皆さまこんにちは。SB C&Sの下山です。
突然ですが、皆さまはこちらのアクセラレータをご存じでしょうか?
こちらは、Tenstorrent社のアクセラレータボード「P150a/b」です。P150は非常に興味深い特徴を備えた製品ですが、このたびご縁があり、Tenstorrent様から実機をお借りすることができました。
GPUの調達価格の上昇やリードタイムの長期化が懸念される昨今、本記事を含む全3回の連載を通じて、Tenstorrent社の概要、GPUの代替となりうる同社製品、そしてそれらの特色について紹介していきます。
Tenstorrent社とは(会社概要)
Tenstorrent社は2016年に設立されたファブレス企業であり、2026年6月現在は米国に本社機能を置き、北米・アジア・欧州に拠点を展開しています。また、Jim Keller氏が2020年末にTenstorrentへ参画し、CTOなどを経て2023年1月にCEOへ就任していることから、氏の関連ニュースなどで同社の名前を耳にしたことがある方もいらっしゃるかもしれません。
同社は後に詳しく触れるAI半導体の設計・販売を主軸として、強みとする半導体IPをベースとしたカスタムチップの設計受託などのビジネスを展開しています。
技術概要
同社の技術スタックは、「Tensixコア」を中核とするAIアクセラレータ、RISC-V、GDDR6、Ethernetを用いたメッシュ型のスケールアウトアーキテクチャ、そしてオープンソースのMLIR(Multi-Level Intermediate Representation)ベースのコンパイラや低レベルSDKで構成されていると捉えられます。以下では、これらの要素をハードウェアとソフトウェアの2つの側面に分けて見ていきます。
ハードウェアスタック
・Tensixコア

https://speakerdeck.com/tenstorrent_japan/tensix-core-akitekutiyajie-shuo?slide=7
Tensixコアは、1コア内に5つの小型RISC-Vコア、2つのNoCルータ、1.5MBのSRAM、そしてTensix Engineを備える構成になっています。
Tensix Engineは、Tile/Matrix Math Engine(FPU)とVector Math Engine(SFPU)と呼ばれる専用演算器で構成されています。Tile/Matrix Math Engine(FPU)は、低精度の行列・タイル演算を高スループットで実行する行列演算器です。一方、Vector Math Engine(SFPU)は、活性化関数の適用を含むAttention機構の処理、細粒度のベクトル演算を得意としています。
ここまでを整理すると、高負荷な線形演算や行列計算をFPUが担い、活性化関数や細かな後処理をSFPUが担当し、さらにFPUとSFPUの制御やデータフロー全体の管理をRISC-Vコアが担う、という構造になっている点がTensixコアの特徴です。
AIワークロードでは、演算そのものよりもデータの読み書きや転送がボトルネックとなり、アクセラレータ内の演算器を十分に使い切れないことがあります。Tensixではこの課題に対し、データをタイル単位で扱い、各コアのすぐそばに置かれているL1メモリ、すなわちローカルSRAM上に配置して処理します。これにより、レイテンシの大きいチップ外GDDR6へのアクセスを抑えつつ、必要なデータをNoC(Network on Chip)経由でコア間、またはDRAMコントローラを介してチップ外GDDR6との間で転送できる構造になっています。
また、GPUアーキテクチャでは、キャッシュの階層化や多数のスレッド切り替えによって、レイテンシの隠蔽が積極的に行われます。これに対し、Tensixの大きな特徴は、SRAMをプログラム側で明示的に管理する点にあります。具体的には、データをいつローカルSRAMへ読み込み、いつ別のメモリ階層へ書き戻すかを、開発者が意識して制御できます。
性能を追求する場合、従来のGPGPUプログラミング以上に明示的なデータ管理が求められることになりますが、その一方でキャッシュミスやキャッシュ置換の影響を受けにくく、メモリアクセスの挙動を予測しやすい(≒レイテンシが予測可能となる)という利点があります。
また、コア同士を結ぶ通信経路であるNoCはトーラス状に構成されており、Tensixコア間、またはコアとDRAMの間でデータを効率よく移動できるよう設計されています。つまりTensixは、単に演算性能を高めるだけでなく、データを演算器の近くに配置し、NoCを通じて計画的に移動させることで、メモリアクセス待ちを抑えながらスループットを引き上げるアーキテクチャだといえます。
まとめると、多くのGPUがスレッド単位の大規模並列処理を得意とし、キャッシュやスケジューラなどのハードウェア機構によって一定程度の最適化を担うのに対し、TensixはAIコンピューティングの中核であるテンソルの移動と行列計算を高効率に実行するため、データと計算の流れをプログラム側から高度に制御できるよう設計されたアーキテクチャだと言えるでしょう。
設計ロードマップ
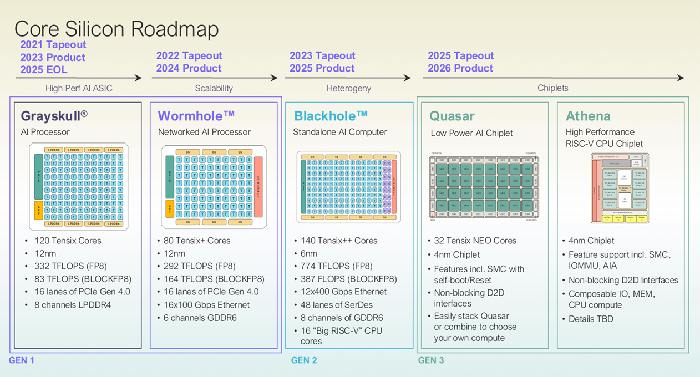
https://speakerdeck.com/tenstorrent_japan/tensix-core-akitekutiyajie-shuo?slide=2
これらのうち、現在商品展開されているのは第一世代後期のWormholeおよび第二世代のBlackholeです。
※ロードマップ画像内ではBlackholeの設計詳細が、初期設計時の「140コア / 774 TFLOPS」と記載されていますが、2026年初頭の仕様改定により「120コア / 664 TFLOPS」へと改められています。
・スケーラビリティの強化:Wormhole
先に存在していたGrayskullアーキテクチャをベースにしつつも、複数のチップを連携させるスケールアウト機能に特化した世代となっています。Ethernetコアをチップ内に取り込んでいるため、外部スイッチを介さずともチップ同士を直接接続することが可能となりました。
・ヘテロジニアス:Blackhole
DRAMコア(メモリバンクコントローラー)やRISC-V CPUコア、Tensixコアなどの異なる種類のコアを混載した構成であり、TenstorrentはBlackholeを「スタンドアロンなAIスーパーコンピュータ」と位置付けています。
FP8精度のピーク性能が664TFLOPSに達したほか、p150a/p150bに4基のQSFP-DD 800Gポートを搭載し、Galaxy Blackholeでは各ASICあたり10本の400GbEリンクを用いる構成が示されています。Tensixコアに加えて16個の"Big RISC-V"コアを統合している点も特徴です。
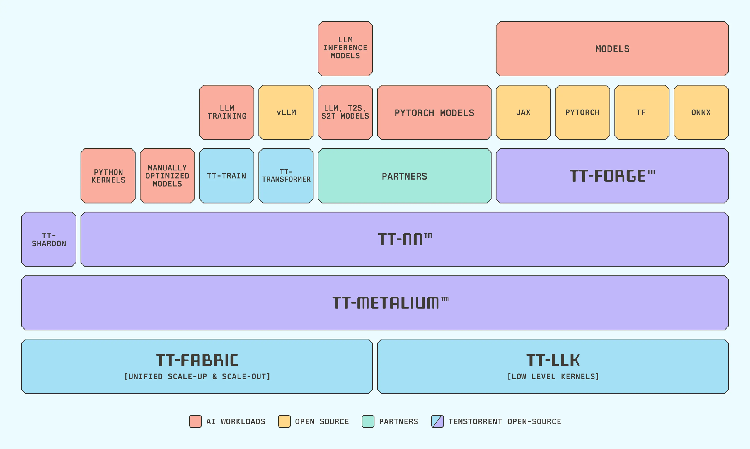
ソフトウェアスタック
Tenstorrent社およびTensixアーキテクチャを取り巻くソフトウェアスタックについては、後ほど詳しくご説明します。その前に、多くの方がまず気になるのは、次の点ではないでしょうか。
「既存のAIフレームワークを用いて開発された資産は、Tensix上で動作するのか?」
この点についても、後ほど取り上げたいと思います。
1.コンパイラ層(TT-FORGE)
スタックの上層部に位置するTT-Forgeは、TT-Torch、TT-XLA、TT-Forge-ONNXなどのフロントエンドとTT-MLIRで構成される、エンドツーエンドのコンパイラスタックです。この最上位層では、一般的なAIフレームワークで作成されたモデルをTenstorrentハードウェア向けに最適化し、コンパイルします。
TT-Torch、TT-XLA、TT-Forge-ONNXは、それぞれのフレームワークに対応したコンパイラフロントエンドであり、後段のTT-MLIRが処理しやすい形式にモデルを変換して引き渡します。TT- MLIR(Multi-Level Intermediate Representation)は、取り込んだモデルの構造を解析し、SRAMへの配置やマルチコアでの並列化などを考慮しながら、Tenstorrent ASICのアーキテクチャに適した実行形式へ自動的に変換します。
既存のPyTorchモデルを利用する場合や、一般的な推論サーバーのバックエンドとしてTensixボードを検討する場合には、十分に実現可能性があると考えられます。つまり、冒頭で触れた「既存の資産はTensix上で動作するのか」という問いに対する答えは、多くの場合で「はい」といえるでしょう。
一方で、CUDAやROCmと言った、各社のGPGPU向けソフトウェアスタックや計算ライブラリに対して高度に最適化されたカーネルをTensixシステム上に移植する場合には、より詳細な検討が必要です。また、以降で紹介する低レイヤー向けのAPIやツールを用いた最適化作業も必要になるでしょう。
2.オペレータ・ライブラリ層(TT-NN)
Tenstorrentのハードウェア上でニューラルネットワークを構成・実行するための演算子(オペレータ)・テンソルをまとめたライブラリです。TT-NNはPythonおよびC++へ向けて、PyTorchに似た操作感のAPIも提供します。また、TT-NNにはCCL(Collective Communication Library)という、マルチチップ構成におけるプロセッサ間の効率的な集合通信をサポートするライブラリが統合されています。
3.低レベル層(TT-Metalium)
スタックの最下層に位置し、全ソフトウェアの基盤となるSDKです。TT-MetaliumはTenstorrentハードウェアをC++で直接制御します。単にMETALと呼ばれる場合もありますが、TT-NNやコンパイラもこのTT-Metalium上で動作しています。
CUDAやROCmと異なる点は、ハードウェアによる自動化(暗黙のキャッシュやスレッドスケジューリング)に頼らず、SRAMやDRAM、NoCと呼ばれるチップ内ネットワークをプログラマが明示的かつ直接コントロールできることが特徴です。これにより、データの移動と計算を完全に分離して最適化することができます。
製品ライン
現在主に入手可能な製品には、主にWormholeとBlackholeが採用されており、PCIeカードもしくはカードが組み込まれたサーバーとして購入可能です。
※カード単位では、チップを単体で搭載する構成や複数搭載する構成など、いくつかのバリエーションが用意される場合があります。一方で、たとえばBlackhole 10やBlackhole 100のように、同世代アーキテクチャ内で性能の異なる製品バリアントを細かく展開する考え方は、基本的には採られていません。
つまり、性能向上を狙う場合は、より高性能な上位製品へ置き換えるのではなく、カードまたはチップを積み重ねていくことで、スケールアウトによる性能向上を目指す設計思想だといえます。
PCIeカード
・Blackhole p100/p150

Tensixコアを120個内包するBlackhole世代のTensixプロセッサを搭載し、28GB(p100)または32GB(p150)のGDDR6メモリを備えます。
p150では、設置環境に応じてアクティブ冷却モデルとパッシブ冷却モデルを選択できます。また、4基のQSFP-DD 800Gポートを搭載しており、複数のp150カードを接続することで、カード間でメモリをプールし、より大規模なモデルやワークロードへスケールさせることができます。
・Wormhole n150/n300

n150はWormholeプロセッサを1つ、n300は2つ搭載します。n150/n300の双方のモデルでアクティブ/パッシブ冷却を選択できます。ボードに搭載されたブリッジ用端子もしくは計二つのQSFP-DD 200Gポートを介して複数のWormholeボードをスタックできます。
Wormhole/Blackhole搭載サーバ
サーバ製品のラインナップとしては、主に次の2つがあります。
・Tenstorrent Galaxy



6Uサイズのエンクロージャーに、合計32基のWormhole/Blackholeプロセッサを搭載します。32基のチップは、それぞれ100GbE(Wormhole)または400GbE(Blackhole)のインターコネクトによりメッシュネットワークを構成し、外部ネットワークスイッチを介さずに相互通信できます。消費電力は8〜10kW程度となっています。
FP8精度におけるピーク性能は、Wormholeモデルが9.3PFLOPS、Blackholeモデルが23PFLOPSです。
・TT-QuietBox 2 (Blackhole)

オフィスやデスクサイドに設置して利用することを目的として開発されたワークステーションタイプの製品です。主要コンポーネントが液冷化されているため、動作音が非常に低く抑えられている点が特徴です。
計4基のBlackholeチップを搭載しGPT-OSS-120Bなどの大きな単一モデルを展開可能なほか、コンパクトな複数のモデルを並行して用いるといった使い方ができる製品です。
まとめ
今回は、Tenstorrent社の会社概要、技術スタック、主要な製品ラインについて紹介しました。Tenstorrent社のアクセラレータ(ASIC)は従来のGPUとは大きく趣の異なる製品ですが、意外にも使い始めるハードルはそれほど高くありません。
次回は、製品のセットアップを進めながら、簡単なテストを実行するまでの流れを実際に検証していきます。
それでは、また次回の記事でお会いしましょう。
Tenstorrent社公式ページ
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。