


こんにちは。SB C&S の村上です。
この記事ではNeMo Evaluatorを用いてベンチマークを実行します。
なお、本記事は以下NeMo Evaluatorの展開を前提としているため、ぜひ先にそちらを閲覧ください。
NVIDIA NeMo Evaluatorの紹介
NVIDIA NeMo Evaluatorの展開の流れ
実施内容の確認
今回はMMLU-JAという日本語の言語能力評価のベンチマークを、GPT OSS 20BとGPT OSS 120Bそれぞれに行っていきます。
MMLUは高校〜専門レベルまでの57分野の4択問題で、人文・社会・STEM・法律/医療など広範な一般知識と推論力を測るベンチマークになります。
※MMLUに限らず、他のベンチマークも利用可能です
こちらおさらいとなりますが、
NeMo Evaluatorでは大きく以下3つのことを実行していきます。
①評価対象のモデルの登録
②ベンチマークの設定の作成
③ベンチマークの実行(どのモデルにどの設定でを指定)
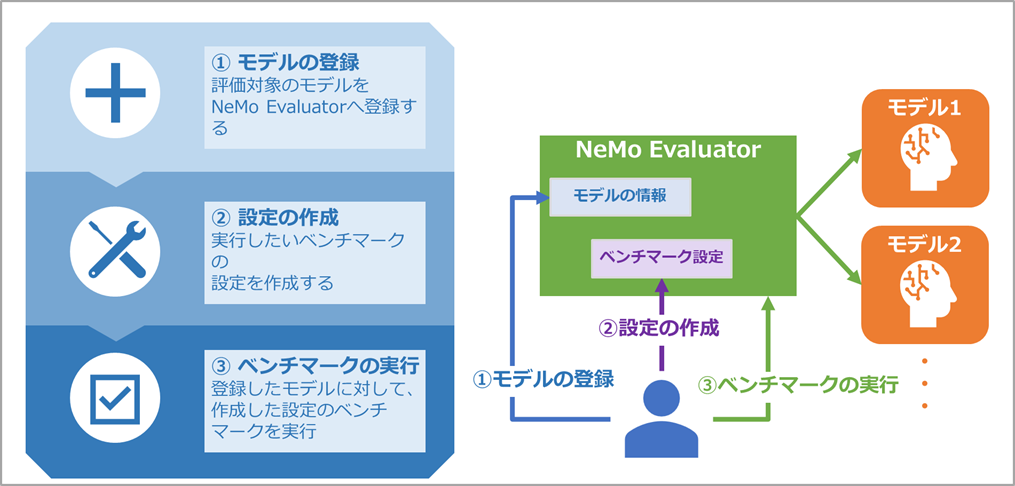
これらは全てNeMo EvaluatorのAPIへ直接HTTPリクエストを実行するか、Python SDKを用いてアプリケーションに組み込むことで実施できます。本記事では直接HTTPリクエストを送る方式で進めます。
NeMo Evaluatorでのベンチマーク実行
まずNeMo EvaluatorのAPIのIPアドレスを確認します。
以下コマンドでnemo-evaluatorという名称のServiceに割り当てられたIPアドレスを確認しておきます。ここからはこのIPアドレスへリクエストを送る形となります。
kubectl get svc -n nemo-ev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
nemo-evaluator LoadBalancer 10.100.80.8 {割り当てられたIP} 7331:31539/TCP
それではモデルの登録を行います。
モデルの登録は{NeMo EvaluatorのIP}:7331/v1/evaluation/targetsのAPIに対してPOSTリクエストを送信します。
以下はGPT OSS 20Bの場合のサンプルとなります。
curl -X "POST" "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/targets" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"name": "gpt-oss-20b-1",
"namespace": "my-organization",
"type": "model",
"model": {
"name": "gpt-oss-20b",
"namespace": "default",
"api_endpoint": {
"url": "http://{LLMエンドポイントのIP:ポート}/v1/chat/completions",
"model_id": "openai/gpt-oss-20b",
"format": "nim"
}
}
}'
実行完了後は同じAPIに対してGETリクエストを送信することで登録されている情報を確認できます。
curl -X "GET" "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/targets" | jq
{
###一部出力省略###
"name": "gpt-oss-20b-1",
"namespace": "my-organization",
"type": "model",
"model": {
"schema_version": "1.0",
"id": "model-AsaYpEiEXFVbqongjqZkSq",
"type_prefix": "model",
"namespace": "default",
"name": "gpt-oss-20b",
###一部出力省略###
"api_endpoint": {
"url": "http://10.20.1.12:8900/v1/chat/completions",
"model_id": "openai/gpt-oss-20b",
"format": "nim"
###一部出力省略###
}
割愛しますが、同じように120Bのモデルも合わせて登録を済ませておきます。
続いて、ベンチマークの設定の作成を行います。
設定の作成は{NeMo EvaluatorのIP}:7331/v1/evaluation/configsのAPIに対してPOSTリクエストを送信します。
以下はMMLU-JAの場合のサンプルとなります。
ここで重要なパラメータとしてはtypeとlimit_samplesとnum_fewshotです。
typeはベンチマークを指定するものになります。指定可能なベンチマークは以下メーカードキュメントに記載があります。
https://docs.nvidia.com/nemo/evaluator/latest/evaluation/benchmarks.html#full-benchmarks-list
limit_samplesは全部で何問ベンチマークの問題をLLMに解かせるかの指定となります。
num_fewshotはベンチマークを実行する際に、LLMに事前に渡すお手本のプロンプト数となります。これによって何もない状態での精度や、ある程度事前知識を与えた場合での精度などをそれぞれ確認することができます。
curl -X POST "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/configs" \
-H 'accept: application/json' -H 'Content-Type: application/json' \
-d '{
"type": "mmlu_ja",
"namespace": "my-organization",
"name": "mmlu-ja-0shot",
"params": {
"limit_samples": 500,
"parallelism": 8,
"request_timeout": 300,
"extra": { "model_type": "chat", "num_fewshot": 0 }
}
}'
なお、こちらもモデルの登録同様にGETリクエストにすることで作成済みの設定を確認できます。
curl -X GET "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/configs" | jq
{
###一部出力省略###
"name": "mmlu-ja-0shot",
"namespace": "my-organization",
"type": "mmlu_ja",
"params": {
"parallelism": 8,
"request_timeout": 300,
"limit_samples": 500,
"extra": {
"model_type": "chat",
"num_fewshot": 0
}
},
###一部出力省略###
}
続いて、ベンチマークの実行を行います。
実行は{NeMo EvaluatorのIP}:7331/v1/evaluation/jobsのAPIに対してPOSTリクエストを送信します。
以下はGPT OSS 20Bに対してMMLU-JAのベンチマークを実行するサンプルとなります。
パラメータは今まで一番シンプルで、targetに評価対象のモデルの登録名、configに作成したベンチマークの設定を指定するのみとなります。
curl -X POST "http://{NeMo EvaluatorのIP}/v1/evaluation/jobs" \
-H 'accept: application/json' -H 'Content-Type: application/json' \
-d '{
"namespace":"my-organization",
"target":"my-organization/gpt-oss-20b-1",
"config":"my-organization/mmlu-ja-0shot"
}'
実行後はここまでと同様にGETリクエストにて一覧を確認できます。
この出力の頭のidが実行しているベンチマーク(ジョブ)のIDとなります。このIDを指定することで、ベンチマークの進行状況や結果の取得を行うことができます。
curl -X GET "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/jobs" | jq
{
###一部出力省略###
{
"id": "eval-223V16Ko8XhpEHYzobWvmC",
"namespace": "my-organization",
"target": {
"schema_version": "1.0",
"id": "eval-target-BkBUkMR6iYj2AVgP8pXNQT",
}
},
"config": {
"schema_version": "1.0",
"id": "eval-config-6iTSD5ruNA3KDyj5qtdW7Q",
###一部出力省略###
}
それでは進行状況を確認します。
以下のようなコマンドで確認したIDとstatusを後ろに指定することで確認できます。
progressが100になり、Job completed successfullyが表示されていれば完了している状態です。
curl -X GET "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/jobs/eval-223V16Ko8XhpEHYzobWvmC/status"
{"message":"Job completed successfully.", "task_status":{},"progress":100.0,"samples_processed":500}
完了後は先ほどのコマンドのstatusをresultsに変えて実行することで評価の結果を確認できます。
curl -X GET "http://{NeMo EvaluatorのIP}:7331/v1/evaluation/jobs/eval-Di7PtvWhmZHQHhJtBhxLWc"/results
こちらは少し出力が見づらいため、一部切り出してみていきます。
出力の中に以下のような項目がいくつか表示されます。これはベンチマーク内で実行されるタスクの種類ごとに生成されます。こちらの場合だと、stemというタスクに対して、0.91(91%)の正解率を出したということを確認できるようなものとなります。
"stem": {
"metrics": {
"score": {
"scores": {
"micro": {
"value": 0.9166666666666666,
"stats": {
"stderr": 0.017445291707064606
}
それでは、GPT OSS 120Bにも同じくMMLU-JAを実行しておき、結果を比較してみます。
今回私の環境で実施した場合の結果は以下のようになり、パラメータ数が多いGPT OSS 120B側の方が精度が良いことが確認できました。

まとめ
NeMo Evaluatorを用いたベンチマークの実行について紹介いたしました。
今回は簡易的な内容の実行のみでしたが、精度を確かめられることを理解できたと思います。他にもRAGやAIエージェントの評価や他のLLMを用いた評価なども可能なため、ぜひお試しください。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
村上 正弥 - Seiya.Murakami -
VMware vExpert




