こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
その第3回目で、データをアップロードする方法をご紹介しましたが、実際にアップロードしてお試し出来るデータがないと、なかなか実際に手を動かして試してみるのは難しいと思います。
③UiPath Communications Mining ~データ準備編~
そこで、この記事では、サンプルデータの作り方をご紹介します。
「勉強のために試せる丁度いいデータがない」
「データを作るのには時間がかかるので、何か提供してほしい」
こんな方はぜひこの記事をご活用ください。
※ただ、データのアップロード時にはAIユニットが消費されてしまいますし、実際のデータで作成した方がより実践的なAIモデルが作成できますので、基本は実際のデータ利用が推奨となります。
目次
1. Pythonのインストール
2. 必要なライブラリのインストール
3. Pythonスクリプトの作成
4. Pythonスクリプトの実行
5. おまけ ~GPT4oでのコード作成プロンプト~
6. 最後に
1. Pythonのインストール
Pythonがインストールされていない場合は、まず、Pythonをインストールします。
Pythonの公式サイト(https://www.python.org/downloads/)からダウンロードしてインストールしてください。
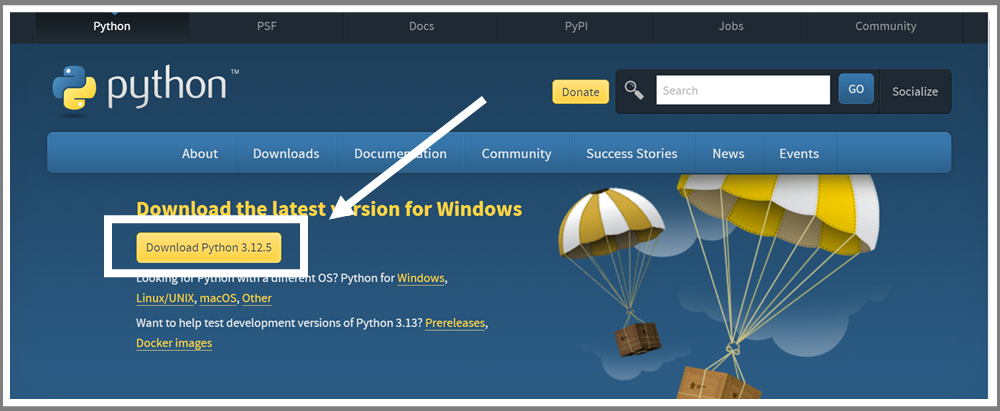
トップページにある「Download Python」ボタンをクリックして、最新バージョンのPythonをダウンロードします。
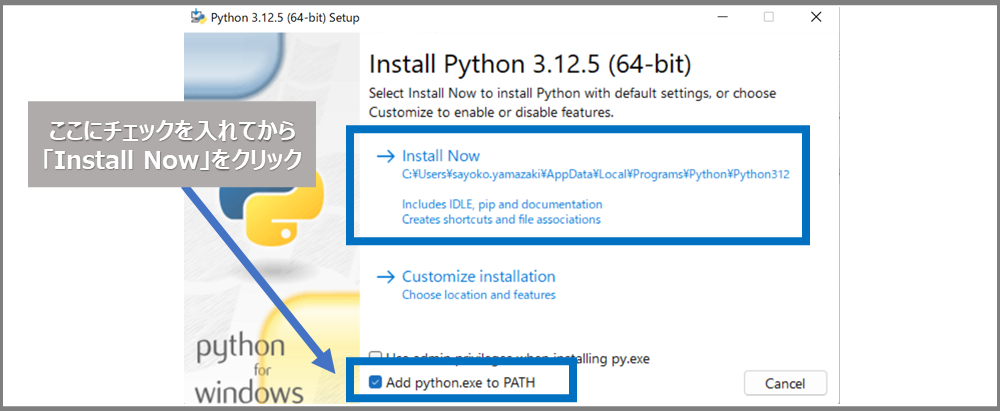
ダウンロードしたインストーラーを実行し、「Add Python to PATH」というチェックボックスにチェックを入れてから、「Install Now」をクリックします。
これでPythonのインストールが完了しました。
2.必要なライブラリのインストール
次に、必要なライブラリをインストールします。今回は、以下のライブラリが必要です:
- pandas
- faker
これらのライブラリをインストールするために、コマンドプロンプト(Macであればターミナル)を開いて、以下のコマンドを入力して実行します:
pip install pandas faker「Successfully」の文字がコマンドに出てきたら、ライブラリのインストールが完了です。
3.Pythonスクリプトの作成
テキストエディタ(メモ帳など)を開いて、以下のコードをコピーし、貼り付けます。そして、このファイルを generate_sample_data.py という名前で保存したら、Pythonスクリプトの完成です!
import pandas as pd
import random
from faker import Faker
from datetime import datetime, timedelta
fake = Faker('ja_JP')
# メールの種別と件名のテンプレート
email_types = [
("Communications Miningの詳細資料のお願い", "Communications Miningについてもっと詳しく教えてほしいとの要望を頂きました。つきましては、よい資料などあれば頂ければと思います。"),
("Document Understandingの見積もり依頼", "弊社ではDocument Understandingの導入を検討しております。見積もりをお願いできますでしょうか。"),
("Test Suiteの資料請求", "Test Suiteについての資料を頂けますでしょうか。"),
("緊急の対応について", "緊急の対応が必要です。"),
("製品に関する問題の報告", "先日ご提供いただいた製品についていくつか問題が発生しましたので、ご確認いただけますでしょうか。"),
("Test Suiteの見積もり依頼", "Test Suiteの見積もりをお願いできますでしょうか。"),
("Document Understandingについての問い合わせ", "Document Understandingについての問い合わせです。"),
("Communications Miningの資料請求", "Communications Miningの資料を頂けますでしょうか。"),
("緊急対応のお願い", "緊急の対応が必要です。"),
("製品の不具合に関するご連絡", "先日購入した製品に関して問題が発生しましたので、ご確認をお願いいたします。"),
("資格試験に関する資料請求", "資格試験についての資料を頂けますでしょうか。"),
("その他の見積もり依頼", "その他の見積もりをお願いできますでしょうか。"),
("その他についての問い合わせ", "その他についての問い合わせです。"),
("その他の資料請求", "その他の資料を頂けますでしょうか。")
]
senders = [f"xxx@sample.company{i}" for i in range(1, 11)]
receivers = ["xxx@sample.demo", "sales@sample.demo", "support@sample.demo"]
cc_list = [f"cc{i}@sample.com" for i in range(1, 11)]
data = []
for i in range(1, 10001):
email_type = random.choice(email_types)
sender = random.choice(senders)
receiver = random.choice(receivers)
cc = random.choice(cc_list)
thread_id = random.randint(100, 200)
timestamp = fake.date_time_between(start_date='-1y', end_date='now').strftime("%Y/%m/%d %H:%M:%S")
customer_name = fake.company()
customer_number = str(fake.random_int(min=100000, max=999999))
message = f"株式会社xx\n佐藤様\nお世話になっております。{customer_name}の{fake.name()}です。\n\n{email_type[1]}\n顧客番号:{customer_number}\n\nお手数ですが、何卒よろしくお願いいたします。"
data.append([i, message, timestamp, email_type[0], sender, receiver, cc, thread_id])
df = pd.DataFrame(data, columns=["ID", "Message", "Timestamp", "Subject", "Sender", "To", "CC", "Thread ID"])
# CSVファイルとして保存
df.to_csv("sample_emails.csv", index=False, encoding='utf-8-sig')
print("サンプルデータの生成が完了しました。")4. Pythonスクリプトの実行
次に、コマンドプロンプト(Macであればターミナル)を開き、以下のように入力して、スクリプトを保存したディレクトリに移動します:
※Windows でデスクトップに先ほど作成したスクリプトがある場合
cd %UserProfile%\Desktop
その後、以下のコマンドを実行してスクリプトを実行します:
python generate_emails.py
スクリプトの実行が完了すると、デスクトップにsample_emails.csvという名前のCSVファイルが生成されます。
これで、CSV形式のサンプルデータを1万件生成することができました!
5. おまけ ~GPT4oでのコード作成プロンプト~
余談ではありますが、今回のこのスクリプトは、社内で利用しているAI チャット(GPT-4o)で生成したものです。プロンプトは以下となります。
あなたはデータサイエンティストです。
自社の特定のメールアドレスxxx@sample.demoに日々寄せられる、顧客からのメールの内容を理解して、メールの意図によって種別分けしたり、メールの文面からエンティティを抽出したりするAIモデルを作ります。
このAIモデルを作るためにデータをとりあえず用意したいのですが、サンプルデータを1万件ほど表形式で作成してもらえますか?
ヘッダーは、ID,Message,Timestamp,Subject,Sender,To,CC,Thread IDの列を作ってください。
※ID列には、メッセージを識別する一意のIDが入ります。
※Message列には、メールのメッセージが入ります。
※Timestamp列は、yyyy/MM/dd HH:mm:ss形式でお願いします。期間は2023年1月から2023年12月までのどこかの期間のタイムスタンプが入るように。
※Subject列には件名が入ります。
※Sender列には、送信者が入ります。送信者は、は、[xxx@sample.company1][xxx@sample.company2][xxx@sample.company3][xxx@sample.company4][xxx@sample.company5][xxx@sample.company6][xxx@sample.company7][xxx@sample.company8][xxx@sample.company9][xxx@sample.company10]のいずれかとなります。
※To列は受信者なので、基本xxx@sample.demoですが、弊社の営業など個人のアドレスがToに入っていることもあるかもしれないです。
※CC列は何か適当にサンプルを入れておいてください。
※Thread ID列は、異なるメッセージを同じスレッドに結び付けるものです
#顧客から来るメールの種別
見積依頼>Document Understanding
見積依頼>Communications Mining
見積依頼>Test Suite
見積依頼>その他
製品問い合わせ>Document Understanding
製品問い合わせ>Communications Mining
製品問い合わせ>Test Suite
製品問い合わせ>その他
資料請求>Document Understanding
資料請求>>Communications Mining
資料請求>>Test Suite
資料請求>資格試験について
資料請求>その他
緊急
クレーム
#メールの文面から抜き出したい情報
※たまに依頼主は製品名や顧客番号をメールに含めるのを忘れるので、必ずしも書いてあるわけではないが、基本的にこれらの内容がメッセージに含まれる。
顧客名
製品名
顧客番号
#メールの文面はなるべくリアルに作ってください。例えば下記のような感じ。
株式会社xx
佐藤様
お世話になっております。abc株式会社の山崎です。
先日はお忙しいところありがとうございました。
その後お客様とお話しまして、Communications Miningについてもっと詳しく教えてほしいとの要望を頂きました。
つきましては、よい資料などあれば頂ければと思います。
顧客番号:002321
お手数ですが、何卒よろしくお願いいたします。
#件名も、いかにもありそうなリアルな感じに作ってください
例えば、クレームを言ってくるお客様は、件名を直球にクレームにしてくることはありません。
6. 最後に
以上が、PythonでUiPath Communications Miningの為の、サンプルデータを作成する方法となります。
1万件ものデータを用意するのは中々大変なので、お役立ていただければ幸いです。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子