


こんにちは。SB C&S の村上です。
この記事ではNVIDIA NIMを用いた推論サーバーの展開について紹介します。
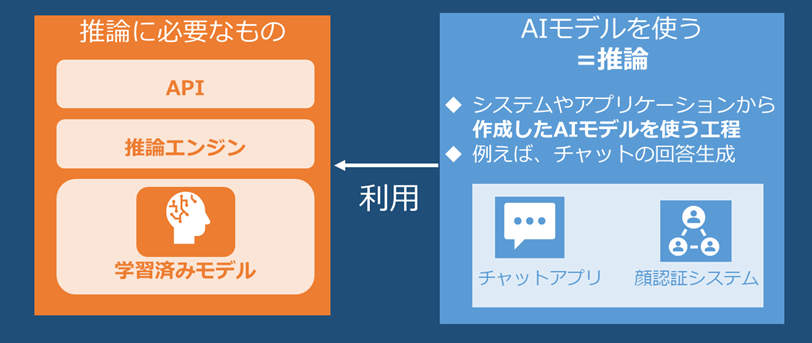
AIの推論で必要なソフトウェア
まずAIをやっていくとなった際に考えるべきタスクとして学習と推論の2つがあります。
学習はAIの本体ともいえるAIモデルを作る工程となります。例えば、チャットできるAIを作りたいとなったら、大量のテキストデータを用意してそれを元にAIを作るイメージとなります。
推論は作られたAIモデルを実際に使う工程となります。例えば、LLMだとチャットの回答生成を行わせたりするものです。

ただし、この推論に関してはただAIモデルを準備するだけでは利用することができません。
AIモデルを読み込んで推論を実行する推論エンジンと、その推論エンジンへ各アプリケーションなどからアクセスするためのエンドポイントとして機能するAPIの仕組みを準備する必要があります。
APIに関しては基本的なアプリケーション開発と同じとなり、純粋にHTTPリクエストを受け取る仕組みを準備します。
例えばPythonのFastAPIやFlaskなどのフレームワークを利用して実装できます。他にも推論用に用意された専用の仕組みを用いることも可能です。
推論エンジンに関しては、いくつかソフトウェアがあり、選択して利用するものとなります。例えば、以下のようなものがあります。
- LLM用: TensorRT-LLM, vLLM, SGLang
- 非LLM用: TensorRT, LibTorch, ONNX Runtime
ソフトウェアによっては推論エンジンとAPIがセットになっているものもあります。
このように推論をするためにはただモデルを準備するだけでなく、APIや推論エンジンを用意する必要があります。
また、本記事では詳細は省略しますが、使うモデルや推論エンジン側もより軽量に、より早く動作するように最適化を行うケースもあります。
NVIDIA NIMとは
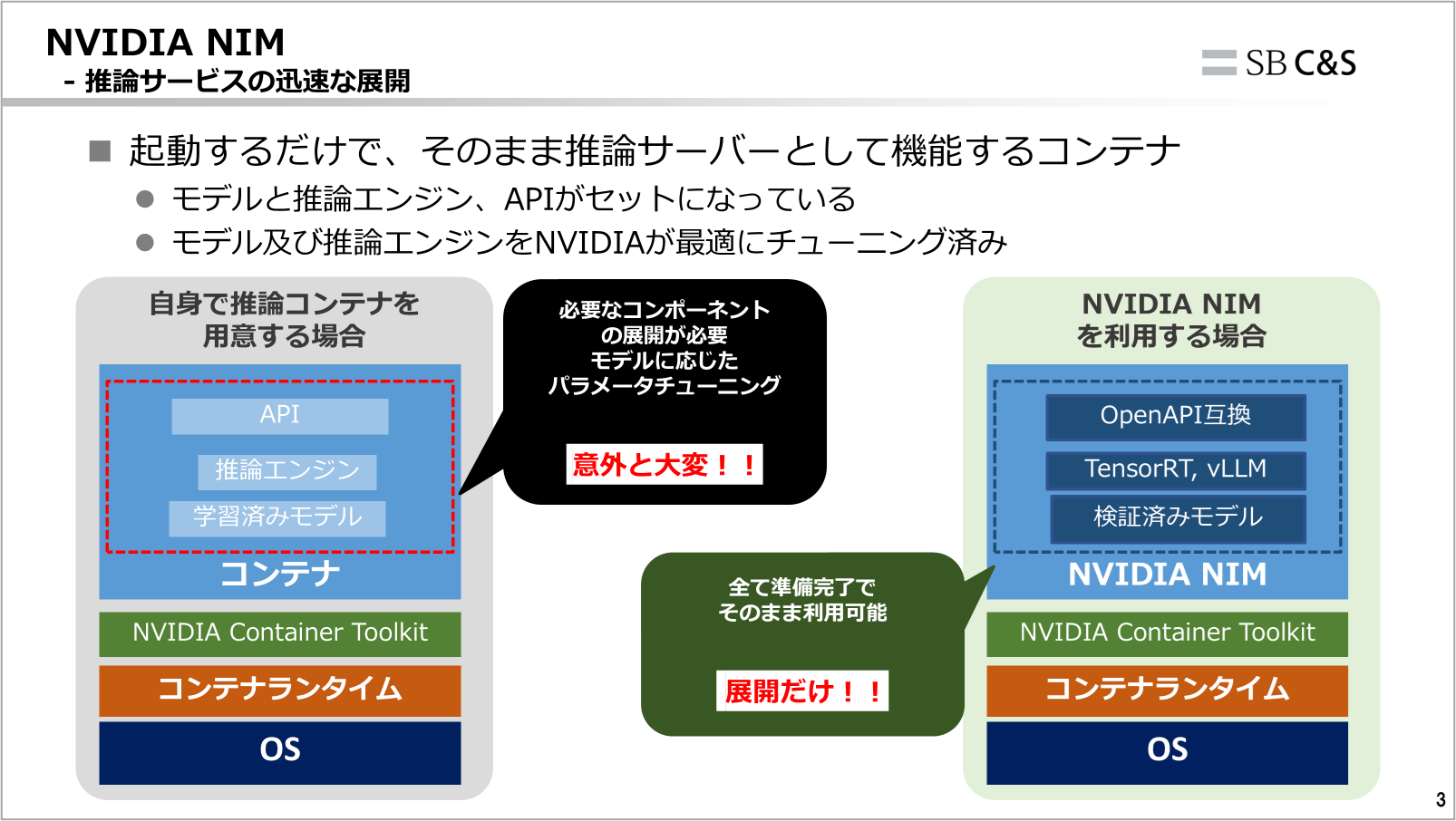
NVIDIA NIMは起動するだけでそのまま推論サーバーとして動作するコンテナ群です。
前章にて推論にはAPI, 推論エンジン, モデルの3つが必要なことを認識いただいたと思います。NVIDIA NIMはこの3つが全てセットになった状態でコンテナとして提供されます。
そのため、使いたいモデルさえ決まっていれば、コンテナを起動するだけですぐに推論を行えるようになります。
また、モデルや推論エンジン自体もNVIDIAによって最適化されています。
利用可能なモデルもllamaなどの主要なモデルを始め多く用意されています。
https://build.nvidia.com/models
NIMのモデルの確認方法
NIMのモデルは大きく2種類の方法で確認することができます。
- NVIDIA API Catalog
- NVIDIA NGC Catalog
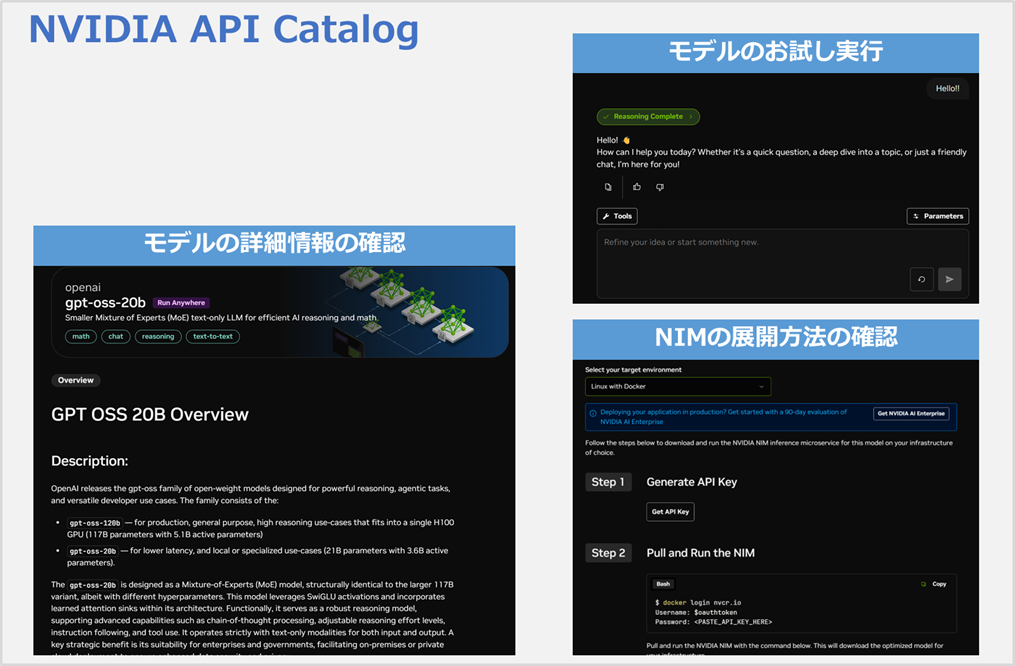
NVIDIA API Catalogではモデルごとに、詳細情報の確認から、モデルのサンプル実行などが実施できます。
また、展開方法も記載されており、まずはここを見ればNIMを試すことが可能になっています。
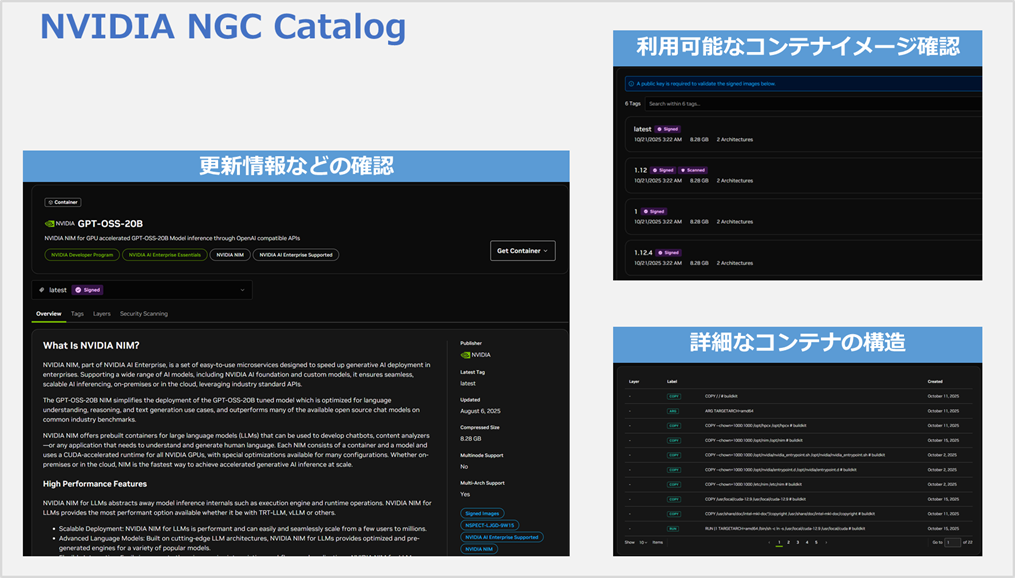
一方NGC Catalogの方ではよりコンテナ目線の情報が記載されています。
例えば、最新がいつ更新されたのか、対応しているアーキテクチャの情報、詳細なコンテナの構造などを確認できます。
また、一番重要な点として、利用可能なコンテナイメージのバージョンを確認できます。
コンテナを使う上では各実行環境によって差がでないようバージョンを指定するケースが多いため、こちらで確認するのが良いです。
最初のお試しとしてはAPI Catalogから始めつつ、もう少し踏み込んでバージョンを指定したりする場合は、NGC Catalogを使うのが良いと思われます。
NVIDIA NIMの展開
それでは試しにNVIDIA NIMの展開を行っていきます。
今回はGPT-OSS-20Bのモデルを搭載したNIMを対象とします。
前提条件としては以下が準備済みとします。
- GPUコンテナが起動可能なコンテナホスト
- 本記事ではH200(141GB) のGPUを利用します
- NGC API Key
- NVIDIAのNGCのサイトから発行可能です
- https://org.ngc.nvidia.com/setup/api-keys
それではまずNIMの展開時に使うパラメータをいくつか環境変数に入れます。
今回は以下3つを準備しておきます。
export NGC_API_KEY={NGCで取得したAPIキー}
export LOCAL_NIM_CACHE=~/.cache/nim
export NIM_KVCACHE_PERCENT='0.5'
1つ目のNGC_API_KEYはその名の通りですが、NGCのAPIキーとなります。NIMは起動時にモデルのダウンロードなどを行います。その際の認証などでこのキーが内部的に用いられます。
2つ目のLOCAL_NIM_CACHEはダウンロードされたモデルのキャッシュの保存先として用いるパスを指定します。2回目以降同じNIMを起動する際にモデルのダウンロードが行わずに素早く起動させるために必要となります。
3つ目のNIM_KVCACHE_PERCENTは利用するGPUメモリのどれくらいを使えるようにするかを指定しています。一般的にLLMの推論では以下2つがGPUメモリを消費します。
- モデルの重み
- KVキャッシュ領域
NIMはデフォルトではGPUメモリ全体の9割を利用しようとします。9割の中で、モデルの重みを展開後、余った領域をKVキャッシュ領域に割り当てる形です。
ただし、GPUを他の用途でも使っている場合やKVキャッシュがそこまでいらない場合などは9割が過剰になる場合もあるため、このオプションで割合を指定できるものです。
例えば今回の141GBのGPUを使っている場合、0.5を指定すると約70GBほどGPUを使うように制御できるイメージです。
なお、NIMには他にも多くのオプションがあるため、用途に応じてお使い分けください。
https://docs.nvidia.com/nim/large-language-models/latest/configuration.html
それではNIMの起動を行います。
先ほど用意した環境変数を指定する形式で、docker runコマンドを実行します。
※初回起動時はモデルのダウンロードが実行されるため、少し時間がかかります。
docker run -it --rm -d -p 8000:8000 \
--gpus '"device='0'"' \
--name "nim-gpt-oss-20b" \
--shm-size=16GB \
-e NGC_API_KEY \
-e NIM_KVCACHE_PERCENT \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
nvcr.io/nim/openai/gpt-oss-20b:1.12
起動が完了したら、コンテナホストのIPアドレスとコンテナのポート番号宛にリクエストを送信すると、チャットのレスポンスが返ってくることが確認できます。
curl -s -X POST 'http://{コンテナホストのIP}:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "openai/gpt-oss-20b",
"messages": [
{"role":"user","content":"日本で一番大きい都道府県は?"}
],
"max_tokens": 512,
"temperature": 0
}' | jq -r '
.choices[0].message.content
'
レスポンス例
日本で一番大きい都道府県は **北海道** です。
- 面積:約83,456 km²(日本全国の約22%)
- 日本の都道府県の中で最も広い面積を持ち、北部の寒冷地帯から南部の温暖な地域まで多様な気候と地形が広がっています。
このようにNIMを用いることで、簡単に推論サーバーを準備することができました。
あとは実際のAIアプリケーション等でIPアドレスとポート番号を指定することで、チャットが可能なLLMとして利用できます。
他のモデルでも試したい場合は、手順含めて記載があるAPI Catalogで探してみてください。
https://build.nvidia.com/
まとめ
今回はNVIDIA NIMを用いた推論サーバーの導入について紹介いたしました。
推論を行うにもモデルだけではなく、APIや推論エンジンなども考慮する必要がある中、NIMを用いることでコンテナを起動するだけで推論ができるのはとても良い点です。
「オンプレミスでLLMを動かしてみよう」となった際の最初の取っ掛かりとしても向いているため、ぜひお試しください。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
村上 正弥 - Seiya.Murakami -
VMware vExpert




