


皆様こんにちは。SB C&Sの下山です。
前回のNVIDIA DGX Spark™関連記事の掲載から4か月も空いてしまいましたが、その間はDGX Sparkのプロモーション施策に注力しており、このたびようやく次のブログに着手できました。
今回は、DGX Spark向けのハンズオンコンテンツ整備の過程で触れる機会があったNVFP4量子化を題材に、前後編に分けてNVIDIA NVFP4フォーマットの概要をできる限り噛み砕いてご説明しつつ、手順のハマりどころなどを共有させていただこうと思います。
なお、本記事の内容は、以下の NVIDIA 公式ドキュメント、その他公開情報を参考に作成しました。
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
OCP「Microscaling Formats(MX) Specification v1.0(2023/9)」(PDF)
そもそも浮動小数点(FP)って?
基本的な定義になりますが、ここで改めて「浮動小数点とは何か」を整理しておきます。
浮動小数点とは、小数点を含む数(実数)をコンピュータで扱うために、有限桁の数として表現する形式です。0.1、0.01、0.001...のように実数は無限に存在するため、コンピュータ上ではメモリ容量の制約から、すべてを厳密に表すことはできません。そのため、実数の多くはデータ型(たとえばdoubleなど)で表現可能な離散的な値に「近い値」へと丸められ、近似値として保持されます(範囲外の場合はオーバーフロー等の扱いになります)。
基本的に、浮動小数点は符号部・指数部・仮数部で表され、指数部や仮数部などの各フィールドは固定長です。

AIやLLMの文脈で登場するFPとその代表例
AI分野で頻出するニューラルネットワークの「学習」とは、正解に近づくように「重み(w、パラメータ)」を少しずつ調整していく作業です。重みの更新は一般に「w ← w − 学習率 × 勾配」と表されますが、学習率や勾配は0.0000nのような非常に小さな値になることがほとんどです。もし整数しか扱えないとすると、こうした重要な値を適切に表現・計算できず、学習というプロセス自体が成立しません。
また、現実世界で取得できるデータは0/5/10/20のような離散値ではなく、連続値である場合が大半です。これらをコンピュータで扱いやすくするために正規化を行いますが、その過程でも小数点を扱う必要が生じる場面が多くあります。
学習目的では過去に、単精度浮動小数点(FP32)が主に用いられてきました。ところが、2017年にTensorコアを備えたNVIDIA Voltaのアーキテクチャが登場して以降、半精度浮動小数点(FP16)とFP32を組み合わせて計算する「混合精度」※1が利用可能になりました。(FP16や後述するBF16、FP8はFP32より精度が低い一方で計算負荷が小さく、モデルの重みなどが占めるメモリ容量も相対的に抑えられます。)
さらに2018年には、Googleの研究チームがBF16(bfloat16)という新たな浮動小数点フォーマットを発表しました。BF16は、FP16よりも指数部のビット数を多く確保する設計です。そのため仮数部が少ないぶん細かな値の精度は低下しますが、代わりにFP32と同等のダイナミックレンジ(表現可能な値の幅)を確保できます。BF16はもともと、Googleが開発を主導するTPUのエコシステムでの採用が多い印象でしたが、近年では利用範囲がより広がっています。たとえばgpt-oss:120Bは、もともとBF16精度でトレーニングされたモデルが、MXFP4(詳細は後述)へ量子化されたうえで配布されています。
さらに2020年頃からは、AMP(torch.cuda.amp)など、機械学習フレームワーク側の対応も進み混合精度をより手軽に導入できるようになりました。その結果として、2022年登場のFP8をはじめとした、より低精度で軽量なデータ型の採用が進んできています。
AIの文脈での大まかなまとめ:
- FP32: 精度に優れるが超重量級
- FP16: 軽量だが、実使用範囲の数値レンジにやや制約あり
- BF16: 学習など、実使用範囲の数値レンジを重視
- FP8: さらに軽量であるものの、精度が低く適用部分を選ぶ
そもそもNVFP4とは?
NVFP4とは、NVIDIA Blackwellアーキテクチャから新規にサポートされた浮動小数点フォーマットです。
従来、LLMを利用する際には、メモリ帯域やメモリ容量そのものへの要求が大きくなりがちである点が、しばしば課題として挙げられてきました。こうした課題に対応するため、モデルの重みが持つ情報をより低ビットのデータ型で保持し、「メモリ使用量の削減」と「データ転送の高速化」を両立させる取り組みが継続的に行われてきました。その結果として、現在ではFP4系のフォーマットが考案され、実際に利用されるようになりつつある、という背景があります。(なお、なぜLLMがmemory-boundになりやすいのかという背景については、別の機会に記事としてご説明したいと考えております。本記事では、LLMの動作においてmemory-boundな状況が発生し得るものとしてお読みいただければ問題ありません。)
ところが、FP4は当然ながら4bitのデータしか保持できない為、より多bitなデータ型と比較して、次のような問題があります。
- 表現できる値の種類が少ない(丸め誤差が増える)
- ダイナミックレンジが狭い(飽和・アンダーフローしやすい)
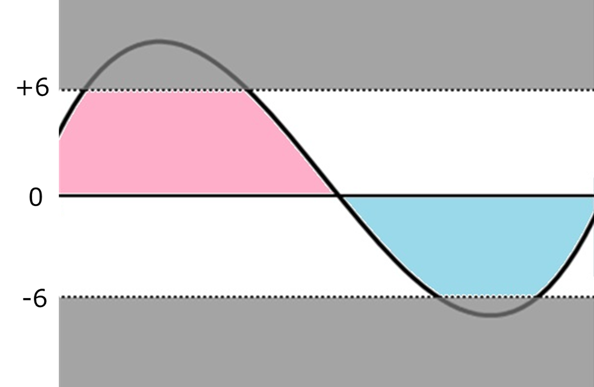
- テンソル内で値のスケール差が大きいと一気に破綻しやすい
FP4は表現可能な値のレンジが非常に狭く(-6、-4、0、+4など)、連続的な値は最も近い表現可能な値へと丸められてしまいます。その結果、たとえば本来-8.0であった値が-6.0に量子化される場合、誤差は25%にもなります。
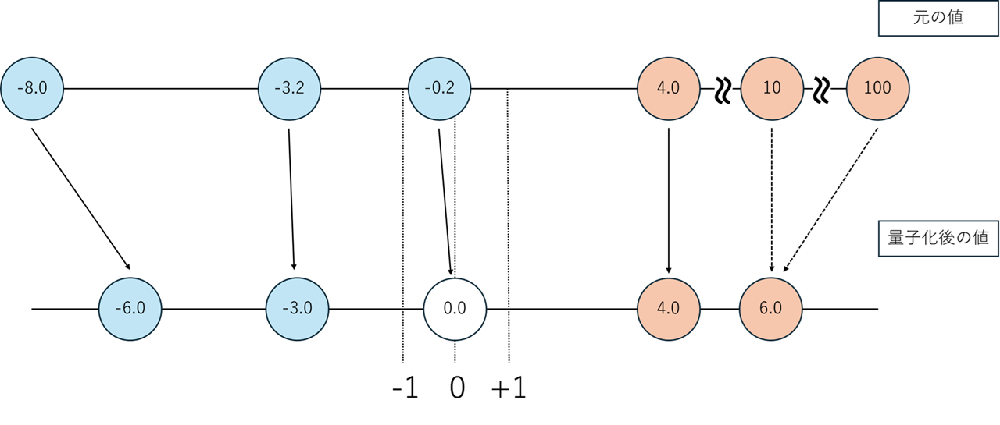
さらに、「表現できる値のレンジが狭い」ことは、すなわちダイナミックレンジが狭いことを意味します。このため、小さな値を高精度に表現しようとすると大きな値が表現できなくなり、逆に大きな値までをカバーしようとすると小さな値が0に近づいて判別できなくなる、といった現象が生じるのです。これらは互いにトレードオフの関係にあり、同時に両立させることはできません。
そこでNVIDIAはBlackwell世代において、FP4のまま精度を補う仕組みとしてNVFP4を導入しました。NVFP4では、数値そのものは粗い4ビット表現のまま維持しつつ、「どの程度の大きさの値が並んでいるか」を示す目盛り、つまりスケール情報を別途持たせます。
具体的には、16個の値を1つのまとまりとして扱い、そのブロックごとにより細かいFP8のスケールを掛けます。さらに、テンソル全体に対してFP32のスケールを掛けることで、全体のバランスを整えます。
ポイントは「4ビット値そのものを高精度化する」のではなく、スケーリング(尺度合わせ)を2段構えにすることで量子化誤差を抑える、という設計に振り切っている点です。この2段構えのスケーリングにより、4ビットという厳しい制約の中でも、実用的な精度を保てるようにしているのです。
この仕組みにより、FP16やFP8と見ると格段に少ないメモリでモデルを扱えるようになります。ただし、NVFP4だけですべての計算を完結させるわけではありません。たとえば行列積のように計算量が大きく、値が大量にやり取りされる部分はNVFP4で処理しつつ、数値に敏感な層や最終的な出力付近は、あえてより高精度な形式を用いる――といった"使い分け"が前提になります。
総括すると、NVFP4は「精度を一定程度割り切る代わりに、メモリ効率と処理速度を大きく得るための仕組み」であり、混合精度と組み合わせてこそ本領を発揮する技術です。
■ここで言う「スケールを掛ける」とは?
大まかに言えば、「スケールを掛ける」とは、量子化後の値に係数を掛け合わせることで、本来の値を復元することを指します。
例えば「5.0 / -40 / 10 / 20」という値の並びがあるとします。ここで、あらかじめスケールとして10を定めて量子化すると、各値は「0.5 / -4.0 / 1.0 / 2.0」に変換されます。量子化後の値に対して再びスケール10を掛ければ、4ビットで保持したデータからでも「5.0 / -40 / 10 / 20」という元の値を(少なくともスケールの観点では)復元できる、という考え方です。
実際のNVFP4では、このスケーリングを2段階で行います。まずテンソル全体に対してFP32スケールを適用し、値をFP4で扱いやすい範囲に正規化します。続いて、16要素(または16個単位のブロック)ごとにFP8スケールを適用することで、より細かな補正を加えます。
Figure 2. NVFP4 two-level scaling per-block and per-tensor precision structure - Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
- 値の保存時
本来の値 ÷(テンソルスケール×ブロックスケール)
- 値の復元時
FP4値 × ブロックスケール × テンソルスケール
MXFP4とNVFP4の関係
NVFP4と同じく4ビットのFP4フォーマットとして、MXFP4があります。詳しい経緯は割愛しますが、MXFP4は、AMD、Arm、Intel、Meta、Microsoft、NVIDIA、Qualcommの7社で構成される業界団体「MX Alliance」が2023年後半に策定したFP4フォーマットです。特定ベンダーの独自技術に依存せず、相互運用性を重視して標準化された点が特徴です。
すでにさまざまな活用例が見られますが、身近な例としてはgpt-ossでの採用が挙げられます。gpt-oss:120Bでは、モデルカード上でTensor typeがBF16とありますが、MoE weightsにMXFP4量子化(post-training)が適用された形で提供されています。
NVFP4とMXFP4はいずれもE2M1のFP4フォーマットである点は共通していますが、仕様には次のような違いがあります。:
- スケーリング対象がMXFP4では32要素単位(NVFP4は16要素単位)
- スケールがE8M0の1段階
NVIDIAの説明によると、必要な計算量はMXFP4のほうが少なくなる一方で、32要素単位のブロックで行列を扱うMXFP4では、FP8(E4M3)とFP32の2段階でスケーリングを行うNVFP4に比べて、ブロック単位の量子化誤差が大きくなり得るとされています。
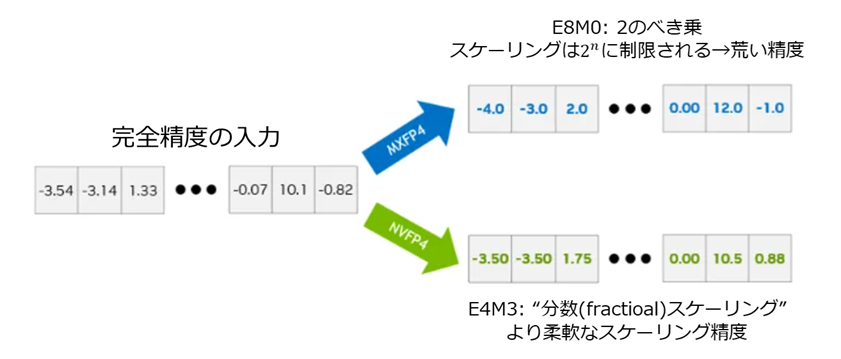
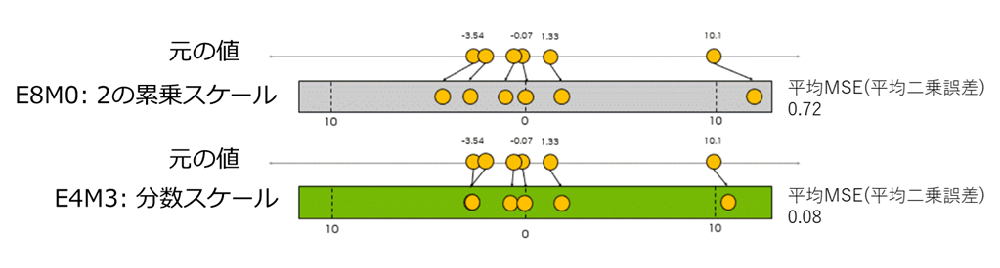
Figure 3. Comparison of quantization precision highlighting power-of-two versus fractional scaling (second-level FP32 scaling omitted for simplicity), Figure 4. Comparison of quantization error when encoding scaling factors with E8M0 versus E4M3 (second-level FP32 scaling omitted for simplicity)
- Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
まとめ
本前編では、NVFP4の技術的な概要を中心にご紹介しました。後編では、Playbookの手順を実際にたどりながら、途中で遭遇した問題とそのトラブルシューティング手順についてもあわせてご紹介します。
それでは、後編でまたお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。




