


こんにちは。SB C&Sにて仮想化製品のプリセールスエンジニアを担当している笠原です。
近年、ビジネスにおけるタブレットやスマートフォンを活用した業務などマルチデバイス化や、在宅ワークなどの働き方の変化によって、ITシステムの重要性が増しています。
ITシステムの停止は、企業の業務停止につながることも多く、ITシステムの高可用性が求められる昨今では、ハードウエアをはじめ各種障害に耐えうる冗長化した構成が、オンプレミス・クラウド環境に関係なく一般的となってきました。
Nutanixが提供するHCIは、ソフトウエアで冗長化アーキテクチャを持っており、いずれかの構成要素に障害が発生してもサービスが稼働し続けられる仕組みになっています。
Nutanixのアーキテクチャ面において、今回は障害に備えたデータの冗長化と故障発生時の挙動について紹介します。
※簡略化のために本記事ではSSDとHDDをディスクと表現します。
従来のデータ冗長化の仕組み
RAIDの概要
RAIDの課題
Nutanixのデータ冗長化の仕組み
NutanixにおけるHCIの基本的な構成
データの保持方法と分散
ディスク故障時の挙動
ノード障害時の挙動
CVM障害時の挙動
従来のデータ冗長化の仕組み
RAIDの概要
多くのストレージにおいては、ディスクの故障に対してデータを保護するためにRAIDが使われています。
確認となりますが、RAIDは複数のディスクをRAIDコントローラによって束ねて1つのディスクとみなし、データを分散して書き込む技術です。
データをミラーリングすることや、パリティと呼ばれる復旧用のデータをディスクに分散して書き込むことでデータを冗長化しています。そのデータの配置方法により、RAID 1,5,6,10といった一般的なRAID方式からストレージメーカー独自のRAID方式まで様々な種類が存在します。
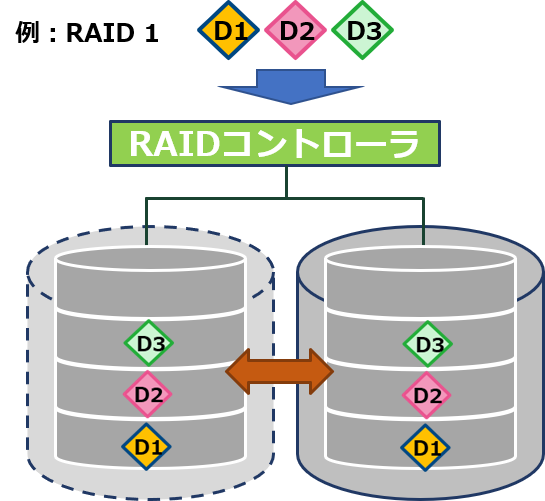
どのRAID方式であっても、ディスクの故障に伴う交換時(また、容量拡張に伴うディスク増設時)にはリビルドが発生し、再度冗長性が確保された状態にします。
RAIDの課題
RAIDは、データ冗長化の基本的な仕組みであり、エンタープライズな環境において必要不可欠な機能であることは間違いありませんが、RAID構成にはデメリット(課題)も存在します。
その課題として、リビルド中のパフォーマンス低下が挙げられます。
上述したように、ディスクが故障した際やディスクを増設する際にはリビルドが発生します。リビルドの動作として、ミラーリングするタイプのRAIDであれば全データのコピー、パリティを使ったRAIDであればパリティ再計算が行われます。
この処理は数日間に渡ることもあり、その間I/Oのパフォーマンスが低下します。
リビルドはディスク全体のデータ量が増えるほど時間がかかり、多くのデータ量を管理する近年においては、この点がより問題点として捉えられています。
また、2重障害に耐えうるRAID(RAID 6など)でなければ、リビルドが完了するまでに他のディスクが故障した場合、記憶したデータを損失する可能性が高くなります。そのため、ディスクの故障が発生した際は新しいディスクへの交換を速やかに行うことが重要になります。ディスク故障に気付かず運用し続けると、他のディスクも故障しデータを損失する恐れも出てきます。
RAID内のディスクが故障した際に、故障したディスクを自動で切り離して予備として設定したスペアディスクに切り替えて自動でリビルドを行い再度冗長性を保つ仕組みがあります。(一般的に予備として待機しているディスクをホットスペアと呼びます)
ホットスペアを準備していた場合、故障したディスクを交換するまでの間、非冗長な状態が続くという課題は解消されますが、スペアディスクは普段使われず待機状態になっているため、スロットに搭載するディスク本数における容量効率が低下してしまいます。
Nutanixのデータ冗長化の仕組み
上述したRAIDの課題をNutanixはどのように解消するか、アーキテクチャを踏まえてご紹介します。
NutanixにおけるHCIの基本的な構成
Nutanixのデータ冗長化について紹介する前に、基本的な構成の確認をさせていただきます。
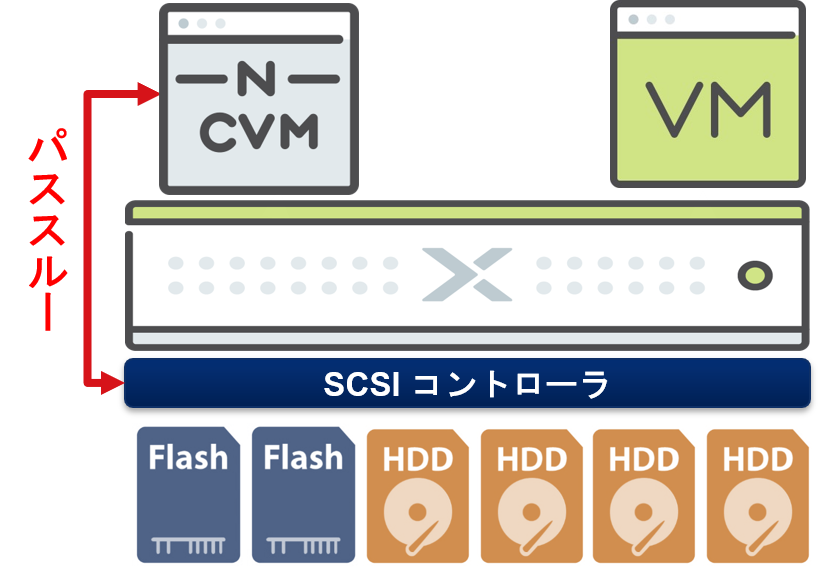
Nutanixは、通常のIAサーバーとフラッシュデバイス及びディスクを搭載した(ハイブリッドの他にオールフラッシュモデルも存在)物理サーバーで構成されています。この物理サーバーのことをノードと呼び、各ノード上でハイパーバイザーが稼働します。
Nutanixで稼働するハイパーバイザー上に、CVM(Controller VM)と呼ばれる仮想アプライアンス(仮想マシン)が展開されます。CVMは、ストレージコントローラや各管理コンポーネントが稼働しています。(CVMは、各Nutanixノードそれぞれに存在します)
CVMは、物理サーバーに搭載されたSCSIコントローラをパススルーで直接接続し、ハイパーバイザーのI/O処理を介さず直接フラッシュデバイス及びディスク制御を行う仕組みとなっています。尚、CVMが管理する各種ディスクはRAIDアーキテクチャを使用していません。
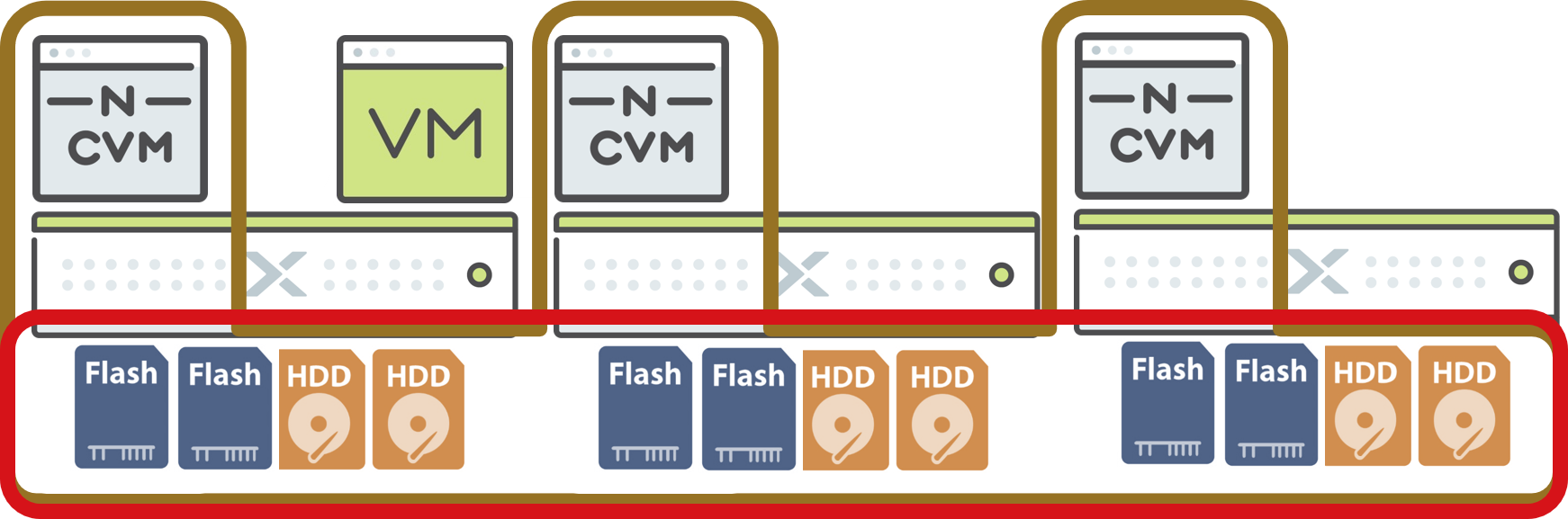
Nutanixでは、原則3ノード以上で1つのクラスタとして構成します。クラスター全体の各ノードに搭載されたディスクを束ねて1つのストレージプールと呼ばれる領域を作成します。各CVM間はネットワークで接続され、どのノードのハイパーバイザーから見ても同一のデータが参照できる(共有ストレージ)ように、CVMがストレージコントローラーの役割を果たします。
データの保持方法と分散
次に、NutanixのHCIにおいて、データがどのように保持され、冗長化されているかについてご紹介します。
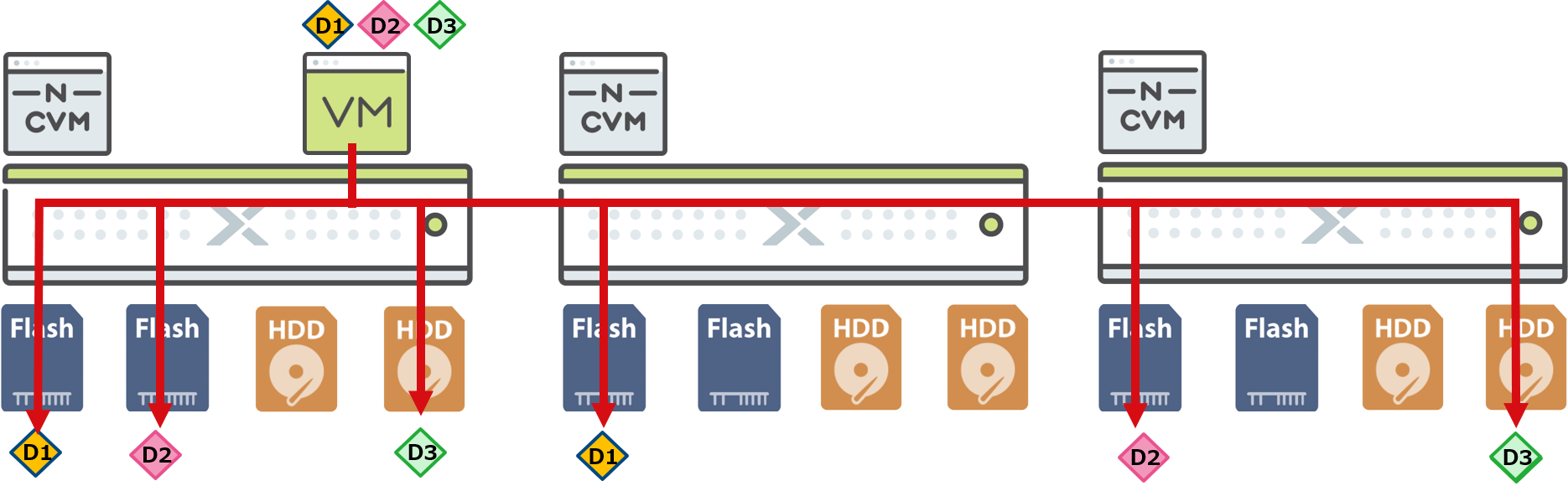
データの冗長化は、Nutanixでは同じデータを複数の異なるノード内のディスクに保存することで行われます。同じデータを2ノードで保持していることをRF2(Replication Factor 2)、3ノードで保持していることをRF3(Replication Factor 3)と呼びます。RF2、RF3の設定は、ストレージプールから切り出されたストレージコンテナごとに設定可能です。また、構成する際はRF2の場合最低3ノード、RF3の場合最低5ノードが必要となります。
仮想マシンのデータが書き込まれる時、仮想マシンが稼働するノード内のディスクと別のノードが保有するディスクに2重化または3重化して書き込まれます。
RF2
RF3
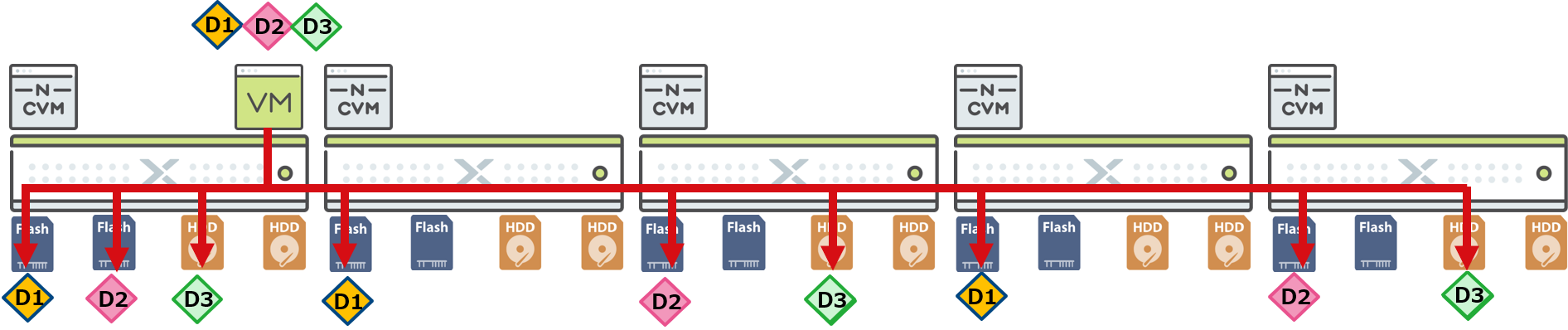
また、1つの仮想マシンのデータは1つのディスクに偏らないよう、複数のディスクに分散されています。(上図の例ではフラッシュデバイスに保存されるD1、D2が別のデバイスに保存されています。)
ディスク故障時の挙動
上述したRAIDの課題2点を、Nutanixのアーキテクチャであればどのように解消されているかを、ディスク故障時の挙動とともに確認していきます。
まず、Nutanixは、ディスク故障が発生すると即座にリビルドが行われます。これにより、ディスクを交換するまでリビルドが開始されないRAIDの課題が解消されます。
Nutanixのリビルドは、ディスク故障が発生した際、故障したディスク内のデータと同じデータを持つ別のディスクを、CVMがメタデータから検索し、該当データをまた別のノードで稼働しているディスクへコピーします。
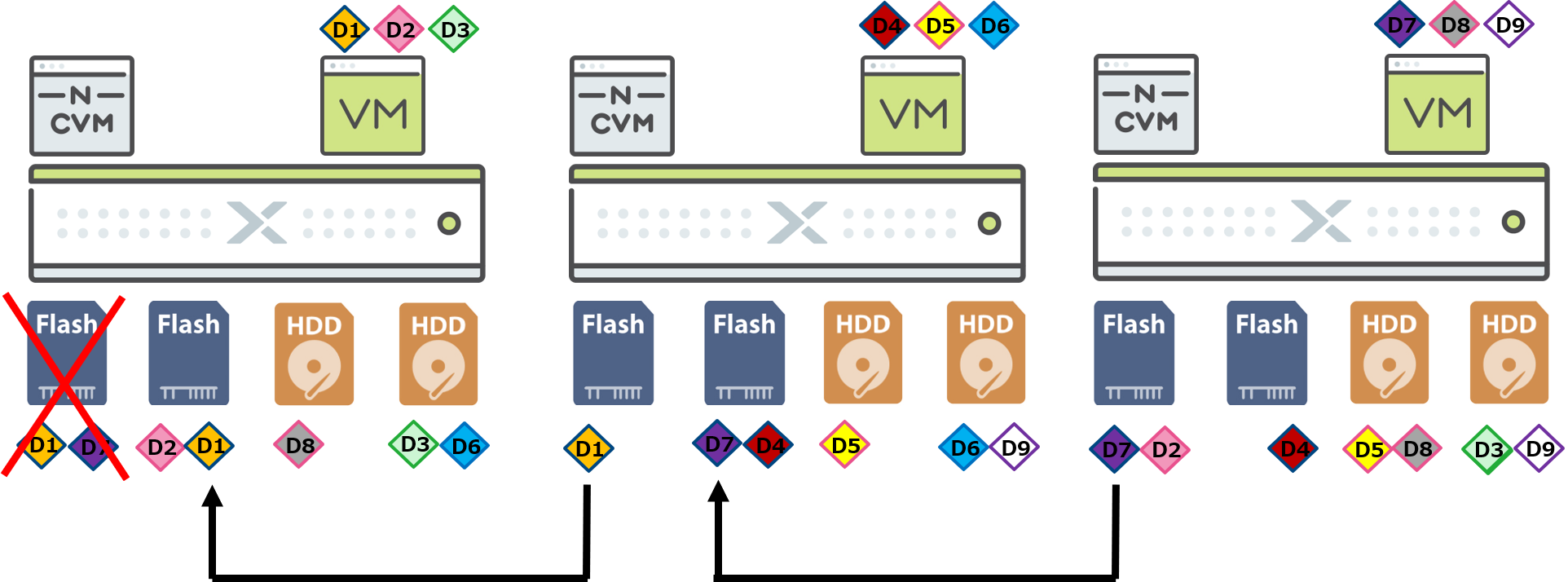
移動する先のディスクはRAIDアーキテクチャーで採用されるホットスペアのような、待機状態のディスクではく、実用量として利用しているディスクの空き領域を利用します。
データがクラスタ内のディスク全体に分散されていることで、ディスク故障が発生した際、クラスタ内の全ノードで残存するディスクすべてで負荷を分散してリビルドの処理が行われます。
これにより、I/Oのパフォーマンスへの影響を最小限に抑え、リビルドが完了するまでの時間を短縮しています。ノード数やディスク数が増えるほど分散できる範囲が広くなるため、より速くリビルドを完了し、クリティカルな状態を解消することができます。
このように、RAIDの問題点であったリビルドにかかる時間とパフォーマンスの低下を抑えたアーキテクチャとなっております。
ノード障害時の挙動
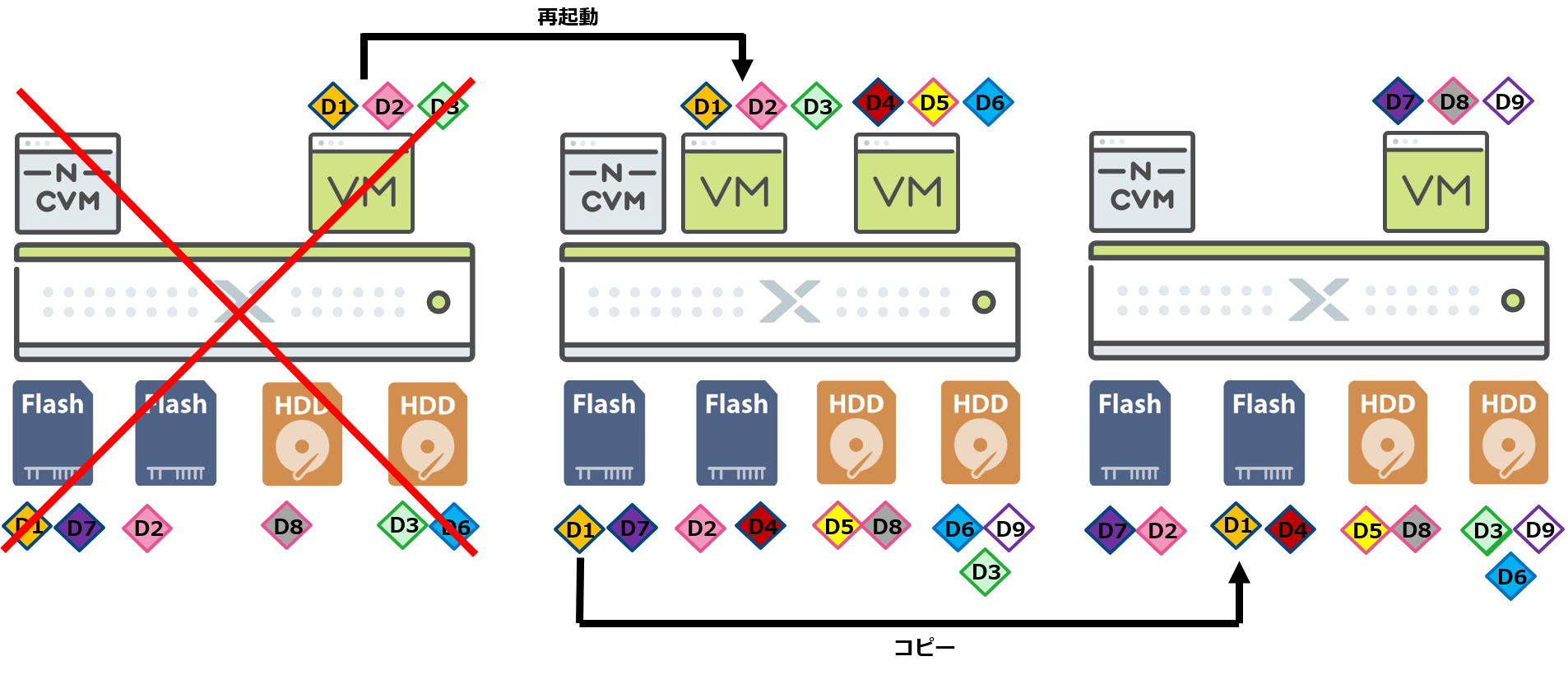
Nutanixはディスクの故障だけではなく、ノード自体に障害が発生した場合もデータを保護し、サービスを継続できる仕組みが備わっています。
ノード障害発生時は、ディスクの故障と同じように、障害が発生しているノード内に保持していたデータを、稼働しているノード間でコピーし再二重化します。ハイパーバイザーで仮想マシンのHAを有効にしておくと障害が発生したノード上で稼働していた仮想マシンは他の稼働中のノードで再起動されます。
CVM障害時の挙動
Nutanixでは、データを管理する核となるCVMに障害が発生した際にも、データを保護し、サービスを継続させることができます。
CVMに障害が発生した際には、CVMに接続されているSCSIコントローラへアクセスできなくなるため、そのCVMによって管理されているディスク内のデータは、読み込めなくなります。データの冗長性においては、ノード障害と同じように障害が発生したノード内のデータのコピーが始まります。
しかし、仮想マシンはHA等で別のノードには移動することなく、CVMの障害が発生したノードで引き続き稼働します。これは、CVMに障害が発生した場合、他のノード上のCVMがI/Oを代替で行うように自動的にパスが制御され、データへのアクセスが継続的に提供される仕組みが備わっているためです
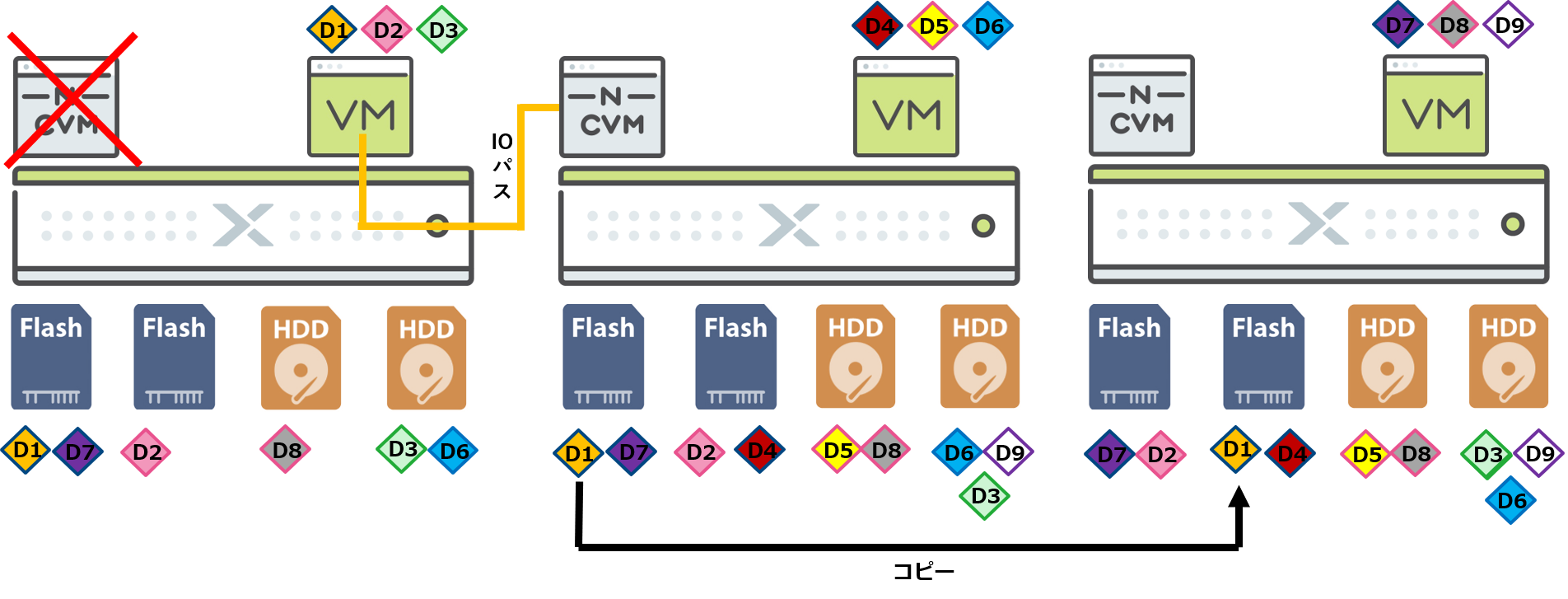
このように、Nutanix HCIにはディスクの故障に対して短い時間で再冗長化を行う仕組みに対応していることはもちろんのこと、CVMの障害やノード自体の障害に対してもクラスターサービスを継続利用できるSelf Healing機能が搭載されています。
また、ノードを跨いでデータを複数保有し、分散するという冗長化に対するアプローチによって近年RAIDが抱えていた問題点を解消しています。
Nutanixのアーキテクチャは、データの冗長化にとどまらず、パフォーマンスの安定性や拡張性といったメリットがあります。本記事を通じて、ITシステムを運用する上で最も大事なデータの取り扱い方(冗長性、安定性、拡張性)に着目いただき、今後ITインフラの製品を選定されるにあたり、「Nutanix HCI」が本当の意味での「ITシステムに求められる高可用性」を実現していることをご理解いただけましたら幸いです。
他のNutanix記事はこちら
著者紹介

SB C&S株式会社
C&S Engineer Voice運営事務局
最新の技術情報をお届けします!



