みなさん、こんにちは。
SB C&S 技術担当の河村です。
※本記事で説明するONTAPのバージョンは9.7になります。
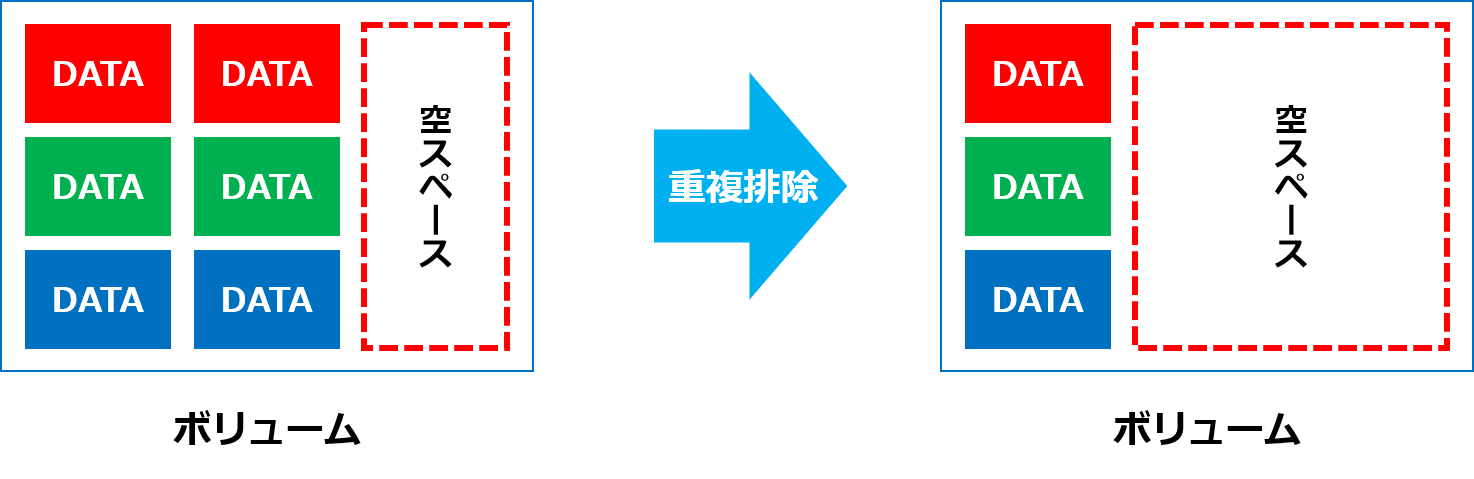
企業データを蓄積するにあたり、複数のファイルの間で重複データは必ず発生します。例えば、日々の業務を効率化するためにテンプレートから資料を作成するとなると、資料のベースとなる部分は当然同じデータが利用されます。また、バックアップにより保存されるデータも、ファイルの一部のみが更新されているだけで、データ全体を見ると重複した部分が多く存在します。
重複排除とは、図のように格納されるデータの中から重複する部分を自動検出し、排除する技術です。圧縮と同様、重複排除の仕組みも各メーカーによって様々です。
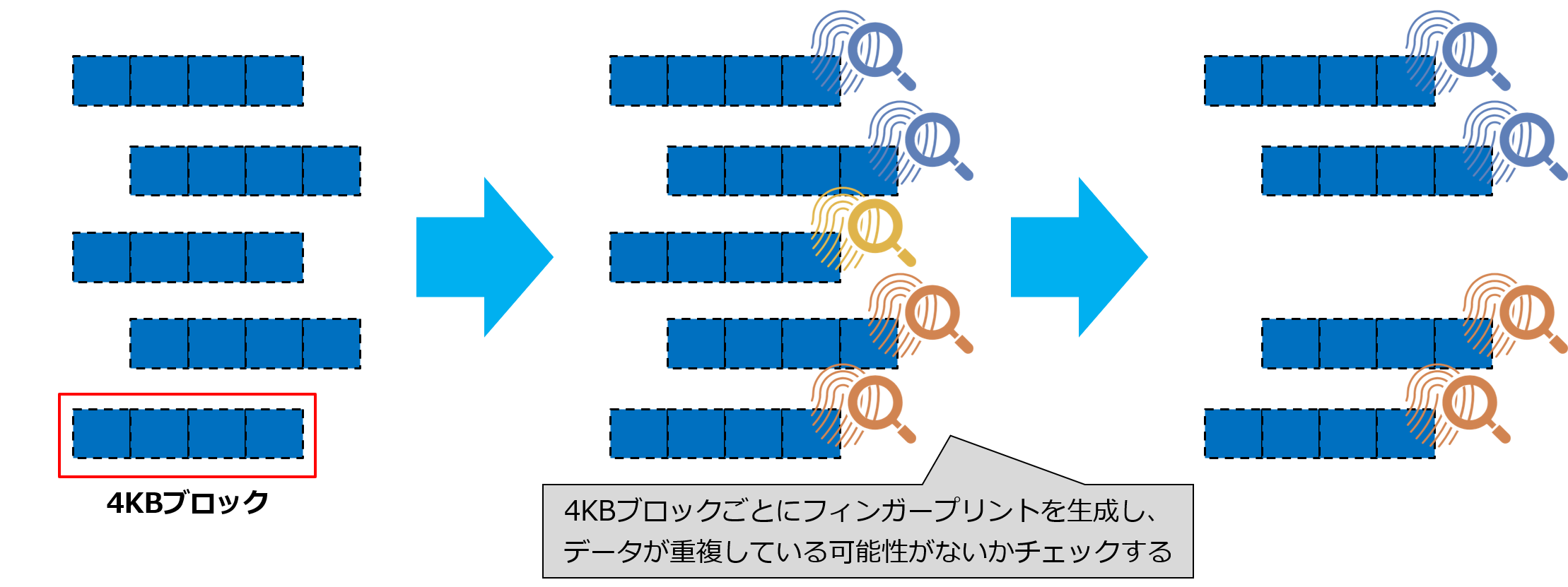
ONTAPのファイルシステムであるWAFLでは、データを4KBのブロックで管理し、ストレージデバイスに書き込みます。
ONTAPの重複排除は、データをWAFLの最小単位である4KBのブロックごとにチェックし、重複したデータを排除します。4KBという小さな単位でチェックすることにより、データの重複する確率が上がり、削減率も向上します。
重複判定の仕組みの1つとして、フィンガープリントを利用する手法があり、ONTAPでもこの手法が使われています。フィンガープリントとは、データから特定の決まりに基づいて生成される値です。ONTAPでは、ハッシュ計算によって生成します。この値は、元になるデータが同じであれば、何度生成しても同じ値となります。反対に元データが変わると生成される値も変わります。この性質からデータの改ざん防止や暗号化処理などに利用されたりします。
ONTAPでは、このフィンガープリントをブロックごとに生成して、重複するデータを排除しています。実データを比較するより、ハッシュ計算後のフィンガープリントを比較する方が、比較時間が早くなり、比較処理によるコントローラへの負荷も下げることができます。
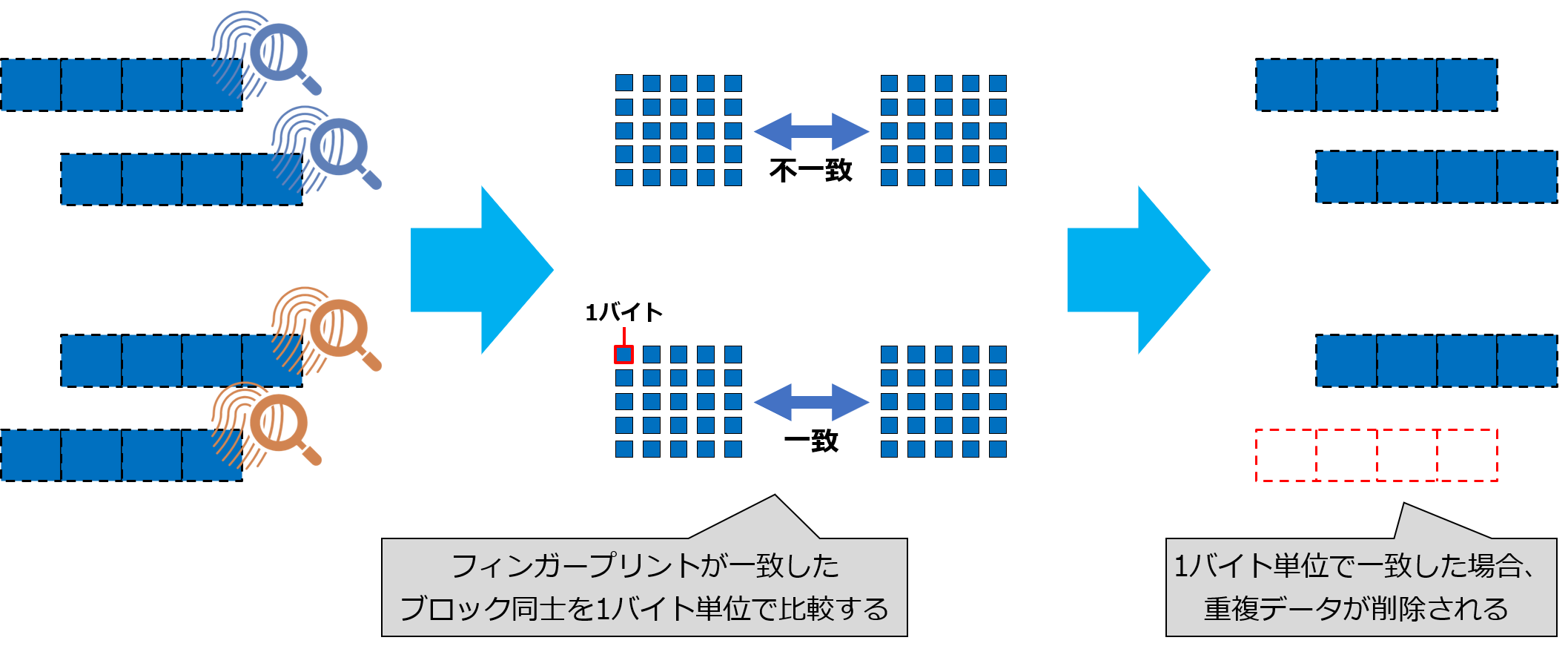
しかし、極稀に異なるデータから同じフィンガープリントが生成されてしまう場合があります。ONTAPではこの問題を回避するため、フィンガープリントが一致したブロックは、あくまで「重複している可能性があるブロック」と判定し、さらにそこからブロック内のデータを1バイト単位で比較して、全く同じである確認がとれて初めてデータを削除します。
このような信頼性の高い仕組みで実現することにより、これまでバックアップ環境などのセカンダリストレージのみに利用されていた重複排除機能を、他社に先駆けてプライマリストレージにも利用できるようにしました。
ONTAPの重複排除処理では下記の2つの実行タイミングが存在します。
・インライン処理
・ポストプロセス処理
ディスクへの書き込みI/Oの低減、ディスク容量、ピーク時間を避けた運用などの要件を考慮し、管理者はどちらか、または両方の実行タイミングを選択します。
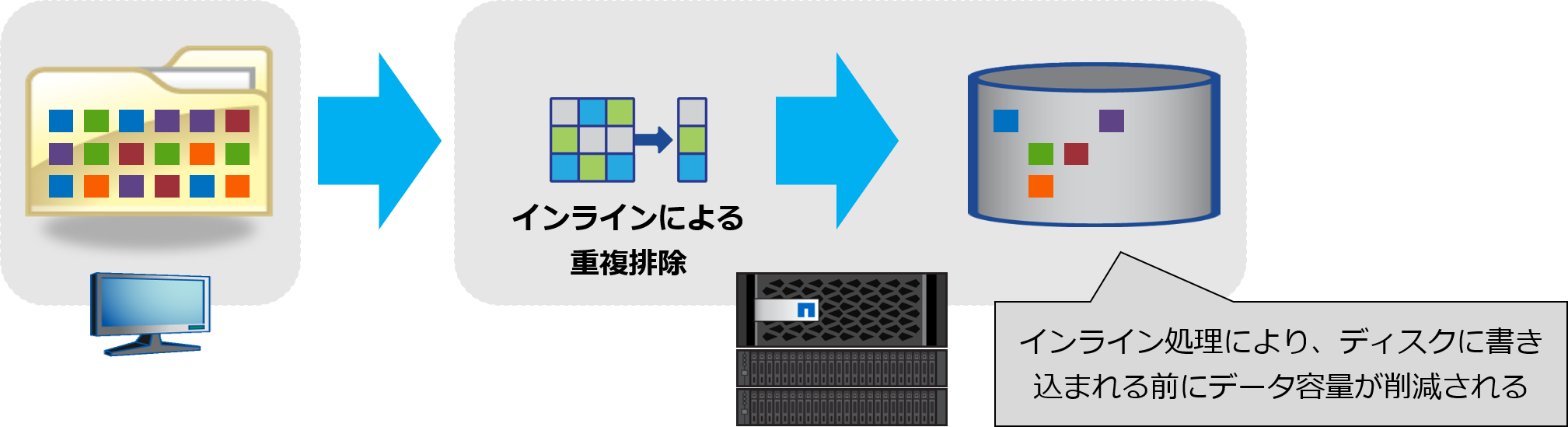
●インライン処理
インライン処理では、ストレージにデータが送信され、ディスクに書き込まれるまでの間に重複排除を実行します。ディスクに書き込まれる前に重複排除が完了しているため、ディスクへの書き込みI/Oの低減、ディスク消費スペースやSnapshotの容量削減に対する効果を即座に発揮することができます。
AFFシリーズでは、書き込み処理によるSSDの劣化を軽減するため、インライン処理による重複排除がデフォルトで有効になっています。
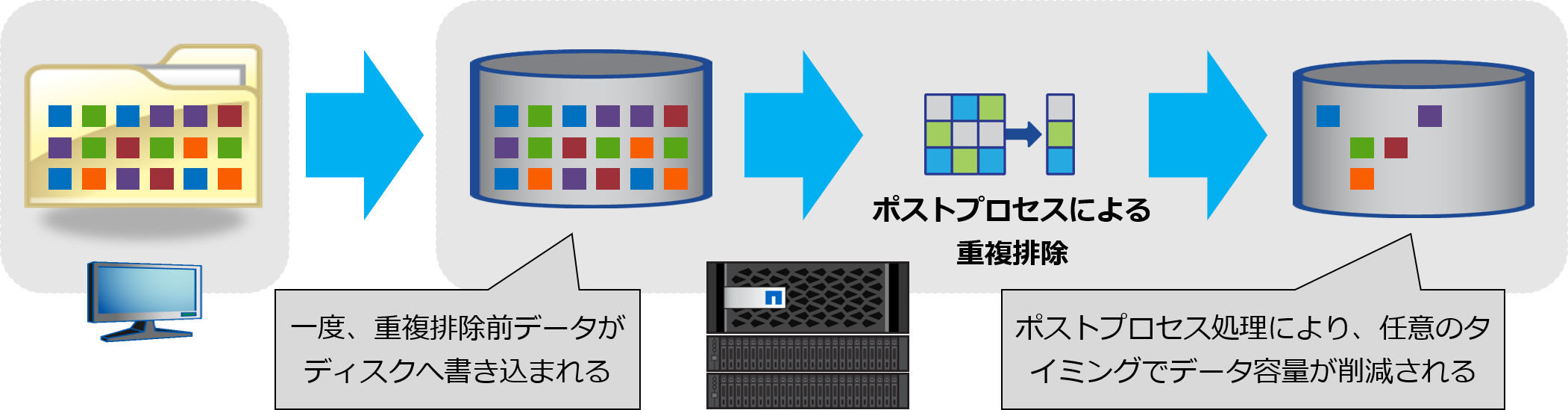
●ポストプロセス処理
ポストプロセス処理では、ストレージにデータが送信され、ディスクに書き込まれた後、設定されたスケジュールにより、定期的に重複排除を実行します。任意のタイミングで実行することができるため、運用のピーク時を避けて処理を実行することで、システムへの影響を最小限に抑えることができます。
AFFシリーズでは、ポストプロセス処理による重複排除を自動実行する機能も存在します。詳細については、次の章で説明します。
ONTAPの重複排除には下記の3種類が存在します。
・ボリューム重複排除
・アグリゲート重複排除(AFFシリーズのみ)
・自動バックグラウンド重複排除(AFFシリーズのみ)
FASシリーズでは、ボリューム重複排除のみサポートされています。
AFFシリーズでは、重複排除効果の要件を考慮し、管理者はいずれか、または全ての重複排除方法を選択します。
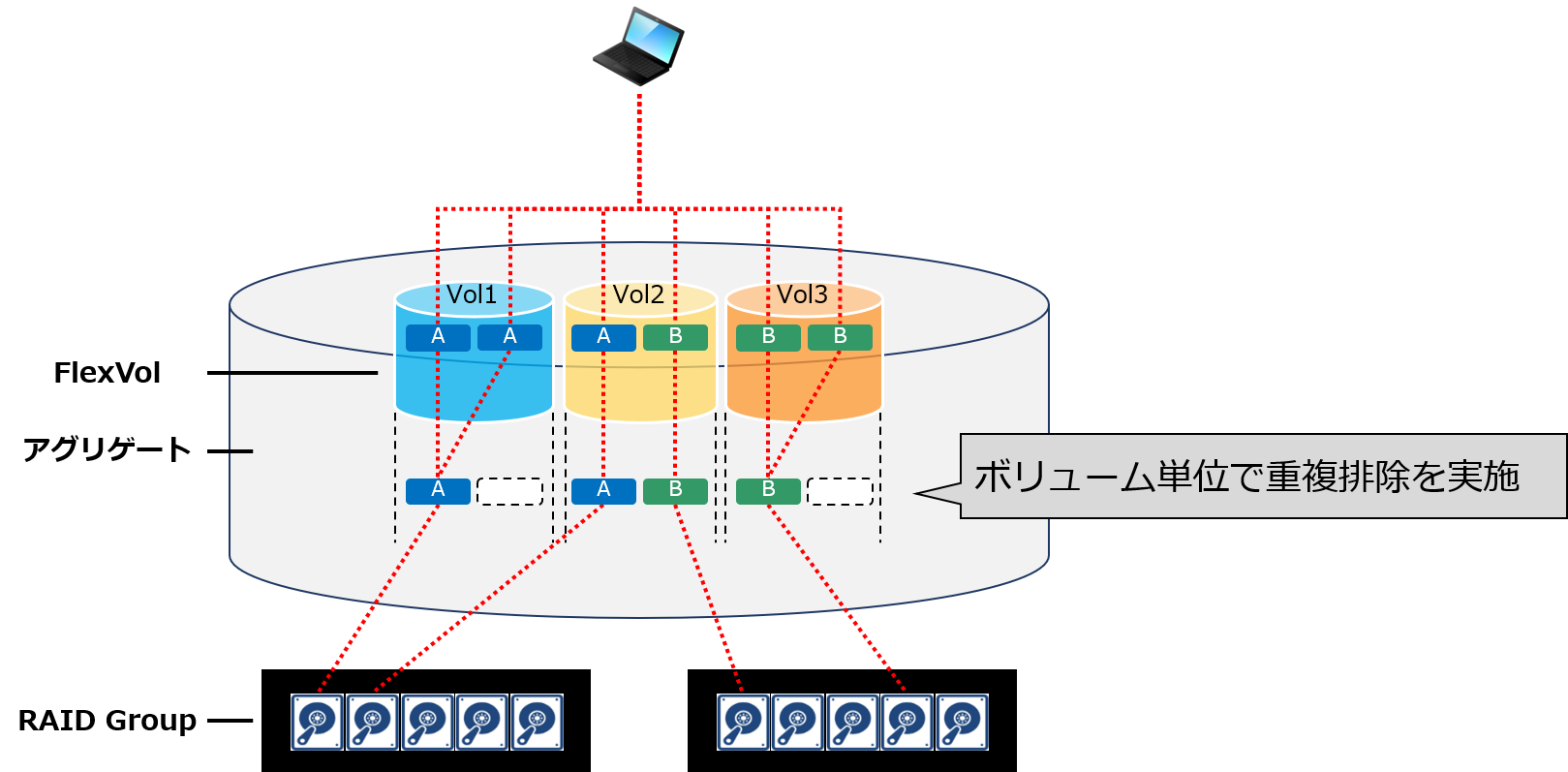
●ボリューム重複排除
図のように、クライアントから見れば、データはボリューム単位に分かれて書き込まれますが、実際はボリュームを構成する基となるディスクに対して分散されて書き込まれます。ボリューム重複排除では、ディスクに分散されるデータをボリューム単位で重複排除します。
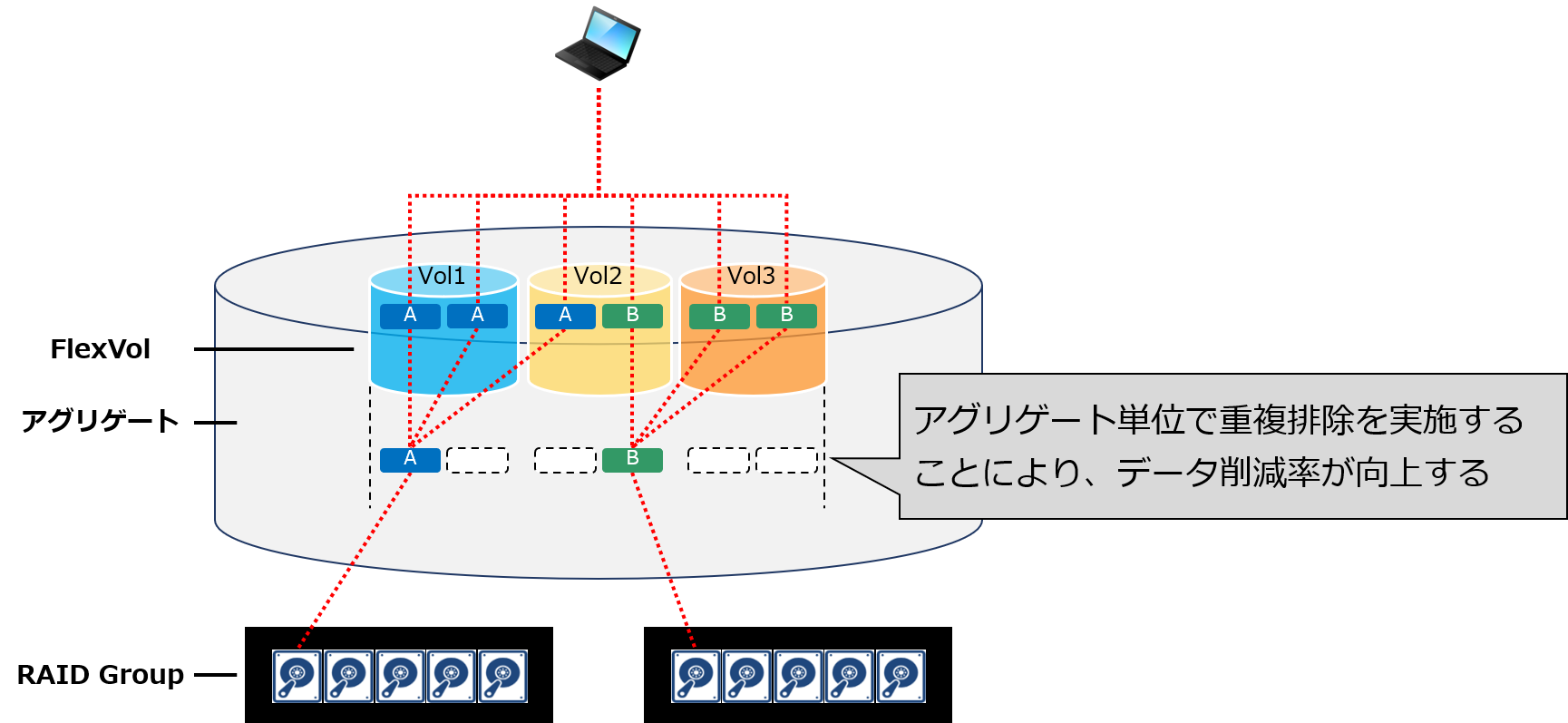
●アグリゲート重複排除(AFFシリーズのみ)
AFFシリーズでは、アグリゲート単位での重複排除も利用できるようになりました。これにより、ボリューム単位より広範囲な重複排除を行うことが可能となり、データの削減率がさらに向上します。
インライン処理によるアグリゲート重複排除は、ボリュームがシンプロビジョニングで作成されていることが前提となりますのでご注意ください。
ポストプロセス処理によるアグリゲート重複排除は、次に説明する自動バックグラウンド重複排除と同様、変更ログの値をトリガーとした自動実行となります。手動実行やスケジュール実行といった機能はありません。
●自動バックグラウンド重複排除(AFFシリーズのみ)
自動バックグラウンド重複排除は、変更ログが決められた閾値に達した際に、ポストプロセス処理によるボリューム重複排除を自動実行する機能です。変更ログとは、ボリューム内のデータが追加や上書きなどにより変更される際に出力されるログとなります。
また、自動バックグラウンド重複排除では、ボリュームの20%がスキャンされた際に15%の削除効率が見込みない場合、ボリュームに対してこの機能を無効化します。
これにより、システムにかかるオーバーヘッドを低減しています。
この機能は、ポストプロセス処理によるボリューム重複排除が設定されていない全てのボリュームにおいて、デフォルトで有効となっています。
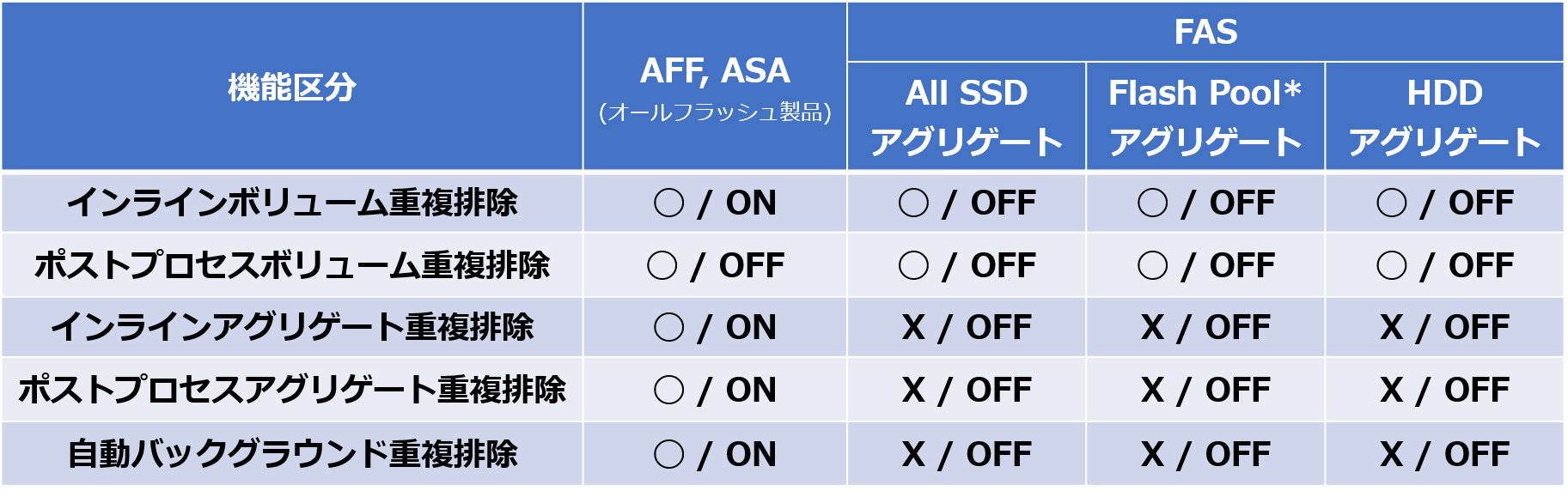
重複排除は、NetAppの全ての製品で利用することができます。
、以下の表をご参照ください。
(2021年3月現在)
FAS All SSD・・・FASシリーズのアグリゲートを全てSSDで構成
Flash Pool・・・SSDとHDDを組み合わせ、アクセス頻度の高いホットデータをキャッシュデータとしてSSDへ配置する構成
また、重複排除機能は、ONTAPに標準搭載されている機能です。
データ圧縮と同様、これだけの機能が無償利用できるというのはNetAppの強みの1つではないかと思います。
重複排除は、Readの割合が高く、同一データを複数持つシステムに適しています。
例えば、「仮想基盤」や「VDI」のような環境では、同じOSで動作するサーバやクライアントが多ければ多いほど重複するデータも多くなります。NetApp社が出したシナリオデータでは、仮想基盤、VDI環境にて、70%もの容量を削減できたという報告があります。
※あくまでシナリオデータ上の結果のため、実際に導入する環境によって数値が変わる可能性があることについてご注意下さい。
重複排除は、前回解説したデータ圧縮 と併用できます。また、SnapMirrorなどのレプリケーション機能でも重複排除したデータを保持したまま同期することが可能です。
ONTAPの各種機能と併せて利用することで、より最適化された形でのデータ管理を提供できます。
・データを4KBという小さなブロックごとに重複排除する
・フィンガープリントと1バイト単位の比較により、信頼性のある重複排除を実現する
・他社に先駆けてプライマリストレージとして重複排除をサポートした
・ディスクへの書き込みI/Oを低減するインライン処理と運用ピーク時を避けて
任意のタイミングで実行できるポストプロセス処理がある
・AFFシリーズでは、ボリューム単位の他にアグリゲート単位の重複排除が利用できる
・AFFシリーズでは、自動バックグラウンド重複排除により、ポストプロセス処理による
ボリューム重複排除を自動実行できる
・データ圧縮と併用できる
・SnapMirrorなどのレプリケーション機能においても重複排除されたデータが継承される
【SB C&S NetAppプロモーションTwitterアカウント】
NetAppに関するさまざまな情報を公開しています。
皆様フォロー宜しくお願いいたします。
TwitterアプリからはこちらのQRコードもどうぞ。