


パッと手軽にPure Storageの特長を掴みたい。
そんなあなたのために、Youtubeで「5分で理解(わか)る、FlashArray!」動画シリーズを公開中です。ぜひこちらも合わせてご覧ください!
==========以下本編==========
こんにちは、SB C&S 中田です。
入門!FlashArrayシリーズでは、Pure Storageのフラグシップモデル「FlashArray」についてより多くの人にその魅力を知っていただけるよう、わかりやすく、を第一に記事を書かせていただきます。
より深い内容を知りたい方は、本サイトにて連載している「実践!FlashArray」シリーズや、弊社にて実施しているハンズオントレーニングにご参加いただけますと幸いです。(ハンズオントレーニングは不定期開催のためセミナー一覧にない場合もございます。ご容赦ください。)
また、「【まずはここから】ゼロからわかるPure Storage」の内容を前提として書いておりますので、まずはそちらをご覧ください。
さて、入門シリーズ第2回となる今回は、FlashArrayのアーキテクチャについての紹介です。書き込みデータの流れ、重複排除と圧縮、RAID-3Dの順に書かせていただきます。
書き込みデータの流れ
ストレージに求められる最重要事項は「データロスを起こさない」こと、そしてその上でより早くデータを転送することです。こちらを念頭にFlashArrayにデータが書き込まれる際の処理順序を見ていきます。
以下の図は、ホストからの書き込み要求に対してコントローラーが準備完了を返したのち、データがホストから送信された後から、コントローラーがAck(書き込み完了)をホストへ送信するまでの処理順序を示しています。
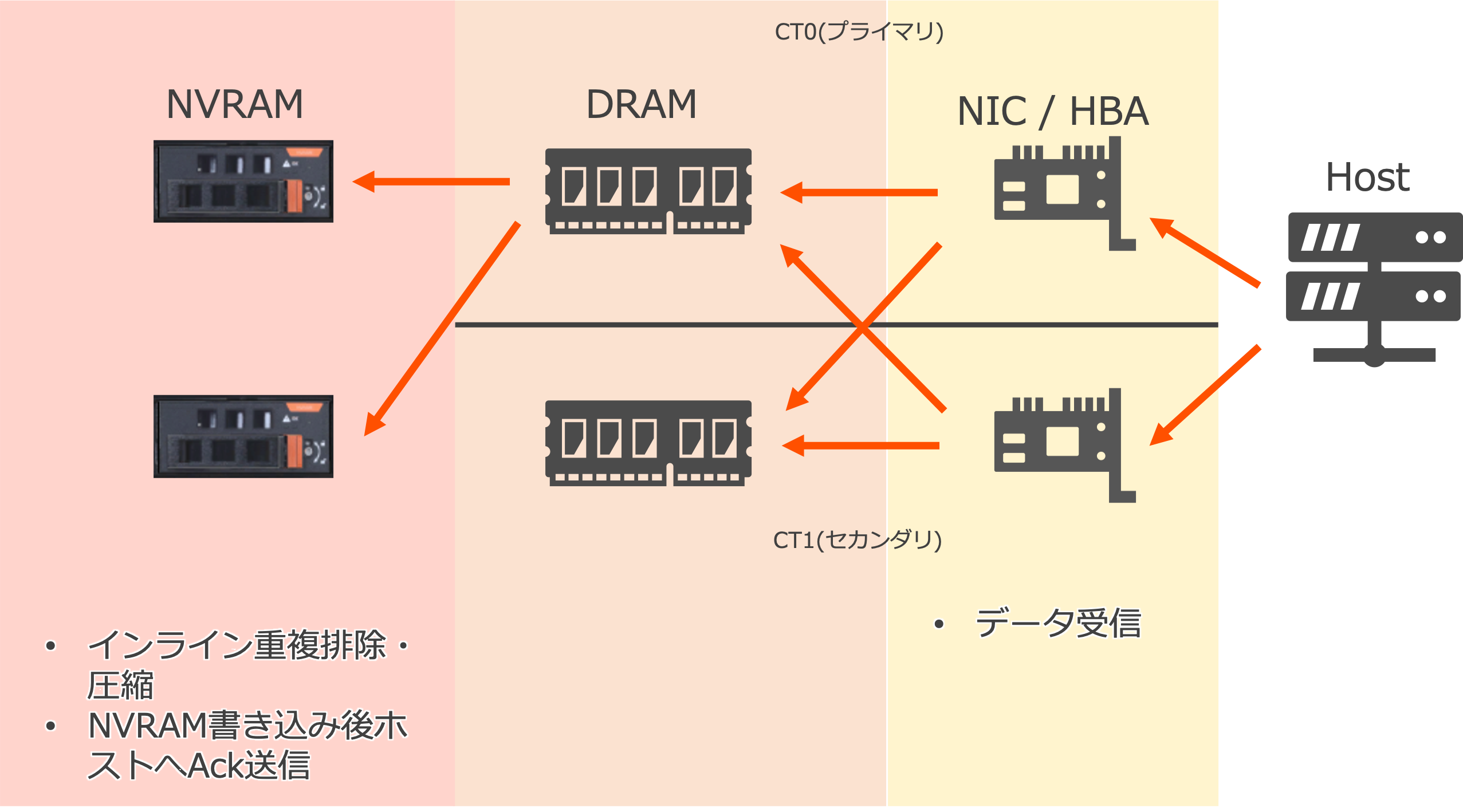
※図ではCT0がプライマリ、CT1がセカンダリとして図示していますが、この役割はコントローラーに対して固定ではなく、起動順序などの要因によって変化します。
まず、データがホストからコントローラーに送信されます。この際、コントローラーのフロントエンドはActive-Activeで動作しているため、両方のコントローラー上のNIC/HBAでデータを受信することができます。つまり、両コントローラー分の帯域幅を有効活用することができます。
次に、NIC/HBAで受け取ったデータは両方のコントローラーのDRAM上にコピーされます。万が一プライマリコントローラーで故障などが発生してもスムーズに切り替えを行うことが可能です。
その後、プライマリコントローラー上のDRAMから2つのNVRAMに対してデータが渡されます。NVRAMにはバッテリーが搭載されているため、仮にPSUからの電力供給が止まったとしてもデータは保持されます。また2つのNVRAM上にデータを保持した状態でAckを送信するため、万が一NVRAMが故障などによって1つのNVRAMが利用できなくなった場合でもデータロスは起こりません。そのため、この時点でホストに対してAckを送信します。
また、NVRAM上では重複排除および圧縮が行われます。これに関しては次の「重複排除と圧縮」の章で詳しく解説いたします。
このように、万が一の事態をケアしつつ高速にデータを処理する仕組みがFlashArrayには備わっています。
重複排除と圧縮
重複排除と圧縮は、ともに効率よく容量を利用するための機能です。これは「ゼロからわかるPure Storage」でも書いた通りPure Storageが追求してきた「価格を抑えて、より広くフラッシュストレージを普及させる」ことに直結する非常に重要な要素となっています。
以下の図は、FlashArrayにおける重複排除と圧縮のフローを示しています。
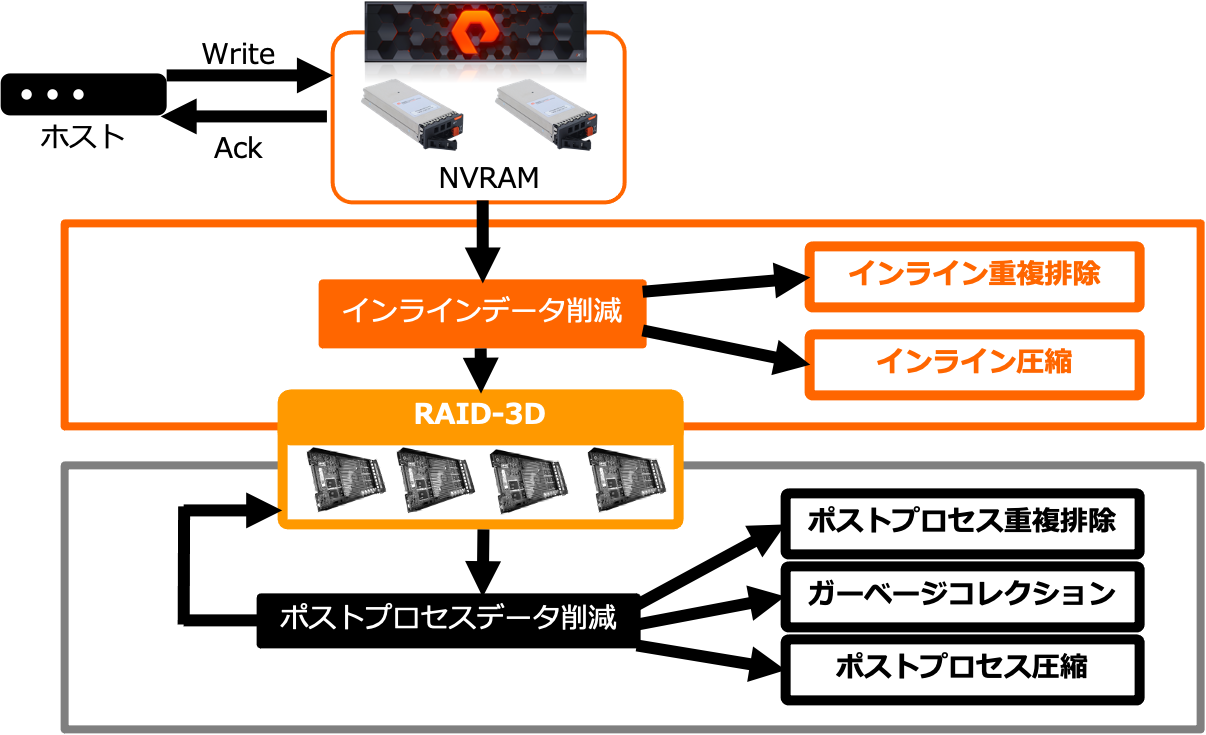
図の通り、重複排除と圧縮はインラインとポストプロセスのそれぞれで実施されます。
インラインでは重複排除・圧縮処理に時間をかけすぎるとボトルネックとなってしまうため、処理速度が重要となってきます。一方でDirect Flash Module(DFM)にデータを書き込む前にデータ量を減らすことは、フラッシュの書き込み寿命やNVRAMからDFMへのデステージに要する時間を短縮することにつながります。そのため、処理速度とデータ削減のバランスが重要となってきます。
一方ポストプロセスではデータ削減率を上げるほどDFMに書き込み可能なデータ量が増えるため、どれだけデータ削減を行うことができるか、が重要となってきます。
以下では重複排除の項と圧縮の項に分け、それぞれインラインとポストプロセスでどのように処理が行われるのかについてご紹介します。
圧縮
圧縮での大きな特徴は、データ分析による効率化です。
インライン圧縮ではデータの分析に基づき、どの程度の圧縮率が見込めるかを判断します。その結果に基づき、圧縮による節約容量が小さいデータ、もしくは圧縮不可能と見做されたデータは圧縮をスキップします。また圧縮速度・解凍速度に優れたLZO圧縮を使用します。
一方ポストプロセス圧縮では先述のデータ分析結果をもとに、複数の圧縮アルゴリズムから最適な圧縮アルゴリズムを選んで実施することで圧縮率をより高めています。
重複排除
重複排除での大きな特徴は、重複データの検出の前に対象データを少なくするための下処理を行うことと、業界最小の512Byte単位の可変調重複検出です。

上記はバイナリエディタでデータを開いた際のものです。重複データ検出前の下処理としてこのように同一パターンの配列が続くデータを事前に重複排除対象から除外しメタデータとして保存しておくことで、検査対象となるデータをなるべく少なくしています。
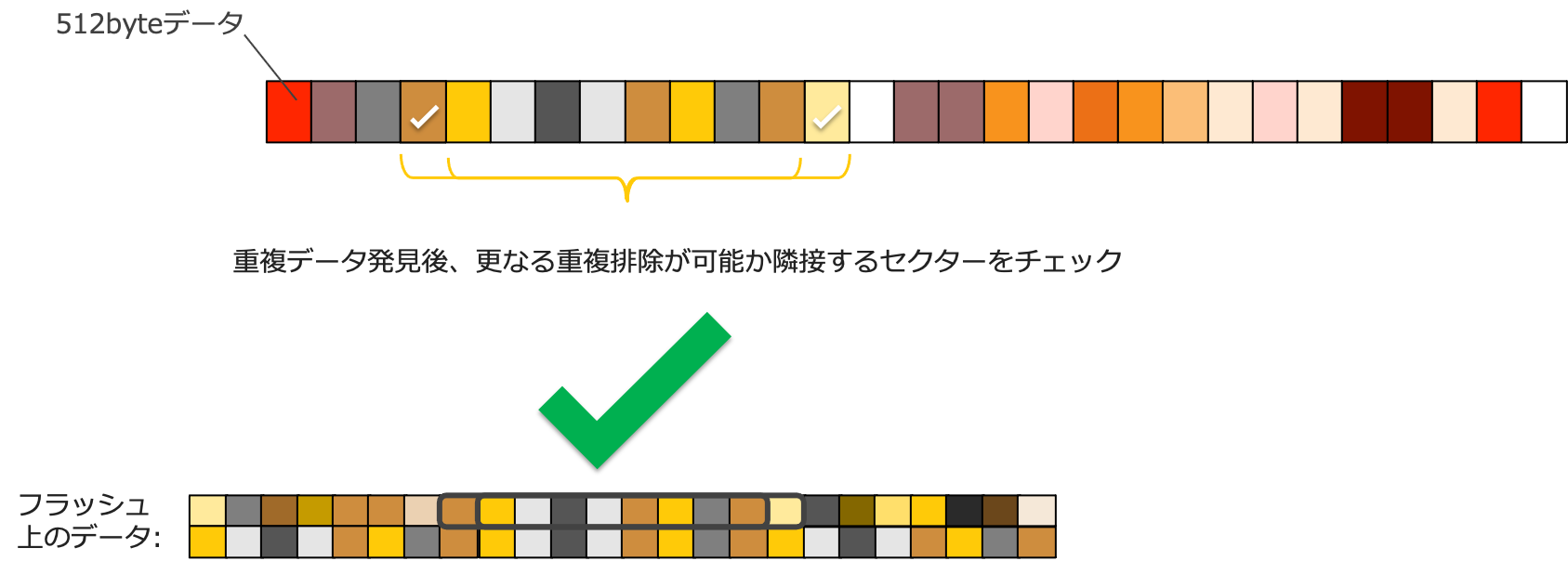
また重複データの検出については、ハッシュ値を用いた重複データの検出・実データの照合を行なったのち、見つかった重複データの隣接データに512byteずつ検査範囲を拡大していくことで、効率よく重複部分の検出を行なっています。
またインラインとポストプロセスでの違いですが、インラインではその検査対象を直近の一定期間、もしくは一定容量のデータまでに絞っています。一方ポストプロセスでは保存された全てのデータを対象として重複検出処理を行うことで、最大効率の重複排除を行います。
このようにFlashArrayでは、データ分析やパターンデータの排除といった仕組み、そしてインラインとポストプロセスでの処理の使い分けによって処理速度とデータ削減率を両立しています。
RAID-3D
RAID-3Dはページ単位の冗長性とドライブ単位の冗長性を確保したRAIDです。ここでは、冗長化されたこの2つのデータ単位に分けて解説します。
ページ単位の冗長性
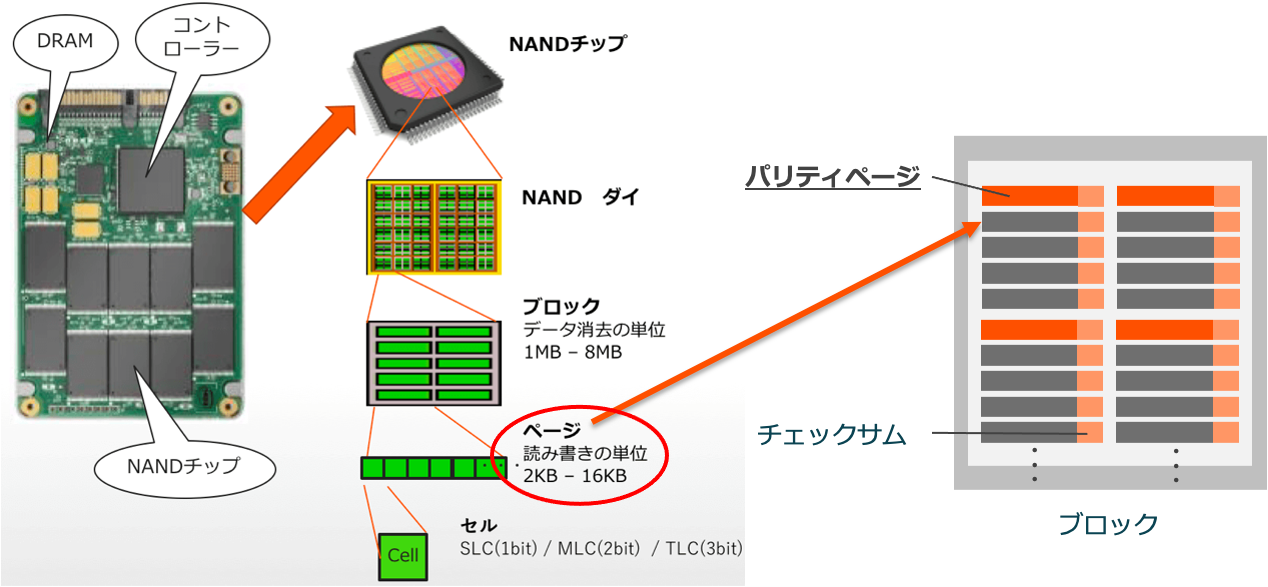
ページ単位の冗長性がなぜ必要なのか、これは「ビットエラー」というHDDにはないフラッシュデバイス特有の現象が関係しています。ビットエラーは、フラッシュにたくさんの読み書きが行われた結果一部のセルが寿命を迎え、データの読み書きができなくなってしまう現象です。ビットエラーが発生した場合、そのデータの復元には通常、ディスク単位のRAIDからの復元が必要となります。しかしこれには全てのディスクへのアクセスが必要となり、ストレージパフォーマンス低下の原因となり得ます。
一方FlashArrayでは、データにページ単位の冗長性を付与しています。ページとは、フラッシュデバイス内の半導体チップ(NANDチップ)を構成するデータの読み書き単位です。ページに書き込まれた実データに対してパリティページを作成することで、上記のようなビットエラーが発生した場合でも、単一のフラッシュデバイス上で復元が完結し、ストレージパフォーマンスの低下を最小限に抑えることができます。
ドライブ単位の冗長性
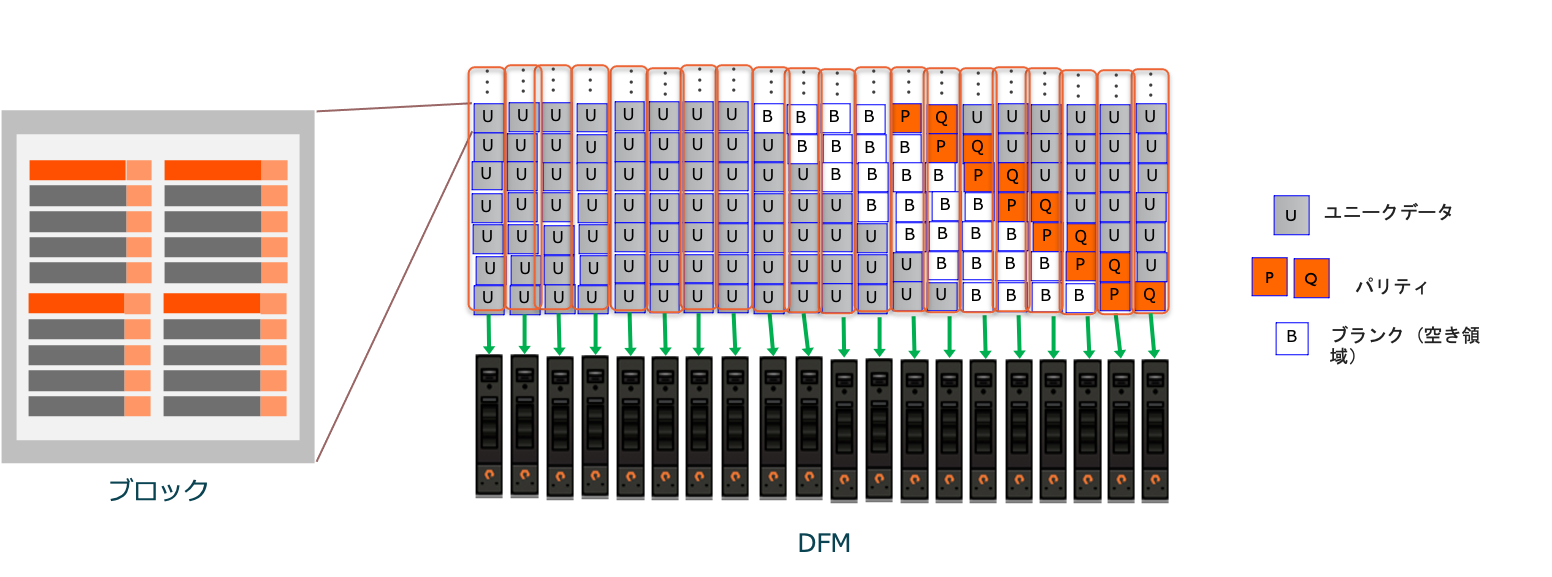
FlashArrayでは、ドライブ上の実データに対して2つのパリティを付与することでドライブ単位の冗長性を付与しています。2つのパリティを作成しているため2本のドライブ同時障害まで対応可能となっており、RAID6相当の冗長性となっています。
ただしRAID6と異なる点として、FlashArrayでは明示的にスペアドライブを指定するのではなく、スペアドライブに対応する容量(ブランク)を分散して確保しています。これにより負荷分散を図りつつスペアドライブ分のパフォーマンスを最大限に活かす仕組みとなっています。
このようにRAID-3Dは、パフォーマンスを最大限に活かしつつ、フラッシュデバイスに最適化された仕組みを持っています。
今回は、FlashArrayのアーキテクチャについて解説しました。次回はFlashArrayのデータ保護&DR(Disaster Recovery)機能について紹介予定です。お読みいただければ幸いです。
Pure Storageに関する全ての記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第1技術部 2課
中田 浩嗣 - Hirotsugu Nakata -
VMware担当を経て、現在ストレージ担当の中でもPure Storageを専任に担当するプリセールスエンジニア




