こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
この記事はその第5回目です。第1回目では基本的な概念について、第2回目では必要な環境準備について説明しました。また、第3回目ではAIモデルのトレーニング前のデータ準備やCommunications Miningへのセットの仕方を説明し、第4回目ではタクソノミーについて紹介しました。
この記事では、いよいよAIモデルのトレーニングを開始していきます。
AIモデルのトレーニングは、「発見」「探索」「検証」などいくつかのフェーズに分かれています。今回は「発見」ページでのトレーニングをしていきます。
目次
1. 「発見」ページでのトレーニング
1-1. クラスター
1-2. 検索
2. 最後に
1. 「発見」ページでのトレーニング
それでは早速トレーニングを開始していきましょう!
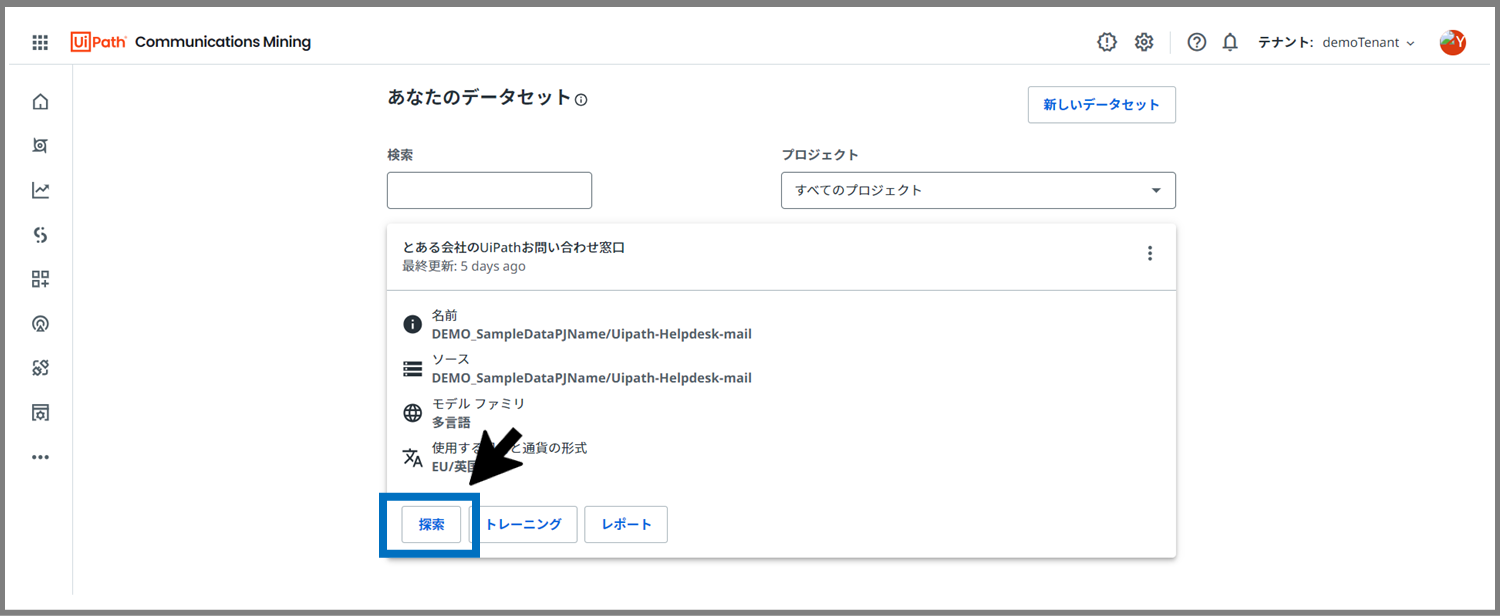
Communications Miningのトップページにいくと、3回目の記事で作成した上記のようなデータセットがあると思います。ここの「探索」ボタンをクリックします。
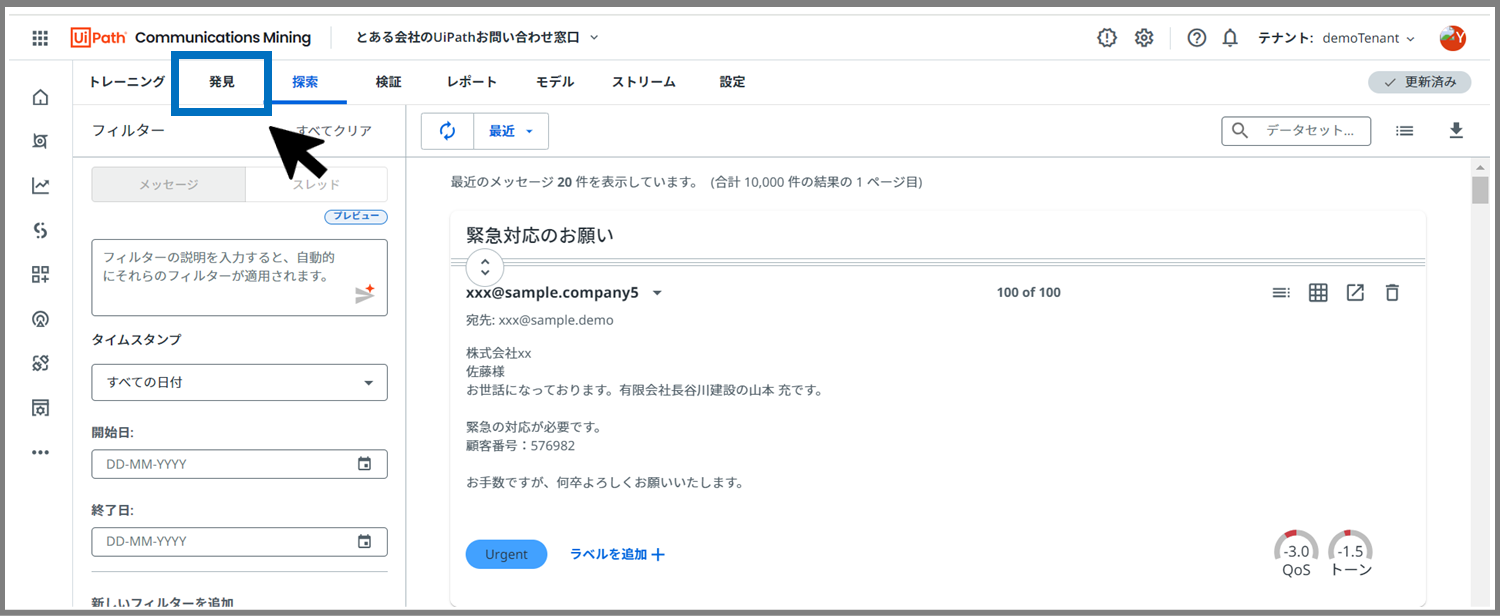
次に、「発見」タブをクリックします。
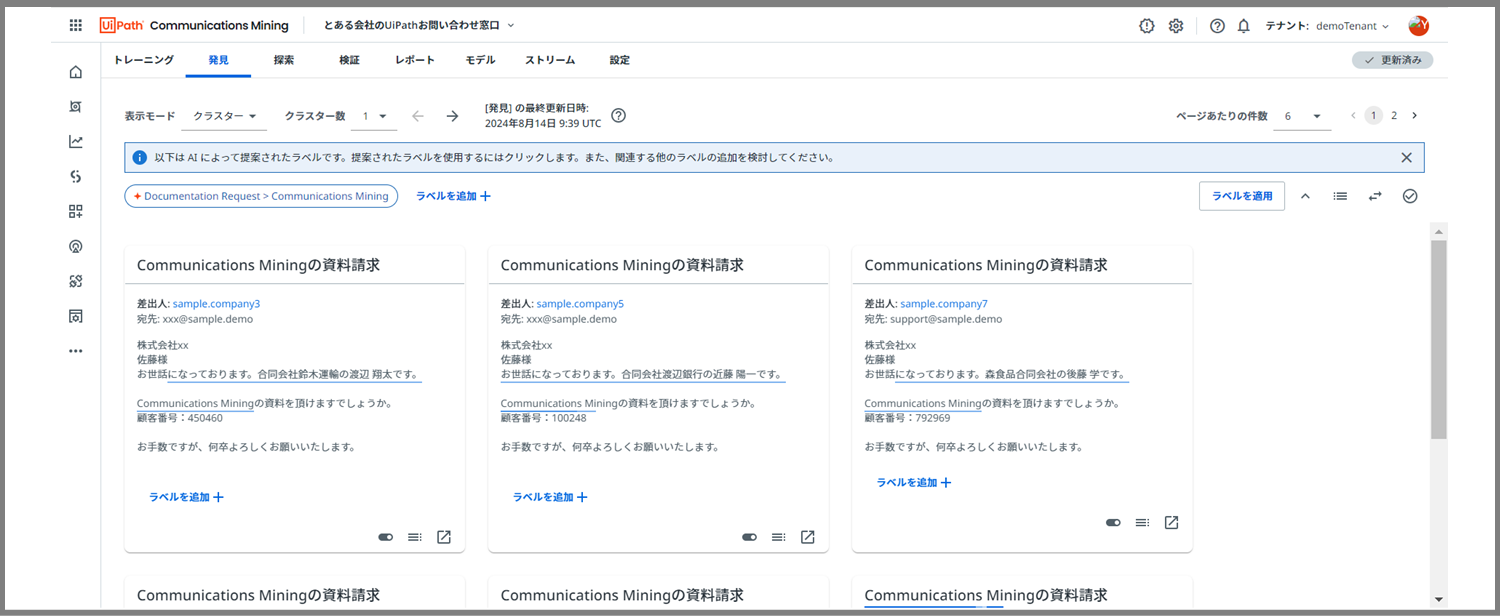
こちらが発見のページです。
このページでは、
- 表示モード:クラスター
- 表示モード:検索
の2つの方法でモデルのトレーニングが可能です。
1-1. クラスター
それでは、まずは「クラスター」を利用したトレーニングから行っていきます。
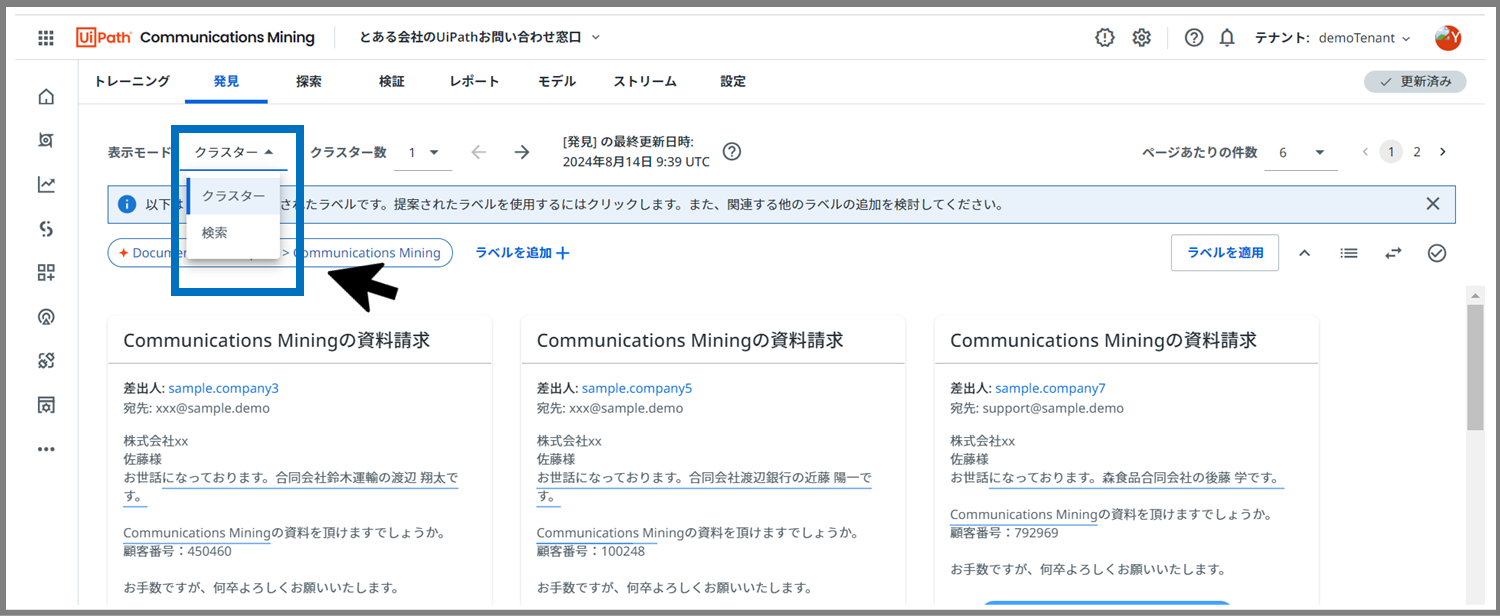
※表示モードは画面左上で切替可能です。
デフォルトはクラスターの表示モードになっています。
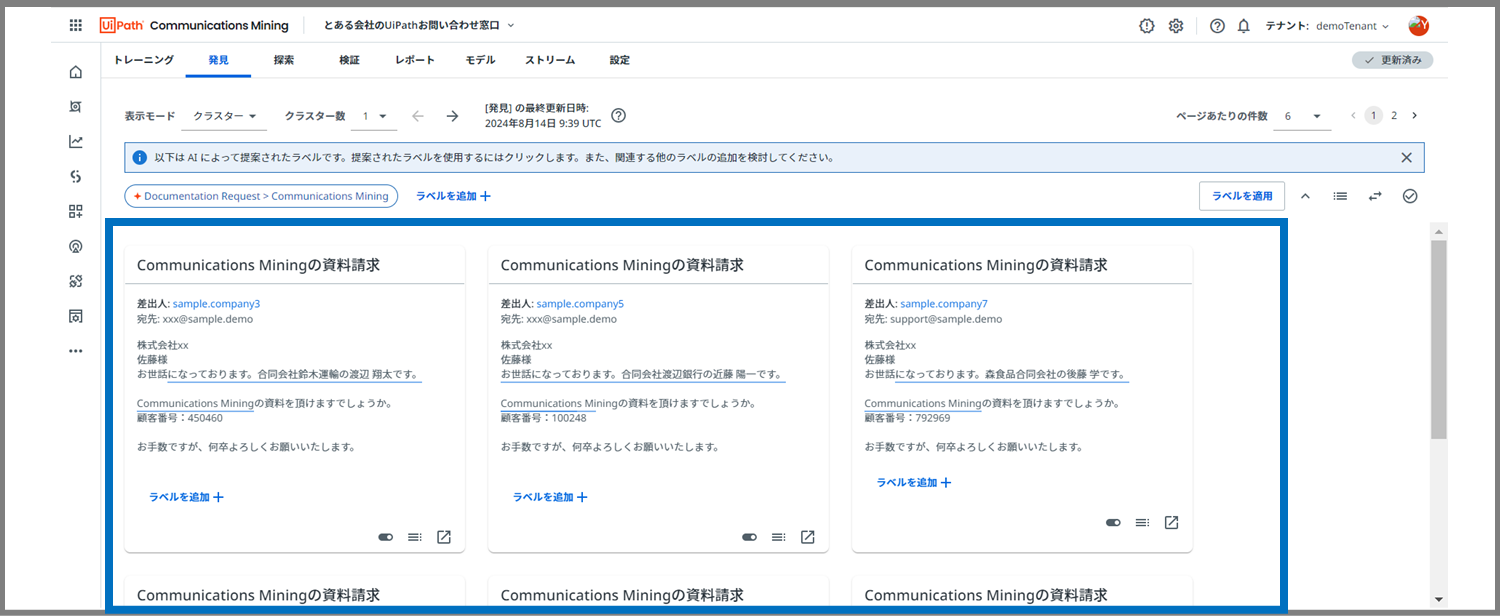
※現在、私の環境では6つのメールメッセージが画面に表示されていますが、この表示数は右上の「ページあたりの件数」から変更が可能です。今回は、「ページあたりの件数: 6」の設定で進めていきます。
★「クラスター」とは
クラスター(cluster)とは、英語で「群れ」や「かたまり」といった意味を持ち、似たものが集まっている状態を指します。
AIの教師なし学習における分析手法の一つに、クラスター分析があります。これは、大量に集められたデータから、特徴が近いデータを集めてグループに分ける方法です。
この手法によって、特徴が近いデータが集まったグループを「クラスター」と呼びます。
現在、画面に6つ表示されているメールメッセージは、このクラスターです。
Communications Miningが、「この6つのメールメッセージは、同じかたまりっぽいけどどうかな?同じラベルが付けられそうじゃない?」とこちらに提案してきてくれています。
ですので、画面に表示された6つのメッセージに目を通し、最適なラベルを適用していきましょう。
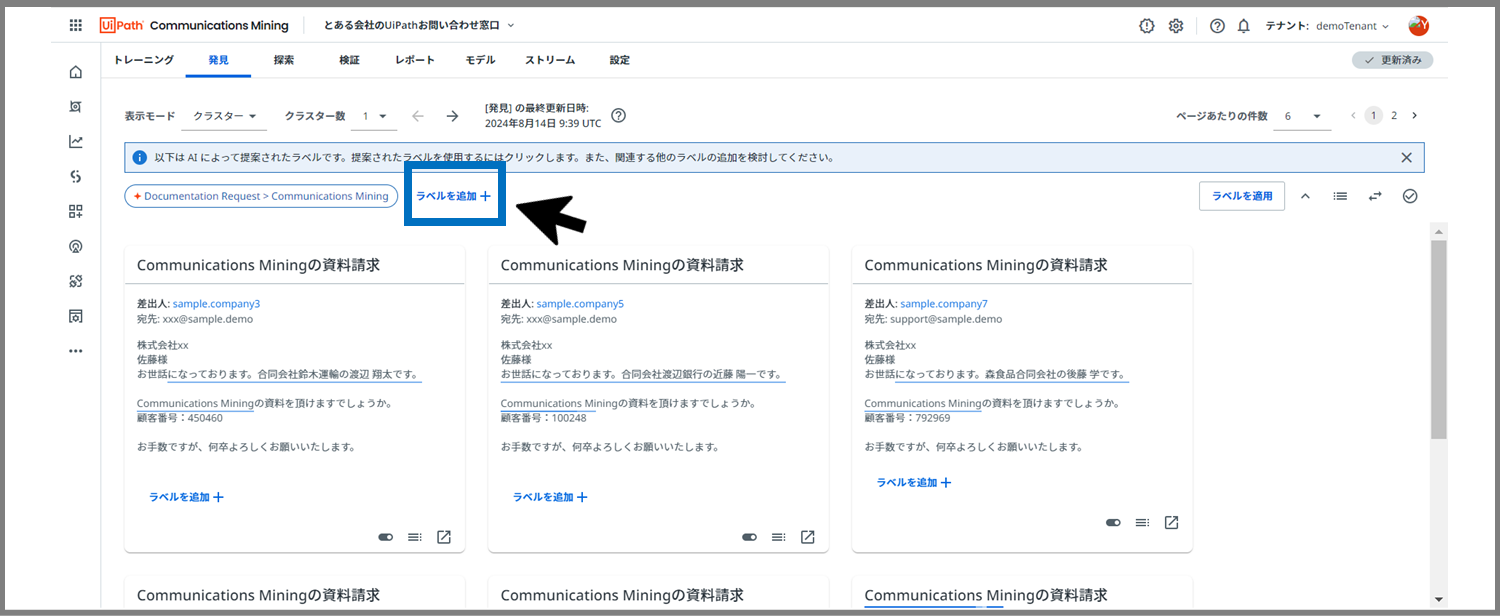
「ラベルを追加+」をクリックします。
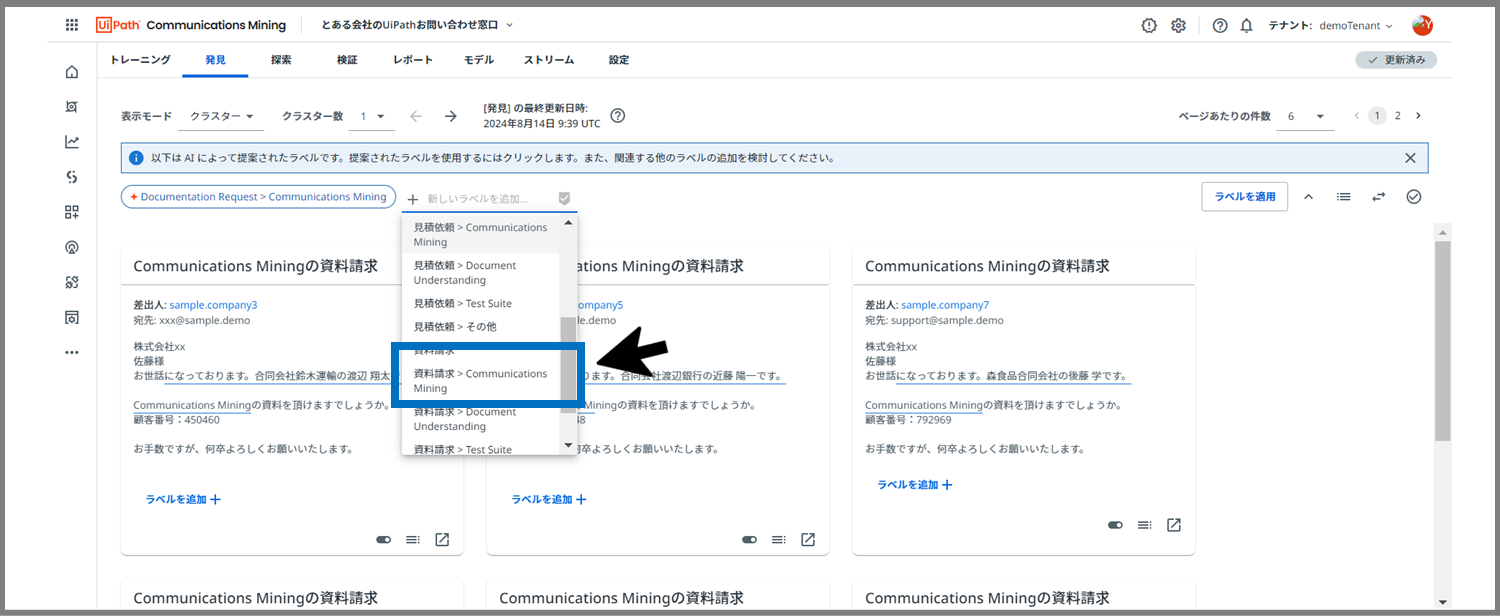
「ラベルを追加+」をクリックすると、4回目の記事で設定したラベルが上の画像のように表示されます。
メッセージを読んだ限り、この6つのメールメッセージはどれも、Comunications Miningの資料請求の要望のようです。
なので、資料請求>Comunications Miningのラベルを選択します。
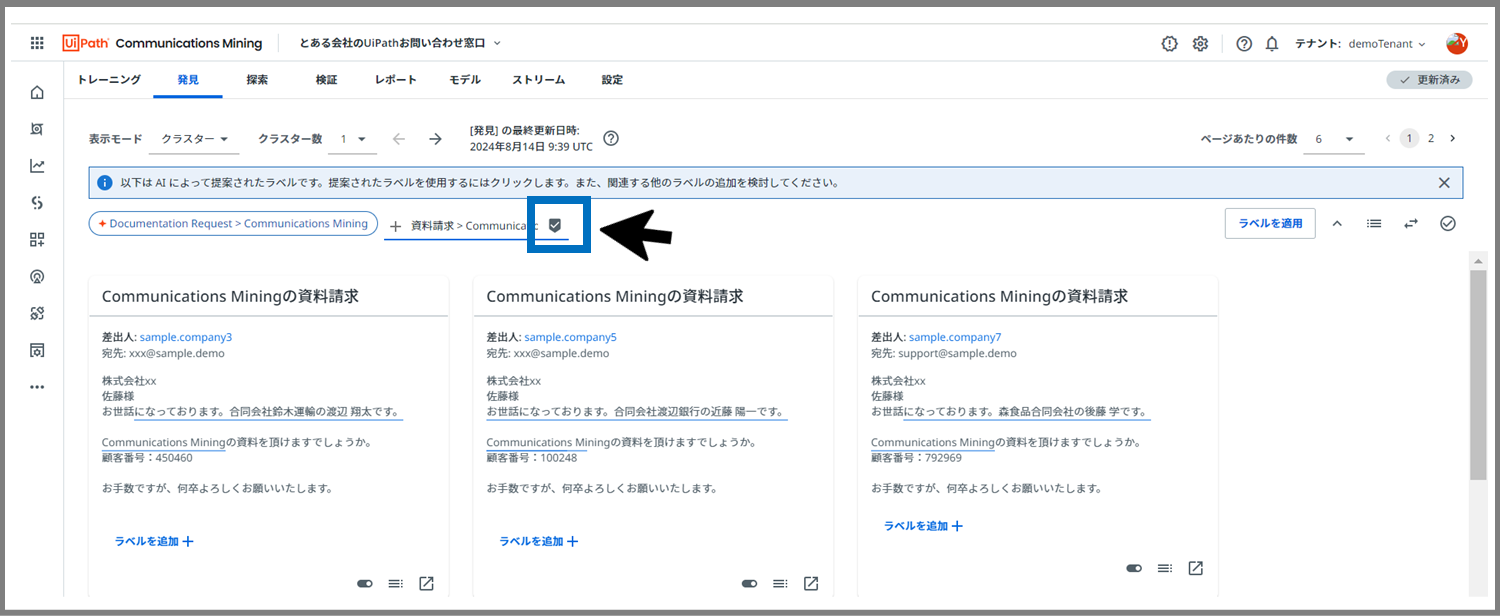 右に出てきたマークをクリックします。
右に出てきたマークをクリックします。
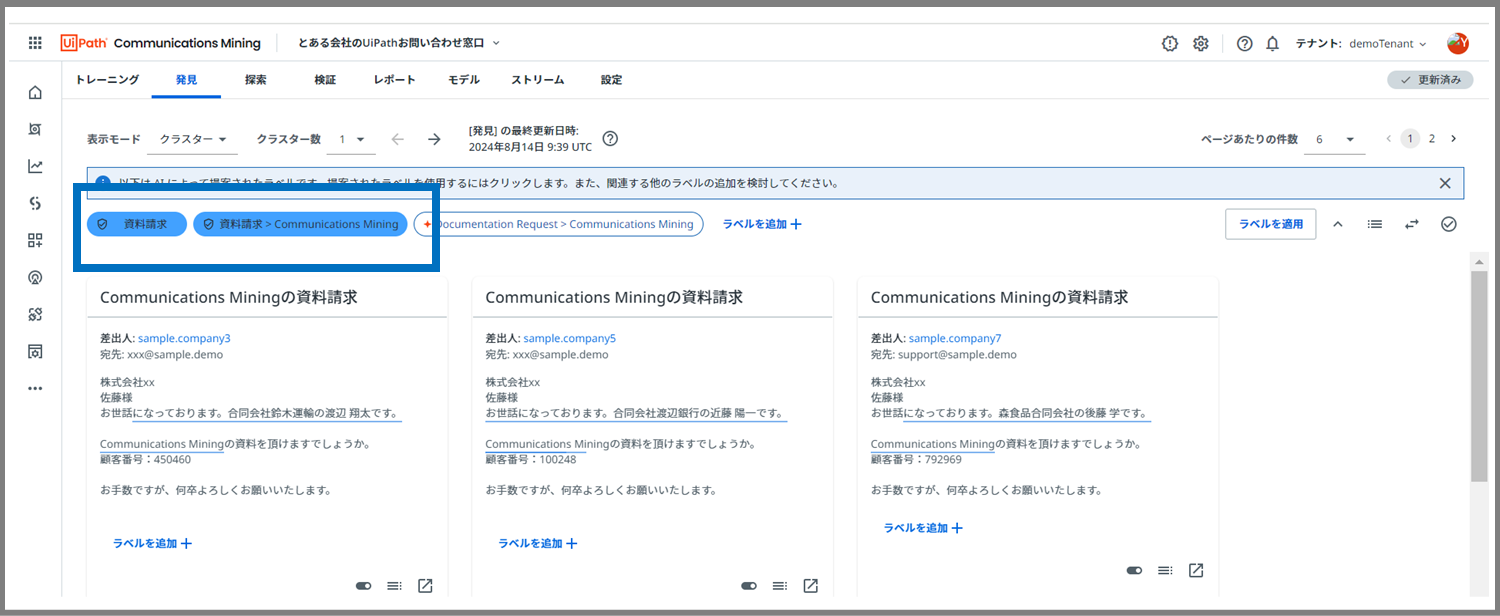
すると、選択したラベルが出現しました!
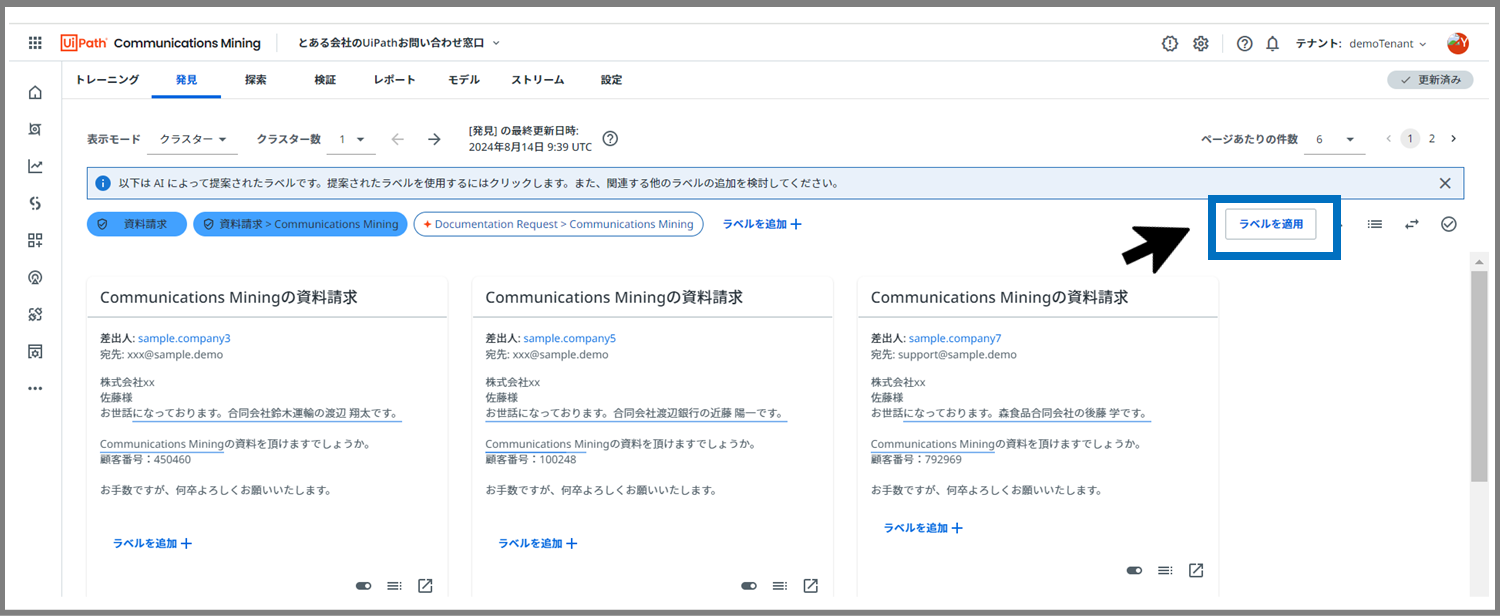
「ラベルを適用」をクリックします。
※「ラベルを適用」をクリックすると、右上に出現した青色のラベルが、下の6つのメッセージ全てに一括で適用されます。
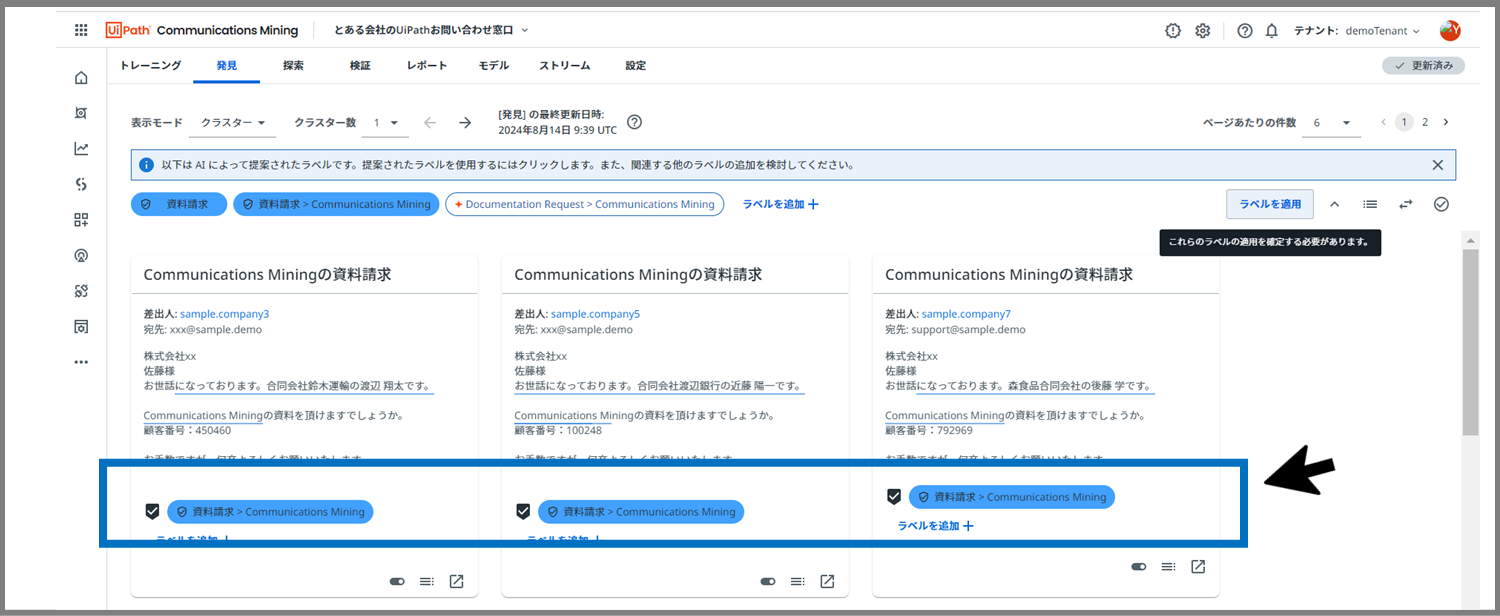
各メッセージ下に上図のように、ラベルが出現したら、ラベルが適用されたサインです。

6つのメッセージ全てにラベルが適用されますが、この6つが同じかたまりなのではないか?というのは、あくまでAIからの提案なので、違う種類のメッセージが混じっていることもあります。
その場合は、そのメッセージに対してだけ、適用したラベルを消してください。
※ラベルにカーソルを合わせると、ラベル右に×マークが出現します。この×マークをクリックすることで、ラベルを消すことができます。
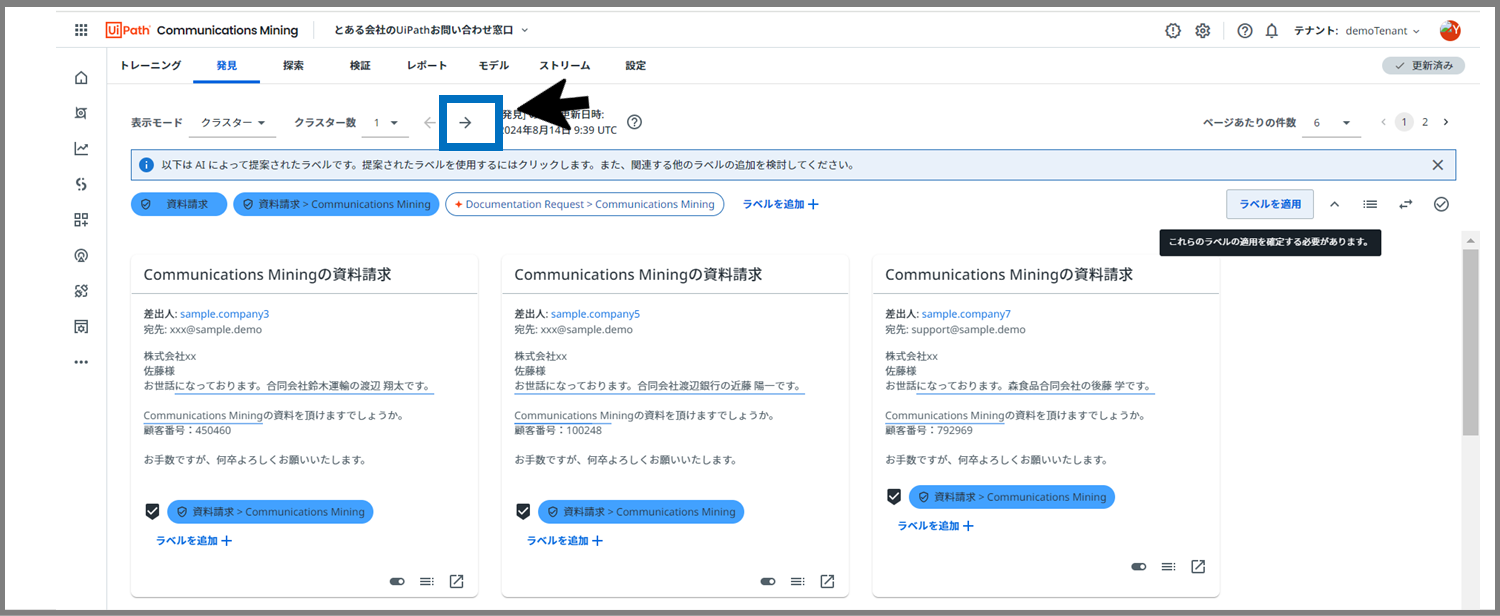
最適なラベルの適用が終わったら、次のページにいきます。
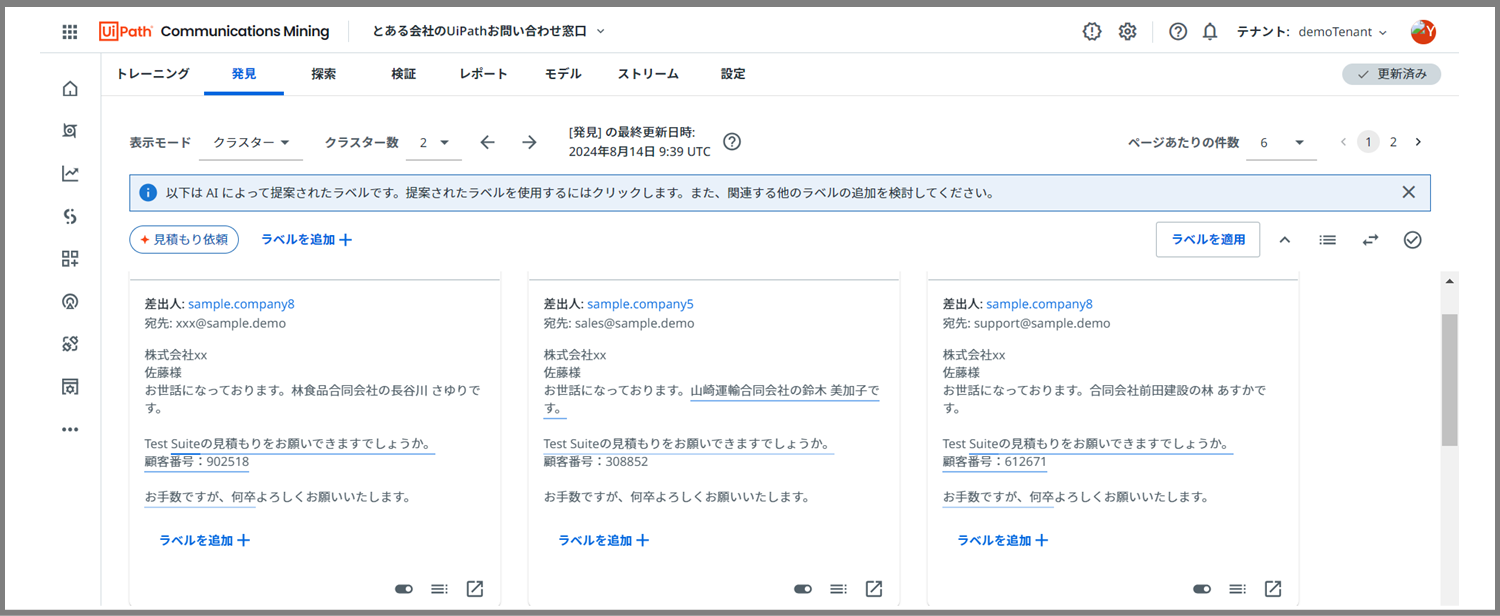
また次のクラスターが提案されますので、これに対しても、先ほどと同じようにラベルを適用していきましょう。
※これをとりあえず、30回ほど繰り返します
もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
【公式ドキュメント】[クラスター] を使用したトレーニング
1-2. 検索
次は、「検索」を利用したトレーニングを行います。
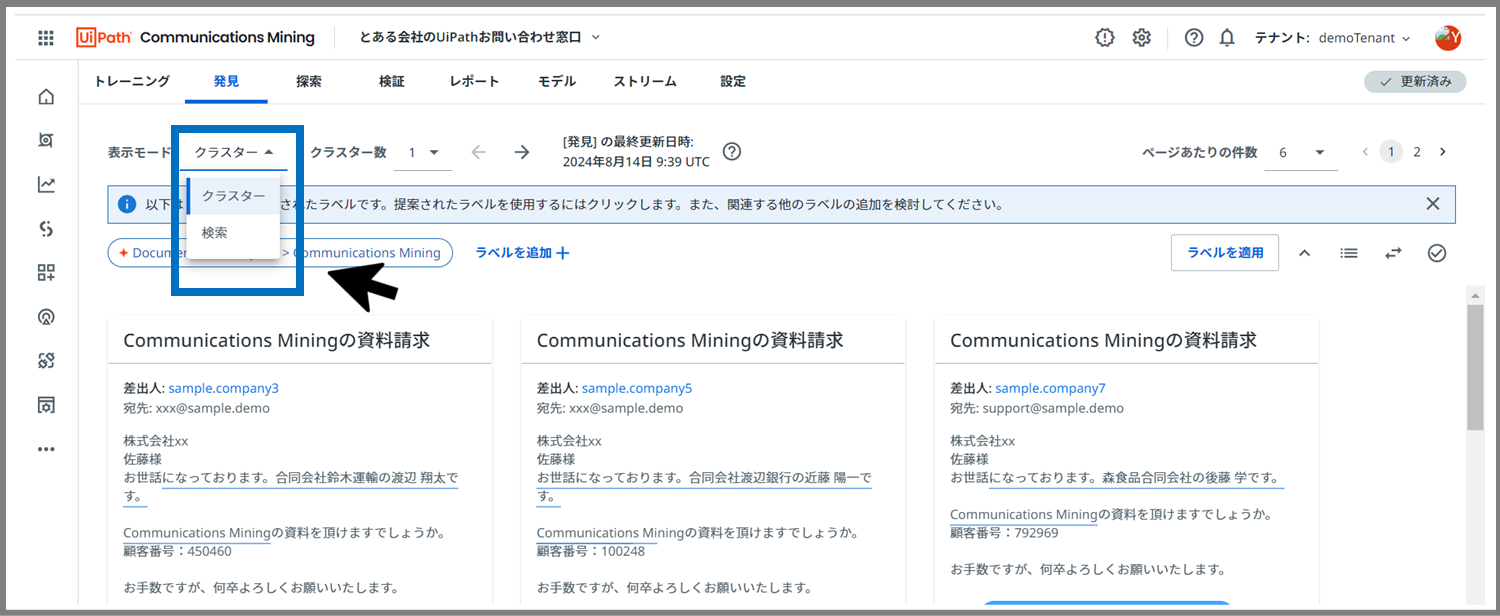
表示モードを画面左上で「検索」に切替えます。
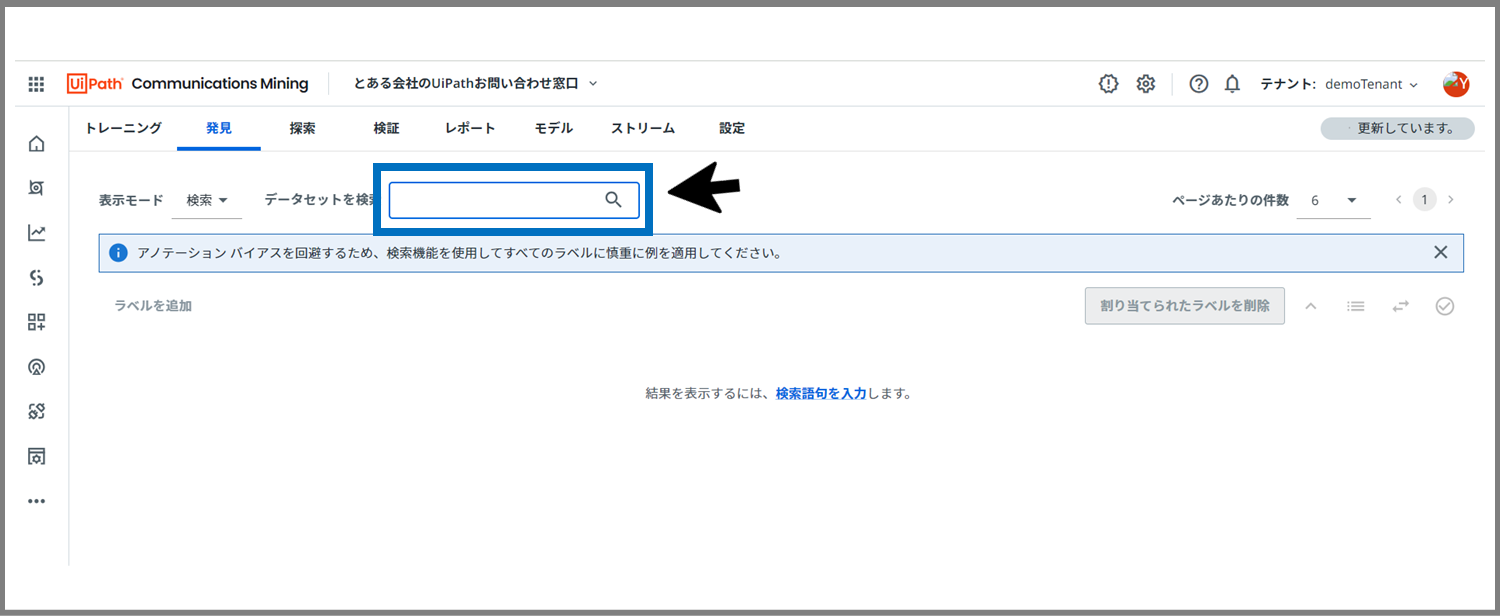
この検索モードを使うと、画面上部の検索ボックスに、検索したい用語を入力して関連メッセージを複数表示することが可能です。
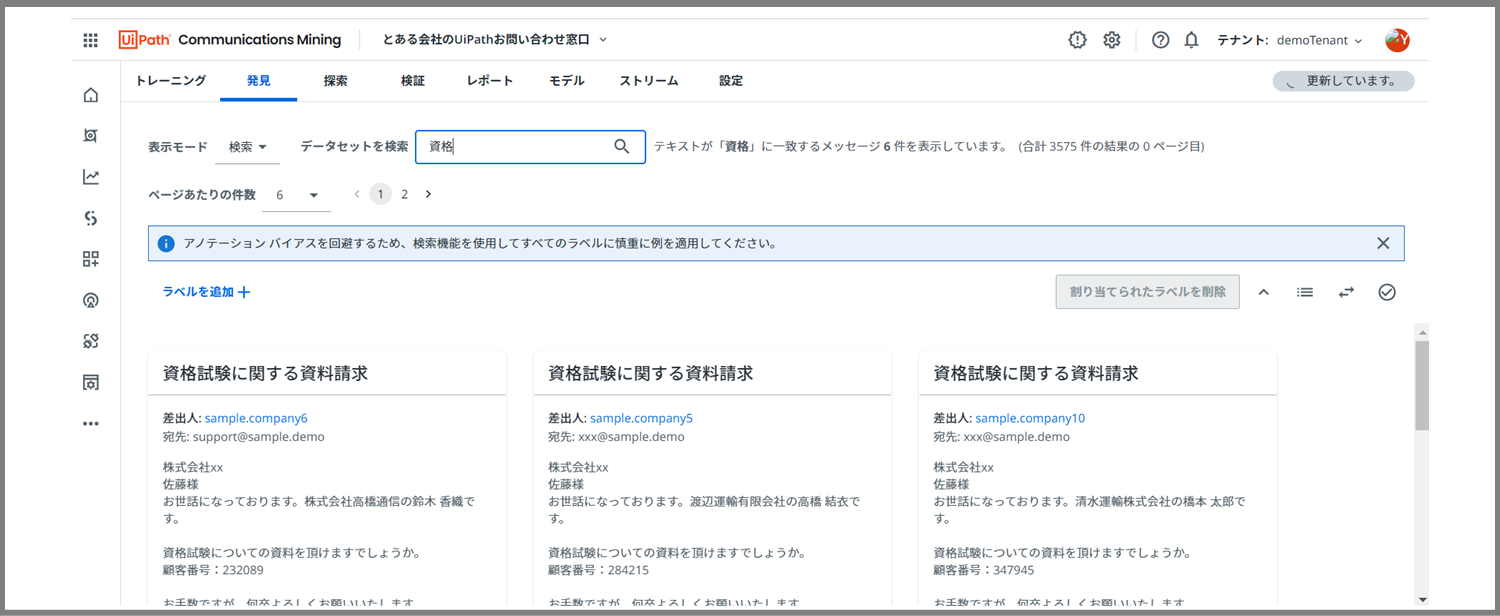
今回は、「資格」という単語を検索して、関連メッセージを表示しました。これに対して、先ほどの「クラスター」モードで行ったようにラベル付けをしていくことが可能です。
「検索」モードを使用してのラベル付けは、基本的には推奨されていません。
※特別な表現がある場合には、1ラベル辺り/10-12件だけラベル付けする程度です。
※「検索」モードを使いすぎると、モデルの精度が悪くなってしまいます。
ですので、今回の記事シリーズにおいては検索モードでのラベル付けは実際には行わないで進めていきます。
「検索」モードでのラベル付けは、まだどのクラスターにも現れていないような、一般的な関連語句や表現があった場合に使える機能です。
今回は単純に「資格」という単語を検索しましたが、実際の生データを扱う時には何かポイントになるような表現があることかと思いますので、そういった場合に使ってみてください。
もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
【公式ドキュメント】[検索] を使用したトレーニング (発見)
2. 最後に
以上が、UiPath Communications Miningの「発見」フェーズにおけるトレーニングでした。
「トレーニングって何をするんだろう?」そんな疑問があった方には、実際のトレーニングがどういうものかお見せすることができたかと思います。
※UiPath Communications Miningにおけるトレーニングとは、(開発者の作業としては)メッセージに最適なラベルなどをつけていく事にあたります。
次回の記事では、「探索」フェーズにおけるトレーニングをしていきますので、お楽しみに。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子