

こんにちは、SB C&Sの幸田です。
vGPUのブログ連載、第4回目となる今回は、物理的なGPUがもつプロセッサー部分やメモリ部分などのリソース、vGPUにいおいてどのように分割利用されているのかを解説します。
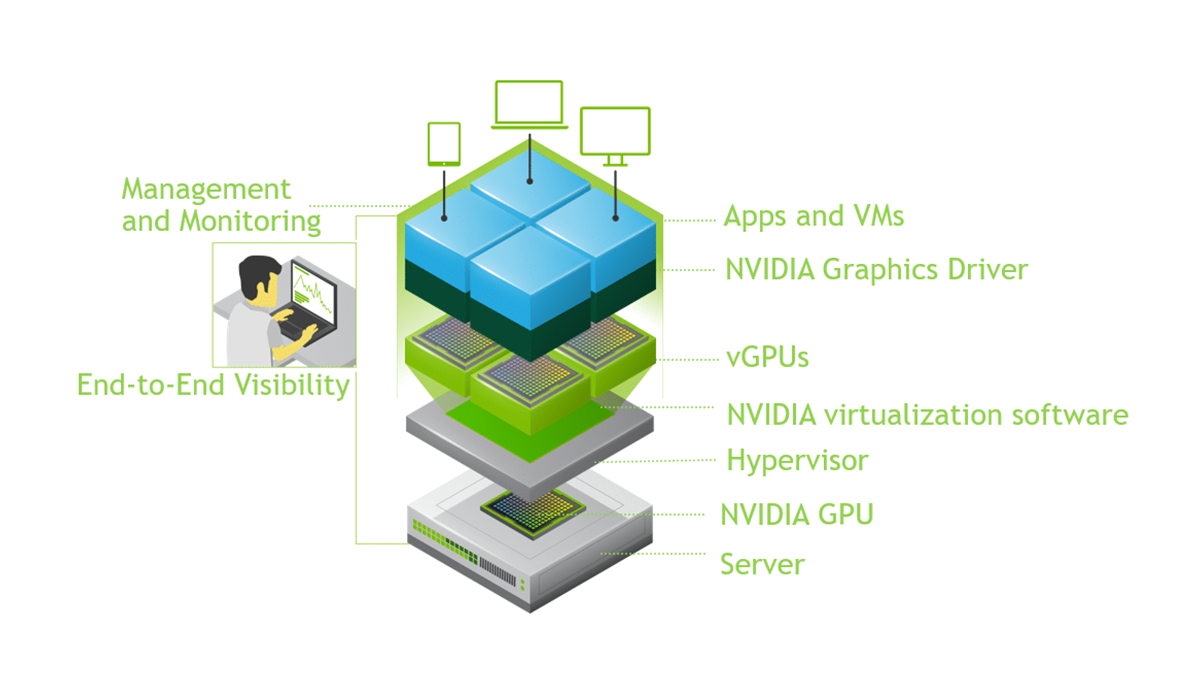
サーバーの仮想化では、CPUやメモリなどのコンピューターリソースが分割され、仮想マシンに利用されます。サーバーに搭載されたGPUも、これらと同様に複数の仮想マシンで利用可能とするための分割利用の方式が実装されています。
それでは具体的なご説明に入ります。
GPUに含まれるリソース
まずはGPUの中に搭載され、vGPUによって分割されるリソースにどのようなものがあるかをご説明します。本記事では、GPUに含まれるリソースのうち主要な2つをピックアップしてご説明します。

コア
ひとつは実際の演算処理を行うコアです。CPUと同じように複数のコアで構成されています。CPUとの大きな違いはそのコアの「数」だといえるでしょう。この記事を執筆している2023年時点では、市場に流通しているCPUの最大コア数は128です。対してGPUは、ハイエンドクラスのものについては10,000を超えるコア数を持っています。CPUのコアは複雑な処理を得意としますが、GPUのコアは単純な処理に最適化されており、膨大な数の単純な演算を同時に行う「並列処理」に特化しています。
フレームバッファ
もうひとつはフレームバッファです。グラフィックスメモリ、あるいはGPUメモリなどと呼ばれることもあります。フレームバッファは、コアで処理するためのデータを一時的に置いておくための領域として機能します。現時点で最も大きなフレームバッファ容量をもつvGPU対応のGPUはNVIDIA A16であり、その容量は64GBです。なお最新のGPUアーキテクチャであるHopperを採用したNVIDIA H100は80GBのフレームバッファを持ちますが、2023年1月時点ではvGPUに対応しておりませんのでご注意ください。
それではここから、それぞれのリソースが仮想マシンによってどのように分割利用されるかをご説明します。イメージしやすくするため、仮想環境のハイパーバイザーと仮想マシンも図示しています。
コアはタイムスケジューリング
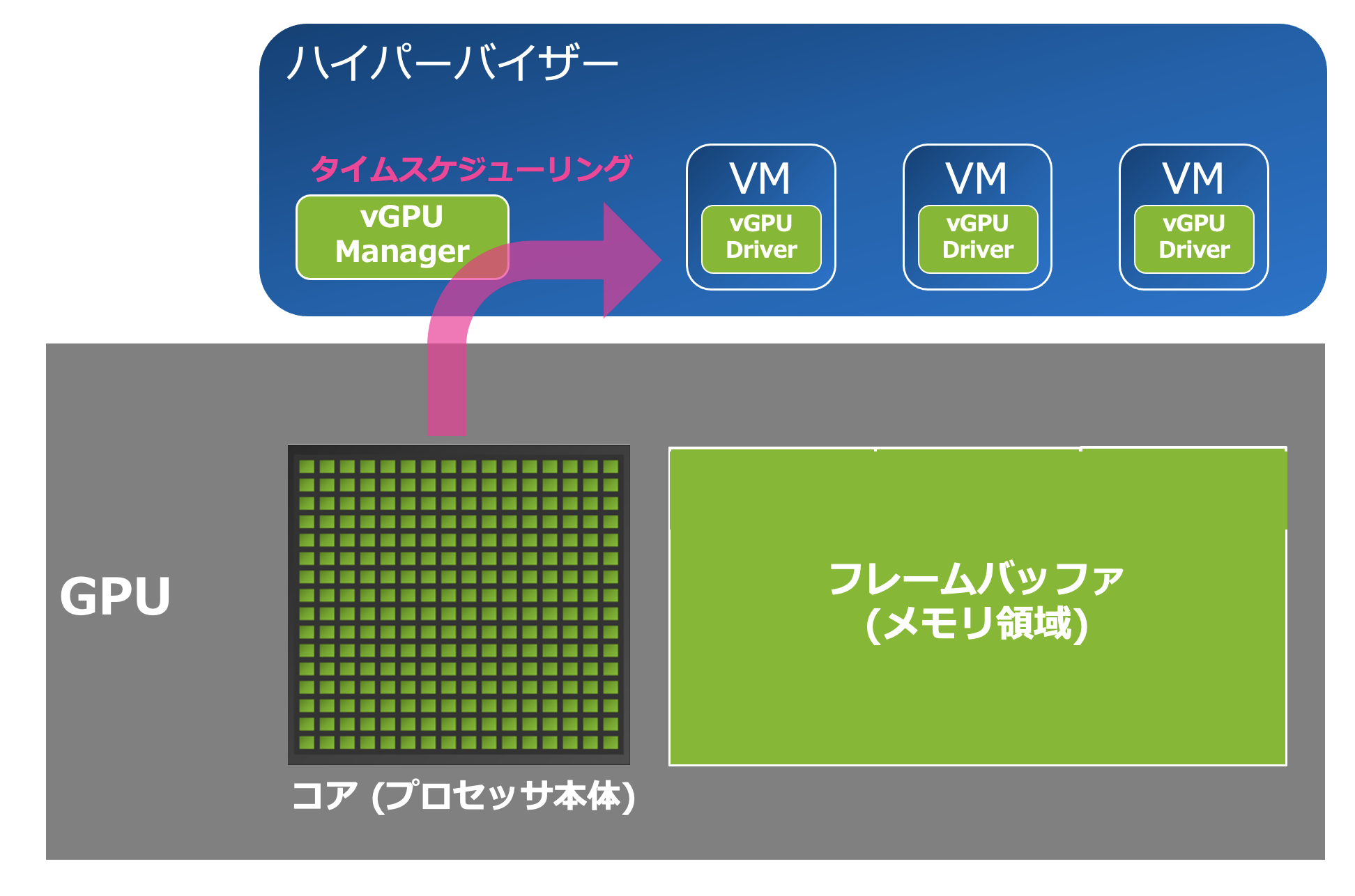
GPUのコアはスタイスケジューリングによって分割利用されます。つまり非常に短い時間ごとにコアを利用させるvGPUを切り替えることで、複数のvGPUによるコアの利用を実現しています。
スケジューラーには3つの方式があり、これらは設定変更によって切り替えることが可能です。それぞれの方式についてご説明します。
① Best Effort Scheduling - ベストエフォート
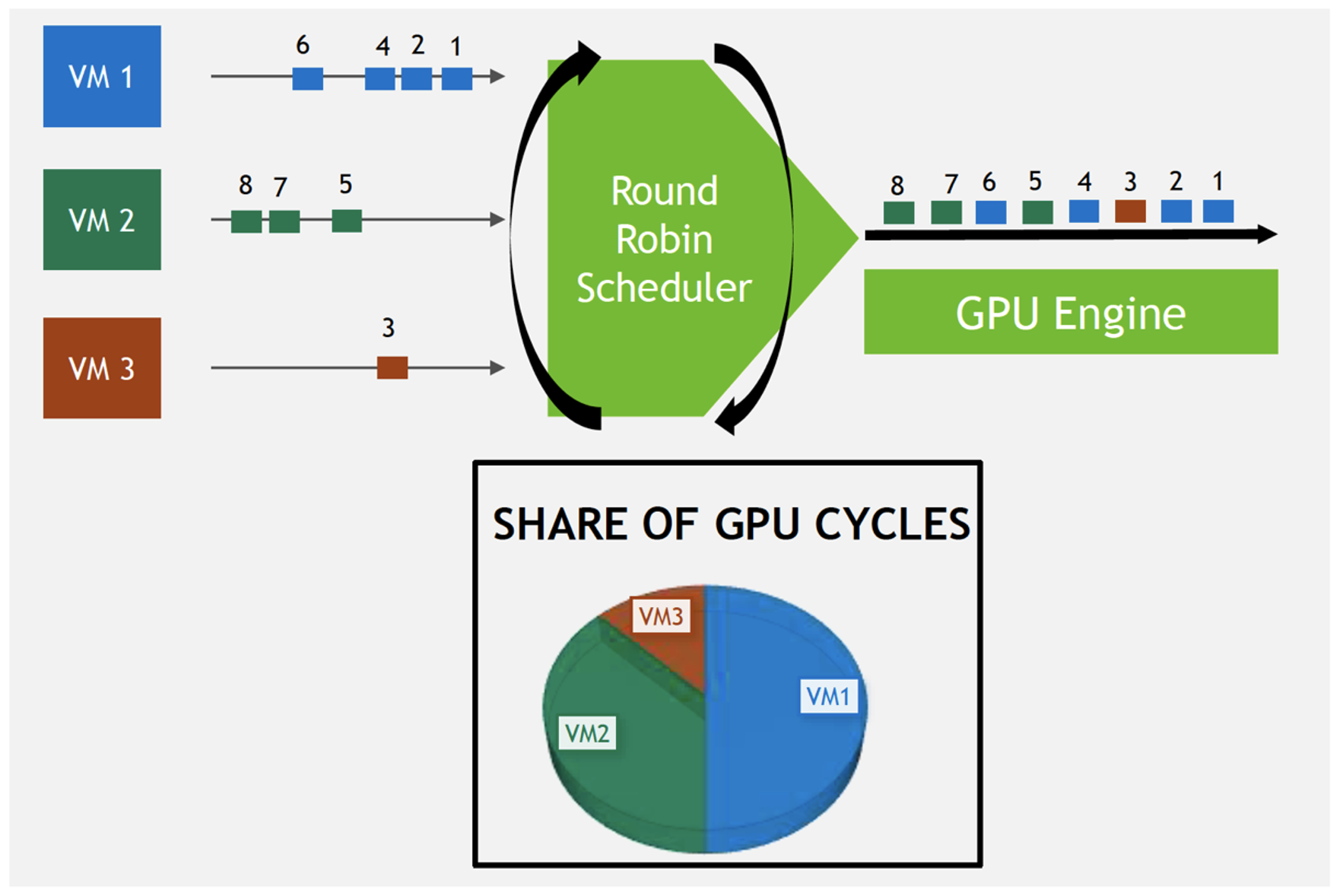
※図中左にあるVMが、vGPU割り当て済みの仮想マシンを表しています
"ベストエフォート" は、単純なラウンドロビンでコアを利用するvGPUを切り替える方式です。デフォルトで設定されており、VDIでのvGPU利用時には一般的にこの方式が採用されます。
ただしBest Effortでは、長い時間のかかる処理がvGPUから要求された場合、その処理が完了するまで当該のvGPUにコアが占有されてしまうという問題が生じます。
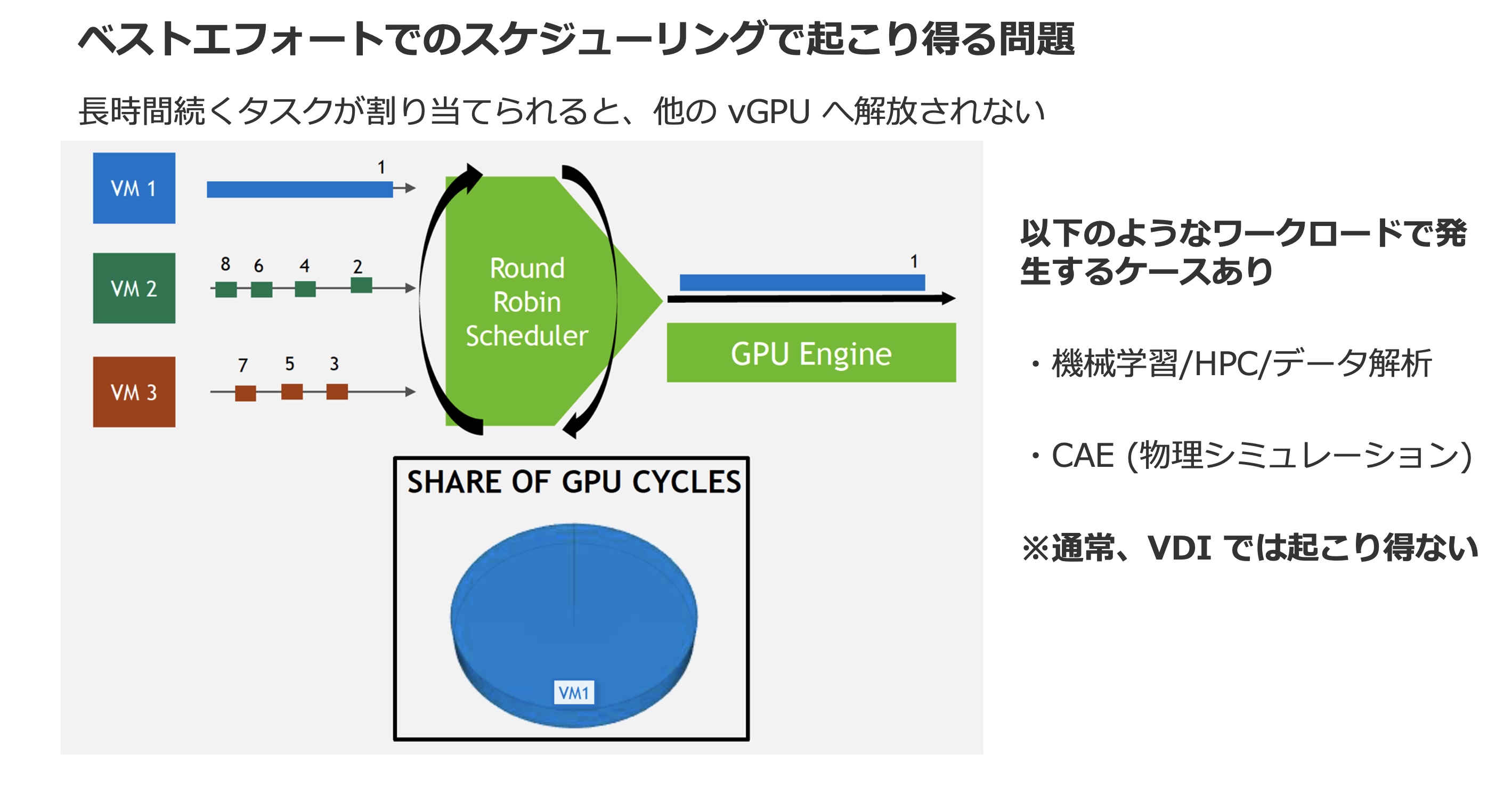
この問題への対処が施されたスケジューラーが次の Equal Share です。
② Equal Share - 等分シェア
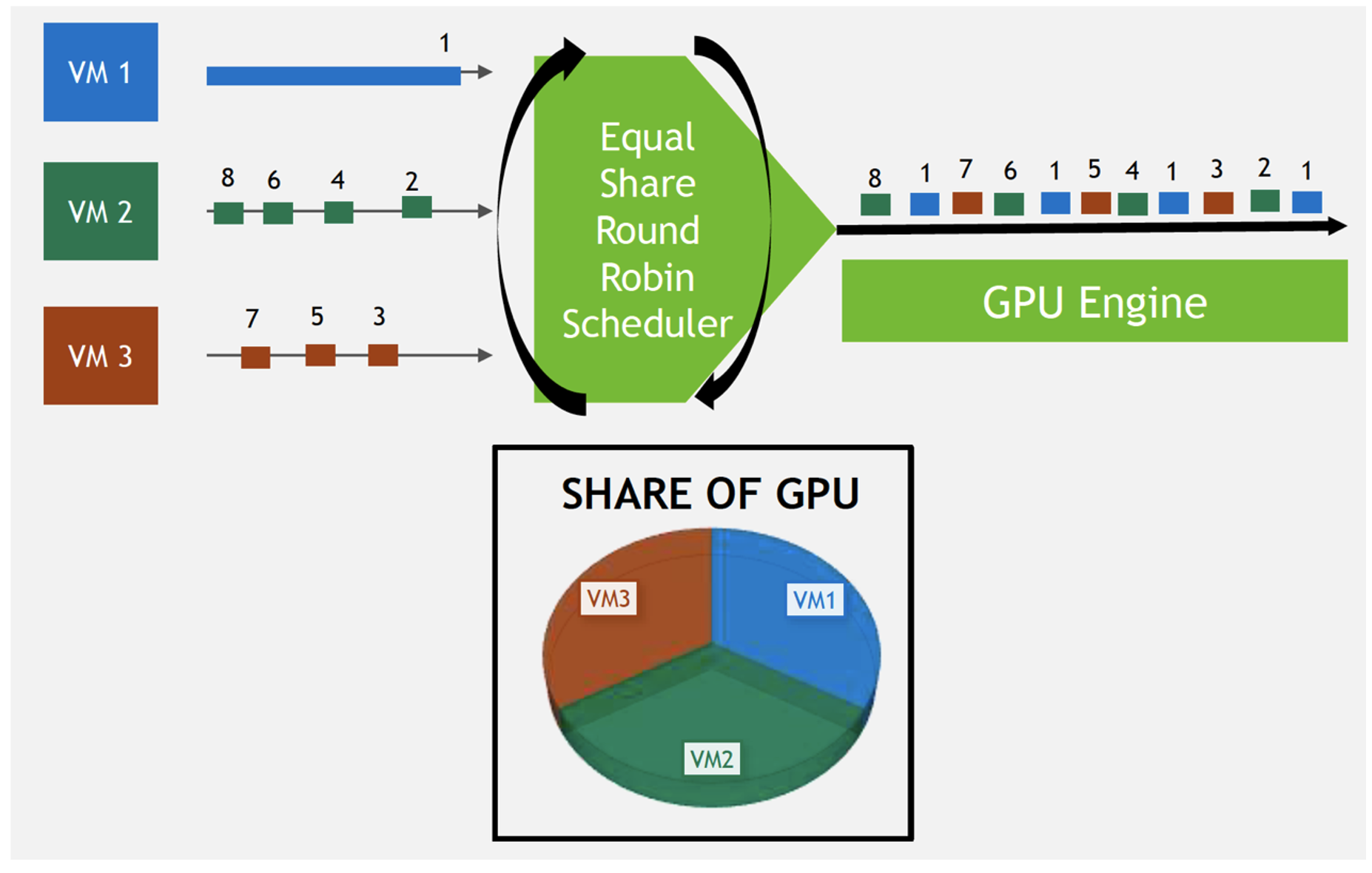
このスケジューラーは、各vGPUが一定の時間内にコアを使用できる時間を等しく保ちます。長時間の処理を実行しようとしているvGPUが出てきた場合、その処理は状態を保存したうえで一時中断され、コアが他のvGPUのタスクに明け渡されます。他のvGPUが一定の時間を配分されてGPUを使い終わり、長時間の処理を行なっていたvGPUにまた順番が戻ってくると、一時中断されていた処理が再開されます。
③ Fixed Share - 固定シェア
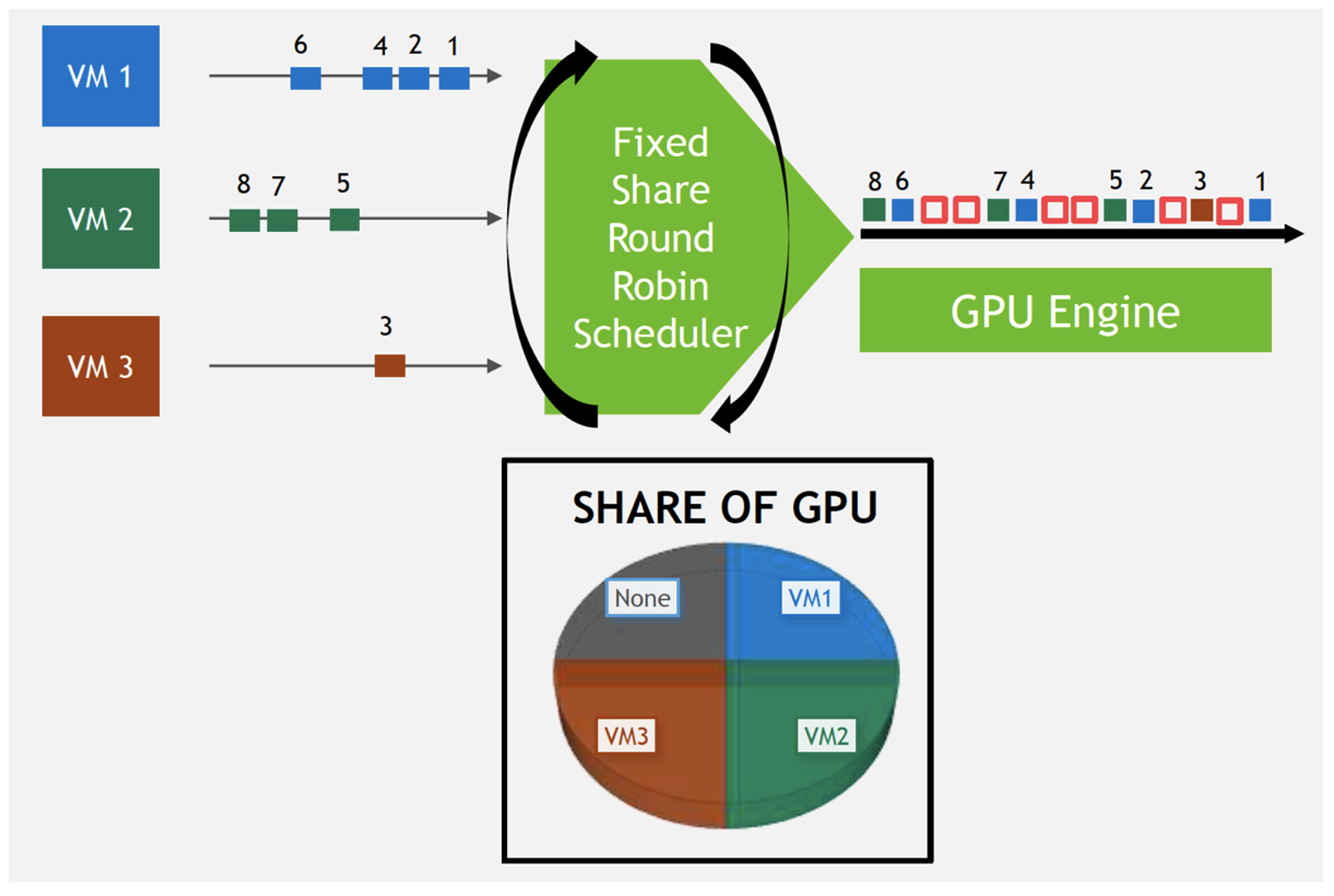
このスケジューラーは、各vGPUが利用できる時間枠をあらかじめ決定します。あらかじめ予約されている時間を過ぎるとコアの利用は中断され、次の仮想マシンに割り当てられます。
特殊なケースでのみ利用されるもので、例えばコンピューターリソースの配分をSLA (サービスレベルアグリーメント) で厳しく定義しているクラウドサービス基盤がそれにあたります。事前に利用者へ向けて提供するGPU性能を定めており、それを確実に確保したい時などに、こちらのスケジューラーが選択されるケースがあります。
例に挙げたようなケースでは有用なのですが、 ある特定のvGPUから処理要求が無かったとしても、そのvGPUに割り当てられた時間帯を他のvGPUのために融通する、といった動作はできないため、通常のVDIなどでこのスケジューラーを選択してしまうと、無駄が生じてしまいがちです。飽くまでも特殊用途向けのスケジューラーであるとご認識いただければと思います。
なおスケジューラーについては、NVIDIAの公式ドキュメントで詳細な解説がなされています。
フレームバッファ(メモリ)は占有
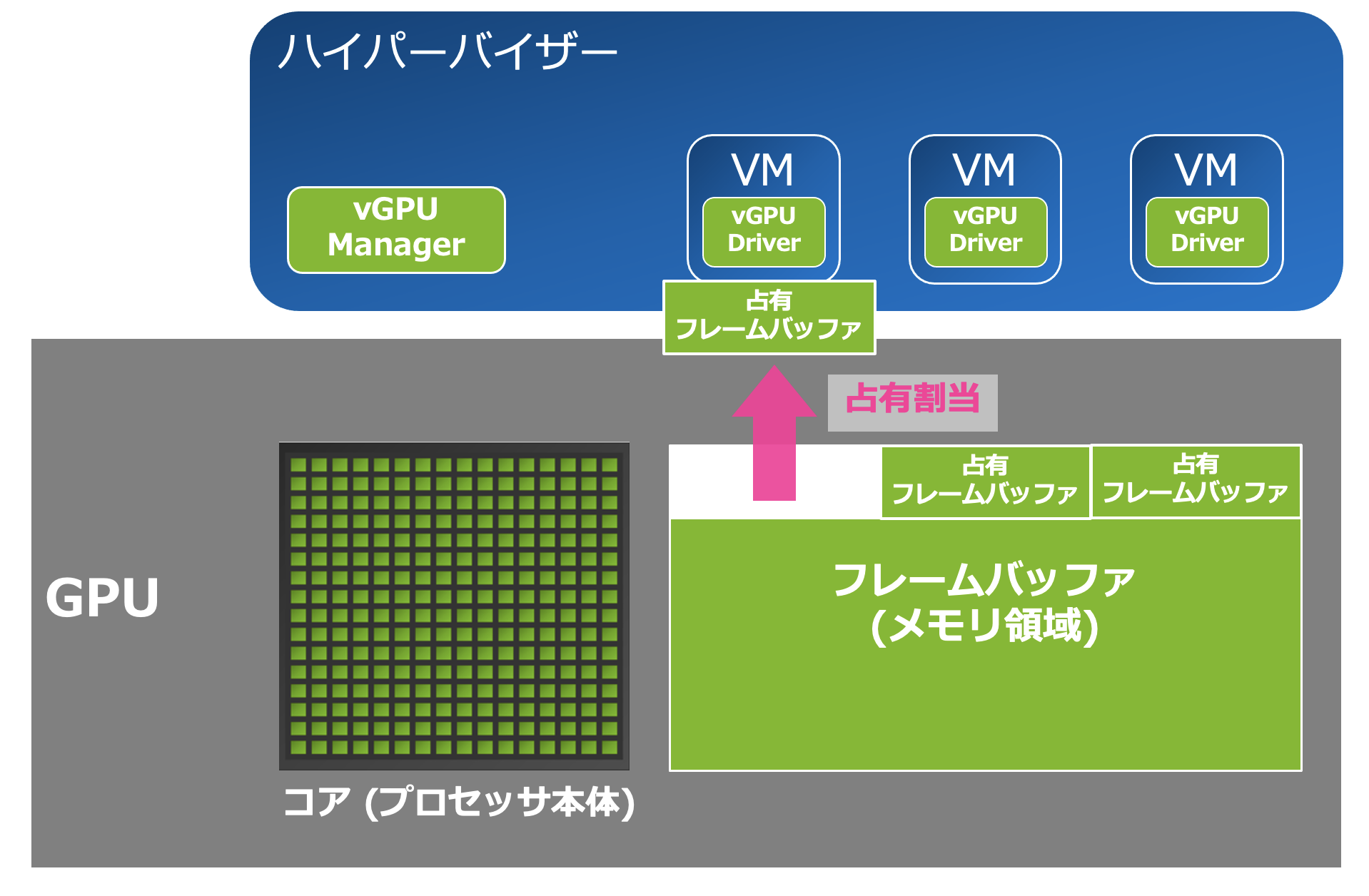
処理対象のデータを一時的に配置する領域であるフレームバッファですが、こちらは各vGPUが一定の容量を占有します。NVIDIAのデータセンター向けGPUは、数GB〜数十GBの容量のフレームバッファをもっており、これをvGPUごとに1GB〜数GBずつ割り当てることが一般的です。
もちろん要件によっては、1つのvGPUに10GB以上、あるいは20GB以上といった容量を割り当てるケースも存在します。
ひとつ留意すべきこととして、ひとつのGPUからvGPUのフレームバッファを分割する際、フレームバッファの容量は均一でなければならないという制限があります。サイジングの際などはこちらを念頭に置いていただくとよいでしょう。
例えば、3Dグラフィックスを用いる仮想デスクトップなどで利用が盛んなモデルである NVIDIA A40 の場合、48GBのメモリ容量を持っています。8GBずつフレームバッファを分割してvGPUを生成する場合、vGPUは最大6つまで利用可能です。24GBずつ分割する場合であれば、vGPUは最大2つです。
まとめ
vGPU利用時、どのように主要なリソース (コア、フレームバッファ) がシェアされるかについて要点をまとめました。
・主要なリソースとして、コアとフレームバッファ(メモリ)が存在する。
・コアはタイムスケジューリングで利用され、スケジューラーは3つのうち1つを選択する。
・フレームバッファは占有割当される。1つのGPUから生成するvGPUのフレームバッファサイズは均一
以上、本記事ではNVIDIA vGPU におけるリソース分割について解説しました。
引き続きvGPUについての情報を発信して参りますので、ぜひともご一読ください。
関連記事
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
幸田 章 - Akira Koda -
NVIDIA製品を中心としたコンピューティング(グラフィックス, AI/HPC)とネットワーキング、VDI を含む仮想化、クラウド等のプリセールス・エンジニア業務に従事。
VMware vExpert 2015-2022




