こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
この記事はその第3回目です。第1回目では基本的な概念について、第2回目では必要な環境準備について説明しました。この記事では、Communications Miningの初期設定であるプロジェクトの作成や、ソースの作成、データセットの作成について、明らかにしていきます。
目次
1. プロジェクトの作成
2. データソースの作成
2-1. まずは生のサンプルデータを用意
2-2. データソースを作成
2-3. データソースに生データをアップロード
3. データセットの作成
4. 最後に
1. プロジェクトの作成
まずは、プロジェクトを作成していきます。
※プロジェクトとは、プラットフォーム内の権限が設定された保存領域です。
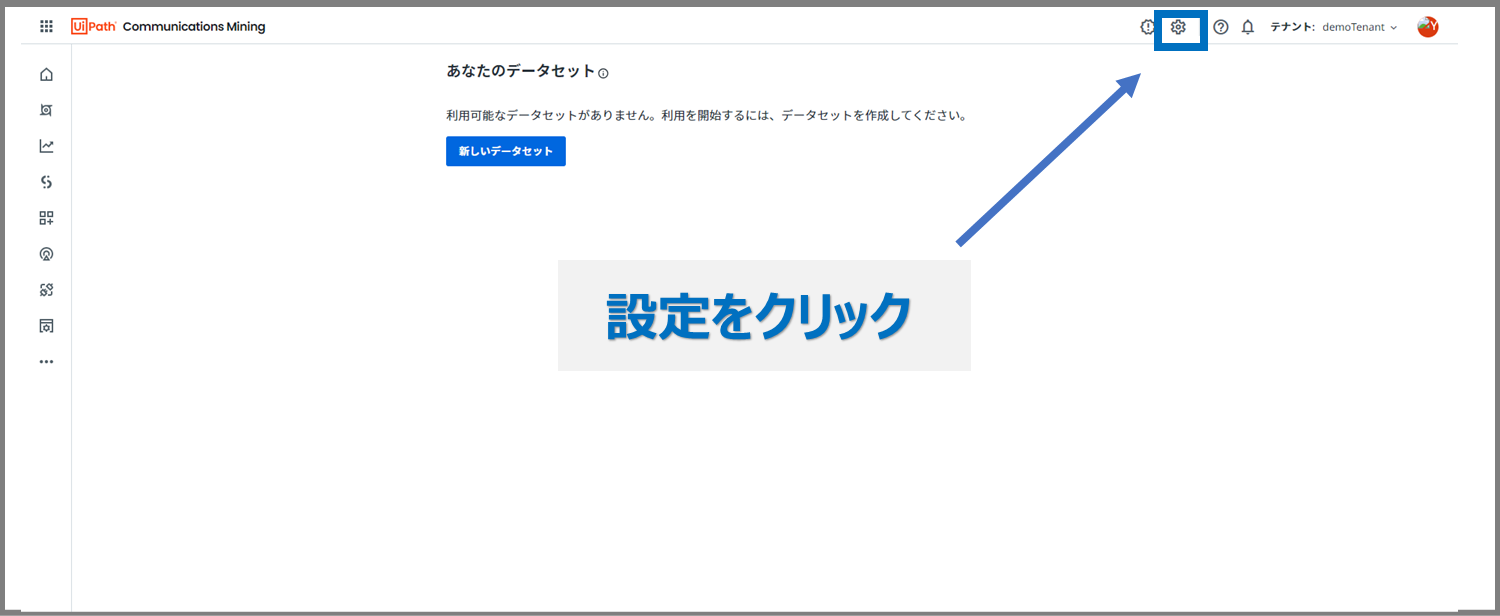
Communications Miningのホーム画面には、データセットの一覧表示のみされているので、設定をクリックして管理ページに移動します。
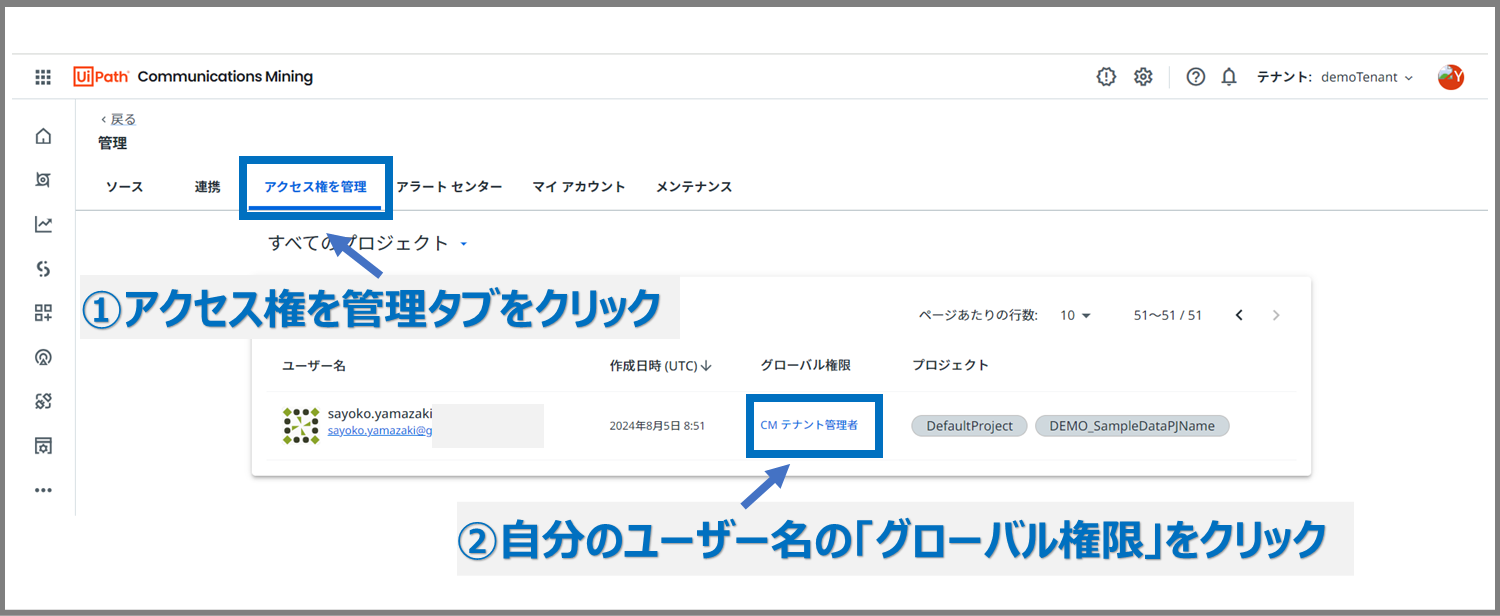
管理ページの「アクセス権を管理」タブをクリック
↓
自分のユーザー名の横、「グローバル権限」の所に表示されている文字をクリックできるので、こちらをクリックしてください。
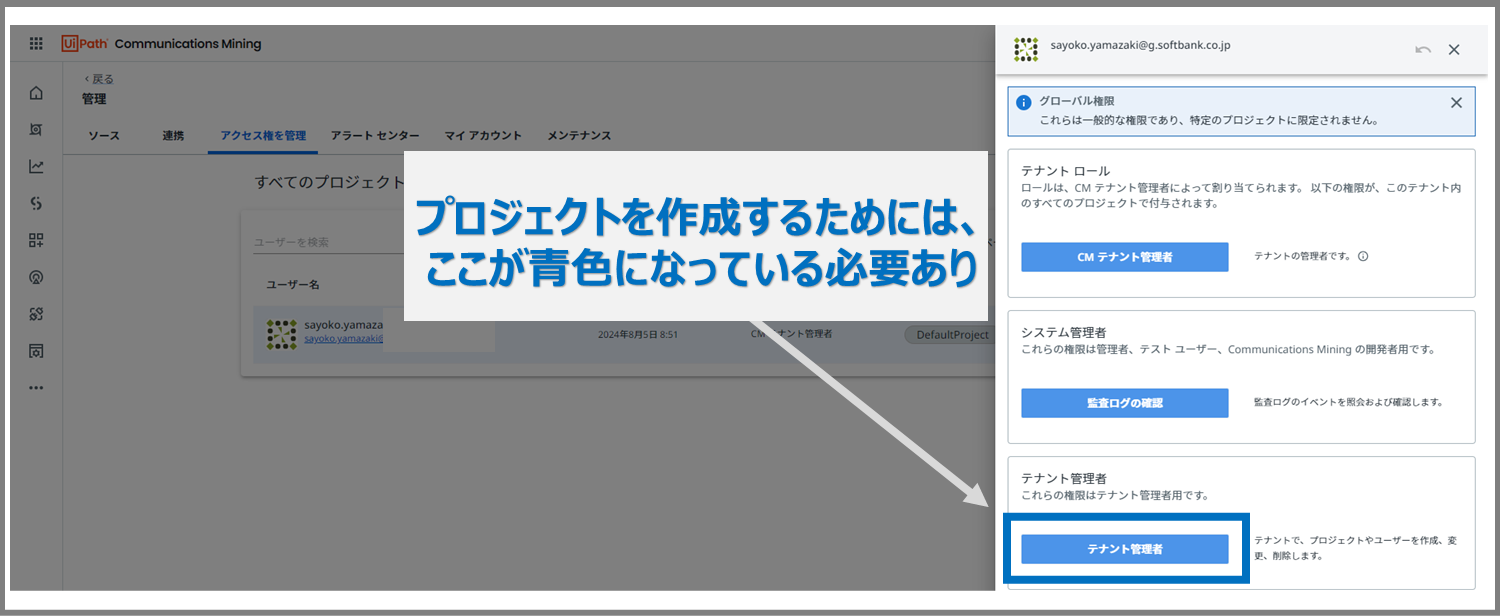
すると、上のような画面が出てきます。
プロジェクトの作成は、「テナント管理者」権限を持つユーザーのみ可能となっています。権限がある場合は青色/権限がない場合は白色です。白色だった場合は、管理者に依頼してください。
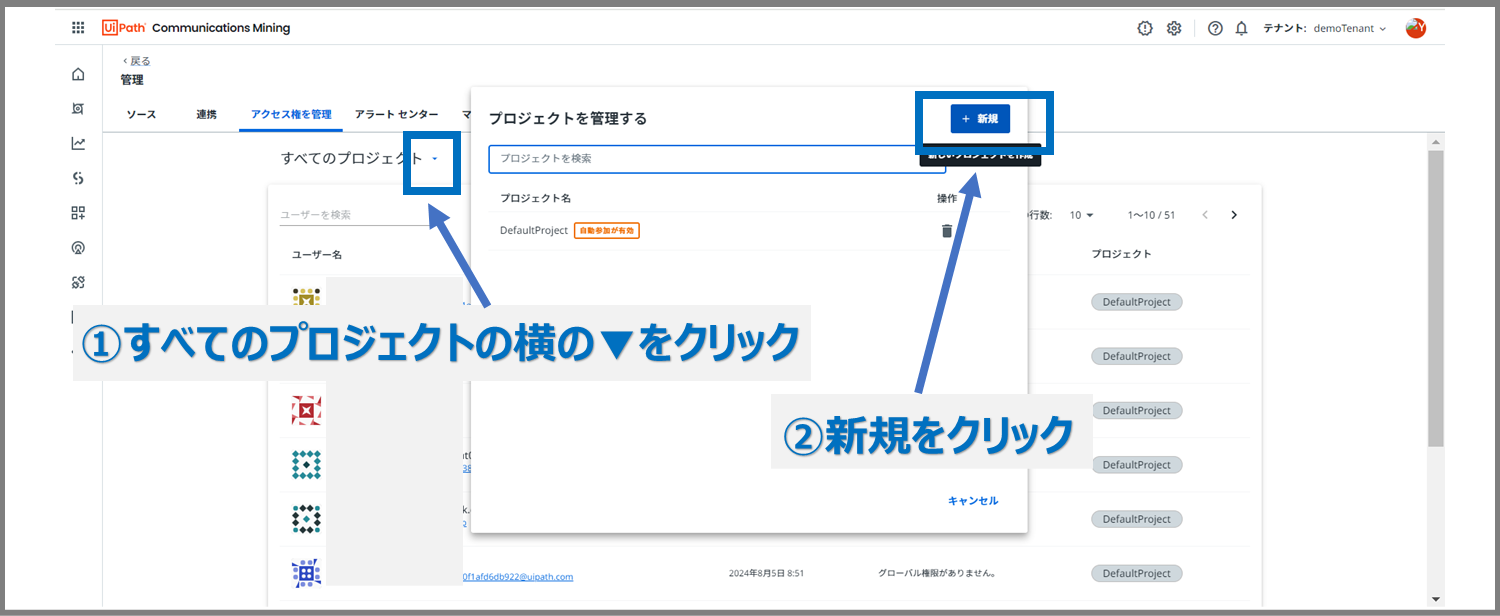
権限があることが確認できたら、「すべてのプロジェクト」の横の▼→「新規」ボタンの順に進みます。
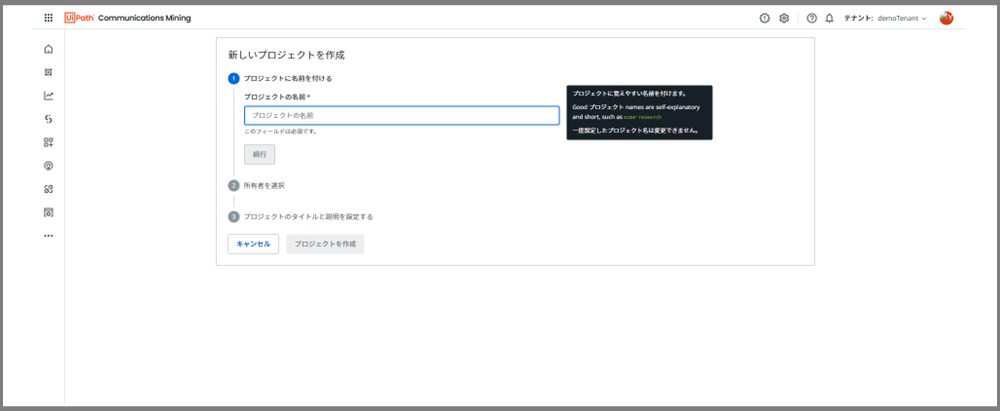
①プロジェクトに名前を付ける
※今回は記事用のデモプロジェクトなので「DEMO_SampleDataPJName」という名前を付けました。プロジェクト名は、一度設定すると変更できないので気をつけましょう。
②所有者を選択
※とりあえず、自分を所有者にしましょう。
③プロジェクトのタイトルと説明を設定する
ここは必須項目ではないので、デモで作るだけであれば白紙で大丈夫です。
①②③のタスク完了後に「プロジェクトを作成」ボタンを押します。
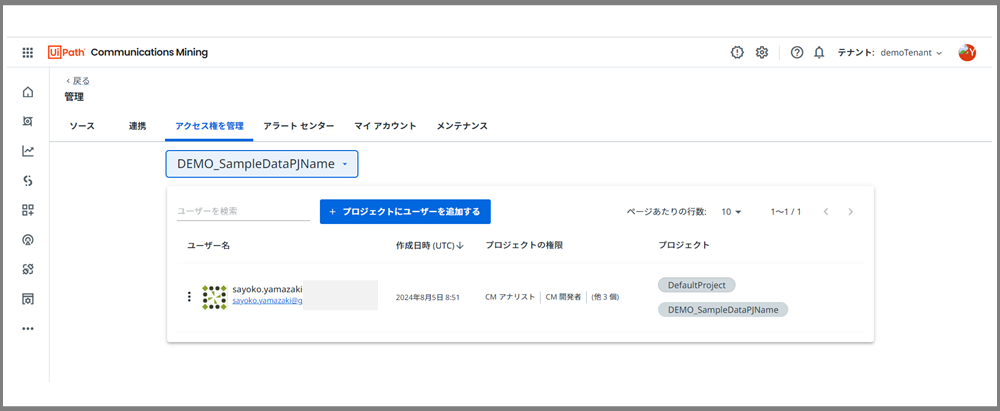
これでプロジェクトが作成されました!
2.データソースの作成
次はデータソースを作成していきます。
データ ソースは、生のデータのコレクションです。たとえば、共有メールボックスのメール、アンケートで回収したすべての回答、電話番号に対するすべての通話などがデータ ソースとなります。
これらのデータをCommunications Miningに色々な方法でアップロードできるのですが、今回のこの記事ではCSV形式でアップロードしていきたいと思います。
その他のデータアップロード方法をもっと詳しく把握したい場合は、下の記事をご参考にどうぞ。※UiPathの中の人が詳しくまとめてくれた記事です
UiPath Communications Mining 準備編 データ連携方法 概要紹介
2-1. まずは生のサンプルデータを用意
AIモデルを作成していくためのメッセージを、CSV形式でCommunications Miningにアップロードするためには、形を整える必要があります。下記のような形式が整ったCSVファイルが必要です。
- 最初の行にはヘッダーが含まれている
- カンマまたはタブで区切られている
- 少なくとも3つの列がある: ID列、メッセージ列、タイムスタンプ列
※ID列には、メッセージを識別する一意のIDが入ります。
※ID列、メッセージ列、タイムスタンプ列以外にも、必須ではないが「Subject列」「Sender列」「To列」「CC列」「Thread ID列」なども含むことができる。 - ファイルは UTF-8、UTF-16、または UTF-32 のいずれかでエンコードされている
- 64MiB以下
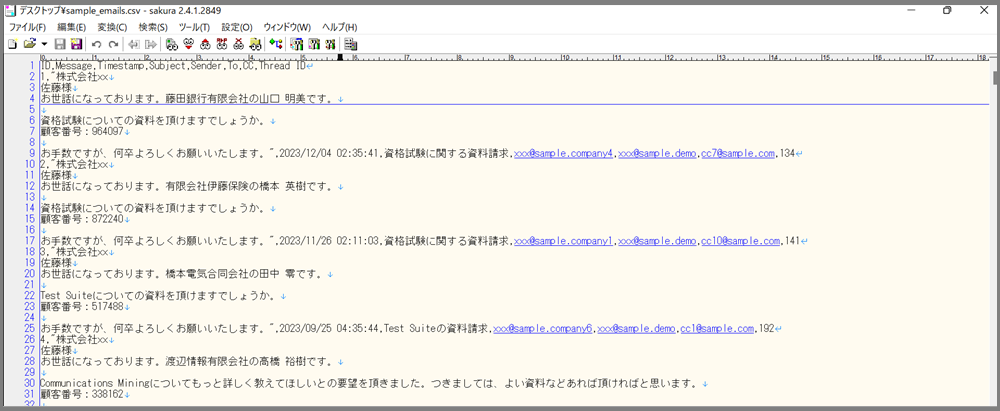
上の画像は、実際に用意したデータです。
※この記事のために、Pythonで作成した架空のサンプルデータ1万行となります。
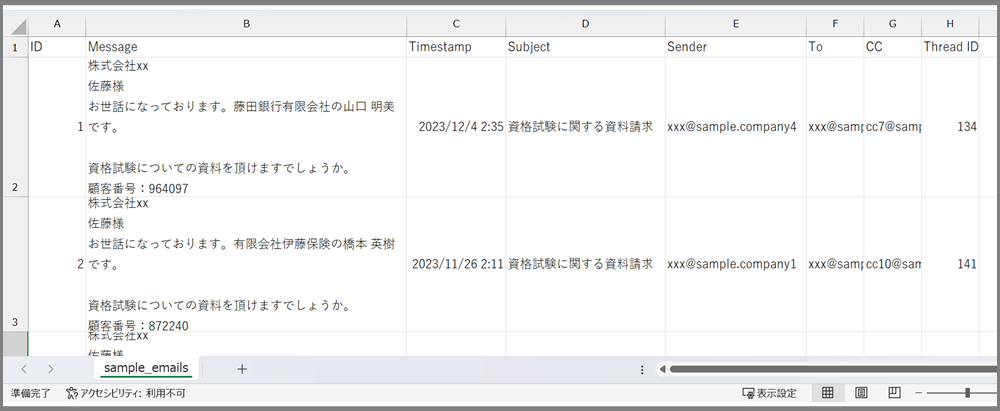
見やすくExcelで開いてみるとこのようなデータとなります。
※このサンプルデータの作り方については、下の記事でまとめてあります。サンプルデータが必要な方はご活用ください。
Pythonでサンプルデータを作成する方法
また、CSVファイルのアップロードについて、もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
※Re:inferの公式ドキュメントです。Re:inferは 、UiPathが買収したCommunications Miningのもとになる製品を作っていた会社となります。UiPathの公式ドキュメントにもCommunications Miningについての記載はありますが、このRe:inferの公式ドキュメントにしか載っていない一部の詳しい情報もあるので、こちらも要チェックです。
Uploading a CSV file into a source
2-2. データソースを作成
それでは、生のデータの準備ができたので、データソースを作成していきます。
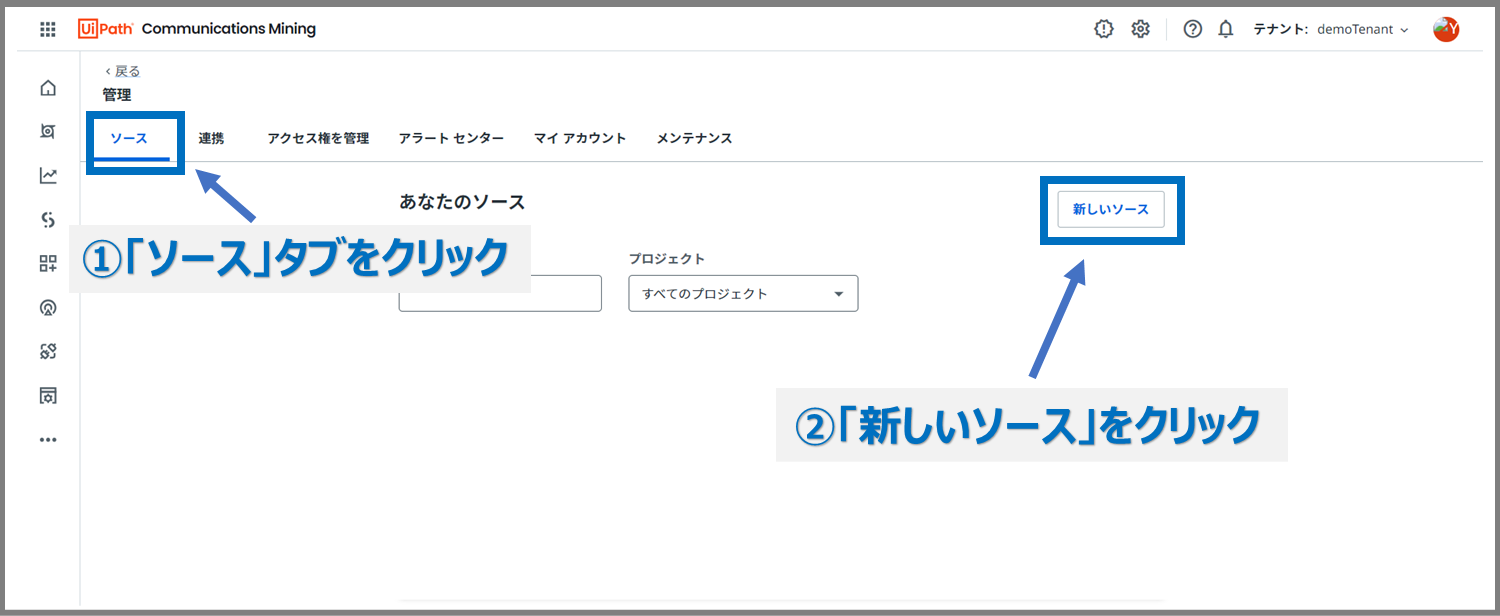
管理ページにて、「ソース」タブ→「新しいソース」ボタンの順に進みます。
※新しいソースを作成するには、「データセット管理者」というユーザー権限が必要になります。先ほどプロジェクトを作ったのがあなたなら、すでにこの権限は持っているはずですが、プロジェクト作成を誰かにやってもらった方は、その方にプロジェクトのページからこの権限をつけてもらう必要があるかもしれません。
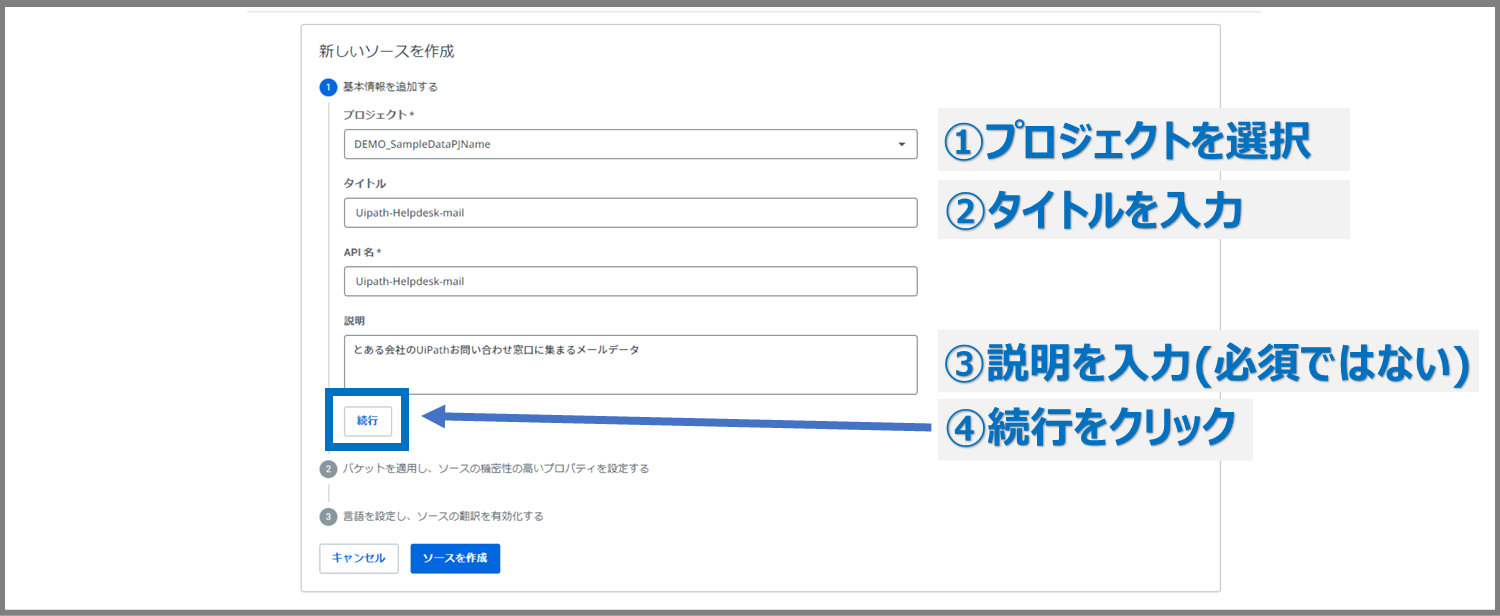
①最初に作成したプロジェクトを選択する
②データセットにわかりやすい名前を付ける
今回用意したデータは、とある会社のUiPathお問い合わせ窓口に集まるメールデータといった内容を意識して作成したサンプルデータです。ですので、「Uipath-Helpdesk-mail」という名前を付けてみようと思います。
③データソースの説明を入力
ここは必須ではありませんが、説明があるとわかりやすいです。今回は、「とある会社のUiPathお問い合わせ窓口に集まるメールデータ」と説明文を入れてみました。
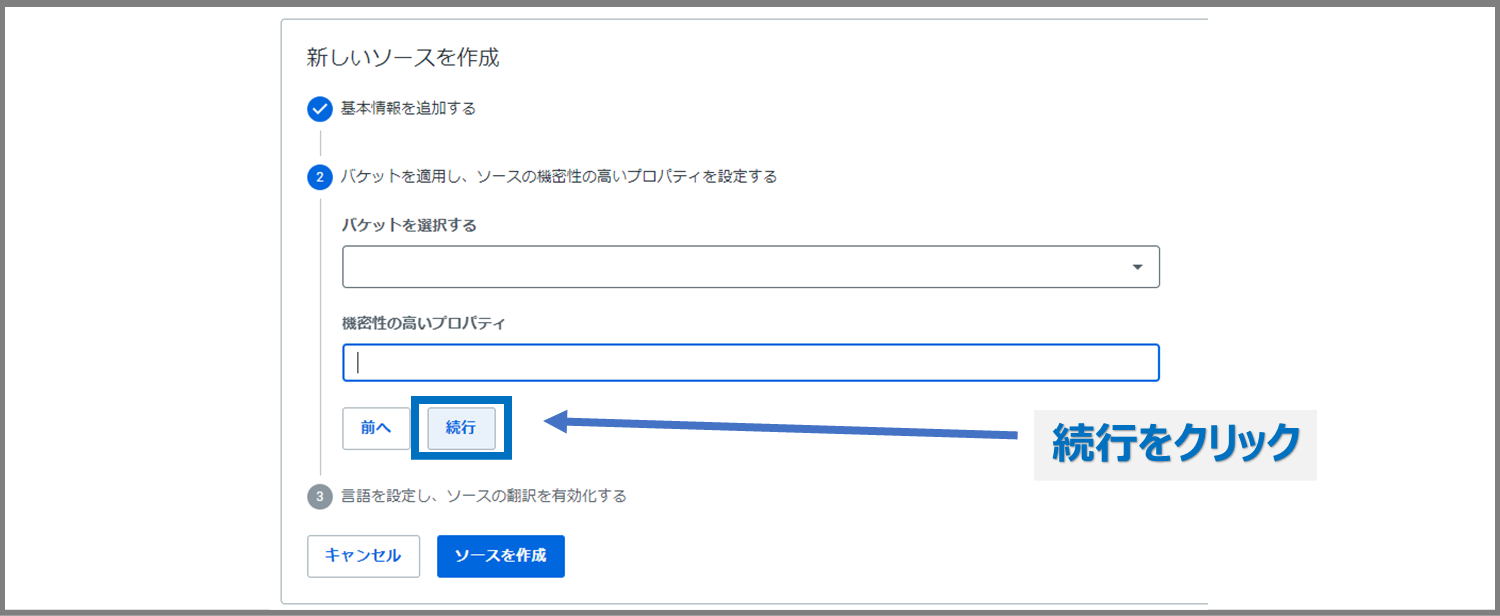
ここは白紙のまま「続行」をクリックします。
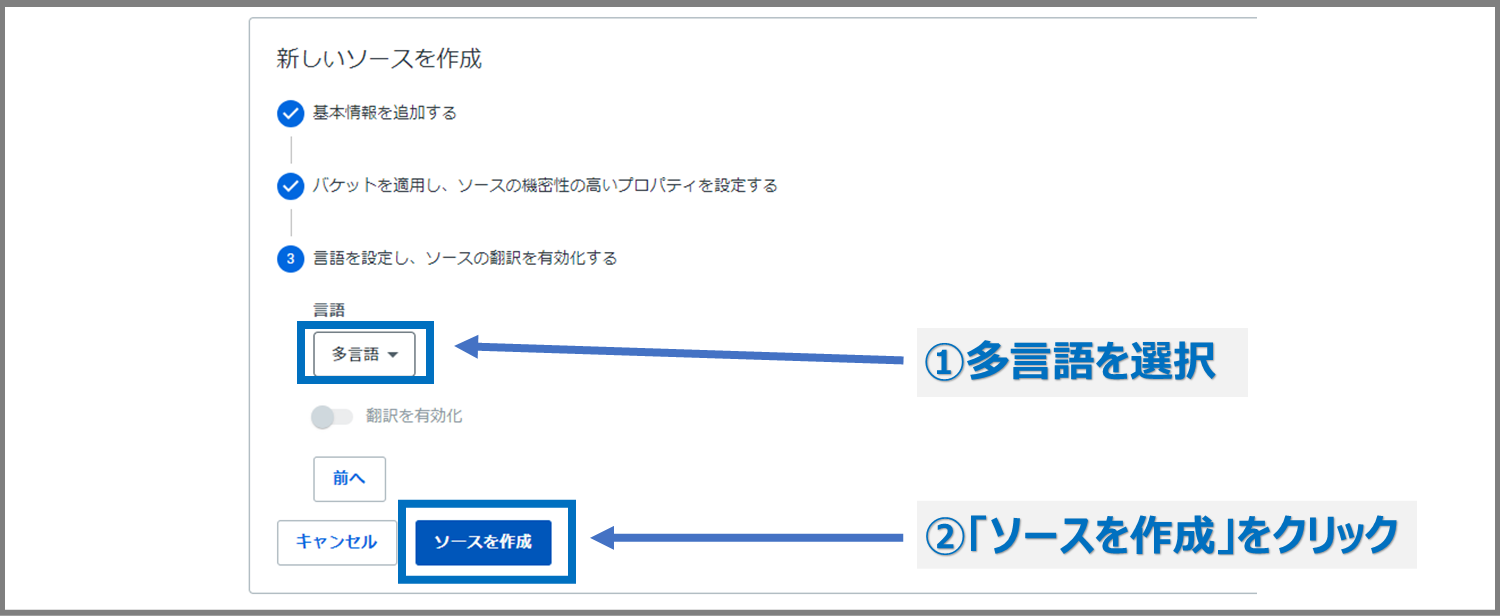
「多言語」を選択→「ソースの作成」をクリックします。
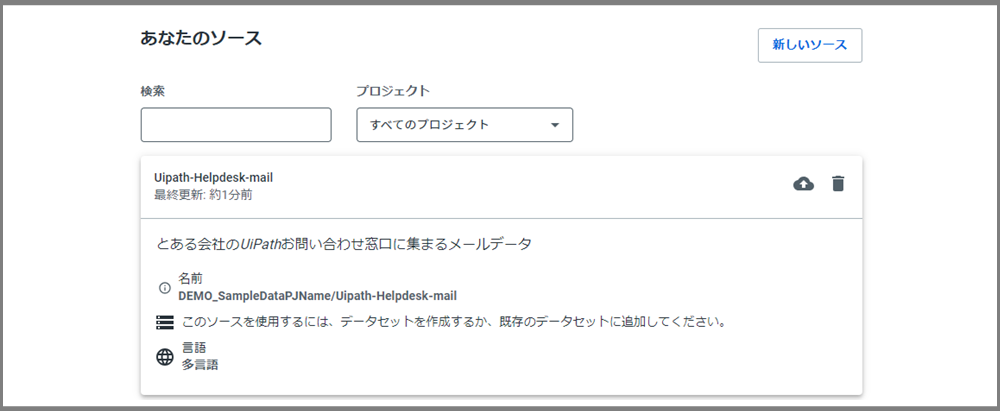
これで、データソースが完成しました!
2-3. データソースに生データをアップロード
今作ったデータソースに、上で作成したCSVデータをアップロードしていきます。
※注意※
ここでデータをアップロードする時にAIユニットが消費されます。
自社環境にAIユニットが潤沢にある方も、管理者に確認しないで使うとコスト増で問題になる可能性もあるのでお気を付けください。
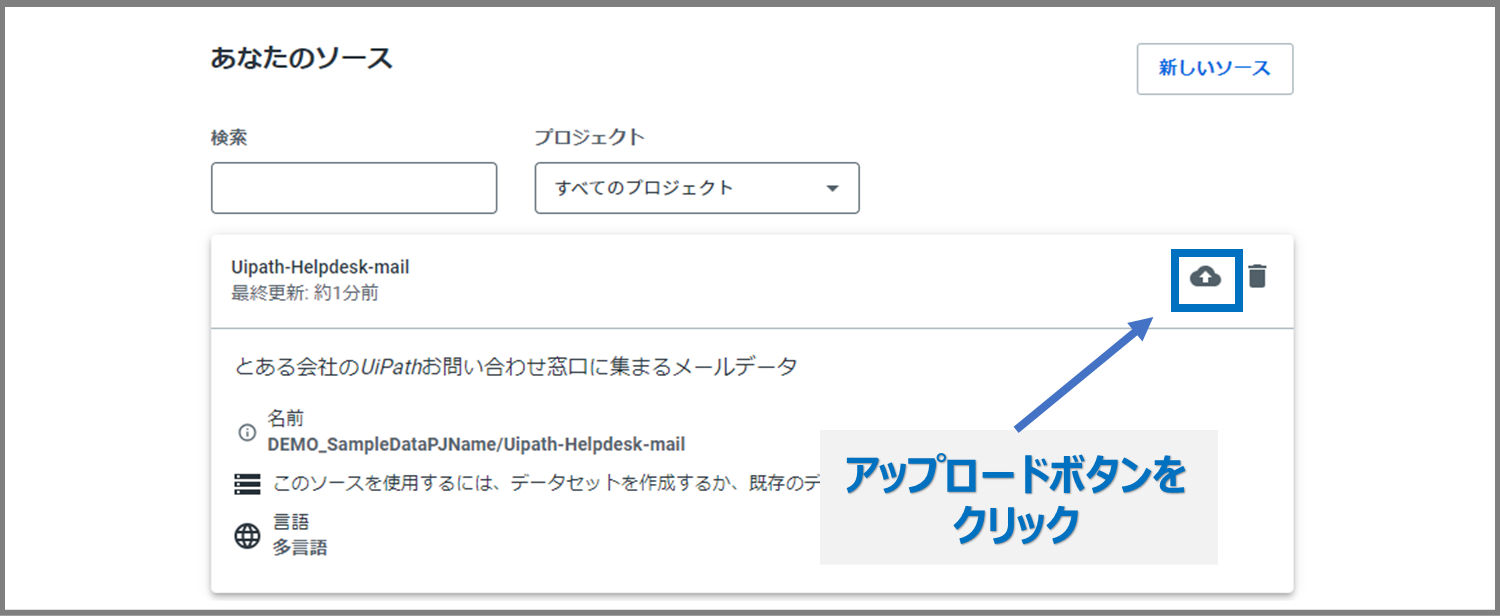
まずは、先ほど作成したデータソースの右上の、アップロードボタンをクリックします。
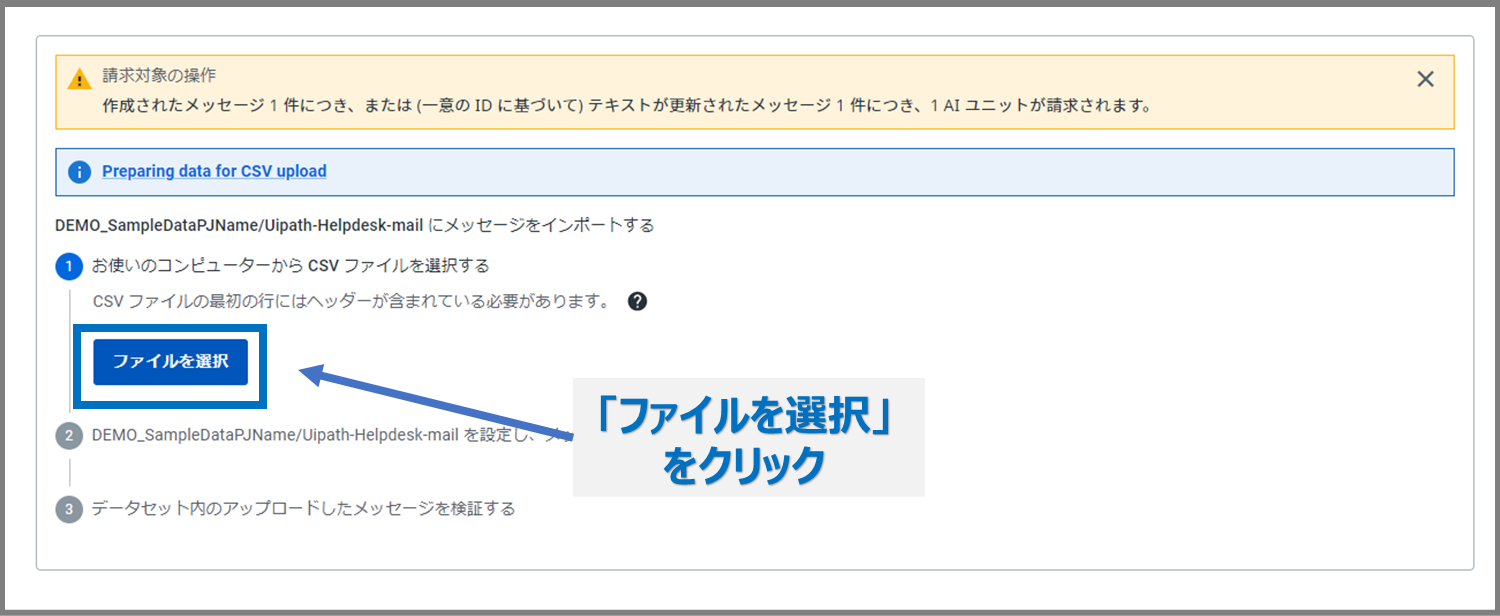
次に「ファイルを選択」をクリックし、先ほどのCSVを選択してアップロードを行います。
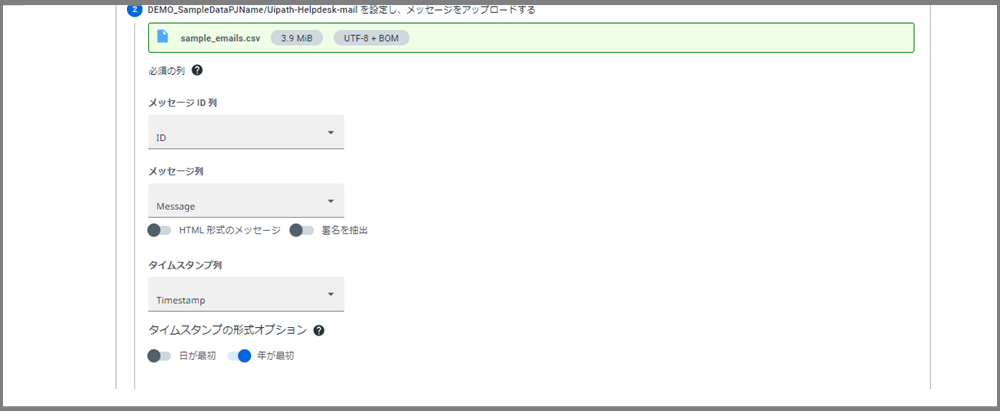
この画面では、列の認識を合わせていきます。私が用意したCSVですと、メッセージID列のヘッダーの名前は「ID」だったので、ここは「ID」を選択し、次のメッセージ列は「Message」を選び...といった具合です。
この画像には出ていないですが、最後に画面下の「アップロード」ボタンを押すとアップロードが始まります。
さぁ、これで、作成したデータソースに、準備したCSVファイルのデータをアップロードする所までが終わりました!
3.データセットの作成
最後は、「データセット」を作成していきます。
先ほど準備した「データソース」には生のデータ(今回でいうと準備したCSVデータ)が入っています。
これから準備するデータセットは、データソースを利用してAIモデルを作成していき、利用していく為の場所と考えて頂ければと思います。
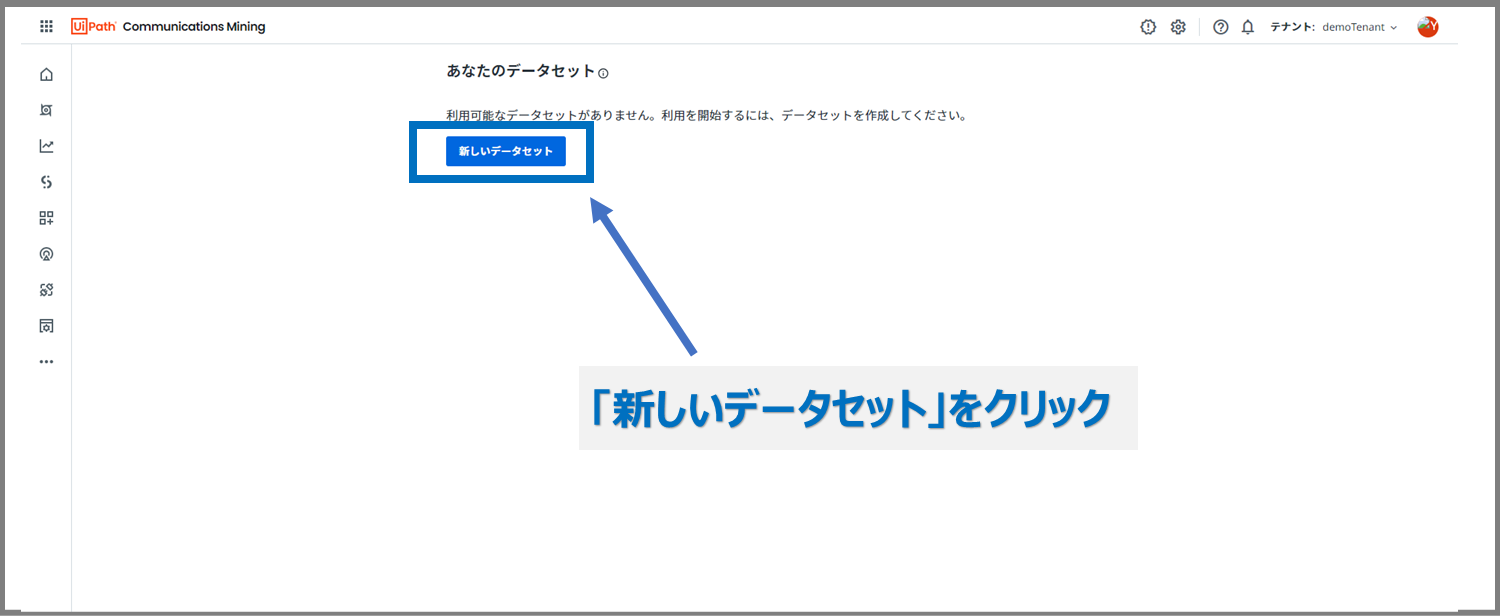
まずは、「新しいデータセット」ボタンを押して、データセットの作成をしていきます。
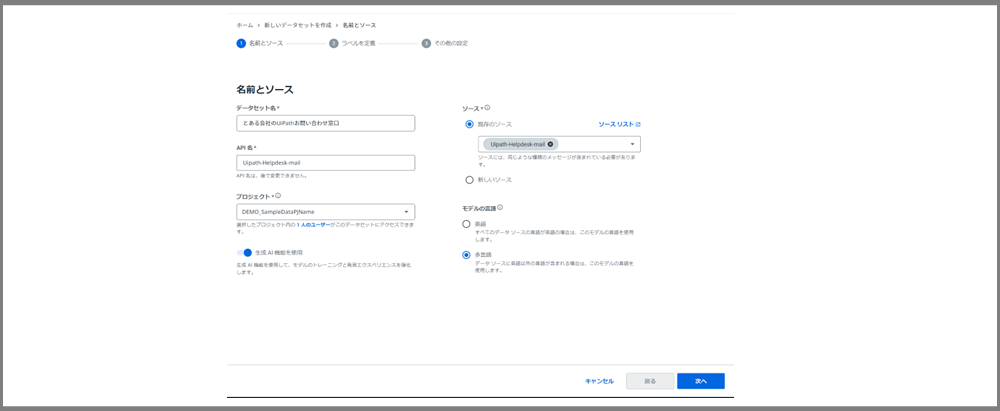
モデルの言語の所ですが、英語と多言語しか選択肢がありません。
日本語の場合は、「多言語」を選択します。
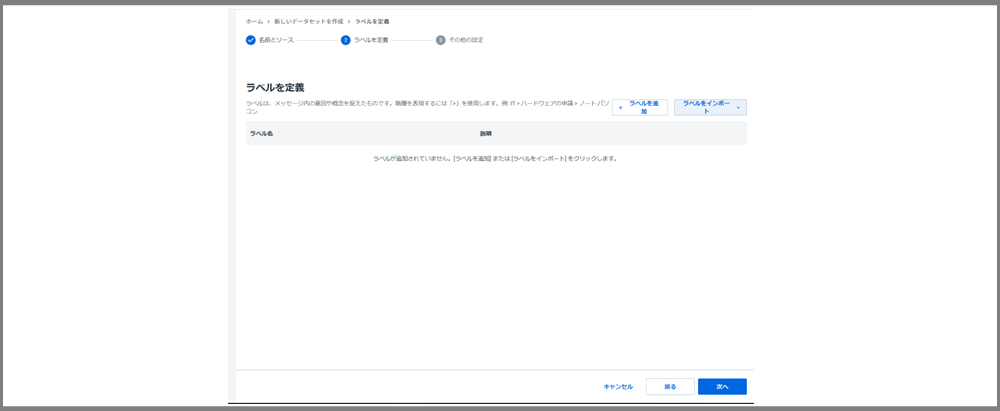
ラベルの定義のページでは、今回は何もせずにそのまま下の「次へ」ボタンを押して次に進みます。
ここの説明は長くなるので、次回の記事で説明しようと思います。
※今この段階でラベルの定義をしなくとも、後からラベル定義をすることができます。
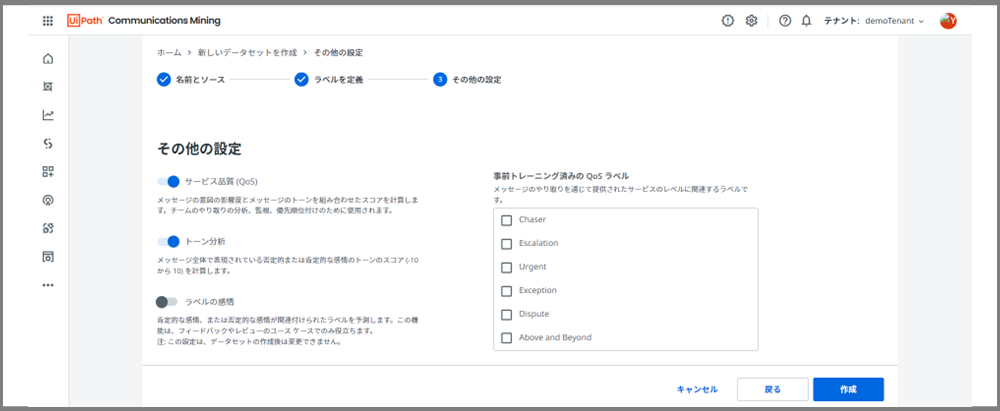
このページでは、「サービス品質」と「トーン分析」を有効化しました。
※ここは、データセットの作成時に必ずしも設定する必要はないです。後からいつでもデータセットの設定ページで操作できるので今は深く考えないでください。
最後に作成ボタンを押して完了です。
データセットが完成しました!
4. 最後に
以上が、UiPath Communications Miningの初期設定でした。
今回の記事では、プロジェクトを作成し、そのプロジェクトにデータソースを作り、その作ったデータソースに、CSVデータをアップロードしました。
更にはそのデータソースを利用して、データセットを作成しました。これでAIモデルをつくっていく準備が整いましたね!
次回の記事では、タクソノミーについて(今回の最後のデータセット作成時に飛ばした、「ラベルの定義」の所)ご紹介していきますので、お楽しみに。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子