


こんにちは。
Cohesityの操作インターフェースであるDashboardでは、データがクラウド / オンプレのどちらにあったとしても分かりやすく扱えるようになっています。 その様子を連載形式でご紹介しています。
-------------------------------------------------------------------------------------------
Cohesity クラウド連携機能のご紹介
第1回 CloudArchive編
第2回 CloudRetrieve編
第3回 CloudTier編
-------------------------------------------------------------------------------------------
今回は「第2回 CloudRetrieve編」です。 "Retrieve(リトリーヴ)"という名の通り、クラウドに保管されたデータを"回収"してリカバリを行います。特にBCP対策やDR対策を検討されている方にご覧頂ければと思います。
なお、CloudRetrieveは前回ご紹介したCloudArchiveのリカバリに関連した機能です。 このため先に「第1回 CloudArchive編」をご覧頂くことをお薦めいたします。
CloudRetrieveとは
前回ご紹介したCloudArchiveは、取得したCohesityでバックアップのコピーを外部ターゲットに送信する機能でした。 CloudRetrieveは「バックアップを取得したものとは別のCohesity Clusterでリカバリを行う」機能です。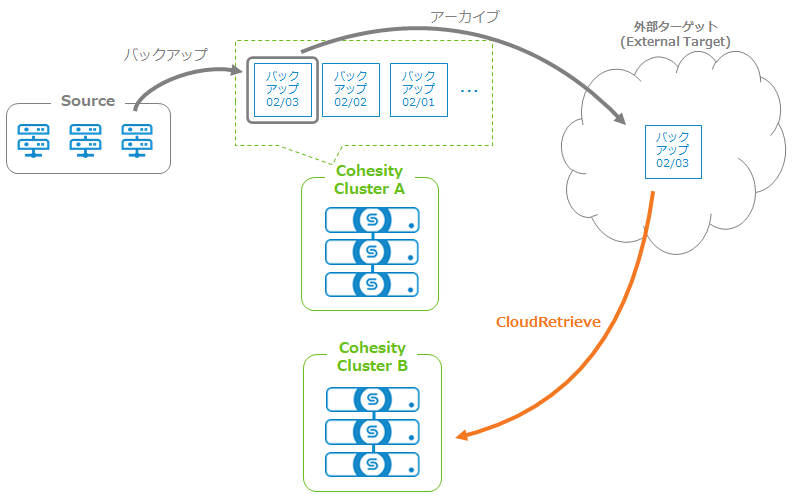 災害が発生して元のCohesity Clusterが利用できなくなった場合など、別のCohesity Clusterを利用してクラウドに保管していたバックアップデータを参照することができます。
災害が発生して元のCohesity Clusterが利用できなくなった場合など、別のCohesity Clusterを利用してクラウドに保管していたバックアップデータを参照することができます。
以前、「Cohesityの裏側を知ろう」でCohesityではデータをChunkという小さな単位に分割して扱っており、それにはメタデータが必要ということをご説明しました。こちらをご覧頂いた方は「なぜCohesity Clusterのバックアップデータが別のCohesity ClusterのChunkを利用できるのか?」という疑問をお持ちになるかもしれません。
実はCohesityのCloudArchiveではChunkを集めるのに必要なメタデータも一緒に外部ターゲットに送信しています。 CloudArchive先のAzure Blobを見てみると「cohesity_icebox_metadata」や「cohesity_icebox_snaptree」といったフォルダが作成されています。 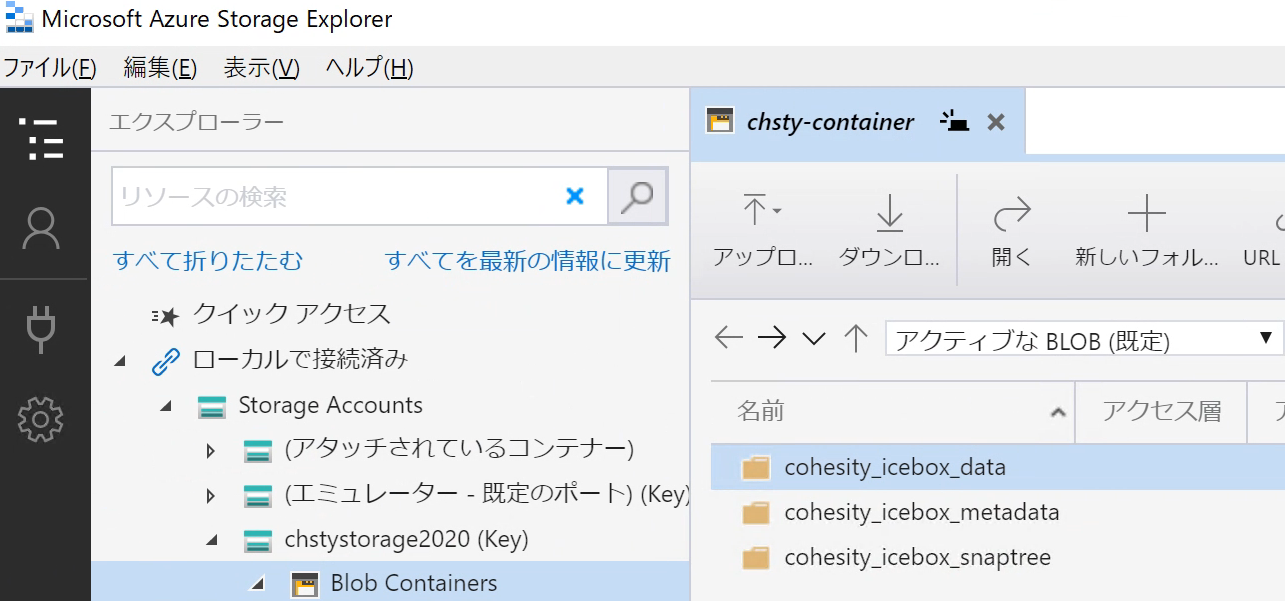 双方ともCohesityのメタデータです。「..._snaptree」フォルダには各ファイルとChunk間の関連づけ、「..._metadata」フォルダには圧縮・重複排除等に関する情報がそれぞれ格納されています。別のClusterであっても、これらメタデータを入手することでクラウド上のChunkを利用できるようになるという訳です。
双方ともCohesityのメタデータです。「..._snaptree」フォルダには各ファイルとChunk間の関連づけ、「..._metadata」フォルダには圧縮・重複排除等に関する情報がそれぞれ格納されています。別のClusterであっても、これらメタデータを入手することでクラウド上のChunkを利用できるようになるという訳です。
CloudRetrieve操作手順
ここからはCloudRetrieveの操作をご紹介します。 (前回に引き続き今回もAzureを利用します。)
今回、CloudArchiveを行ったものとは別のCohesity Clusterを用意しました。本稿では便宜上、CloudArchiveを行ったClusterを「Cluster A」、CloudRetrieveを行うClusterを「Cluster B」と呼びます。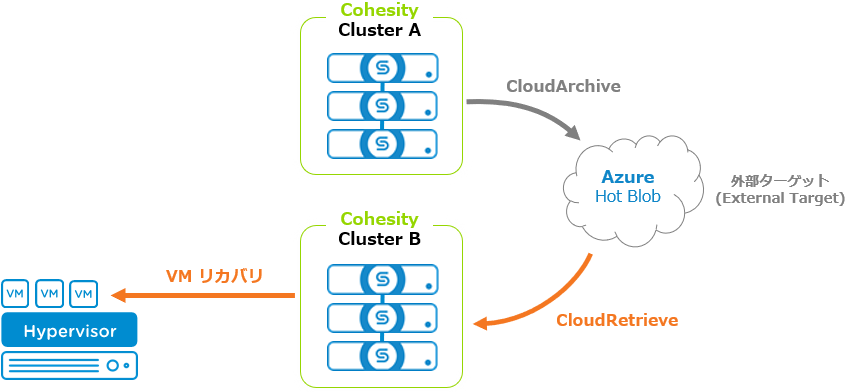 前回の「CloudArchive編」でvSphere仮想マシンのバックアップをCloudArchiveで外部ターゲットに保存していますので、このバックアップを「Cluster B」側からリカバリしてみたいと思います。
前回の「CloudArchive編」でvSphere仮想マシンのバックアップをCloudArchiveで外部ターゲットに保存していますので、このバックアップを「Cluster B」側からリカバリしてみたいと思います。
(1) 外部ターゲットの登録
Cluster BのCohesity Dashboardで、リカバリしたいデータが含まれているクラウドストレージを外部ターゲットとして登録します。(詳細は前回の記事をご参照ください。)
ここでは前回CloudArchiveを行ったAzure Blobを外部ターゲットとして登録しました。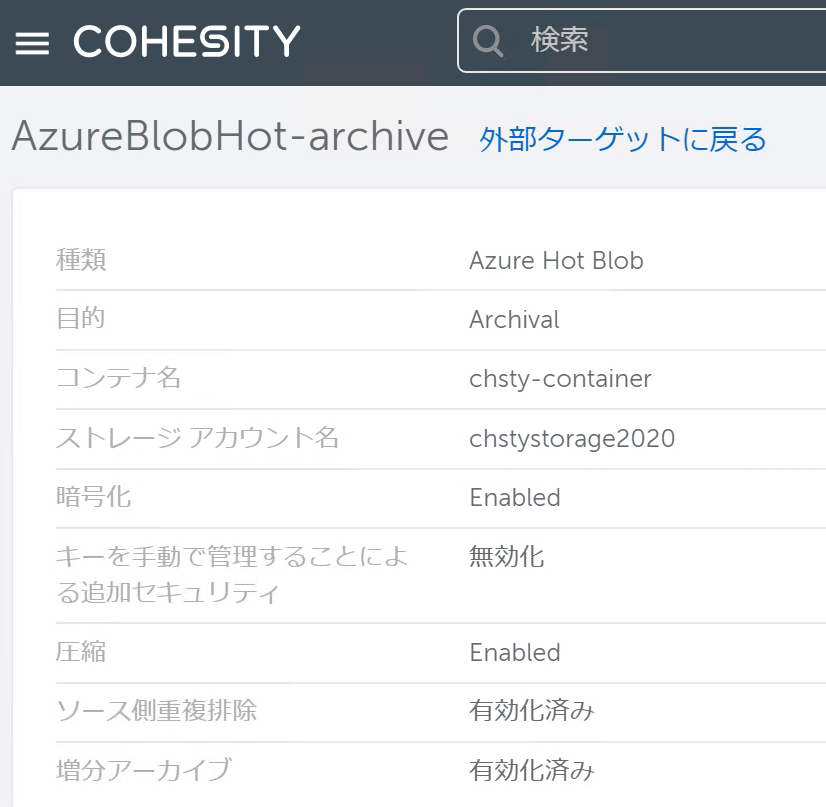
(2) アーカイブされたデータの検索・ダウンロード
[ ≡ ]ボタンをクリックして [データ保護]> [CloudRetrieve] を選択します。 以下の画面が表示されます。CloudRetrieveの手順概要が記載されており、まずは外部ターゲット上のデータを検索して、利用したいバックアップデータをCohesityのローカルにダウンロード、そして回復(リカバリ)という順序で操作を行うことが分かります。 画面下部の[検索を開始]をクリックします。
以下の画面が表示されます。CloudRetrieveの手順概要が記載されており、まずは外部ターゲット上のデータを検索して、利用したいバックアップデータをCohesityのローカルにダウンロード、そして回復(リカバリ)という順序で操作を行うことが分かります。 画面下部の[検索を開始]をクリックします。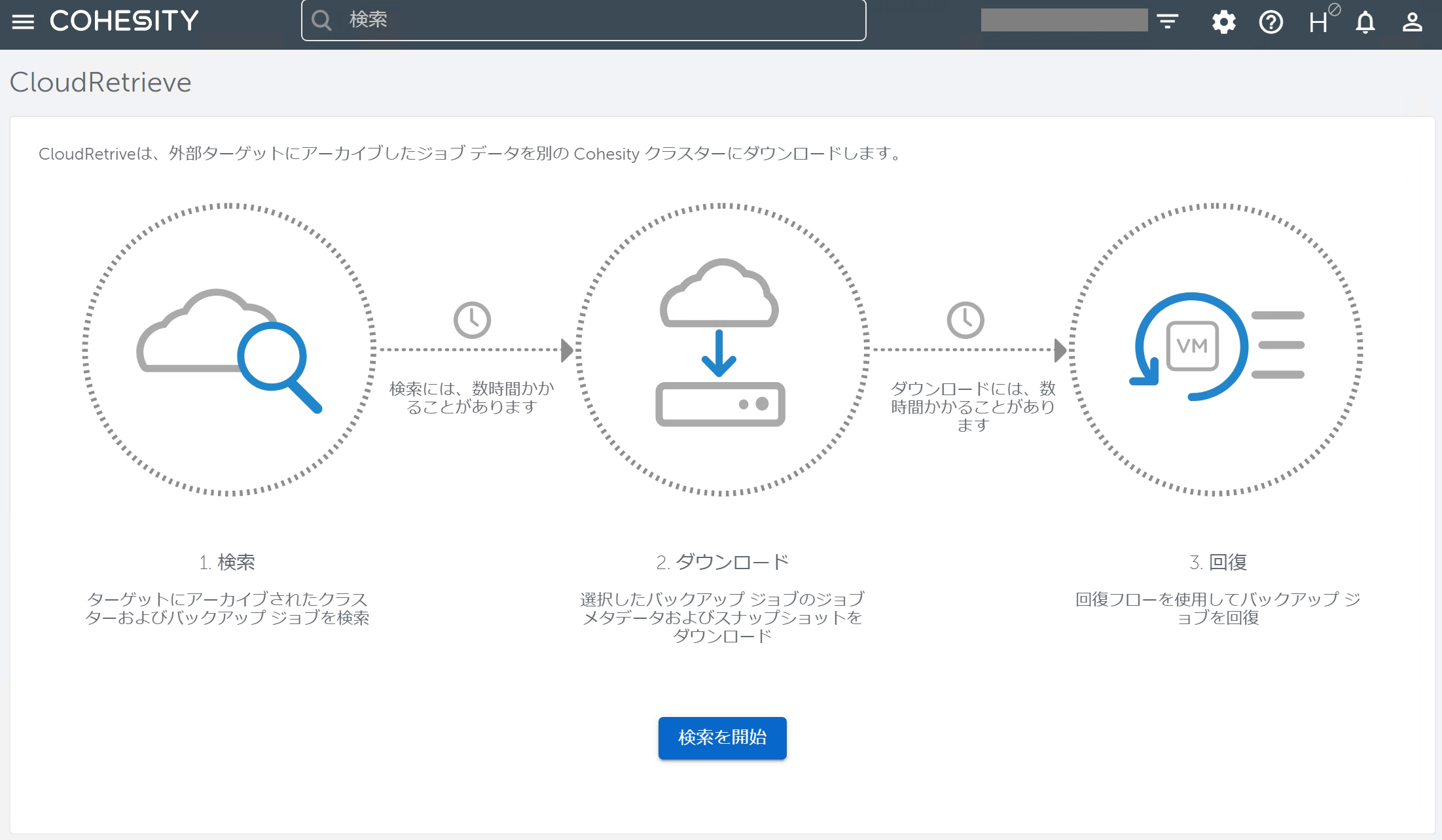
まずは外部ターゲット側に存在するデータを検索します。 ここではClusterやバックアップジョブで絞り込んで検索することができます。 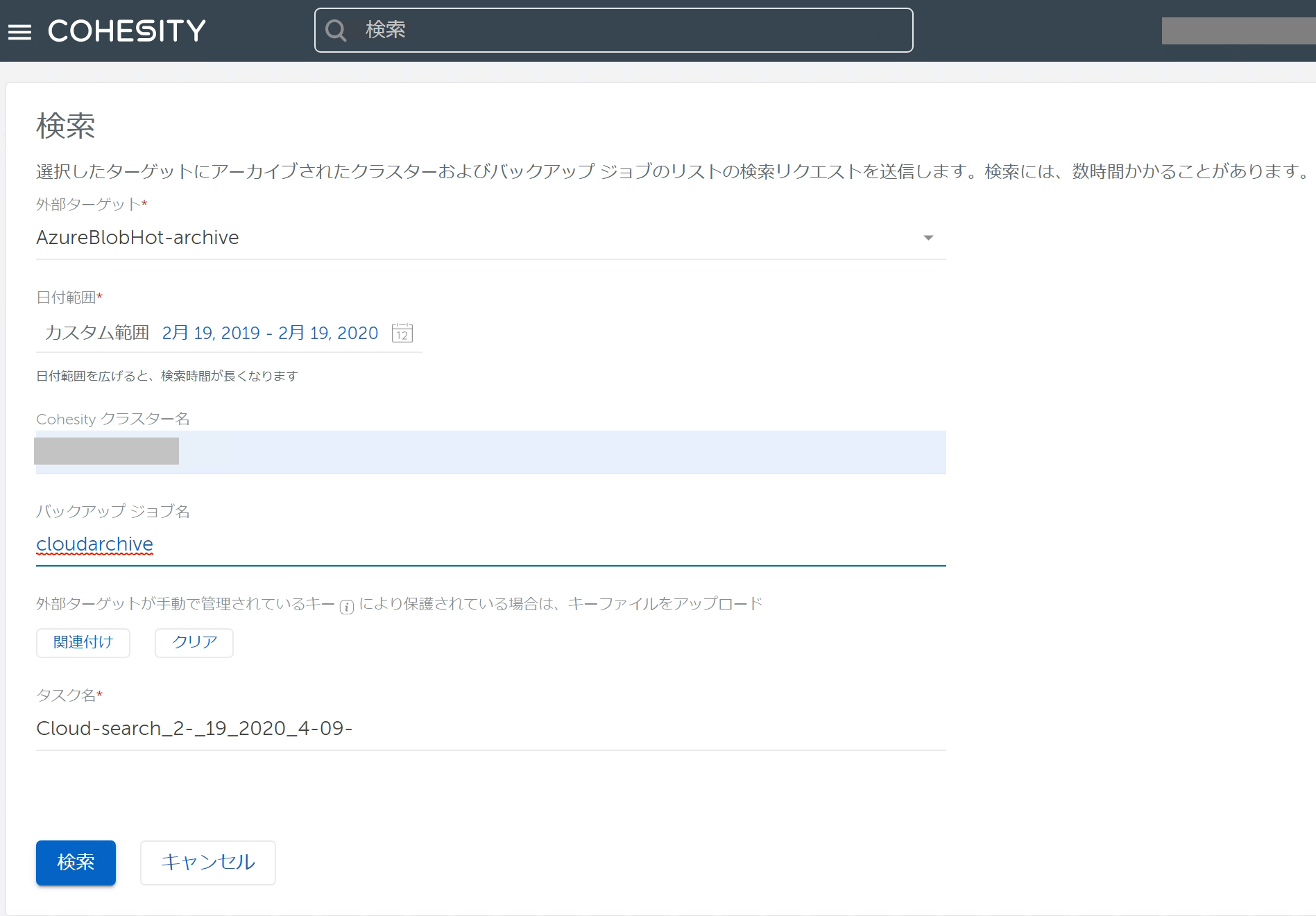 「外部ターゲット」には手順(1)で登録したものを指定します。 Cluster AのCluster名、バックアップジョブ名(名称の一部分でも構いません)を入力して[検索]をクリックします。
「外部ターゲット」には手順(1)で登録したものを指定します。 Cluster AのCluster名、バックアップジョブ名(名称の一部分でも構いません)を入力して[検索]をクリックします。
前回CloudArchiveを行ったバックアップジョブが表示されたら、ジョブ名の左横にあるチェックボックスにチェックを入れます。 さらにダウンロードしたデータをどのStorageDomainに保存するかを指定して、[ダウンロード]をクリックします。(ここで指定するのはCluster B上に存在するStorageDomainです。)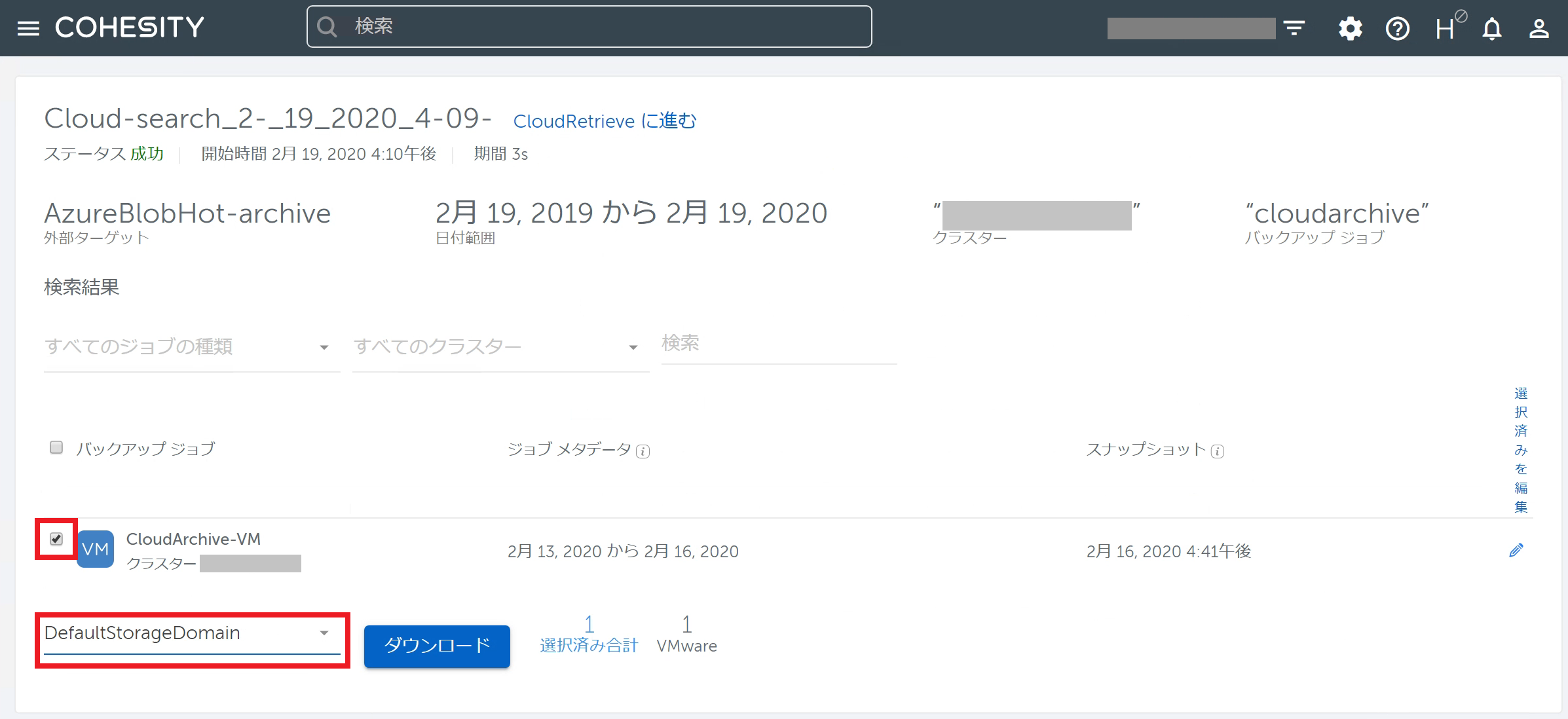 ダウンロードが開始されますので完了まで待機します。
ダウンロードが開始されますので完了まで待機します。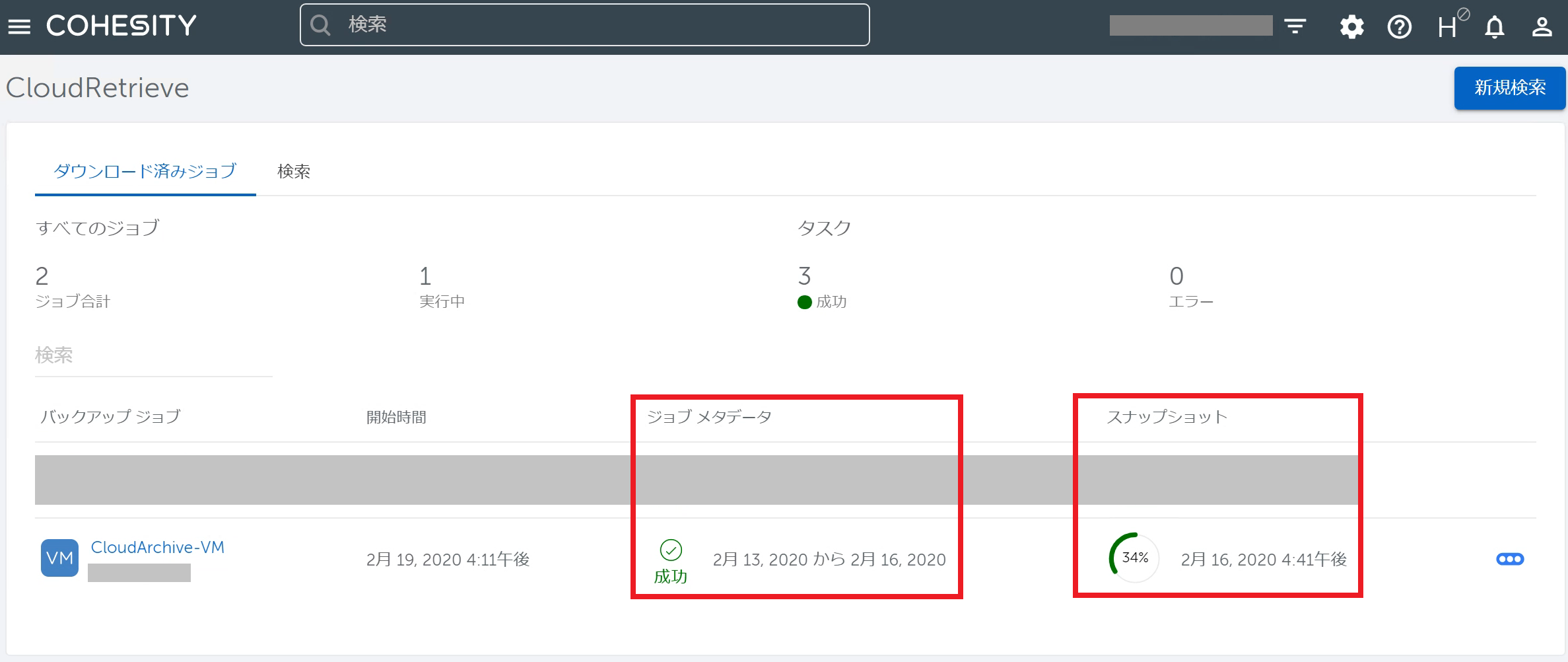 画面にもありますように、まずメタデータがダウンロードされてからスナップショット(バックアップデータ本体)がダウンロードされます。 メタデータだけでなくスナップショットがダウンロードされるまで待機しましょう。
画面にもありますように、まずメタデータがダウンロードされてからスナップショット(バックアップデータ本体)がダウンロードされます。 メタデータだけでなくスナップショットがダウンロードされるまで待機しましょう。
ダウンロードが完了したらバックアップジョブ名をクリックします。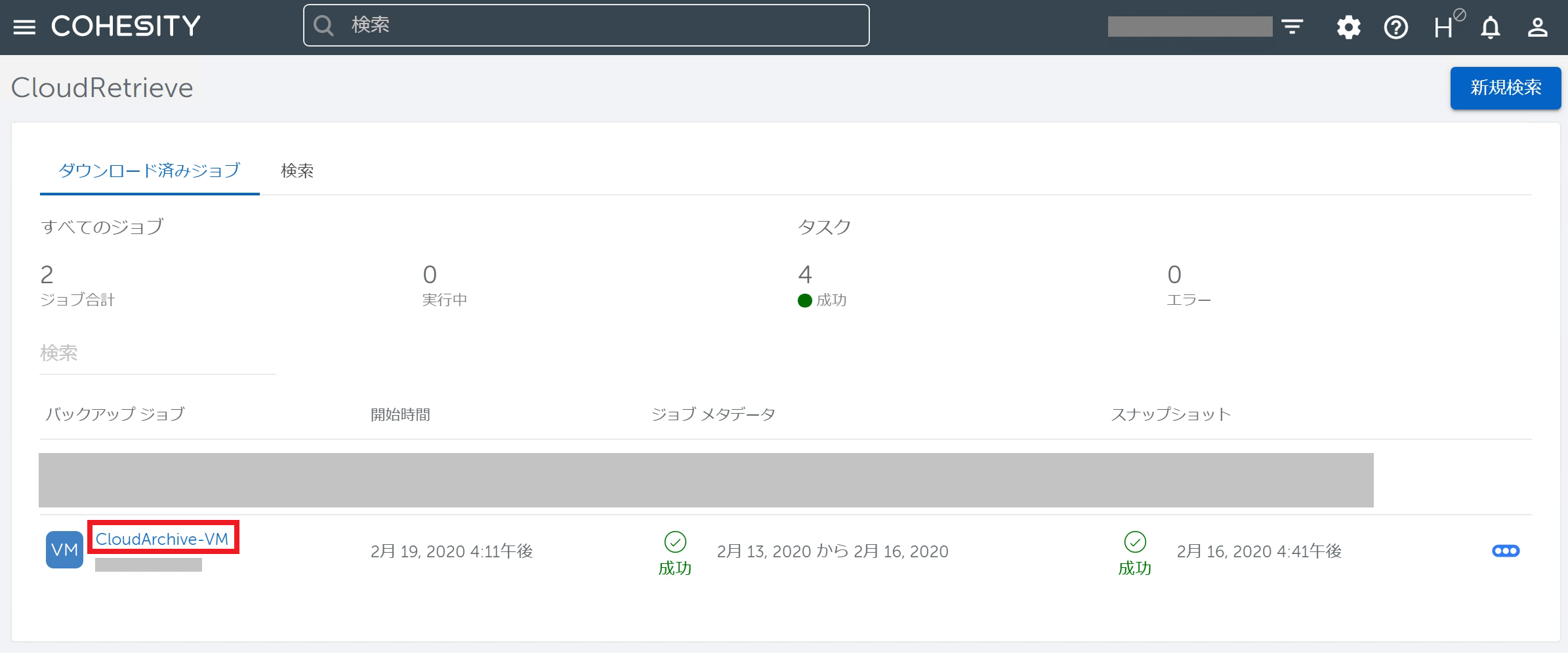
24時間以内に実行されたバックアップジョブが表示されます。 「ジョブ実行が見つかりません。」と表示された場合は、左上の日付をクリックします。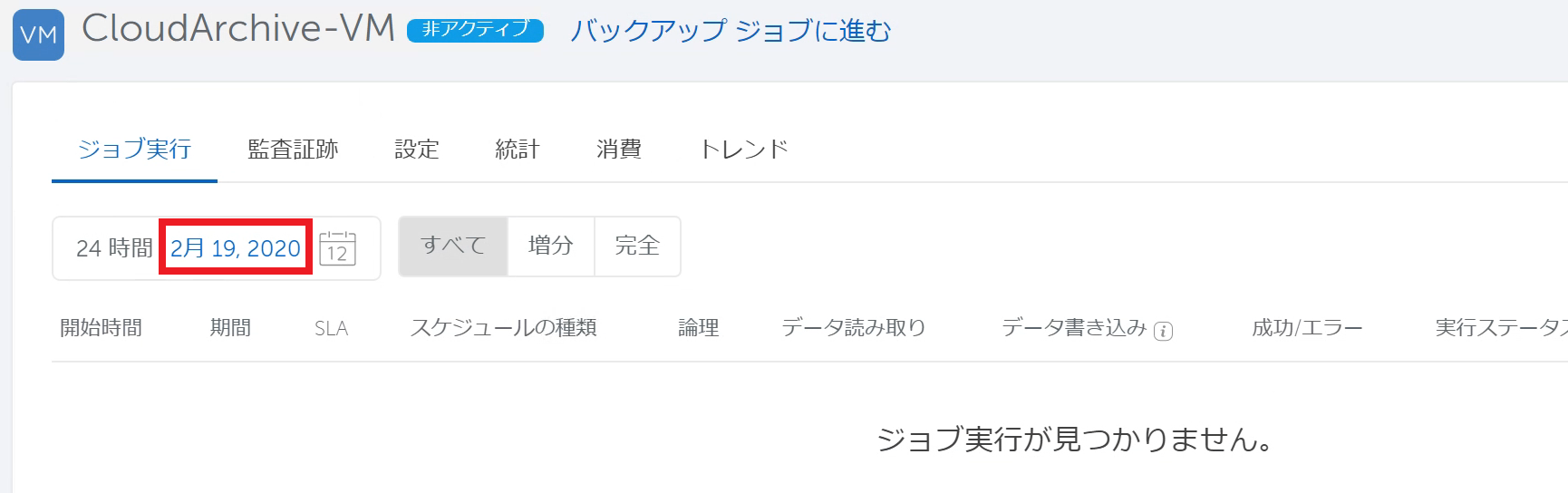
カレンダーが表示されますので、CloudArchiveが行われた日付が含まれるように設定し[保存]をクリックします。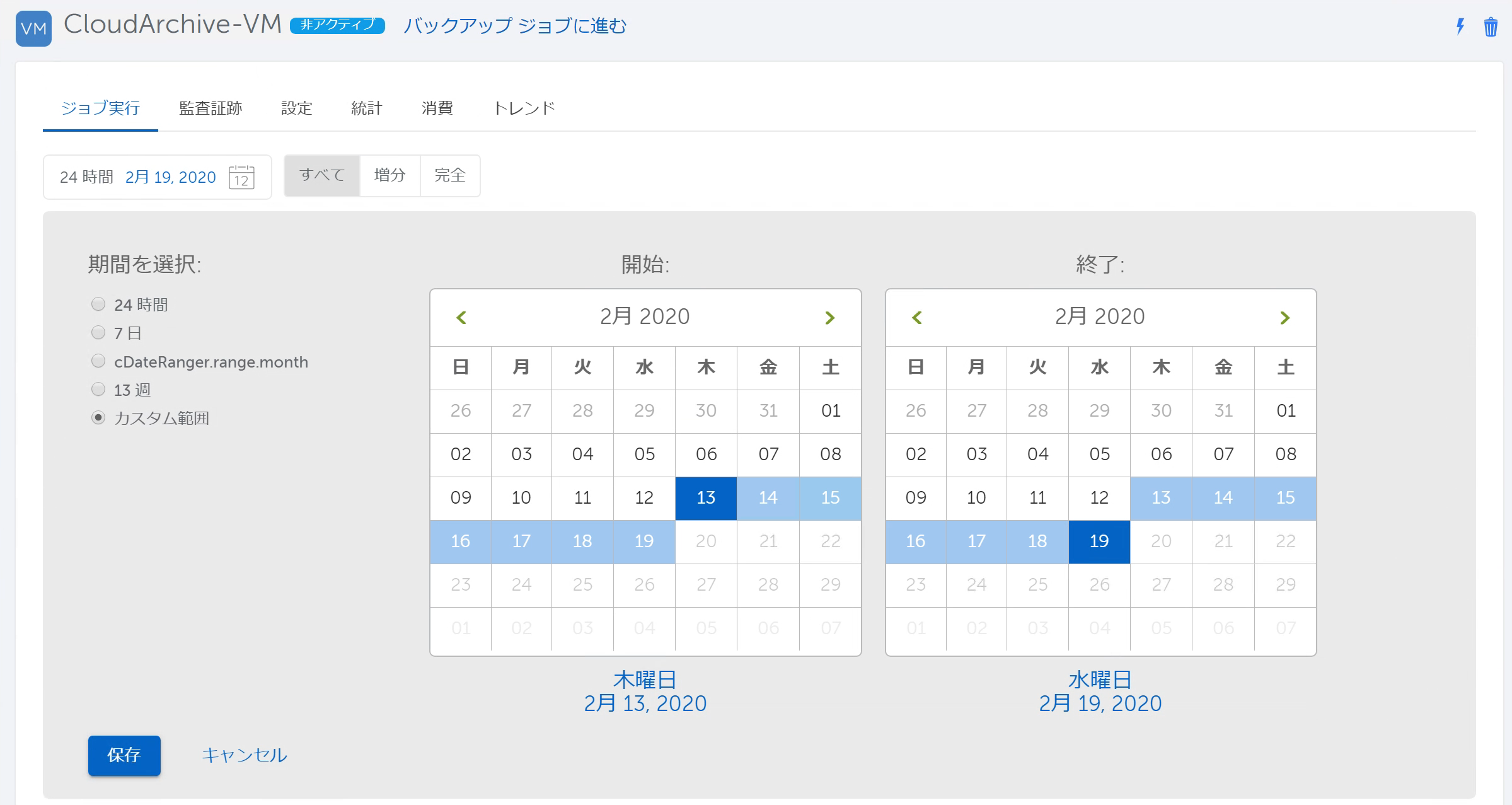
Cluster Bで2回分のバックアップが見えるようになりました。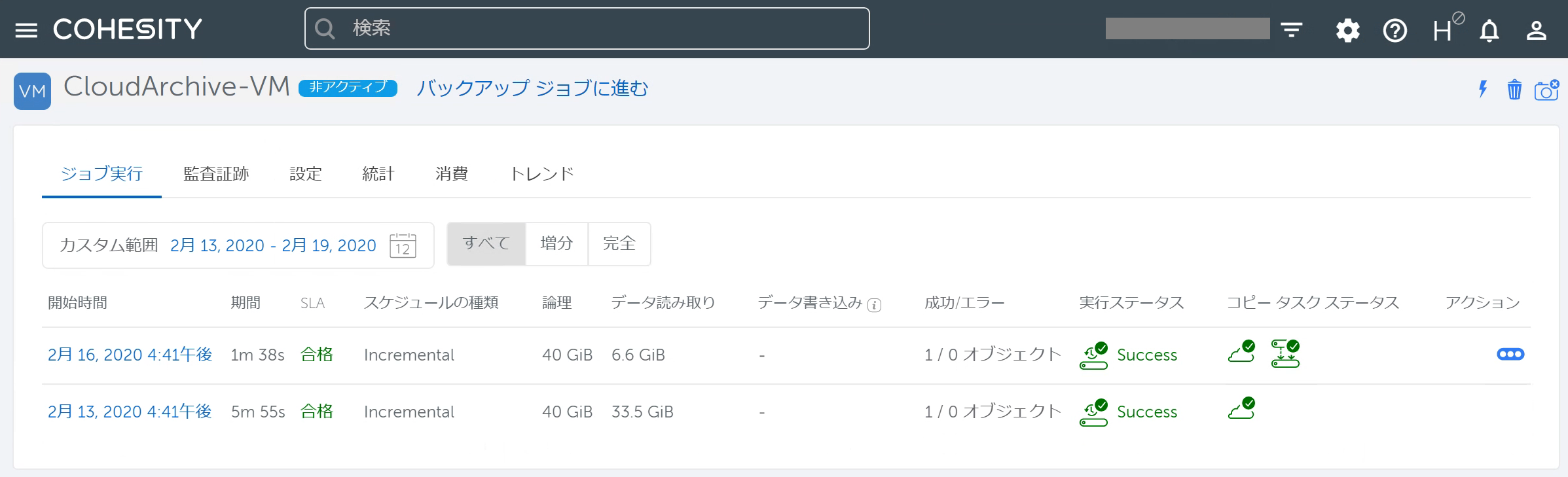
前回、Cluster Aでは日次バックアップを行っていましたが、アーカイブは週次にしていました。 クラウド上には「初回バックアップ」と「日曜時点のバックアップ」が存在していますので、ここではそのデータが見えてきます。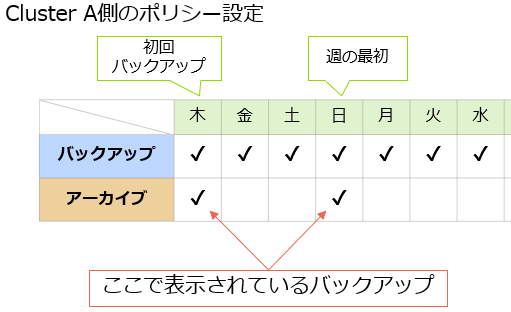
(3) CloudRetrieveされたデータでVMリカバリ
手順(2)まででクラウド上に存在していたバックアップデータはCluster Bのローカルにコピー(ダウンロード)されています。 このため、以降はクラウドからデータをダウンロードすることなくリカバリ処理を行うことができるようになります。
Cluster BからVMのリカバリを実行してみましょう。CloudRetrieveの画面からリカバリ対象のVMの右側にあるアイコンから、「ダウンロード済みスナップショットを回復」を選択します。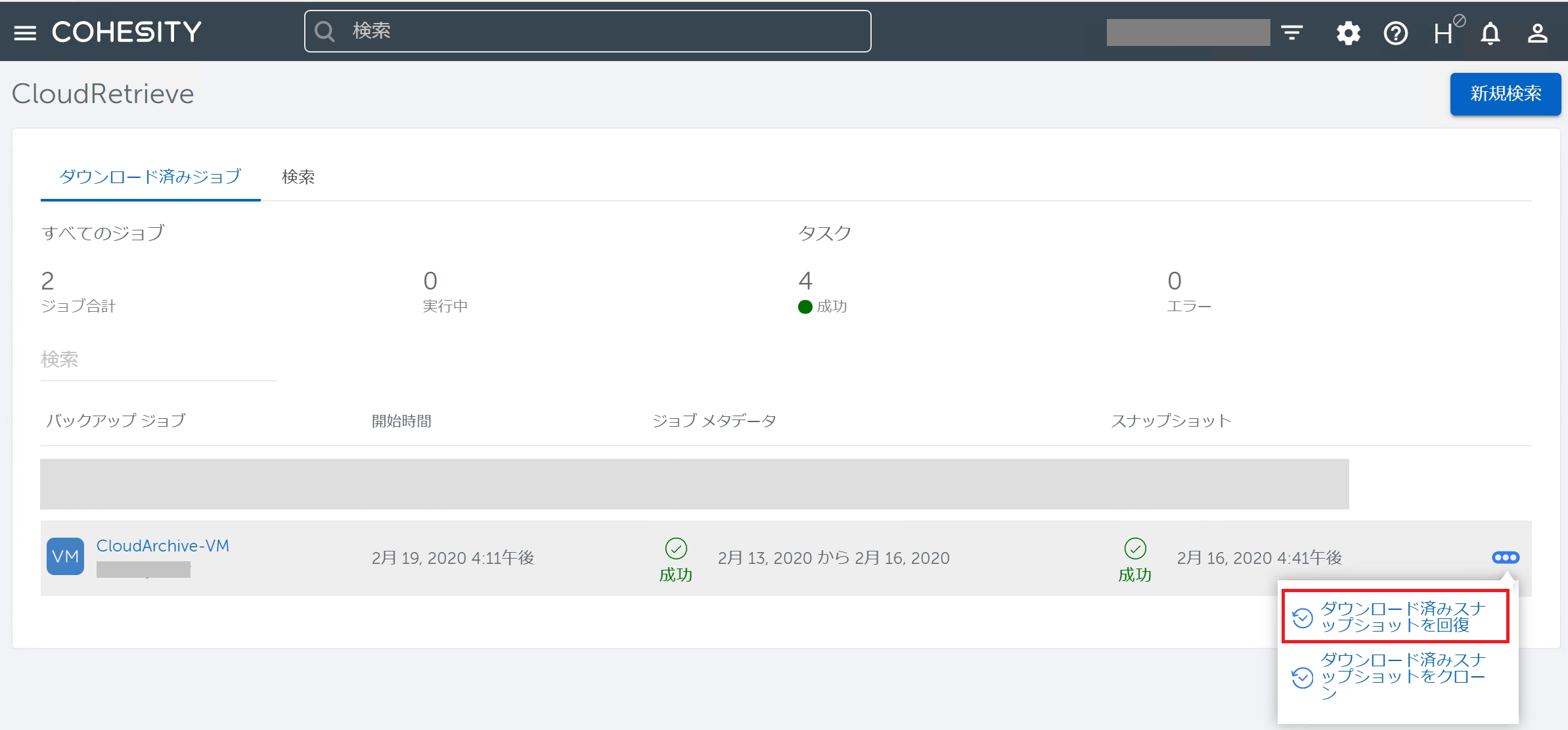
ここからは前回記事の「【おさらい】CohesityローカルデータからのVMリカバリ」でご紹介した内容と同じです。 「VMを回復」画面に移りますので、リカバリタスクを作成して[終了]をクリックすればVMのリカバリが開始されます。(適宜、リカバリ先のvCenter ServerやESXi Serverをソースとして登録します。)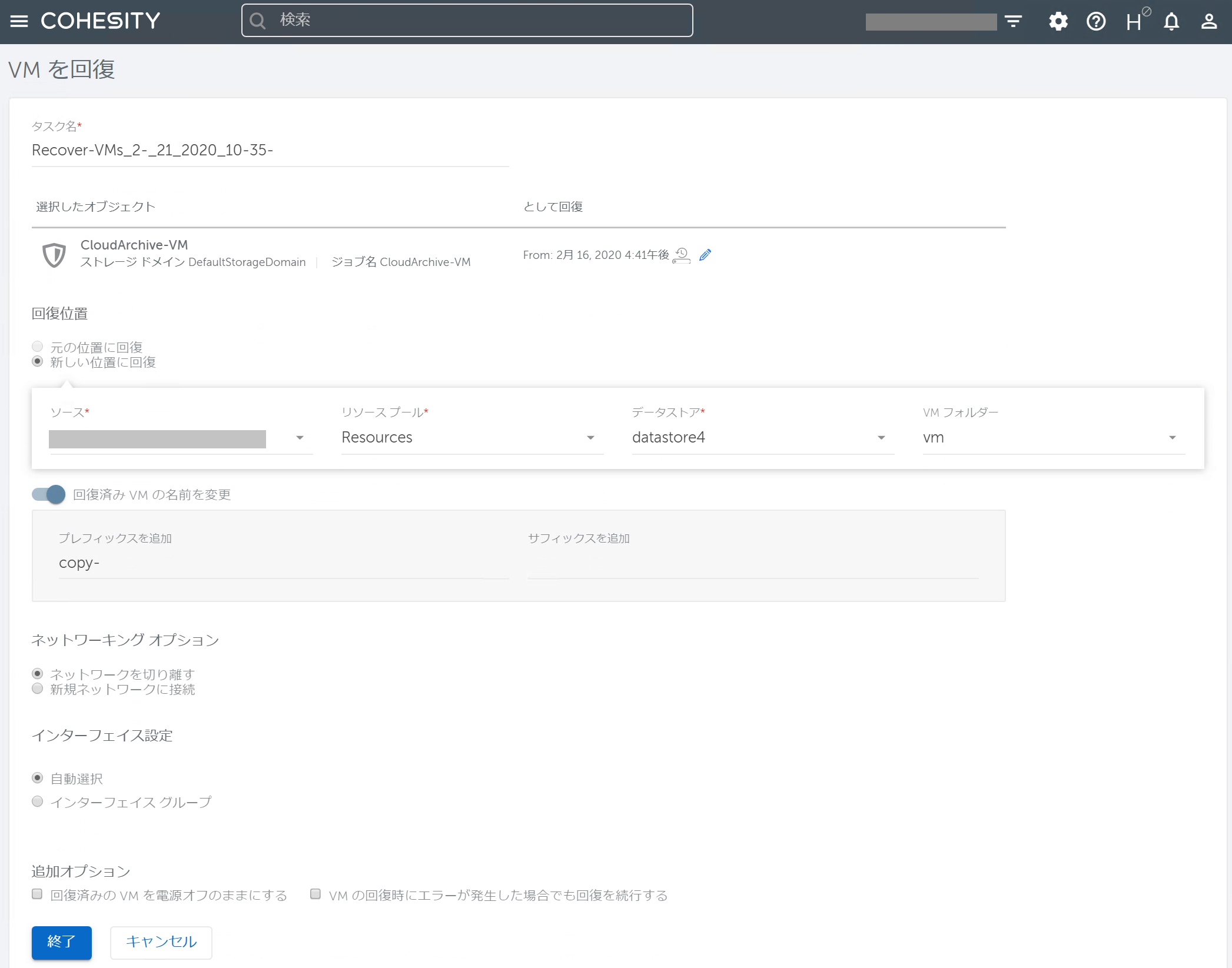
なお、上記画面で「として回復」のアイコンをクリックするとCohesityローカルのデータを使ってVMリカバリできることが確認できます。
【補足】ダウンロードされるバックアップとダウンロードされないバックアップ
一連の手順をご紹介しましたが、手順(3)でVMリカバリを行う際に一回分のバックアップしかCohesityローカルにダウンロードされていないことに気付かれた方もいらっしゃるかもしれません。 なぜこのような状態になるかを補足しておきたいと思います。 上図では2月16日のバックアップはCohesityローカル・外部ターゲット両方に存在しているのに対して、2月13日のバックアップはCohesityローカルにダウンロードされていません。これはCloudRetrieve実行時の設定によるものです。
上図では2月16日のバックアップはCohesityローカル・外部ターゲット両方に存在しているのに対して、2月13日のバックアップはCohesityローカルにダウンロードされていません。これはCloudRetrieve実行時の設定によるものです。
以下はCloudRetrieveでバックアップデータを検索したときの画面です。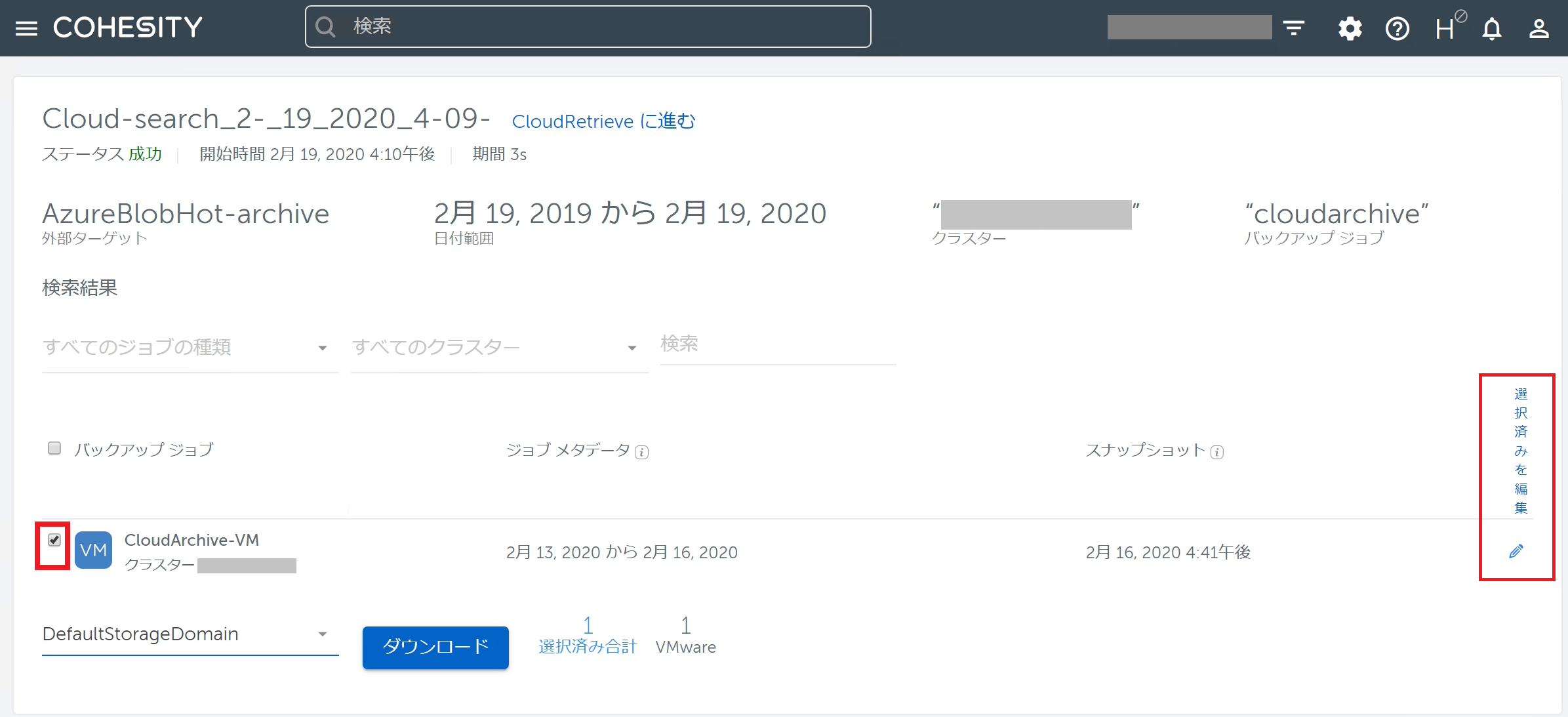 検索結果に表示されたバックアップジョブの左にあるチェックボックスにチェックを入れると「選択済みを編集」アイコンがクリックできるようになります。このアイコンをクリックするとダウンロード対象のデータを指定することができます。
検索結果に表示されたバックアップジョブの左にあるチェックボックスにチェックを入れると「選択済みを編集」アイコンがクリックできるようになります。このアイコンをクリックするとダウンロード対象のデータを指定することができます。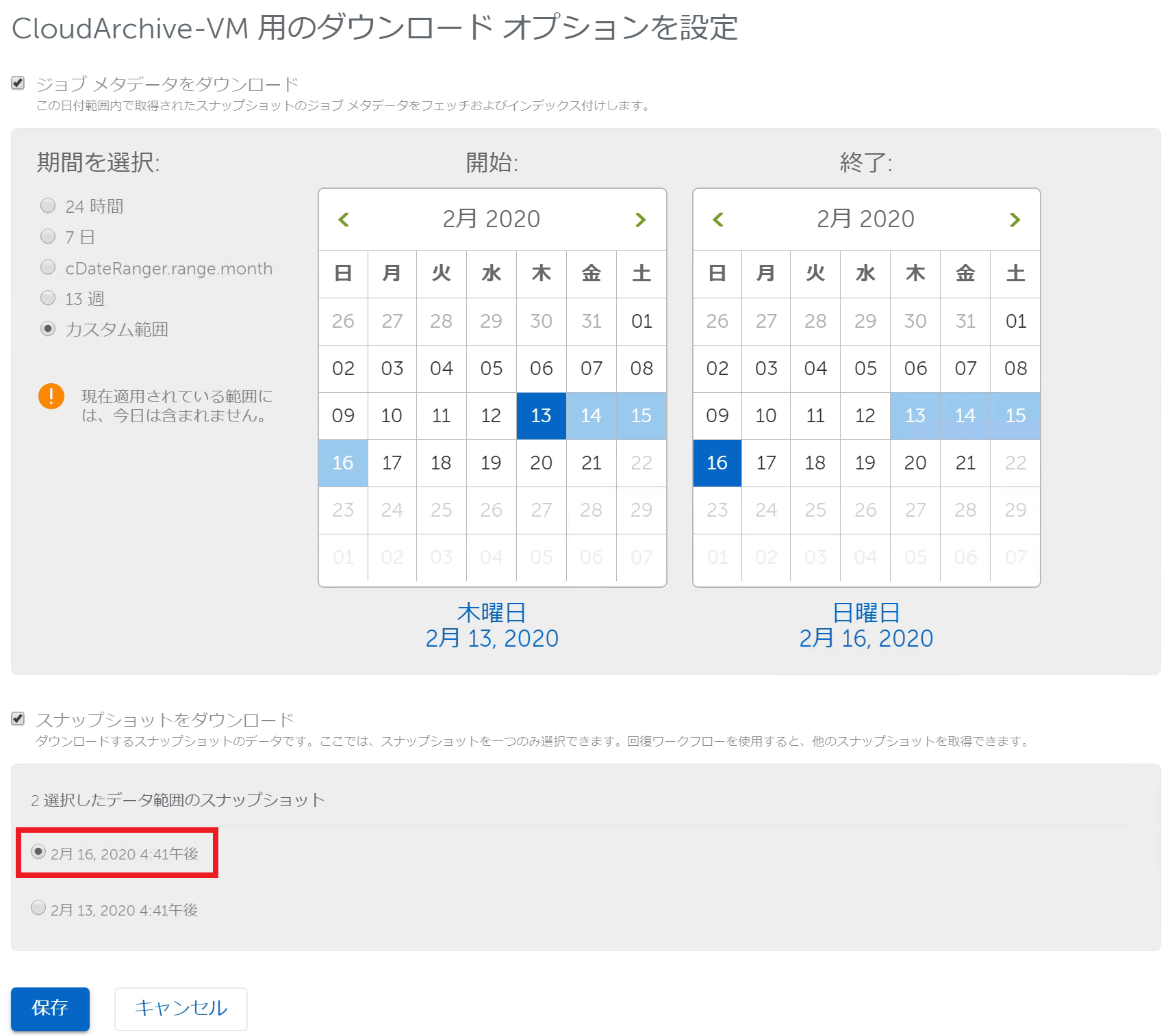
デフォルトでは「スナップショットをダウンロード」で最新の2月16日のバックアップが選択されています。 このため、2月16日のバックアップのみCohesityローカルにダウンロードされていたという訳です。
前回のCloudArchive編に引き続き、CloudRetrieve編をお送りしました。
CloudArchiveでバックアップデータをクラウドに保管しておけば、万が一災害等でCohesity Clusterが利用不可になったとしても、別のCohesity Clusterを利用することでリカバリ処理を行うことができるようになっています。
さらに、CloudRetrieveではバックアップデータだけでなくメタデータも一緒にダウンロードして、バックアップデータをリカバリに利用できる状態にしてくれます。 従来型のバックアップ製品では、オフサイトのバックアップデータをリカバリに利用する場合にカタログ情報(バックアップサーバーがバックアップデータを扱うための情報)を意識して操作しなければいけないものもあります。 一方でCohesityは、ユーザーがカタログ情報の扱いを特に意識しなくともリカバリできるデザインになっていることもお分かり頂けたかと思います。
次回(第3回)はCohesityのストレージ領域をクラウドに延伸させられる「CloudTier」についてご紹介したいと思います。お楽しみに。
※ 今回使用した環境はCohesity Softwareバージョン6.4.0です。サービスや製品の仕様ならびに動作に関しては、予告なく改変される場合があります。
Cohesity社ウェブサイト: https://www.cohesity.com/ja/
Cohesity関連記事の一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄




