皆様こんにちは。SB C&Sの下山です。
前回の記事の最後で、今後の連載では実際のアプリケーションやベンチマークの紹介に進む予定であることをお伝えしました。
その前段として、今回は2台の DGX Spark をスタック構成で運用する際に必要となる準備作業について整理しておきます。
なお、本記事の内容は、以下の NVIDIA 公式ドキュメントを参考に作成しました。
目次
物理的な接続手順
NVIDIA社が認定しているスタック構成用ケーブルは限られており、そのうち弊社にて利用しているAmphenol社製のNJAAKK-N911はケーブル長が 40 cm です。

このため、2台のSparkは物理的に近い位置に配置する必要があります。

Sparkおよびスタック構成用ケーブルはホットプラグに対応しているため、接続時にSparkをシャットダウンする必要はありません。また、各Sparkには2つのポートが搭載されていますが、どちらのポートにケーブルを接続しても問題ありません。

NICについて
スタック接続に使用するQSFPポートを制御するコントローラーにはConnectX-7が採用されており、Sparkに搭載されているConnectX-7は単一ポートあたり最大200 Gbit/sのイーサネット接続に対応可能です。
本来、ConnectX-7はEthernetに加えてInfiniBandプロトコルにも対応していますが、現時点ではEthernet通信のみがサポートされていることが確認されています。
以下はデバイスの情報をコマンドで表示した情報です。
0000:01:00.1 Ethernet controller: Mellanox Technologies MT2910 Family [ConnectX-7]
0002:01:00.0 Ethernet controller: Mellanox Technologies MT2910 Family [ConnectX-7]
0002:01:00.1 Ethernet controller: Mellanox Technologies MT2910 Family [ConnectX-7]
0007:01:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. Device 8127 (rev 05)
0000:01:00.0 rocep1s0f0 (MT4129 - P4242-0000 ) NVIDIA DGX Spark, P4242-0000, 2-port QSFP up to 200G, Ethernet, PCIe5 fw 28.45.4028 port 1 (ACTIVE) ==> enp1s0f0np0 (Up)
~一部省略~
NWセットアップ手順
ここまでのステップで物理的な接続は完了していますが、実際に通信を行うために必要なIPアドレスなどの設定はまだ行われていません。このセクションでは公式のドキュメントに則ってそれらの設定を2台のDGX Sparkに行っていきます。
スタック接続通信のセットアップ
スタック接続通信にIPアドレスを割り当てる方法として以下2つがあります。
・netplanを使用した自動割り当て(NVIDIAが提供するYAMLファイルを利用)
・手動での設定
ここではnetplanを用いた自動でIPアドレスを設定する方法を記載します。
※手動での設定方法は以下ユーザーガイド内「Option 2: Manual IP assignment (advanced)」をご参照ください
https://docs.nvidia.com/dgx/dgx-spark/spark-clustering.html#option-2-manual-ip-assignment-advanced
①netplan設定ファイルのダウンロード
②設定ファイルへ適切な権限を設定
③Netplan設定の適用
以下は上記手順を実際に実行した際の様子となります。
ここまでの設定にて2台のSparkは互いに通信可能な状態となりました。
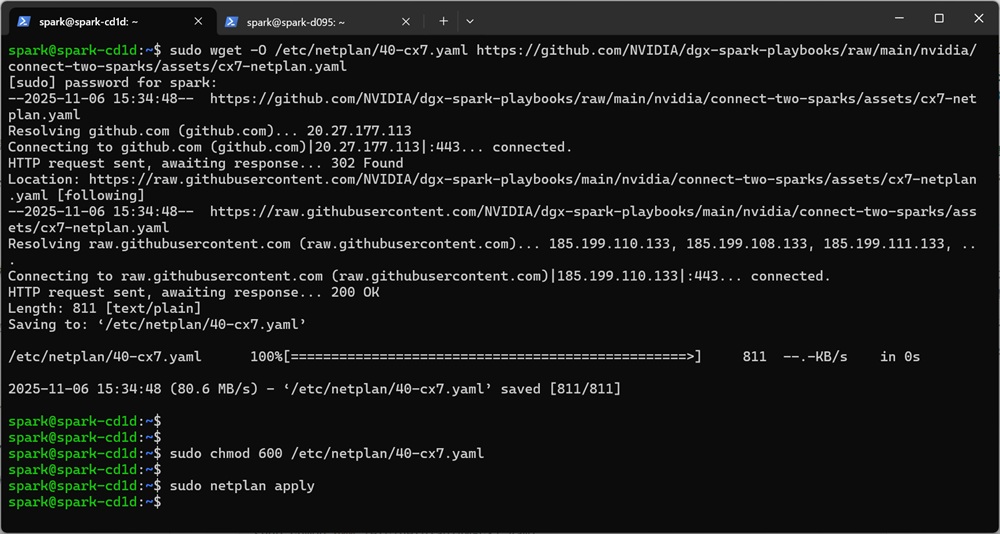
DGX Spark Discovery Scriptの実行
続いて、各Sparkへパスワード不要のSSH認証とノード識別の設定を行います。
本設定のためにNVIDIA社がDiscovery Scriptというスクリプトを提供しているため、そちらをダウンロードし実行します。
※Discovery Scriptもそれぞれのホストで実行が必要です。
①Discovery scriptのダウンロード
②スクリプトへ実行権限を付与
③スクリプトの実行
以下は上記手順を実際に実行した際の様子となります。
ここまでの設定にて2台のSparkはノードの識別が出来るようになりました。
NCCLセットアップ手順
続いて、2台のSpark間で高速なGPU間通信を実現するために必要なNCCLと呼ばれる通信ライブラリを入手します。
■NCCLとは
NVIDIA Collective Communication Libraryの略称であり、ニッケルもしくはエヌシーシエルと読みます。
ディープラーニングなどの分散学習では、GPU間でデータをやり取りする際に、All-Reduce・Scatter・Gatherなどの「コレクティブ通信」と呼ばれるさまざまな通信が発生します。
NCCLは、これらの通信方式やNVLink、InfiniBand、EthernetといったGPU接続トポロジーを自動的に判別し、ユーザーへ意識させることなく高効率な通信を実現します。さらに、NCCLはGPUDirect RDMAに対応しており、これを利用することで、従来のCPU経由の通信と比較して、より低レイテンシかつ高スループットな通信を可能にします。
通信経路のイメージ:
【アプリケーション層】
CUDA / PyTorch / TensorFlow etc...
↓ ↑
【通信ライブラリ層】
NCCL(通信制御・集約演算)
↓ ↑
【データ転送層】
GPUDirect RDMA(GPUメモリ直接通信)
↓ ↑
【ネットワーク層】
RoCEv2(Ethernet上のRDMA通信)
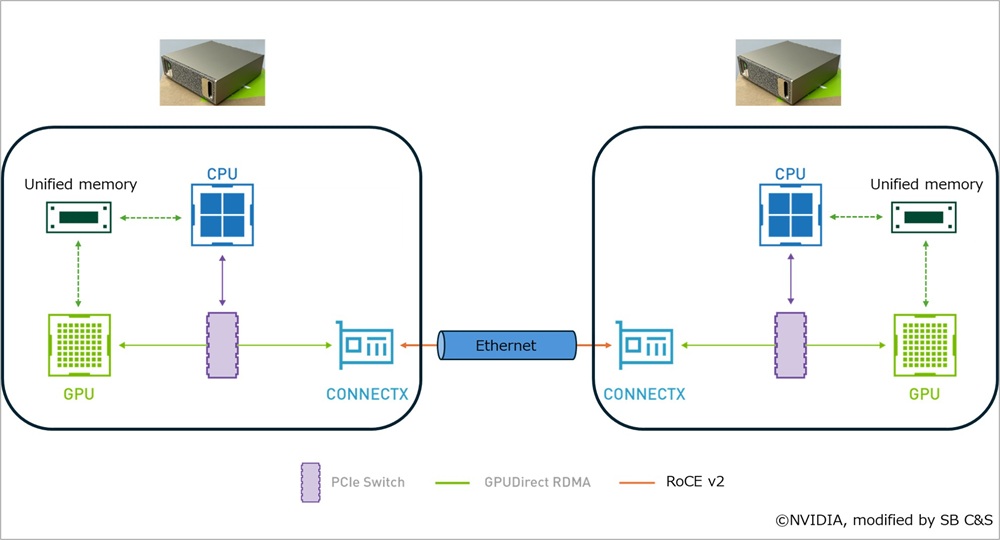
画像引用元:NVIDIA GPUDirect
NCCLの構築
NCCLを利用するための準備を進めていきます。
このステップも双方のSparkで実行してください。
まず、BlackwellアーキテクチャをサポートするソースからNCCLをビルドします。
なお、ビルドにあたり一部依存関係のインストールも実施しています。
sudo apt-get update && sudo apt-get install -y libopenmpi-dev
git clone -b v2.28.3-1 https://github.com/NVIDIA/nccl.git ~/nccl/
cd ~/nccl/
make -j src.build NVCC_GENCODE="-gencode=arch=compute_121,code=sm_121"
続いて、必要なパラメータを環境変数に格納しておきます。
この環境変数は実際にNCCLを利用する際に用います。
export CUDA_HOME="/usr/local/cuda"
export MPI_HOME="/usr/lib/aarch64-linux-gnu/openmpi"
export NCCL_HOME="$HOME/nccl/build/"
export LD_LIBRARY_PATH="$NCCL_HOME/lib:$CUDA_HOME/lib64/:$MPI_HOME/lib:$LD_LIBRARY_PATH"
NCCLテスト手順
それではNCCLの準備ができましたので、NCCLの動作確認を行います。
NVIDIA社のリポジトリにてテスト用ツールが提供されているため、そちらを利用します。
https://github.com/NVIDIA/nccl-tests
なお、本手順も双方のSparkで実施してください。
①NCCLテストスイートの構築
git clone https://github.com/NVIDIA/nccl-tests.git ~/nccl-tests/
cd ~/nccl-tests/
make MPI=1
②有効なNW I/FとIPアドレスの特定
NCCLのテストに用いる有効なI/FとIPアドレスを確認します。
ibdev2netdev
ip -brief link show
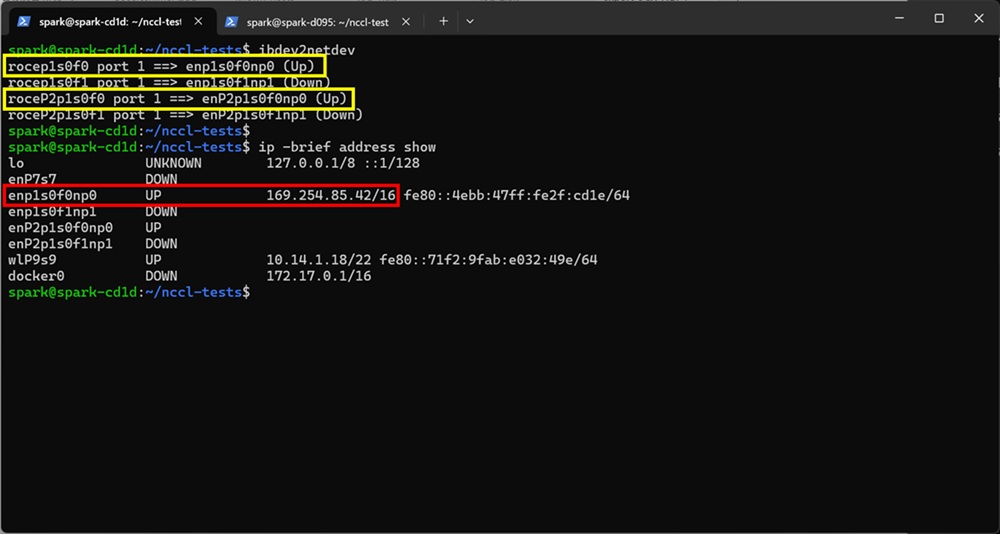
以下画像の実行例ではibdev2netdevの実行結果から、黄枠内のenp1s0f0np0とenP2p1s0f0np0がUPしていることが確認できます。続いてipコマンドを実行すると、enp1s0f0np0にのみアドレスがアサインされていることがわかりました。
これらの点から、テストではenp1s0f0np0を用いることとします。
③NCCLテストの実行
テストを実行するには、両ノードで以下のコマンドを実行します。IPアドレスとインターフェース名は、前の手順で確認したものに置き換えてください。
export UCX_NET_DEVICES=<interface name>
export NCCL_SOCKET_IFNAME=<interface name>
export OMPI_MCA_btl_tcp_if_include=<interface name>
# 2台のSparkにまたがるall_gatherパフォーマンステストの実行 (コマンド例のIPアドレスは前のステップで確認したものを用いる)
mpirun -np 2 -H <自NodeのIPアドレス>:1,<対向NodeのIPアドレス>:1 \
--mca plm_rsh_agent "ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" \
-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH \
$HOME/nccl-tests/build/all_gather_perf
このテストを私たちの環境で実行した場合次のような結果が得られました。
Node1: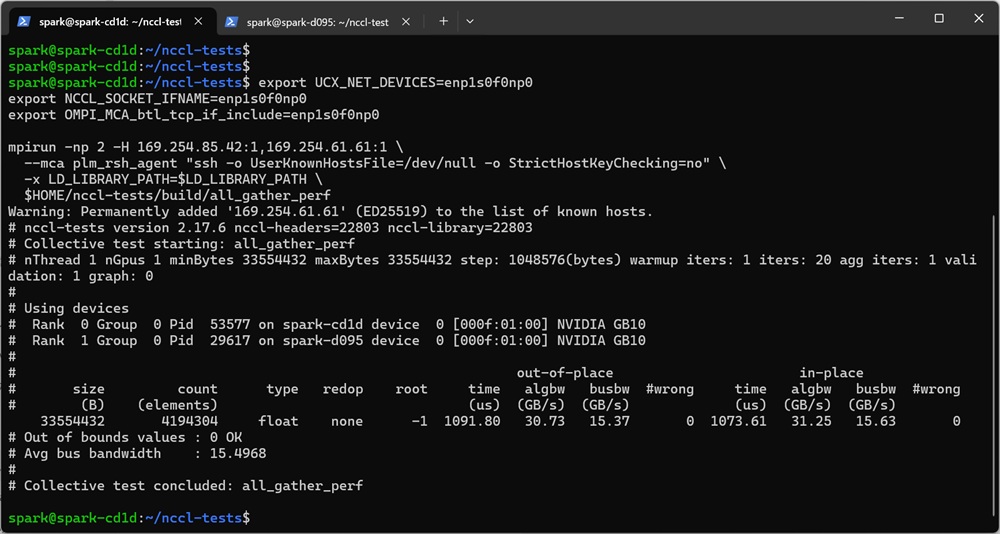
Node2: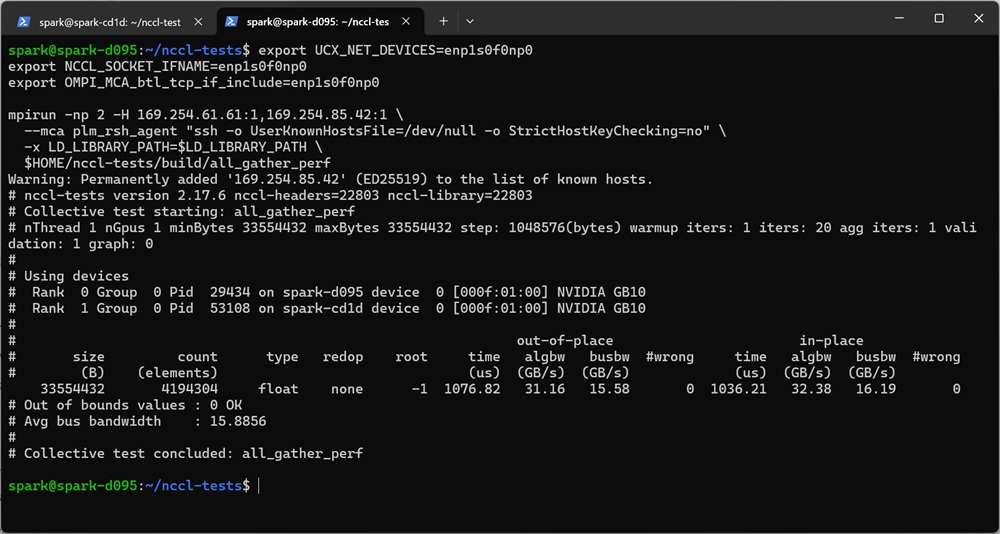 出力結果より、今回のテストでは片方向あたり15.4〜15.8GB/sの通信速度が確認されました。この値は約126Gbit/sに換算され、ConnectX-7として十分に高い性能が発揮されています。
出力結果より、今回のテストでは片方向あたり15.4〜15.8GB/sの通信速度が確認されました。この値は約126Gbit/sに換算され、ConnectX-7として十分に高い性能が発揮されています。
まとめ
この連載では、公式ドキュメントをもとに、2台の Spark をスタック構成で接続し、実際に GPU 間通信のテストを行う手順をご紹介しました。これらの手順を通じて、2台の Spark は互いに連携し、分散学習における GPU 間通信を高速に処理できるようになります。
次回以降の連載では、2台のノードにまたがってアプリケーションを実行する実践的な検証を進めていく予定です。ぜひ今後の掲載を楽しみにお待ちください。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。