こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
この記事はその第4回目です。第1回目では基本的な概念について、第2回目では必要な環境準備について説明しました。また、第3回目ではAIモデルのトレーニング前のデータ準備やCommunications Miningへのセットの仕方を説明しました。
この記事では、モデル トレーニングを開始する前にタクソノミーを構築する方法について、明らかにしていきます。
目次
1. タクソノミーとは
2. 今回のケースにおけるタクソノミー定義
3. Communications Miningにタクソノミーをセット
1-1. ラベルの設定
1-2. フィールドの設定
1-2-1. フィールドの種類
1-2-2. 一般フィールド
4. 最後に
1. タクソノミーとは
さて、それではタクソノミーとは何でしょうか。
「タクソノミー(taxonomy)」とは、「分類」を意味する言葉です。元々は生物学で生物を分類するための用語ですが、IT業界では、情報やデータを階層的に整理することを指します。
UiPath Communications Miningにおいては、構造化データとして最終的に取得したいラベルやフィールドを決める事を「タクソノミーを設計する」と表現します。
ラベルは、それぞれのデータ内における意図または概念のことです。
フィールドは、データから抽出する情報を指します。
これだけだとわかりにくいので、下の図を用意しました。

左図の1番上の「丸くて赤くて美味しい」というデータをみてください。
これに対して、
ラベルは、それぞれのデータ内における意図または概念のこと。
つまり、「丸くて赤くて美味しい」というデータには、「フルーツ>りんご」というラベルがつけられると思います。
フィールドは、データから抽出する情報を指します。
「丸くて赤くて美味しい」というデータからは「赤」という情報を抽出したいです。
これは「色」を指すと思います。
このように、AIモデルを実際にトレーニングしていく前に、
- どのようなラベルを各データに紐づけるのか
- どのようなフィールドを抽出したいのか
これらを明確にする必要があります。
最終的に構造化データとして出力されるアウトプットがこの「ラベル」や「フィールド」になるため、分析したいコミュニケーションデータがどのようなものか、自分がCommunications Miningで自動化したい業務のためにどのようなアウトプットが必要か、どのような分析を行いたいかをよく考えながら、タクソノミーの設計を行うことが重要です。
2. 今回のケースにおけるタクソノミー定義
タクソノミーとは何なのかを説明した所で、今回のこのハンズオン記事シリーズにおいてはどういったタクソノミーを定義するのかを説明します。
前回1万行くらいのサンプルメールデータをアップロードしましたが、あのデータは、とある会社のUiPathお問い合わせ窓口に集まるメールデータといった内容を意識して作成したものです。
お問い合わせ窓口に日々寄せられる、顧客からのメールの内容を理解して、メールの意図によって種別分けしたり、メールの文面からフィールドを抽出したいです。そこで、定義したラベルとフィールドは下記のようになります。
ラベル(メールの意図)
見積依頼 > Document Understanding
見積依頼 > Communications Mining
見積依頼 > Test Suite
見積依頼 > その他
製品問い合わせ > Document Understanding
製品問い合わせ > Communications Mining
製品問い合わせ > Test Suite
製品問い合わせ > その他
資料請求 > Document Understanding
資料請求 > Communications Mining
資料請求 > Test Suite
資料請求 > 資格試験について
資料請求 > その他
緊急
クレーム
フィールド(メールの文面から抜き出したい情報)
顧客名
製品名
顧客番号
3. Communications Miningにタクソノミーをセット
各データに対し、どのようなラベルやフィールドをCommunications Miningに認識してほしいのかが決まったので、実際に設定していきます。
1-1. ラベルの設定
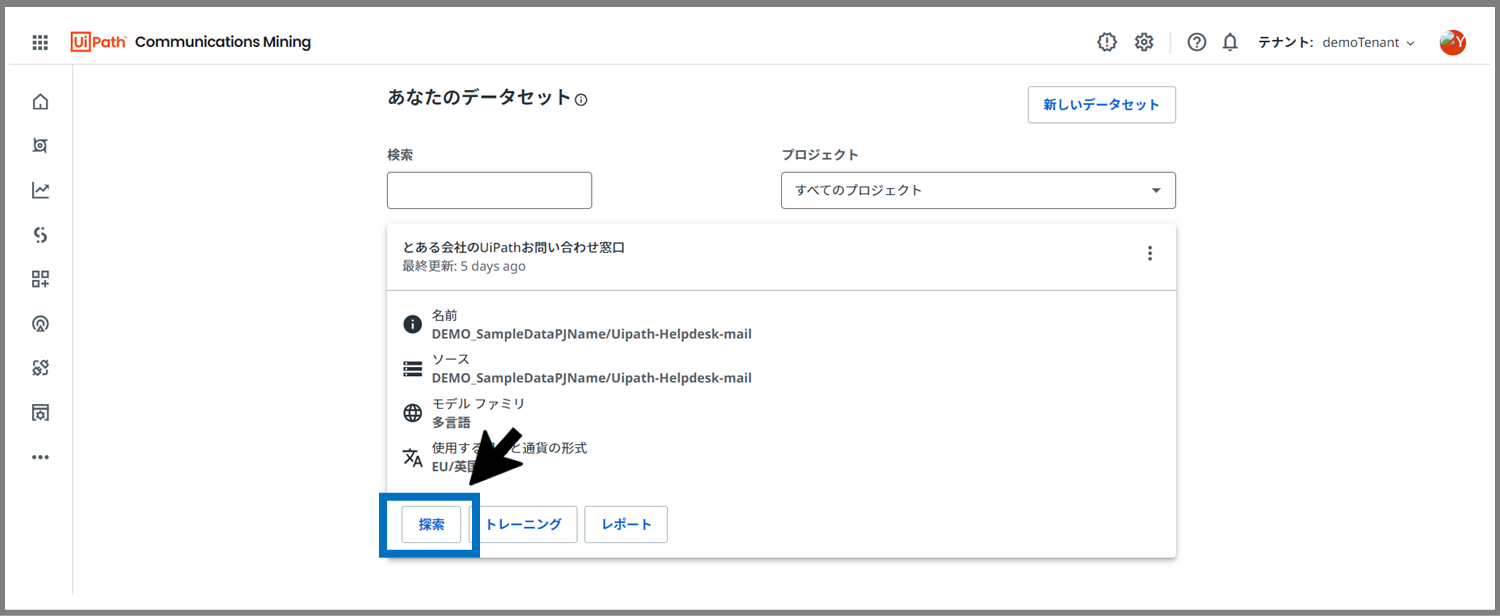
まず、Communications Miningのホームにいくと、3回目の記事で作成した上記のようなデータセットがあると思います。ここの「探索」ボタンをクリックします。
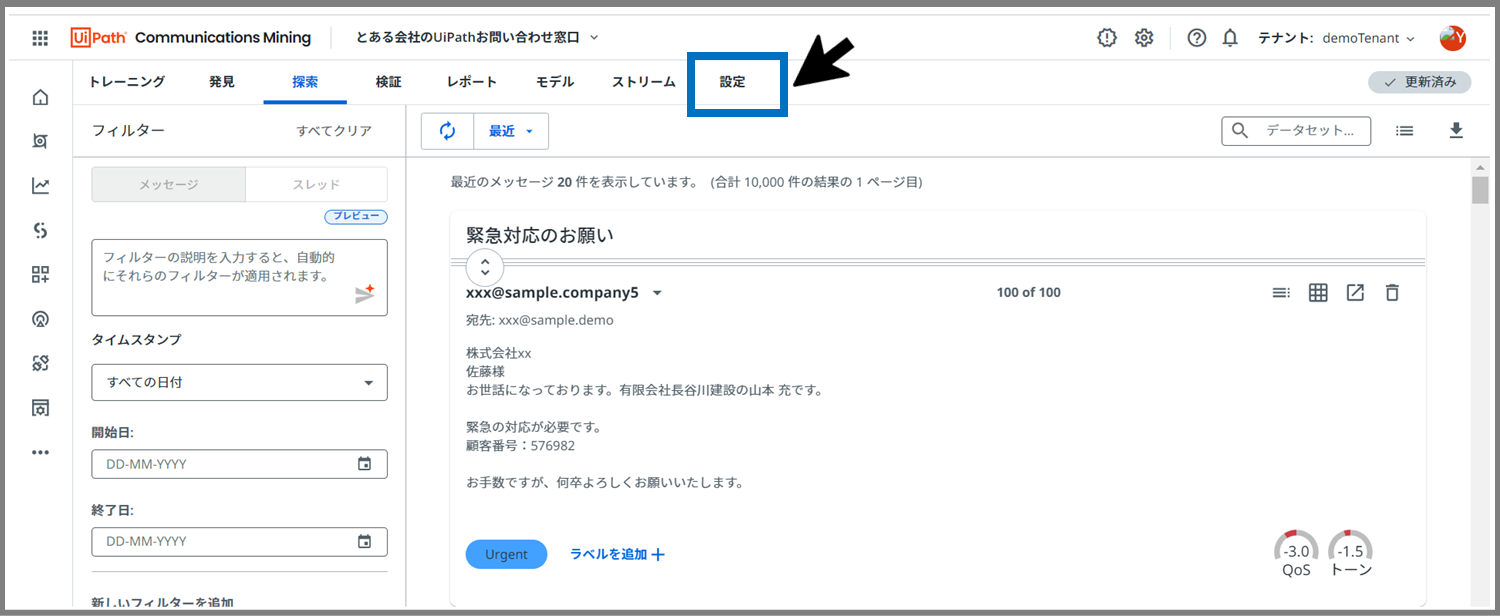
次に「設定」タブをクリックします。
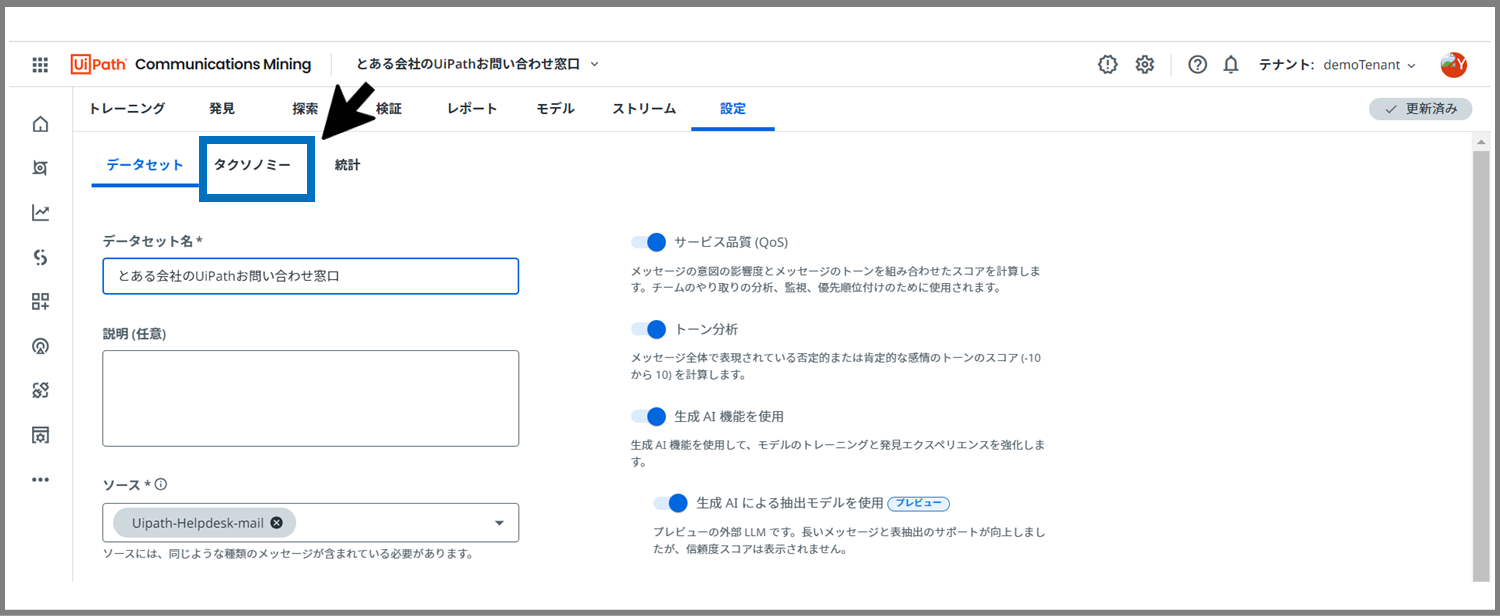
「タクソノミー」タブをクリック
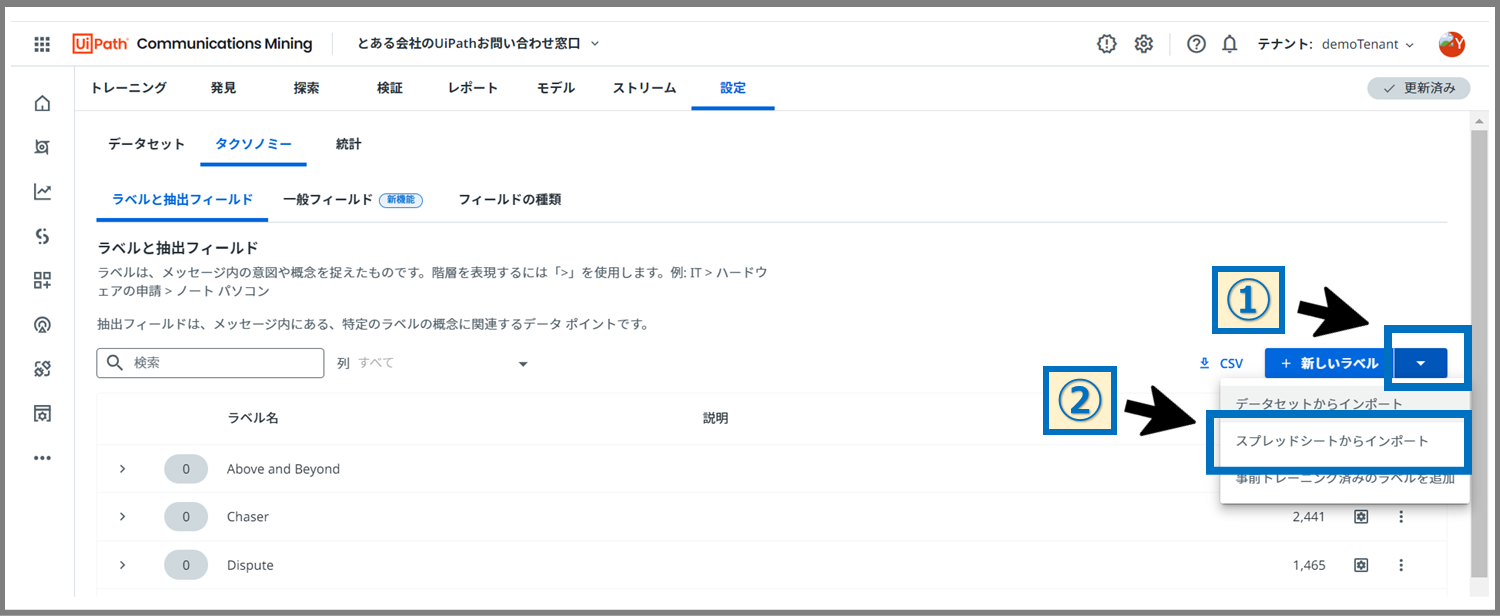
「新しいラベル」ボタン横の▼をクリックすると出てくる、「スプレッドシートからインポート」をクリックします。
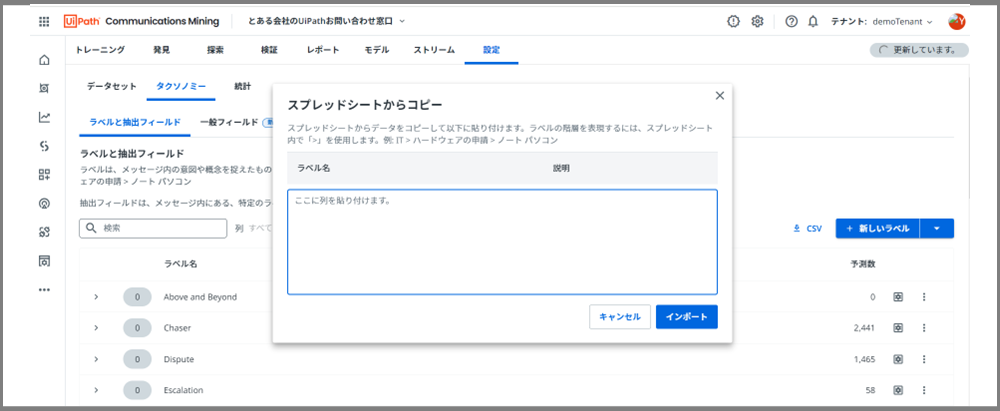
すると、上記のような画面が現れるので、「ここに値を貼り付けます」のフィールドに、2. 今回のケースにおけるタクソノミー定義で定義したラベルを全てコピーして貼り付けます。
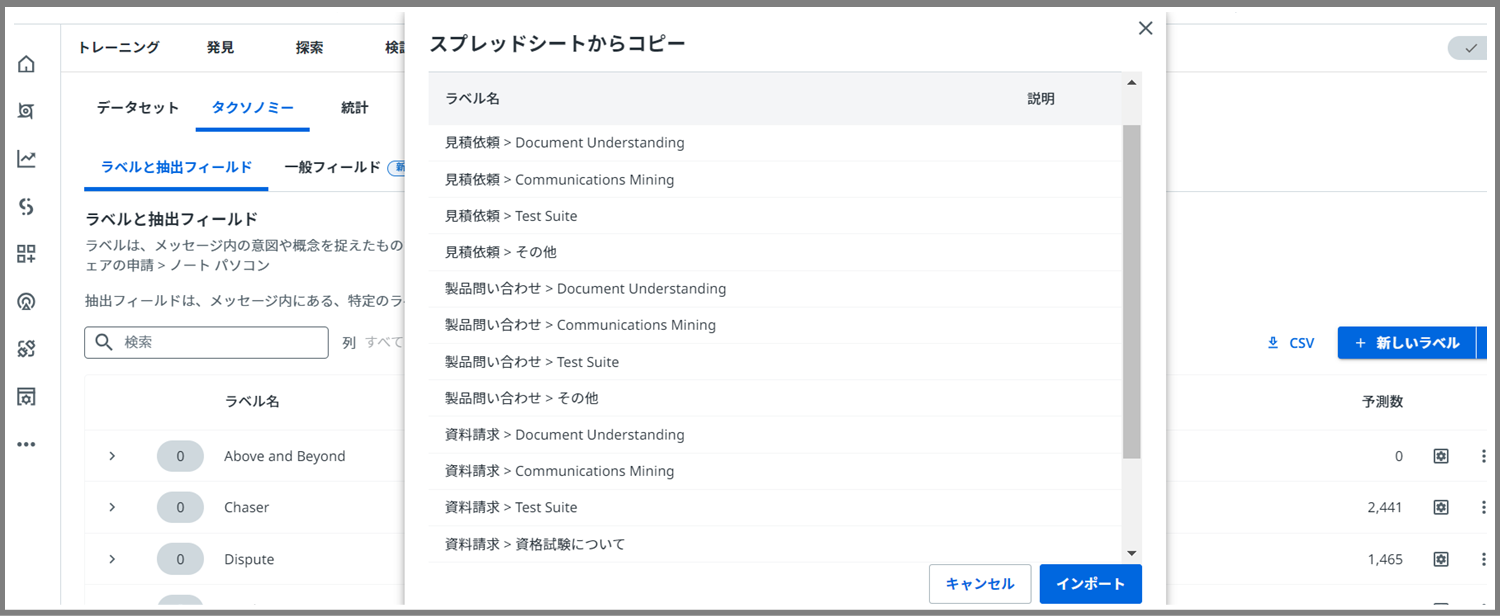
すると、このようにラベルを一気に全て貼り付けることができました。1つ1つ入力する必要がないのは便利でいいですね。
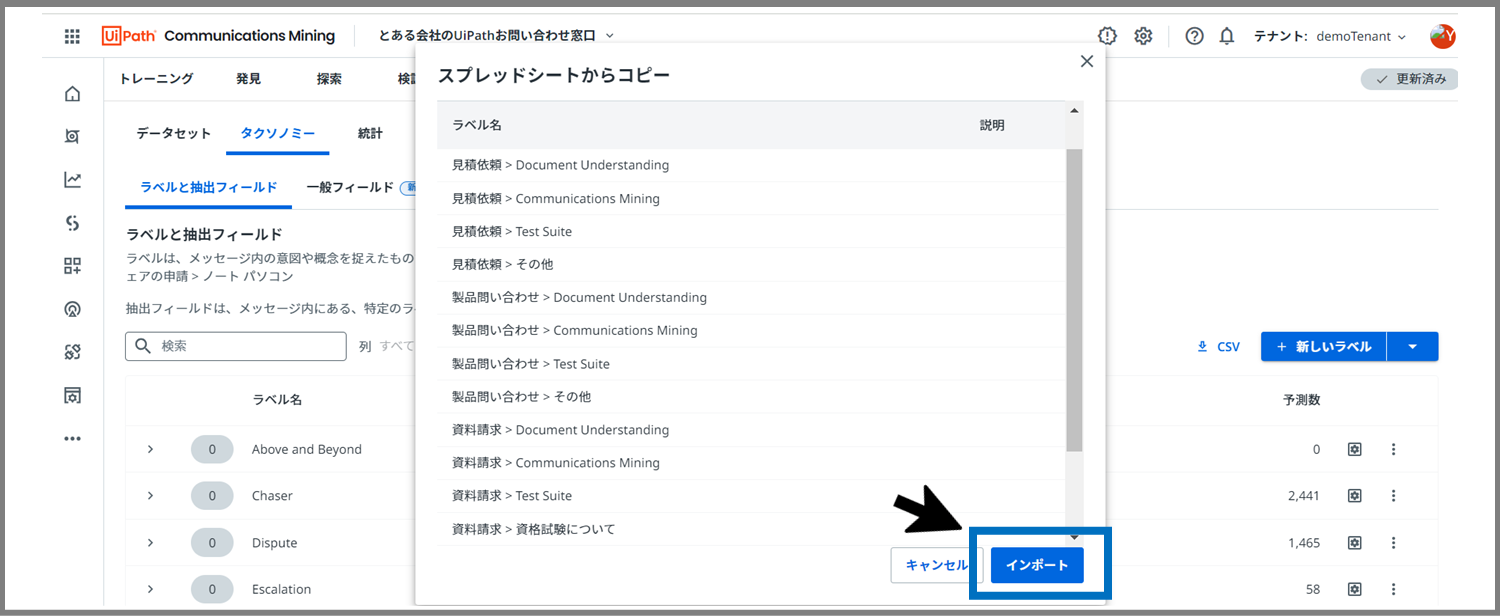
無事にラベルが入力されたら、「インポート」ボタンをクリックします。
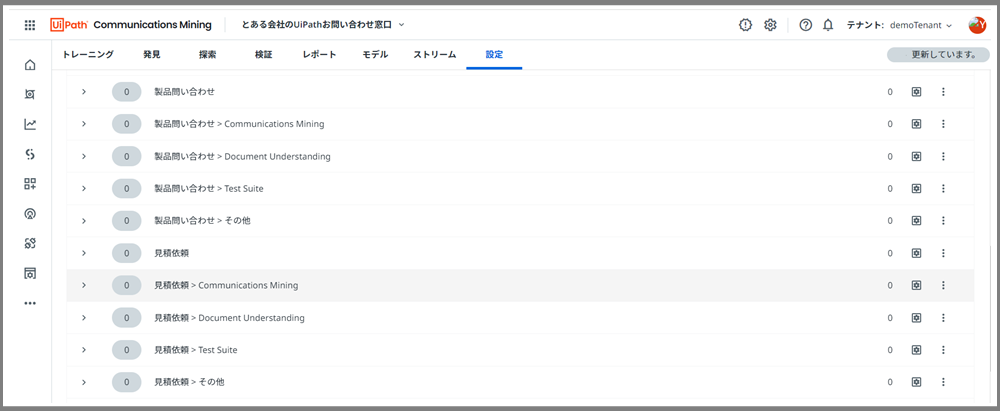
これでラベルの設定が完了です!
1-2. フィールドの設定
1-2-1. フィールドの種類
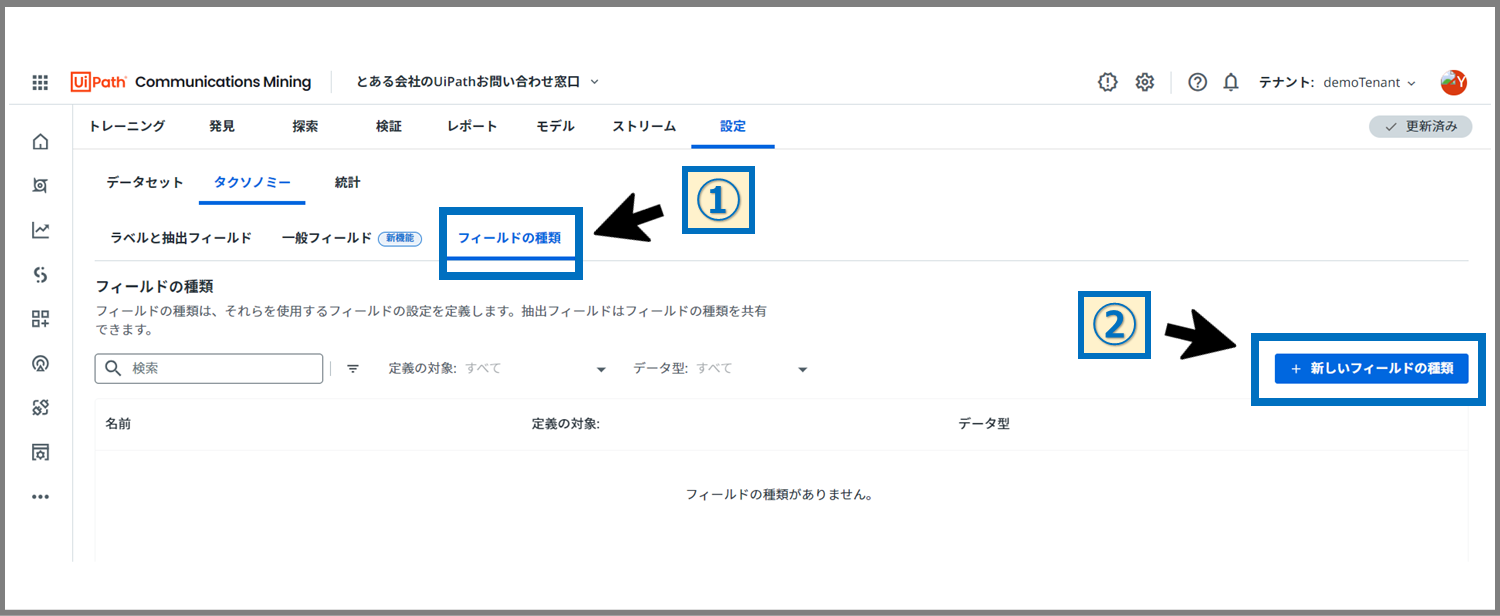
次に「フィールドの種類」のタブを選択し、「新しいフィールドの種類」ボタンをクリックします。
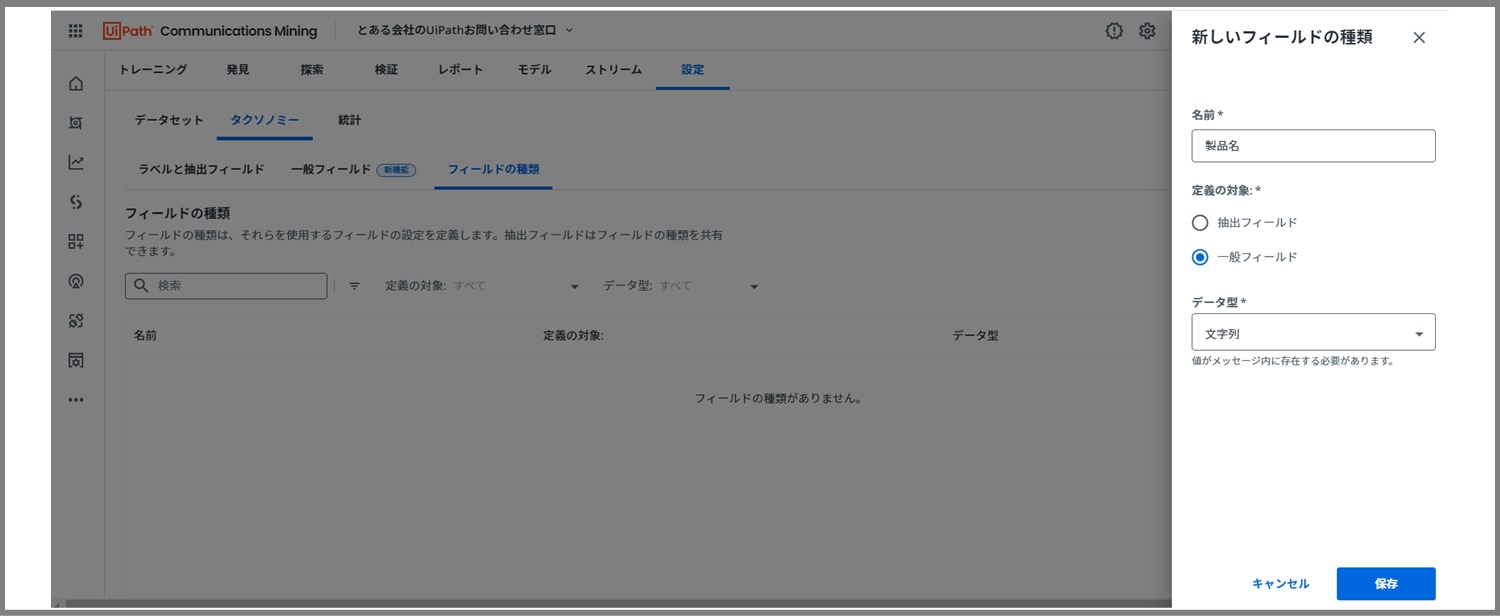
すると、上図のような入力画面が現れます。
「名前」には、2. 今回のケースにおけるタクソノミー定義で定義した一般フィールドを入力します。
※顧客名、製品名、顧客番号
「定義の対象」は、一般フィールドを選んでください。
「データ型」は文字列を選択してください。
最後に「保存」ボタンで完了です。
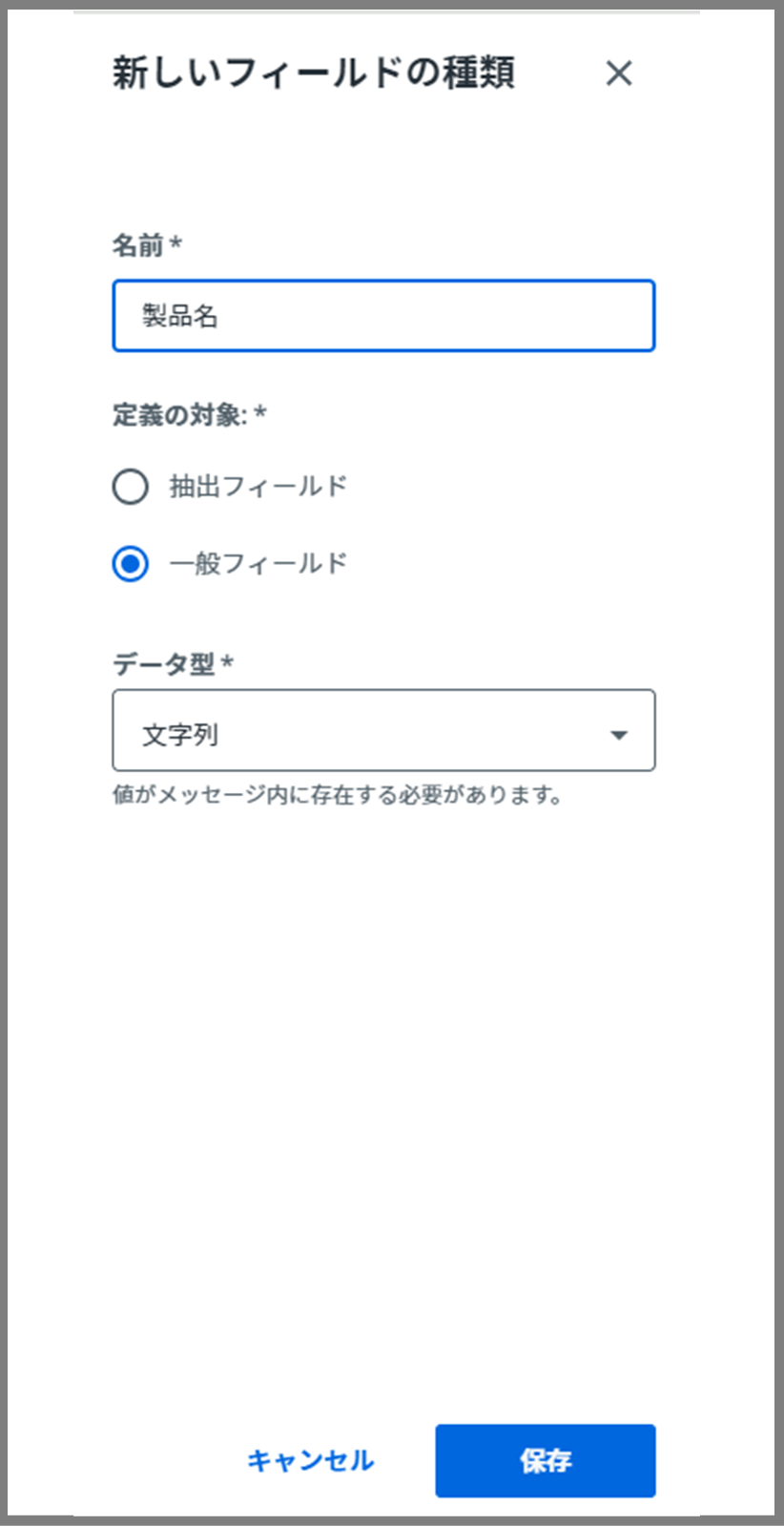
※先ほどのラベルみたいに一気に設定はできないので、「顧客名、製品名、顧客番号」を、1つ1つ設定していきます。
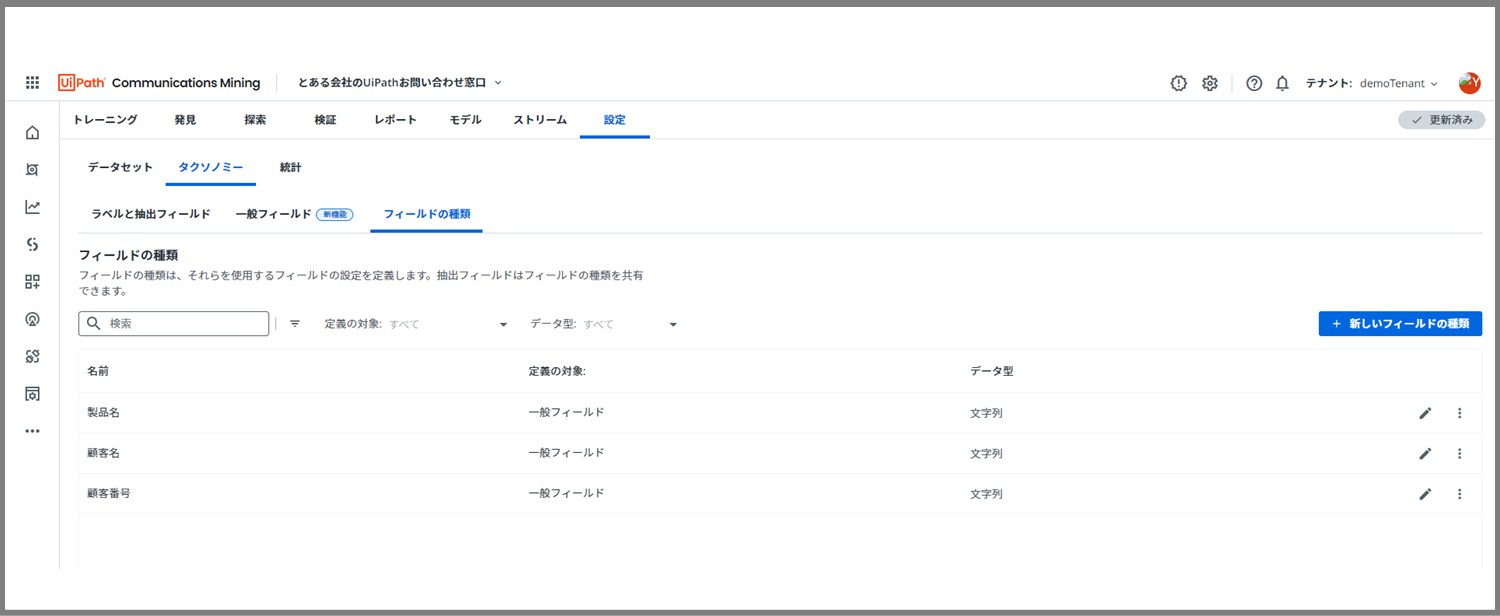
これで、フィールド種類の設定が全て完了しました。
今回のハンズオンシリーズでは、定義の種類で「一般フィールド」を使いますが、フィールドには「抽出フィールド」というものもあります。
話が複雑になるので、今回は「抽出フィールド」は利用しませんが、公式ドキュメントで「一般フィールド」と「抽出フィールド」の違い・使い分けもチェックしておくことを推奨します。
1-2-2. 一般フィールド
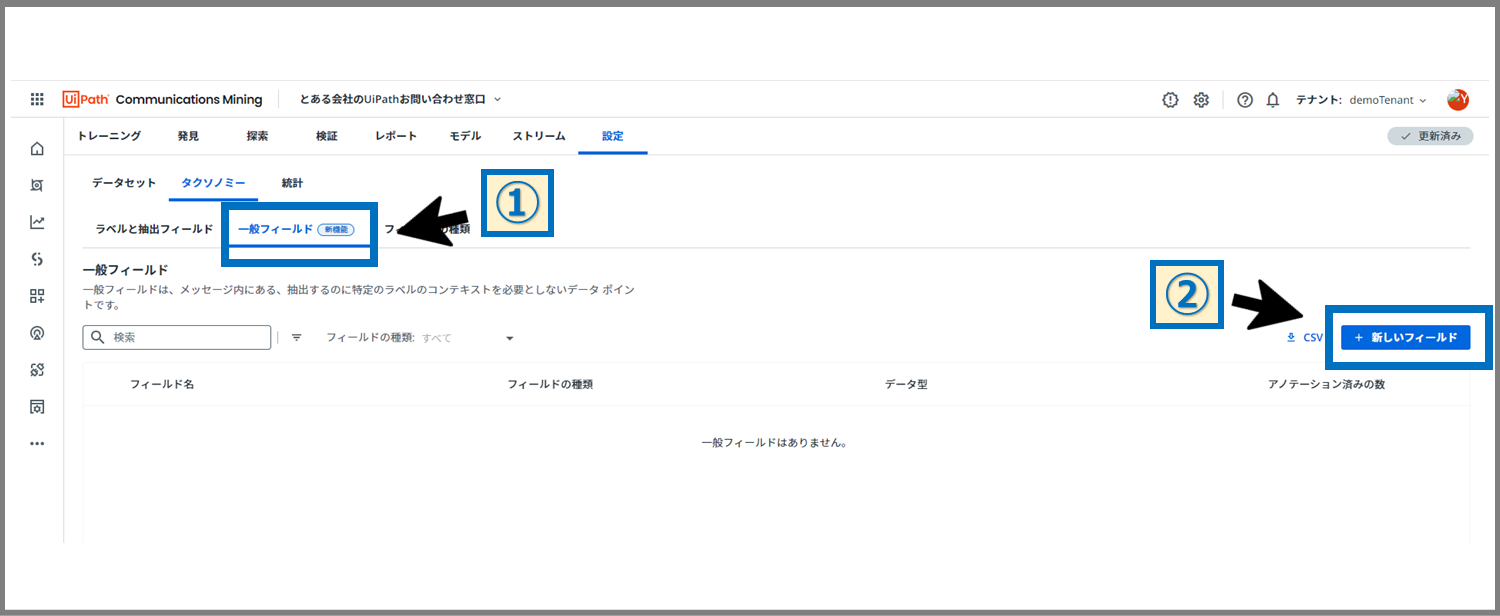
次に、①「一般フィールド」のタブを選択し、②「新しいフィールド」ボタンをクリックします。
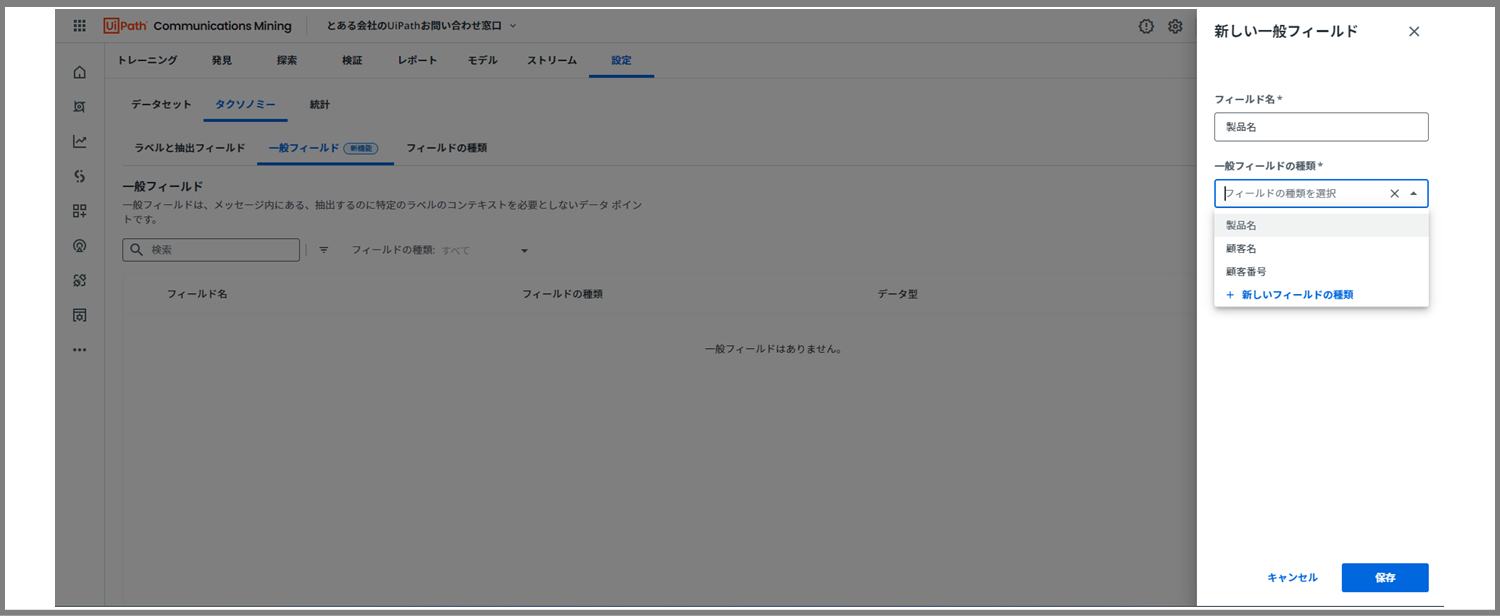
すると、上図のような入力画面が現れます。
「名前」には、先ほど定義したフィールド名を再度入力します。
※顧客名、製品名、顧客番号
「一般フィールドの種類」では、先ほど設定した「フィールド種類」を選択します。
最後に「保存」ボタンで完了です。
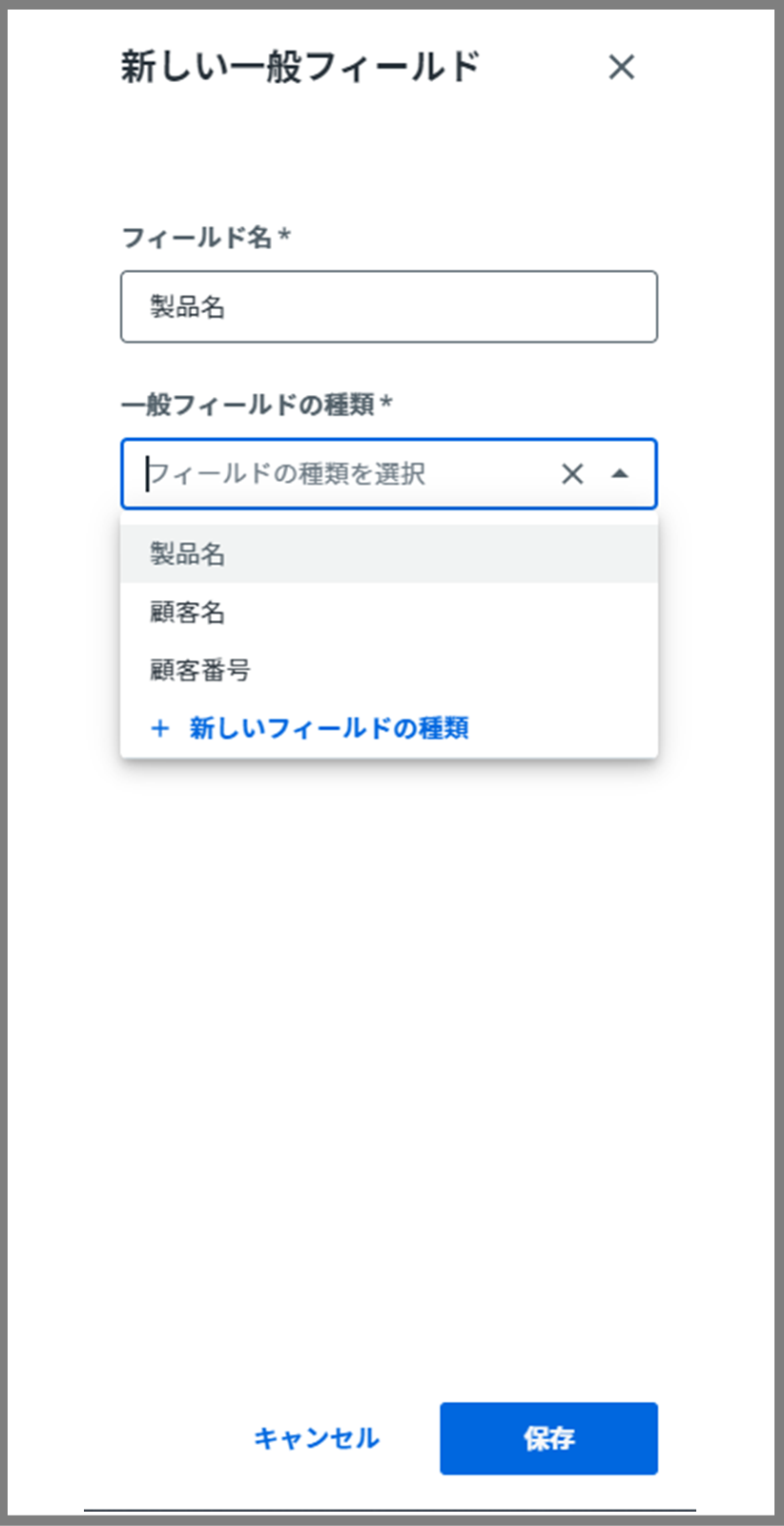
※これも、「顧客名、製品名、顧客番号」を、1つ1つ設定していきます。
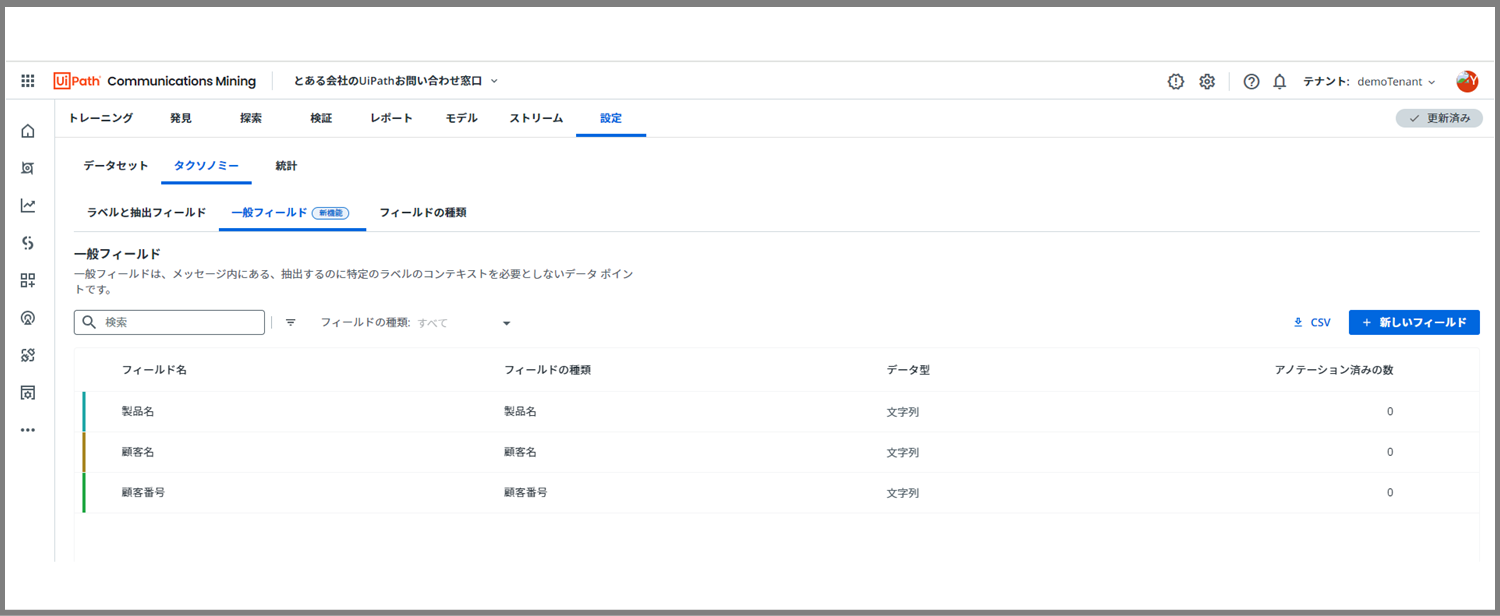
これで、一般フィールドの設定も全て完了しました。
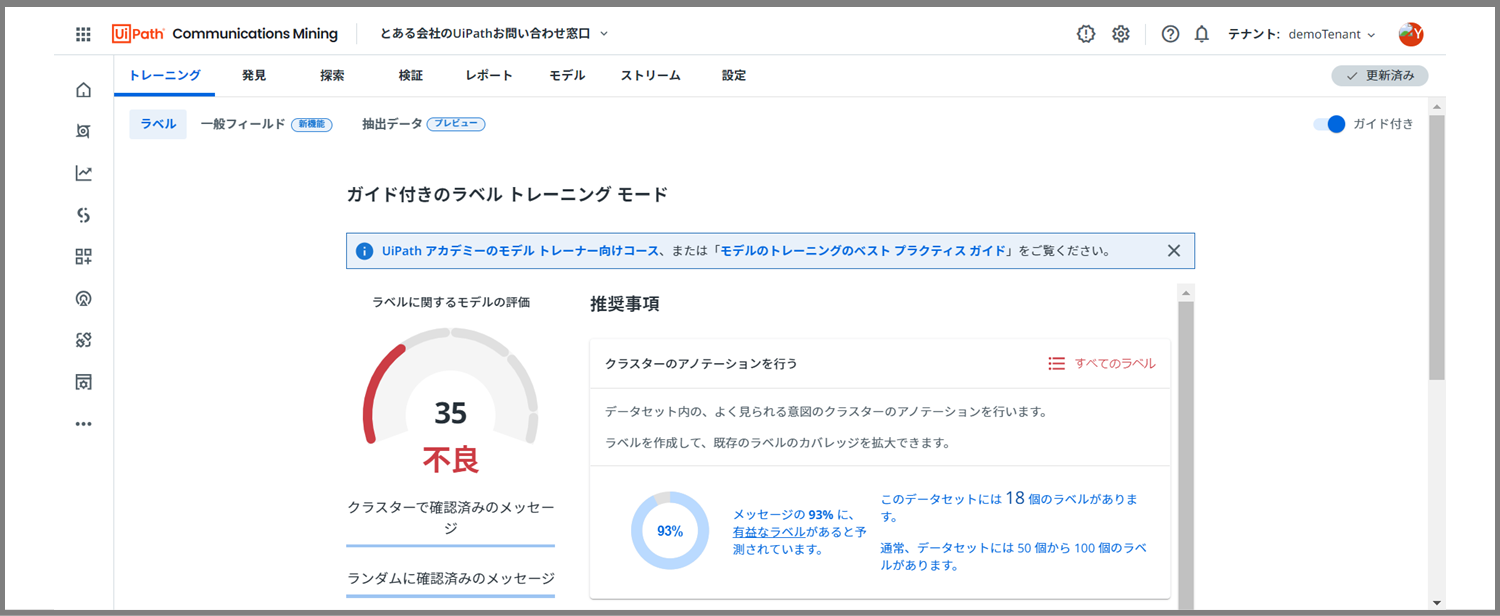
ラベルと一般フィールドの設定後、30分くらい放っておくと、「トレーニング」のページがこのようになりました。
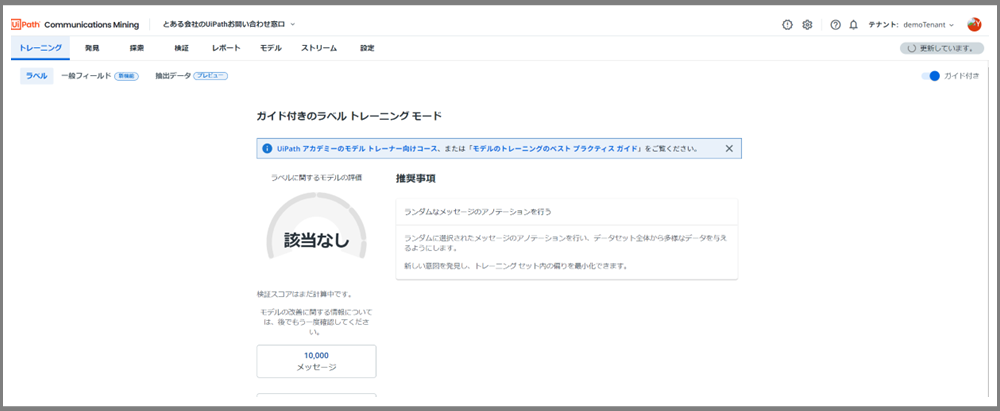
上が、タクソノミーを定義する前の「トレーニング」ページの状態です。左上の半円の図に「該当なし」と出ていますね。評価が何もない状態でした。
現在のモデルへの評価は「35」「不良」となっています。
タクソノミーの設定をするだけで、ある程度内部で勝手にトレーニングが進んで、AIモデルがカスタムされ、そこへの評価行われたということになります。
次回から、トレーニングを進めていくと、ここの数値が更に改善されていくことが確認できると思います。
4. 最後に
以上が、UiPath Communications Miningのタクソノミー設定でした。
次回の記事では、いよいよAIモデルをトレーニングしていきますので、お楽しみに。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子