


みなさんこんにちは。
前回のブログ記事でAzure AI Searchのサービス概要やフルテキスト検索の様子をご紹介しました。(「インデックス」や「ドキュメント」といった語句については前回ご説明していますので、本ブログ記事の前にご一読いただけますと幸いです。)
最近ではAzure OpenAI ServiceのようなAIで自然言語を扱う手法への注目が集まっていることもあり、言葉の「意味」に基づく検索が求められるケースがあります。 そのような場合に利用できるのが「ベクトル検索」です。 本ブログ記事ではAzure AI Searchを利用したベクトル検索についてご紹介しますが、基本的な操作や機能をご説明するため今回もごく簡単なデータを利用いたします。
前回のブログ記事ではフルテキスト検索についてご紹介しました。 このとき利用したCSVファイルには料理など食事に関連したお手伝い券が存在しますが、「食事」という言葉自体は用いられていないため「食事」というワードでフルテキスト検索してもヒットしません。 今回は「食事」という言葉の意味を考慮した検索を行ってみます。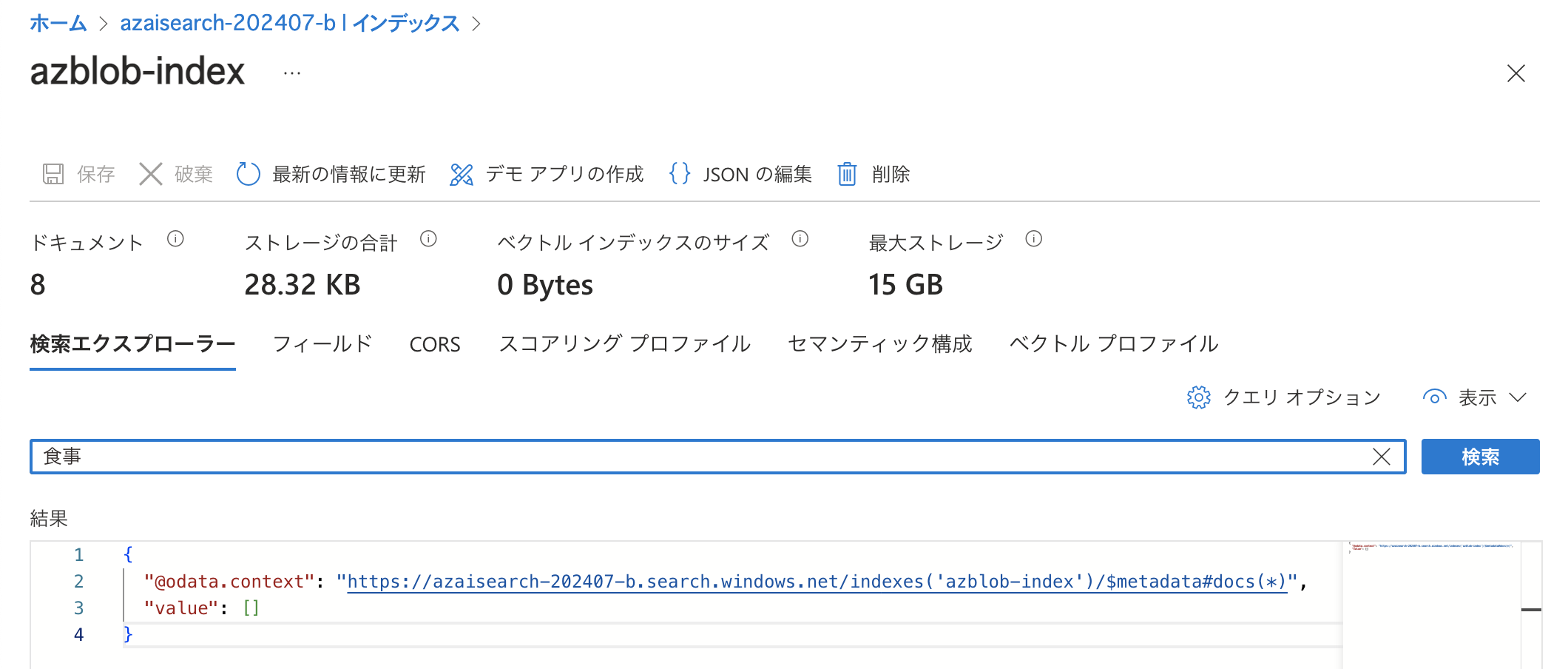
Embedding(埋め込み)とベクトル検索
まずは言葉の「意味」を考慮した検索について簡単に確認しておきましょう。 例えば「えんぴつ」と「ボールペン」は言葉として全く別のものではありますが、どちらも筆記用具という点では同じです。 また、「えんぴつ」と「pencil」のように同じものを指す言葉でも言語が異なるような場合もあります。 「何か書くもの」と言われたときに、探索対象のデータの中に存在する情報がえんぴつやボールペン、さらに英語でpencilとなっている場合でも、意味の近さを考慮した探索ができれば、こういった筆記用具の情報を活用することができるという訳です。
意味の近さを算出するにあたっては、データをベクトル形式の数値表現にしてその近さを計算します。 この考え方に基づく検索手法が「ベクトル検索」です。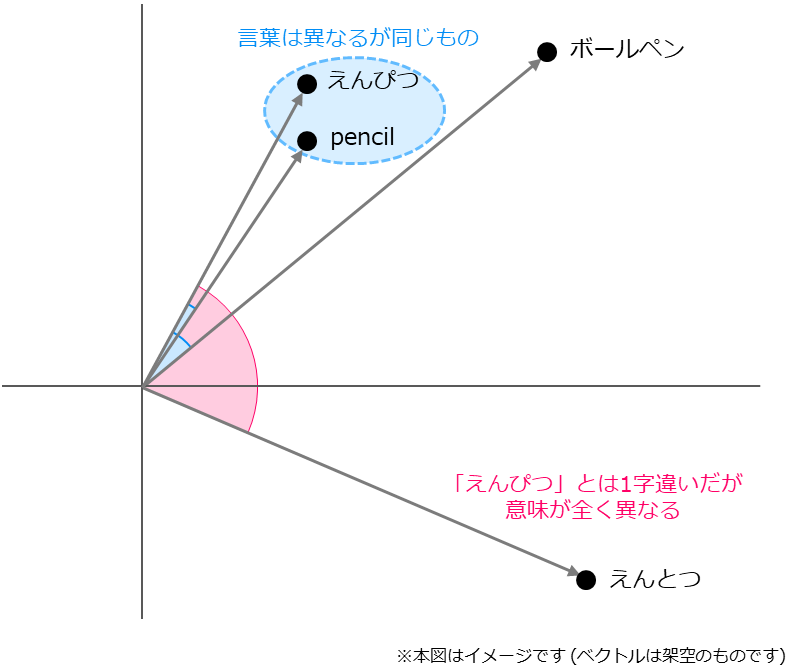
データをベクトルに変換するにあたっては、Embedding(埋め込み)のAIモデルを利用することが可能です。 Azure OpenAI ServiceではEmbeddingのためのモデルも提供されており、こちらを利用してデータをベクトルに変換することもできます。
※ Microsoft Learnのリファレンスをご覧いただくとテキストの数値変換をイメージしやすいかもしれません。
Azure OpenAI Service の REST API リファレンス - 埋め込み
https://learn.microsoft.com/ja-jp/azure/ai-services/openai/reference#embeddings
今回の目標
本ブログ記事(前編)と後続のブログ記事(後編)の2回にわたり、ベクトル検索を行えるようインデックスを作成しデータを取り込む様子をご紹介します。
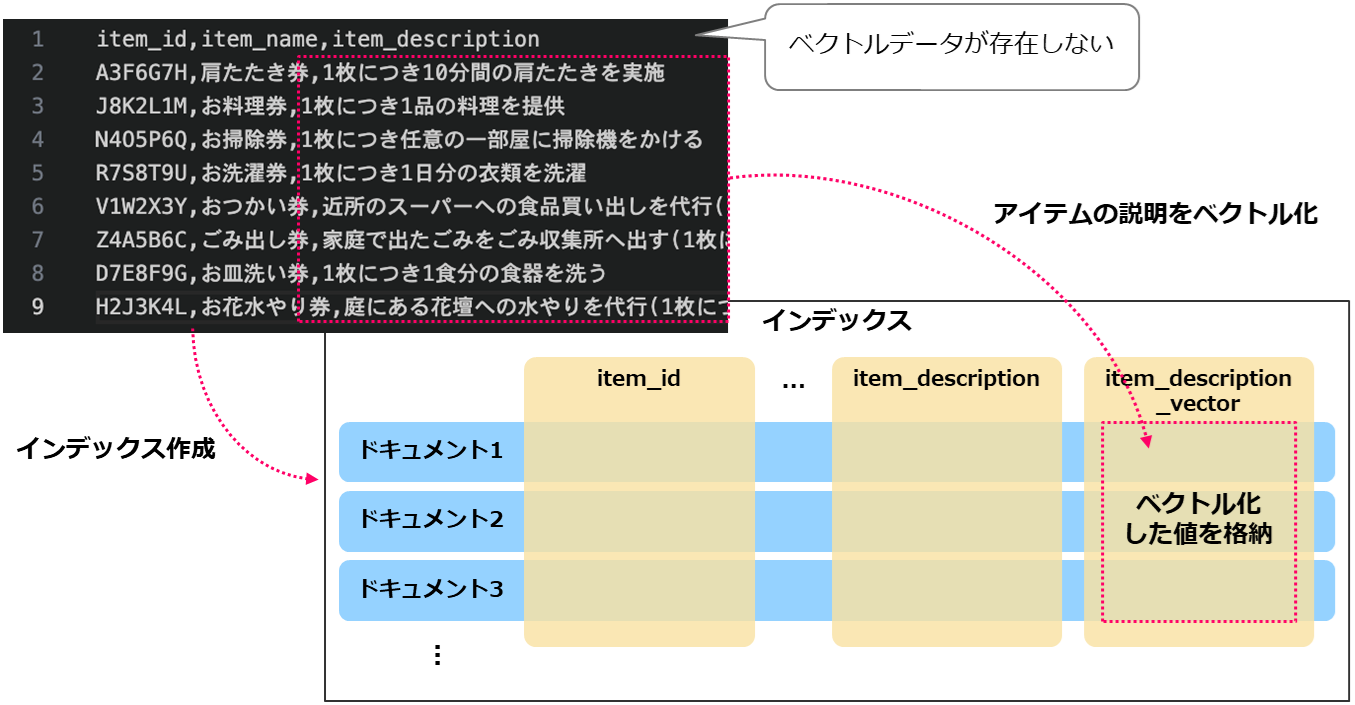
利用するデータソースは前回と同様ですが、Azure Blob ストレージに格納しているCSVファイルには(架空の)アイテムIDと名称、説明のみが記述されており、ベクトルのデータは存在しません。 このため、アイテムの説明をベクトル化したものをAzure AI Searchの機能によって新たなフィールド「item_description_vector」に格納されるようにしたいと思います。
※今回は前回のブログ記事で作成したインデックスやインデクサー、データソースなど削除した状態で、一からインデックスを作成し、インデクサーを実行します。
インデクサーを実行した後にベクトル検索を行い、前述の「食事」という言葉の意味に基づいた検索ができるか確認します。
なお、今回は基本的な機能をご紹介するため扱うドキュメントの数が少なく、item_descriptionフィールドに格納される説明文もかなり短いテキストです。 このため今回はパフォーマンスや精度などについては考慮せず進めていきます。
「データのインポートとベクター化」に関する補足
インデックスを作成するにあたり、「データのインポートとベクター化」ウィザードでインデックス作成とコンテンツのベクトル化を行うことが可能です。
ただし本機能は本ブログ記事執筆時点でプレビューの状態であり、Blobやファイルに対し 1 つのドキュメントが作成される仕様になっています。 今回利用するCSVファイルは前回のブログ記事でご説明した通り「1対多のドキュメント」として扱いたいため、本ウィザードの利用には適していません。 (「データのインポートとベクター化」の詳細についてはこちらをご参照ください。)
本ウィザードに沿ってCSVファイルをもとにインデックスを作成すると以下のようになります。 以下は「*」で検索した結果です。 「@odata.count」の値が1になっており、データが1件のみになっていることが分かります。 また「chunk」フィールドを見ると、CSVファイルに記述していたヘッダーや複数の券の情報が混在してしまっています。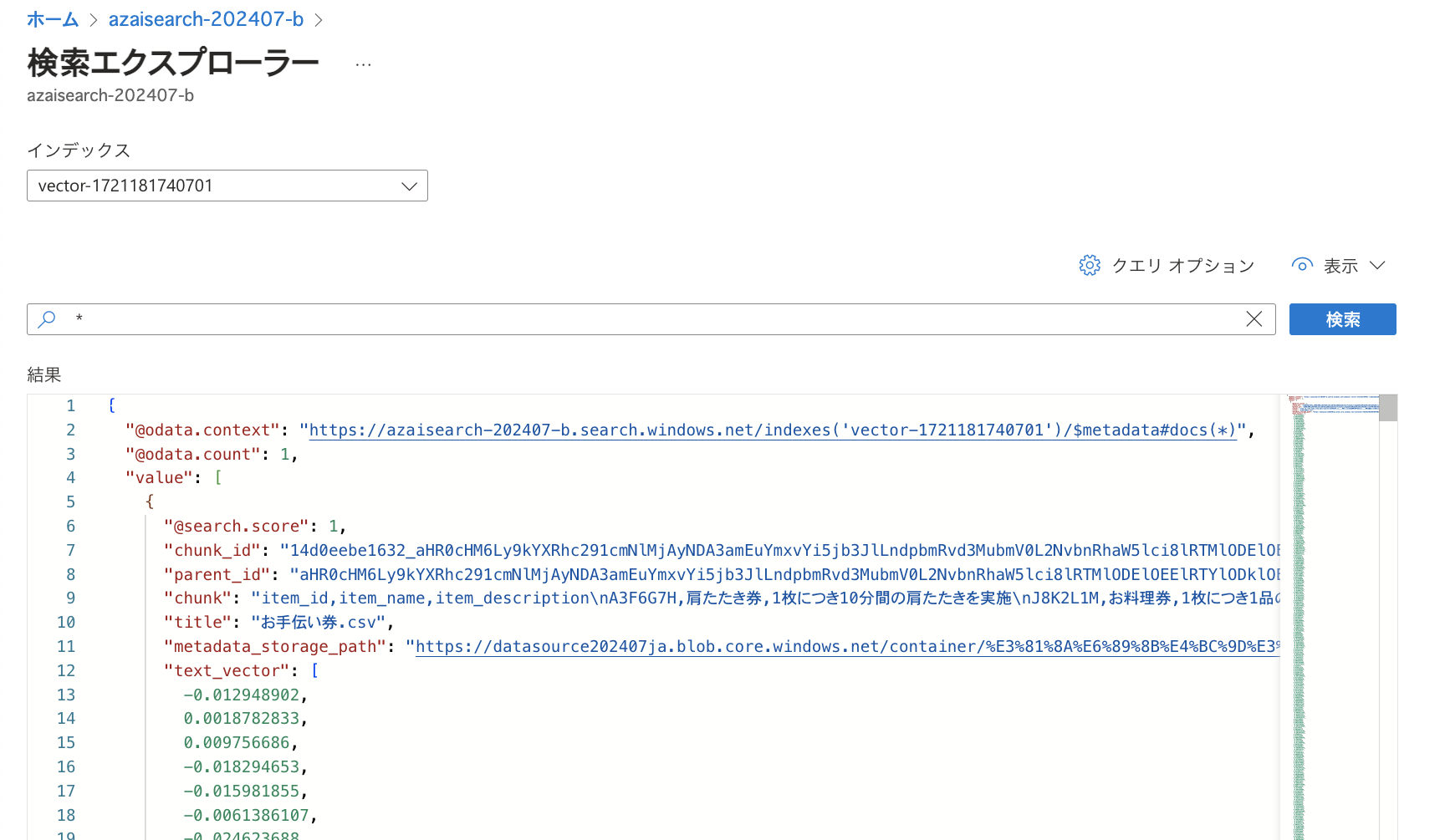
今回は「データのインポート」ウィザードも「データのインポートとベクター化」ウィザードも利用せずにインデックスへデータを組み込んでみます。(Azure Portalを使用した操作をご紹介します。)
ベクトル化されたデータを格納するためのインデックスを作成
本ブログ記事ではデータソースの登録やインデックスの作成についてご紹介します。
事前準備
事前にEmbeddingのためのAIモデルとしてAzure OpenAI Serviceに「text-embedding-ada-002」をデプロイしておきました。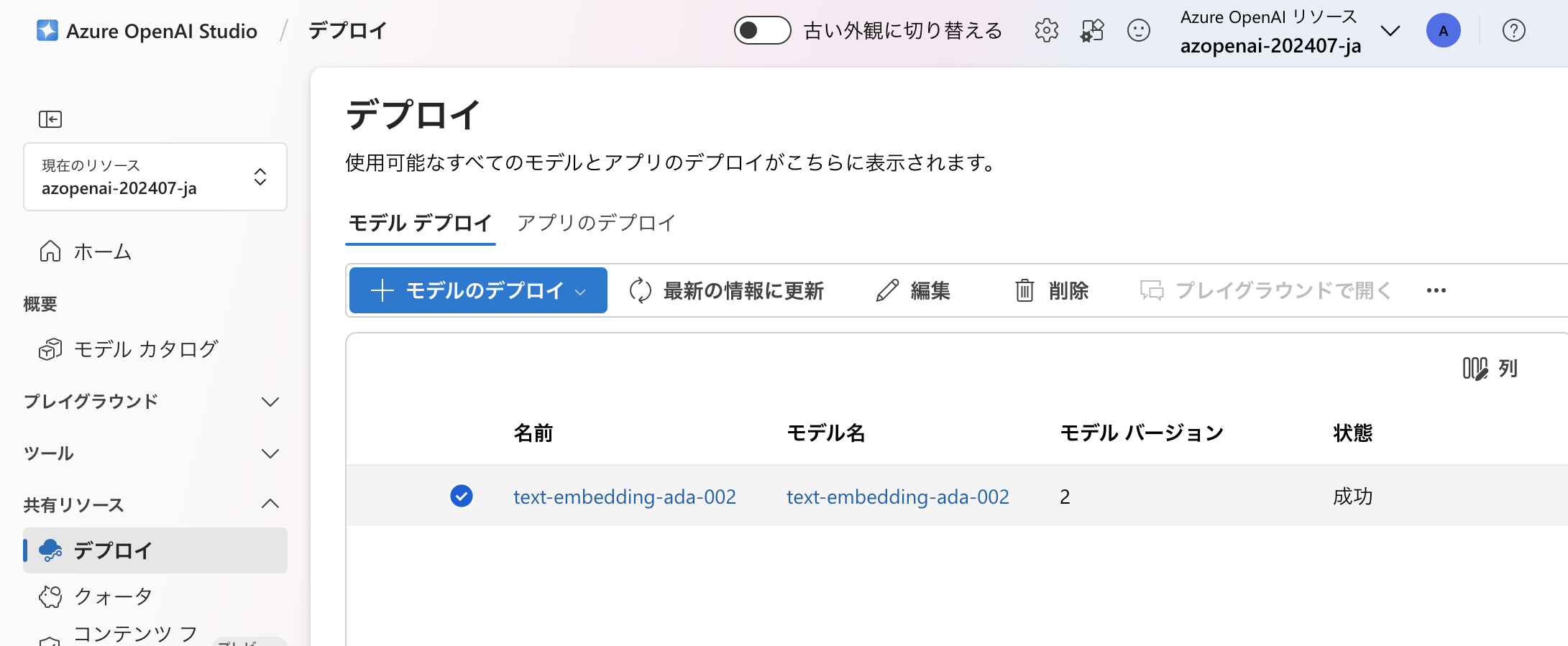
Azure OpenAI Serviceのリソース名やキーを控えておきます。(今回はAzure OpenAI Serviceの認証にキーを利用します。)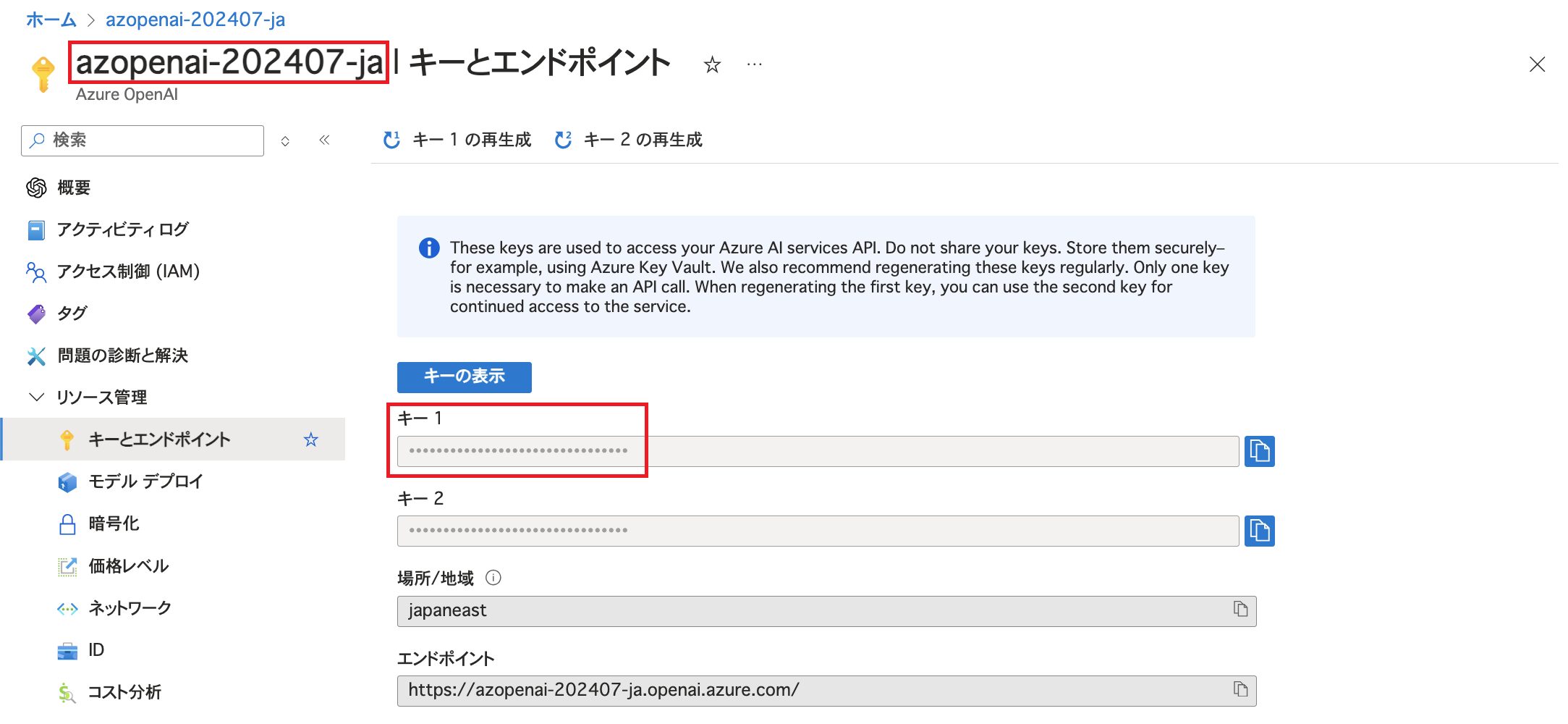
データソースの登録
インデックス作成に使用するCSVファイルの在り処であるAzure Blob ストレージをAzure AI Searchのデータソースとして登録します。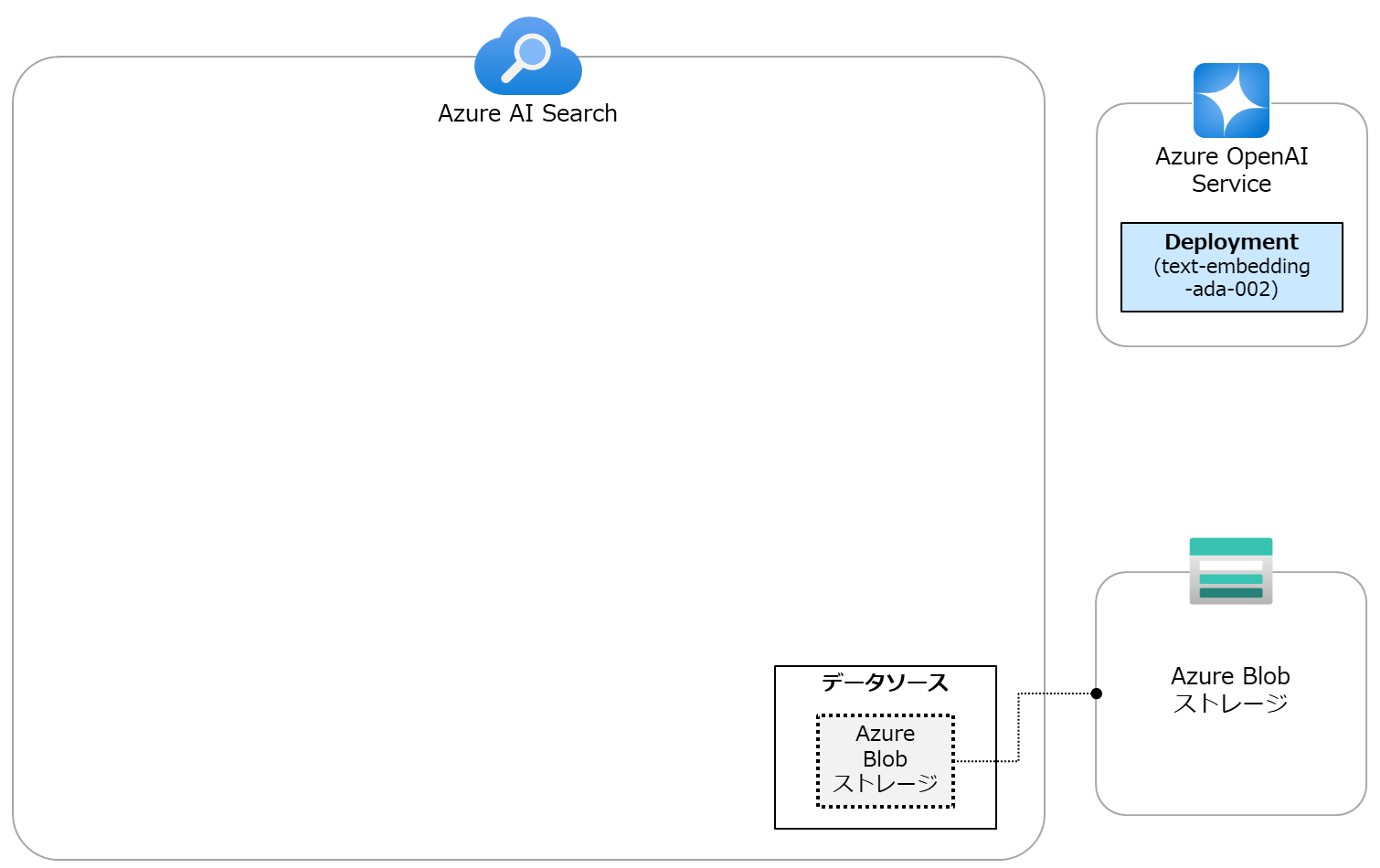
Azure AI Searchの「データソース」を開いて「データソースの追加」をクリックします。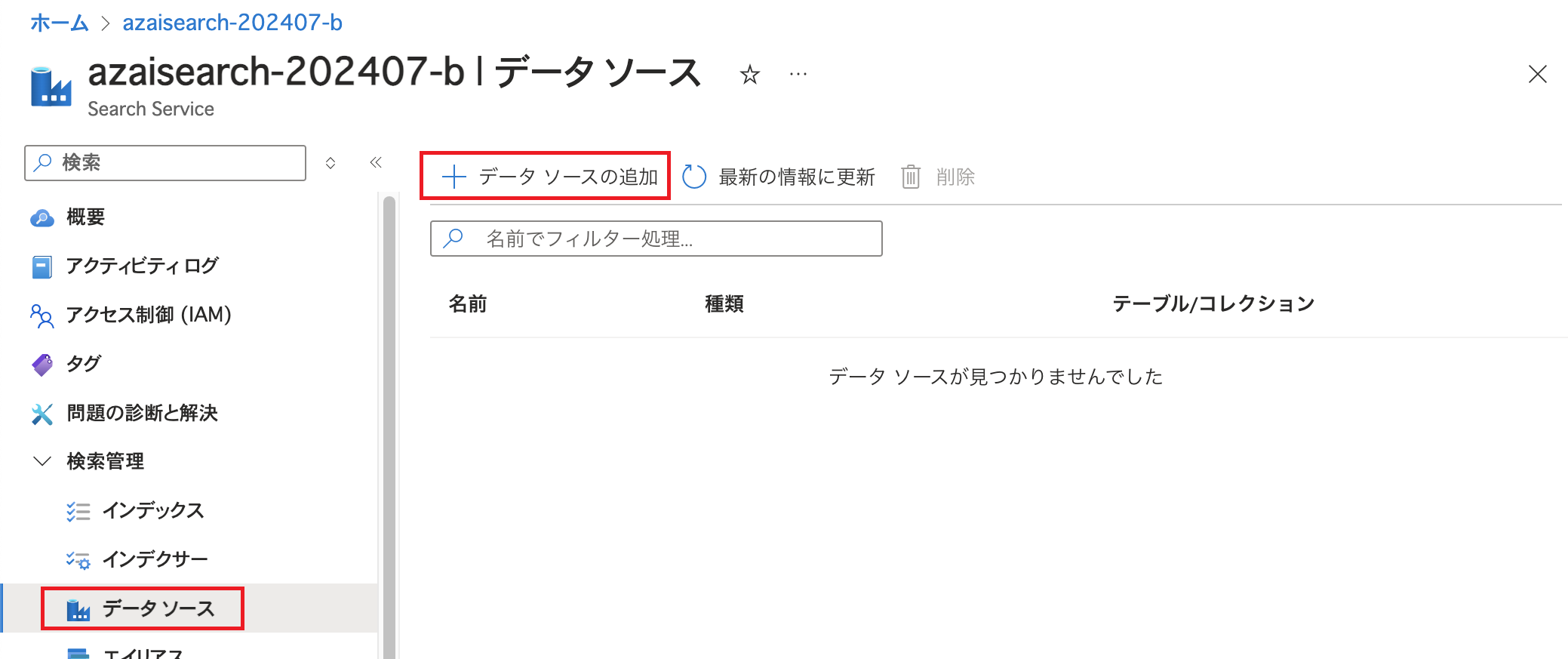
Azure Blob ストレージの情報を入力し「保存」をクリックします。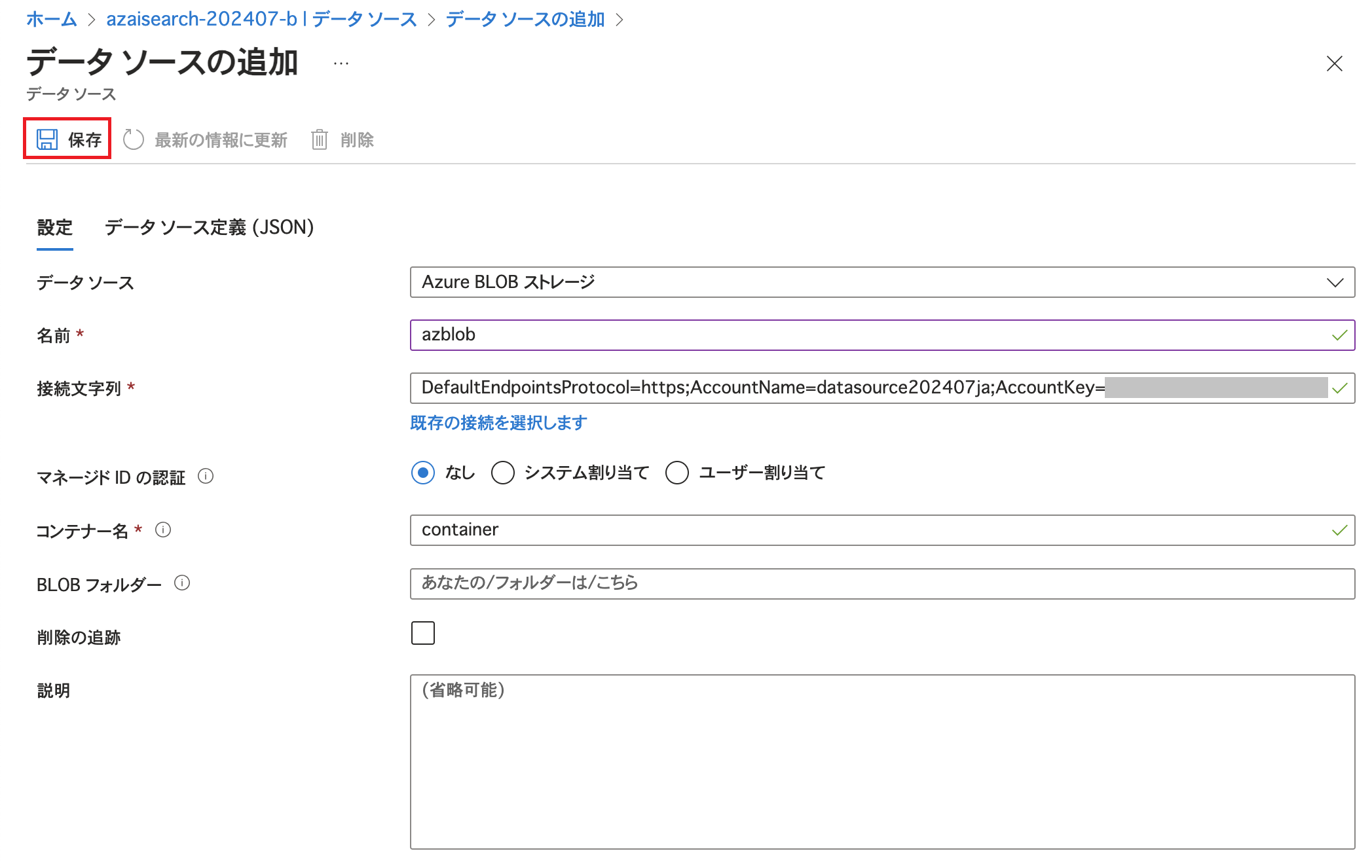
インデックスの作成
インデックスを新たに作成します。 ここではまだデータソースからデータの取り込みはせず、データを取り込むための箱を作るようなイメージです。
「インデックス」を開き「インデックスの追加」をクリックします。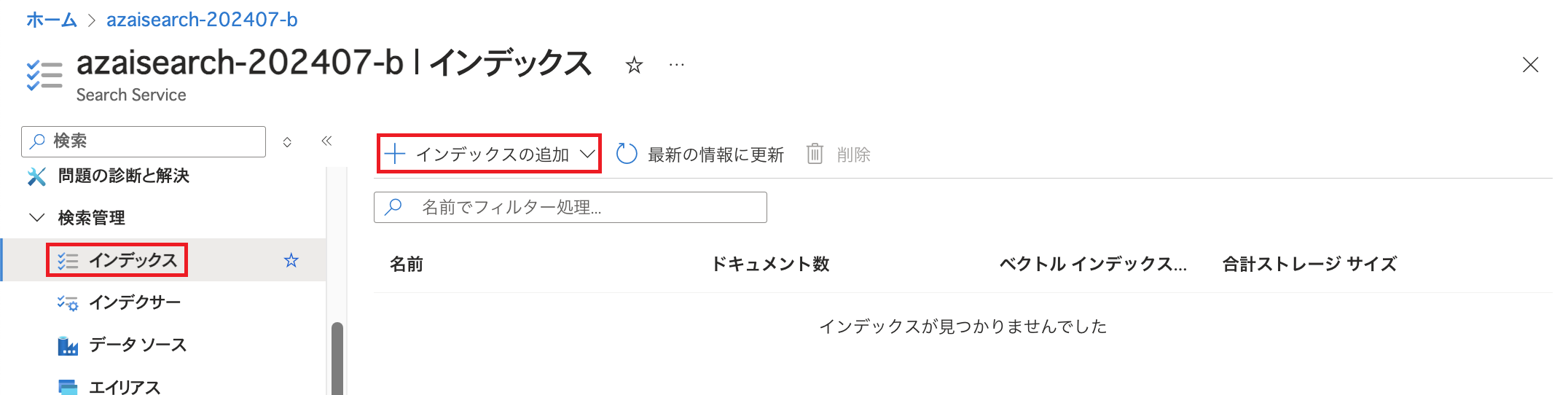
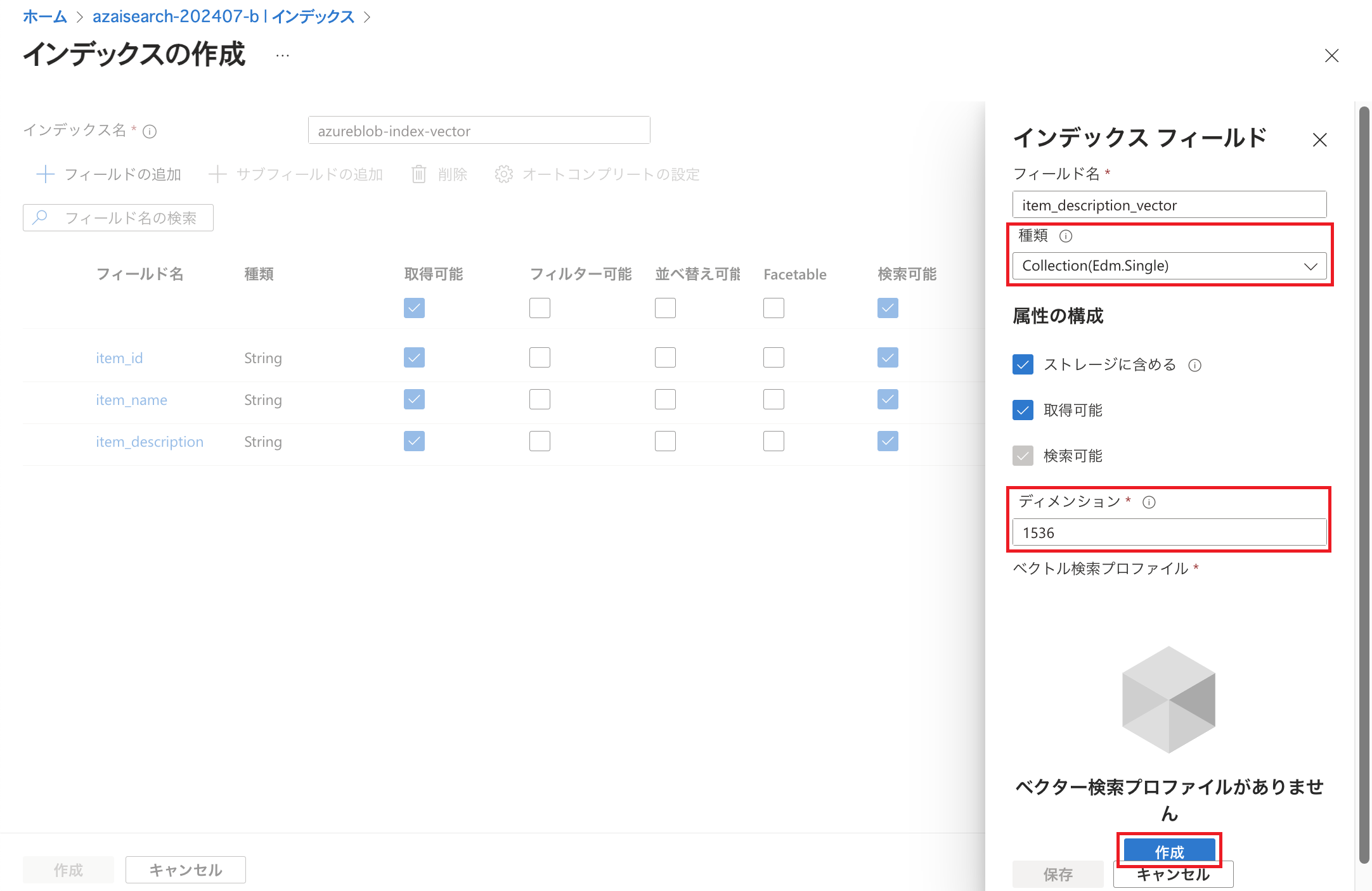
フィールドを追加していきます。 フィールド名はCSVファイル内のヘッダーに合わせています。 フィールドについては前回のブログ記事でご説明していますのでそちらをご参照ください。 なお、今回は「item_description」のデータをベクトル化して「item_description_vector」というフィールドに格納します。 種類を「Collection(Edm.Single)」とし、動作確認のためにベクトルのデータを参照できるよう「取得可能」にチェックを入れています。 ディメンションについては利用するAIモデルを考慮して設定します。 Microsoft Learnに記載の通り「text-embedding-ada-002」を利用する場合は「1536」とします。 ベクター検索プロファイル(ベクトルプロファイル)の「作成」をクリックします。
※Azure AI Searchにおけるベクトル検索の仕組みについてはこちらで紹介されていますが、ベクトルデータのインデックス化やクエリに対する処理のためベクトル検索プロファイルを設定します。
アルゴリズムの「作成」をクリックします。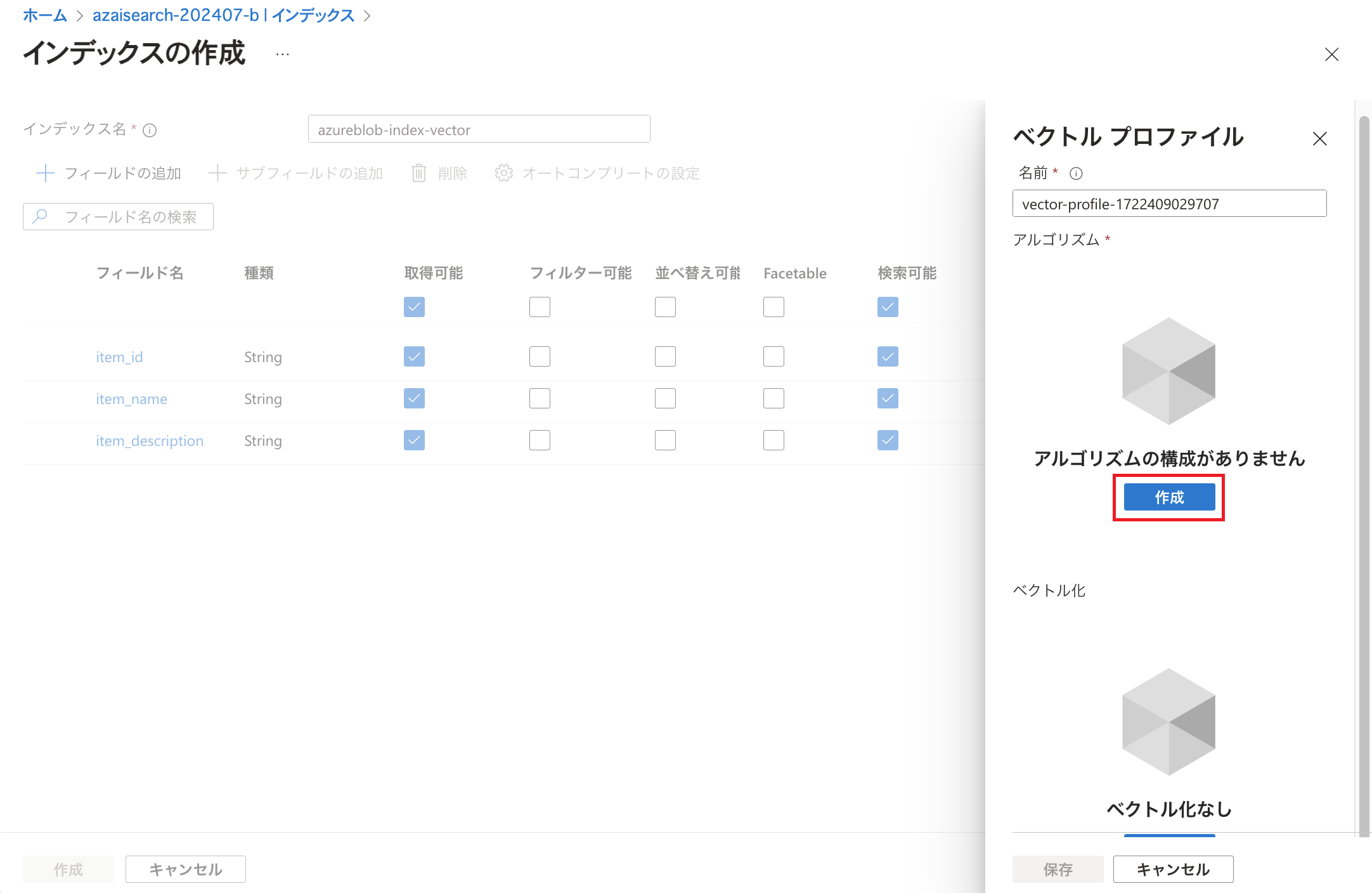
ここではベクトル検索のためのアルゴリズムを設定します。 Azure AI Searchのベクトル検索プロファイルでは「Hierarchical Navigable Small World (HNSW)」や「完全なKニアレストネイバー (KNN)」といったアルゴリズムを選択できるようになっており、ここではHNSWを設定しています。 ここでは各Kindパラメーターの値をデフォルトのまま「保存」しています。(各パラメーターについてはこちらで説明されています。)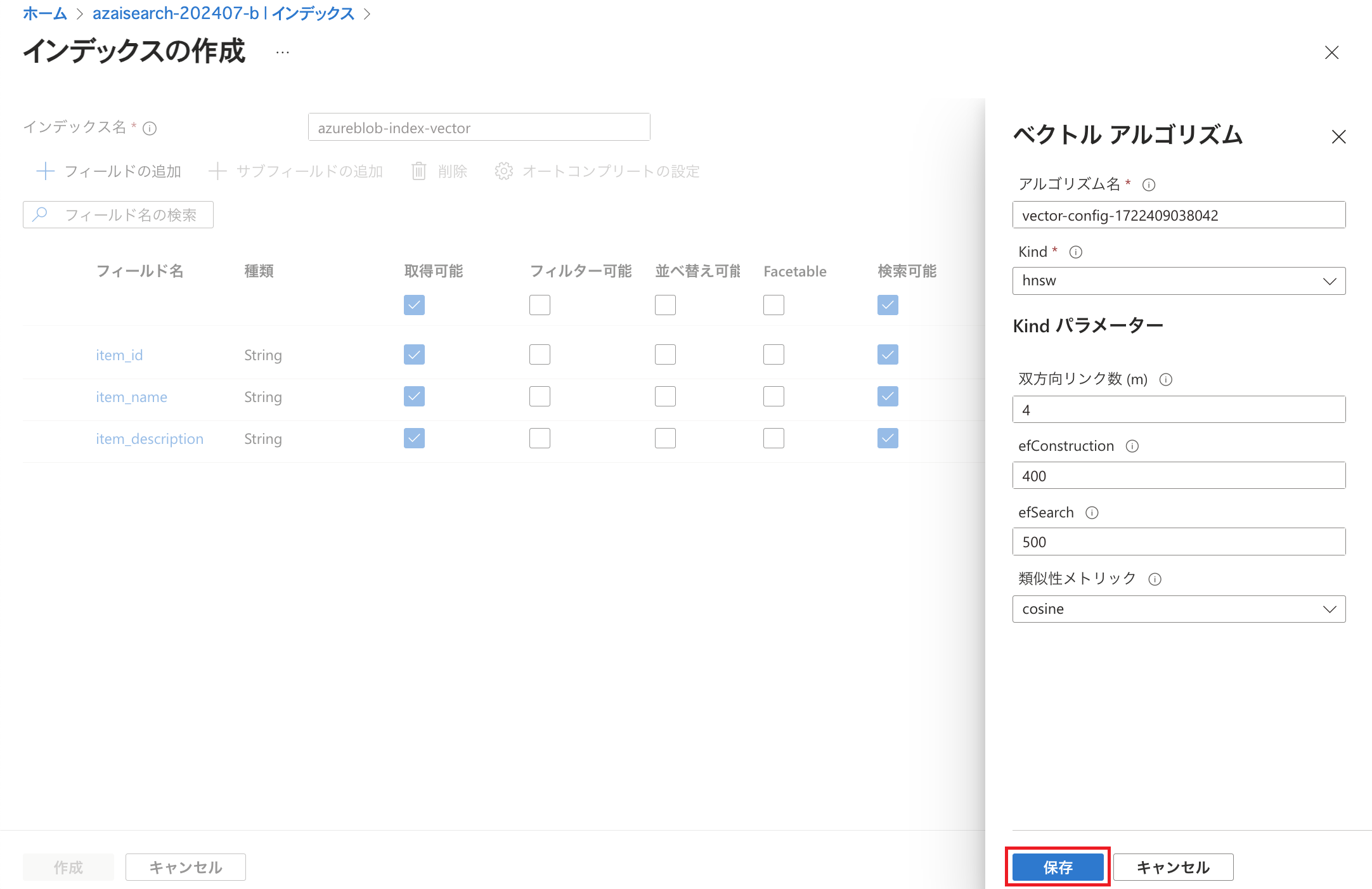 ベクトル化の「作成」をクリックします。 こちらはクエリ実行の際にテキストをベクトルに変換するための設定です。 本設定を行うことによって、Microsoft Learnで紹介されているようにクエリに記述されたテキストをベクトル化して検索することができるようになります。
ベクトル化の「作成」をクリックします。 こちらはクエリ実行の際にテキストをベクトルに変換するための設定です。 本設定を行うことによって、Microsoft Learnで紹介されているようにクエリに記述されたテキストをベクトル化して検索することができるようになります。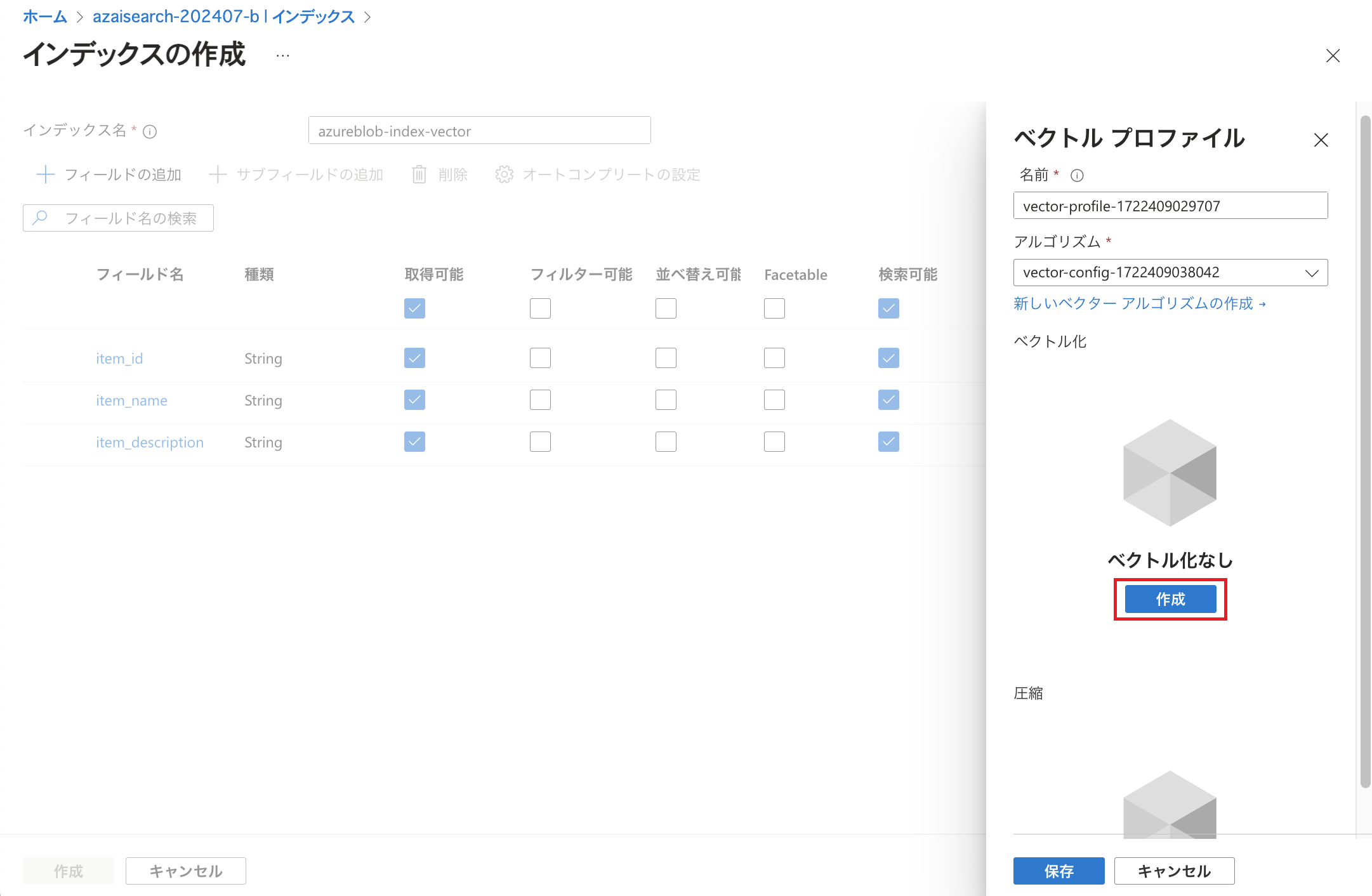
Embeddingのためのモデルを指定して「保存」をクリックします。 今回はインデックスに格納するベクトルデータを生成するために「text-embedding-ada-002」を利用しますので、ここでは同じ種類のモデルを指定する必要があります。(こちらに前提条件が記載されていますのでご参照ください。)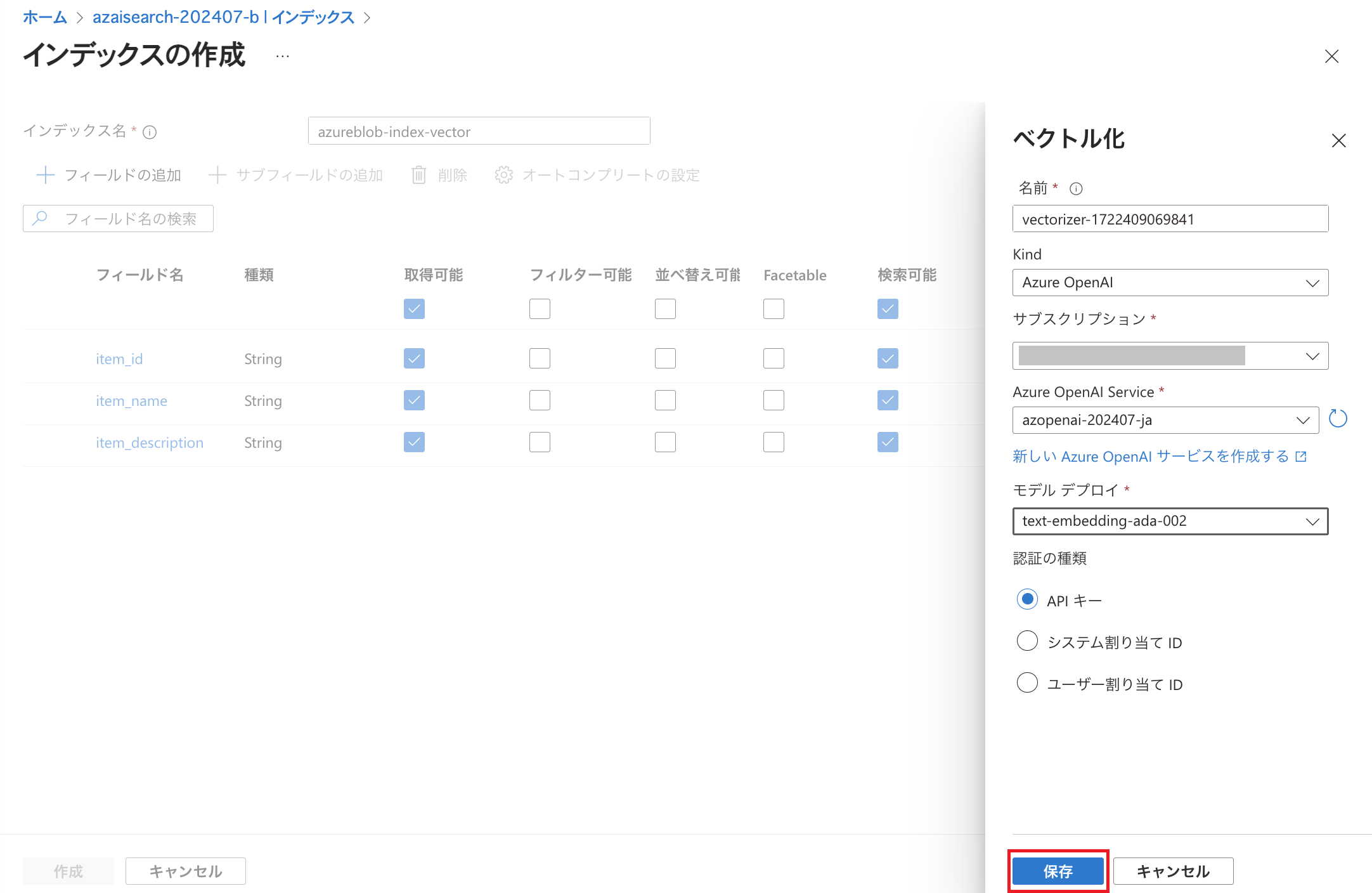
今回は圧縮の設定は行わず、「保存」をクリックします。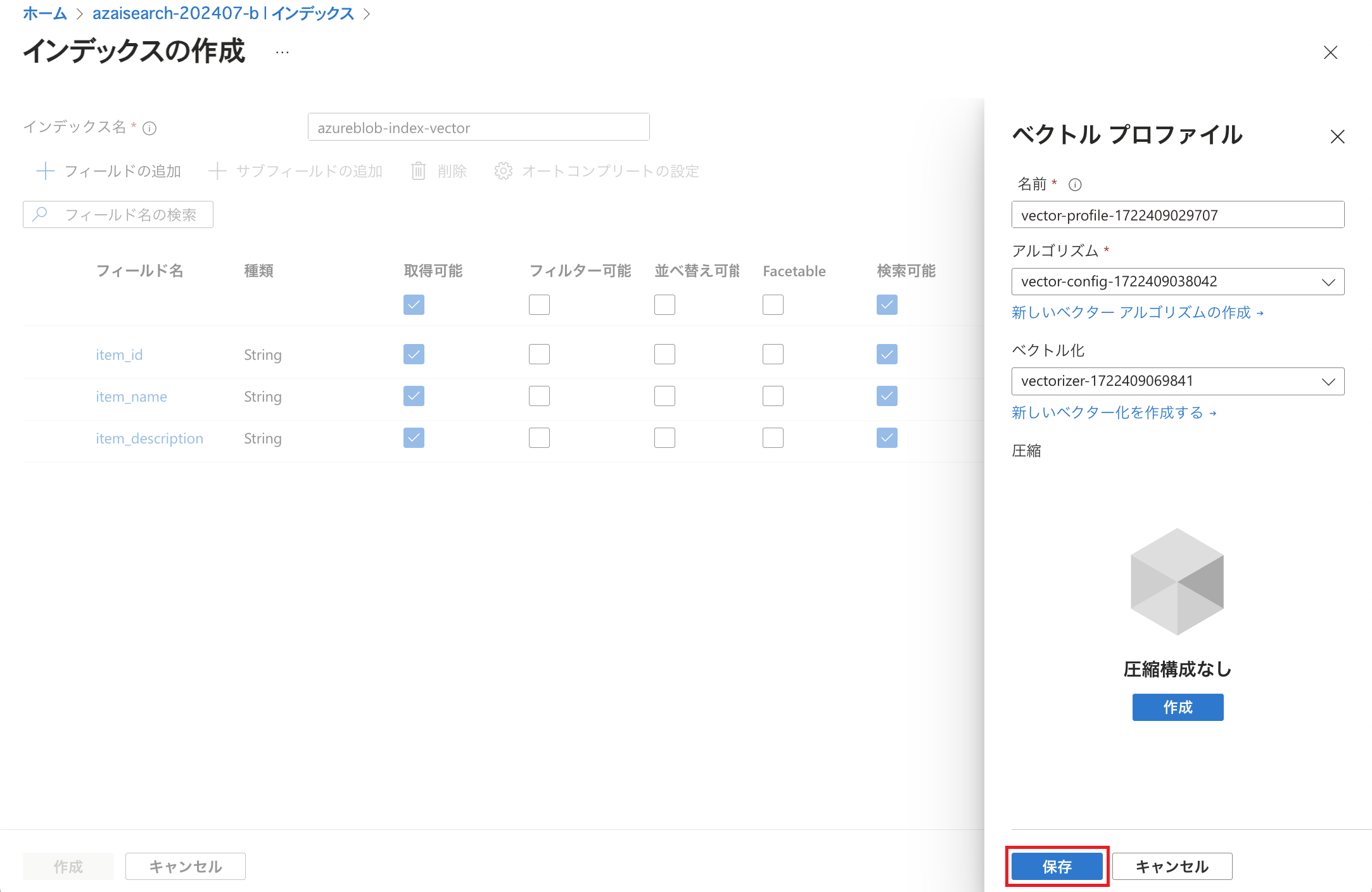
ベクトルプロファイルの設定ができましたので「保存」をクリックします。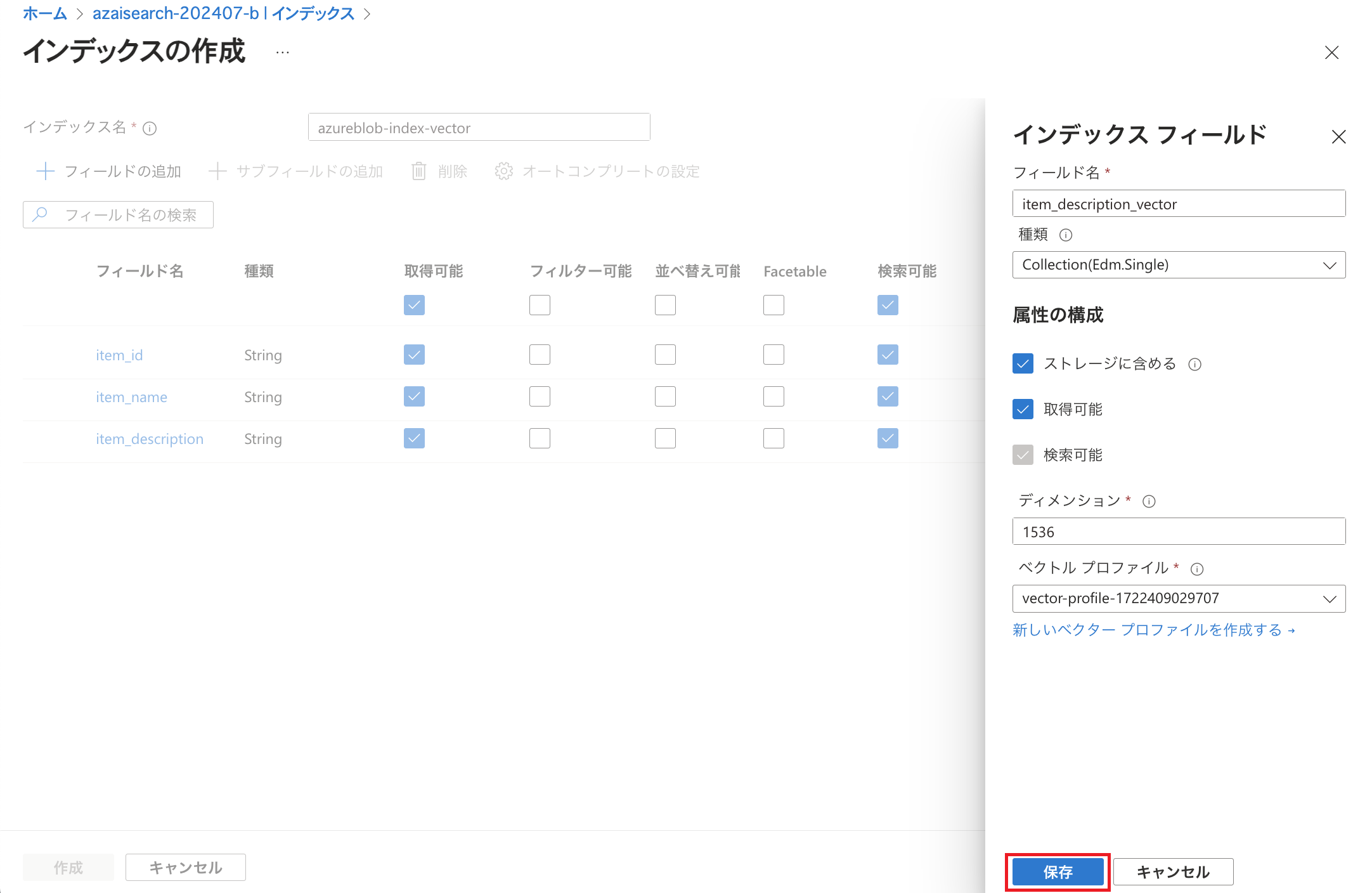
キーは前回のブログ記事と同様に「AzureSearch_DocumentKey」としておきました。
※事前に用意したCSVファイルではitem_idが一意の値になっているためこちらをキーとして利用することもできますが、今回は前回のブログ記事と同様としました。 キーに関してはこちらに記載の通り制限事項があります。
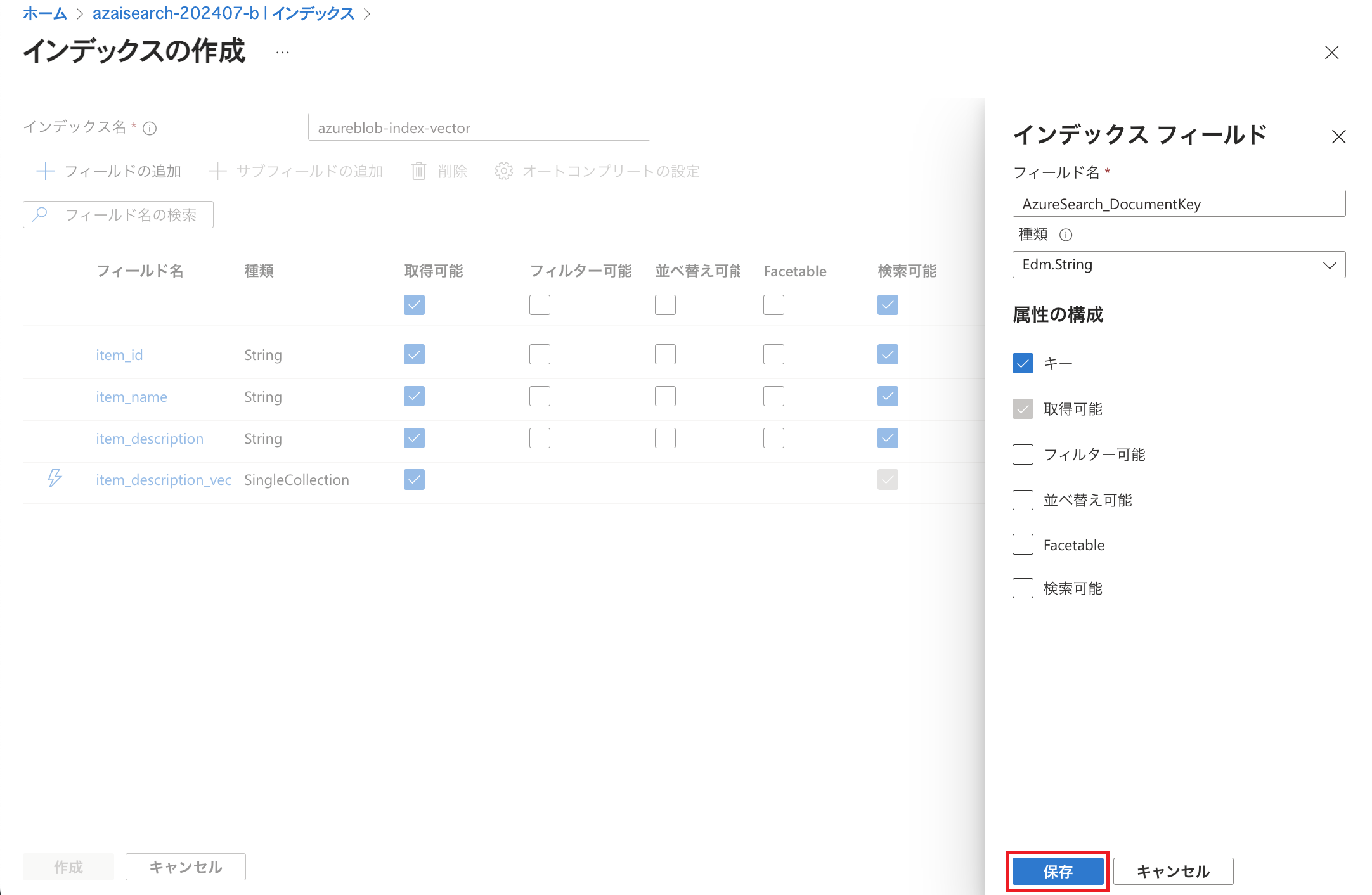
「作成」をクリックします。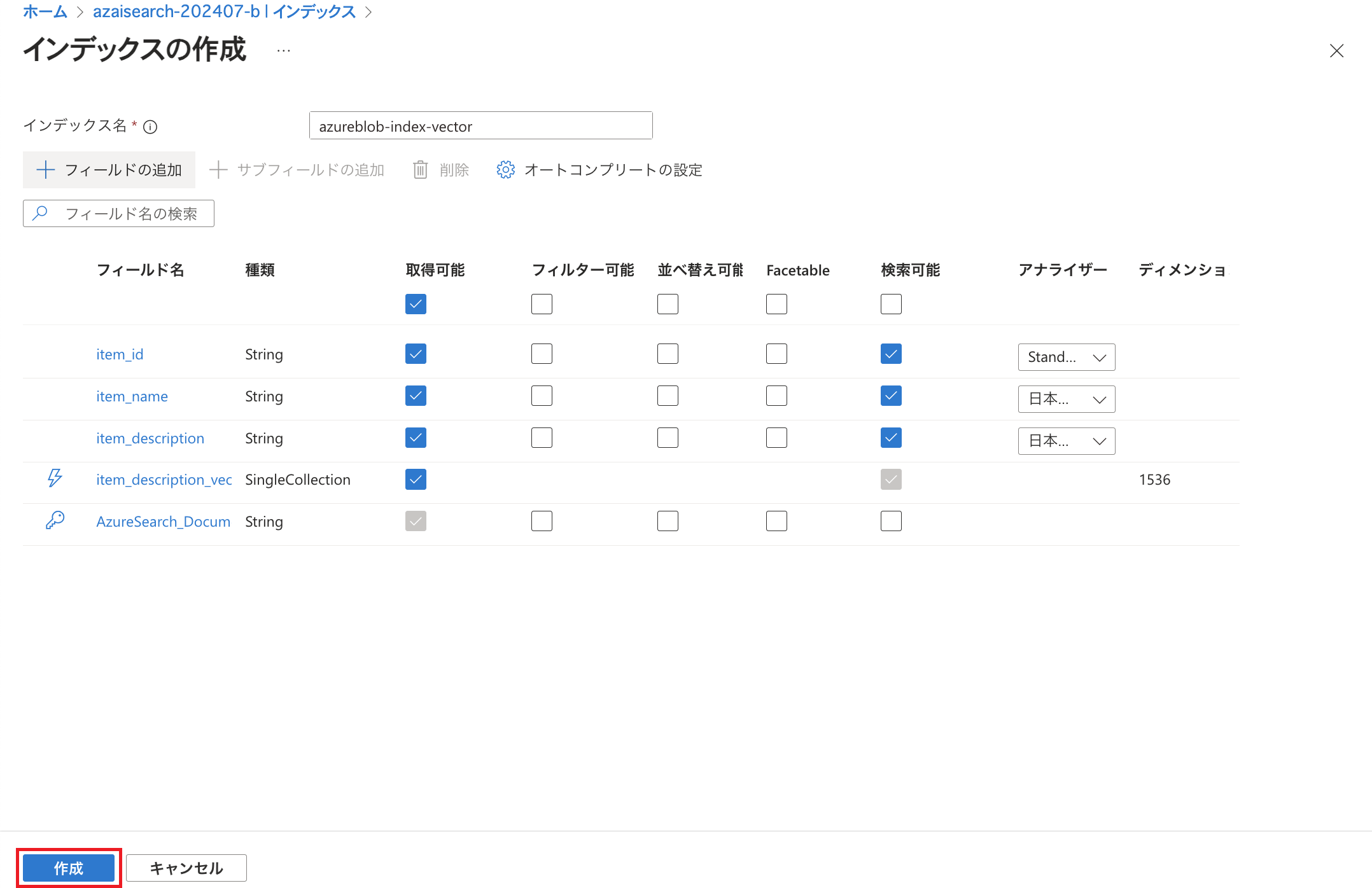
下図はここで行った操作のイメージです。(図中ではフィールドを一部省略しています。) ここでは「item_description_vector」フィールドを用意し、ベクトルプロファイルを設定したという点がポイントです。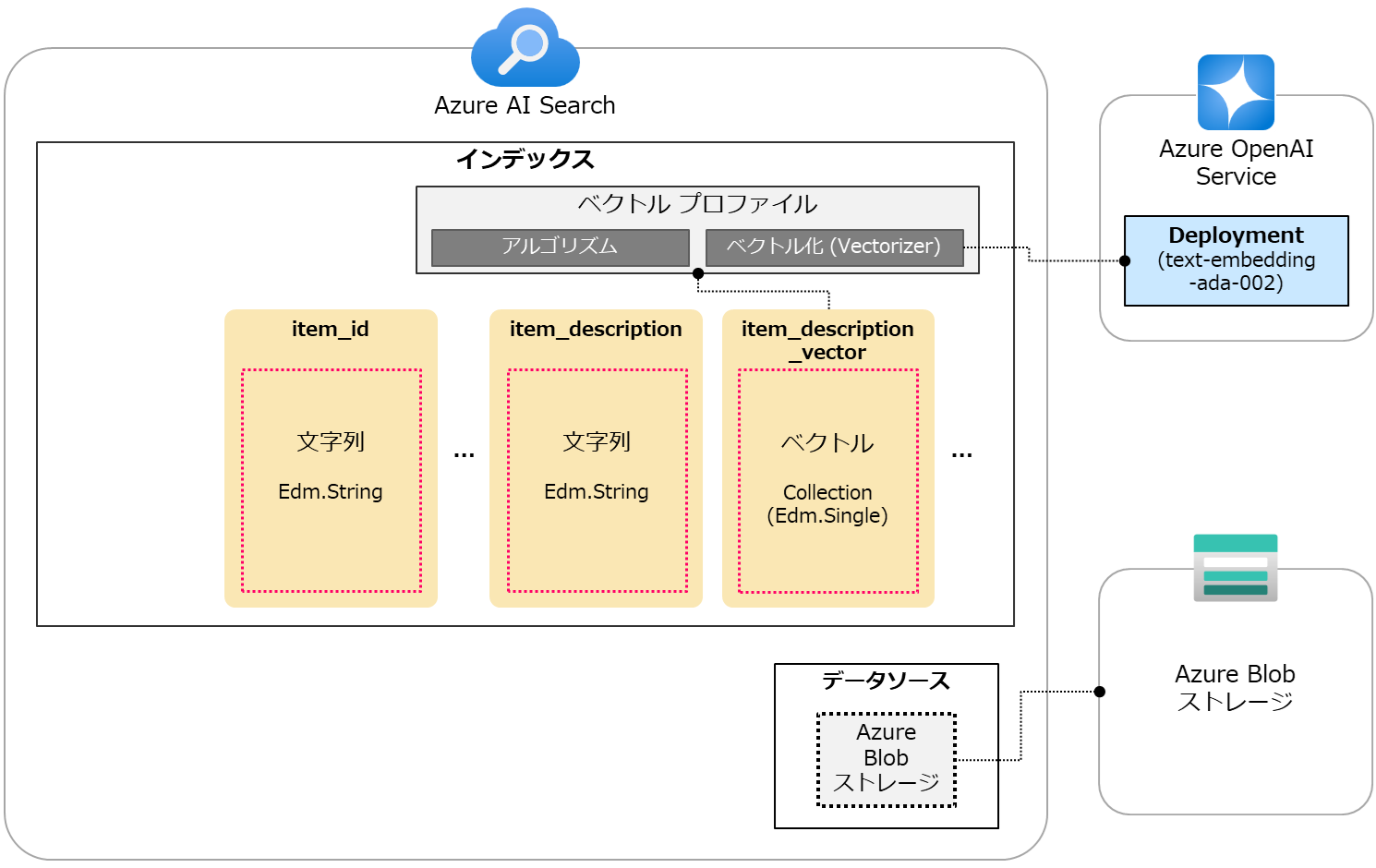
まとめ
本ブログ記事ではベクトル検索を行うためにデータソースの登録、インデックスを作成する様子をご紹介しました。
この時点では作成したインデックスにドキュメントがなく、ベクトル化されたデータも存在しません。 「後編」でデータのベクトル化やインデクサーの実行などご紹介いたします。
インデックスのフィールドに「ベクトル化」の設定を行った意味など少々分かりにくいかもしれませんが、「後編」でベクトル検索を行う際に改めてご説明いたします。
Azureを取り扱われているパートナー企業様へ様々なご支援のメニューを用意しております。 メニューの詳細やAzureに関するご相談等につきましては以下の「Azure相談センター」をご確認ください。
Azure相談センター
https://licensecounter.jp/azure/
※ 本ブログ記事は弊社にて把握、確認された内容を基に作成したものであり、サービス・製品の動作や仕様について担保・保証するものではありません。サービス・製品の動作、仕様等に関しては、予告なく変更される場合があります。
Azureに関するブログ記事一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄
