こんにちは。SB C&S の村上です。
今年もNVIDIAの年次イベントであるNVIDIA GTCに現地参加しております。
NVIDIA GTCは、NVIDIAが主催する世界最大級のAI・HPC分野のカンファレンスです。GPUやAIインフラといった基盤技術だけでなく、生成AI、エージェントAI、フィジカルAI、ロボティクス、自動運転、クラウドなど、幅広い領域での最新技術や活用事例が一堂に会します。中でも1000近くにわたるセッションの数々や各企業の展示ブースはとても見応えがあります。
2026年のGTCは、米国日時で3月16日から19日まで、米国カリフォルニア州サンノゼで開催されています。
街の風景もGTC一色になっており、見渡す限り"GTC"の文字が並んでおり、近隣の商業施設にはAIのJensen Huang氏と会話できる展示も設置されておりました。

基調講演 (Keynote Session) は3月16日に行われ、NVIDIA CEOのJensen Huang氏が、AI、コンピューティング、ロボティクスの次世代像について発表する構成となっています。 講演当日は朝早くから長い行列ができており、開場後まもなく会場の座席はほぼ埋まっていました。

ここからはKeynote Sessionで語られた内容のうち、特に印象的だったポイントを整理してご紹介します。
★Keynote SessionのLive録画はYouTubeで公開されており、誰でも視聴することが可能ですのでぜひご視聴ください。なお本記事のこれ以降の画像は、特に記載が無い限りこの動画の画面キャプチャをお借りしたものです。
振り返りと全体像
まず今年は、CUDA® 20周年 というNVIDIAにとって大きな節目の年でした。基調講演の冒頭では、現在のNVIDIAの強みはGPUそのものだけで成り立っているのではなく、GPUを汎用的な計算資源として活用するための土台であるCUDAを開発し、それを長年にわたって育ててきたことにあると語られていました。CUDAとともに成長してきたことで、多くの開発者やパートナー、そして幅広いエコシステムから支持を集め、現在のNVIDIAが築かれてきたことが改めて強調されていたのが印象的でした。
実際、現在ではGPUを活用する多くのライブラリやアプリケーションがCUDAをベースに開発されており、AIやシミュレーション、データ分析など多くの分野でCUDAが前提になることが多いです。そうした状況を見ると、NVIDIAの進化がGPUの進化だけではなく、CUDAを中心としたソフトウェア基盤とともにあったとあらためて実感しました。
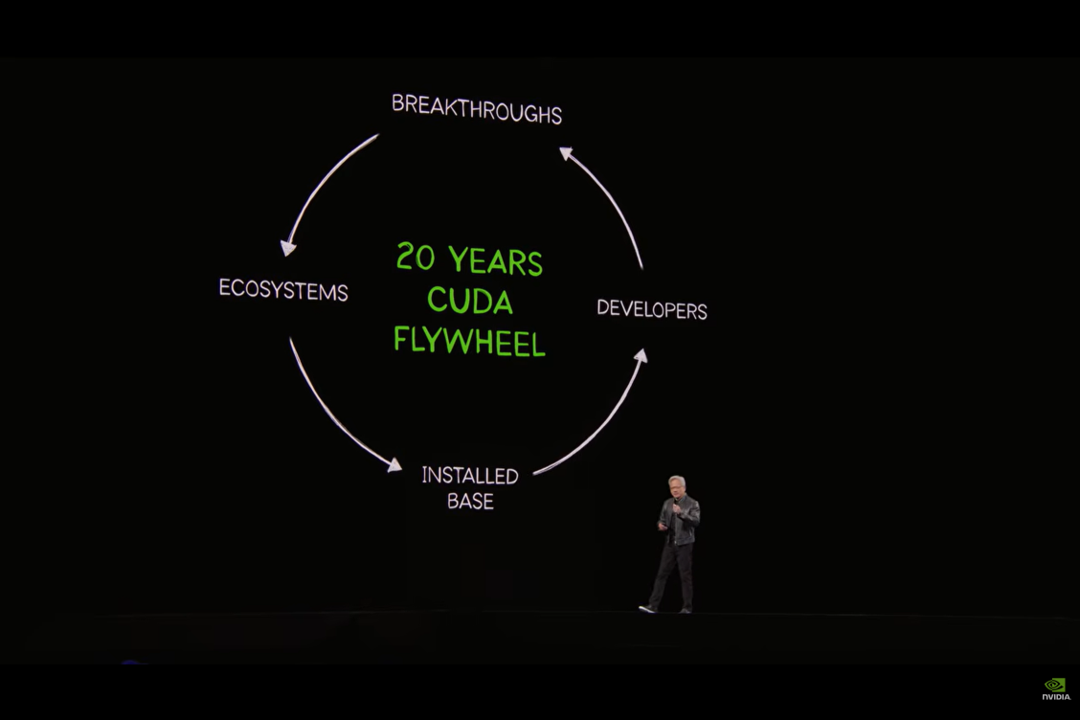
そのうえで今回の基調講演は、こうした20年の積み重ねを振り返るだけでなく、その基盤の上に次のAI時代をどう築いていくのかを示す内容になっていました。生成AIの普及に伴いAI活用が広がるなかNVIDIAが見据えているのは、単なるモデル実行基盤ではなく、推論、エージェントAI、フィジカルAI、ロボティクスまでを含めた、より広い産業基盤としてのコンピューティングです。
本記事では基調講演で発表された中でも特に以下のトピックを中心に整理していきます。
- NVIDIA Groq 3 LPXの追加で、推論アーキテクチャがさらに拡張
- Feynmanが示す、次のAIコンピューティング基盤
- Open Modelの拡大
- AIエージェントの急先鋒OpenClawと、安全性強化のNemoClaw
- DSXでAI Factoryをデジタルツイン上に再現
- Space Computingへの取り組み
- フィジカルAI (自動運転・ロボティクス)
NVIDIA Groq 3 LPXの追加で、推論アーキテクチャがさらに拡張
今回の基調講演の中でも特に私が興味を惹かれたのが、Groq 3 LPX の追加により複数種類のプロセッサを組み合わせる推論アーキテクチャという考え方が出てきた点です。
これまでNVIDIAは大規模モデルの学習と推論の両方を高効率に処理できるプラットフォームを構築してきました。それらを支える重要な要素として高スペックなGPUがあり、より高レベルな推論も実現できるよう日々GPUは進化をし続けていました。
一方でGroq 3 LPXが加わることで、全ての推論処理をGPUに集約するのではなく、処理に応じて最適なプロセッサへ引き渡すことが語られていました。
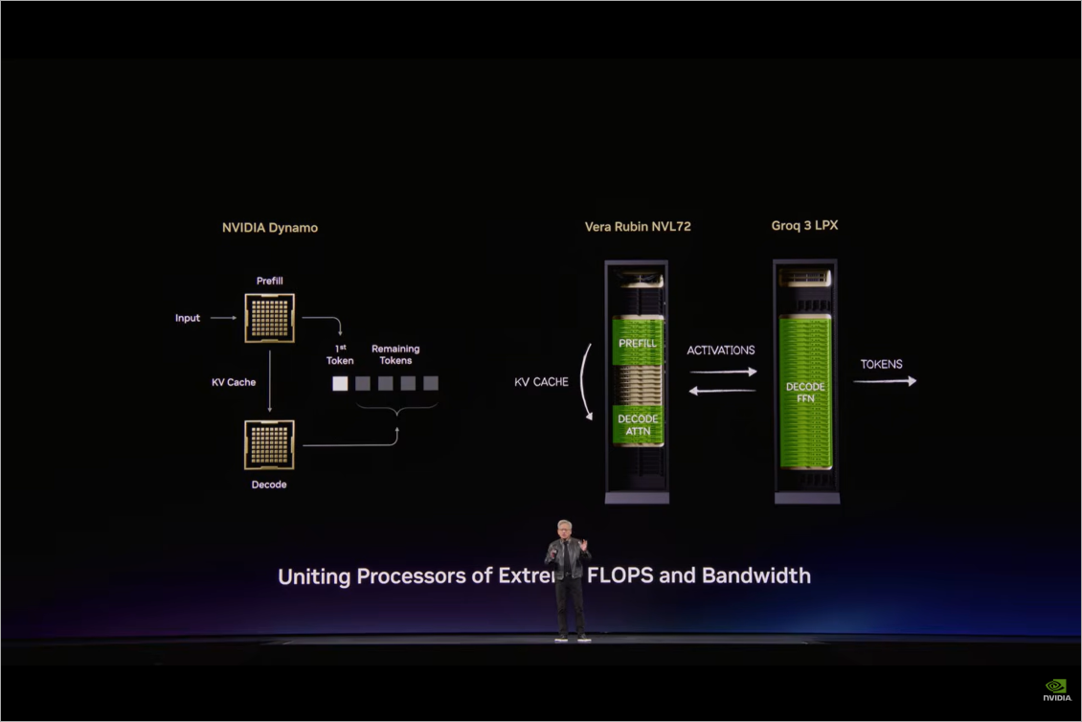
まず推論の処理では一般的にPrefill → KV Cache → Decode(Token生成)の流れで処理が行われます。
初めにユーザーから送られてきたプロンプト全体を読み込んで文脈理解などの初期計算を行うPrefillが行われ、その結果としてKV Cacheが構築されます。そして、実際に回答を生成(Token)していくDecodeの処理が行われます。
このDecodeに関しては更に分解するとAttentionとFFN(Feed Forward Network)の2つの処理があります。Attentionは簡単に言うと、長文生成の際などで少しずつTokenが生成される際に、次の回答生成に必要な情報をKV Cacheから洗い出します。FFNはAttentionの処理によって取り出された情報をもとに大量の変換処理を行いTokenを生成しています。
従来のアーキテクチャではこれらを全てGPUで実施していましたが、このうちの最後のDecode のFFNの処理を、特化したGroqのLPU(Language Processing Unit)であるGroq 3 LPXで実施することで最適化するといったものでした。
実際にセッション内で表示されていた資料でもNVIDIA Vera Rubin NVL72側がPrefillやDecode時のAttentionを担い、Groq 3 LPX側がDecode FFNを担う という形で役割分担が表現されていました。
文脈理解やKV Cacheを活用する処理はRubin側で行い、その結果得られた中間表現をGroq側へ渡してFFNを実行し、Token生成を加速するイメージとなります。
なお、Groq 3 LPX自体については、NVIDIA Developer Blogでも早速情報が公開されており、補足としてあわせて確認できます。
https://developer.nvidia.com/blog/inside-nvidia-groq-3-lpx-the-low-latency-inference-accelerator-for-the-nvidia-vera-rubin-platform/
★番外編 - 次世代AI基盤NVIDIA Vera Rubinと新たな推論基盤の発表
Feynmanが示す、次のAIコンピューティング基盤
例年GTCでは注目どころとして次世代以降のアーキテクチャを含めたロードマップの紹介があり、今年も新しい世代としてFeynman世代について語られていました。
発表では、NVIDIA Blackwell、Vera Rubinに続く将来世代としてFeynmanが示されており、NVIDIAが引き続き複数年にわたりAI基盤を進化させていく方針が示されていました。また今回の説明では、Feynmanでは新しいGPUを搭載するだけでなく、LPUを搭載した構成にも触れられており、GPU単体の性能向上だけでなく、前述の用途に応じて異なるプロセッサを組み合わせる方向性が示されていた点が特徴です。

Open Modelの拡大
NVIDIAが提供するOpen Modelの拡大もトピックとして語られていました。これまでNVIDIAは言語AI向けのNemotron、世界モデルのNVIDIA Cosmos™、ロボティクス向けのNVIDIA Isaac™ GR00Tなど多岐にわたるモデルの開発・公開を行っています。
NVIDIAは単一の汎用モデルを中心に据えるだけではなく、領域ごとの要件に応じたモデルを整備する方向に着手しており、今後もOpen Modelの開発へ貢献を続けていくと示されていました。
実際にAIの進化のためにはハードウェアやソフトウェアの進化だけでなく、AIモデルの整備が必要となる中、その点もNVIDIAは積極的に取り組む姿勢を感じ取りました。
講演内ではNVIDIAが開発している最新のモデル群も紹介されていました。

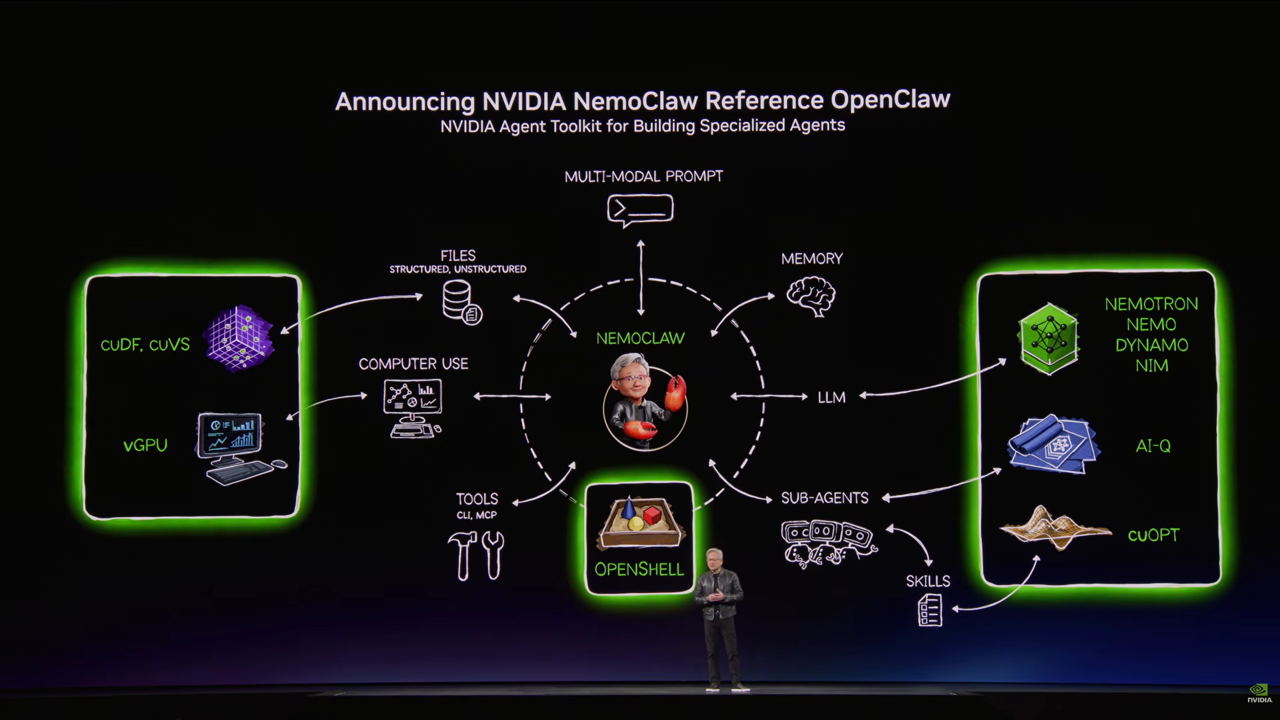
AIエージェントの急先鋒OpenClawと、安全性強化のNemoClaw
OpenClawを企業でより安全に活用するための仕組みとして、NemoClawも基調講演にて紹介されました。
まず OpenClaw は、2026年に大きな注目を集めたオープンソースのAIエージェント基盤です。ユーザーの手元のマシンや自分で管理する環境上で動作し、普段使っているチャットアプリからローカルマシン内のアプリや他ツールをAIをLLMを通じて操作できるのが特徴です。
例えば、受信メールの整理や送信、カレンダー管理、各種タスクの実行といったローカル環境で行う処理をチャット経由で指示することができます。
基調講演では、OpenClaw は「LLMをエージェントへ変えるための土台」として紹介されていました。
ただ受け答えをするだけではなく、ツールを操作し、継続的に処理を実行し、AIが実際に仕事を進めるための実行基盤として表現されていました。
特に今後の新しいエージェントの形として、単なるチャットボットではなく実際の作業環境に入り込んで仕事を進めるものとして紹介がされていたことが印象的です。
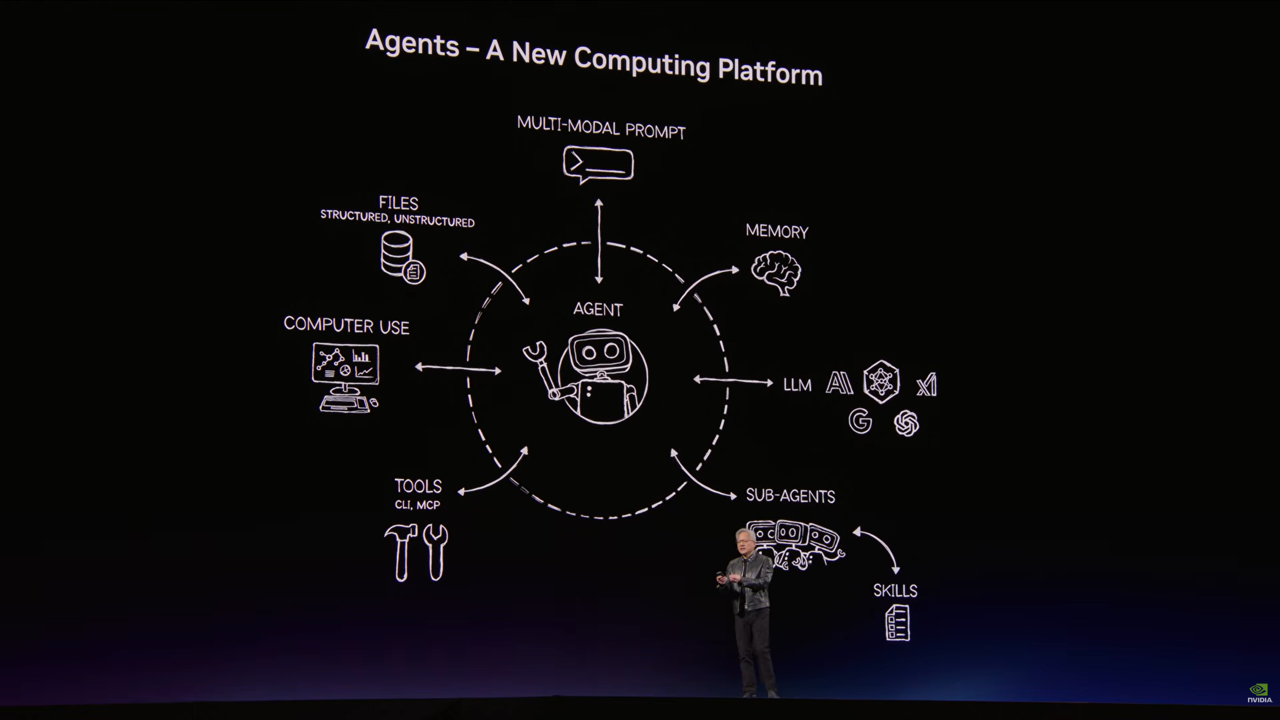
ただし、OpenClaw はあらゆるアプリやツールに触れて処理を行ってくれるというとても便利なものですが、そのままではリスクも伴います。
エージェントがメール、ファイル、各種サービスに広くアクセスできるということは、権限管理やデータ保護などが不十分な場合、情報漏えいや意図しない操作につながるおそれがあります。
そこで発表されたのが NemoClawでした。NemoClaw は、OpenClaw に対してプライバシーとセキュリティの制御を追加するためのオープンソースの仕組みです。OpenClaw の利便性を活かしながら、企業利用に必要な安全性や管理性を補う役割を担うものとして紹介されていました。
仕組みとしては、OpenClawをより制御しやすい実行環境の上で動かし、サンドボックス化された環境やガードレールを通じて、エージェントのアクセス範囲や動作を管理しやすくするものといったイメージのものと感じました。
まだNemoClawはearly preview段階ですが、今後開発が進み正式版がリリースされれば、OpenClaw のような自律型エージェントが企業の業務の中で本格的に活用される未来も近づいていると感じる内容でした。
★番外編 - NVIDIA NemoClawで、OpenClawをエンタープライズ仕様に
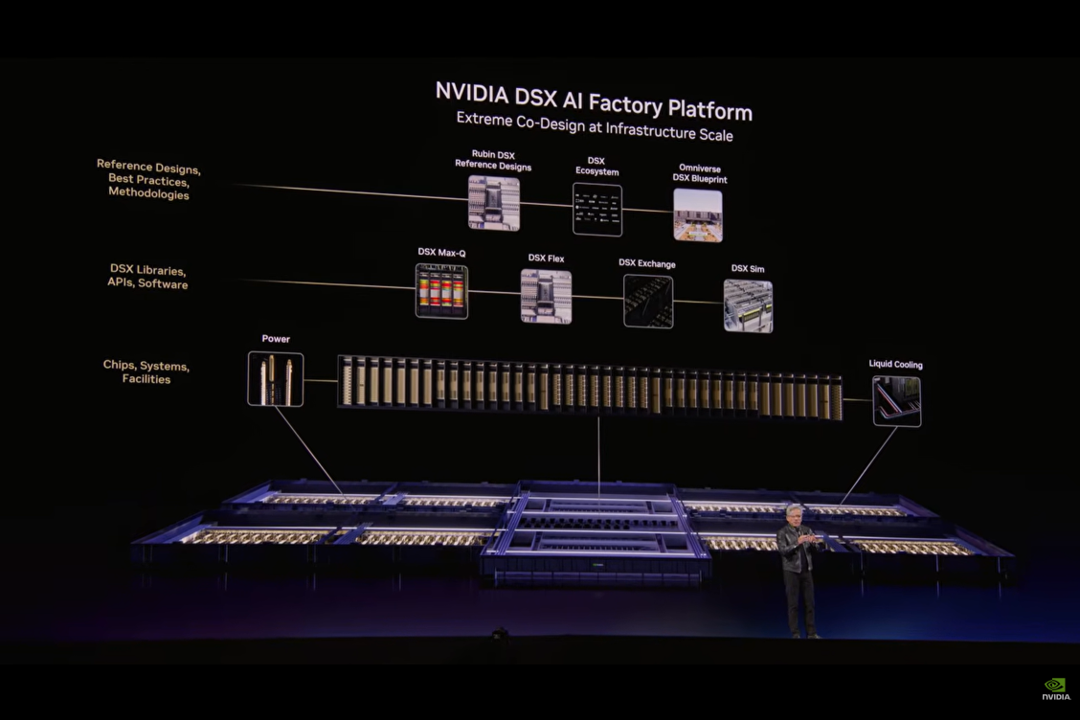
DSXでAI FactoryをOmniverse上に再現
今回の基調講演では、DSX もAI Factoryを支える要素として紹介されていました。位置づけとしては、AI Factoryを実際に構築する前に、NVIDIA Omniverse™上で設計・検証していくためのブループリントに近いものとして語られていたように見えます。
AI Factoryでは、計算資源だけでなく、電力、冷却、ネットワーク、設備配置まで含めた全体設計が重要になります。DSXは、そうした複雑な構成を実際に構築する前に、仮想空間上で計画し、構築、最適化をしていくための仕組みとして語られていました。
★番外編 - DSXでデジタルツインのAIファクトリーを設計・構築・シミュレート
Space Computingへの取り組み 宇宙データセンター実現への布石も
また、DSXの紹介に続き、宇宙空間におけるNVIDIAの取り組みについても、次の2点が簡潔に紹介されました。
・衛星搭載用途向けに、特別に放射線耐性を備えた NVIDIA IGX Thor™ の提供をすでに行っていること
・宇宙空間に構築するデータセンター向けのコンピューターとして NVIDIA Space-1 Vera Rubin Module を新たに開発中であること

空気や重力のない宇宙空間では、伝導や対流による冷却が利用できないため、放射による熱放散に頼らざるを得ません。そのため、この高度な技術課題に対し、エンジニアが精力的に取り組んでいることが語られていました。
また、本件に関連するプレスリリースからは、NVIDIA Jetson Orin™ も宇宙で利用可能なプラットフォームとして提供されることが確認できます。
フィジカルAI (自動運転・ロボティクス) の発表には、あの有名キャラクターのロボットが登場
デジタルの世界でのエージェントと同様に、物理世界で知覚し、推論し、行動するエージェントであるロボットにも、NVIDIAは長い間取り組んできた、とJensen Huang氏は語ります。

この文脈におけるロボットには、もちろん自動運転車も含まれており、まずはその関連のパートナーシップの拡大の発表です。
NVIDIAの自動運転タクシー対応プラットフォームの新たなパートナーとして、BYD、ヒュンダイ、日産、吉利汽車が加わることが明かされました。すでにメルセデス、トヨタ、GMと結んでいるこのパートナーシップの参加企業は、合計で年間1,800万台の車を製造しているとのことです。
そしてUberとの提携も発表されました。複数の都市で、これらの自動運転タクシー対応車両をUberのネットワークに展開し、接続する計画が語られました。
次にロボティクス分野でのパートナーシップについても触れられ、ABB Robotics, KUKAなどがロボットを製造ラインに展開できるよう、物理AIモデルをシミュレーションシステムに統合するためにNVIDIAと協力していることが示されました。壇上のスクリーンの左側にはCaterpillarが、そして右側には言及された2社のものと共に日本企業であるファナックの重機も並んでいます。
加えてT-Mobileとの協業においては、現在の無線電波塔が、NVIDIA Aerial™のAI-RANにおけるロボットや自動運転用の電波塔としても稼働する未来が示されました。NVIDIA Aerialは、交通状況の推論や、AIを用いたビームフォーミングなどを提供可能なプラットフォームです。
実際のロボットやシミュレーション空間の動画も放映され、ここではNVIDIA Alpamayoを用いた自動運転とそのシミュレーションや、製造・物流・医療といった様々な業界でのロボット活用への取り組みが紹介されました。動画の終盤にDisneyの "アナと雪の女王" に登場するキャラクターであるオラフのロボットがシミュレーター上で動作する様子が紹介され、そして動画が終わると...

なんとそのオラフのロボットが現実世界の壇上に。完全に自律して映画の中から飛び出してきたような動作をし、これまた映画そのもののコミカルな音声で、Jensen Huang氏の呼びかけに対して自然に応答します。
最後に、ヒューマノイドやJensen Huang氏のアバターが登場する動画が放映され、仮想空間でAIの進展やNVIDIAのテクノロジー、そして今回のGTCに関する歌と楽器の演奏を披露したあと、現実世界の舞台上に戻ってJensen Huang氏とオラフがKeynote Sessionの終幕を告げました。
まとめ
以上、GTC2026 Keynote Sessionのレポートでした。
今年も多くの発表内容があり、とても見応えのある内容だったのではないでしょうか。特に個人としてはGroq 3 LPXの登場により、今後の推論基盤がどのように変化していくかが楽しみです。
引き続き、弊社では最新情報をキャッチし随時発信していきますので、ぜひお楽しみにください。
なお、GTC 2026における個々の発表についての詳細は、NVIDIAのNewsroomにまとめられたページがございますので、あわせてご参照ください。
NVIDIAに関する他情報発信はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
村上 正弥 - Seiya.Murakami -
VMware vExpert