


みなさんこんにちは。
Azure AI Searchの基礎的な内容を以下のブログ記事でご紹介しています。
簡単なデータを使ってAzure AI Search入門(1) - サービスの概要
簡単なデータを使ってAzure AI Search入門(2) - ベクトル検索(前編)
Azure AI Search独自の語句など少しずつ知っていただけるような構成にしていますので、(1)からご覧いただけますと幸いです。
本ブログ記事は「簡単なデータを使ってAzure AI Search入門(2) - ベクトル検索(前編)」の続きです。 前編ではベクトル検索を行うためのインデックスの作成までを行いました。 下図は実施した設定のイメージです。(図中ではフィールドを一部省略しています。) 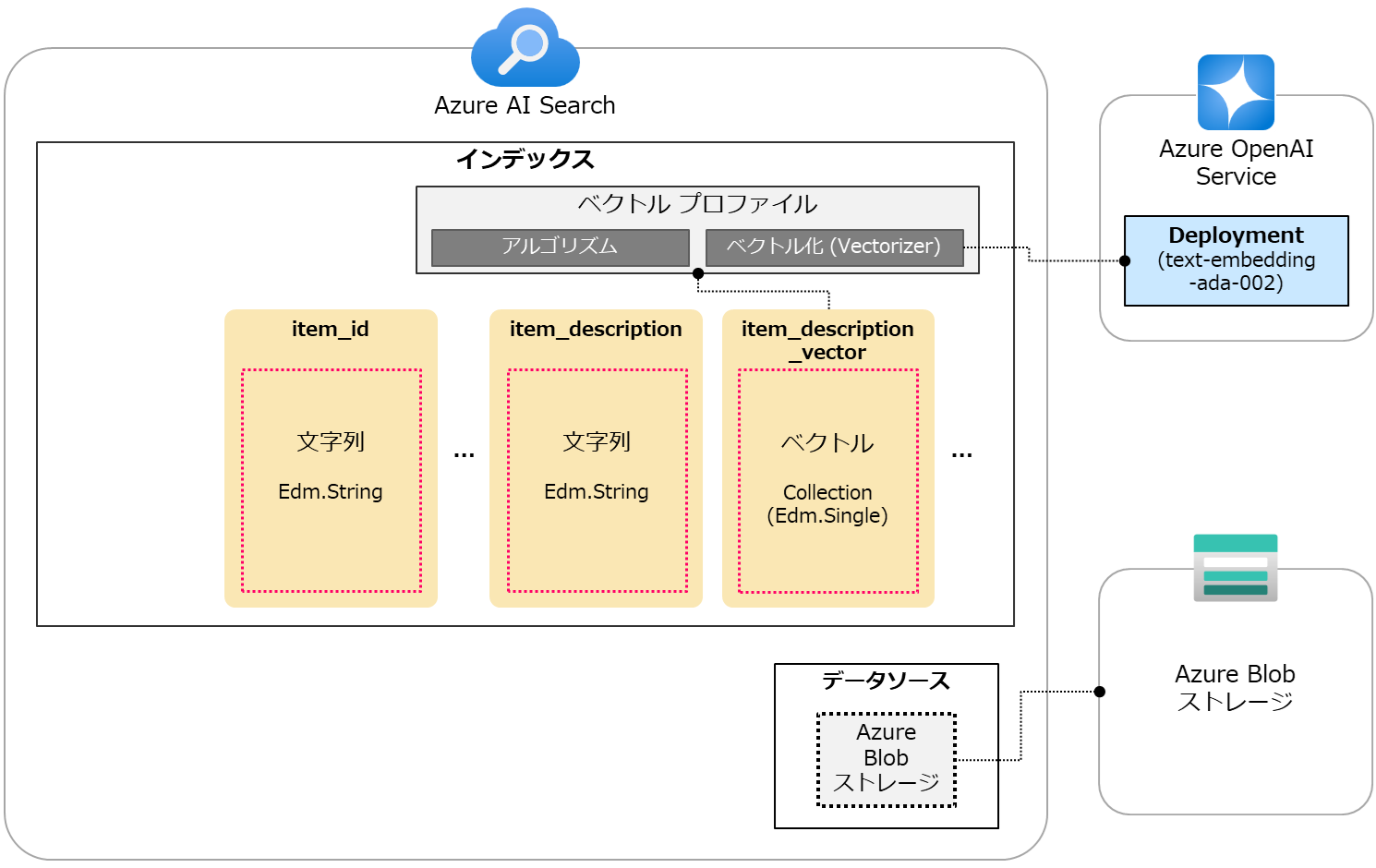
ベクトル化されたデータを含むインデックスを作成 (続)
前編でご紹介した設定を完了した時点では、インデックス内にドキュメントがなくベクトル化されたデータも存在していません。 ベクトル検索を行えるよう、本ブログ記事では後続の設定をご紹介します。
スキルセットの作成
インデックス作成にあたり、データに何らかの処理を加えた(エンリッチした)上でインデックスに格納したいというケースがあります。 Azure AI Searchではこのような場合に「スキルセット」を利用することが可能です。 例えば「長いテキストを特定の長さに分割する」「テキストを結合する」「テキストを翻訳する」といった個々の処理をそれぞれ「スキル」とし、一連のスキルを「スキルセット」として設定します。 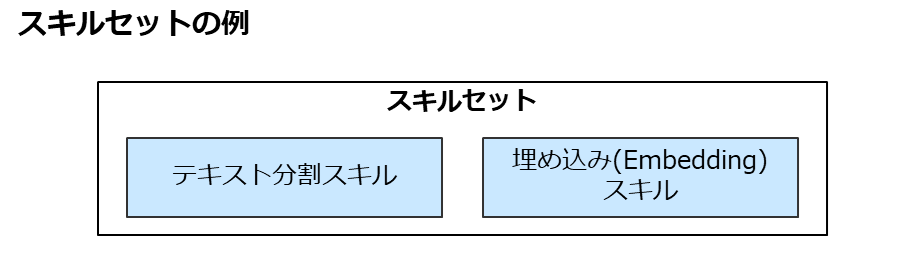
今回はCSVファイルに記載された説明をベクトル化するため、Azure OpenAI Serviceの「text-embedding-ada-002」による埋め込み(Embedding)処理をスキルとして設定します。
※ Microsoft Learnではテキストをチャンクに分割(チャンキング)した上でベクトル化する手法が紹介されていますが、今回扱うテキストは非常に短いためテキスト分割スキルは設定せず、スキルセットに埋め込み(Embedding)処理のみ設定します。 長いテキストを扱うような場合はテキスト分割スキルの併用をご検討ください。
「スキルセット」を開き「スキルセットを追加」をクリックします。
「スキル定義テンプレート」で「Azure OpenAI 埋め込みスキル」を選択すると、画面右下にテンプレートが表示されます。 これをskillsにコピーし、前編の事前準備で用意したAzure OpenAI Serviceのリソースの情報に基づいて値を編集します。 dimensionsの値を「1536」としていますが、こちらはEmbeddingのために利用するモデル「text-embedding-ada-002」でサポートされるディメンションが1536であるためです。また、スキルにはコンテキスト(context) / 入力(inputs) / 出力(outputs)といった設定項目が存在します。 これらの設定の意味については後ほど改めてご説明いたします。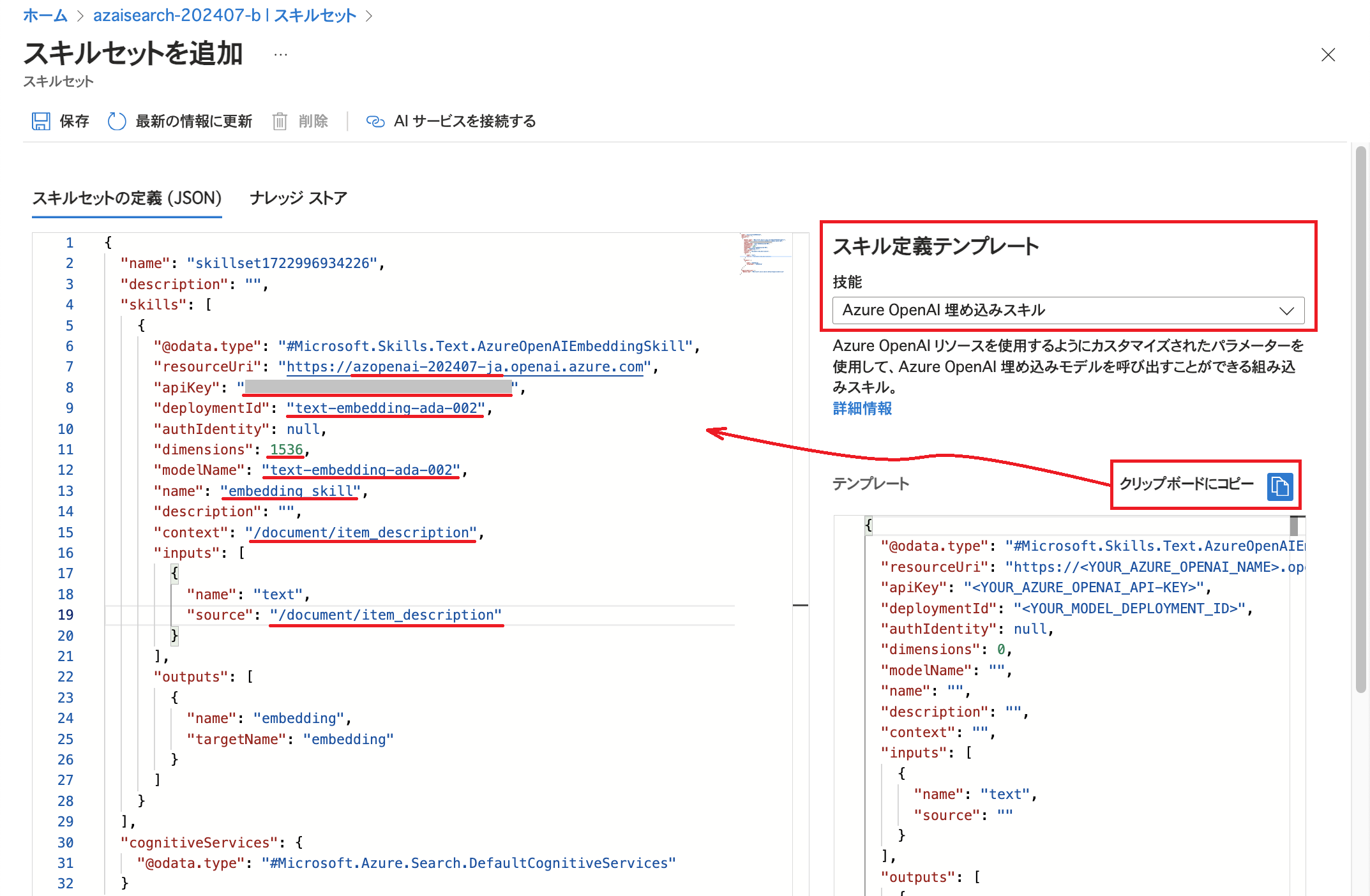
編集が完了したら左上の「保存」をクリックします。 
下図はここまで実施した設定のイメージです。 スキルセットの中にAzure OpenAI 埋め込みスキルがあり、本スキルはAzure OpenAI Serviceにデプロイしているモデルを利用します。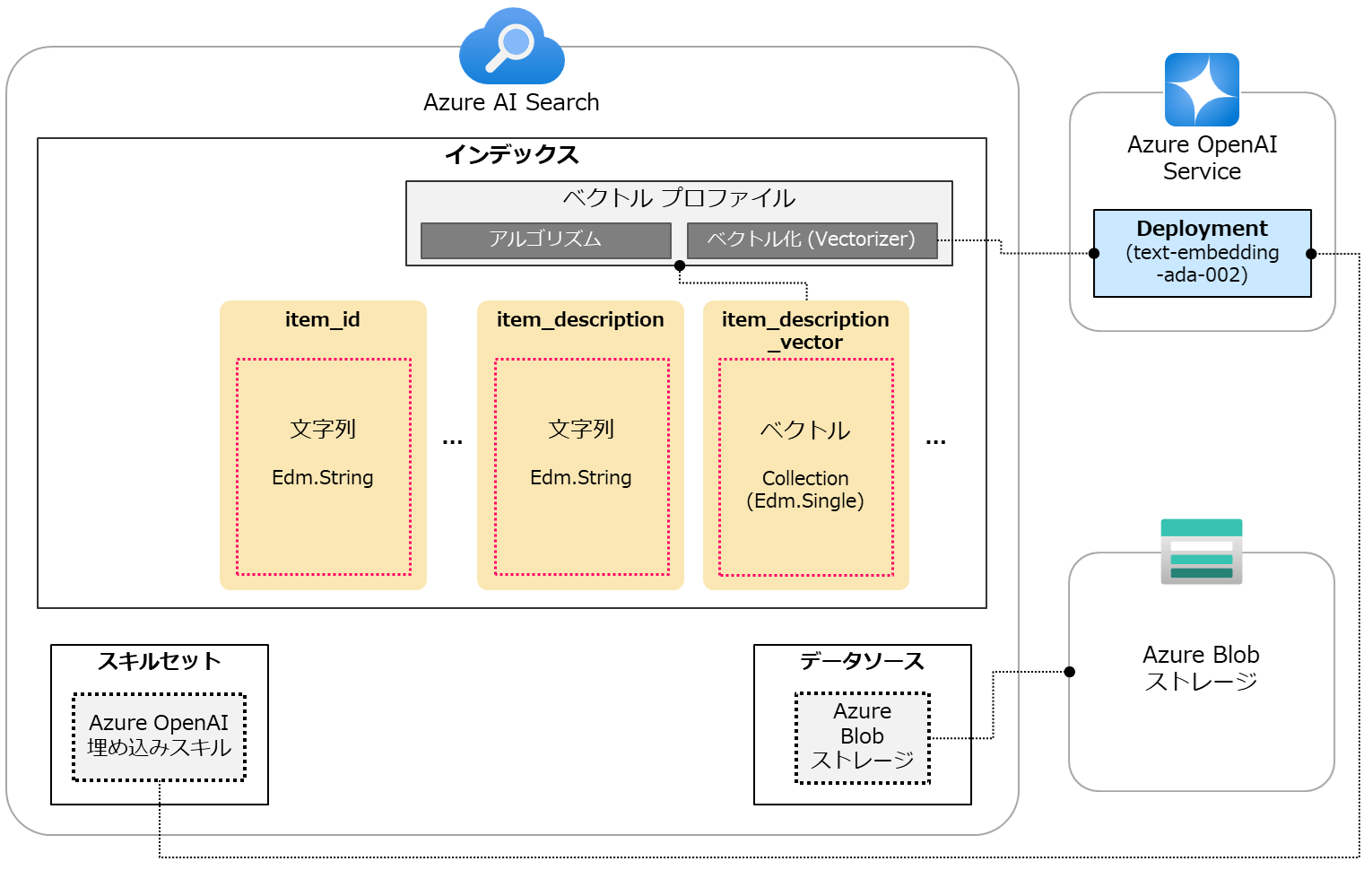
インデクサーの作成
インデクサーを作成し実行します。 今回はインデクサーにスキルセットを紐付けます。 下図のようにスキルセットによってエンリッチされた上でデータがインデックスに取り込まれるイメージです。(今回の例ではitem_descriptionのデータのみがエンリッチされます。)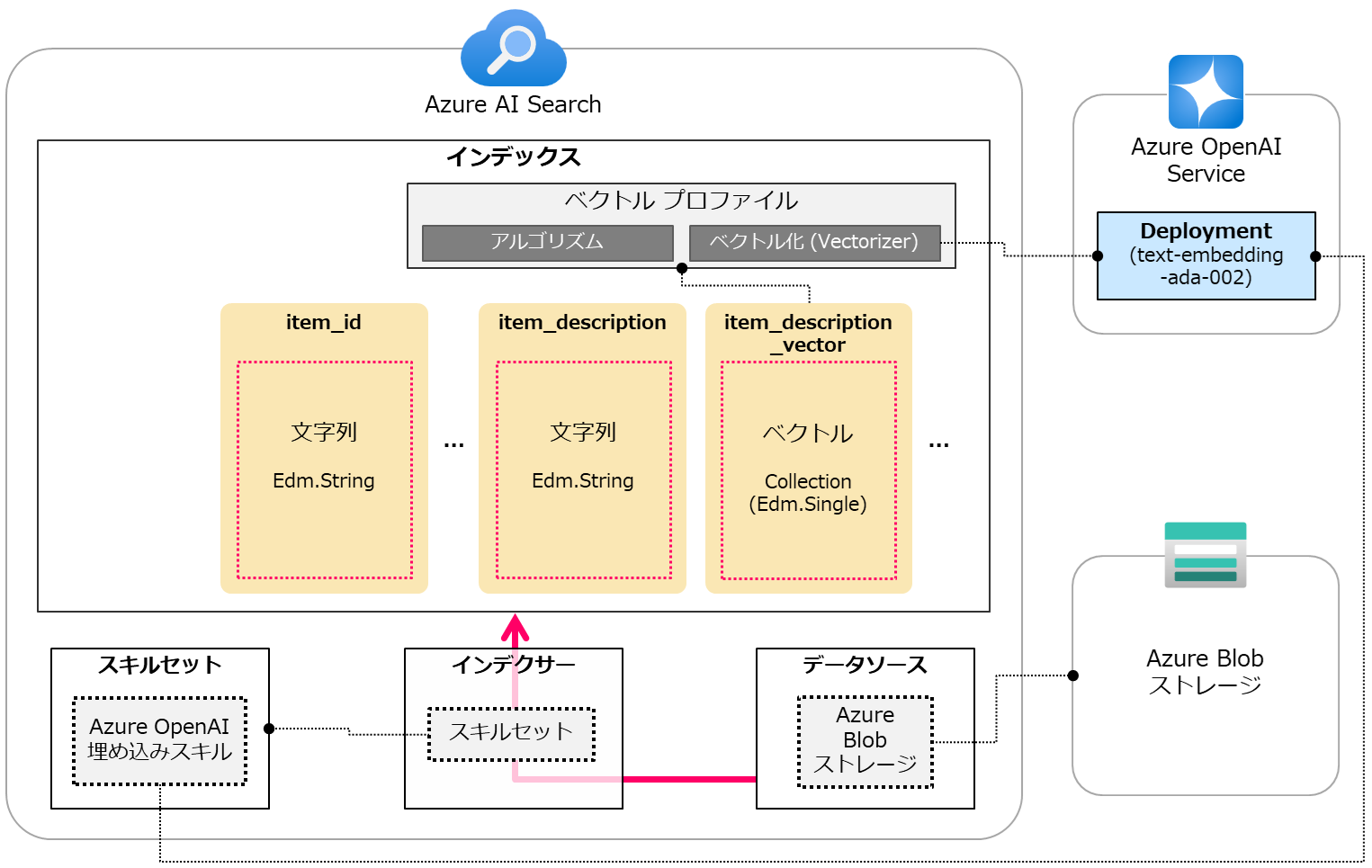
「インデクサー」を開き「インデクサーの追加」をクリックします。
インデクサーの名前、先程作成したインデックス、データソース、スキルセットを指定します。 次に詳細設定を行うためこのまま下へスクロールします。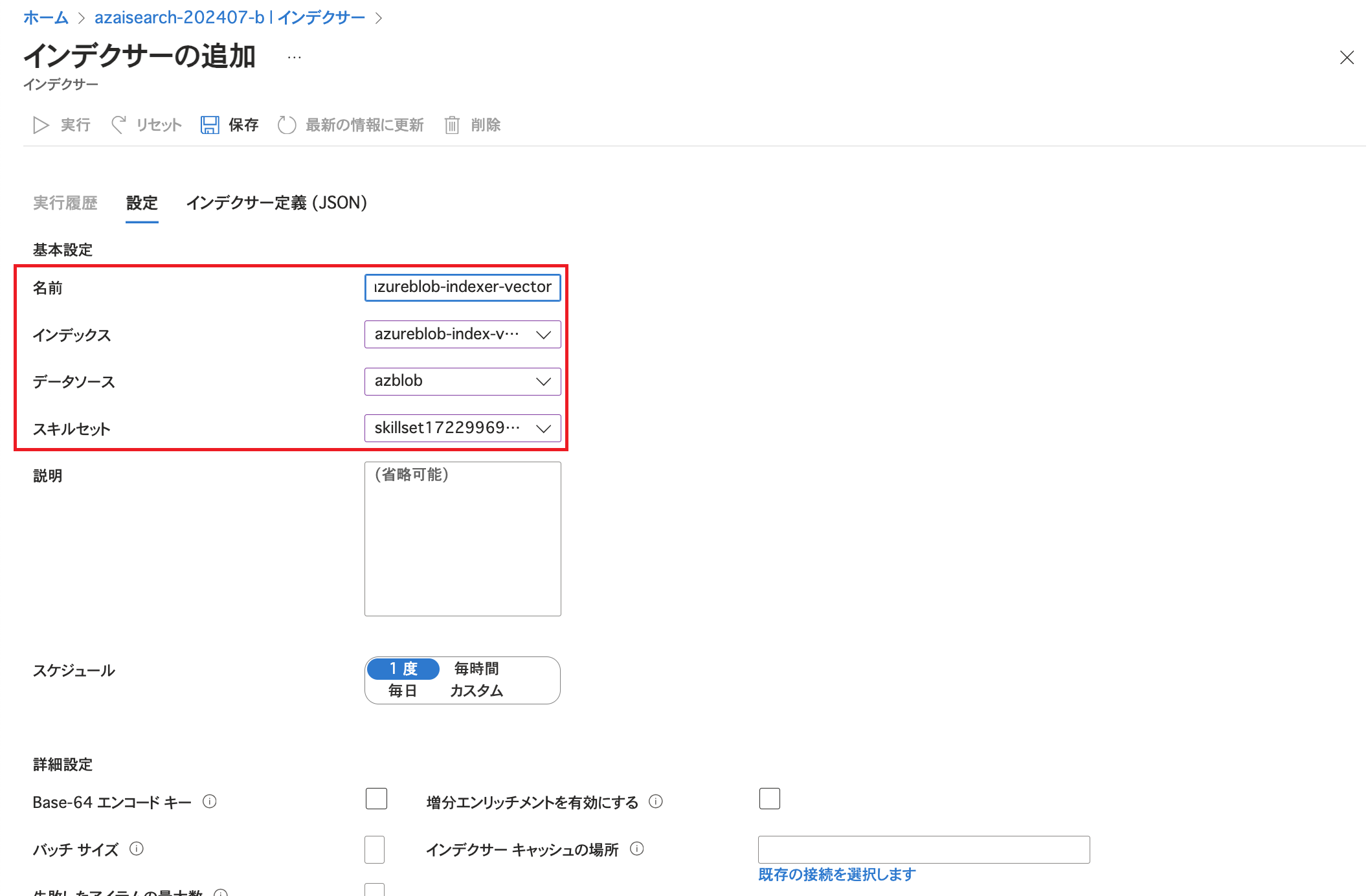 今回はCSVファイルを扱うため解析モードを「区切りテキスト」にし、区切り記号文字やヘッダーの有無をCSVファイルの記述内容に合わせて指定します。 次にJSON形式で設定を行うため同じ画面で上へスクロールします。
今回はCSVファイルを扱うため解析モードを「区切りテキスト」にし、区切り記号文字やヘッダーの有無をCSVファイルの記述内容に合わせて指定します。 次にJSON形式で設定を行うため同じ画面で上へスクロールします。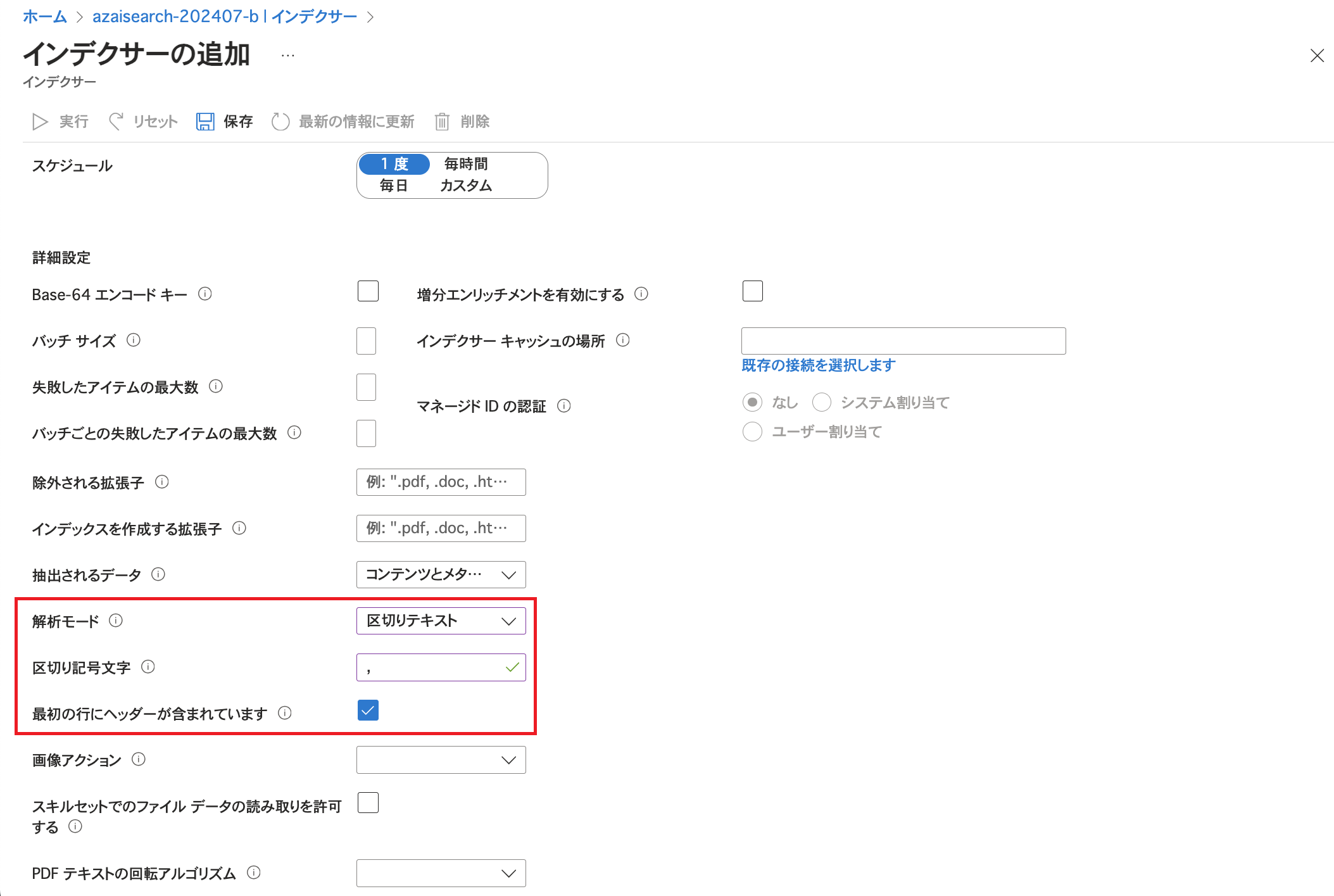 「インデクサー定義(JSON)」をクリックしfieldMappingsとoutputFieldMappingsの設定を追加します。 fieldMappingsではキーとして利用する「AzureSearch_DocumentKey」の値をBase64でエンコードする設定を行っています。 また、今回はインデクサーの設定でEmbeddingのためにスキルセットを指定しているため、生成されたデータをインデックスに格納するためにoutputFieldMappingsの設定を行っています。
「インデクサー定義(JSON)」をクリックしfieldMappingsとoutputFieldMappingsの設定を追加します。 fieldMappingsではキーとして利用する「AzureSearch_DocumentKey」の値をBase64でエンコードする設定を行っています。 また、今回はインデクサーの設定でEmbeddingのためにスキルセットを指定しているため、生成されたデータをインデックスに格納するためにoutputFieldMappingsの設定を行っています。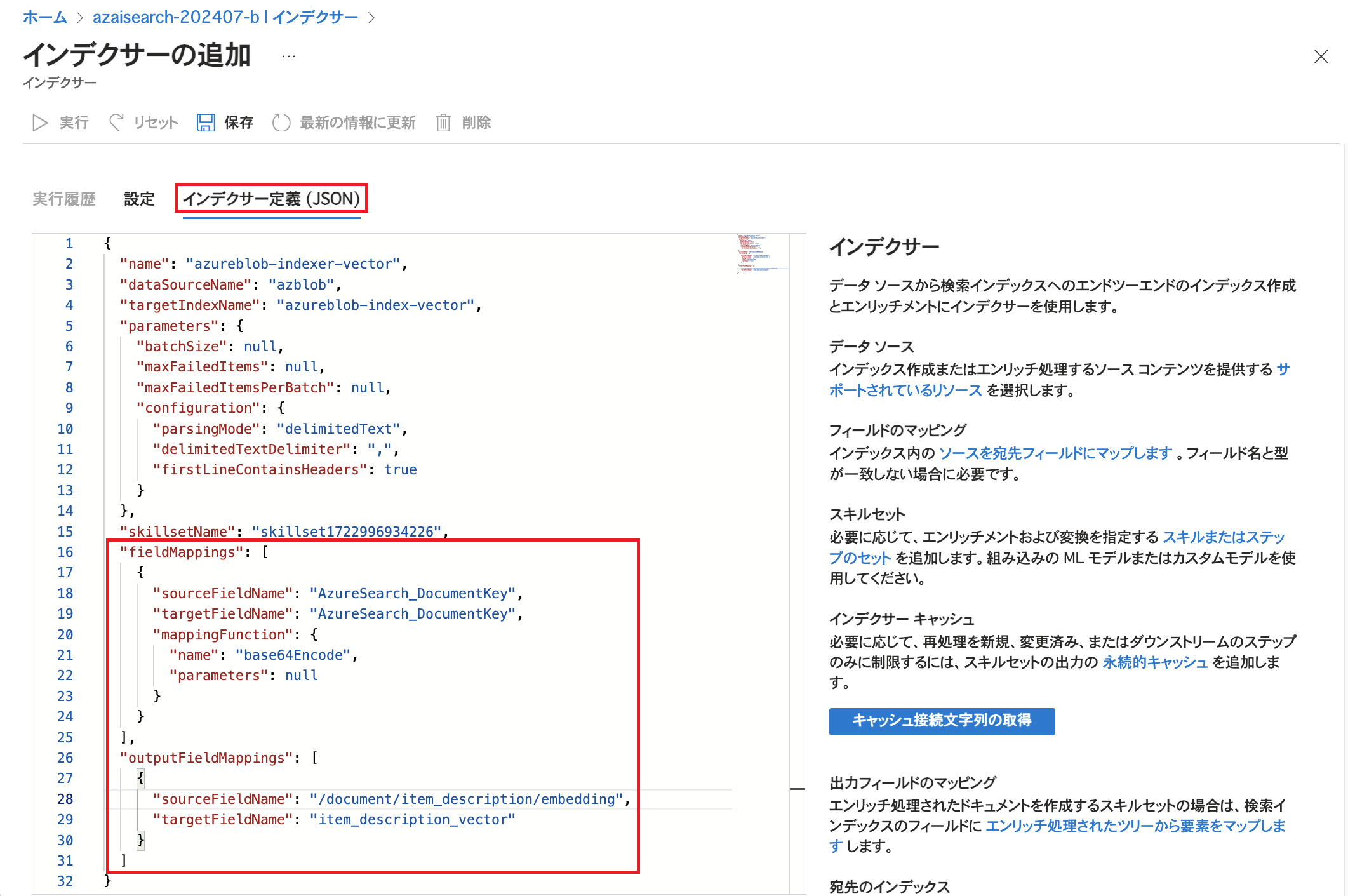
JSONの編集が完了したら「保存」をクリックします。
「保存」をクリックするとインデクサーが実行されます。 「実行履歴」を開き、実行状況が表示されていない場合は「最新の情報に更新」をクリックします。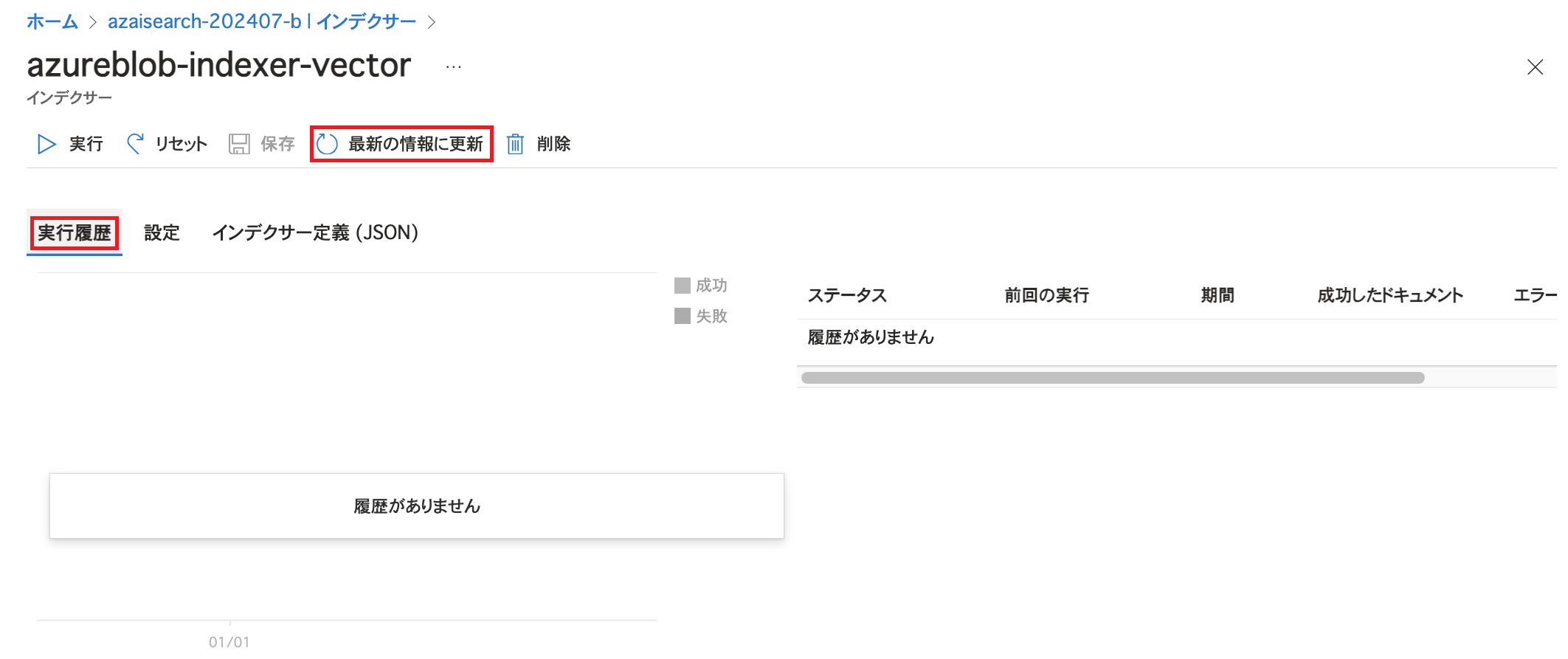
インデクサーの実行が完了したのち、ステータスが「成功」になっていることやエラー / 警告が発生していないことを確認します。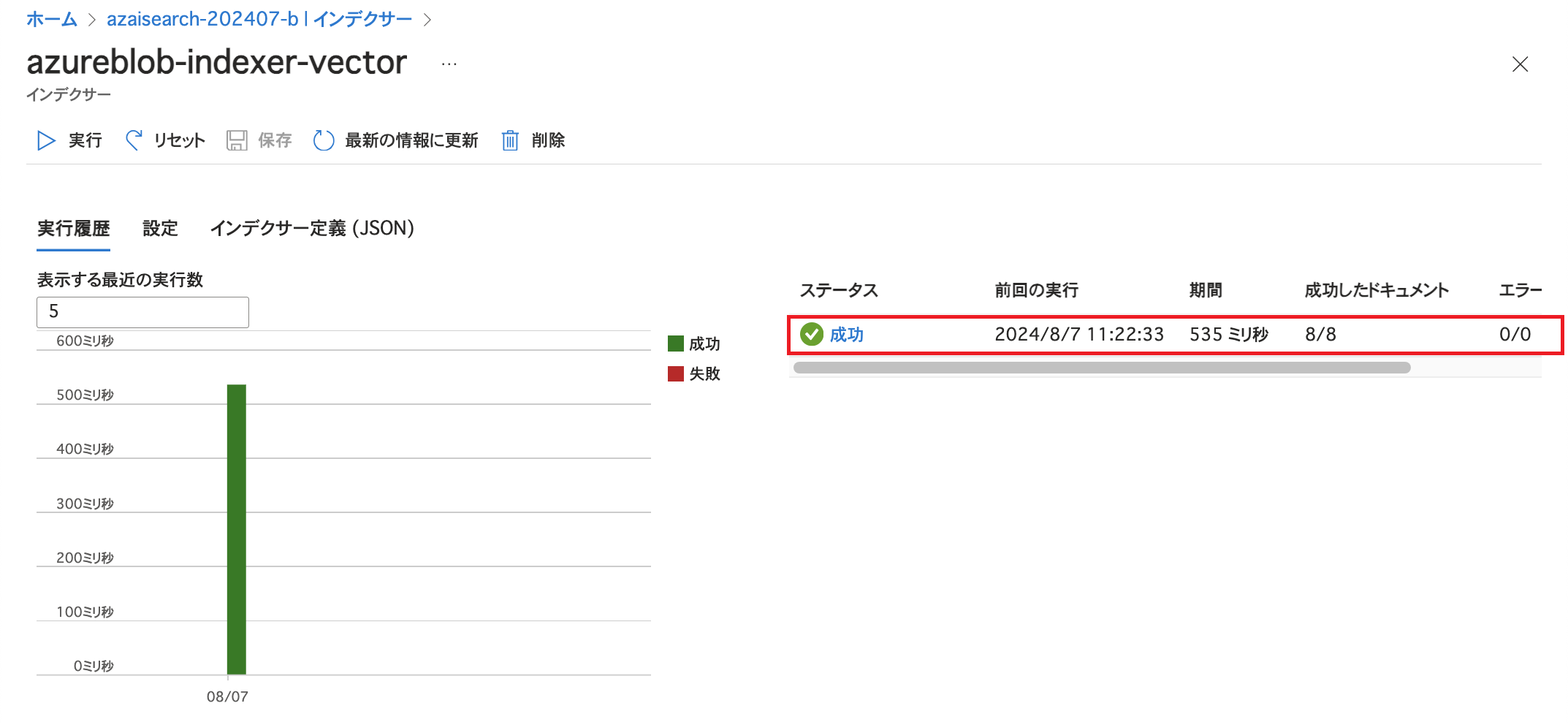
以上でインデックスへのデータの取り込みが完了しました。
スキル設定時のコンテキスト / 入力 / 出力に関する補足
スキルセットの定義でスキルを設定するにあたり、コンテキスト(context)や入力(inputs) / 出力(outputs)の設定で悩まれる方もいらっしゃるかもしれません。 一部の設定値に「/document」という表記がありますが、これが何を指しているかを確認しておきましょう。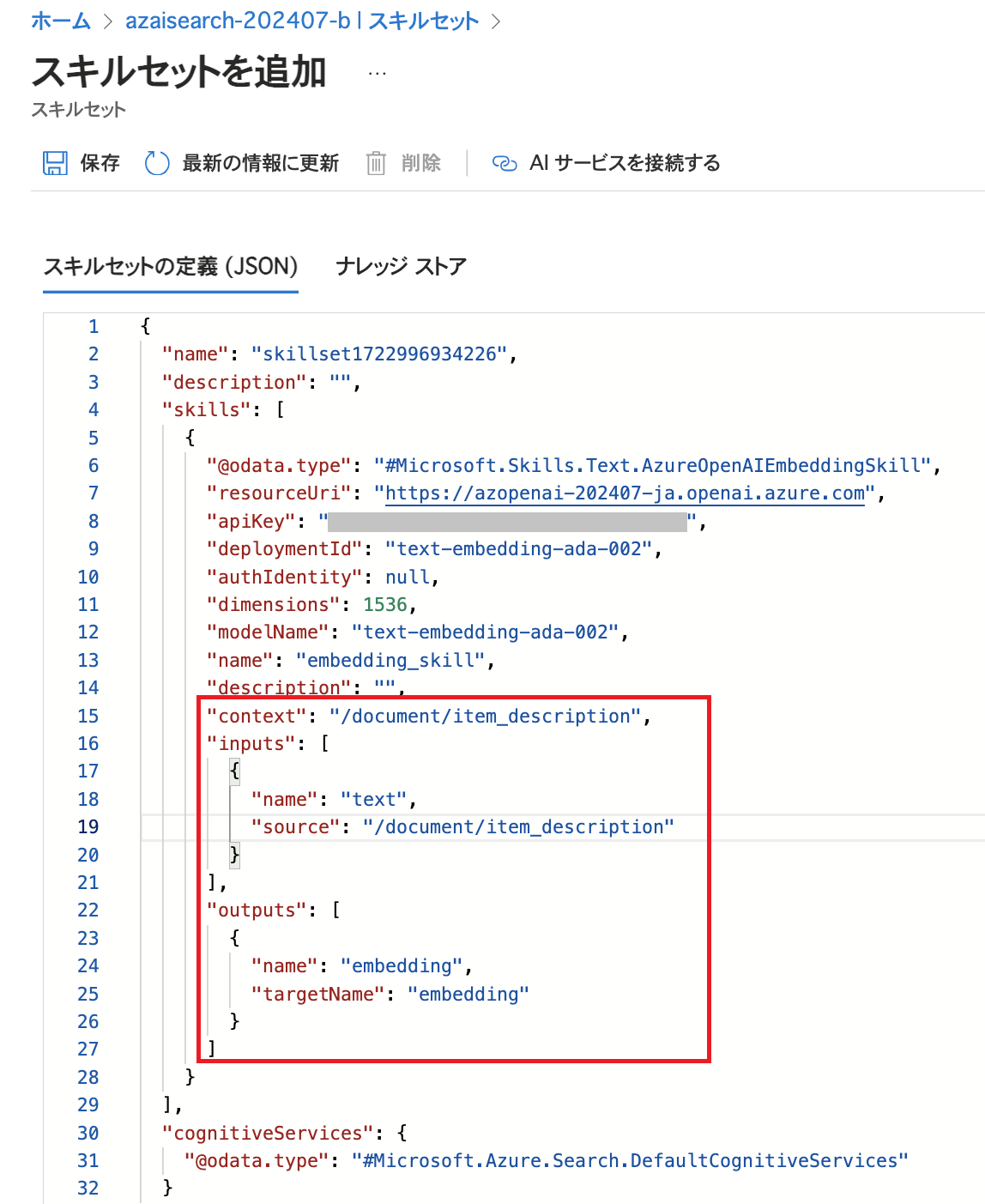
スキルセットによってデータを加工したり作成したりすることを「エンリッチ」あるいは「エンリッチメント」と呼びますが、スキルセットが実行される際にAzure AI Searchの内部で「エンリッチされたドキュメント」が一時的に作成されます。 エンリッチされたドキュメントは「/document」をルートとしたツリー状の構成になっています。 具体的な構造についてはAzure AI Searchの「デバッグセッション」で確認することが可能です。
デバッグセッションの細かな操作のご紹介は割愛しますが、デバッグセッションの「AIエンリッチメント」タブ内の「エンリッチ処理されたデータ構造」で最初のドキュメント(今回の場合は肩たたき券に関するドキュメント)を確認した結果が以下です。 「document」の配下にitem_idやitem_nameなどが並び、ツリー状になっていることが分かります。 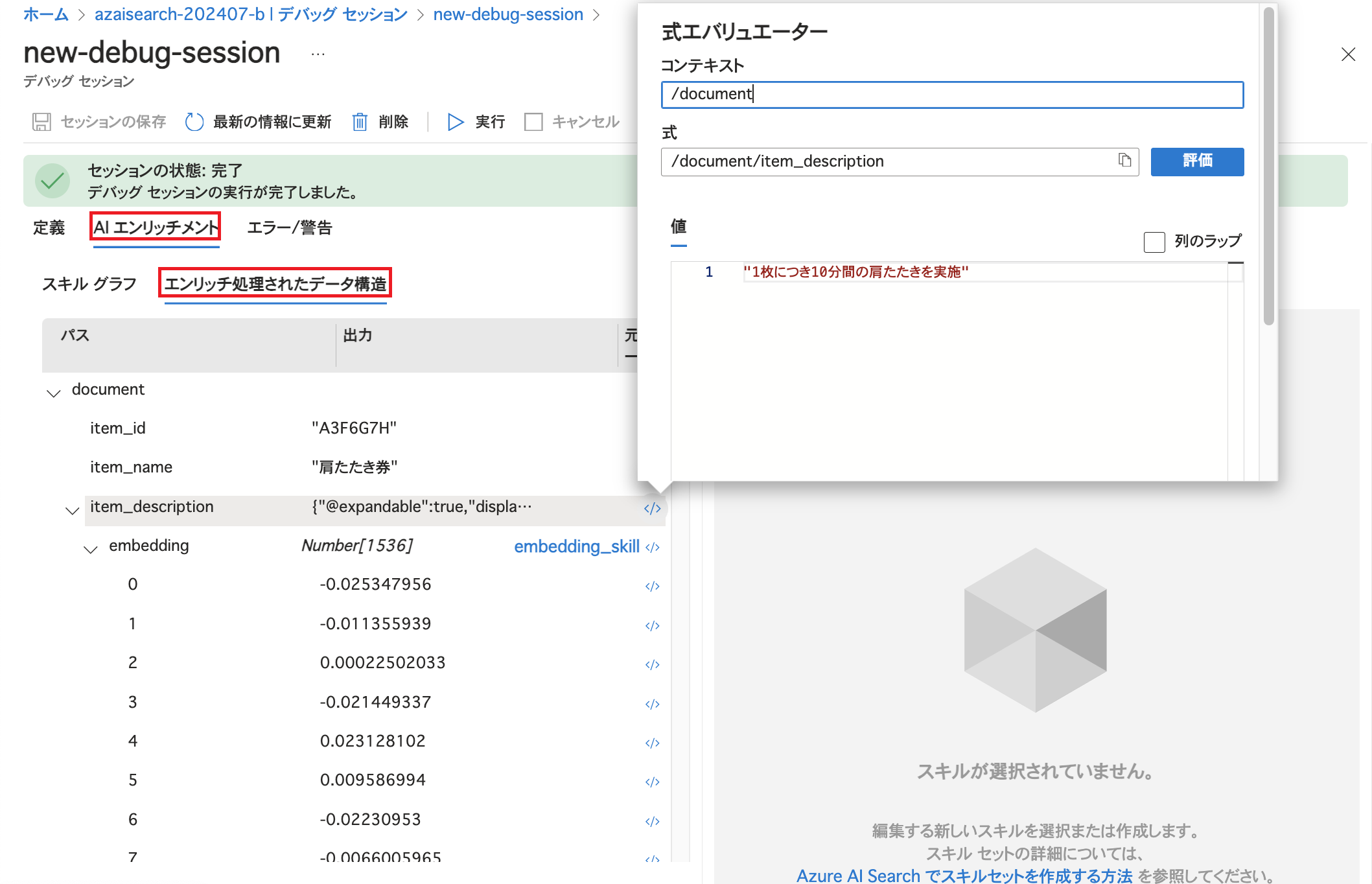
スキルの設定におけるコンテキスト(context)はスキルによるエンリッチのスコープを指しています。 今回は各ドキュメントのitem_descriptionフィールドに1回スキルが実行されるよう「"context": "/document/item_description"」と設定していました。
また、入力(inputs)に関しては「エンリッチされたドキュメント」のノードを指定しますので今回は「/document/item_description」を指定しています。 出力(outputs)に関しては新しいノードにエンリッチされたデータが格納されます。 今回の例ではスキルによって生成されたベクトルデータが/document/item_description/embeddingに格納されるようにしています。 なお、出力のノードはコンテキストで指定したノード(/document/item_description)の子ノードとして追加されます。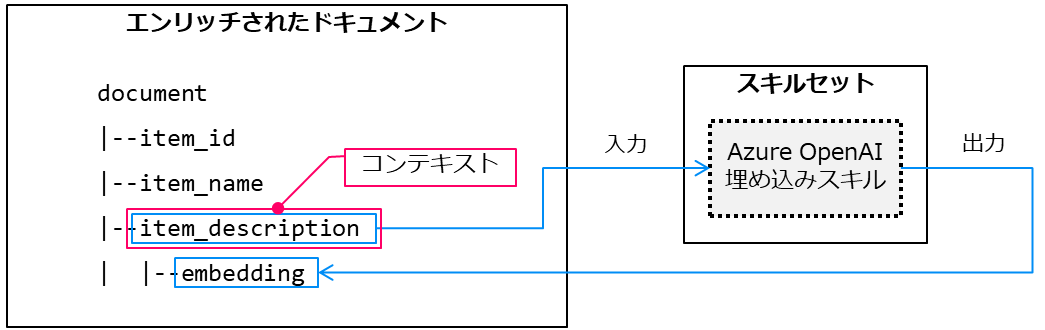
※ これらの設定の詳細については以下の資料に記載がございますので、併せてご参照ください。
Azure AI Searchでのスキルセットの概念
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-working-with-skillsets
Azure AI Search での AI エンリッチメント
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-concept-intro
エンリッチされたドキュメントは前述の通り一時的に作成されるものです。今回の例であれば、エンリッチされたドキュメントの/document/item_description/embeddingに存在するベクトルデータをインデックス内にデータとして取り込みたい場合には設定を行う必要があります。 今回はインデクサーの「outputFieldMappings」で設定しています。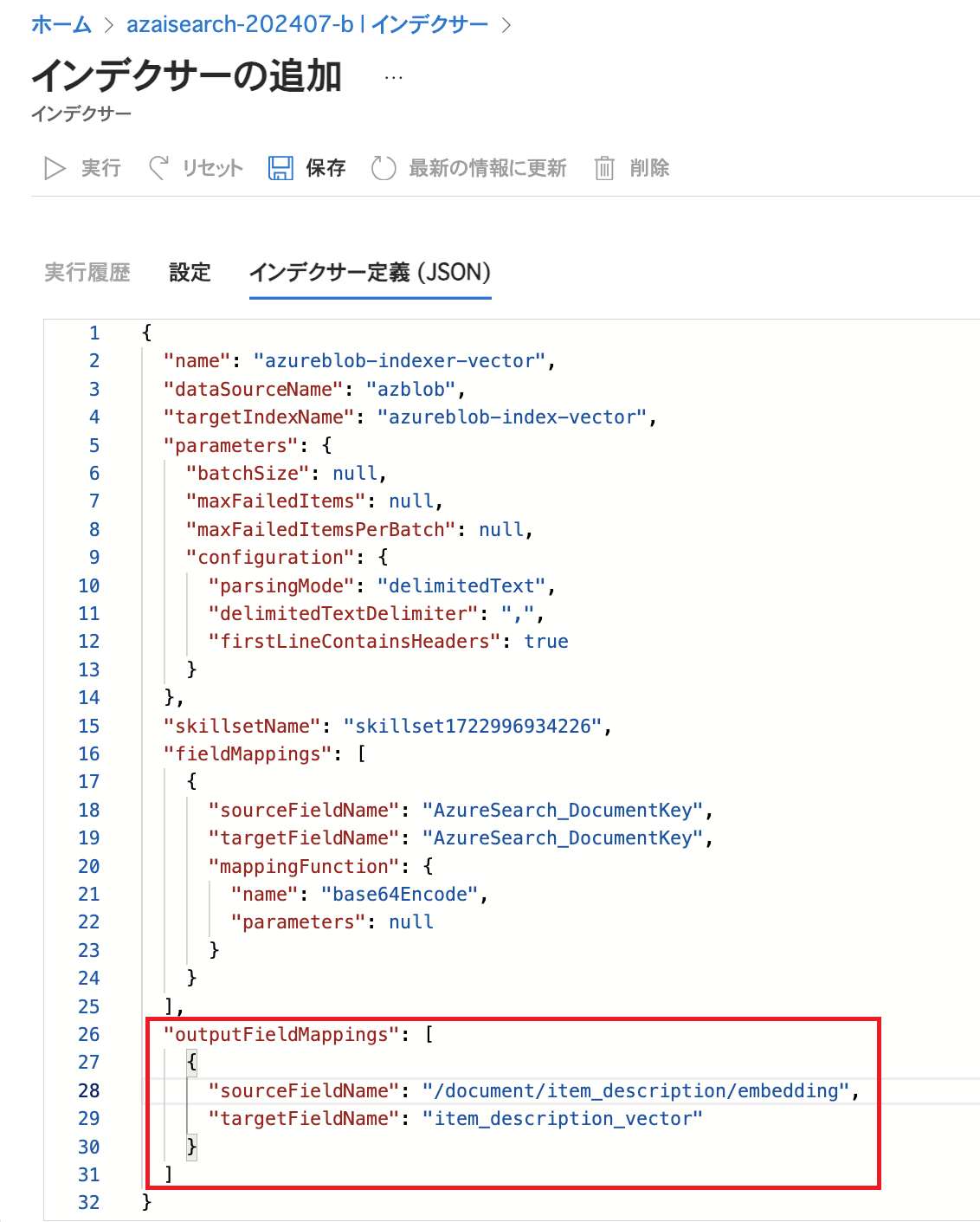
sourceFieldNameでエンリッチされたドキュメントのノードを指定し、targetFieldNameでインデックスのフィールドを指定しています。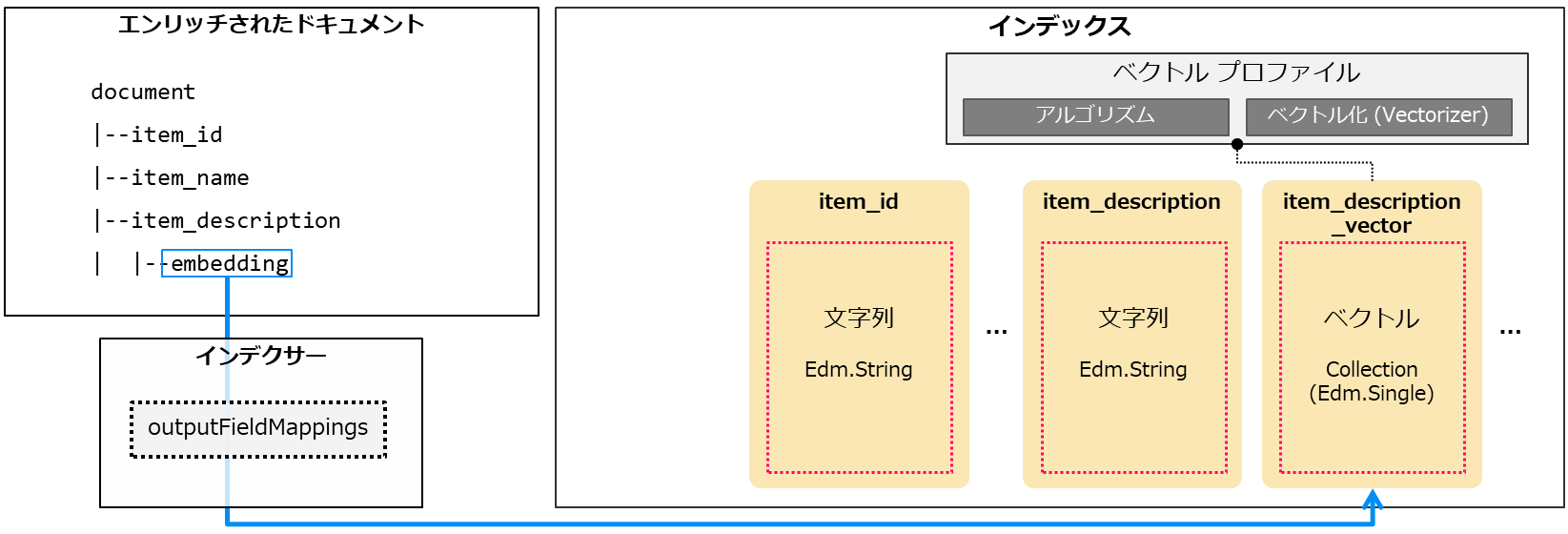
ベクトル検索
インデックスにデータ(ドキュメント)が格納されましたので、Azure AI Searchの検索エクスプローラーを利用して確認を行います。
検索エクスプローラーではベクトル検索を行うこともでき、「クエリオプション」にベクトル検索をオン / オフする設定があります。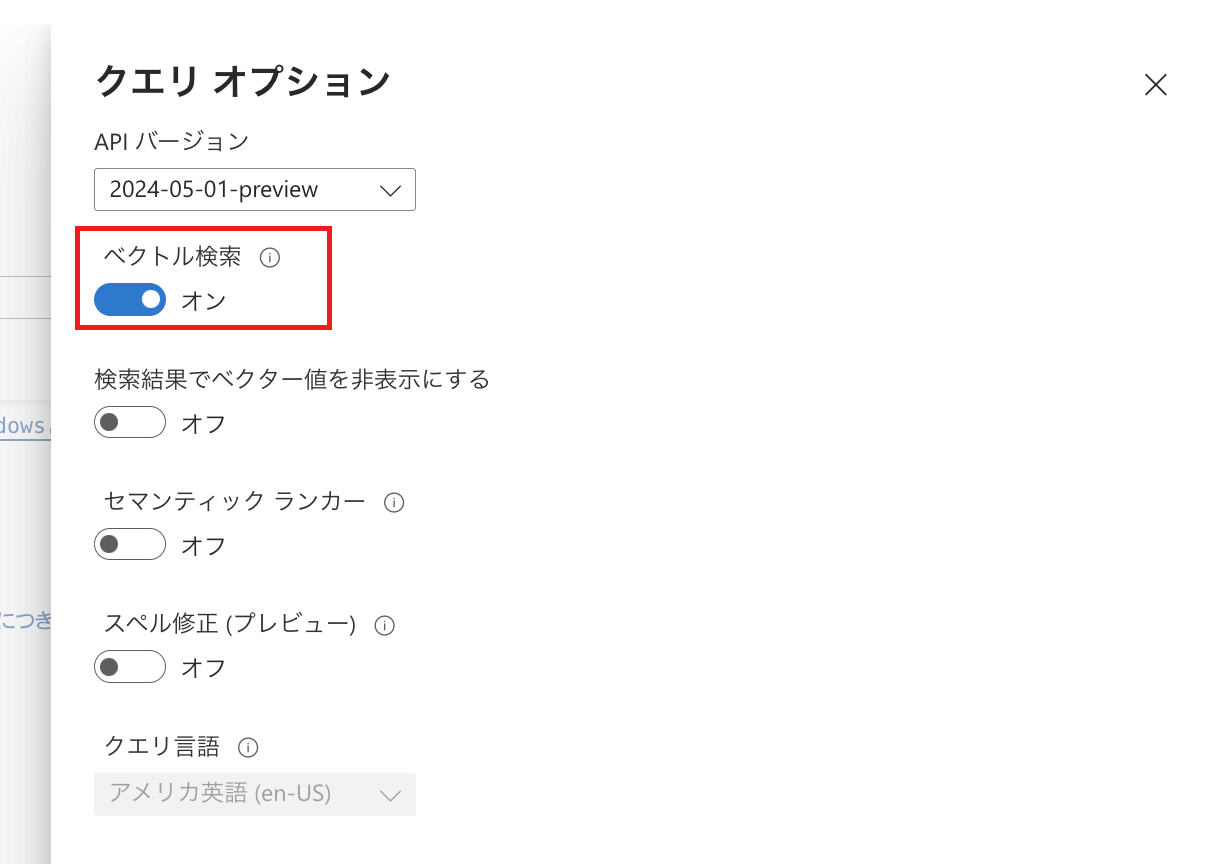
ベクトル検索の前に
まずはベクトル検索を行う前にどのようなデータを閲覧できるか確認してみます。
ベクトル検索をオフにした状態で「*」で検索した結果が以下です。 item_description_vectorにベクトルデータが格納されていることが分かります。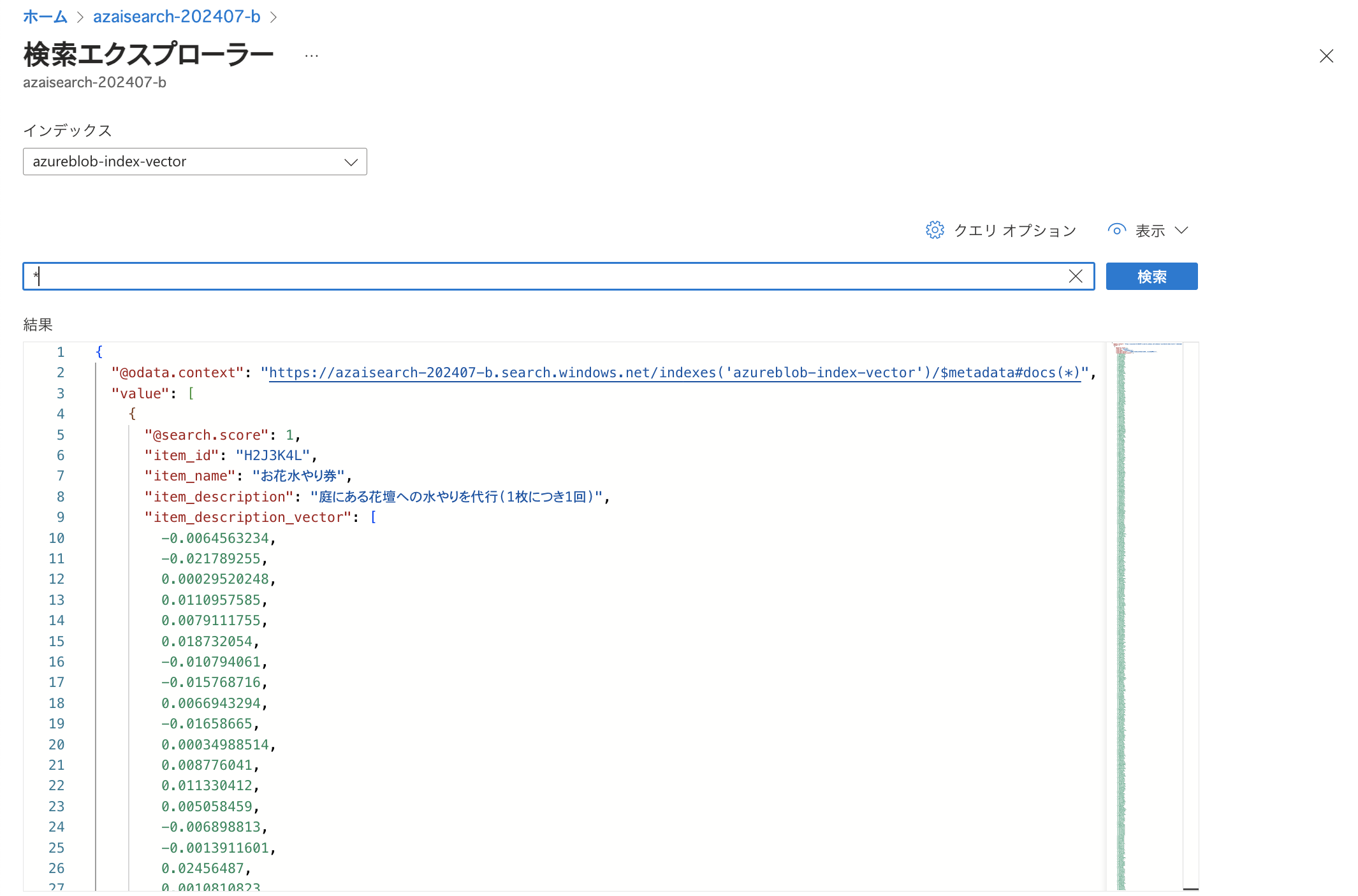
他の券にもベクトルデータが存在しています。
ベクトル検索
ここからは「クエリオプション」でベクトル検索をオンにし、JSONビューで操作を行います。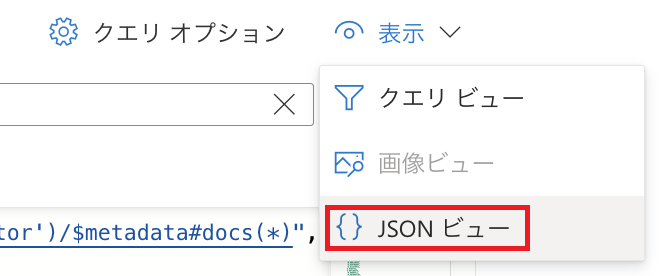
今回は「食事」という言葉の意味で検索してみます。 JSON クエリエディターに以下を記述して検索します。 ここでは見やすさを考慮してselectにより検索結果にアイテム名と説明のみ表示されるようにしています。 またvectorQueries内の記述は、item_description_vectorというフィールドに対して「食事」というテキストで検索を行うというものです。
|
「"kind": "text"」としているため、検索にあたってはインデックス作成時にitem_description_vectorフィールドに設定した「ベクトル化」によって検索テキストがベクトルに変換されます。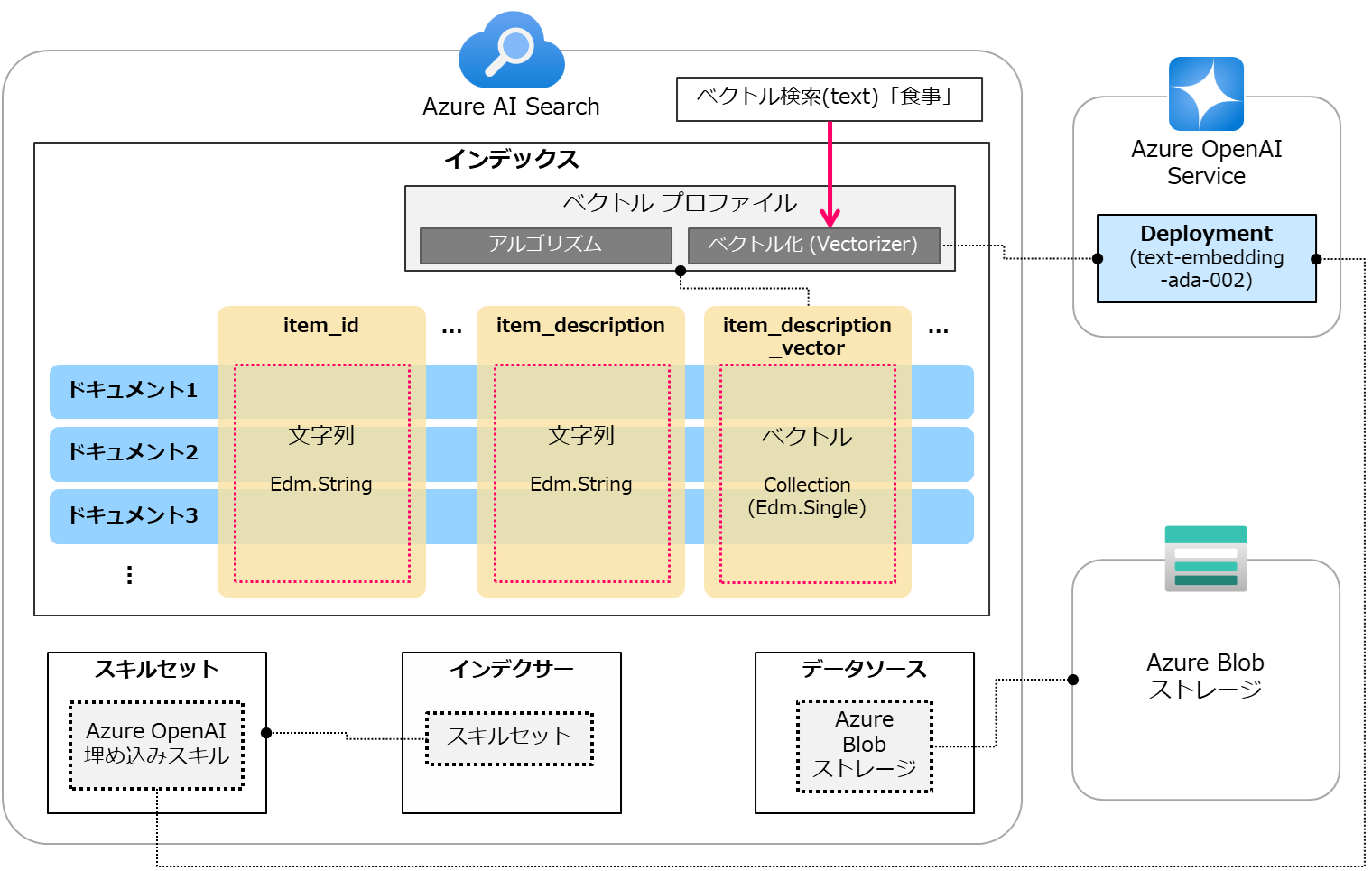 検索結果は以下です。 結果は「@search.score」が高い順に並んでいます。(ベクトル検索におけるスコア付けについてはこちらをご参照ください。) 料理や食器、食品買い出しといった「食事」に関わりのある説明文が上位に並んでいます。
検索結果は以下です。 結果は「@search.score」が高い順に並んでいます。(ベクトル検索におけるスコア付けについてはこちらをご参照ください。) 料理や食器、食品買い出しといった「食事」に関わりのある説明文が上位に並んでいます。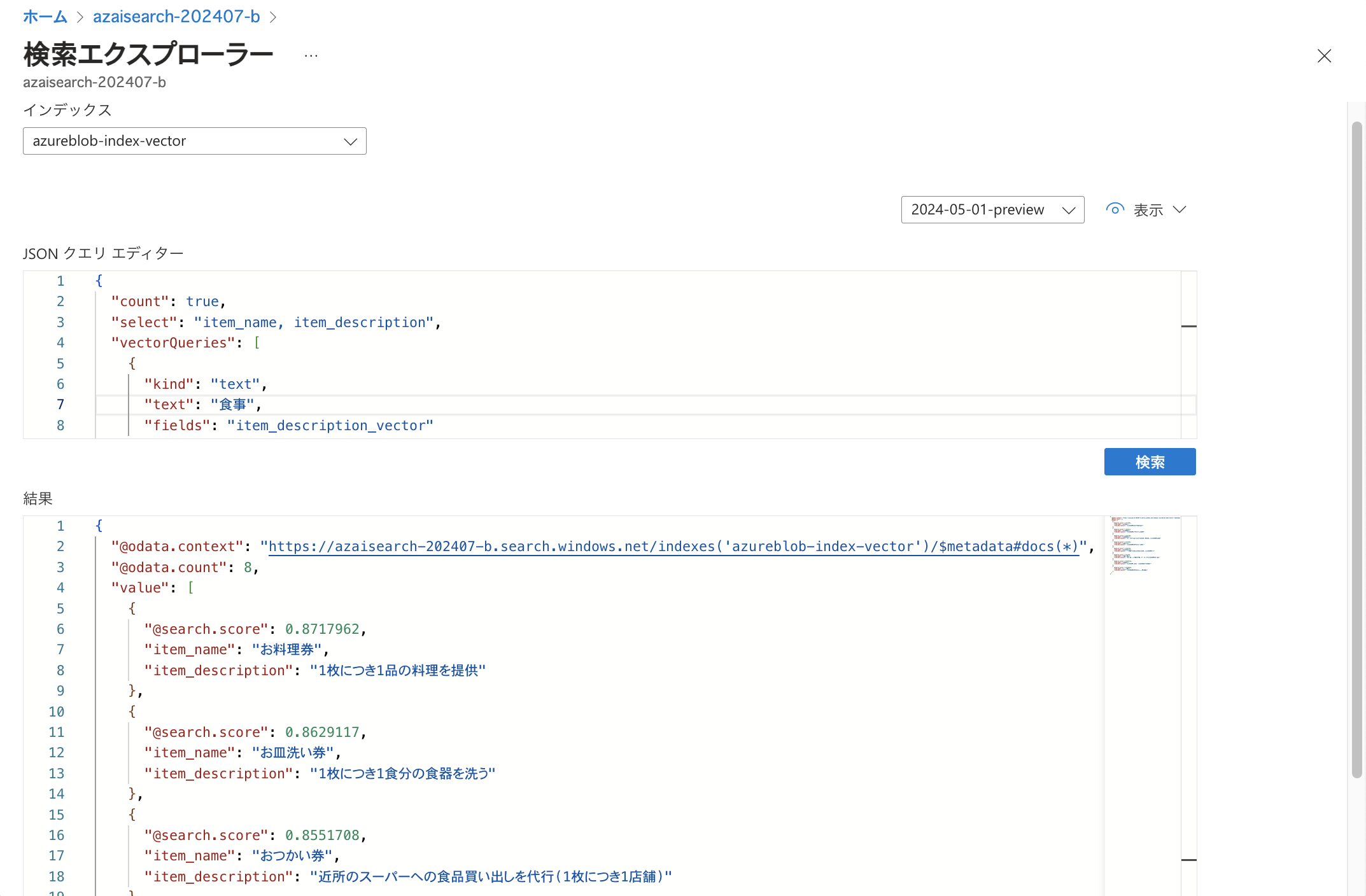
上記の結果では「@odata.count」の値が8になっており、CSVファイルに記述されていた8種類全ての券が検索結果に表示されています。 以下のように指定することで返される結果の数を絞ることが可能です。
|
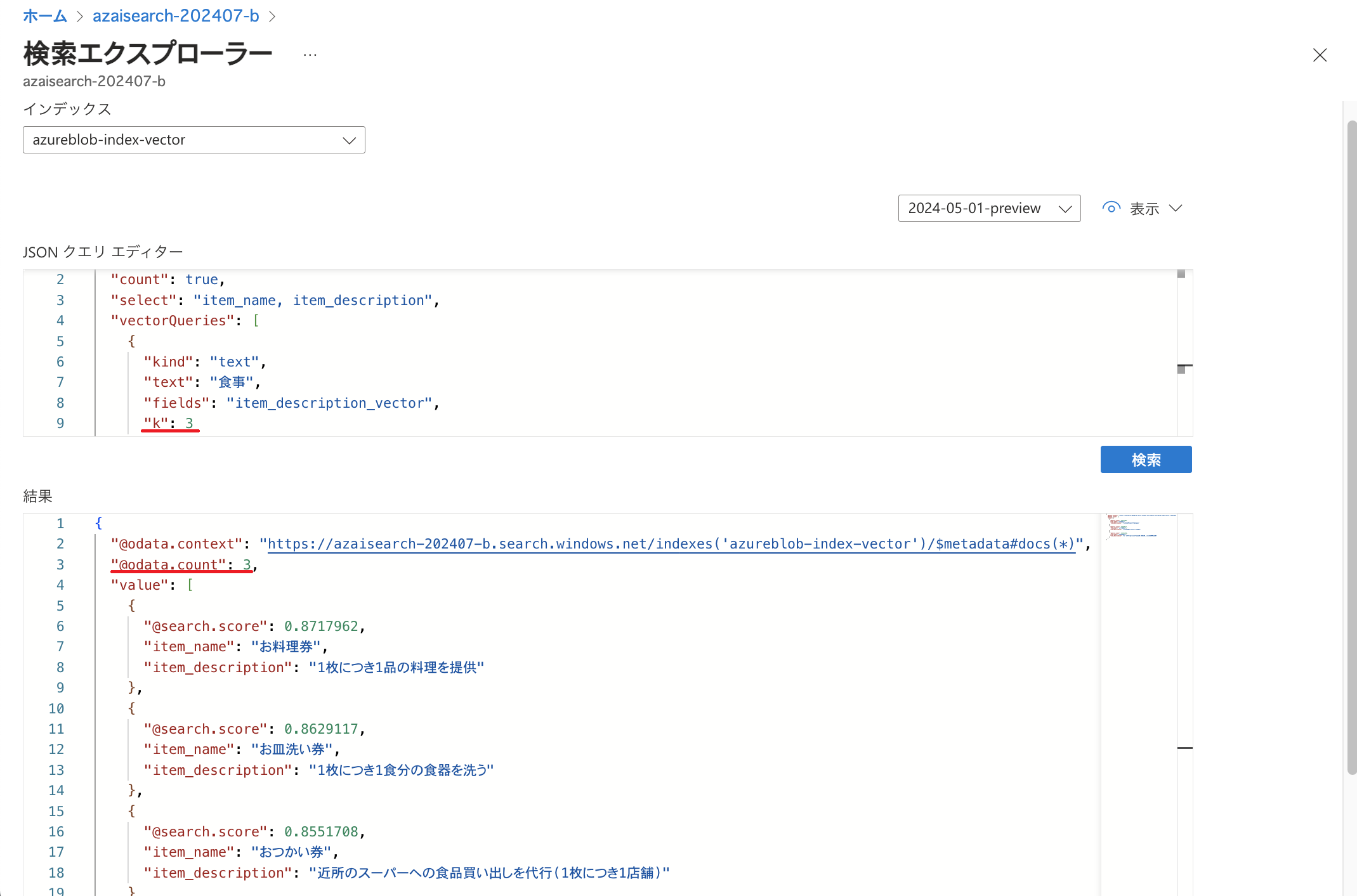
今回は簡単な例をご紹介しましたが、ベクトルクエリで利用できるパラメーターなど詳細はMicrosoft Learnをご参照ください。
まとめ
以前のブログ記事ではAzure AI Searchの概要やフルテキスト検索をご紹介し、今回はベクトル検索についてご紹介しました。 今回はAIモデルによる処理をスキルとして扱うなど、以前よりステップアップした内容になっていたのではないかと思います。 「エンリッチされたドキュメント」など内部的な処理を考慮しつつ設定を行う箇所もありましたが、Azure AI Searchを実際に操作いただくと理解が深まりやすいかもしれません。
「ハイブリッド検索」や「セマンティック ランク付け」などまだご紹介できていないAzure AI Searchの機能もございますが、Azure AI Searchにおけるデータの処理や検索の概要を捉える上で本ブログ記事をお役立ていただけましたら幸いです。
Azureを取り扱われているパートナー企業様へ様々なご支援のメニューを用意しております。 メニューの詳細やAzureに関するご相談等につきましては以下の「Azure相談センター」をご確認ください。
Azure相談センター
https://licensecounter.jp/azure/
※ 本ブログ記事は弊社にて把握、確認された内容を基に作成したものであり、サービス・製品の動作や仕様について担保・保証するものではありません。サービス・製品の動作、仕様等に関しては、予告なく変更される場合があります。
Azureに関するブログ記事一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄
