


Aristaブログの第2回となる今回はAristaのAIクラスタネットワークのプロダクトについての紹介となります。
本ブログは大きく2部構成でお届けします。
1.AIクラスタネットワークについて
2.AristaのAIクラスタネットワーク製品について
「1.」についてはAristaの話ではなくAIインフラのネットワークの全般的なお話となりますので、すでにご存じの方は読み飛ばしていただければと思います。
1.AIクラスタネットワークについて
1-1.AIインフラにおけるネットワークの位置づけ
企業が自社AI基盤を作る際にはサーバー側に搭載されるGPUが注目されがちですが、実際にはサーバー間を接続するネットワークも重要となってきます。
AIインフラにおけるネットワークは大きく以下の3つに分けられます。
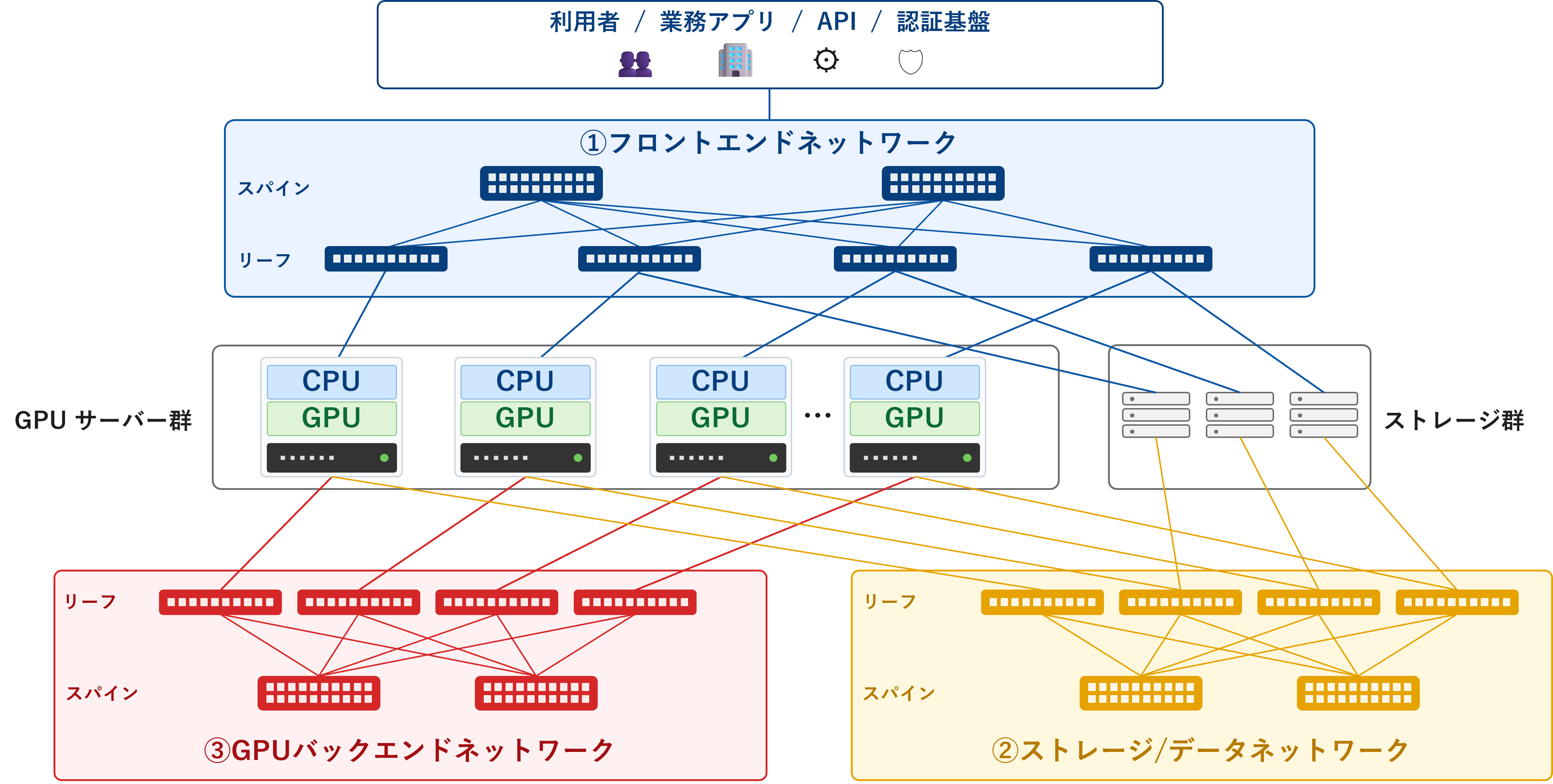
図1:AIインフラネットワーク
①フロントエンドネットワーク:利用者との接続
ユーザーやアプリがAIを使うための通り道となるネットワーク
②ストレージ/データネットワーク:データとの接続
AIが学習・推論・保存に使うデータ置き場へアクセスするためのネットワーク
③GPUバックエンドネットワーク:GPU同士の接続
複数GPUで学習や推論を高速に進めるためのネットワーク
①と②については従来のデータセンターネットワークに求められる要件と大きな違いはないのですが、③のGPUバックエンドネットワークではネットワークにも特殊な要件が求められます。
今回は③のGPUバックエンドネットワークを"AIクラスタネットワーク"と呼び、こちらに焦点を当てて進めていきます。
1-2.AIクラスタネットワークの重要性
ここではAIクラスタネットワークがなぜ重要なのかをお話しします。
・GPUを複数台で使うと、GPU間通信が発生する
大規模AIでは、1台のGPUだけで処理するのではなく、複数GPU、複数サーバーで処理を分散します。
このとき、GPU同士で計算結果や中間データを同期して平均化する必要があります。
・通信待ちが発生するとGPUが遊ぶ
AIクラスタネットワークでは、GPUが高速に計算してもネットワークが遅いとGPU間の同期が遅れて次の処理に進めません。
つまり、ネットワークがボトルネックになると、高価なGPUの稼働率が下がります。
上記よりAIクラスタネットワークはGPUの性能を引き出し、学習や推論の処理時間を短縮し、AI基盤全体のTCOを左右する重要な要素となります。
1-3.AIクラスタネットワークに求められる要件
従来のデータセンターネットワークではNorth-South、East-Westのトラフィックが混在する環境ですが、GPU間通信のAIクラスタネットワークではEast-Westトラフィックがメインとなります。
AIクラスタネットワークとして求められる要件には以下のようなものがみられます。
・高帯域
AIクラスタでは、GPU間で大量のデータをやり取りします。
そのため、スイッチ単体の高速インターフェースだけでなく、クラスタ全体としてどれだけ帯域を確保できるかが重要です。
・ロスレス性
パケットロスはモデルの精度や学習時間に影響を与えるため、いかにパケットロスを発生させないかが重要です。
・低遅延・低ジッター
分散学習や大規模推論では、一部の通信が遅れると全体が待たされることがあります。
・負荷分散
AIクラスタでは、特定のリンクや特定スパインにトラフィックが偏ると性能が落ちます。
従来のECMPだけで十分か、フロー単位の偏りをどう抑えるか、輻輳時にどう分散するかが重要です。
1-4.RDMAとは
前述のAIクラスタネットワークの要件の高帯域や低遅延への対応策としてRDMA(Remote Direct Memory Access)という技術があります。
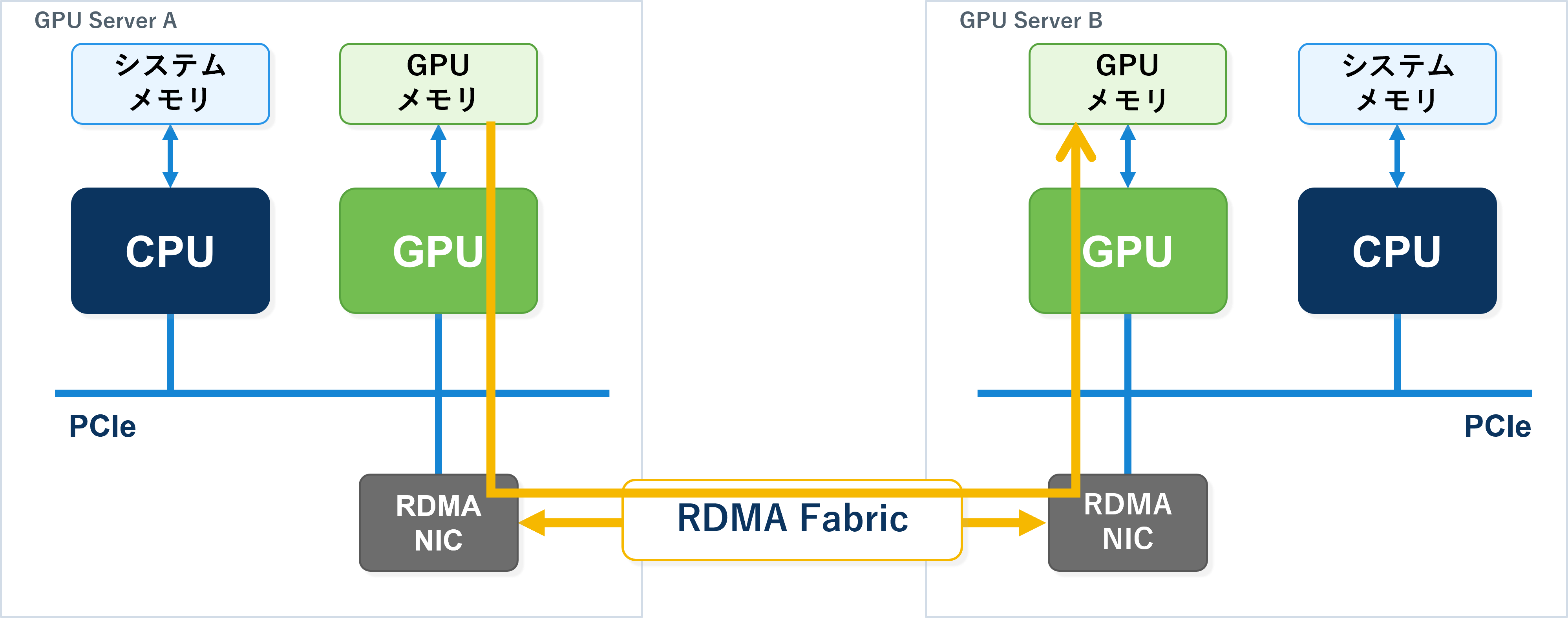
図2:RDMA
RDMAは、Remote Direct Memory Accessの略で、CPUやOSのネットワーク処理を大きく介さず、NIC主導でリモートメモリとのデータ転送を行う技術です。
RDMAでは、CPUやOSのネットワーク処理を極力介さずにNICがデータ転送を行うため、通信遅延を抑えつつ、高速かつCPU負荷の少ないデータ転送を実現できます。
1-5.AIクラスタネットワークの選択肢(InfiniBand vs Ethernet)
AIクラスタネットワークには大きく2つの方式があります。
InfiniBand
InfiniBandは、HPCやAI分野で利用される高性能インターコネクト規格で高帯域・低遅延を実現します。
前述のRDMAを標準で実装しています。
現在はNVIDIAの独占市場となっています。
Ethernet
ネットワークの標準技術であるEthernetを利用してAIクラスタネットワークを構成するアプローチです。
InfiniBandと比較して輻輳や遅延等が発生しやすいため対策が必要となり、対策としてRDMAをEthernet上で実現するRoCE(RDMA over Converged Ethernet)などがあります。
従来はInfiniBandが有力な候補でしたが、近年は、RoCEや輻輳制御、負荷分散、可視化機能の進化により、EthernetベースのAIネットワーキングも大規模AIクラスタの有力な選択肢となっています。
今回ご紹介するArista製品がAIクラスタネットワークの有力な選択肢となります(もちろんAristaはEthernetを用いたアプローチとなります)
AIクラスタネットワークは、GPUサーバーを単につなぐためのネットワークではありません。
分散学習や大規模推論において、GPUの性能を引き出し、AI基盤全体の効率を左右する重要なインフラです。
その実現方式としてはInfiniBandとEthernetがあり、企業のデータセンター運用や既存ネットワークとの親和性を考えると、EthernetベースのAI Networkingは有力な選択肢です。
次章は、こうしたAIクラスタネットワークの要件に対して、Arista AI Networkingがどのような考え方でアプローチしているのかを整理します。
2.AristaのAIクラスタネットワーク製品について
ここからはAristaのAIクラスタネットワーク向け製品の特長をご紹介します。
Aristaの特徴でもあるEOSを搭載した製品により構成されたソリューションとなります。
EOSについては前回のブログを参照ください。
AristaではAIクラスタネットワークの要件に対して以下の表の通り対応しています。

表1:AIクラスタネットワーク要件に対するAristaの対応
それぞれの機能についてご紹介させていただきます。
2-1.Etherlinkについて
Arista Etherlinkは、AIクラスタ向けに最適化されたAristaのEthernetベースのAIネットワーキング・ソリューション群の総称です。
NVIDIA GPUなどに限定された専用ファブリックではなく、標準ベースのEthernet、RoCEを軸にした「オープン標準」を前提としており、大規模なAI学習・推論・ストレージ接続を支える設計になっています。
2-2.Etherlinkを構成する製品群
Etherlinkポートフォリオを構成する具体的な主要製品群は、主に以下の3つのカテゴリに分類されます。
①AI Leafスイッチ(ボックス型)
7060X シリーズ
主にGPUサーバーなどを直接収容する高密度なTop of Rackスイッチです。
最新の 7060X6 シリーズ は、AI向けに最適化されたリーフスイッチです。
最大64ポートまたは32ポートの800Gインターフェースを搭載し、最大51.2Tbpsのスループットを提供します。
2層のリーフ・スパイン構成を用いることで、数千ポート規模まで拡張が可能です。
②AI Spineスイッチ(モジュラー型 / ボックス型)
7800Rシリーズ/7280Rシリーズ
リーフスイッチを束ね、大規模なAIクラスタを構築するためのコアとなるスイッチです。
7800R4シリーズは、AIワークロード向けにクラス最高性能を実現するハイパフォーマンス・モジュラー・システムです。
単一デバイスで最大576ポートの800G(または1152ポートの400G)を収容し、ノンブロッキング460Tbpsの転送能力を持ちます。
AIクラスタ向け専用のラインカード(例:7800R4C-36PE)もラインアップされています。
③分散Etherlinkスイッチ(Distributed Etherlink Switch)
7700R シリーズ
複雑な階層を作らずに超大規模な環境をシンプルに構築するための分散型システムです。
最新の7700R4 Distributed Etherlink Systemは、シングル構成(単一のネットワーククラスタ)でありながら、1システムで最大32,000基の800Gアクセラレータ(GPU等)までスケールアウト可能な分散スイッチシステムです。
2-3.EtherlinkのAI向けの輻輳回避機能
前章でも簡単に触れましたが、Ethernetの環境ではInfiniBandと比較すると輻輳などが起こりやすくなり、対策が必要となります。
AristaのEtherlinkではオープンな技術を採用しているため、前述のRoCEの他以下のようなAIクラスタネットワークで標準的な輻輳回避の機能を搭載しています。
PFC
輻輳時に8個に分類したクラス(キュー)の中で特定の優先クラスだけを一時停止することで、RoCEトラフィックのパケットロスを抑える仕組みです。
従来のフロー制御と異なり、リンク全体を止めるのではなく、必要なトラフィッククラスに限定して制御できるため、輻輳が発生しても性能を維持することが可能です。
ECN
パケットをドロップする前に輻輳の兆候を通知する仕組みです。
ネットワーク側が早期に輻輳を通知し、送信側がレートを調整することで、パケットロスを抑えることができます。
DLB
リアルタイムのリンク利用状況を考慮してトラフィックを分散する機能です。
従来のECMPでは、ハッシュ結果により特定リンクに大容量フローが偏ってしまうことがあります。
AI通信では少数の大きなフロー(エレファントフロー)が多く、特定のリンクにトラフィックが偏ってしまう問題が発生しやすいです。
DLBは実際の利用状況に応じて分散を最適化することで、ネットワーク全体の帯域利用率を高めることが可能です。
またArsitaでは独自の輻輳回避技術としてArista Cluster Load Balancing(CLB)を実装しています。
CLB
CLBの目的はDLBと同様に複数あるリンクのうち特定のリンクにトラフィックが偏ってしまうことを防止することにあります。
DLBはローカルのリンクの負荷をもとにトラフィックを分散することで、リーフからスパインに向けた負荷分散には有効ですが、逆方向のスパインからリーフに対しては通常はパスが一つしかないため効果を発揮できません。
これに対してCLBではローカルのリンクだけではなくRoCEのヘッダ情報を参照することで、クラスタ全体の負荷分散を図ります。
これによりDLBでは実行できなかったスパインからリーフ方向への負荷分散も実現できます。
2-4.AIクラスタネットワークの可視化機能
AristaではAristaのEOS製品を管理するためのソフトウェアとして「CloudVision」を提供しており、AIインフラネットワークの可視化もCloudVisionで行います。
CloudVisionが提供するAIクラスタネットワーク向けの可視化機能には以下のようなものがあります。
①テレメトリの収集
EOSにはLANZ(Latency Analyzer)の機能が搭載されてます。
LANZは、スイッチ内の出力キュー長や輻輳状態、キューイング遅延を監視し、マイクロバーストや輻輳の兆候を可視化します。
ここで収集したデータをCloudVisionで可視化することが可能です。
②AIジョブビュー
AIジョブに特化したトラブルシューティング機能です。
・ジョブ単位のモニタリング
実行中のAIジョブごとに、関与しているサーバー数、NIC数、リーフスイッチ数、フロー数などを一覧表示します。
・ドリルダウン分析
ジョブ全体の状態から、特定のデバイス、サーバー、フローへとドリルダウンし、迅速かつ正確な原因分析とインシデント対応を実現します。
③輻輳制御(PFC/ECN)イベントの検知と自動相関付け
AIインフラ最大の課題である輻輳を可視化・解決する機能です。
・輻輳の迅速な検出
前述のPFCやECNといった輻輳制御の発生イベントを生成し、AIジョブのパフォーマンスに影響を与える輻輳を即座に検出します。
・根本原因の特定
発生したPFC/ECNイベントを、特定のデバイスやトラフィックパスと関連付けることで、輻輳の根本原因や潜在的な誤設定を特定し、解決へと導きます。
2-5.消費電力問題への対策
AIクラスタの大規模化に伴って、光トランシーバーの消費電力とコストが大きな課題となってきています。
800G、1.6Tbpsとポート速度が上がるほど、スイッチASICやサーバだけでなく、光モジュール(トランシーバ)の電力・発熱・コストも無視できなくなってきています。
この課題を解決する技術には
LPO
CPO
があります。
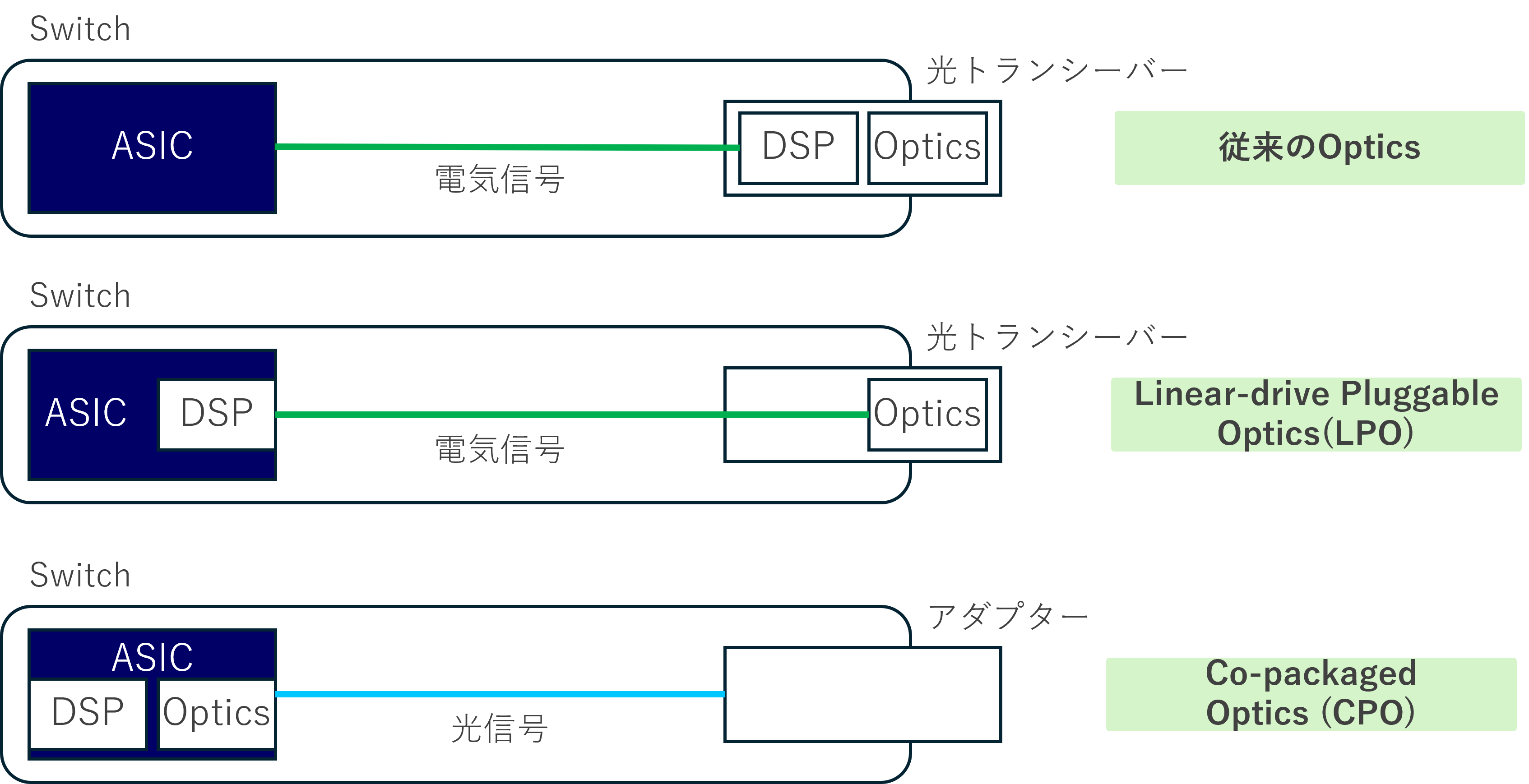
図3:LPOとCPO
図の通り従来型のOpticsではDSP(Digital Signal Processor)はトランシーバ内に搭載されていました。
LPOではトランシーバ内の電力消費の大きいDSP(の機能)をASIC内に搭載することで電力消費を抑えるとともに、低遅延の効果を得ることができます。
基本的にはASIC側が対応している必要があり、AristaスイッチでもBroadcomのJericho3やTomahawk5のチップを搭載したモデルで対応しています。
また次の段階のアプローチとしてCPOがあります。
CPOはさらにOptics(光エンジン)をASICに近い位置に搭載することでさらなる消費電力の低減を図ります。
その反面Opticsの故障は従来であればトランシーバの交換で対応できましたが、CPOでは機器ごと交換となるケースもあり、保守性の面で課題があります。
今後、CPOを採用した製品が登場する可能性があります。
3.まとめ
AristaのAIインフラネットワークソリューションは、単なる高速スイッチの製品群ではなく、
・EOSを中核としたソフトウェア基盤
・EtherlinkによるAI向けEthernetプラットフォーム
・PFC/ECNによる輻輳制御、DLB/CLBによる負荷分散
・CloudVisionによる可視化
・LPOによる電力・コスト最適化
を組み合わせた総合的なAIファブリックであると言えます。
AIクラスタネットワークの設計では、ポート速度やスイッチ容量だけを見るのではなく、ロスレス性、輻輳制御、可視化、消費電力、光接続、運用自動化まで含めて評価する必要があり、その観点で、AristaのEtherlinkは、オープンEthernetで大規模AI基盤を構築したい企業にとって、有力な選択肢の1つになると思います。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
技術本部 技術統括部 第3技術部 1課
藤ノ木 俊



