


2021年3月15日よりAutomation Anywhere Enterprise A2019はAutomation Anywhere Automation 360へ名称が変更となりました。
みなさまこんにちは。清水勇弥です。
この記事ではWebサイトからの情報取得を安定化かつ高速化させるHTML Parserパッケージをご紹介します。(パッケージのバージョンは1.0.3)
Webサイトから情報を取得する際にはWebページをブラウザで表示させ、キャプチャでプロパティを取得するという流れが一般的ですが、それらの代替手段となります。一歩進んだRPAの運用を目指す方は活用いただければと思います。
本記事は一定のBotの開発経験をお持ちの方を対象としており、基礎的な事項の説明を省いています。
目次
1.使用方法
1-1.事前準備
1-2.アクションの種類と使い方
1-2-1.取得
1-2-2.検索
1-2-3.変換
2.HTML Parserパッケージによる検索の効果
2-1.安定化
2-2.高速化
3.制約
4.まとめ
1.使用方法
今回は応用編ということで諸々の論述は後回しにし、より実践的に使用方法からご説明します。
1-1.事前準備
HTML Parserパッケージは標準搭載のパッケージではないため、Bot Storeから取得します。
Automation Anywhere社が提供しているパッケージで、ダウンロードおよび使用は無料です。
ただし、「Community Support Only」となっており、問題や不明点があってもサポート窓口での対応はありません。フォーラムなどで有識者に質問する必要がありますのでご注意ください。
なお、Bot Storeからのパッケージ取得方法はこちらの記事(BotStoreの使い方)をご確認ください。
1-2.アクションの種類と使い方
パッケージには以下5つのアクションが含まれています。
【1】Advanced Search with RegEx(正規表現による高度な検索)

【2】Get HTML Content(HTMLコンテンツの取得)
【3】Convert HTML to XML(HTMLをXMLへ変換)
【4】Search with Selector(セレクターによる検索)
【5】Simple Search for Elements(要素の簡易検索)
表示される順序では上の通りとなりますが、使用順は異なります。ここでは使用順となる機能分類別にご紹介します。
1-2-1.取得
【2】Get HTML Content(HTMLコンテンツの取得)
URLまたはHTMLファイルをHTMLソースとして指定することでHTMLを文字列の変数として出力できます。
試しにYahoo!JAPANのトップページを指定してみます。すると、下図のように結果が出力されます。
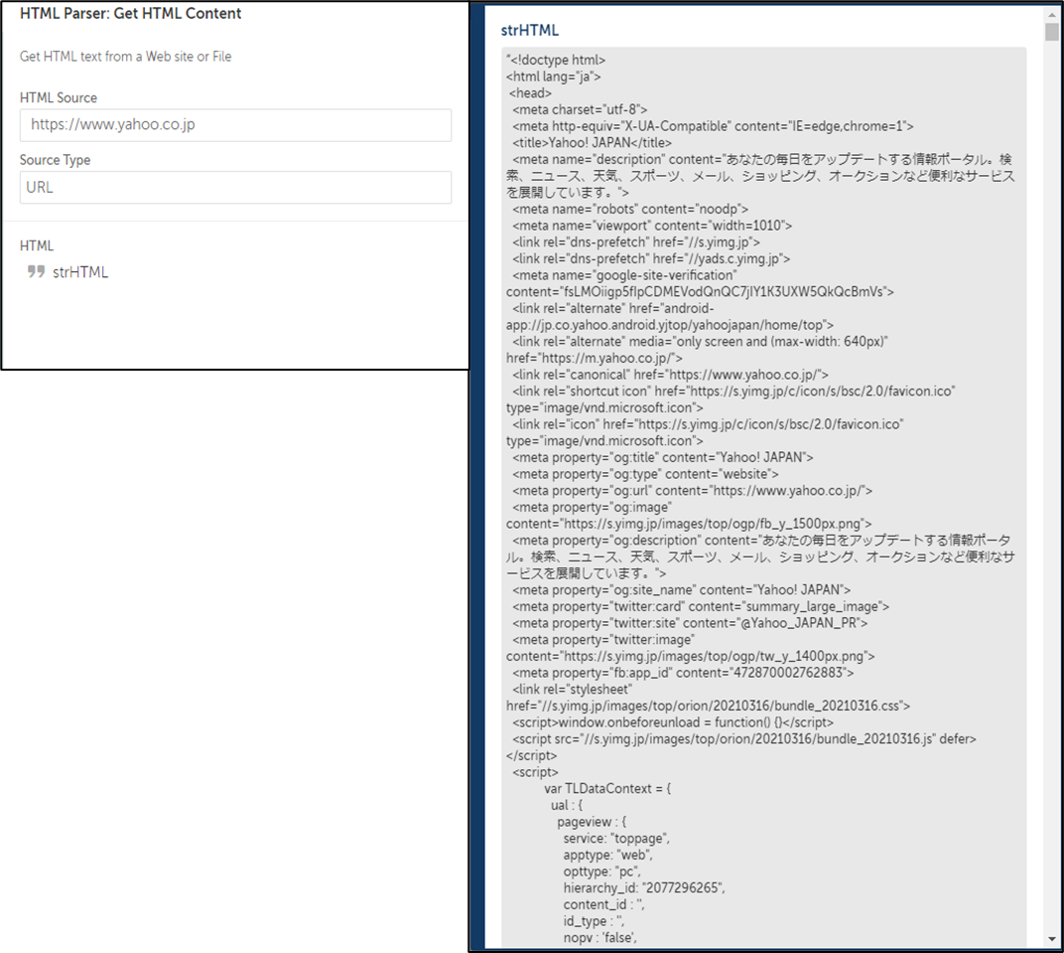
このアクションで出力するHTMLの文字列変数は他のアクションのインプットデータとして再利用することになります。
1-2-2.検索
【5】Simple Search for Elements(要素の簡易検索)
HTMLの文字列をインプットデータにし、HTMLのtagやid、class、textといった要素を選択しその属性を指定することで、対象となるHTMLの要素を全て抽出するアクションです。
例えば「tag」を選択し、「a」と指定した場合、ハイパーリンクに関する要素を全て抽出することができ、結果は下図のようにディクショナリタイプのリスト変数で出力されます。
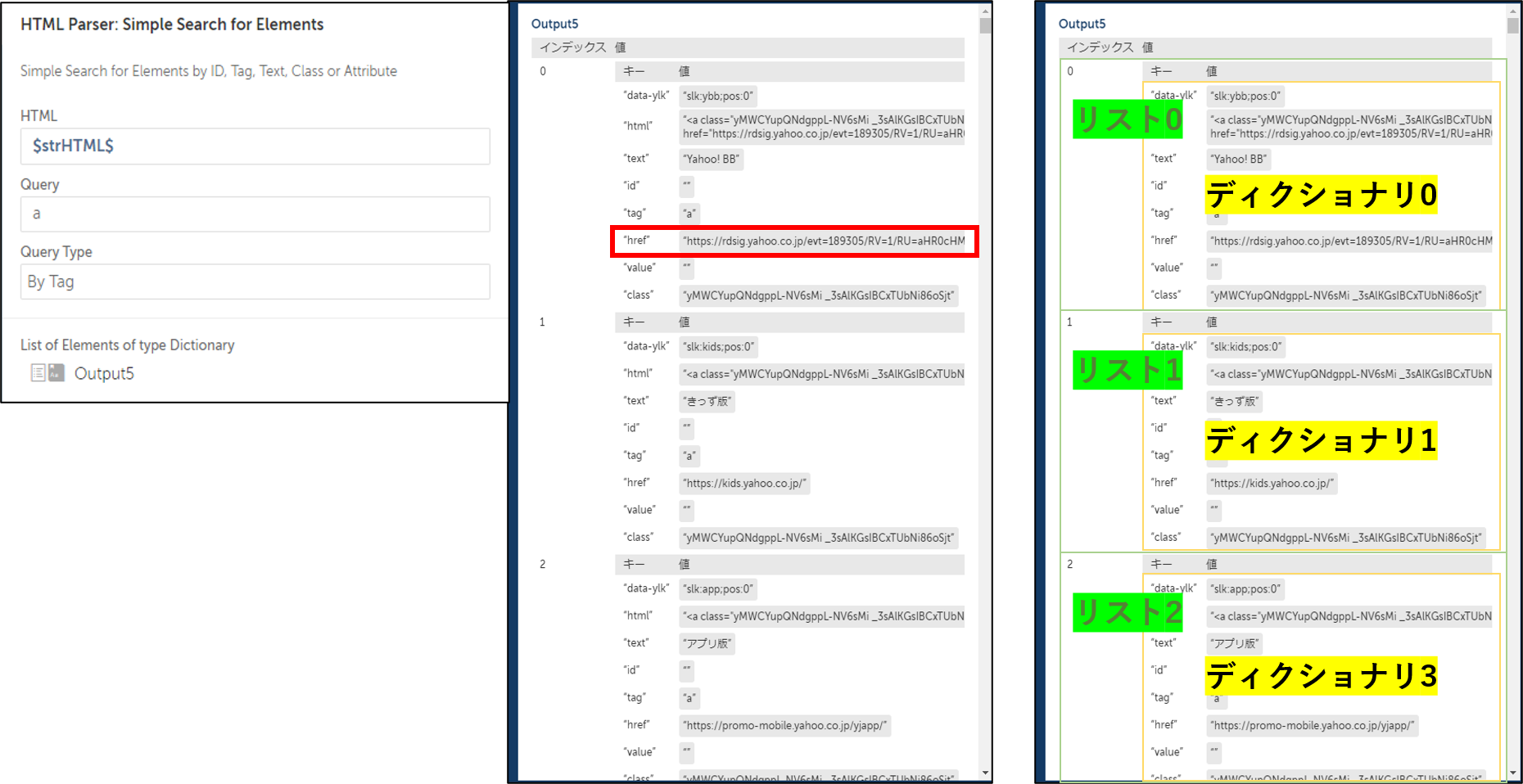
出力された要素の値を変数で指定する方法は
$変数名[インデックスの番号]{キーの値}$
とします。
例えば、上から1つ目のリンク先URL(上図の赤枠の項目)を他のアクションで使いたい場合は
$Output5[0]{href}$
と指定します。
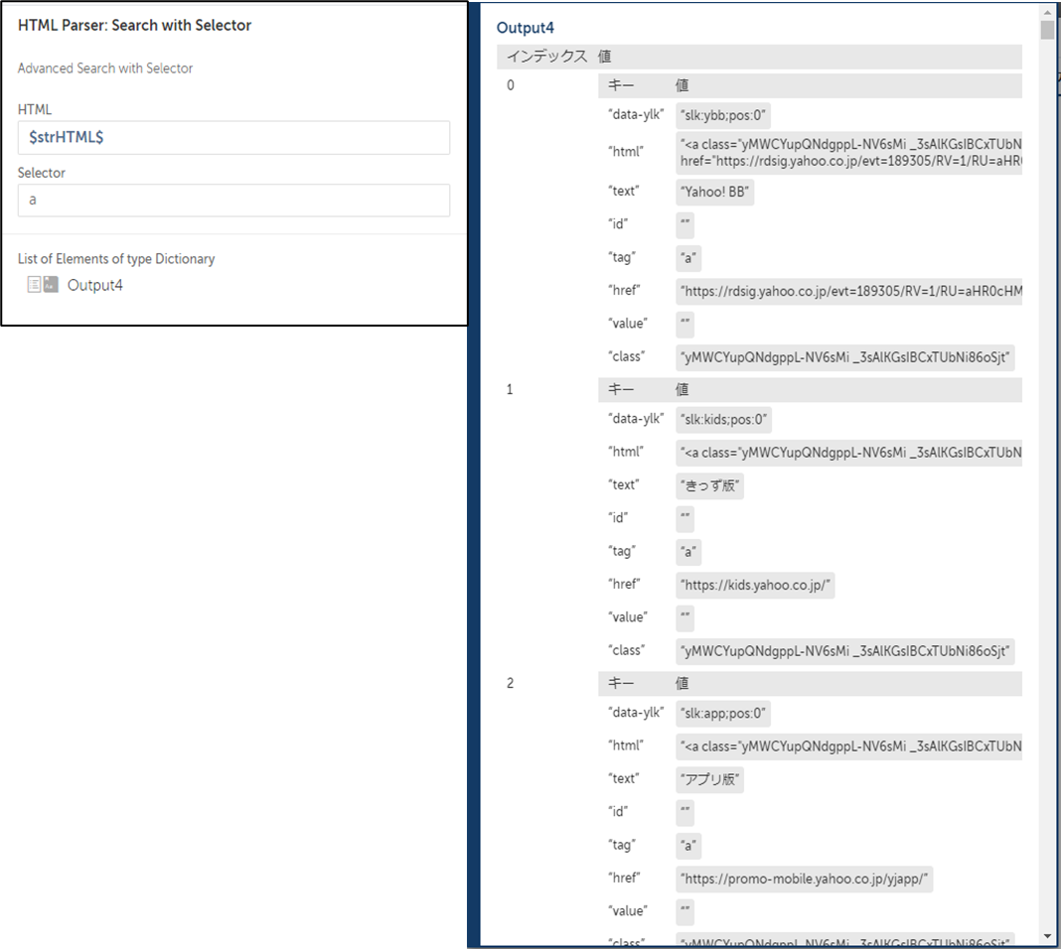
【4】Search with Selector(セレクターによる検索)
同様の検索機能ですが、こちらはセレクター式によって対象のHTMLの要素を抽出するアクションです。複合的な条件を指定できるため、複雑な構造のWebページに適しています。
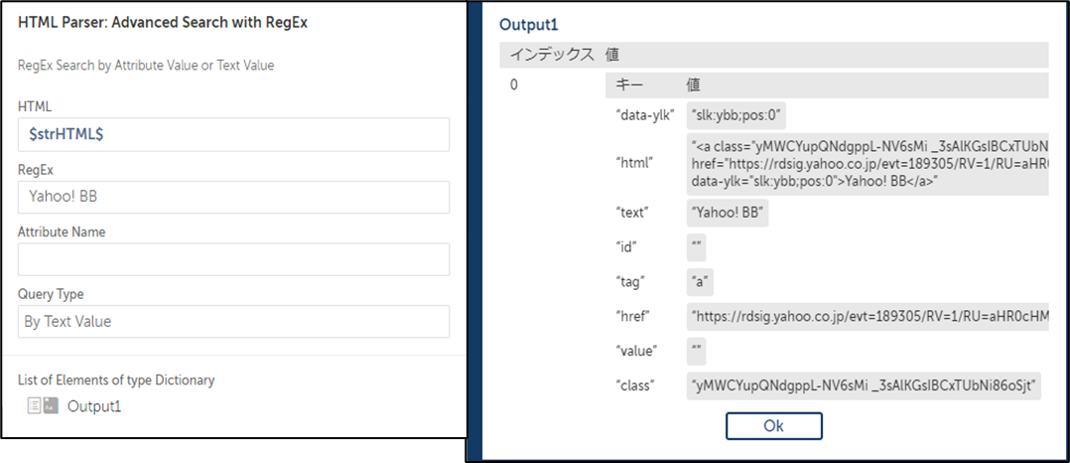
【1】Advanced Search with RegEx(正規表現による高度な検索)
こちらは正規表現による検索機能です。前の2つの検索機能よりもさらに複雑な指定が可能です。正規表現についてはこちらのサイトなどを参考にしてください。
1-2-3.変換
【3】Convert HTML to XML(HTMLをXMLへ変換)
取得したHTMLをHTMLをXML形式に変換します。HTMLが構造化されるため、後続のアクションで操作が容易になります。記事の主旨とは逸れますので、詳細は割愛します。
2.HTML Parserパッケージによる検索の効果
ここからはHTML Parserパッケージで検索することによる効果を安定化、高速化の観点でご説明します。
2-1.安定化
Webページをブラウザで表示し、キャプチャでプロパティを取得する場合、アクセス先のサーバーの応答が安定しないことやRunnerのクライアントにおいて予期せぬ挙動、操作が発生することで異常終了してしまいます。
アクセス先のサーバーが全く応答しない場合は異常終了を防げませんが、多少トラフィックが混雑しているような状況では、HTMLだけを取得しており受信するデータ量が少ないために受ける影響が小さくなります。
また、クリックやキーストロークなどのクライアントのユーザーインターフェースの操作が発生しないため、Attendedの環境ではBotを実行しながら他の作業をすることも可能です。
「RPAあるある」の1つとして、ソフトウェアやOSの自動アップデートで異常終了するということをよく耳にしますが、クライアントがシャットダウンされない限りBotは動き続けることができますので、その対策としても有効です。
2-2.高速化
前述の通り、HTML ParserパッケージではWebサイトからはHTMLだけを取得しているためダウンロードする容量が少なく、さらにブラウザでの表示もしないので処理時間をかなり短縮できます。
具体的な比較の例を挙げますと、某株価サイトから2020年12月末時点の4,088件の東証上場銘柄の前日終値を取得するBotを作成し計測したところ、キャプチャアクションでは開始から終了まで3時間7分かかりました。
そのBotが稼働している間はRunnerのクライアントとライセンスを占有してしまい他のBot実行ができませんので、これでは資源効率の面でもよくありません。
一方、HTML Parserパッケージではわずか24分で完了しました。同じ結果を得られたのですが87%もの時間を削減できました。もちろんネットワークやハードウェアの使用状況は異なりますが、それだけでは説明がつかないほど大幅な削減ができることは伝わるかと思います。
なお、稼働時間が削減できると予期せぬ異常終了の発生も抑制されるので、循環して安定化にも寄与します。
3.制約
これまでご説明した通常の使用方法では、過去2つの場合で使用できませんでした。HTML Parserパッケージで項目を取得することができないか、もしくは何らかのひと手間加える必要があると思われます。
第1にログインを必要とするWebサイトの場合です。
ログイン後に発行されるセッションIDを保持したままWebサイト上を遷移しなければなりませんが、セッションIDに関する項目が無いので、毎回新しいWebアクセスになってしまいます。
ログインセッションを引き継ぎながら処理させることや、HTMLを取得するURLのパラメータにユーザーIDとパスワードを付与してアクセスさせるなどの手段が考えられます。
詳しい方はぜひ挑戦してみていただきたいですが、セキュリティホールとならないようご注意ください。
第2にJavaScriptで動的にHTMLが発行されているWebサイトの場合です。身近な例ですとAutomation AnywhereのProduct Documentationのサイトがこちらにあたります。
HTMLを取得しても、JavaScriptが呼び出されているソースのみで、動的に発行される実際の各種項目は取得できません。
4.まとめ
いかがでしょうか?
最初はWebサイトのHTML構造を把握するのに試行錯誤が必要になるかと思います。ですが実装できた際の効果は抜群ですのでぜひチャレンジしてみてください。
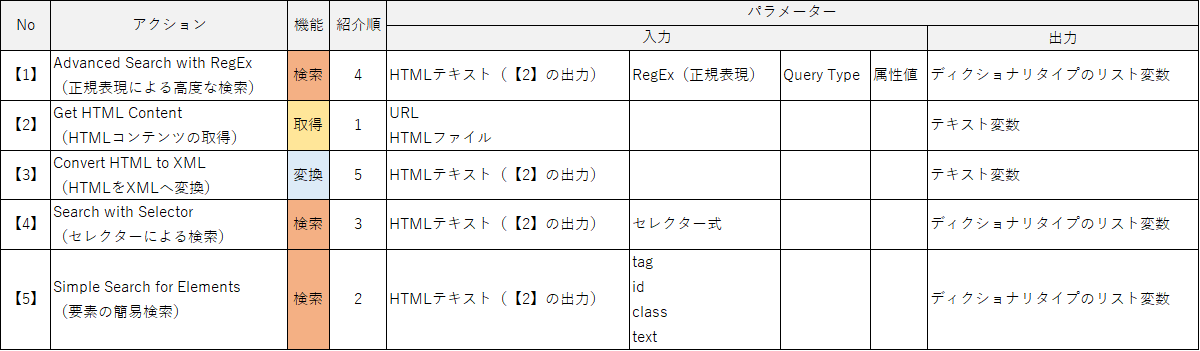
以下にパッケージの各アクションの入出力をまとめました。検索機能が3種類もあり、それぞれの特性を把握しながら使い分ける必要も出てきますので使用する際の参考資料としてお使いください。

他のおすすめ記事はこちら
著者紹介

先端技術推進統括部
RPAビジネス推進部
清水 勇弥
ひとり西日本チーム




