


こんにちは。SB C&S の間山です。
この記事ではNVIDIA社が提供しているDGX Platformと弊社で導入しているDGX H200の紹介をします。
1.1 DGXのラインナップと代表的なユースケース
DGXはデスクサイド用途を想定したコンピュータからデータセンター向けのサーバ、大規模 LLM など、 巨大な AI ワークロードを想定したラックスケールのシステムまでを含む製品群となっています。
ここでは DGX Spark/DGX Station/DGX H200/GB200シリーズについて簡単に説明します。
・DGX Spark
個人・小規模チーム向けのデスクサイドAIスーパーコンピュータ。
手元で LLM や生成 AI のプロトタイピング・評価・ファインチューニングを高速に回したいときに適しています。
・DGX Station
研究室や開発部門など、チームで共有して使うデスクサイド型AIワークステーション。
データセンターを用意せずに、DGX Sparkよりもさらに大規模モデルの学習・推論環境をオンプレで持ちたい場合に適しています。
また、最新モデルの DGX Station 2025 は、従来の x86 CPU に代えて GB300 Grace Blackwell Ultra Desktop Superchip を採用した新しい構成となっています
・DGX Hxxx/Bxxxシリーズ
データセンター向けの8GPU 搭載サーバで、社内共通のAI基盤の中核ノードになる存在。
LLM・画像/音声モデルなど幅広いAIワークロードを、複数台クラスタ化し(BasePod,SuperPod)として運用することも可能です。
・GB200 NVL72 / DGX GB200 シリーズ
兆単位のパラメータを持つ LLM のトレーニングとリアルタイム推論を実現するラックスケールのシステム。 より大規模な環境を想定しているシステムです。
1.2 DGX H200の構成
DGX H200は生成 AI や大規模言語モデル向けに設計され、ハードウェア、ソフトウェアともに最適化されたGPU サーバです。
8基のH200 GPUと大容量メモリ、高速ネットワークを 1 台にまとめたサーバとなっており、クラスタ用途も想定されたコンポーネントで構成されています。具体的なコンポーネントは下記の通りとなっています。

弊社契約データセンタ設置のDGX H200 2台
GPUブロック
GPU
・NVIDIA H200 GPU x8
・GPUあたり141GBのHBM3eメモリ ノード合計1,128GB
NVLink
・第4世代NVLink搭載。GPU間で900GB/秒を実現
NVSwitch
・900 GB/秒のGPU間帯域幅を提供する第4世代 NVSwitchを4 基搭載
・双方向 GPU 間帯域幅 合計7.2TB/秒を実現
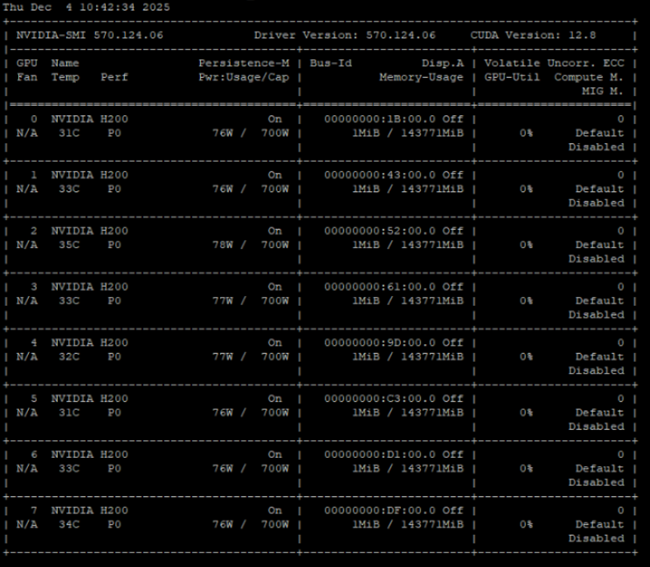
nvidia-smiコマンドによる搭載GPUの確認例
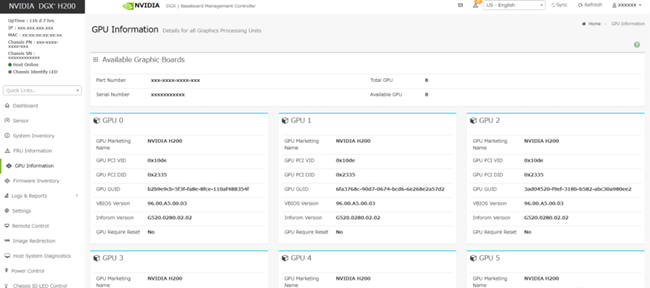
Baseboard Management Controlle(BMC)による搭載GPUの確認例
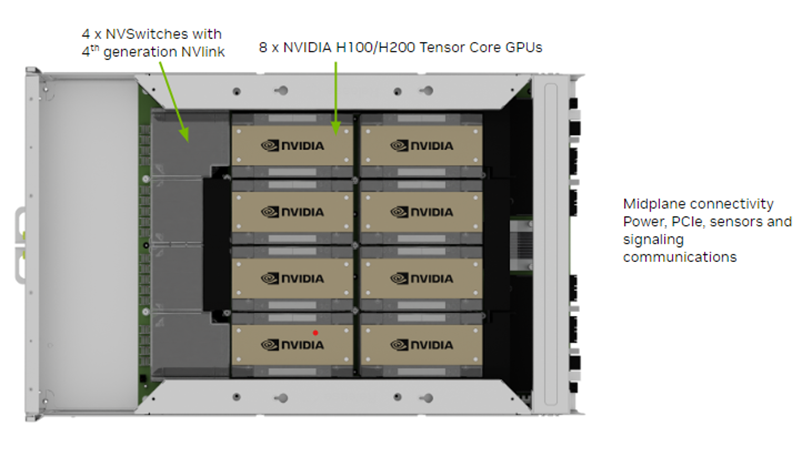
GPUトレイのコンポーネント
出典 NVIDIA NVIDIA DGX H100/H200 System User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/
CPU/RAM/ストレージ
CPU
・Intel Xeon Platinum 8480C × 2
合計 112 コア / ベース 2.0 GHz / 最大 3.8 GHz
システムメモリ
・合計2 TB DDR5メモリ
OS 用ストレージ
・NVMe M.2 SSD 1.9 TB × 2(RAID1 構成)
データ用ストレージ
・NVMe U.2 SSD 3.84 TB × 8(RAID0/RAID5変更可)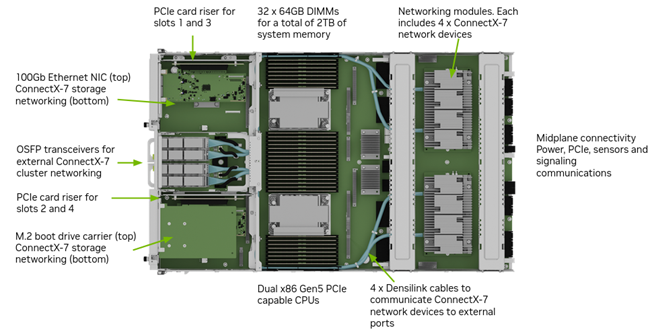
マザーボードトレイのコンポーネント
出典 NVIDIA NVIDIA DGX H100/H200 System User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/
ネットワーク
高速計算/クラスタ用ネットワーク
・OSFP ポート x4(内部的に 8×シングルポート ConnectX-7 として機能)
・ポートあたり最大 400 Gb/s(InfiniBand / Ethernet 対応)
ストレージ/汎用バックエンド用ネットワーク
・デュアルポート QSFP112 ConnectX-7 VPI × 2
・合計 4 ポート / 最大400 Gb/s クラスで外部ストレージ等との接続を想定 (InfiniBand / Ethernet 対応)
管理/ユーザーアクセス用
・10 Gb/s オンボード NIC(RJ45)
・100 Gb/s デュアルポート Ethernet NIC
・BMC(Baseboard Management Controller)用 RJ45 ポート

ネットワークポート
出典 NVIDIA NVIDIA DGX H100/H200 System User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/
電源 / FAN
電力ユニット
・ホットスワップ可能な3300W PSUx6 (200-240 V)
・4+2の冗長電源
FAN
・12個の大風量のホットスワップ可能なファンモジュール
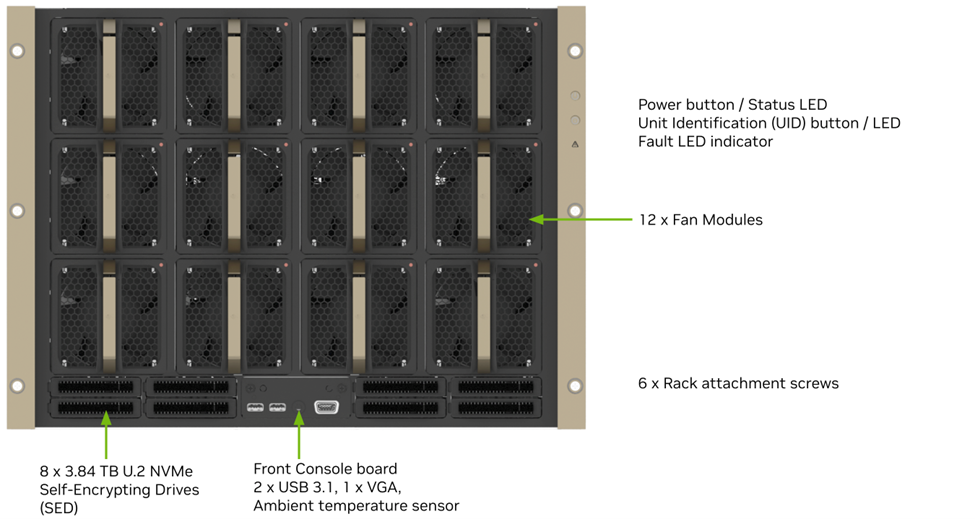
DGX正面のコンポーネント
出典 NVIDIA NVIDIA DGX H100/H200 System User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/
1.3 NVLink および NVSwitch
本章では、普段あまり耳にしない"NVLink"と"NVSwitch"が、なぜ最新の AI サーバにとって欠かせない存在なのかを噛み砕いて解説していきます。
「GPU 同士の通信」がそもそもなぜ大事なのか
近年の大規模な AI 学習/推論では、1つのモデルを複数のGPUに分割して載せて処理することが標準となっています。
FP16 想定だとモデルだけでおよそ 800〜900GB 前後の容量が必要とされており、推論用にはさらに KV キャッシュ用などの VRAM が必要です。
H200 1枚のGPUメモリは141GBなので、このクラスのLLMは1つのGPU には物理的に載らず、DGX のようなマルチGPU 環境にモデルを分割して配置することが前提になります。
そこで活躍するものはGPUを直接かつ高速に接続するNVLinkと複数のNVLinkをまとめるNVSiwitchです。
NVLinkとは
NVLinkは、GPU 同士を直接つなぐための高速インターコネクトです。
DGX H200が搭載する第4世代NVLinkは、GPU1基あたり最大900GB/sの帯域でを持っており、 一般的なサーバ内部接続に使われるPCIe 5.0(約64GB/s)と比べて桁違いに太い帯域となっています。
NVSwitchとは
NVSwitchは、NVLinkをさらに発展させ、より多くのGPUを相互接続するためのスイッチング技術です。
各GPUから伸びるNVLinkをNVSwitchチップに集約することで、多数のGPU同士がどの組み合わせでもNVLinkのフルスピードで通信できるようにし、大規模システムでのGPU間通信を効率的にします。
DGX H200の場合はNVSwitchを4 基搭載しており、8 基のH200 GPU間で合計7.2 TB/sの双方向帯域を実現しています。
これは GPU 1 基あたり900GB/sの第4 世代NVLinkを8基分フルに活かした帯域であり、マルチ GPU に分割した巨大な LLM でも、高速に通信できるように設計されています。
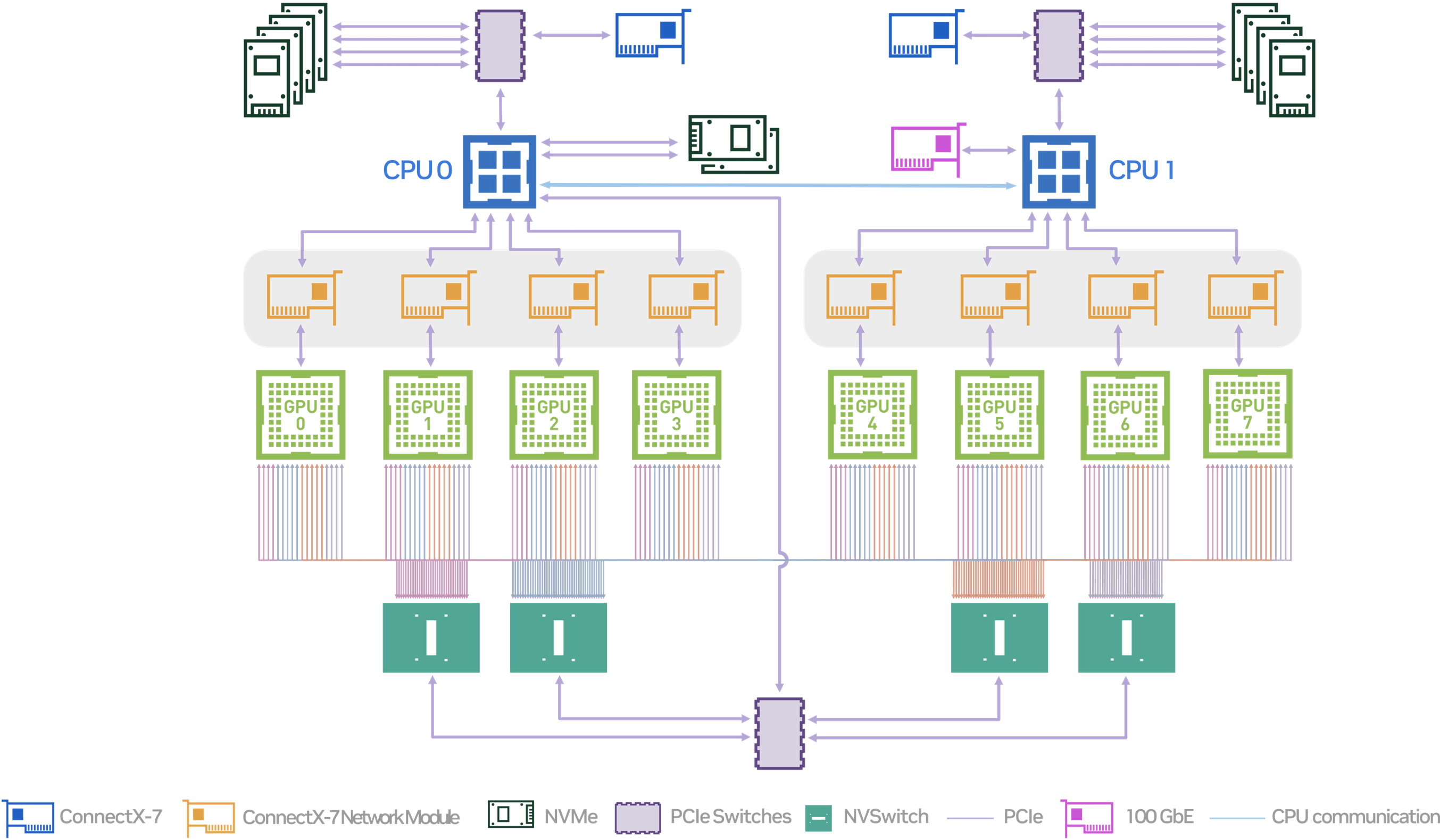
NVLinkとNVSwitchの例
出典 NVIDIA DGX H100/H200 User Guide
https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html
1.4 OS、各種ソフトウェア群
本章では、DGX H200に搭載されているOS、ソフトウェアについて解説していきます。
DGX OS
DGX H200 には、DGX OSと呼ばれるOSが搭載されています。
これは Ubuntu をベースに、DGXシリーズ向けにドライバ構成が最適化されたディストリビューションで、NVIDIA 自身が検証・サポート対象としている環境です。
ドライバ、その他ツール
DGX H200には、AI開発で使うコンポーネントが最初からインストールされています。
例として下記コンポーネントが含まれています。
・NVIDIA DataCenter GPU ドライバ
・Docker Engine
・NVIDIA Container Toolkit
そのため、DGX をラックに設置して初期セットアップを終えれば、
1.docker runでNGC の学習用コンテナを起動する
2.用意した学習スクリプトやノートブックを投入する
という流れで、余計なソフトウェアインストールやドライバ調整を挟まずAI開発を始められる構成になっています。
監視コンポーネント群
DGX は特殊な構成であり、さらに複数台を束ねてクラスタを組む使い方が一般的です。
そのため、運用・監視の仕組みが最初から用意されていることがとても重要なポイントです。
代表的なものとして次の2つが含まれています。
・NVSM (NVIDIA System Management)
DGX システム全体のヘルスチェックやログ取得、ファームウェア情報の確認などを行うためのツール群です。
コマンドラインから「このノードの状態は健康か?」「どのコンポーネントにアラートが出ているか?」といった確認が可能です。
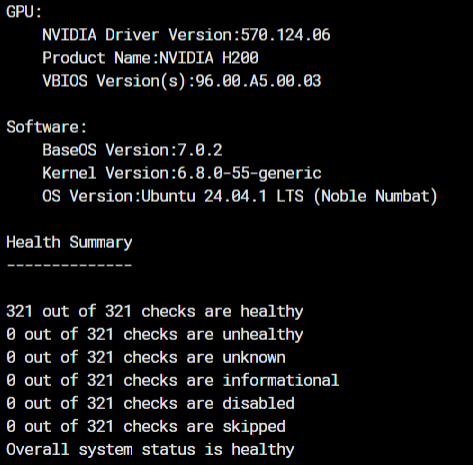
DGX H200に対しNVSMを用いたヘルスチェック結果の抜粋
・DCGM (Data Center GPU Manager)
GPU利用率・温度・エラー情報・クロックなど、GPUに関する詳細なメトリクスを収集・管理するための仕組みです。
PrometheusやGrafanaなどと連携することで、DGXクラスタ全体のGPU状況をダッシュボード化し、しきい値アラートを飛ばすといった運用が可能となります。
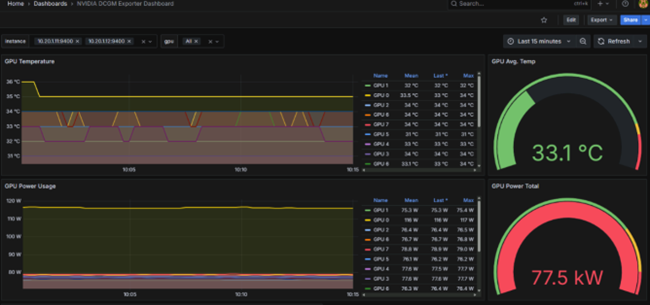
DCGMを用いでDGX H200 x2をGrafanaで監視
1.5 まとめ
本記事ではDGX PlatformとDGX H200の紹介をしました。
NVIDIA DGX Platformは、デスクサイドからラックスケールまでをカバーするプラットフォームです。
また、DGX H200は8基のH200 GPUや大容量メモリ、高帯域 NIC、NVLink / NVSwitch による GPU 間接続など、一般的な x86サーバとは異なるマルチGPU・クラスタ用途として非常に強力な製品です。
さらに、DGX OSを中心としたNVIDIA検証済みソフトウェアスタックにより、GPUドライバやコンテナ基盤といったAI開発の環境が整っており、NVSMやDCGMを用いて大規模環境でも一貫した監視と運用が行えます。
DGX は単なる高性能サーバだけではなく、企業が生成AIやLLMを本格的に運用するための"ハードウェア+ネットワーク+ソフトウェア+運用ツール"が統合された製品です。
他のおすすめ記事はこちら
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
間山 翔宇
VMware vExpert




