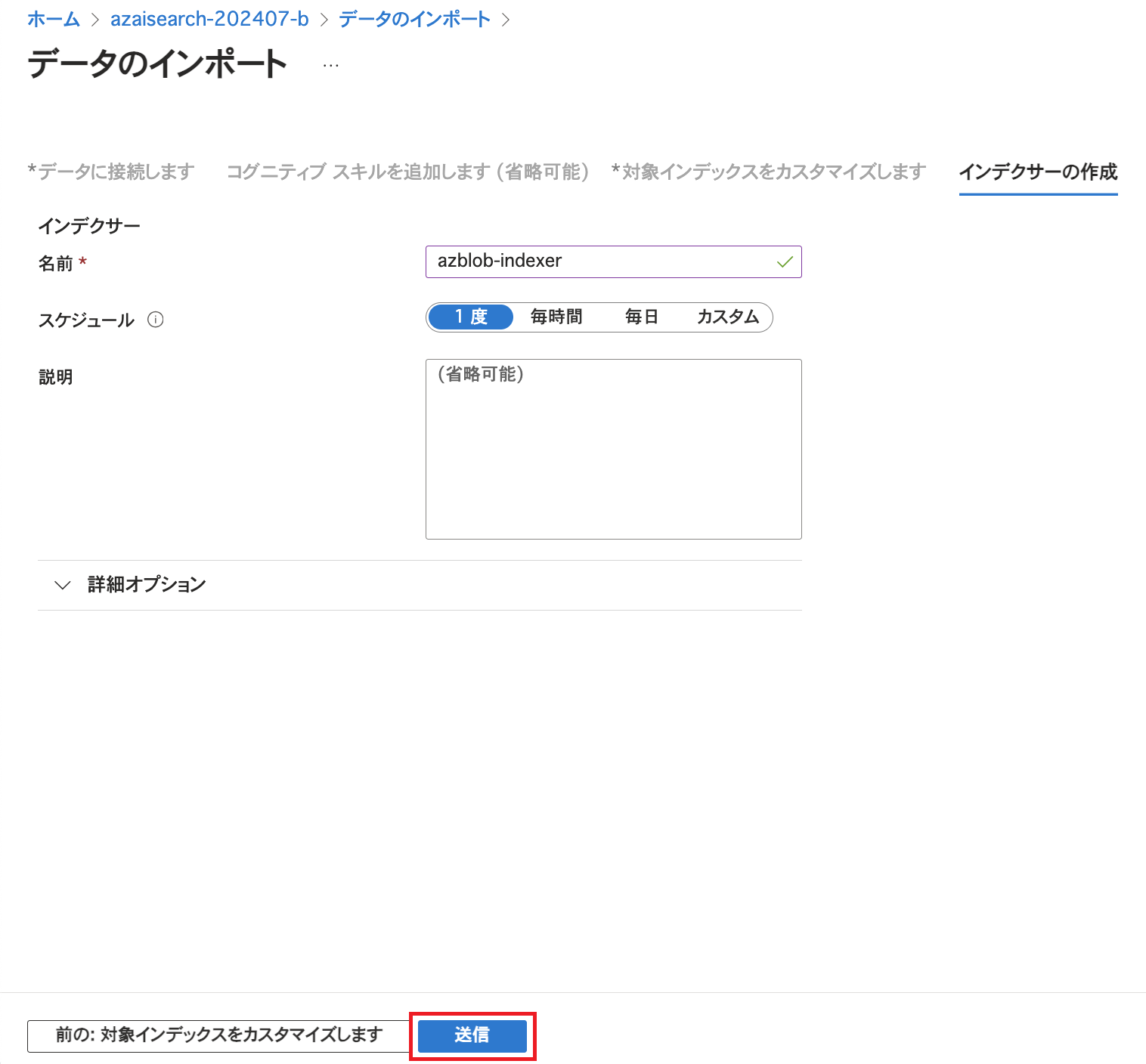 インデクサーの画面で実行状況を確認することが可能です。
インデクサーの画面で実行状況を確認することが可能です。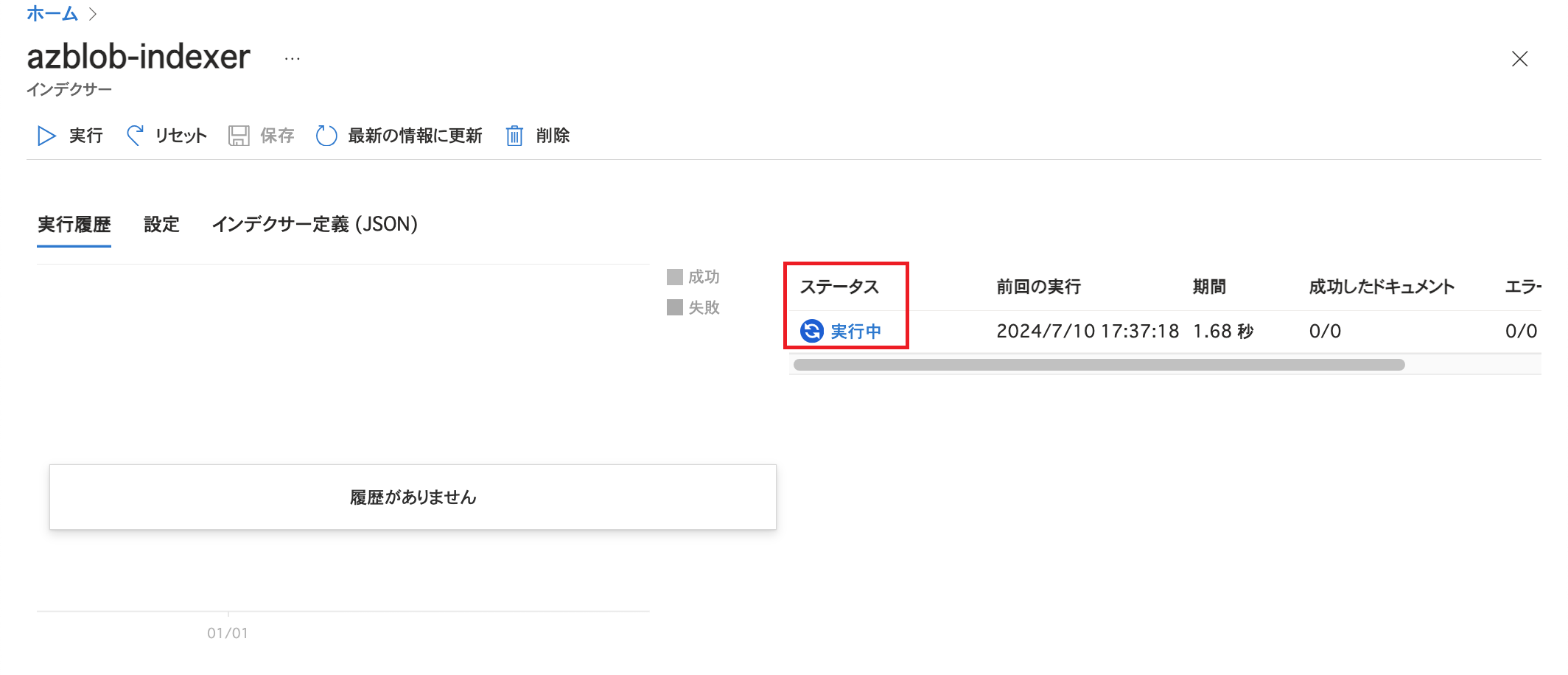 インデクサーの実行が完了すると以下のような画面になります。 ステータスが「成功」になっていることを確認します。 また、今回利用したCSVファイルは1点のみですが、「成功したドキュメント」の数が8になっています。 これはインポートしたCSVファイルに8つのアイテムの情報が記載されており、これを解析モード「区切りテキスト」としてインデクサーを実行したためです。
インデクサーの実行が完了すると以下のような画面になります。 ステータスが「成功」になっていることを確認します。 また、今回利用したCSVファイルは1点のみですが、「成功したドキュメント」の数が8になっています。 これはインポートしたCSVファイルに8つのアイテムの情報が記載されており、これを解析モード「区切りテキスト」としてインデクサーを実行したためです。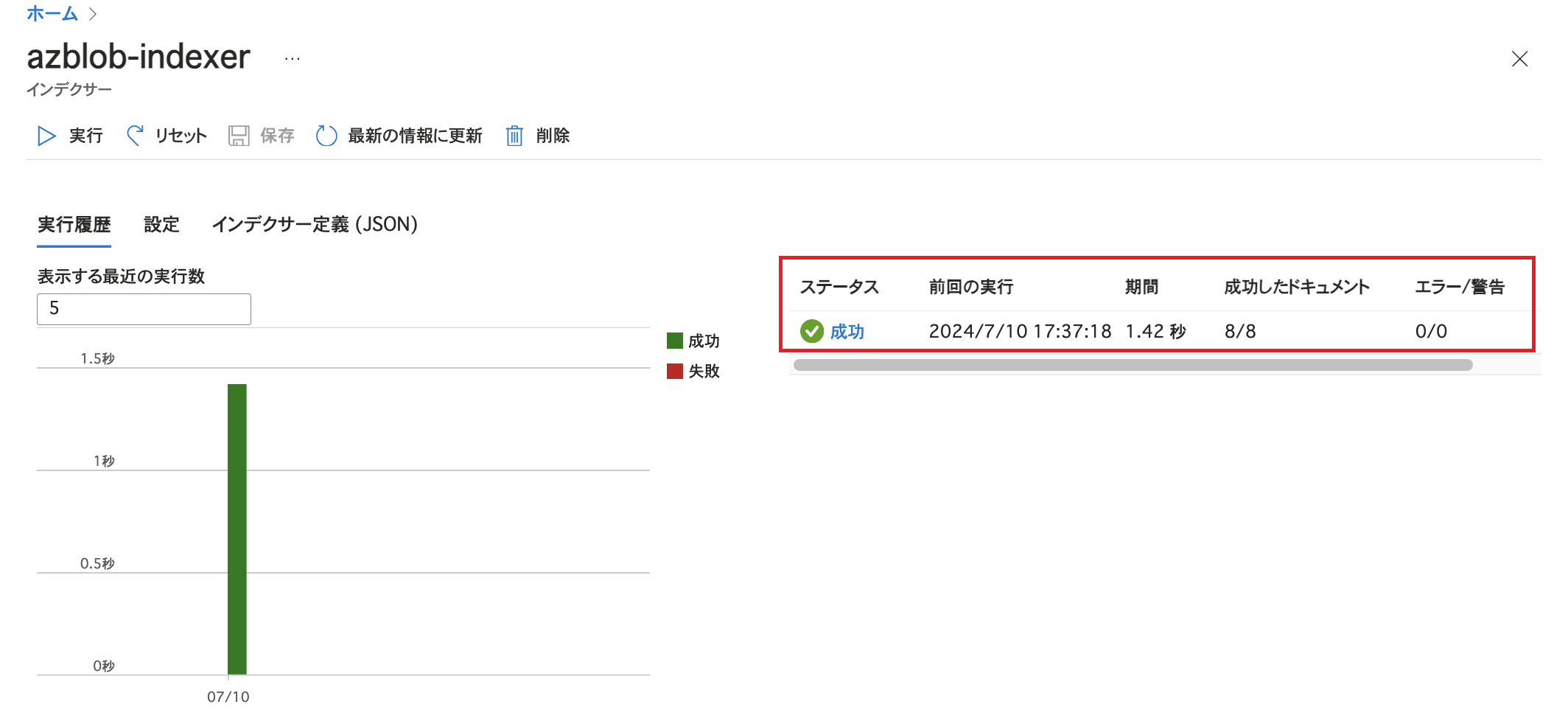
「型(データ型)」に関する補足
今回使用したCSVファイルの各フィールドは文字列のデータですが、数値やブール値(trueまたはfalse)など文字列以外のデータを扱いたいといった場合もあるでしょう。 そのような場合は扱うデータに合わせて型(データ型)を指定します。 例えば浮動小数点数を扱う場合は「Edm.Double」、ブール値を扱う場合は「Edm.Boolean」といったようにデータ型を指定することが可能です。 今回インポートしたデータにおいては「item_」で始まる各フィールドで文字列が扱われるため、データ型を「Edm.String」にしていました。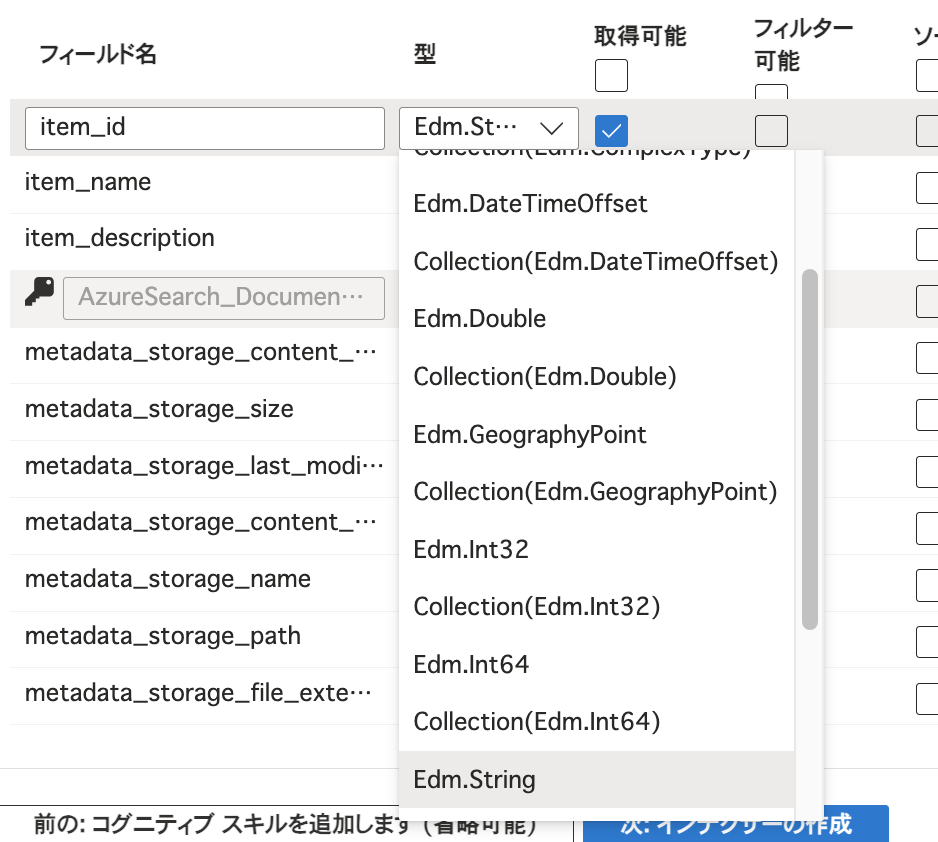
データ型についてはMicrosoft Learnにまとめられています。
「アナライザー」に関する補足
データ型が「Edm.String」かつ「検索可能」にチェックを入れたものについては「アナライザー」を指定できるようになります。 アナライザーは単語の分割や原形にする(時制表現による影響を受けないようにする)といった処理を行い、データを検索しやすいように分析します。 アナライザーには複数の種類があり、既定では「標準 - Lucene」が設定されます。
今回利用したCSVファイルでは、アイテムの名称と説明を日本語で記述していました。 日本語の言語的な特性を考慮した分析を行ってほしい場合は、日本語に対応した言語アナライザーを利用することが可能です。 日本語の言語アナライザーには「Lucene」と「Microsoft」の2種類があります。 両者には機能やインデックス作成所要時間などの違いがありますので、こちらも併せてご参照ください。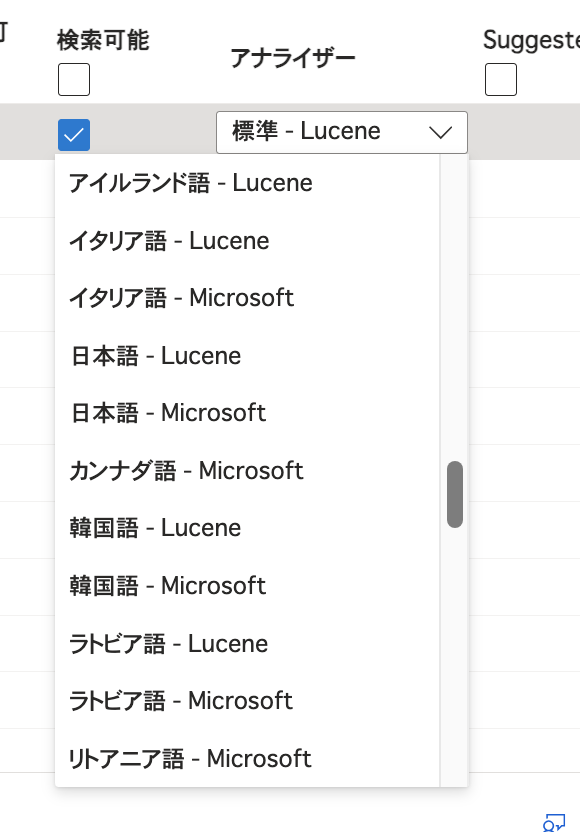
要件を満たすアナライザーが見つからない場合にはカスタムアナライザーを作成することも可能です。
なお、ここではインデックス作成におけるアナライザーについてご説明しましたが、アナライザーはクエリの際にも検索語の分析で利用されます。(クエリの種類によってはアナライザーによる分析が行われないこともあります。)
フルテキスト検索
インデックスの作成が完了しましたので、検索が可能かどうか試してみます。 今回はテキストに一致する情報があるかを検索する「フルテキスト検索」を行います。 検索を行う方法としてはAzure SDKやREST APIを利用することも可能ですし、Azure Portalで「検索エクスプローラー」を利用するという方法もございます。 今回は検索エクスプローラーを利用します。  「*」で検索すると全件表示されます。(「結果」にJSON形式でデータが表示されます。) フルテキスト検索では検索結果の関連性を「BM25」というアルゴリズムによりスコア付け / ランク付けし、その値が「@search.score」として表示されています。 値が高いほど関連性が高いことを示します。 以下の例では@search.scoreが全て1になっていますが、これはスコア付け / ランク付けをしていないということを示します。ワイルドカードで検索を行うとスコア付け / ランク付けが行われないためこのようになっています。
「*」で検索すると全件表示されます。(「結果」にJSON形式でデータが表示されます。) フルテキスト検索では検索結果の関連性を「BM25」というアルゴリズムによりスコア付け / ランク付けし、その値が「@search.score」として表示されています。 値が高いほど関連性が高いことを示します。 以下の例では@search.scoreが全て1になっていますが、これはスコア付け / ランク付けをしていないということを示します。ワイルドカードで検索を行うとスコア付け / ランク付けが行われないためこのようになっています。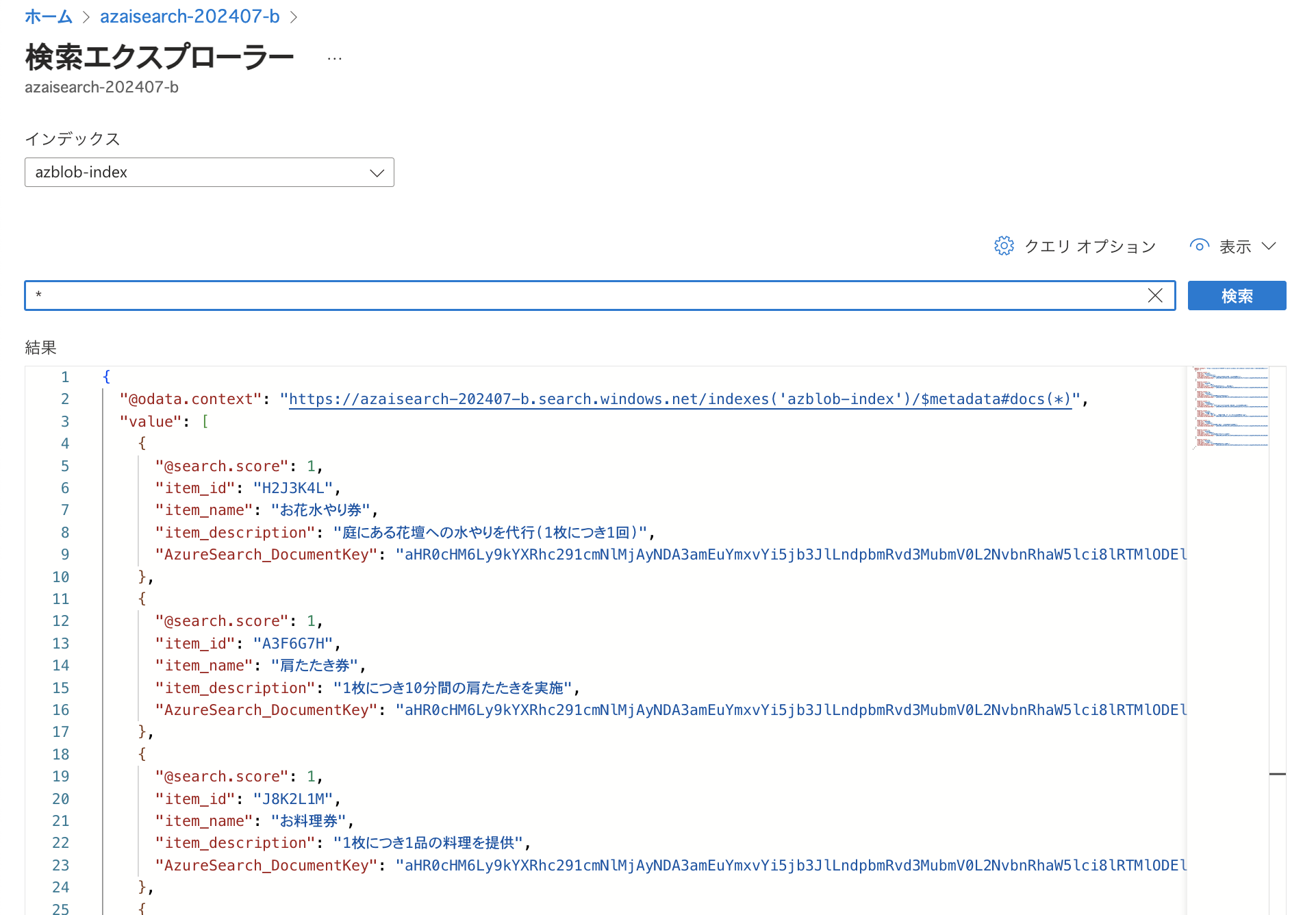
例として料理に関して検索した結果が以下です。 こちらの例では関連性のスコアリング / ランク付けが行われています。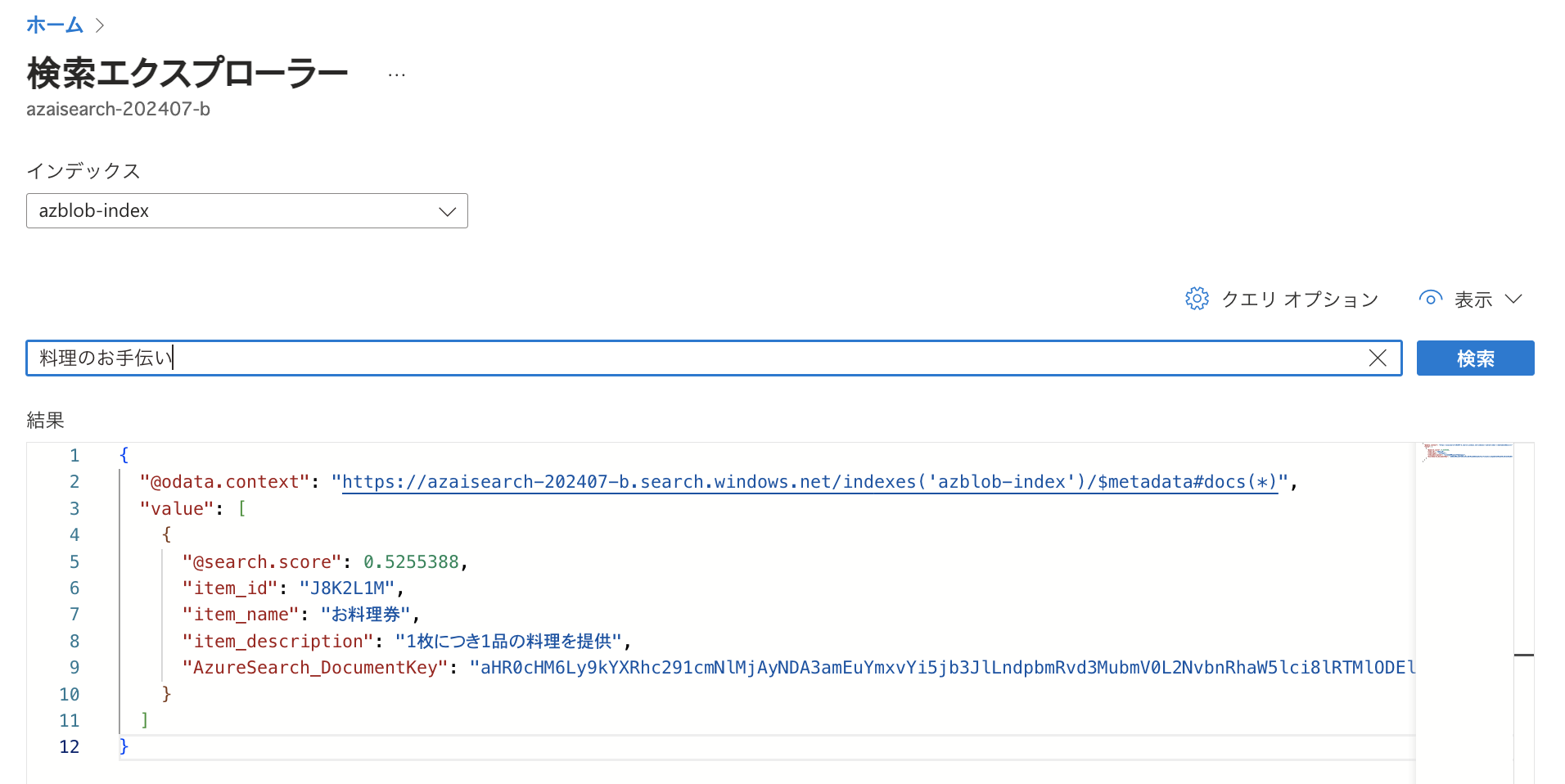
JSON形式でクエリを記述することも可能です。 「表示」で「JSONビュー」を選択します。 以下の例では"select"によって検索結果に表示されるフィールドを絞り込み、"count"をtrueにすることで検索条件に合うドキュメントの数が返されるようにしています。 この他のパラメーターについてはMicrosoft Learnをご参照ください。
以下の例では"select"によって検索結果に表示されるフィールドを絞り込み、"count"をtrueにすることで検索条件に合うドキュメントの数が返されるようにしています。 この他のパラメーターについてはMicrosoft Learnをご参照ください。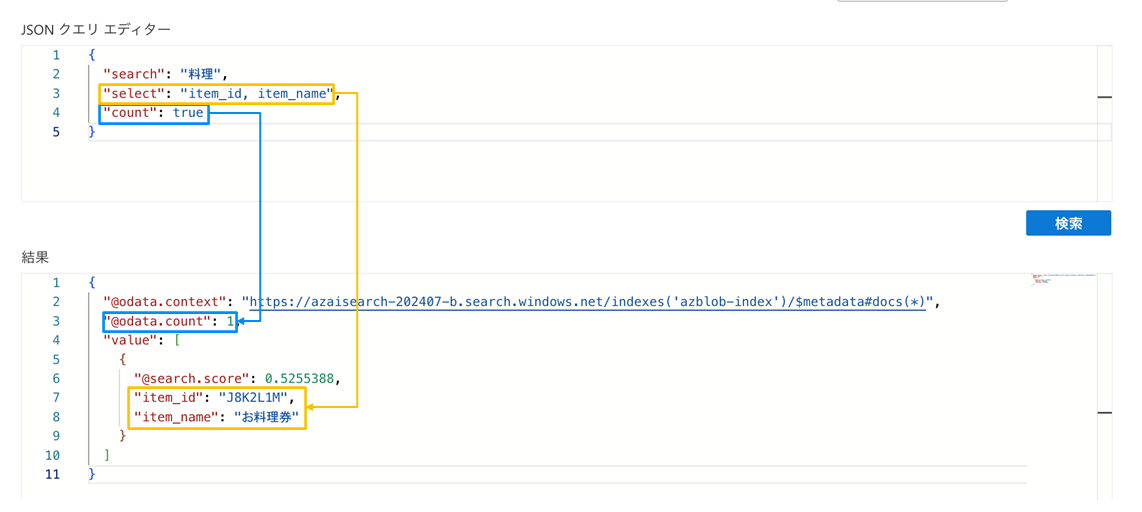
フルテキスト検索の処理に関する補足
検索エクスプローラーを利用した検索の例をご紹介しましたが、フルテキスト検索を行うにあたり内部的には4段階の処理が行われています。
(1) クエリ解析: クエリを単語やフレーズなどの「サブクエリ」に分解
(2) 字句解析: アナライザーにより(1)のテキストを加工 (単語を原形にする、重要でない単語を削除するなどの処理)
(3) 文書検索: インデックスに(2)と一致するドキュメントがあるか探す
(4) スコア付け: 検索結果に対し関連度をスコア付け
なお、検索の仕方によっては処理が変わる場合があります。 詳細についてはこちらをご参照ください。
まとめ
今回はAzure AI Searchの基本的な概念をご紹介しました。 Azure AI Searchの全ての機能を網羅するというよりも、サービスの概要を掴んで頂けるよう簡単なデータを例に基本的な考え方をご紹介しました。 まずは最小限の基本的な機能に触れて頂き、その次のステップとしてスキルセット / エンリッチメント / ベクトル化(ベクター化)など本ブログ記事ではご紹介していない機能に触れて頂くと理解が深まりやすいかもしれません。 また、本ブログ記事ではフルテキスト検索についてご紹介しましたが、ベクトル検索(ベクター検索)など異なる手法が存在しており、手法によって操作方法や内部処理など変わる点にご留意ください。
Azure AI Searchは昨今Azure OpenAI Serviceと組み合わせて利用するケースを目にすることがありますが、その意義などまた改めてご紹介できればと思います。
Azureを取り扱われているパートナー企業様へ様々なご支援のメニューを用意しております。 メニューの詳細やAzureに関するご相談等につきましては以下の「Azure相談センター」をご確認ください。
Azure相談センター
https://licensecounter.jp/azure/
※ 本ブログ記事は弊社にて把握、確認された内容を基に作成したものであり、サービス・製品の動作や仕様について担保・保証するものではありません。サービス・製品の動作、仕様等に関しては、予告なく変更される場合があります。
Azureに関するブログ記事一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄
