


こんにちは。
「かんたんCohesity」と題してCohesityの主な機能を連載でご紹介してきました。
-------------------------------------------------------------------------------------------
第1回 Cohesityの「買い方」
第2回 Cohesityはセットアップも「かんたん」
第3回 NASとして使うCohesity
第4回 バックアップサーバーとして使うCohesity
第5回 Cohesityによるバックアップの"活用"
第6回 Cohesityならアプリケーション導入も「かんたん」
番外編 Cohesityの裏側を知ろう
-------------------------------------------------------------------------------------------
今回は「番外編」です。
連載を通じてCohesityの操作が「かんたん」であることをお伝えしてきましたが、実はCohesityがユーザーに見えないように裏で色々な処理をやってくれています。 通常、Cohesityを使っている間にこれらを意識することはほとんどありませんので知らなくても基本的な操作はできますが、せっかくの「技術ブログ」ですから"番外編"としてDeep Diveをお送りしたいと思います。
本稿では「SpanFS」「SnapTree」をピックアップして内部動作をご紹介します。 とはいえ可能な限り「かんたん」にご紹介しますので、Cohesityの内部動作が気になる方はぜひご一読ください。
SpanFSによるデータの扱い方
連載第3回で触れましたが、CohesityはSpanFSという分散ファイルシステムを採用しています。 実際のSpanFSではiNodeやBlob、Brickといった複数の構成要素によりファイルを効率的に扱っていますが、全てを細かく説明すると煩雑になってしまいますので「実データ(Chunk / Chunkfile)」と「メタデータ」に抽象化してご説明します。
■Chunk / Chunkfile
Cohesityでは書き込まれる実データを8~24KB(可変長)に分割して、小さな塊で管理しています。 この分割されたデータのひとつひとつを「Chunk(チャンク)」と呼びます。 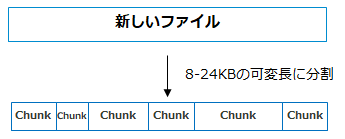 (重複排除の設定が有効にされている場合は)Chunk単位で重複排除されます。可変長のChunk単位で重複排除、すなわち可変長重複排除ですので、データ削減効率の良いテクノロジと言えます。
(重複排除の設定が有効にされている場合は)Chunk単位で重複排除されます。可変長のChunk単位で重複排除、すなわち可変長重複排除ですので、データ削減効率の良いテクノロジと言えます。
さらにChunkは8MBの「Chunkfile(チャンクファイル)」としてまとめられた上で、ディスクに書き込まれます。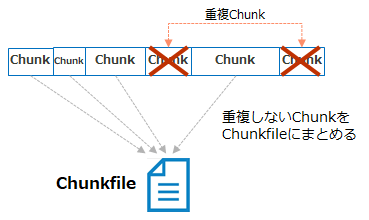
■メタデータ
Cohesityに対してあるファイルの読み出しが要求された場合は「メタデータ」を参照して必要なChunkを探し出し、ファイルを提供します。 「メタデータ」では、あるファイルを構成するChunkがどれか / ChunkがCohesityクラスタ内のどのディスクに書き込まれているかといった情報を保持しています。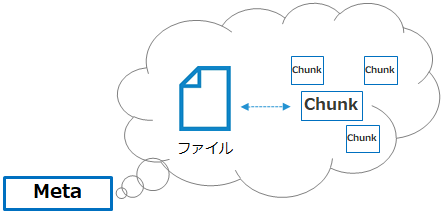
Chunk / Chunkfileとメタデータの書き込み先についてもここで確認しておきましょう。 連載第1回でCohesityの物理アプライアンス版をご紹介しました。ディスクがFlash(SSD)とHDDのハイブリッドの場合を例にご説明します。
CohesityのメタデータはSSDに書き込まれます。 実データであるChunk (Chunkfile)については、通常、中身がランダムデータであればSSDに、シーケンシャルデータであればHDDに書き込まれますが、ViewのQoS Policy設定により書き込み先をコントロールすることも可能です。(QoS Policyについては連載第3回をご参照ください。) ランダム / シーケンシャルの判別はCohesityが内部的に行ってくれます。
Cohesityの耐障害性
ストレージ製品についてお話をする際、避けて通れないのが耐障害性(フォールトトレランス)の仕様です。 仕様が少々複雑になっていますので、ここで整理しておきましょう。
Cohesityの耐障害性の仕組みとしては「RF (Replication Factor)」と「EC (Erasure Coding)」の2種類が備わっています。 これらをまとめて「Resiliency」と呼んだりします。
まず押さえておきたいポイントは、「メタデータと実データ(Chunk / Chunkfile)でそれぞれ設定できるResiliency設定が異なる」という点です。
メタデータに対し設定できるのはRFのみです。 実データに対してはRFまたはECのいずれかを設定できます。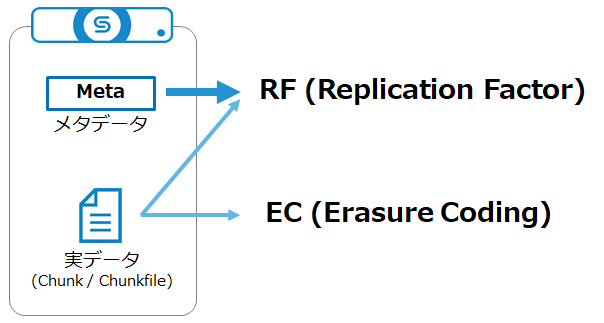
次に、RFとECの仕組みを詳しく見てみましょう。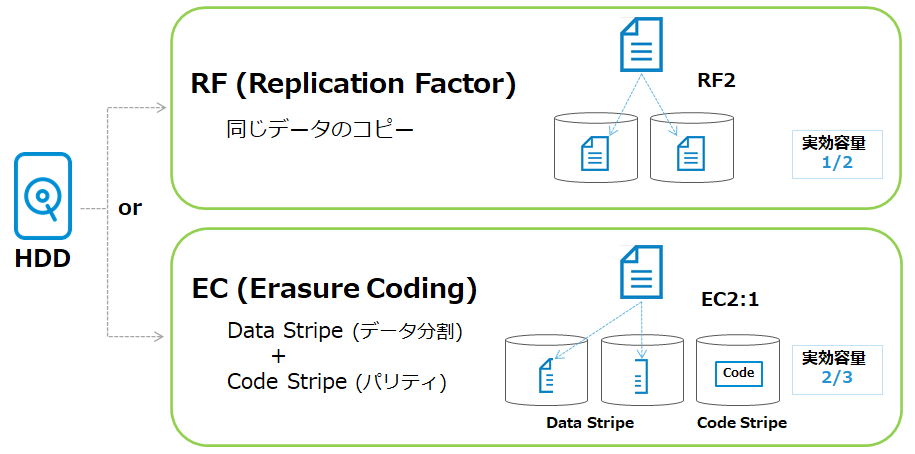 ■RF (Replication Factor)
■RF (Replication Factor)
RFはあるデータの同一コピーを保持するもの(ミラーリング)です。
Cohesityでは「RF2」または「RF3」を設定することができます。(バージョン6.4.1からは「RF4」の設定が可能です。 またシングルノードのVE(Virtual Edition)は「RF1」で動作します。) 「RF2」であればデータのコピーを2つ、「RF3」であればデータのコピーを3つ保持します。 もしも「RF2」でCohesityを利用する場合、Cohesityの実効容量は物理容量の1/2になります。 「RF3」なら実効容量は物理容量の1/3です。
■EC (Erasure Coding)
ECはあるデータを書き込む場合に、データを分割したものとパリティをディスクに書き込むというものです。
CohesityではChunkfileを分割したものを「Data Stripe (データストライプ)」、パリティを「Code Stripe (コードストライプ)」と呼びます。 Cohesityではこのストライプ数をユーザーが指定することができ、「EC2:1」や「EC5:2」というようにM:Nの比で表記されます。 前項(M)がデータストライプ数、後項(N)がコードストライプ数を表しています。 例えば「EC2:1」であれば、Chunkfileを2分割したもの(データストライプ数2)と、パリティを1つ(コードストライプ数1)ディスクに書き込みます。 EC2:1の場合の実効容量は物理容量の2/3です。
以前「おすすめのResiliency設定はありますか?」という質問を頂いたことがありますが、特に推奨設定はありません。 ただし、以下のグラフのようにResiliency設定によって利用可能なディスク容量が変わる点にご留意ください。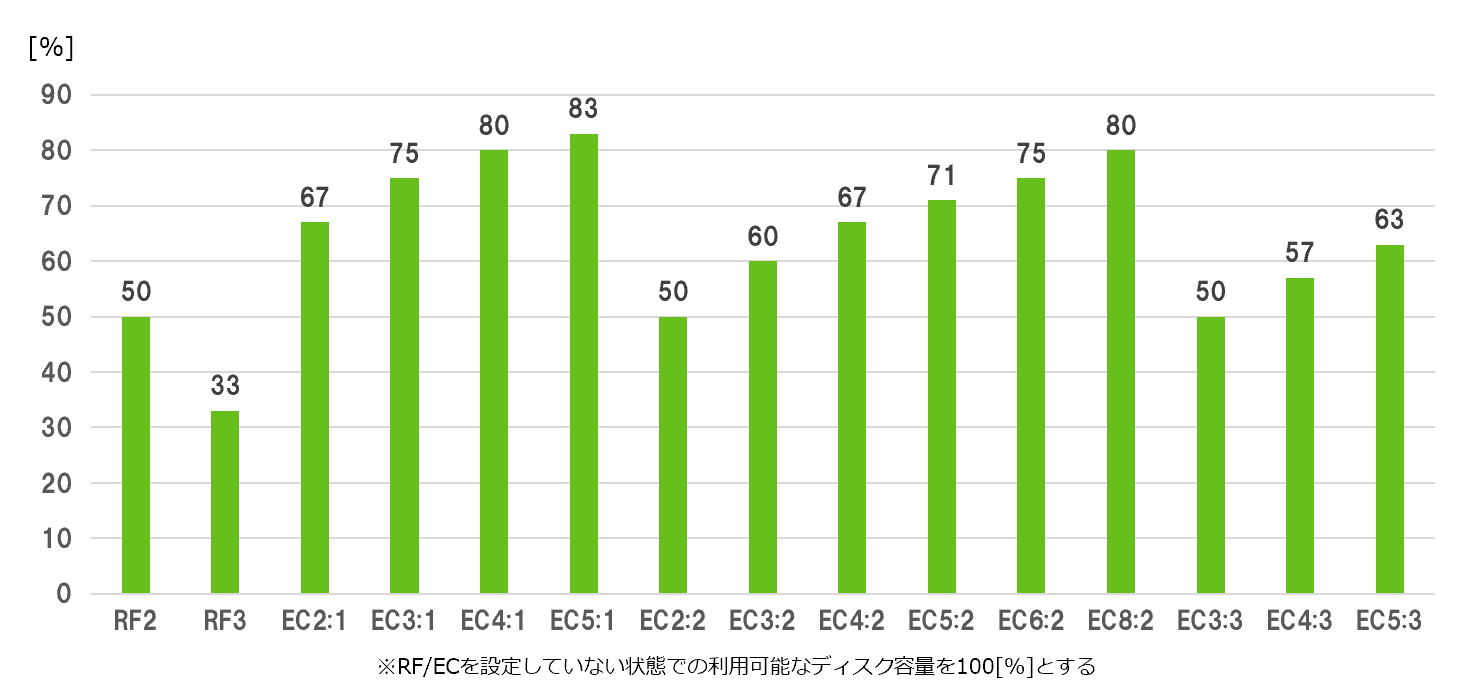 なお、RF2にするかRF3にするか / ECを何対何にするかについては、Clusterを構成するノード数やディスク / ノードの破損をいくつまで許容するかを考慮して決定します。 Cohesityのフォールトトレランスは「2D:1N」のように比で表されます。 例えば「2D:1N」であれば「2つのハードディスク(D=Disk)または1台のノード(N=Node)障害に耐えられる」ということです。 Cohesityではユーザーがこの「比」を決めることで、RFやECの設定を分かりやすく行えるようになっています。 ここでStorage Domain(ストレージドメイン)におけるフォールトトレランスの設定を実際に見てみましょう。 ストレージドメインの詳細設定に「フォールトトレランス」という項目があります。
なお、RF2にするかRF3にするか / ECを何対何にするかについては、Clusterを構成するノード数やディスク / ノードの破損をいくつまで許容するかを考慮して決定します。 Cohesityのフォールトトレランスは「2D:1N」のように比で表されます。 例えば「2D:1N」であれば「2つのハードディスク(D=Disk)または1台のノード(N=Node)障害に耐えられる」ということです。 Cohesityではユーザーがこの「比」を決めることで、RFやECの設定を分かりやすく行えるようになっています。 ここでStorage Domain(ストレージドメイン)におけるフォールトトレランスの設定を実際に見てみましょう。 ストレージドメインの詳細設定に「フォールトトレランス」という項目があります。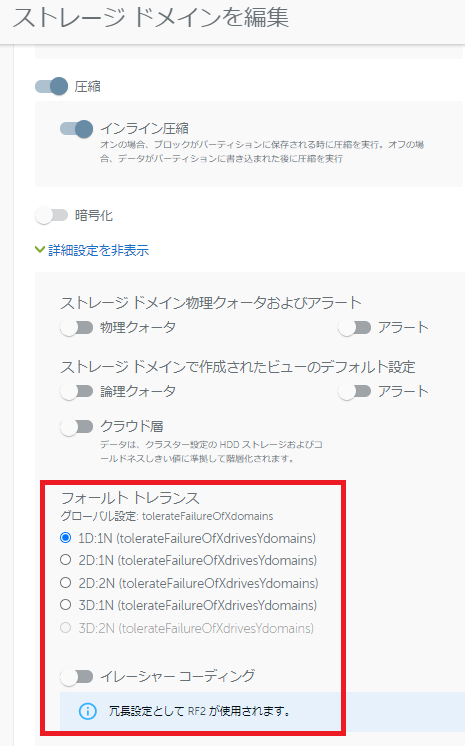 この環境は4ノードでクラスタリングしていますので、「1D:1N」~「3D:1N」が設定できるようになっています。 「1D:1N」(1つのハードディスクまたは1台のノード障害への耐性を持つ)でECが無効の場合、CohesityはRF2で稼働するようになります。 ECを有効にした場合は、ドロップダウンリストでEC2:1またはEC3:1が選べるようになります。
この環境は4ノードでクラスタリングしていますので、「1D:1N」~「3D:1N」が設定できるようになっています。 「1D:1N」(1つのハードディスクまたは1台のノード障害への耐性を持つ)でECが無効の場合、CohesityはRF2で稼働するようになります。 ECを有効にした場合は、ドロップダウンリストでEC2:1またはEC3:1が選べるようになります。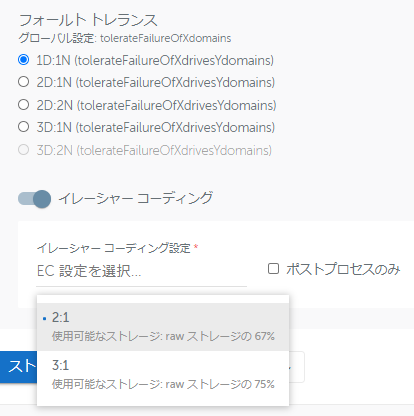 さらに「2D:1N」を選んでみると、EC無効の場合にはRF3で稼働するようになります。
さらに「2D:1N」を選んでみると、EC無効の場合にはRF3で稼働するようになります。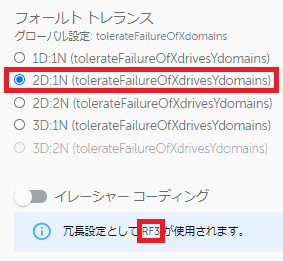 「2D:1N」でECを有効にすると、EC2:2~EC6:2がドロップダウンリストで選べるようになります。
「2D:1N」でECを有効にすると、EC2:2~EC6:2がドロップダウンリストで選べるようになります。 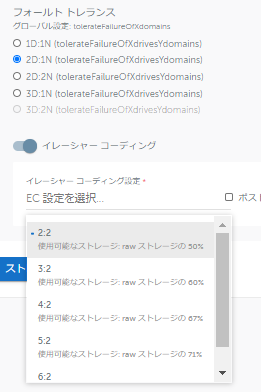 このように、Cluster内のノード数や障害への耐性をどの程度持たせるかを決めることで、RFやECを分かりやすく設定することができるようになっています。
このように、Cluster内のノード数や障害への耐性をどの程度持たせるかを決めることで、RFやECを分かりやすく設定することができるようになっています。
なお、Cohesityバージョン6.5からはラックやシャーシレベルでのフォールトトレランスも設定できるようになりました。
SnapTreeとは
Cohesityによるデータの「書き込み」処理を中心にご紹介しましたが、「読み出し」に関連した処理についてもご紹介します。
連載第5回でCohesityによるクローン機能をご紹介した際、弊社環境ではクローンVMの提供が十数秒で完了したとお伝えしました。 ここには「Cohesityが自身のディスク上でばらばらになっているデータを集める時間」も含まれています。
バックアップからのリカバリも含め、Cohesityは「ばらばらになっているデータを集める」能力に優れています。 これはCohesity独自の「SnapTree」によるものです。
さらにSnapTreeでは特にスナップショットの世代数上限が定められていません。 これはどのように実現されているのでしょうか。
従来のスナップショットとSnapTreeを比較してみましょう。
例えばAとBというデータから成るスナップショットがあったとして、データBが更新されるごとにスナップショットを取っていきます。一般的な従来製品のスナップショットは以下のようにデータが保持されます。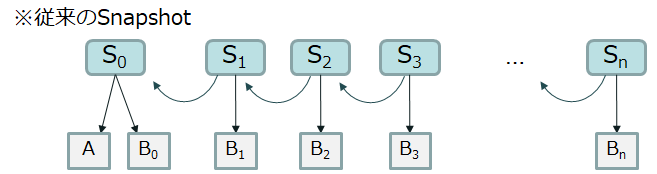
ここでスナップショットSnを使いたい場合、データAとBnが必要になります。 データAを参照するには、Snのひとつ前、さらにそのひとつ前、...というようにひとつずつ世代を遡る必要があります。 そうするとデータAに至るまでの「チェーン」が長くなってしまい、参照に時間がかかってしまいます。 スナップショットの世代数について上限が定められているケースがあるのはこのためです。 例えばVMware vSphereでは、ひとつのチェーンあたり最大32スナップショットまでがサポートされています。 さらにパフォーマンスを考慮した場合のベストプラクティスとしては2~3スナップショットです。 (詳細はVMware社のKBをご参照ください。)
スナップショットの世代数について上限が定められているケースがあるのはこのためです。 例えばVMware vSphereでは、ひとつのチェーンあたり最大32スナップショットまでがサポートされています。 さらにパフォーマンスを考慮した場合のベストプラクティスとしては2~3スナップショットです。 (詳細はVMware社のKBをご参照ください。)
一方でCohesityは独自の「SnapTree」により効率よくデータを参照することができます。SnapTreeではB+ツリーの木構造が採用されており、ポインタでデータにアクセスします。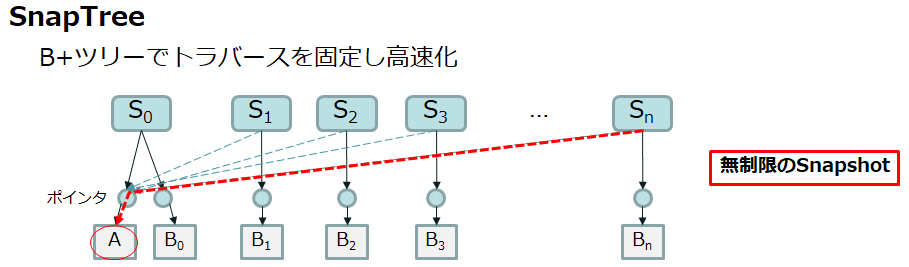
データAを使う場合に以前のスナップショットを参照しなくてよいため、このぶん時間が短縮されます。 いくつもの世代数を遡ったとしても、ポインタにより迅速に実データにアクセスできるようになっていますので、特にスナップショット数の上限値が定められていません。
ストレージとバックアップサーバーが一体になったCohesityならではの強みとも言えるでしょう。
連載「かんたんCohesity」の番外編ということでDeep Diveをお送りしました。
内部仕様をご紹介したためやや複雑な内容になってしまいましたが、CohesityのDashboardはこのようなテクノロジを深く理解していなくとも利用できるユーザーフレンドリーなつくりになっています。
弊社ではCohesityの貸出機をご用意しておりますので、ぜひ一度体感頂ければ幸いです。
本稿をもちまして連載「かんたんCohesity」は完結です。 お読みくださりありがとうございました。
とはいえ、本連載でご紹介できたのはCohesityの機能の基礎的な部分のみです。 皆様にCohesityの良さをより深くご理解頂くべく、引き続き様々な機能をご紹介していきたいと思います。 直接お目にかかる機会もあるかと思います。 Engineer Voiceでのテクノロジ解説や検証レポート等のリクエストがありましたら可能な限り対応したいと思いますので、お気軽にお声がけください。
※ サービスや製品の仕様ならびに動作に関しては、予告なく改変される場合があります。
※ 本ブログはCohesity バージョン6.5.1ならびに2020年9月時点の情報に基づいて記載しています。 後継バージョンにおける仕様変更等についてはメーカードキュメントをご確認ください。
※ 図表の修正を行いました。(2021/11/16)
Cohesity社ウェブサイト: https://www.cohesity.com/ja/
Cohesity関連記事の一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄




