こんにちは。SB C&Sの幸田です。
今年もNVIDIAの年次イベント、GTCに現地参加しております。
パンデミックの影響で臨場開催は一時中断していましたが、2024年から復活し、今年も大盛況のうちに開催されています。
NVIDIAが主催するGTCは、学術研究からビジネス活用まで、最先端のAIを中心的なトピックスとして扱う発表会・展示会です。
開催場所はカリフォルニア州サンノゼのMcEnery Convention Centerとその周辺。
現地の来場者数は25,000人、Web経由で視聴するバーチャル参加登録者の数は300,000人を数えます。
昨年のGTC 2024では現地の来場者数が17,000人でしたので、大幅増ですね。


今年も街が丸ごとGTCに染まっております。自動運転車の展示などは道路の一部を利用して行われ、
会場前の公園は当イベント開催期間のみGTC Parkと名付けられて、ランチやナイトマーケットの会場として参加者に開放されます。
世界中が注目するJensen Huang氏の基調講演は昨年同様、本会場から少し離れたSAP Centerで行われました。会場や近隣のホテルからはシャトルバスも出ています。
盛況であるぶん入場のための行列は長めでしたが、無事会場へ入り、開演時間に。
壮麗なオープニングムービーと音楽がひとしきり流れると、いよいよJensen Huang氏が登場して開演です。



スポンサーへの謝辞が述べられ、コンシューマー向けの最新GPUとなるGeForce RTXシリーズの新モデルを紹介してから、メッセージと各種発表が始まります。
それでは以下、ご説明が拙いところも多く恐縮ですが、さっそく本編をご紹介いたします。
最新Blackwell世代のGPUが支える膨大なコンピューティングの需要
まずは10年前から現在までのAIの進化を振り返るところから、Jensen Huang氏のメッセージは始まりました。
画像や音声の認識を行う「知覚的なAI(Perception AI)」から始まり、ここ5年間は「生成AI(Generative AI)」に力が注がれました。
質問のテキストから答えを生成することはもちろん、テキストから画像、画像からテキスト、テキストから動画など、異なるモダリティ(種別)の生成が可能となっています。
そして現在注目されている「エージェントAI (Agentic AI)」は、目的を達成するための手段を推論し、複数のツールや自ら獲得した新しい知識を使って自律的に動作するAIです。
さらに次の波であるロボットや自動運転などの「物理世界のAI(Physical AI)」の実装もいよいよ本格化しつつあります。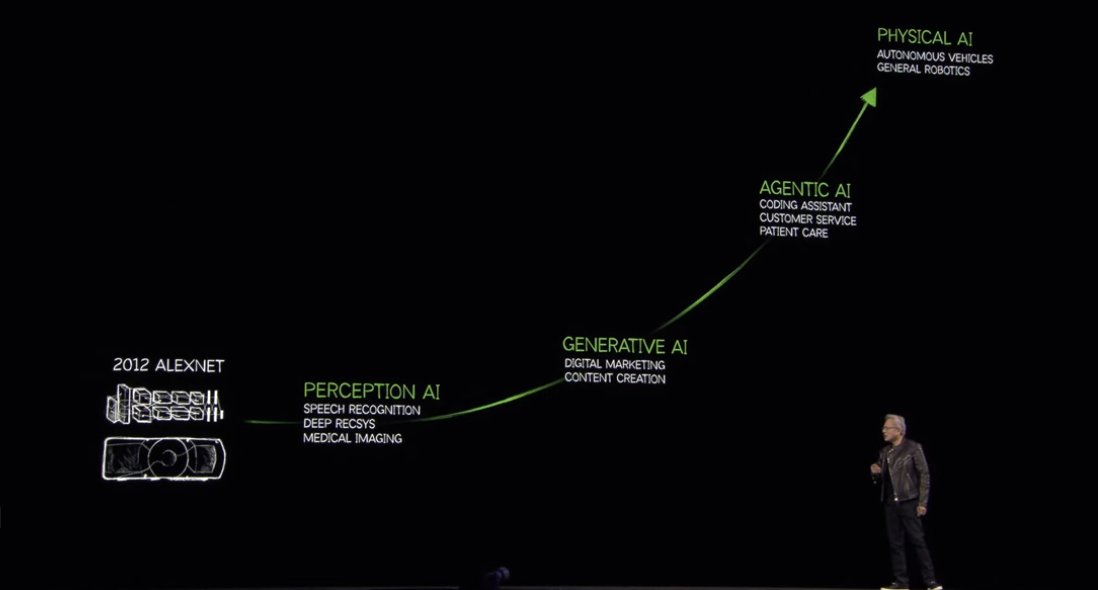
また、その進化に伴って、AIの精度を向上させる手法も新たに生まれていきました。
特に、AIの思考のプロセスが明示されるCoT (Chain of Thought) と呼ばれる「段階的な推論」や、強化学習(RL - Reinformation Learning)の新しい手法であるRLVR (数学的に検証可能な報酬を使って行う強化学習。人間のフィードバックを用いる手法はRLHF) が取り入れられていくことによって、昨年の同時期に比べてAIに必要と考えられるコンピューターリソース量は100倍になったと述べられました。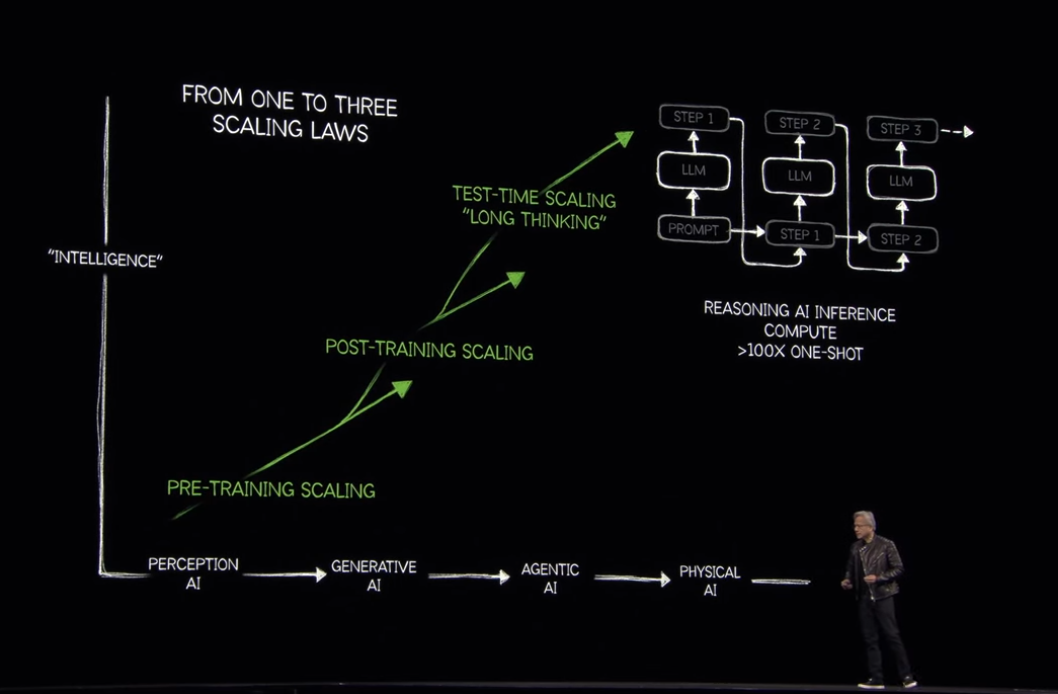
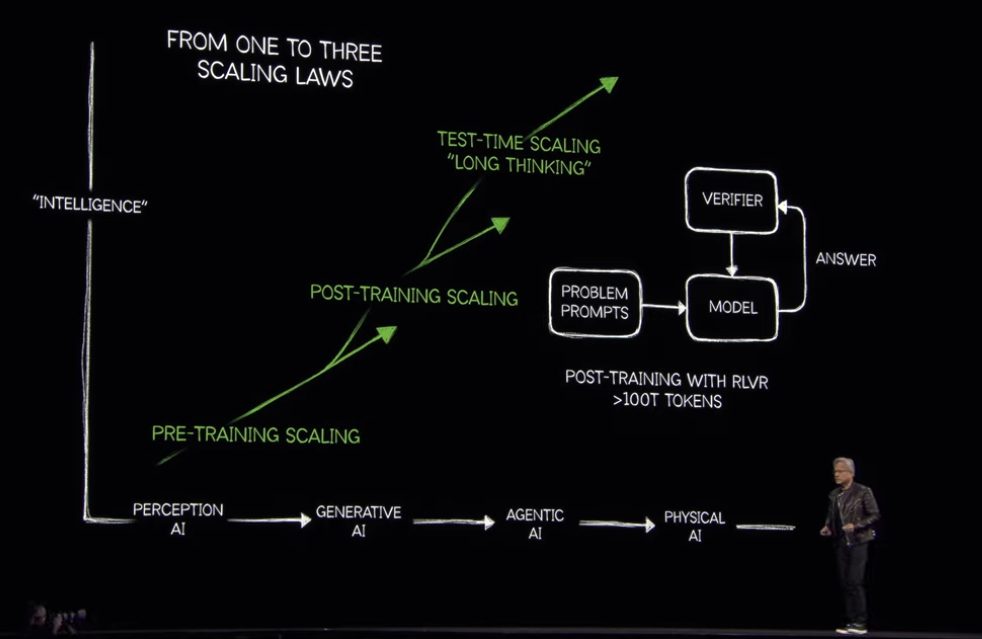
裏付けとして、Top4のパブリッククラウド (AWS, Azure, GCP, OCI) のGPU調達は、Hopper世代のピークだった2024年の約130万基に対し、Blackwell世代の1年目である2025年は既に現在までのところで360万基にも上っていることが示されました。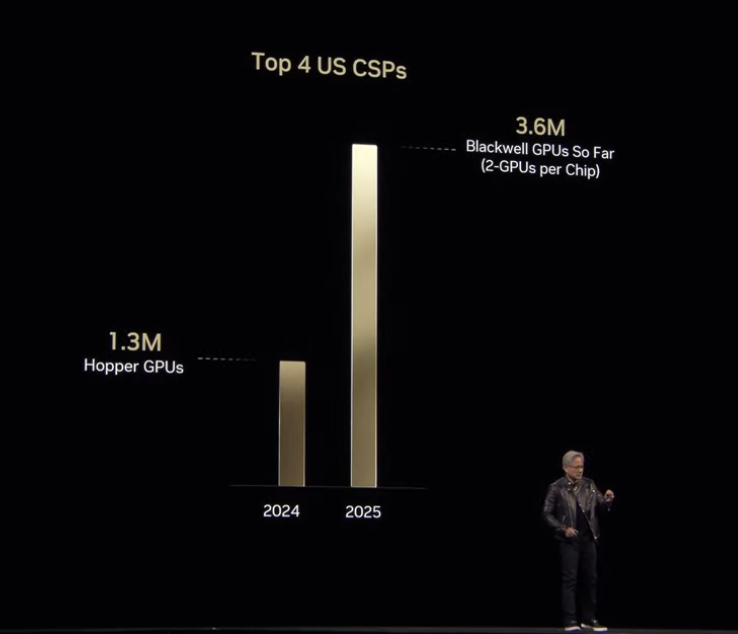
また、一般的なデータセンターの市場の伸長に対して、NVIDIAのデータセンター関連の業績の伸長率が非常に高いことも示されました (青紫が一般的なデータセンター、白金のグラデーションがNVIDIAのデータセンター関連の業績) 。この背景として、従来の汎用的なコンピューティングが限界を迎え、すでに作られたものが用いられる「検索ベース」のコンピューティングから、GPUを中心としたアクセラレーターが知識やソフトウェアを生成する「生成ベース」のコンピューティングへの転換点が来ていることが主張されました。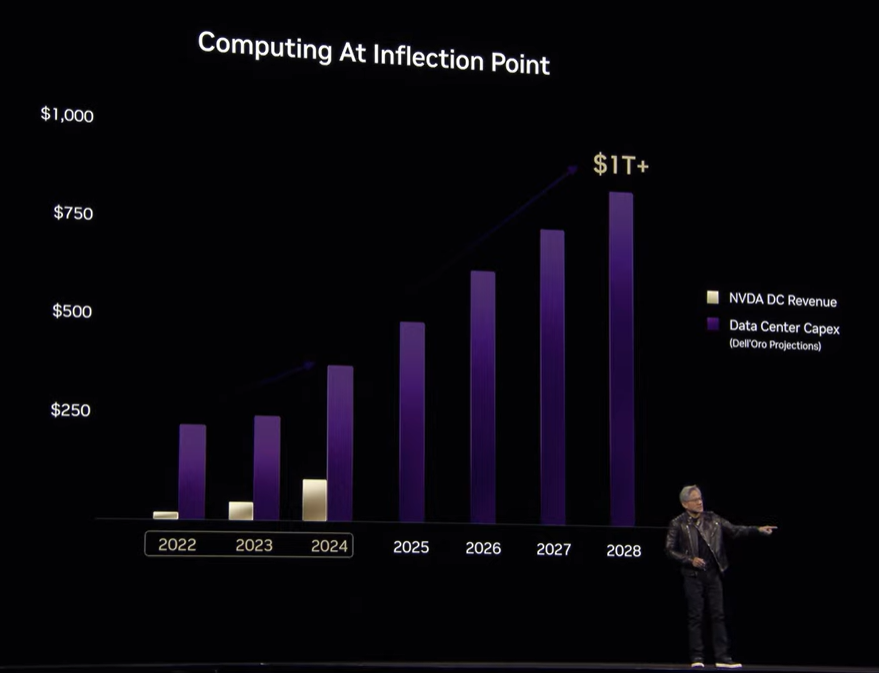
個々の産業領域におけるAI活用の進化についても触れられました。NVIDIAは多数の産業ドメイン=業界に特化したプロダクトの開発も行っており、AI関連の演算を行うライブラリは例年ずっと進化し続けてきました。現在も新たに生まれつつあることが紹介され、特に今回ピックアップされたものはCAE (物理シミュレーション等を用いる工学支援) に関する処理を高速化するCuDSSです。
このタイミングで2つの業界における巨大プレイヤーとの連携も発表されました。Cisco, T-Mobile, ODCなど複数社と連携しての無線ネットワーク構築と、GMと連携しての自動運転車の開発です。
自動運転の開発に関連して、安全性の確保を行うためのチップ・ソフトウェア・ツール・サービスを含む包括的なシステム「NVIDIA Halos」も発表されました。
このシステムは、グラフィック開発プラットフォーム「NVIDIA Omniverse」、忠実に再現された物理空間(生成型世界基盤モデル)を生成してロボットや自動運転の開発を実行するプラットフォーム「Cosmos」を使用します。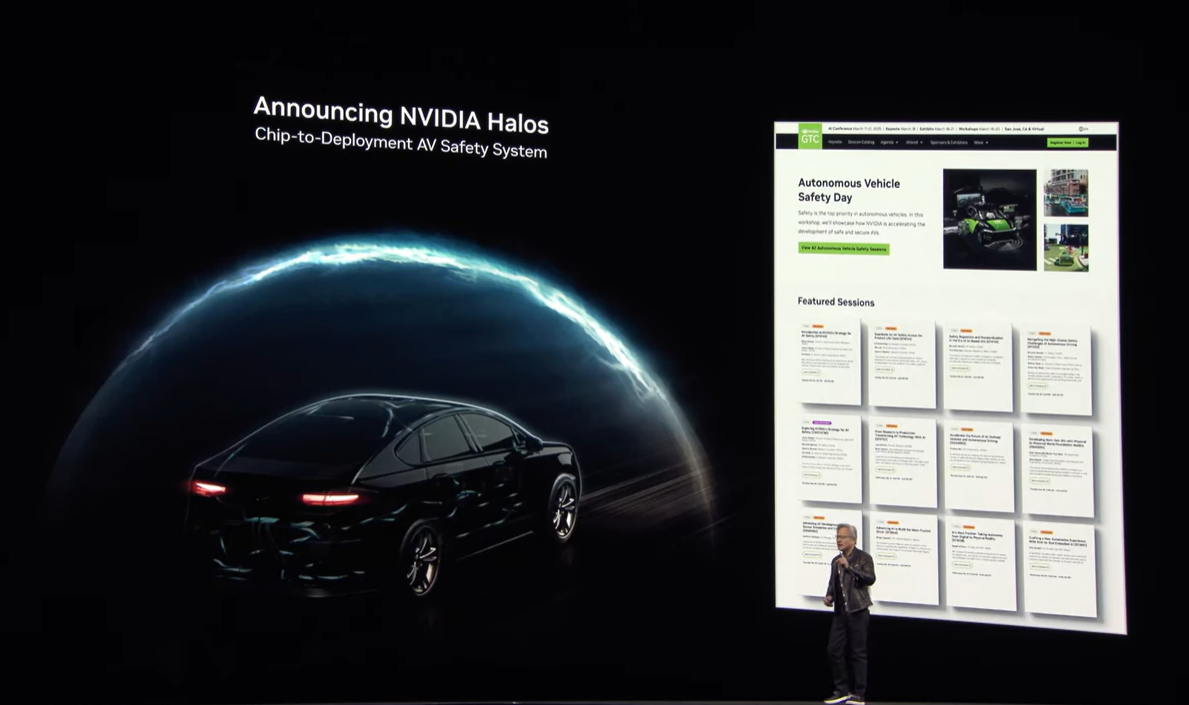
このような状況下で、最新のBlackwell世代のGPUを搭載するプロダクトがFull Production, つまり本格的な生産・展開に入ったことが示されました。
その主軸となるのが、Grace CPUを組み合わせた水冷式の 「GB200 NVL72」 です。ラック一本丸ごとのソリューションであり、各ハードウェアベンダーから提供されます。
Grace CPUが統合され、Blackwell GPU間はNVLinkで高速に接続されて一本のラックに収まる、完成された構成であることが強調されています。ここまでに説明された爆発的なコンピューティングの需要を受け止めるシステムとして、現在NVIDIAが提供している主力製品がこのGB200 NVL72です。
以上のような、AIが次々と進化を遂げながら産み出されていくプラットフォームは、近年巷で使われている呼称と同じくこのGTC Keynoteでも "AI Factory" と呼ばれていました。
推論を大幅に効率化する NVIDIA DYNAMO
AIのモデルが入力されたデータに対して出力を行うフェーズを "推論" と呼びますが、「より多くの入力に対して素早く推論する」ことと、「一つ一つの推論の精度を向上させる」ことの間には、トレードオフの関係があります。バランスをとりつつその成果を最大化する (下図のグラフを右上に膨らませる) ことが求められますが、簡単なことではありません。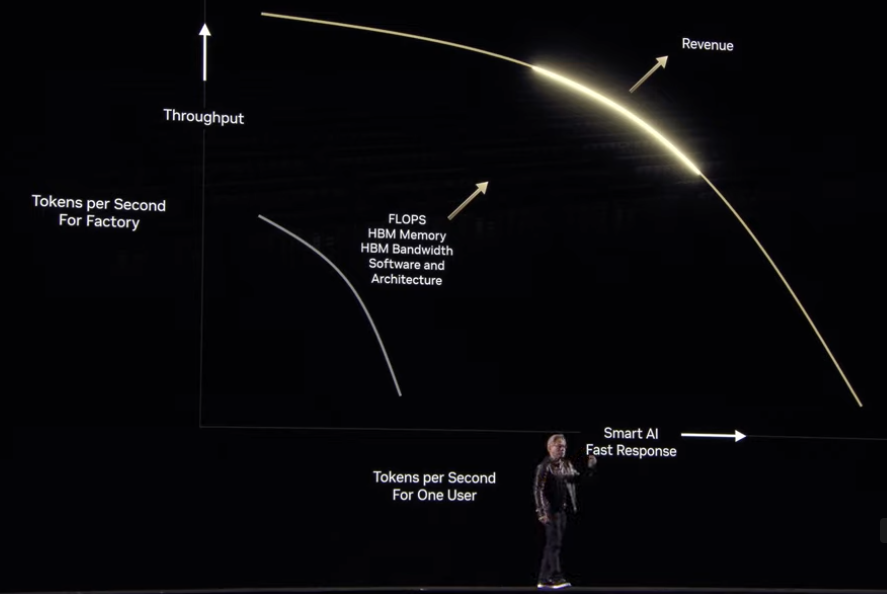
悩ましい状況の中、推論の手法は進化を続け、より多くのリソースを必要としています。段階的・論理的な思考を行うCoTなどの手法を用いた推論処理については前段でも説明されました。このような手法で推論を行うAIは Reasoning AI と呼称され、精度の向上のために重要なものであると評価されており、今後広く取り入れられていくことが予測されています。
Reasoning AIは渡された課題に対して多角的に解決策を検討するために、自身で課題を分解してトークンを生成し、何段階にも分けた推論を行ってその結果を出力します。従来の推論がある問いについて500トークン弱を処理することで回答しているのに対し、Reasoning AIは8000を超えるトークンによって回答していることが簡単なデモで示されました。
つまり、より膨大なコンピュートリソースの要求がある中で、前述のトレードオフの問題に対処していかなければならない、ということです。
NVIDIAがこの状況を受けて今回発表したのが「NVIDIA DYNAMO」です。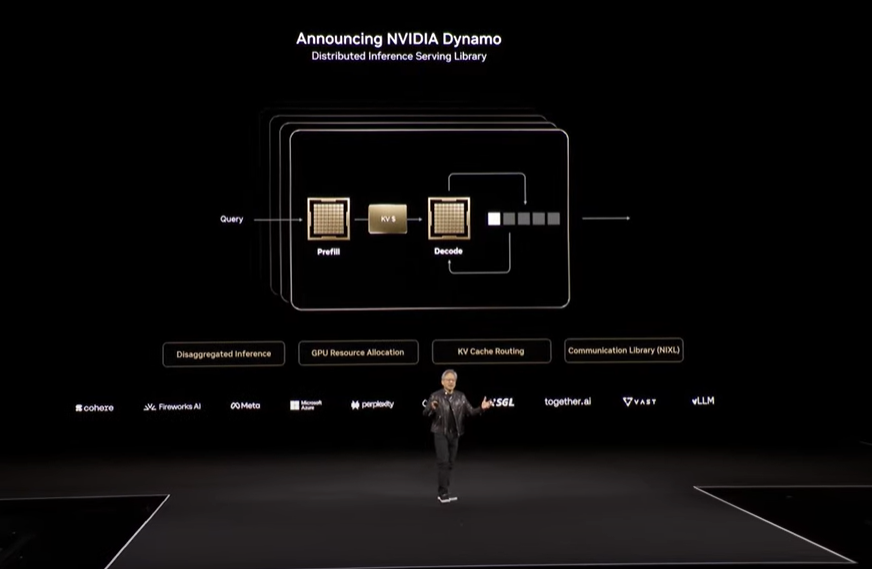
DYNAMOは、モデルが行う推論処理 (入力にあたるプレフィルと、出力にあたるデコード) をクラスタ内のGPUへ適切に分散させ、効率的な処理を実行します。また、以前の推論で生成・蓄積した知識 (KVキャッシュ) を複数のGPUに分散して配置し、最も役立つものへのルーティングを行って活用しつつ、不要なものはGPU上から除去して無駄のないリソースの利用を行うことを可能にします。
このDYNAMOに加え、量子化 (演算に使う数値の近似値をとって簡略化) も行うことで、Hopper世代と比べて性能は大きな飛躍をみせています。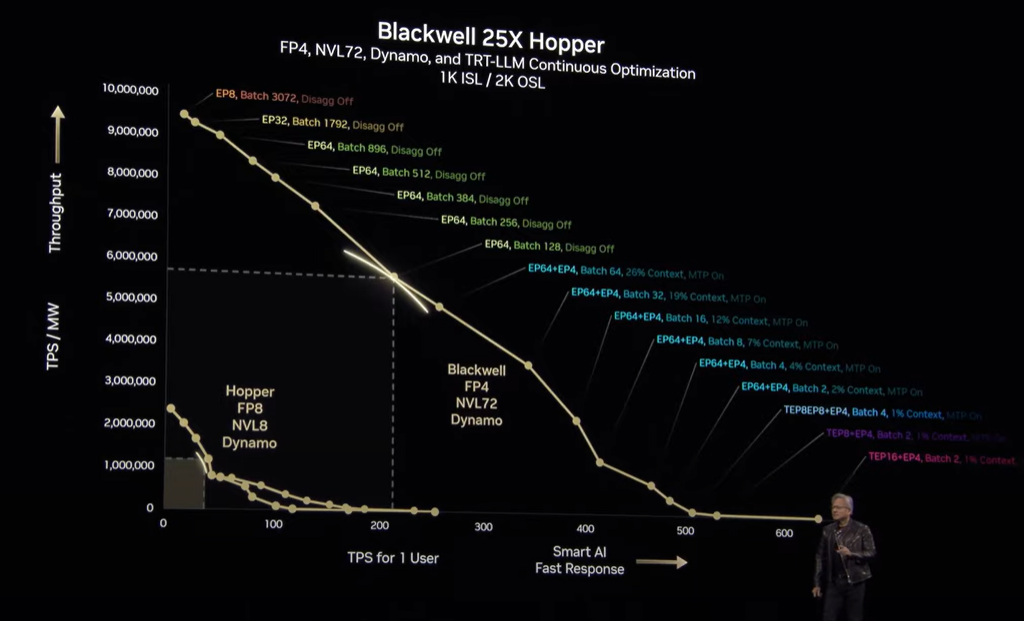
なおDYNAMOは、以前から存在する Triton Inference Server の後継と位置付けられており、提供形式としては NVIDIA Inference Microservices (NIM) のひとつとなります。つまり、実体はコンテナもしくはKubernetesのHelmチャート(コンテナ群)となるようです。
新しいプラットーフォームのロードマップ Blackwell Ultra, Vera Rubin
そして新しいGPUのロードマップも示されました。まずは既存のBlackwellを強化した 「Blackwell Ultra」です。
既存のBlackwellを用いたGB200 NVL72と比較すると、Blackwell Ultra NVL72 は1.5倍の性能を実現できることが示されました。
リリースは2025年の後半です。
少し先のロードマップとして、Vera世代のCPU, Rubin世代のGPUを統合したシステムである 「Vera Rubin NVL144」 も紹介されています。
名称にある数字はGPUの搭載数を示しており、搭載密度がさらに向上していることが分かります。
GPU間接続のNVLinkも、GB200の第5世代から第6世代にアップグレードされます。
2026年の後半にリリースが予定されています。
そしてさらに、「Rubin Ultra NVL576」も紹介されました。こちらは名称には入っていないですがVera世代のCPUも統合されており、Rubin世代のGPUはさっそく従来よりも強化されたかたちで採用される模様です。
NVLinkはさらにアップグレードされ、第7世代となるようです。
リリースは2027年の後半を予定してるようです。
RubinとHopperを比較すると、性能は900倍、一定性能あたりのコストは33分の1となるとのこと。間にあるBlackwellと比較しても、その向上度合いの高さがよく分かります。
シリコンフォトニクスを採用したネットワーキングを発表
GPU間を中心とした通信性能の要求も膨れ上がる中で、NVIDIAは新たに "シリコンフォトニクス" を採用したNICとスイッチを開発したことを発表しました。
シリコンフォトニクスとは、CPU, GPUなどのシリコン半導体で用いられる製造技術を応用して、大規模・高密度な「光回路」を構成する手法です。
なお光回路は、通信で用いられる光を電気に変換せずそのまま光として扱って処理をする機構のことで、通信設備などでは実用化がすすんでいる技術です。
NVIDIAの開発したNICは、CPO (Co-Packged-Optics) と呼ばれる光学パーツとシリコン半導体を同一パッケージにした構成となっているとのこと。
名称は「NVIDIA Photonics」です。
重要な要素技術としてMRM (Micro-Ring Modulator : マイクロリング変調器) があり、NVIDIAはこの研究に投資をつづけてきたといいます。TSMCが独自に持つプロセスにより製造されていることが明かされました。
これにより、NVIDIAの最新EthernetプロダクトであるSpectrum-Xシリーズ、およびInfiniBandプロダクトであるQuantum-Xシリーズは、通信速度が現行の800Gb/秒から1.6Tb/秒へアップグレードされます。
また、特に大きな効果として紹介されていたのが電力消費量の低減です。Jensen Huang氏が自らケーブルを手に取り、ひとつあたり30Wを消費する現行のトランシーバーを例に挙げて、これがGPUごとに6基、GPUが100万基あるとすると、180MWもの電力が通信に消費されていることが解説されました。シリコンフォトニクスの採用は、この電力消費を極小にまで圧縮することが可能な技術といえるようです。
企業・組織のコスト削減という意味に加えて、国家・地域の電力供給の逼迫に対処するうえでの重要性を強調した説明であったと考えることができます。
具体的なプロダクトのロードマップも示されました。
Spectrum-Xへの採用は2026年後半、Quantum-Xへの採用は2025年後半を見込んでいるようです。
そしてこのタイミングで、全体のロードマップが示されました。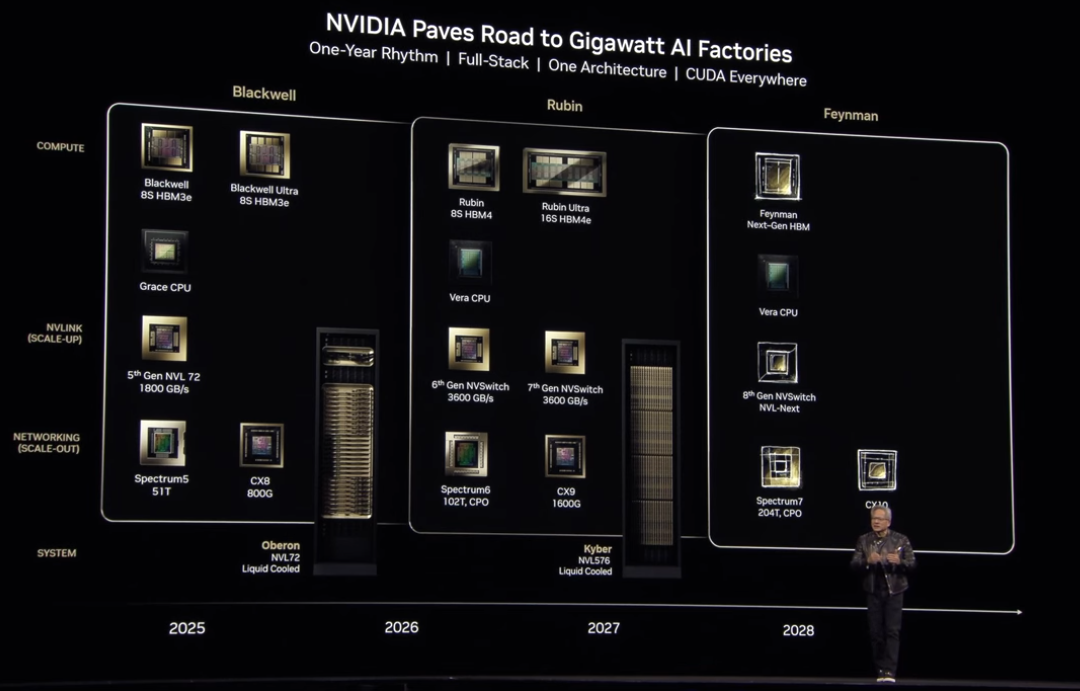
Vera Rubin のさらに先、2028年の位置にFeynmanが見えていますね。すでに予告されていた名称ですが、改めてGTCで正式に掲示されたことになります。
物理学者のリチャード・P・ファインマンからとった命名とみて間違いないかと思われます。ちなみに Vera Rubinはどちらも、アメリカの天文学者ヴェラ・クーパー・ルービンからの命名です。
超小型の「NVIDIA DGX Spark」、そして「DGX Station」復活
2025年1月6日のCESでProject DIGITSとして発表され、極めて小さな筐体にBlackwell GPUを搭載したプロダクトがついに販売開始されます。
発表以来、非常に話題性の高いトピックスとして扱われていましたので、もしかしたらこれが今回のGTCの "目玉" と思って期待されていた方も多かったかもしれません。
正式名称は「NVIDIA DGX Spark」となりました。Jensen Huang氏いわく、「(初期のDGXである) DGX-1のようなもの」ということで、128GBのGPUメモリを備えるなど筐体からは想像できないハイスペックなプロダクトです。NVIDIA NIMで提供される各種の推論サービスを十分に実行できる性能が備わっています。
さっそく、GTCの参加者向けの先行予約がアナウンスされていました。
画面左、Jensen Huang氏が右手に持っている筐体がDGX Sparkです。いかに小さいかが見てとれます。
また、液冷の高性能ワークステーションとして以前にNVIDIAから提供されていた、「DGX Station」が復活することも発表されました。
静音性が高く発熱も低いため「オフィスに置けるDGX」として、DGX Stationは研究・開発職の方々から人気を博していましたが、2022年末に一旦販売が終了していました。
このたびGrace CPU, Blackwell GPUを搭載し、大幅に強化されて復活したかたちとなります。
OEMとして各ハードウェアベンダーから販売される予定で、jensen Huang氏からはHP, DELL, Lenovo, ASUSがベンダーの例として挙げられていました。
どちらのプロダクトも、データサイエンティストとして研究・開発を行われる方々を中心に注目度・期待の度合いが高いようで、会場からは歓声が上がっていました。
なおこれらの詳細は弊社下山の番外編記事でご紹介させていただきますので、本記事では割愛させていただきます。
エンタープライズ向けプラットフォームに関するアップデート
主要なエンタープライズ (※) 向けストレージ・HCIベンダーに向けた、新しいリファレンスアーキテクチャも発表されています。
(※ このKeynoteの文脈の中では、"エンタープライズ" は「研究機関やGPUクラウド事業者など極端なGPU需要を抱える企業・組織 "以外" のプレイヤー」とご認識いただければ近しいニュアンスになるかと思います)
推論ワークロードの高速化につながるアーキテクチャで、具体的に対象となるワークロードとしては、NVIDIAが提供するLLMである Llama Nemotron のマイクロサービスや、それをベースとしたエージェントAIのリファレンスである NVIDIA AI-Q で開発されるサービスが挙げられています。
なおこのリファレンスアーキテクチャの構成要素としては、Blackwell GPU, Smart NICのBlueField-3, Spectrum-Xのネットワーキング、そしてNVIDIA AI Enterpriseが含まれています。
リファレンスアーキテクチャの名称は「AI Data Platform for Enterprise」です。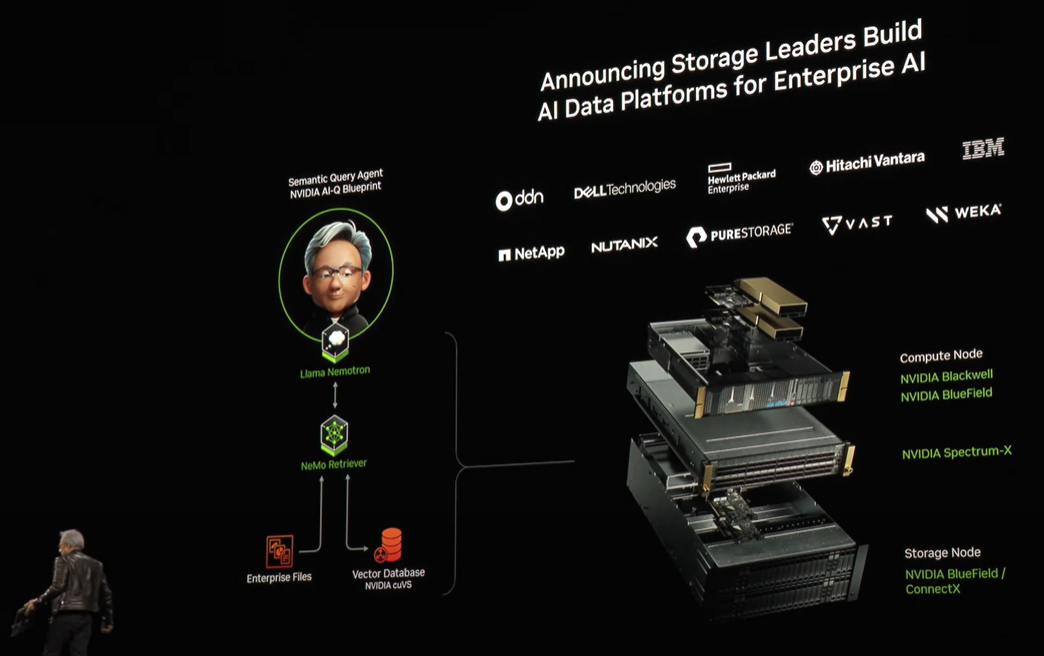
エンタープライズ向けAIシステムの提供にあたって、NVIDIAは多数の企業と提携していますが、その中でも今回特にピックアップされた企業は DELL Technologies です。
非常に多くの顧客、新規製品リリース、そして導入したコンピューターの性能値の合計、といった実績が示されました。
また、NVIDIAが提供する学習済み推論モデルLlama Nemotronの最新版、「Llama Nemotron Reasoning」もこのタイミングで発表されました。
すなわち、多段で論理的に推論を行うことによって高い精度を実現することができるようになります。
完全なオープンソースであり、NVIDIA NIMからも提供されるこのLLMは、DGX Spark上でも利用可能であると説明されました。
エージェント型のAIを開発するにあたってこれを活用することで、非常に精度の高いアウトプットを期待することができるといえます。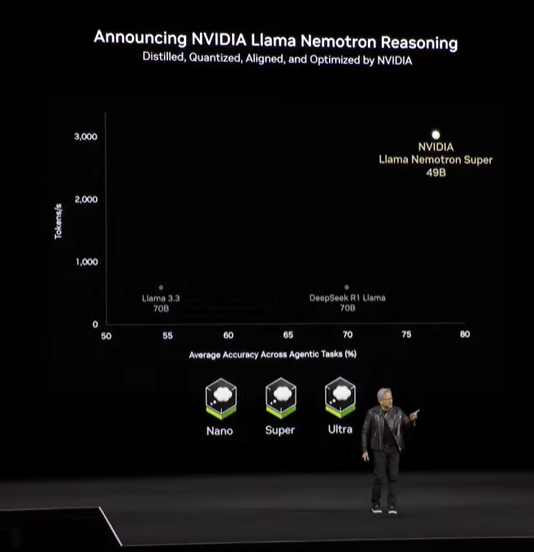
なおエージェント型AIの開発にあたっては、NVIDIAは世界中の多数の企業と連携して、サービスの開発を行っています。
例示されたのは、Accenture, Amdocs, AT&T, BlackRock, Cadence, Capital One, Delloite, Ernst & Young, Nasdaq, SAP, ServiceNow でした。
ロボティクスに関する発表 新しい物理エンジンをGoogle, Disneyと共に開発
最後にロボットに関する発表が行われました。
NVIDIAの提供するAI・グラフィックスのためのインフラ上で Omniverse, Cosmos, Isaac を活用することで、現実世界と非常に近い仮想空間でロボットのトレーニングを行うことは従来から可能でした。自動運転車と同様に、現実世界では再現が困難な事象も含めたトレーニングを、これまた現実世界では不可能な回数の試行数を繰り返す強化学習で行います。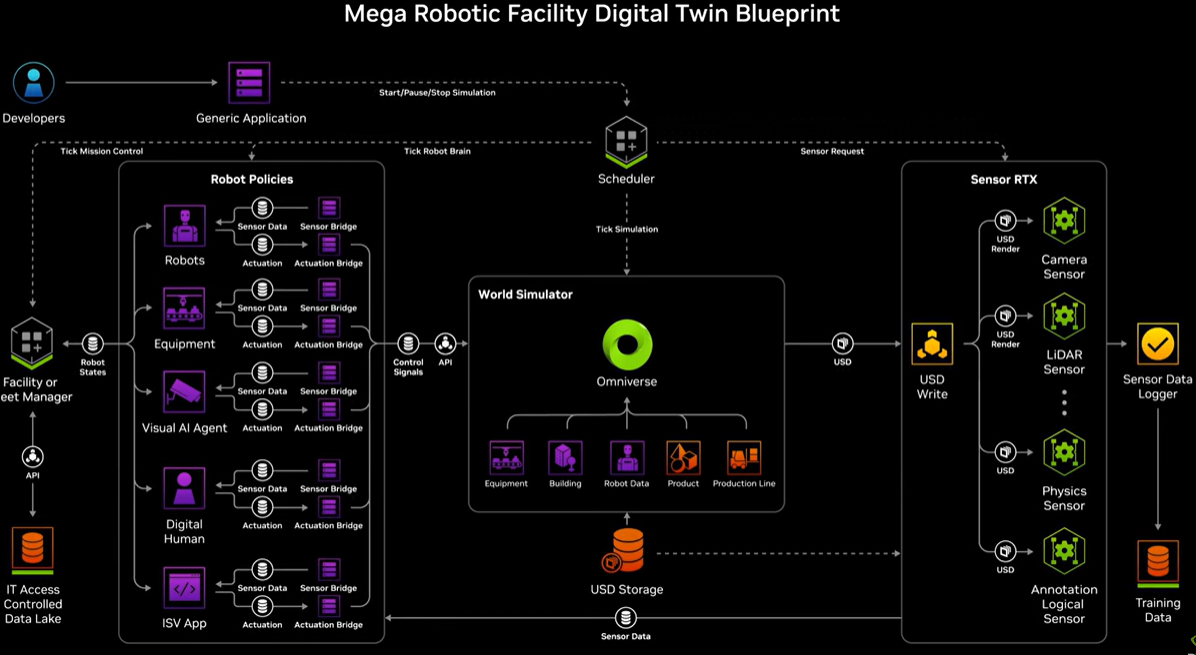
ここに、前段で登場したRLVR (数学的に検証可能な報酬を使って行う強化学習) も応用されます。ロボットの動作における報酬 (うまく動いているか) を正確にフィードバックするには、非常に高精度な物理エンジンが必要となることが説明されました。
この物理エンジンを、世界中のロボット開発者に広く使われている開発フレームワークに調和・統合して開発するための、Google DeepMind, Disney Research との提携が発表されました。
新しい物理エンジンは「Newton」と命名されています。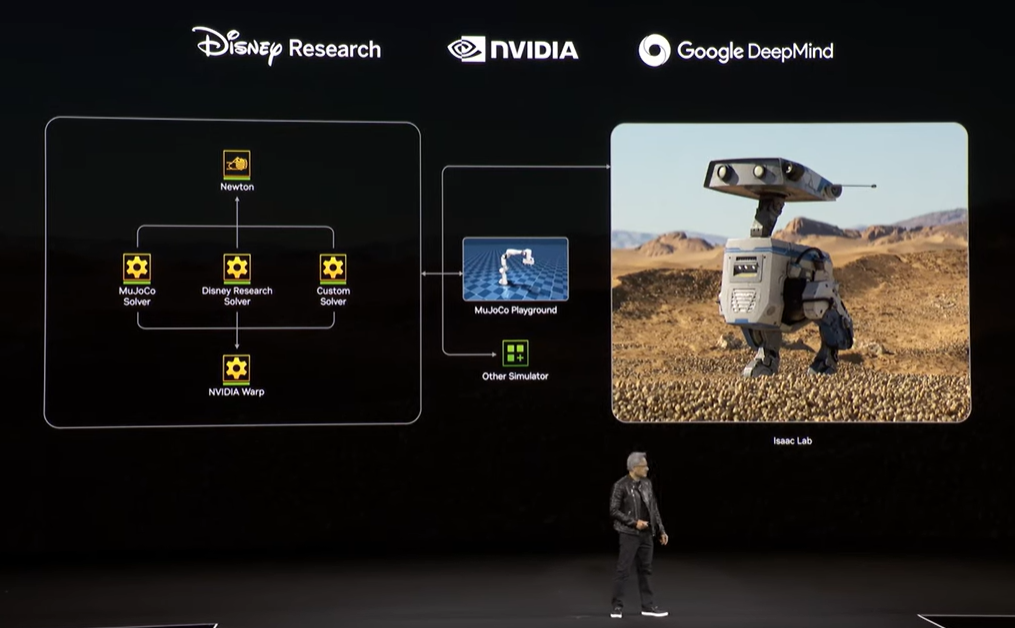
図中の中央にある青いアイコン、Google DeepMindの Mujoco が広く使われているフレームワークにあたります。
そしてDisney Researchは、このNewtonを利用する最初の企業となったということです。
GTCの舞台上へ実際にDisneyが開発した小さなロボット "Blue" が歩いてきて、Jensen Huang氏をじっと見つめながら言葉に反応している様子は、多くの方がとてもかわいらしく感じられるものだったと思います。
2時間以上に渡った基調講演は、この "Blue" にJensen Huang氏がランチタイムになったことを伝える一幕をもって終演を迎えました。
以上、長くなりましたがGTC Keynote Sessionのレポートでした。
GTC 2025における個々の発表についての詳細は、NVIDIAのNewsroomにまとめられたページがございます。
Keynoteで取り上げられたもの以外にも、皆さまにとって注目すべき発表が見つかるかもしれませんので、ここから参照いただければと思います。
少しでも本記事が皆さまのお役に立てば幸いでございます。
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
幸田 章 - Akira Koda -
NVIDIA製品を中心としたコンピューティング(グラフィックス, AI/HPC)とネットワーキング、VDI を含む仮想化、クラウド等のプリセールス・エンジニア業務に従事。
VMware vExpert 2015-2022