


【Tips】では、Automation Anywhere Automation 360 の開発に役立つヒントや工夫、
様々なテクニックをご紹介していきます。
今回は、正規表現の便利な使い方として、
「正規表現を利用した文字列抽出方法」をご紹介します。
※本記事はAutomation 360 v.24 (Build 13343) 時点での情報です。
目次
3.正規表現を利用した文字列抽出方法(方法のみ確認したい方はこちらをクリック)
1.正規表現の概要
正規表現とは、「文字列の表現方法」となっております。
しかし、文字列の表現方法と説明されてもいまいちピンとこないと思いますので、
一つ例題を見ていただきたいと思います。
【例題】
Aさん、Bさん、Cさんの文章から「郵便番号」を検索したい場合、
どのようにすれば良いでしょうか?
Aさん:自宅の住所は「〒111-1234 ○○県○○市...」です
Bさん:私の家は、2225678 ××県××市...となっております。
Cさん:333-1234△△県△△町...
3人とも文章の書き方がバラバラで、さらに郵便番号の「-(ハイフン)」の有無まで違います。
これでは検索することが難しそうですが、そこで登場するのが正規表現となります。
一旦難しい説明は後回しにしますが、
郵便番号は正規表現で下記のように表すことができます。
(下記は一例ですので他にも様々な書き方があります)
\d{3}-?\d{4}
上記の正規表現を用いて Automation Anywhere の「文字列:置換」アクションを試してみると、
下図のような結果となります。
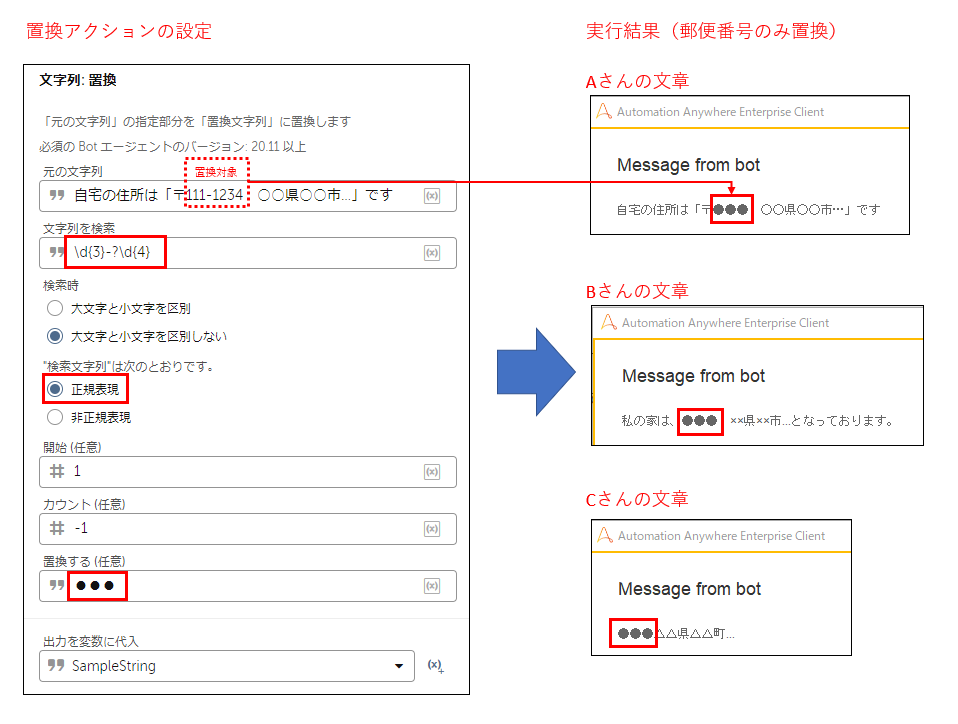
どの文章でも郵便番号のみ置き換えられていることが確認できます。
今回は郵便番号を例に用いましたが、
上記のように、わずかに条件の違う文字列を、
一つの文字列で表現する方法が正規表現と呼ばれるものとなります。
2.正規表現のメタ文字
正規表現ではメタ文字と呼ばれる特殊文字を利用して様々な文字列を表現します。
ここでは、主なメタ文字の紹介をしていきます。
■一覧
| 文字 | 読み方 | 機能 |
|---|---|---|
| . | ドット | 任意の1文字 |
| ^ | キャレット | 行の先頭 |
| $ | ダラー | 行の最後 |
| * | アスタリスク | 直前の文字を0回以上繰り返す |
| + | プラス | 直前の文字を1回以上繰り返す |
| ? | クエスチョンマーク | 直前の文字を0回または1回のみ繰り返す |
| {} | ナミカッコ | 直前の文字をナミカッコ内の数値分繰り返す |
| [] | カドカッコ | カドカッコ内のいずれかの1文字 |
| | | パイプ | OR条件の指定 |
| () | カッコ | 複数の文字のグループ化 |
| .* | ドットアスタリスク | 0文字以上の1段落分の文章(ドットとアスタリスクの組合せ) |
| \d | - | 数字1文字 |
| \D | - | 数字以外の1文字 |
| \w | - | 全てのアルファベット、数字、アンダースコアのいずれか1文字 |
| \W | - | 全てのアルファベット、数字、アンダースコア以外のいずれか1文字 |
| \s | - | スペース、タブ、改行などの空白文字 |
| \S | - | 空白文字以外の全ての文字 |
| \r | - | OS 9までのMacなどで使用されていた改行コード |
| \n | - |
UNIX、OS 10以降のMacなどで使用されている改行コード ※Automation Anywhere のアクションではこれを使用します |
| \r\n | - | Windowsなどで使用されている改行コード |
| \t | - | タブの空白文字 |
■各メタ文字の概要
| 文字 | 読み方 | 機能 |
|---|---|---|
| . | ドット | 任意の1文字 |
改行以外の何でも良い1文字にマッチします。
例えば、
「..県」で検索する場合、「千葉県」にはマッチしますが、「神奈川県」にはマッチしません。
| 文字 | 読み方 | 機能 |
|---|---|---|
| ^ | キャレット | 行の先頭 |
行の先頭を表現する際に使用します。
例えば正規表現を「^りんご」とした場合、
「りんご ぶどう」という文章の「りんご」はマッチしますが、
「ぶどう りんご」という文章の「りんご」にはマッチしません。
| 文字 | 読み方 | 機能 |
|---|---|---|
| $ | ダラー | 行の最後 |
行の最後を表現する際に使用します。
例えば正規表現を「りんご$」とした場合、
「ぶどう りんご」という文章の「りんご」はマッチしますが、
「りんご ぶどう」という文章の「りんご」にはマッチしません。
| 文字 | 読み方 | 機能 |
|---|---|---|
| * | アスタリスク | 直前の文字を0回以上繰り返す |
直前の文字の0回以上の繰り返しを表現します。
0回以上という意味が少し分かりづらいですが、
例えば、正規表現を「abc*」( c の0回以上の繰り返し)とした場合、
「ab」「abc」「abcc」「abccc」などにマッチします。
「ab」にもマッチする理由は、
「 c が0回 = c がない場合」にもマッチするという条件になっているためです。
| 文字 | 読み方 | 機能 |
|---|---|---|
| + | プラス | 直前の文字を1回以上繰り返す |
直前の文字の1回以上の繰り返しを表現します。
例えば、正規表現を「abc+」( c の1回以上の繰り返し)とした場合、
「abc」「abcc」「abccc」などにマッチします。
アスタリスクと違い「1回以上」という条件のため、
「ab」のみのように「c」が存在しない場合はマッチしません。
| 文字 | 読み方 | 機能 |
|---|---|---|
| ? | クエスチョンマーク | 直前の文字を0回または1回のみ繰り返す |
直前の文字の0回または1回のみの繰り返しを表現します。
例えば、正規表現を「abc?」( c の0回または1回のみの繰り返し)とした場合、
「ab」「abc」のどちらかのみにマッチします。
| 文字 | 読み方 | 機能 |
|---|---|---|
| {} | ナミカッコ |
直前の文字をナミカッコ内の数値分繰り返す |
直前の文字の繰り返し回数を指定するときに使用します。
例えば正規表現を「10{3}円」とした場合、
「1000円」にはマッチしますが、「100円」や「10000円」にはマッチしません。
また、「10{1,3}円」とした場合、
「0を1回以上3回以下繰り返す」という条件になり、
「10円」、「100円」、「1000円」にマッチするようになります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| [] | カドカッコ | カドカッコ内のいずれかの1文字 |
カドカッコ内のいずれかの1文字にマッチさせたい場合に使用します。
使用方法が複数あるため注意が必要です。
【使用方法①】
正規表現を「 天気は[晴雨] 」とした場合、
「天気は晴」と「天気は雨」の両方にマッチします。
【使用方法②】
正規表現を「 天気は[^晴雨] 」のようにカドカッコ内の先頭に
「 ^(キャレット)」を付けた場合、「晴と雨以外の1文字」という条件になります。
そのため、「天気は曇」などにマッチするようになります。
【使用方法③】
正規表現を [a-z] とした場合、
小文字の半角アルファベット「aからz」までのいずれか1文字にマッチします。
全角アルファベットにマッチさせる場合は「a」と「z」を全角にします。
同様に、 [A-Z] なら大文字のアルファベットいずれか1文字、
[0-9] なら0~9までの数字いずれか1文字、
[ぁ-ん] なら濁音・半濁音を含む全てのひらがないずれか1文字、
※小文字の「ぁ」から始まることがポイントです
[ァ-ヴ] なら濁音・半濁音を含む全ての全角カタカナいずれか1文字にマッチします。
※小文字の「ァ」から始まることがポイントです
半角カタカナは注意が必要で、
濁音・半濁音を含む全ての半角カタカナの場合は、
[ヲ-゚]+ という書き方になります。
※ただし、1文字ではなく連続した半角カタカナの文字列に
マッチしてしまうので注意が必要です。
これは半角カタカナの濁点・半濁点が独立した1文字となっているためです。
濁音・半濁音を含まない全ての半角カタカナいずれか1文字にマッチさせたい場合は、
[ヲ-゚] という書き方になります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| () | カッコ | 複数の文字のグループ化 |
複数の文字を1つのグループにまとめるときに使用します。
例えば、正規表現を「(ちゃ)+っと」とした場合、
「ちゃ」の1文字以上の繰り返しとなるため、
「ちゃっと」や「ちゃちゃっと」などにマッチします。
また、グループ化した文字列はカッコの数分、「$1」「$2」・・・という形式で、
扱うことができるようになります。
例えば、正規表現を「(..県)(..市)」として「千葉県千葉市」にマッチした場合、
「$1」には「千葉県」、「$2」には「千葉市」が代入されます。
| 文字 | 読み方 | 機能 |
|---|---|---|
| | | パイプ | OR条件の指定 |
複数の正規表現で同時に検索したい場合に使用します。
例えば、正規表現を「10{2}円|10{3}円」とした場合、
「100円」と「1000円」の両方にマッチします。
また、「グループ化」と組み合わせることで、「2文字以上の文字列」の複数条件検索が可能となります。
例えば、正規表現を「天気は(晴れ|くもり)」とした場合、
「天気は晴れ」と「天気はくもり」の両方にマッチします。
カドカッコでは1文字のみという制限がありましたが、
カッコとパイプを組み合わせることで2文字以上の文字列に対応できます。
| 文字 | 読み方 | 機能 |
|---|---|---|
| .* | ドットアスタリスク | 0文字以上の1段落分の文章(ドットとアスタリスクの組合せ) |
1段落分の文章を表現するときに使用します。
ドット(改行以外の何でも良い1文字)+ アスタリスク(直前の文字を0回以上繰り返す)
の組み合わせとなっているため、文章中に改行が入る場合は注意が必要です。
0文字以上の繰り返しとなっているため、文字がない場合もマッチします。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \d | - | 数字1文字 |
\ (バックスラッシュ)と d の組み合わせで一つのメタ文字をなっており、
0-9の数字1文字を表すときに使用します。
正規表現の [0-9] と同じ意味になります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \D | - | 数字以外の1文字 |
数字以外の1文字を表すときに使用します。
正規表現の [^0-9] と同じ意味になります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \w | - | 全てのアルファベット、数字、アンダースコアのいずれか1文字 |
全てのアルファベット、数字、アンダースコアのいずれか1文字を表すときに使用します。
正規表現の [a-zA-Z0-9_] と同じ意味になります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \W | - | 全てのアルファベット、数字、アンダースコア以外のいずれか1文字 |
全てのアルファベット、数字、アンダースコア以外のいずれか1文字を表すときに使用します。
正規表現の [^a-zA-Z0-9_] と同じ意味になります。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \s | - | スペース、タブ、改行などの空白文字 |
スペース、タブ、改行などの空白文字を表すときに使用します。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \S | - | 空白文字以外の全ての文字 |
空白文字以外の全ての文字を表すときに使用します。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \r | - | OS 9までのMacなどで使用されていた改行コード |
改行コードのキャリッジリターン(CR)を表すときに使用します。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \n | - | UNIX、OS 10以降のMacなどで使用されている改行コード |
改行コードのラインフィード(LF)を表すときに使用します。
※Automation Anywhereの正規表現で改行コードを表す場合は、「\n」を使用します。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \r\n | - | Windowsなどで使用されている改行コード |
改行コードのキャリッジリターン+ラインフィード(CRLF)を表すときに使用します。
| 文字 | 読み方 | 機能 |
|---|---|---|
| \t | - | タブの空白文字 |
タブの空白文字を表すときに使用します。
■メタ文字のエスケープ
URLやメールアドレスを検索するときなどに、
「.(ドット)」等のメタ文字を通常の文字として扱いたい場合は、
「\.」のようにメタ文字の前に「\(バックスラッシュ)」を付けます。
例えば、正規表現を「abc.com」とした場合、
「abcdcom」など意図しない文字列にもマッチしてしまいます。
このような場合は正規表現を「abc\.com」とすることで、
「abc.com」という文字列のみにマッチするようになります。
3.正規表現を利用した文字列抽出方法
冒頭の例題では、郵便番号の置き換えを行いましたが、
ここでは郵便番号の抽出を行う方法を説明していきます。
まずは例題の内容を再確認します。
【例題】
Aさん、Bさん、Cさんの文章から「郵便番号」を検索したい場合、
どのようにすれば良いでしょうか?
Aさん:自宅の住所は「〒111-1234 ○○県○○市...」です
Bさん:私の家は、2225678 ××県××市...となっております。
Cさん:333-1234△△県△△町...
また、郵便番号の正規表現も再確認します。
(下記は一例ですので他にも様々な書き方があります)
\d{3}-?\d{4}
(補足)正規表現の解説
▶ \d{3} ⇒ 数字3文字を表す
▶ -? ⇒ -(ハイフン)が0回(ない場合)または1回(ある場合)の両方を表す
▶ \d{4} ⇒ 数字4文字を表す
それでは抽出を行う方法ですが、
Automation Anywhereでは「文字列:置換」アクションを使用します。
実行する内容としては下記になります。
手順①:文章全体にマッチする正規表現を作成
手順②:抽出したい文字列を () で囲みグループ化
手順③:グループ化した文字列で全ての文章を置き換え
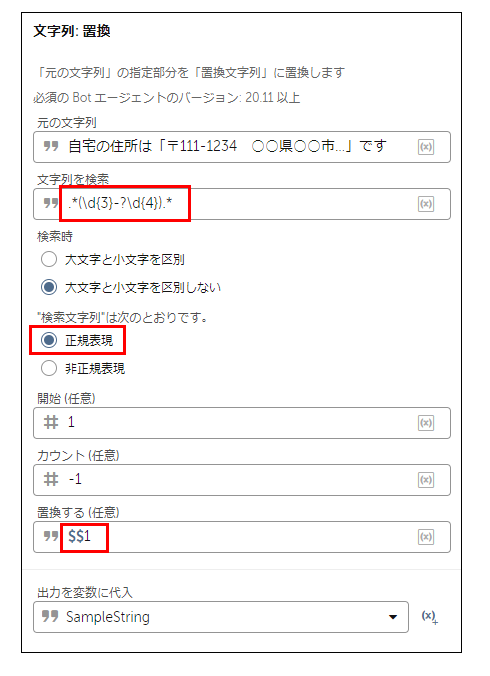
手順①:文章全体にマッチする正規表現を作成
「文字列:置換」アクションをワークフローに挿入し、下図のように下記3点を設定します。
【元の文字列】 ⇒ Aさんの文章を貼り付け
【文字列を検索】 ⇒ 下記の正規表現を貼り付け
【検索文字列を次の通りです。】 ⇒ 正規表現を選択
.*\d{3}-?\d{4}.*
※正規表現のチェックには「正規表現 チェック」などで検索の上、
各種チェックツールをご使用ください
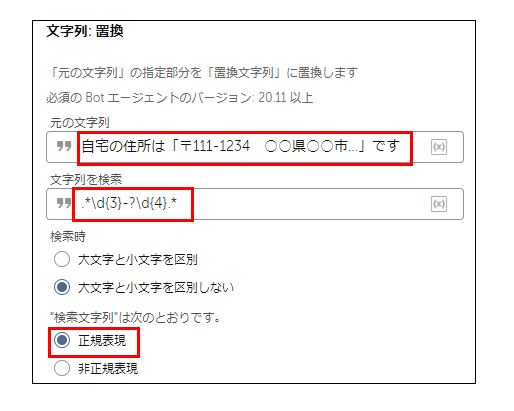
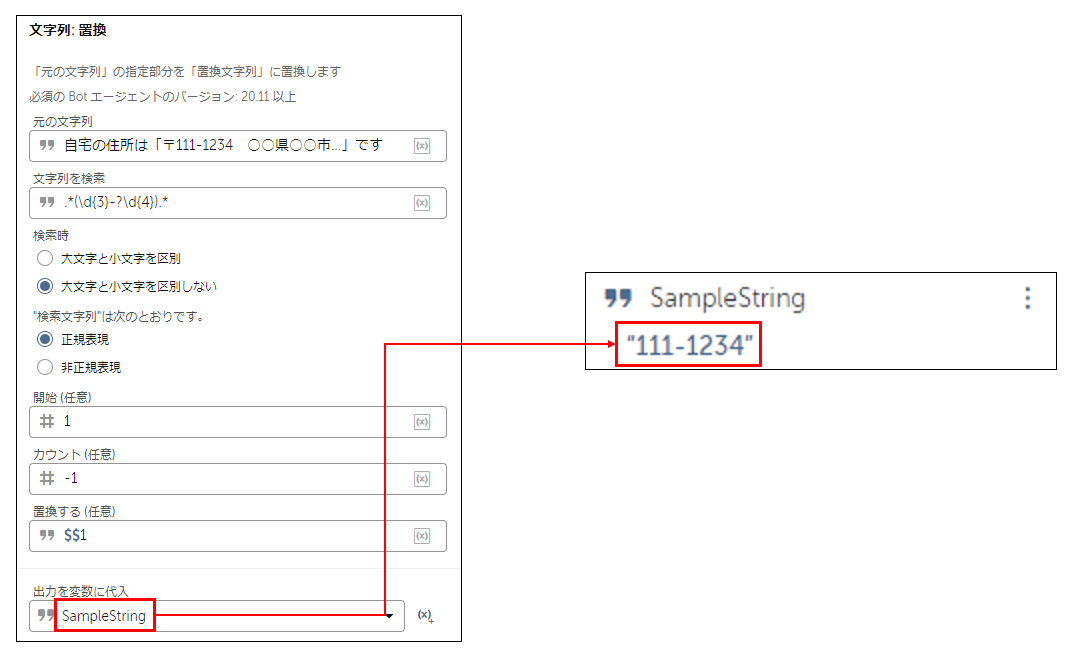
手順②:抽出したい文字列を () で囲みグループ化
今回は郵便番号を抽出するため、 \d{3}-?\d{4} を () で囲みます。
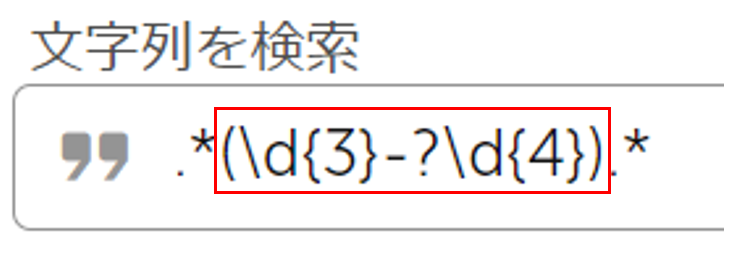
手順③:グループ化した文字列で全ての文章を置き換え
「置き換えする(任意)」に「$$1」と入力します。
※「$$1」は Automation Anywhere 独自の書き方となります。
Automation Anywhere では変数が「$」で囲まれるという仕様の関係上、
「$」をエスケープするためには「$$」という書き方をしなければなりません。
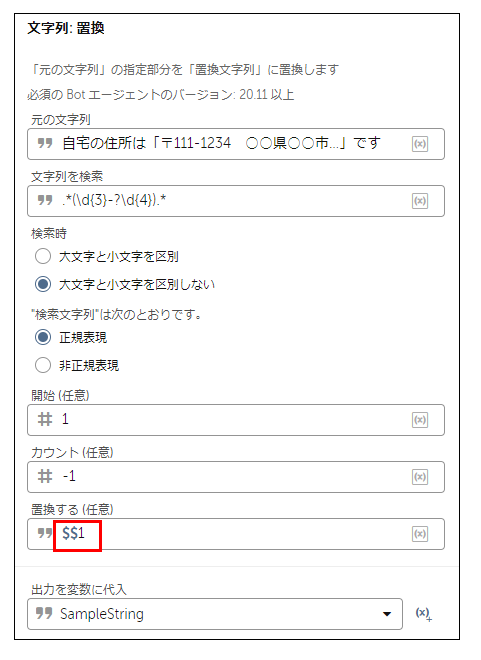
置換結果を出力する変数を設定しBotを実行すると、
下図の結果となり郵便番号のみ抽出されていることが確認できます。
(元の文字列を、Bさん、Cさんの文章に変更しても同様に抽出されます)
4.使用例の紹介
ここでは、正規表現と「文字列:置換」アクションの使用例を紹介していきます。
※正規表現は一例となっておりますので、例外パターンなどが存在するケースの際は、
必要に応じて修正してください
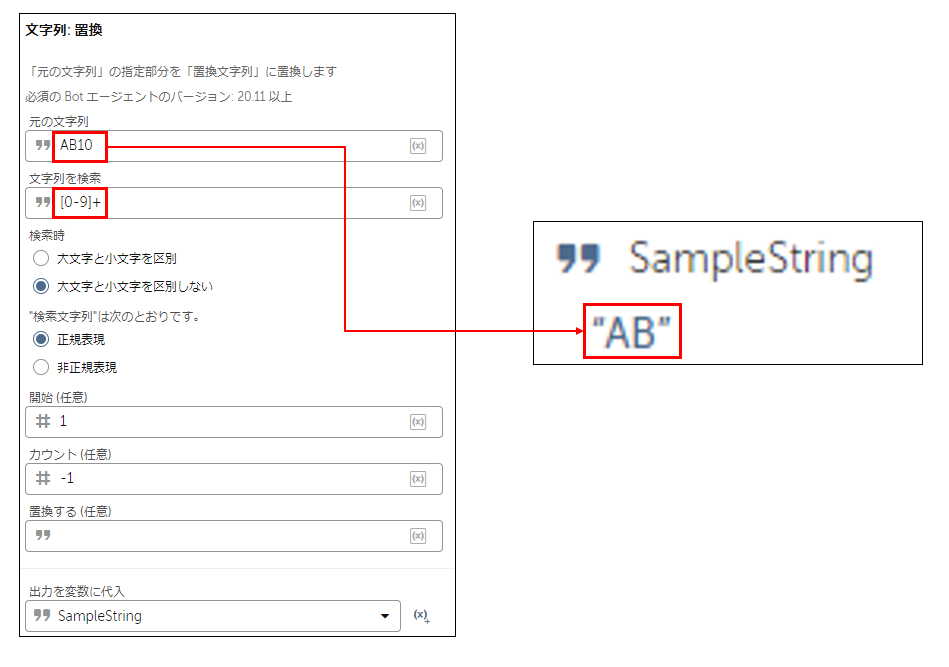
■エクセルのセルアドレスから列名または行番号を抽出
【列名のみ抽出(行番号を削除)】
正規表現の例:[0-9]+
▼解説
[0-9]+ で「1」や「12」や「123」などにマッチするので、
これを「空白で置き換える=削除する」ことで列名のみを残します。
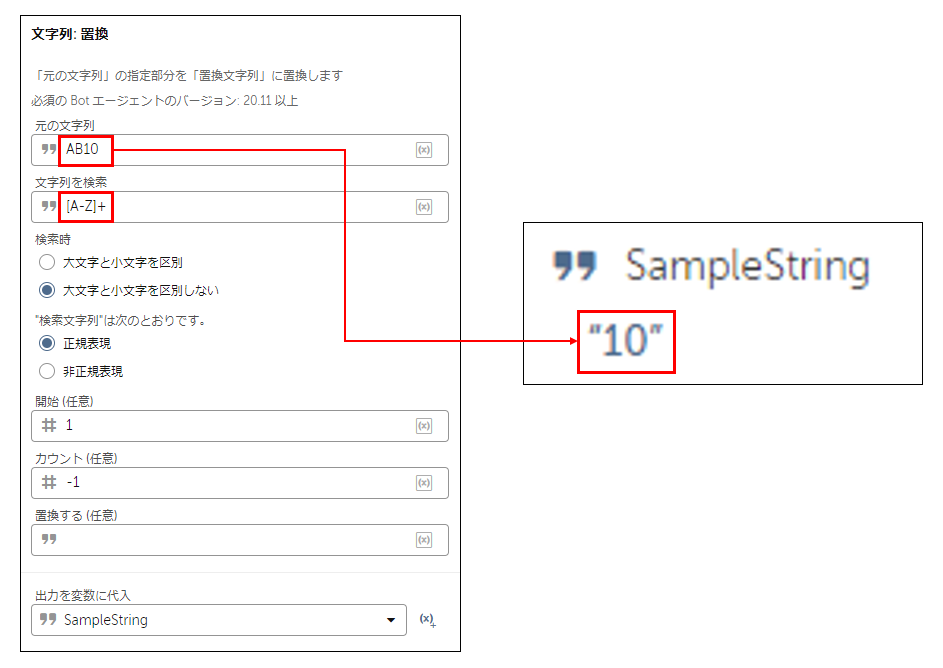
【行番号のみ抽出(列名を削除)】
正規表現の例:[A-Z]+
▼解説
[A-Z]+ で「A」や「AB」や「ABC」などにマッチするので、
これを「空白で置き換える=削除する」ことで行番号のみを残します。
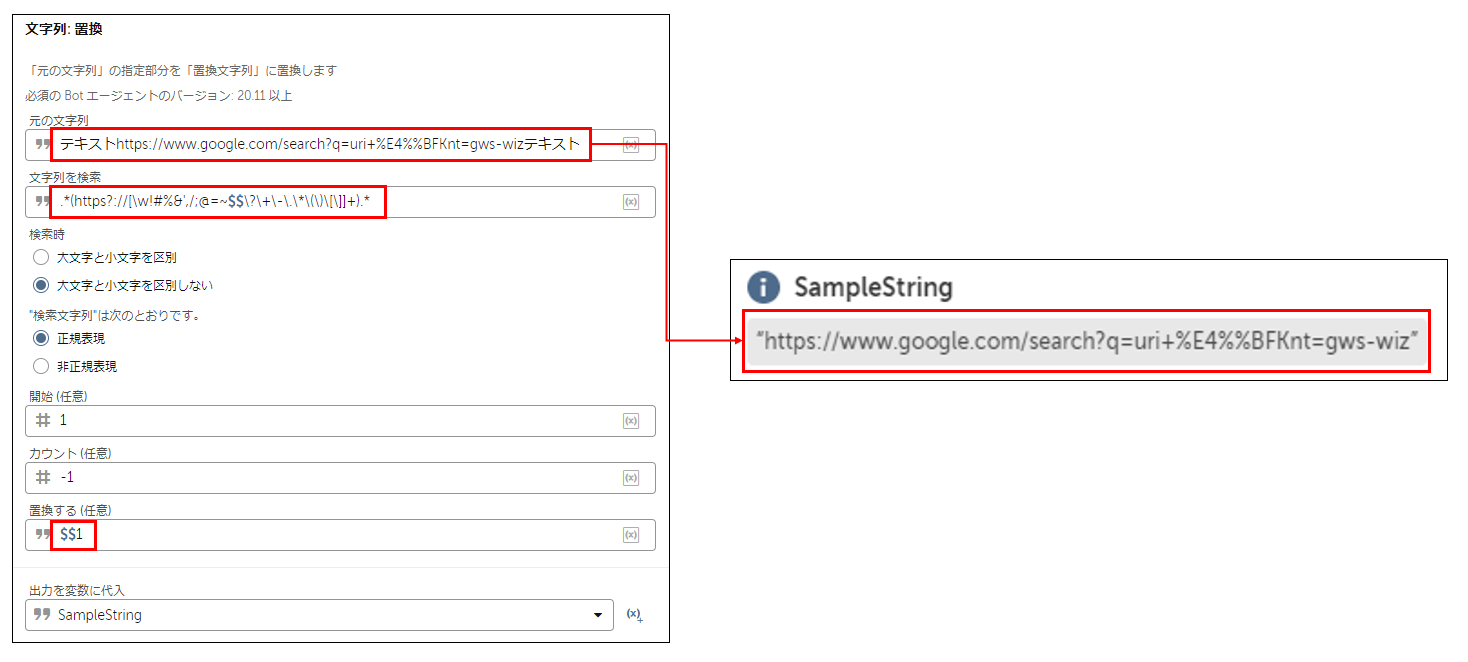
■文章中からURL(URI)を抽出
正規表現の例:.*(https?://[\w!#%&',/;@=~\?\+\-\.\*\(\)\[\]$$]+).*
▼解説
.* で、空白または何らかの文章を表します。
() で、抽出する部分を指定します。
(カッコで囲まれた部分を抽出することになります)
https?:// で「http://」または「https://」のどちらかを表します。
[\w!#%&',/;@=~\?\+\-\.\*\(\)\[\]$$]+ で、
全てのアルファベット、数字、アンダースコアと、
URL(URI)で使用される全て記号の連続した文字列を表します。
\w が、「全てのアルファベット、数字、アンダースコア」に該当し、
!#%&',/;@=~ は、エスケープが不要な記号、
\?\+\-\.\*\(\)\[\] は、エスケープが必要な記号のため全て「\」が付いております。
また、Automation Anywhere 独自の注意点となりますが、
「$」をエスケープするためには「$$」と記載しなければなりません。
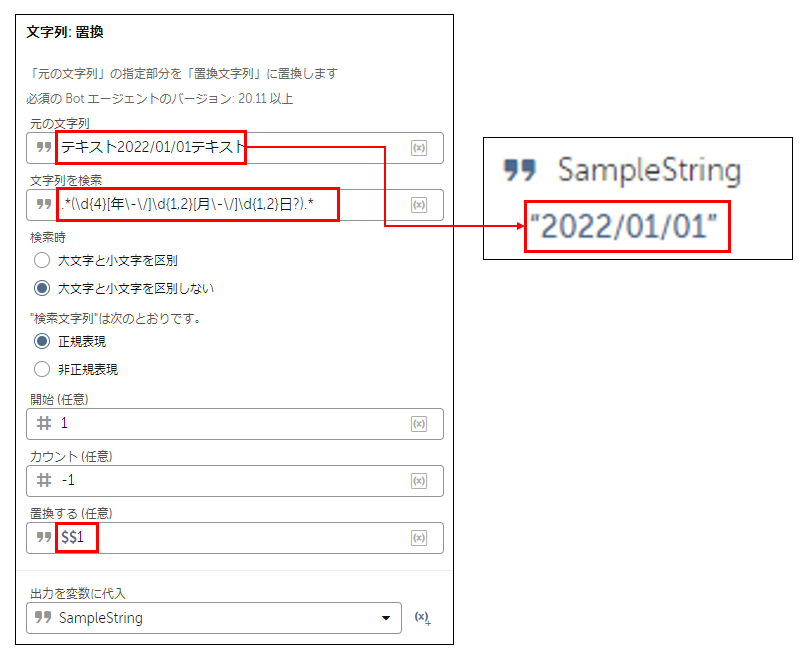
■文章中から西暦の日付を抽出
正規表現の例:.*(\d{4}[年\-\/]\d{1,2}[月\-\/]\d{1,2}日?).*
▼解説
上記の正規表現では、「2022/01/01」や「2022年1月1日」など、
年月日が「漢字」、「-」、「/」で区切られているパターンの
日付を抽出することができます。
「20220101」のように年月日の区切りがない場合は、
.*(\d{8}).* などパターンに合わせて正規表現を修正してください。
\d{4} で、数字4文字を表します。
[年\-\/] で、年と月の間に「年」、「-」、「/」のいずれか1文字を表します。
\d{1,2} で、「数字1文字」または「数字2文字」のどちらかのみを表します。
[月\-\/] で、月と日の間に「月」、「-」、「/」のいずれか1文字を表します。
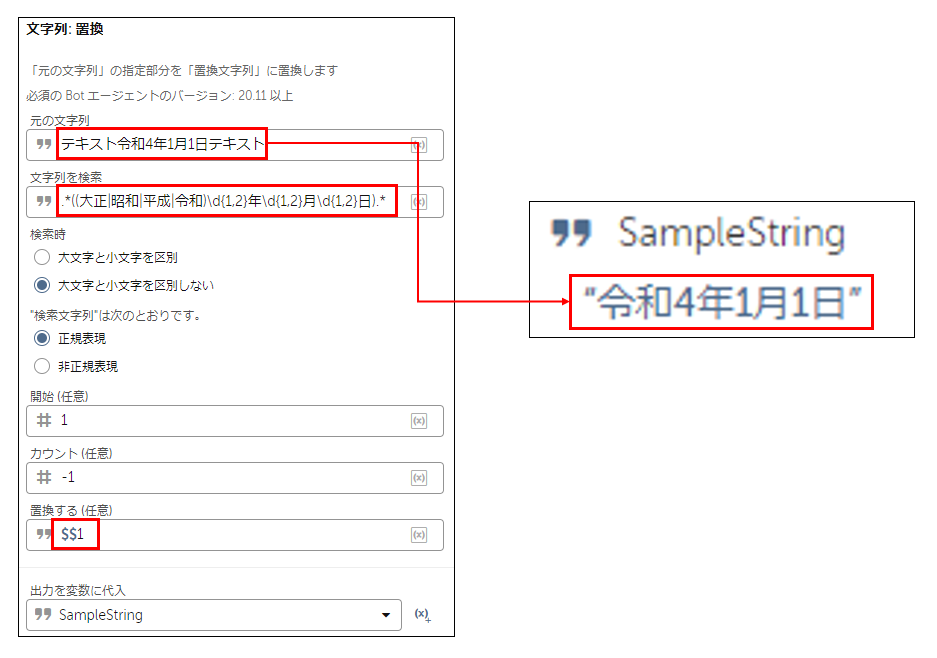
■文章中から和暦の日付を抽出
正規表現の例:.*((大正|昭和|平成|令和)\d{1,2}年\d{1,2}月\d{1,2}日).*
▼解説
(大正|昭和|平成|令和) で、大正、昭和、平成、令和のいずれかを表します。
5.まとめ
今回は「正規表現を利用した文字列抽出方法」についてご紹介しました。
正規表現を使いこなすことで複雑な条件の文字列抽出を行うことができるようになりますので、
是非今後のBot開発にお役立ていただけますと幸いです。
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
植木 真




