


■はじめに
本記事ではCrowdsrike Falcon の NGAV実装環境における
"攻撃検知時の対応フロー"および"セキュリティアラート発生時の端末隔離の基準"について記載しております。
※本記事に記載している対応フローや隔離の基準はあくまで一般論を元にしたサンプルになります。
実際の攻撃は記載されている範囲の対応ではカバーできないものなどもございます。
そのため本記事記載の内容はあくまで"社内での対策検討などの際の参考程度"にとどめていた
だけますと幸いです。
本記事の記載内容に基づく対応によるインシデントなどについて、当方は一切の責任を負いか
ねます事をご承知おきください。
■セキュリティは導入した!しっかりと検知してアラートをあげてくれるようになった!「で、どうすればいいの?」
セキュリティ担当者もしくはシステム管理者の皆様におかれましては、近年のサイバーセキュリティ事情の悪化に伴い対応を行われている事と存じます。
アンチウィルスやEDR、XDRなどのセキュリティをこれから導入する方や、すでに導入されている方々は必ず上記のような疑問を持つことがあるのではないでしょうか。
「アラートあがってるけど何すればいいかわからない。攻撃されてるけど、なにもできない。」
事前の対応方針の策定や機器の使用方法の把握があいまいな状態ではいかなる機器を投じても、攻撃が起きた際に二の足を踏んでしまいます。
そこでここでは
・事前に準備しておきたいセキュリティ事象(インシデント等)発生時の"対応フロー"
・事象発生端末の"隔離の基準"
について、CrowdStrike Falcon の利用を想定しながらお話しいたします。
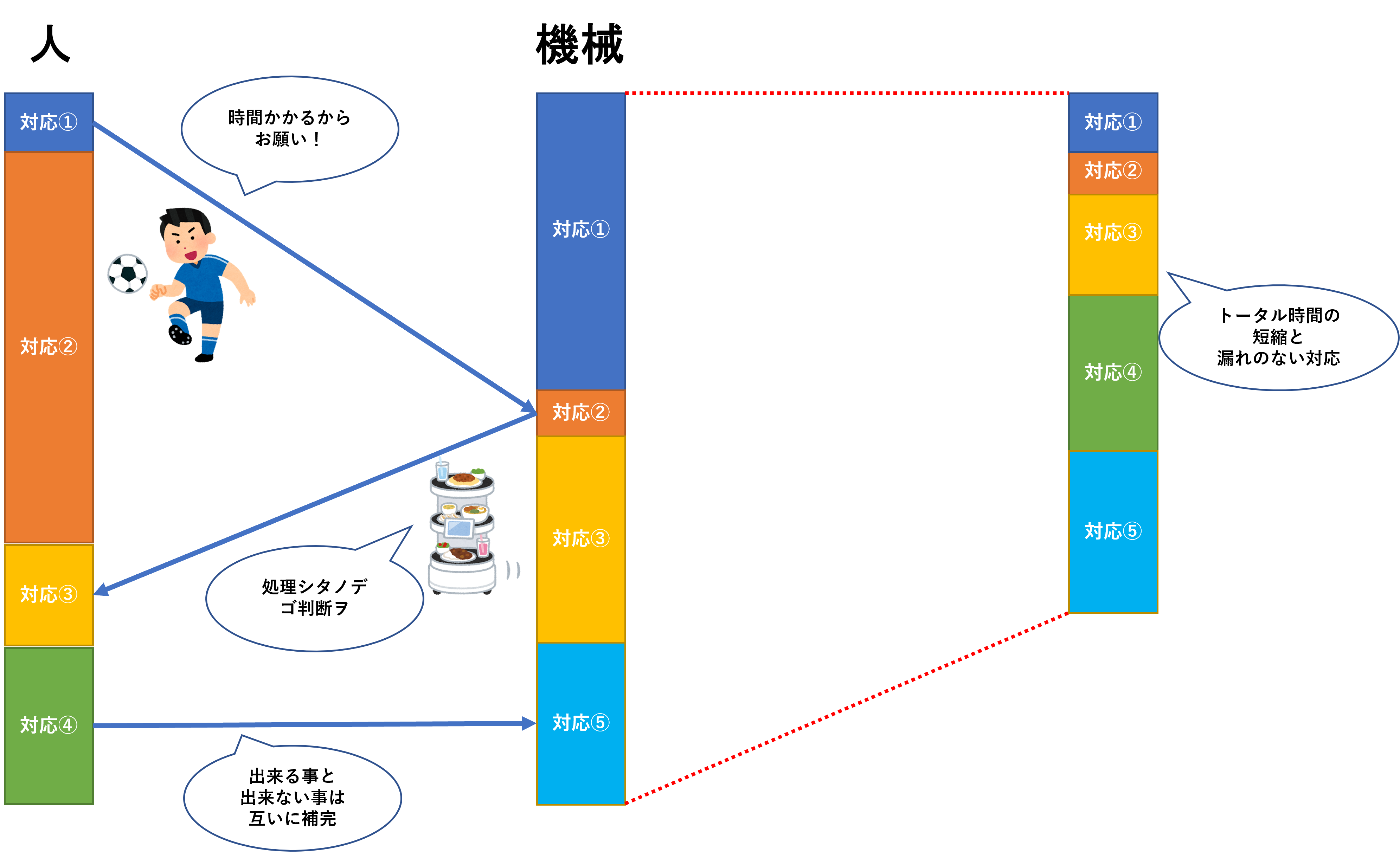
■機械に任せる部分/人が担う部分
まず結論を申し上げると、セキュリティ専業のエンジニアでもアラートやログの一つ一つから完璧にインシデント等のセキュリティ事象の対応を完遂することは難しいです。
そもそもの話として、膨大な量のログを人力で読み解いて対応するというのは現実的ではありません。
それは原則、機械に任せるべきことなのではないでしょうか?
だからこそ、セキュリティ機器は今こぞってAIを利用したアラートの相関や攻撃のマッピングなど分析評価に注力しています。
そこに対してすべてを人力で賄おうとするアプローチはセキュリティ機器の設計思想に逆行しているとも言えます。
要するに機械の判断が信頼に値するものであれば、機械の対応を最大化し人の対応部分を最小化していくことが理にかなった負担の少ない運用という事になります。
ではここからが本題です。
本記事の主題であるFalconを利用したセキュリティ事象の対応フローと隔離の基準について上記を念頭に一例としてご紹介させていただきます。
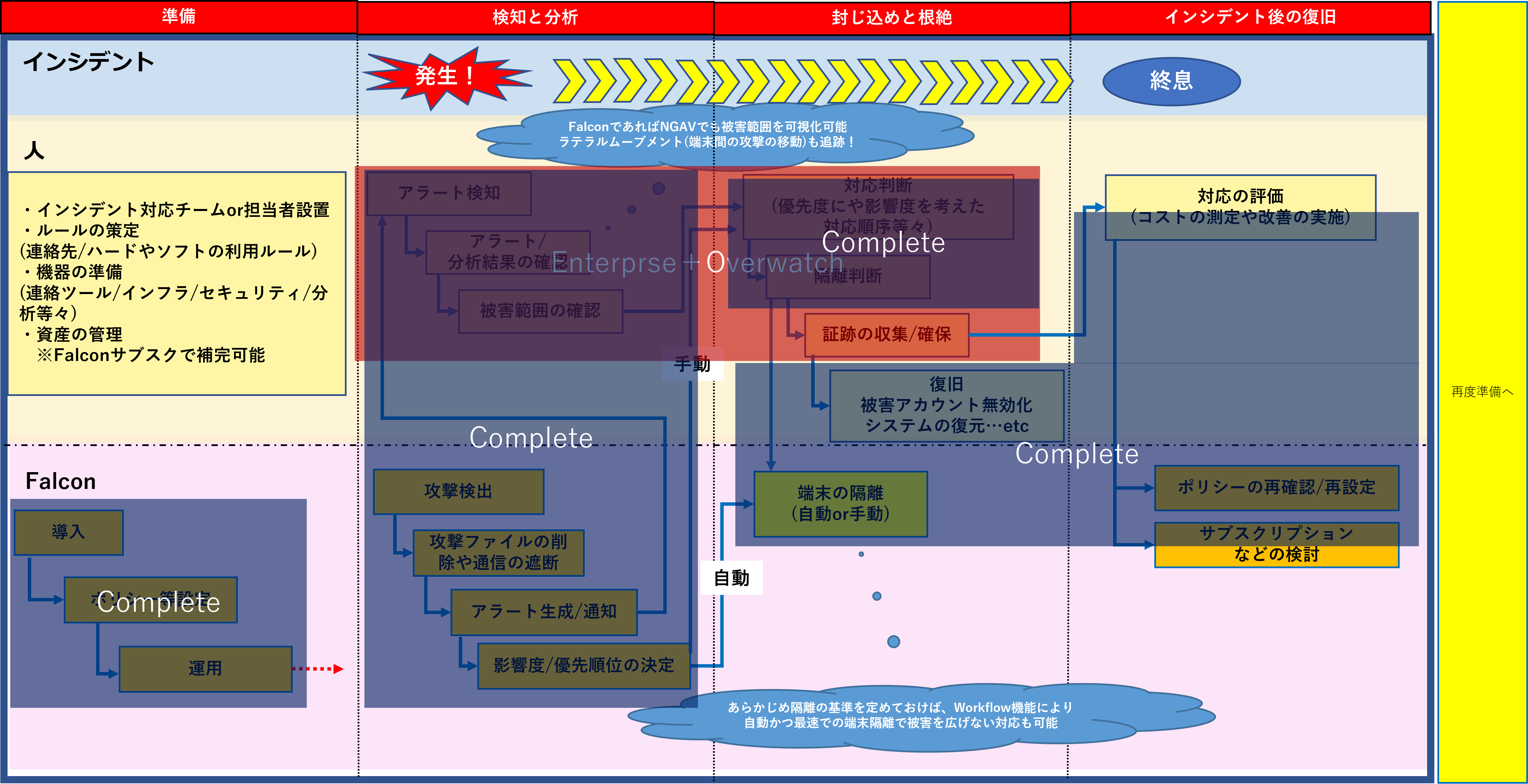
■Falconを利用したセキュリティ事象への対応の大枠 対応フロー例
まず簡単にインシデント対応の基本的な考え方からさらってみます。
米国立標準技術研究所(NIST)によるセキュリティインシデント対応の4つのフェーズは以下のようになります。
https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-61r2.pdf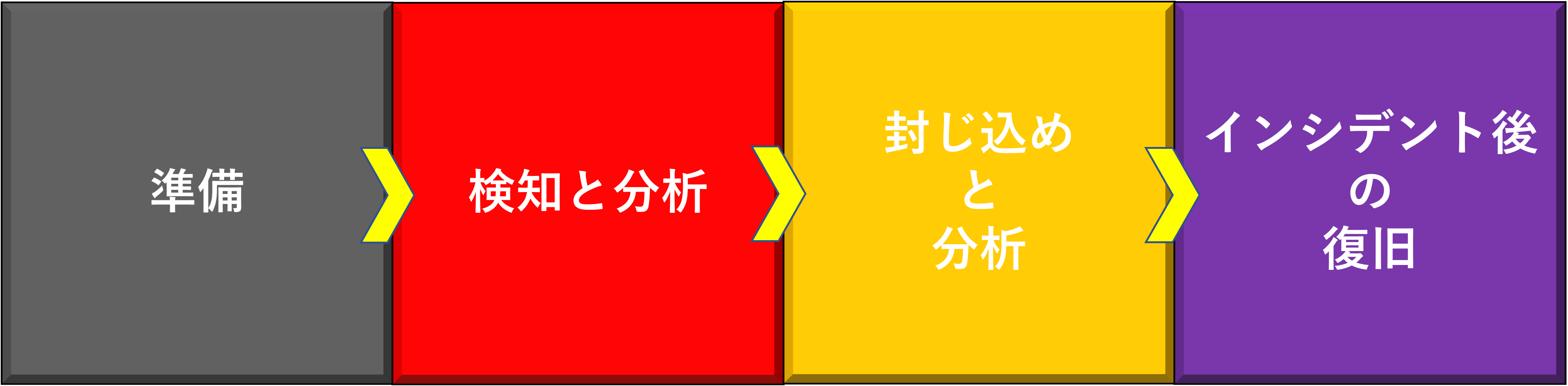
============================================================
①準備
⇒インシデント発生前に準備すべき対策や組織の体制やルール/システム部分に関する要求または予防について記載しています。
インシデント発生時の対応はもちろん重要ですが、それに備えた準備ができていないと後に続くすべての工程に支障をきたします。
インシデント発生時の組織としての正しい対応の物差しにもなりますので、こちらは事前にしっかりと確認/策定しましょう。いうに及ばず主にしっかりと人が担うべき部分となります。
あるいは、ポリシーなどの形で機械側に落とし込むことで予防と対策を行い、ある程度機械側で対策を整えることも可能です。
②検知と分析
⇒インシデント発生原因の類型や前兆/兆候についての記載や、証跡となる情報一般や行うべき対応について記載されています。
インシデント対応の重要部分となりますが、こちらに記載されている内容はセキュリティ機器(EDRなど)で補完できる部分が多くなります。
対応を考えるという観点で言えばここは機械に任せるべき部分と言えます。
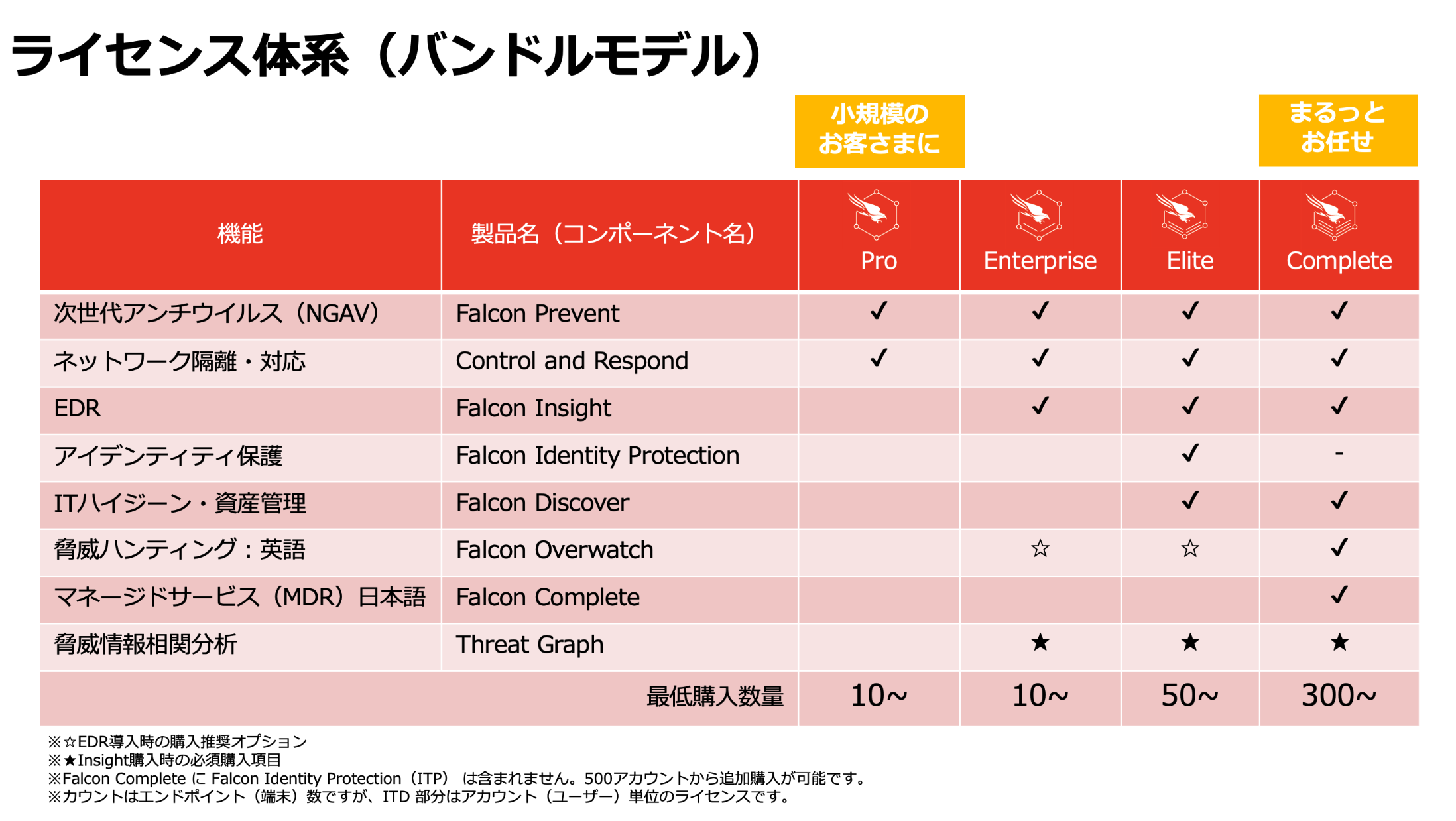
こちらはCrowdStrikeの記事になりますので、あえて言及させていただくとFalcon(Pro)であればNGAVでも十分対応可能となっています。
※詳細は後述。
③封じ込めと根絶
⇒②に近い内容ではありますが、原因の特定から先の更なるインシデントの拡大を防ぐための対応(エンドポイント端末の隔離)や、システム自体復旧及び脆弱性への対策。
業務を再開するためのシステムや端末の正常性の復旧に向けた行動が記載されています。
NW機器などの対策も含むことになるので、通常EPPやEDRだけでは機械任せにはできない部分となります。
人と機械で対応していくほかありません。
しかしながら、製品によってはサブスクリプションによる機能追加などで機械側での対応部分を増やすことにより負担減へとつなげられます。
こちらもFalconでのアンサーカードが用意されておりますので、もちろん後述させていただきます。
さらに言及すると、初期の侵入からラテラルムーブメント並行する平均的な時間は1時間ほどです。
②と③に関してはその時間の中で漏れなく対応することが求められることをご留意ください。
④インシデント後の復旧
⇒インシデント後の学習と改善。対応評価などについて記載されています。被害や対応にかかるコストの算定も行います。
ここまで行うことにより、インシデント対応は終結するといえます。人が対応する部分です。
また、インシデント対応はPDCAのように際限なく改善していける点にも着目してください。
============================================================
上記までの内容に、例としてFalcon Proの利用を想定したものをフロー化してみました。
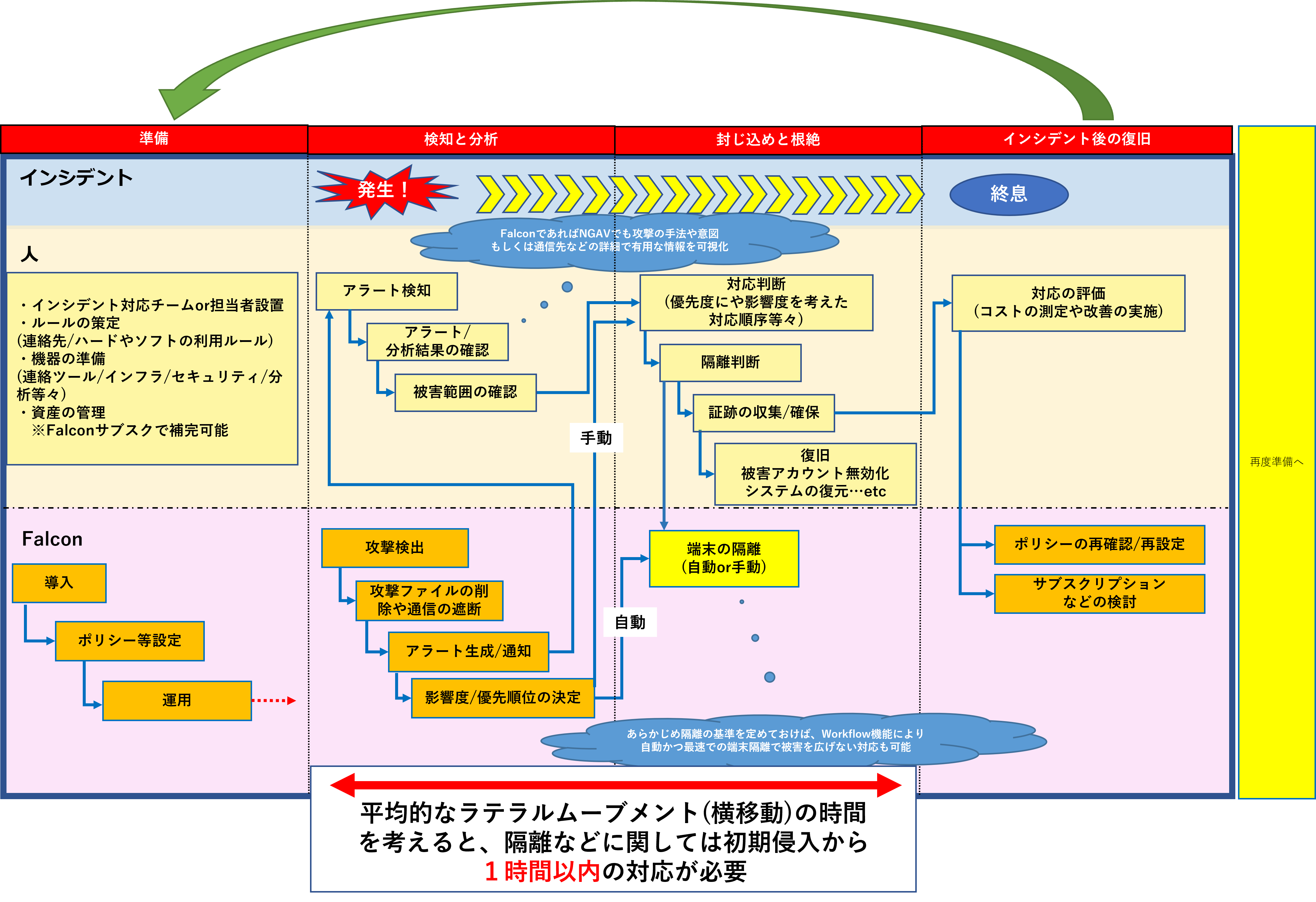
ここでまず考えたいのは、アラートから対応完了までの時間の少なさです。
短時間で対応を行うことを考えると、あらかじめの準備と必要作業の手順化/フロー化、フロー工程のある程度の機械化は必須となります。
また、ある程度機械にゆだねる形で最適化したとしても、部分的に人の判断が必要となる部分が残ります。
例えば、影響度や優先度の決定や隔離の判断部分です。
ここではFalconの分析の活用+企業のセキュリティ方針に合わせた対応の強度を策定する必要があります。
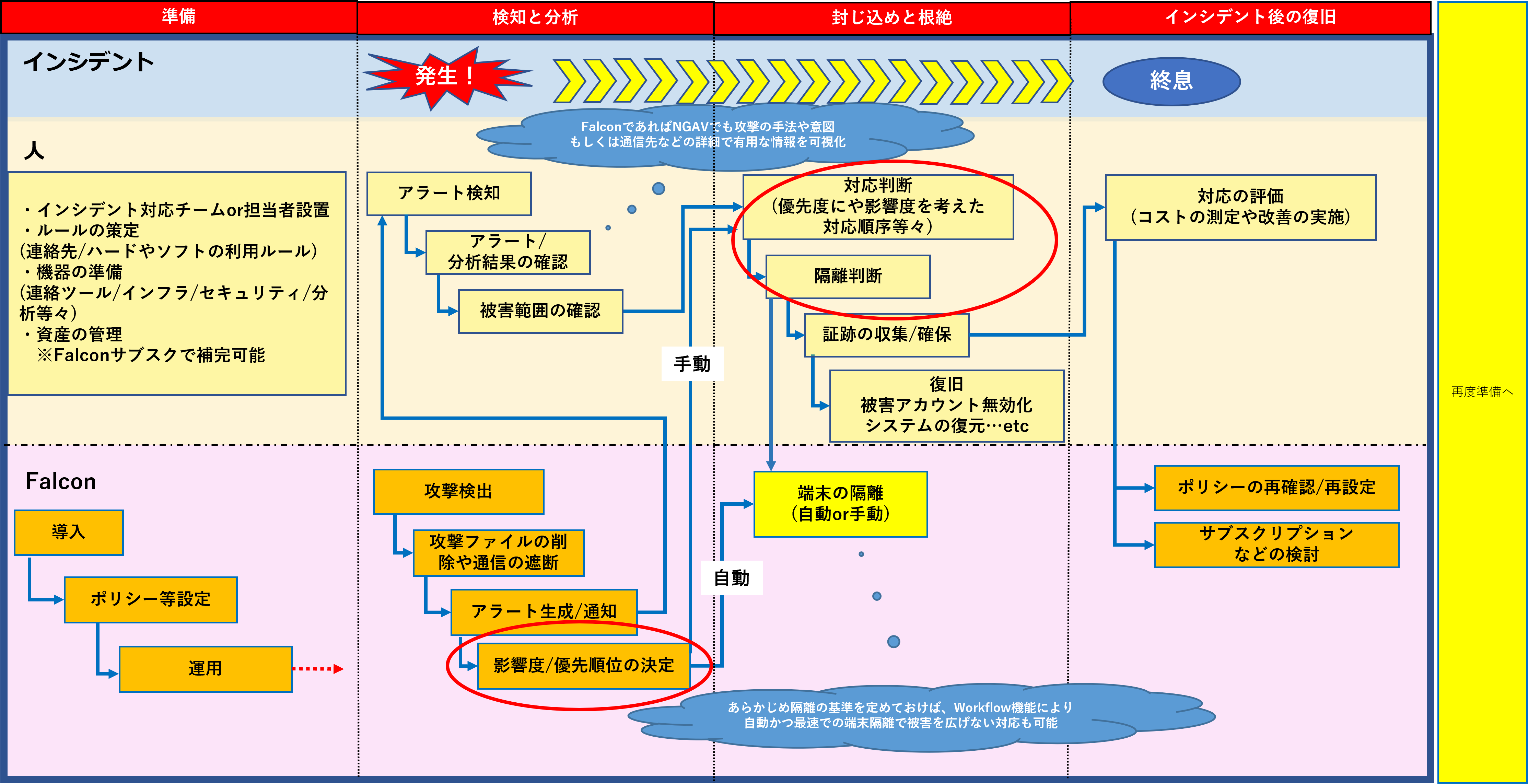
事象が発生してから考えるのでは間に合いません。
隔離の基準はあらかじめ考え標準化してある必要があります。
では、エンドポイント端末の隔離の判断に活用できるものは何でしょうか?
■隔離の基準となりうるものを活用する
例えば、Falconではアラートの分析結果内に重大度の指標があります。
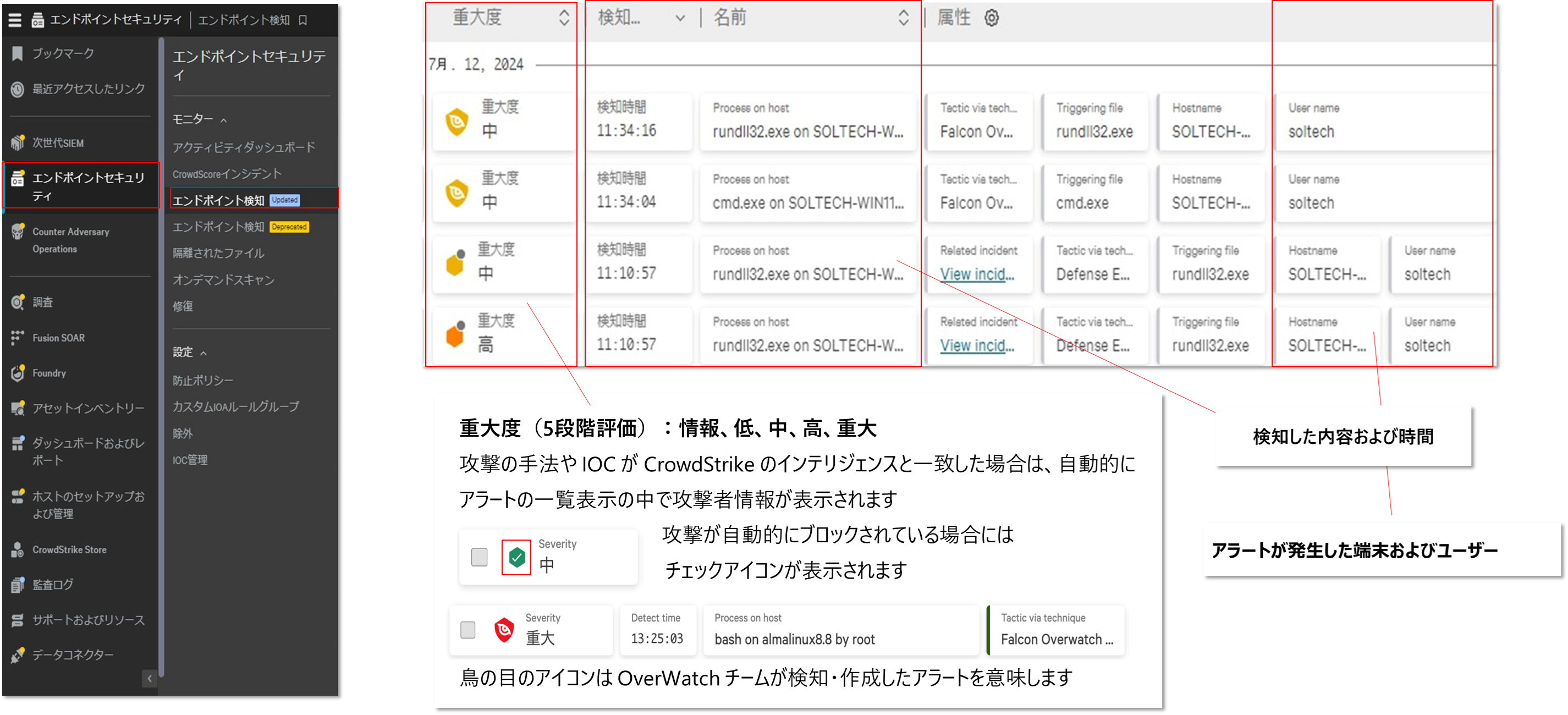
事前の誤検知対策(内製アプリケーションなどの例外化)を行い、検出内容を信頼するのであれば、端的にこちらを一つの基準とすることも可能です。
また、併せてブロックなどの自動対応の有無をトリガーにすることにより危険な状態の端末を判断し隔離を行うこともひとつの方法であるといえます。
Falcon Platformのアラート情報はEDR製品に近いレベルの詳細さを持っていますので、今挙げた以外の情報も指標とし、対応を標準化することで緊急時にロスなく隔離を実施できます。
また、アラート画面に表示される情報を隔離の基準とするということはWorkflowの自動隔離ルールの作成も実現可能という事になります。
対応の速さと正確さが重要なセキュリティ事故対応において、大きなアドバンテージを得ることが可能です。
重大度はセキュリティベンダー(CrowdStrike)の知見であり、システム担当者のスキルに左右されない強固な基準とも言えます。
そういった意味では、EDRを加えたFalcon Enterpriseを導入することで判断の基準をさらに増やすというのも一つの考え方かもしれません。
他には?
あるいは判断部分のみを別のサービスやサブスクリプションで補完/補強するという考え方もあります。
例えばOverWatchの利用により、24/365の専門家による監視を行うことにより、更に高度で精度の高い監視を行うというのも一つの手段です。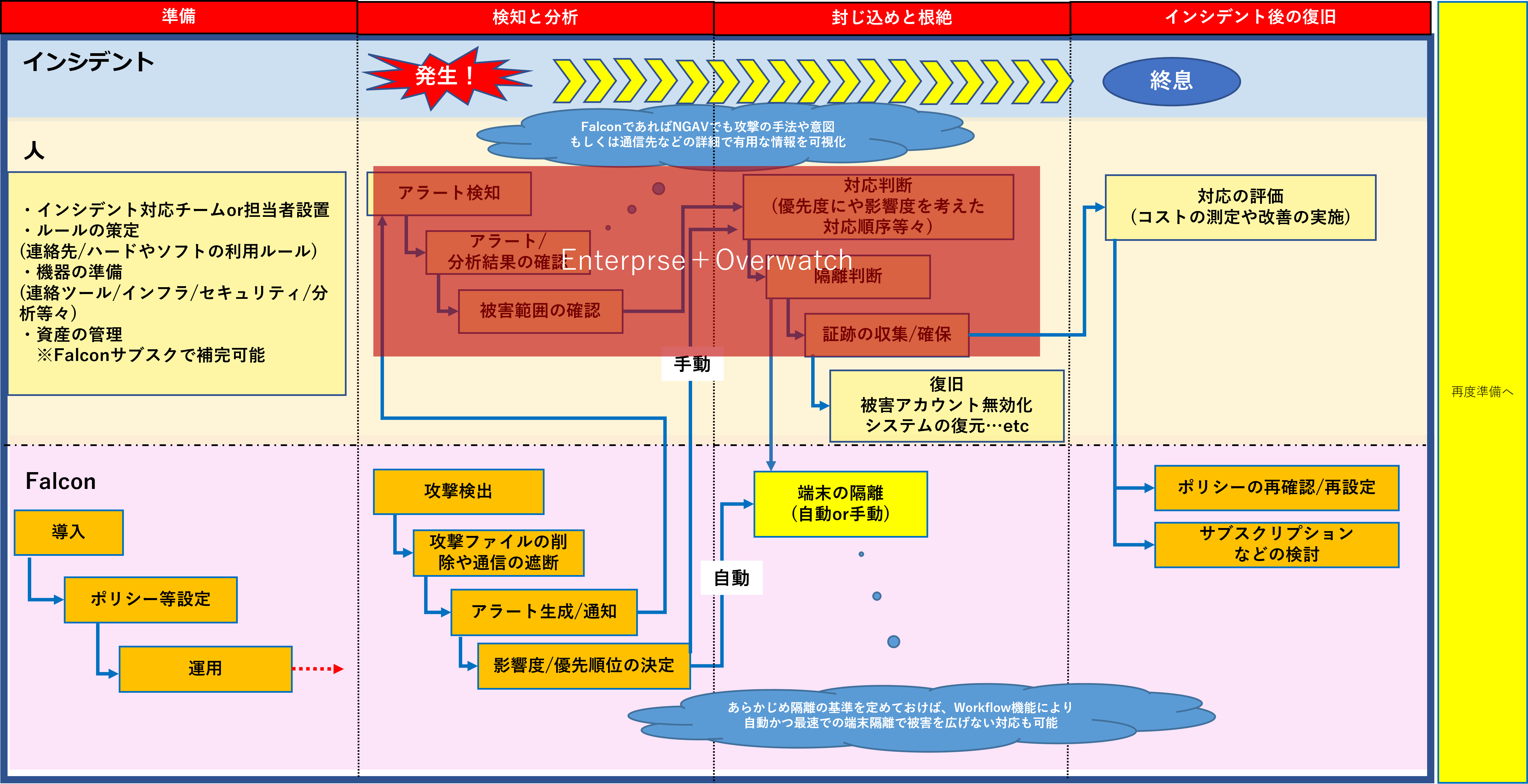
もしくは、判断の外出し(MDRやSOC)という事も可能であり、Falconであれば製品についてネイティブな知見を持つエンジニアがポリシー設定から緊急時の対応まで請け負ってくれるFalcon COMPLETEというプランも存在します。
外部のSOCやMDRのオペレーターは貴重な人材であり場合によっては協力会社など外部からの招へいであったり製品の習熟度にばらつきがあることも少なくありません。
セキュリティ機器のメーカーや製品は非常に多くなっているため機器ごとの検出仕様の差分も多く「さもありなん」という具合です。
また、メーカーがハンドリングするという点は不測の事態の最中に仕様問い合わせなどのロスや認識の齟齬が発生し難いというのも一つの魅力だと考えられます。
このようにCrowdStrikeのサービスがメーカーネイティブなサービスであるというアドバンテージはとても大きいという点は是非ご留意ください。
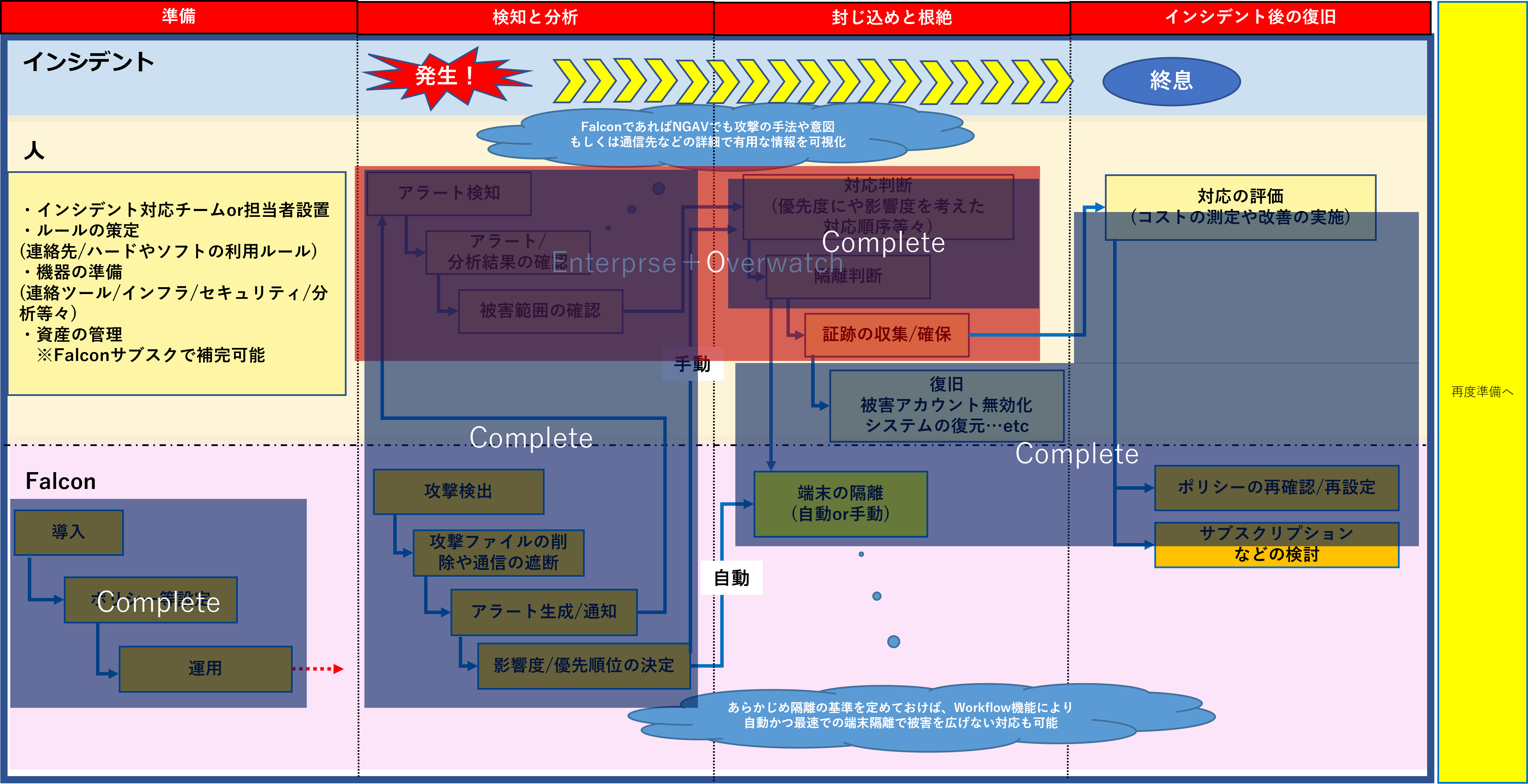
以上のような形で、組織規模や担当者のリソース、スキルマップに合わせた隔離基準を事前に設定しておくというのが、セキュリティ事象発生時の対応を考える上で一つのアンサーと言えます。
■余談「隔離の基準の明示や自動隔離はなぜ難しいのか」
セキュリティインシデントと一口に言ってみても「攻撃者によるもの」や「オペミスによるもの」あるいは偶発的な要因によるものなど様々です。
例えば同じ系統のマルウェアでも作成者によって攻撃手法が異なっていたり、ユーザー側の端末やシステム利用環境も千差万別であるため「これなら間違いない」という統一的な基準を設けることが難しくなっています。
※本記事で冒頭に念押しさせていただいたのもそういった事情がございます。
こういった要因により各メーカーが作成するシグネチャの検知トリガー(文字列などによるマッチ部分)が微妙に異なっているのと同様に、隔離という保護対策の実行トリガーの置き所の判断も非常に難しい部分があります。
とりわけ"端末の隔離"は、ビジネスにおいて非常に深刻なインパクトを起こしかねないデリケートな処置と言えます。
また、その部分に対する考え方については日本よりメーカーが本拠地を持つ諸外国の方がより重く捉えている傾向があります。
ユーザーの安全と事業継続の双方を真剣に考えると、なかなかに悩ましい課題です。
上記がすべてというわけではありませんが、
「いまいち隔離の基準についての話題をはっきり出してくれない」「自動隔離してくれたら便利なのになんで搭載してくれないの?」
という話の裏にはこういった事情もあるのです。
■最後に
今回の記事では「セキュリティ事象発生時の対処のヒント」という形にとどまってしまっておりますが
セキュリティ対策を考える上でのひとつの参考程度になれば。という思いで執筆させていただきました。
ここまで記事を読んでくださった皆さんにとって最適な保護の形を見つけていただければ幸いです。
ご一読いただき、ありがとうございました。
※本ブログの内容は投稿時点での情報となります。今後アップデートが重なるにつれ
正確性、最新性、完全性は保証できませんのでご了承ください。
他のオススメ記事はこちら
著者紹介

SB C&S株式会社
技術本部 技術統括部 第4技術部 1課
宮澤 建人





{kind=link}