こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
この記事はその第6回目です。第1回目では基本的な概念について、第2回目では必要な環境準備について説明しました。また、第3回目ではAIモデルのトレーニング前のデータ準備やCommunications Miningへのセットの仕方を説明し、第4回目ではタクソノミーについて紹介しました。
第5回目では、「発見」ページを利用してのモデルトレーニングを行いました。
今回の記事では「探索」ページでのトレーニングを行います。
目次
1. 「探索」ページでのトレーニング
1-1. シャッフル
1-1-1. ラベルの適用
1-1-2. フィールドの適用
1-2. 教える
1-3. 信頼度が低い
2. 最後に
1. 「探索」ページでのトレーニング
「発見」ページは、クラスター提案をしてくれました。
「探索」ページでは、データセット内のメッセージを詳細に検索、レビュー、フィルター処理し、個別のメッセージやフィールドを確認することが可能です。
これにより、各ラベルやフィールドに対して一貫したトレーニング例を提供し、モデルの精度を高めていくことができます。
それでは早速トレーニングを開始していきましょう!
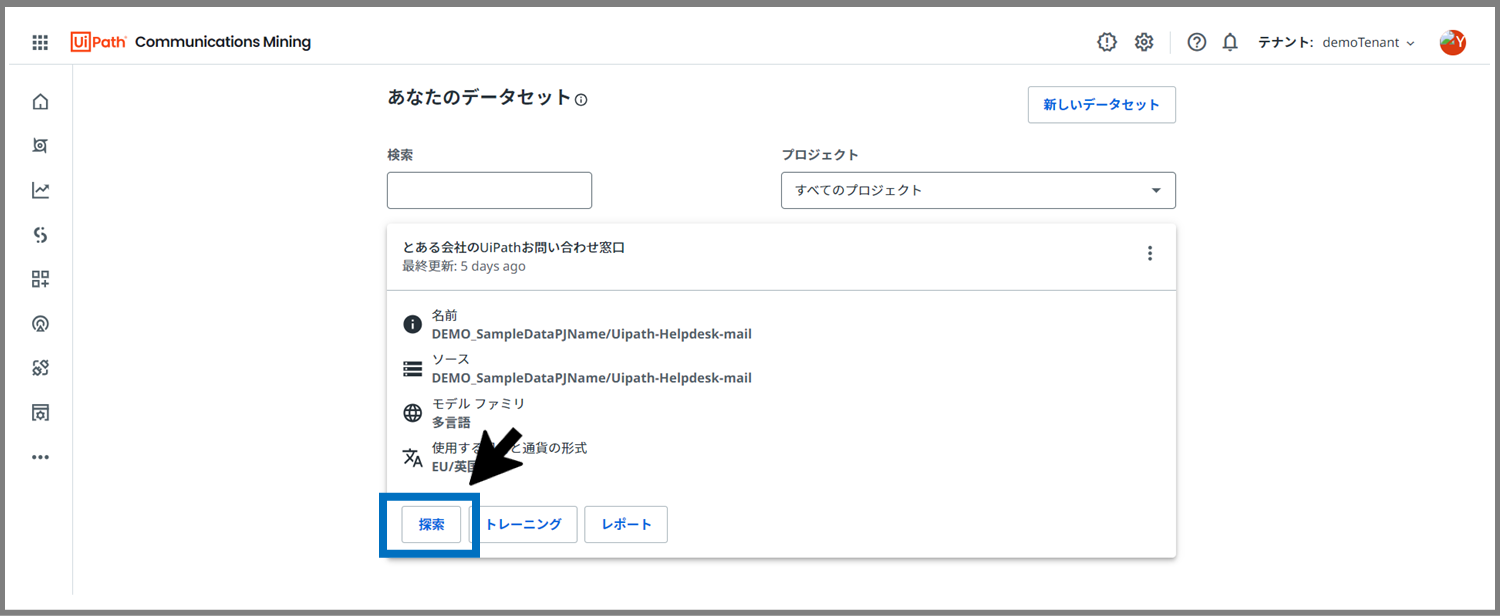
Communications Miningのトップページにいくと、3回目の記事で作成した上記のようなデータセットがあると思います。ここの「探索」ボタンをクリックします。
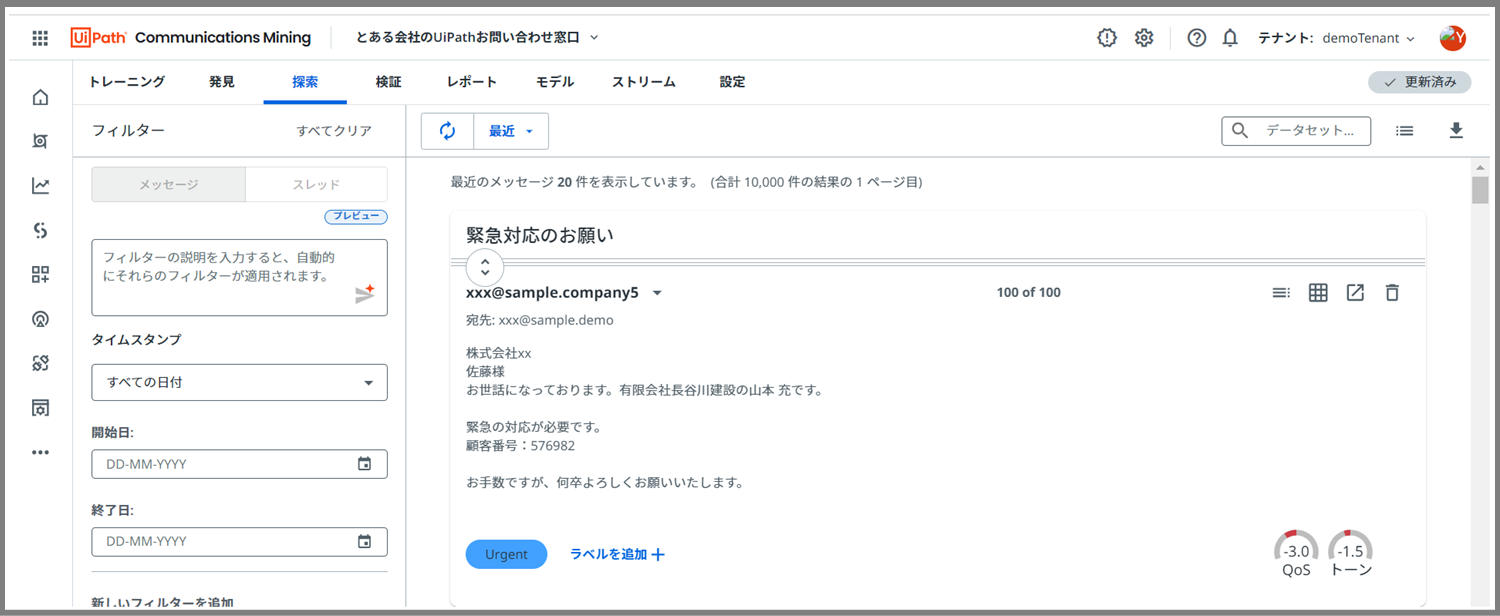
こちらが「探索」のページです。
このページでは、
- 「シャッフル」モード
- 「教える」モード
- 「信頼度が低い」モード
などの方法でモデルのトレーニングをしていきます。
1-1. シャッフル
それでは、まずは「シャッフル」モードを利用したトレーニングから行っていきます。
「シャッフル」は、探索フェーズの 最初の手順にあたります。
このモードでは、メッセージがランダムに表示されます。
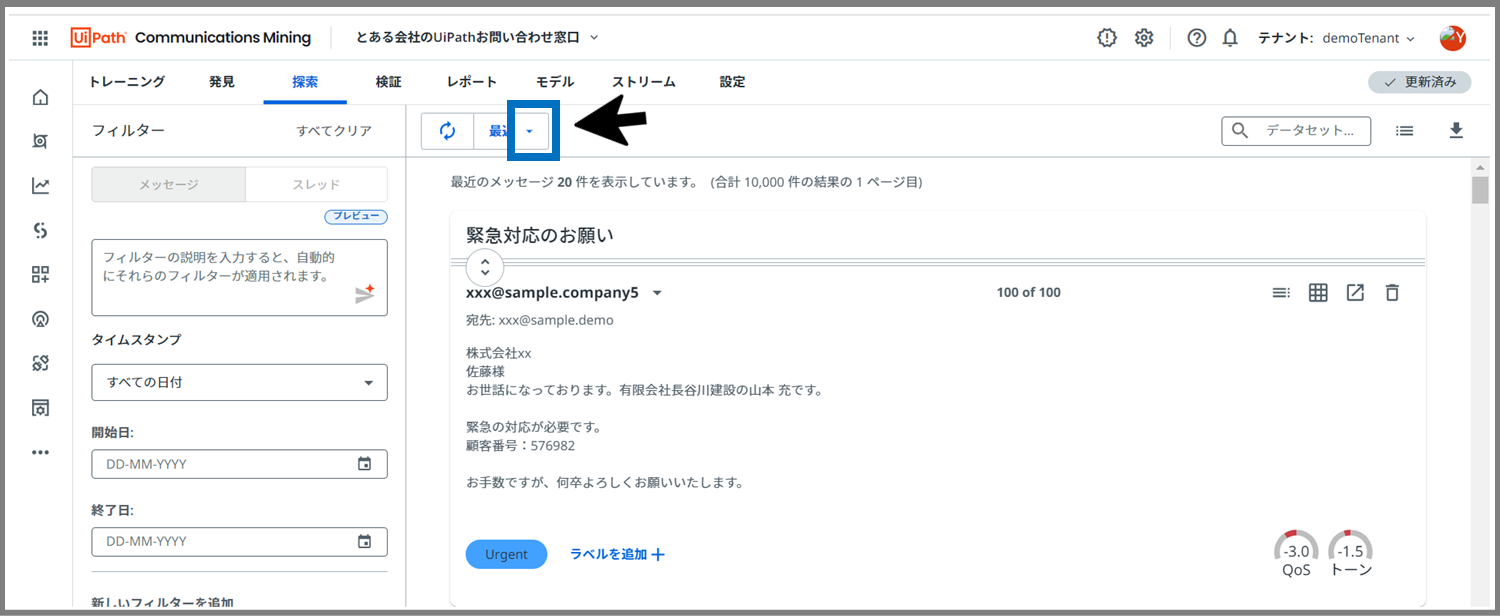
※表示モードは画面上部の▼ボタンで切替えます。
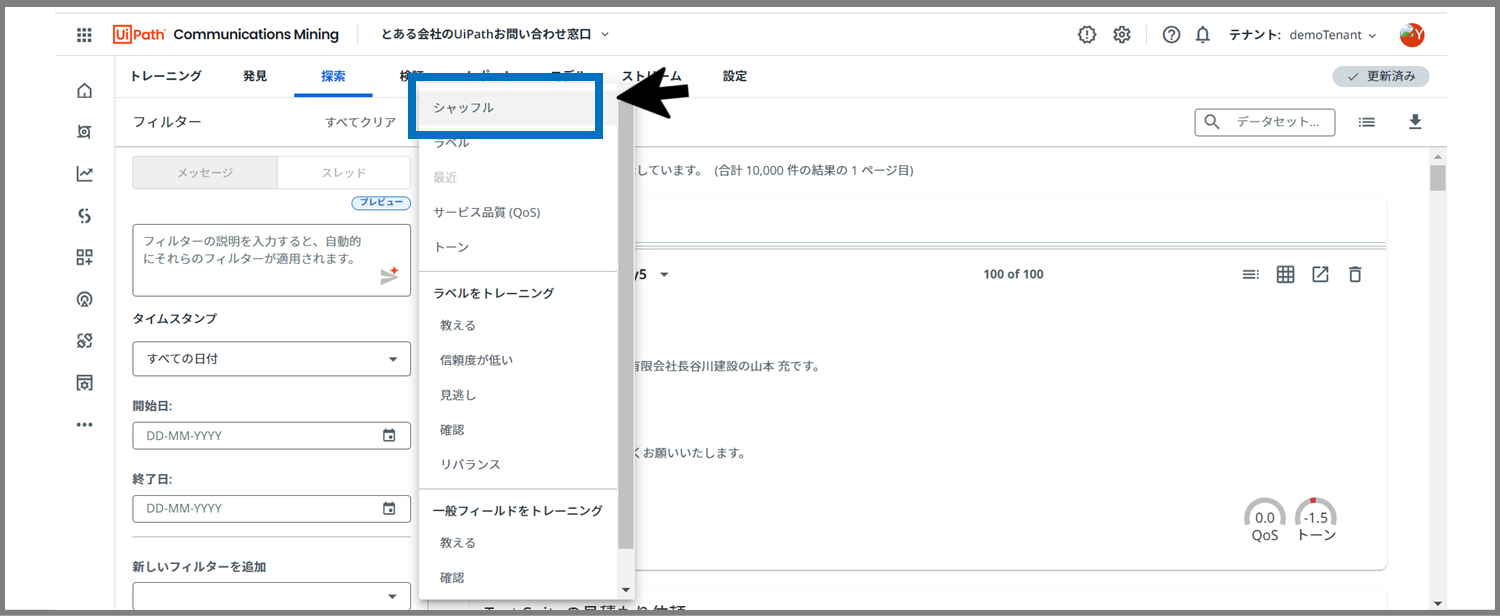
「シャッフル」を選びます。
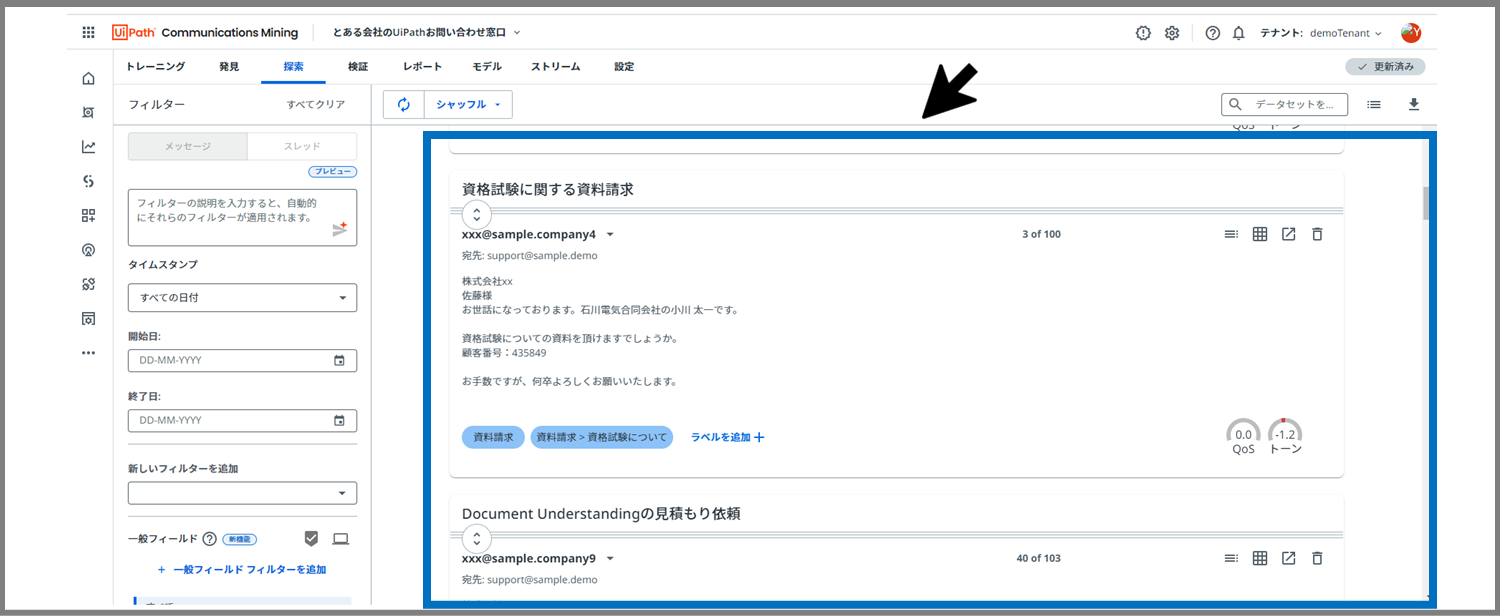
ランダムに選ばれたメッセージが表示されました!
これから、200件のメッセージのラベル・一般フィールドをつけていきます。
※「シャッフル」モードでの推奨ラベル付け件数は、公式では少なくとも200件と言われています。データの規模や複雑さによってはもっと必要となると思います。
1-1-1. ラベルの適用
まずは、ラベルを適用してきましょう。
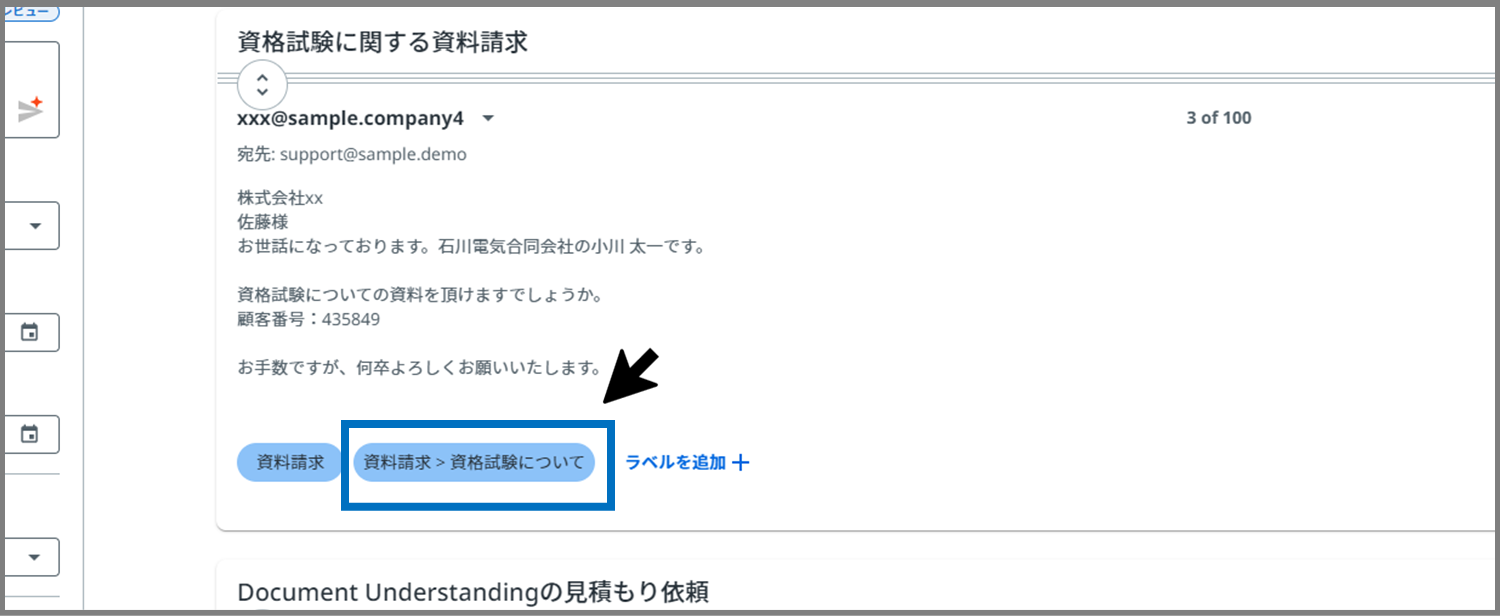
水色のラベルは、Communications Miningからの提案です。
「このラベルじゃないの?」みたいに提案してくれています。
※あくまでAIからの提案なので、違う場合は無視して、横の「ラベルを追加+」ボタンから正しいラベルを選択します。
水色のラベルが正しければ、水色のラベルをクリックします。
この場合は「資料請求>資格試験について」が正しいラベルなので、これをクリックします。
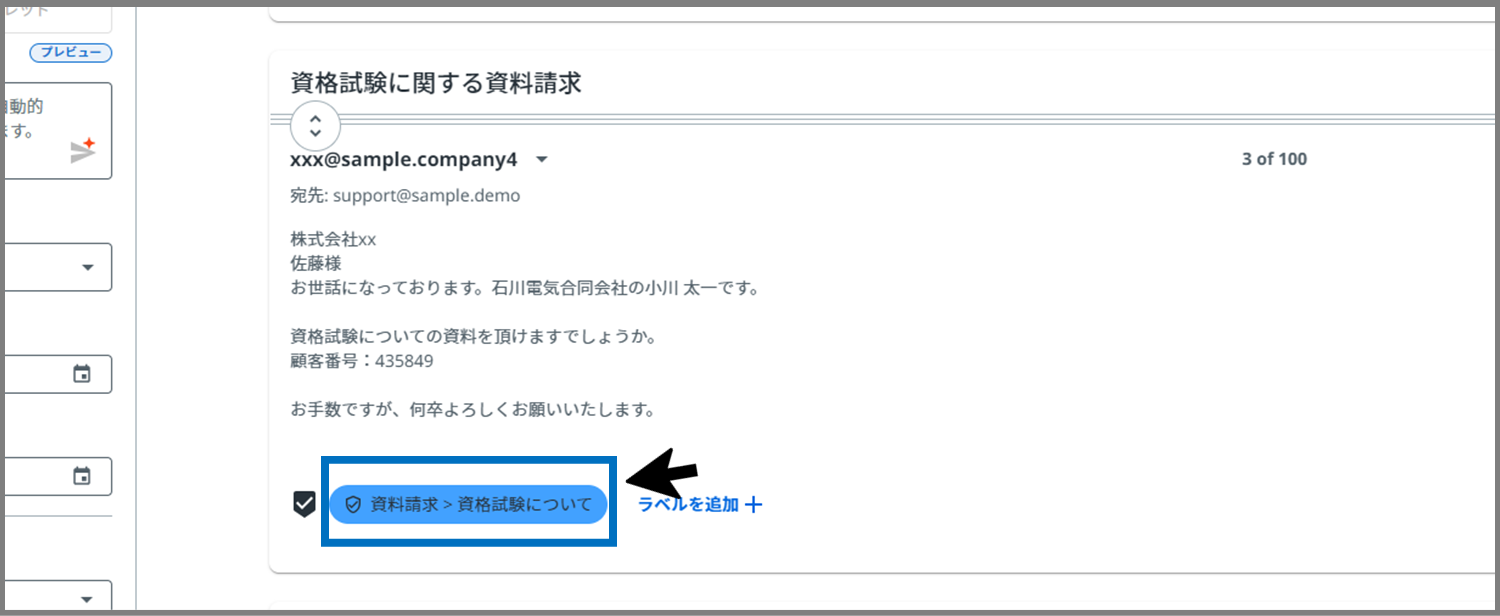
すると、上の画像のようにラベルの水色が濃い色になりました!
これでラベルの適用は完了です。
1-1-2. フィールドの適用
次は、一般フィールドを適用していきます。
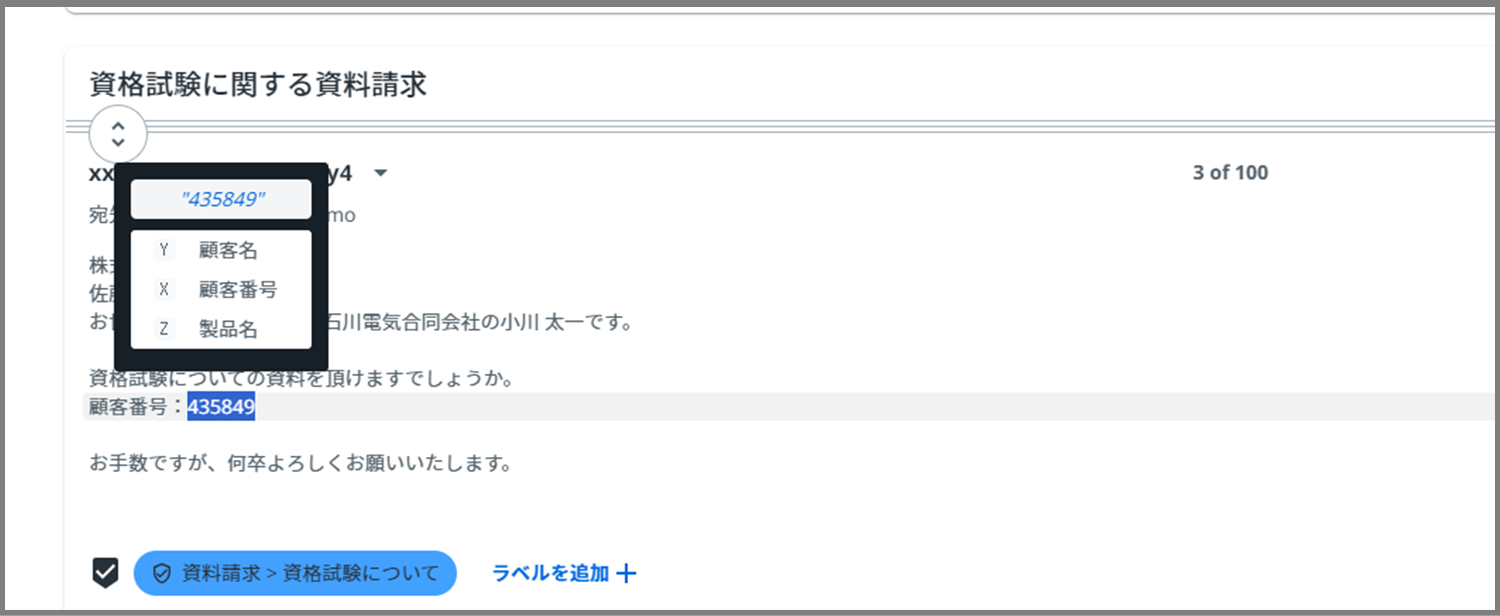
まずは、顧客番号から。
顧客番号にあたる番号(今回の場合は、435849という番号)を、カーソルをドラッグして選択します。
すると、上の画像のように、4回目の記事で、一般フィールドとして設定した項目が出てきます。
今回は、顧客番号なので、「顧客番号」をクリックしてください。
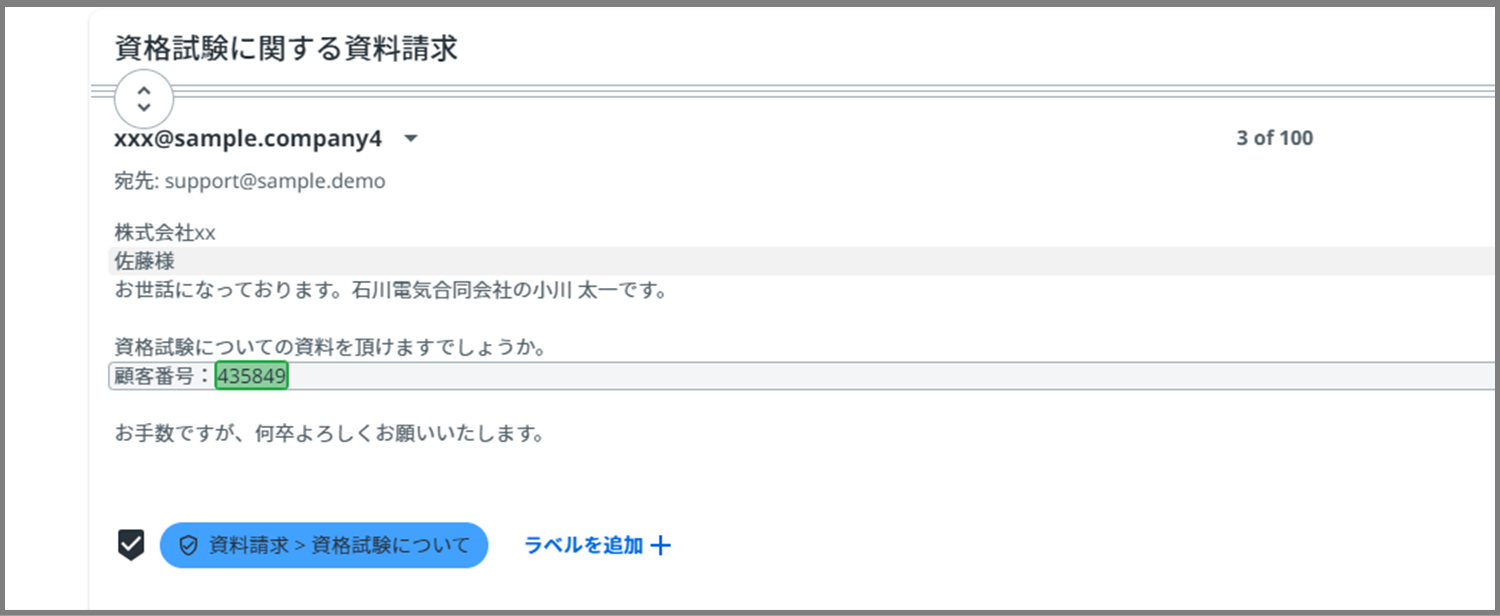
すると、上の画像のように一般フィールドを適用した部分に色がつきました。
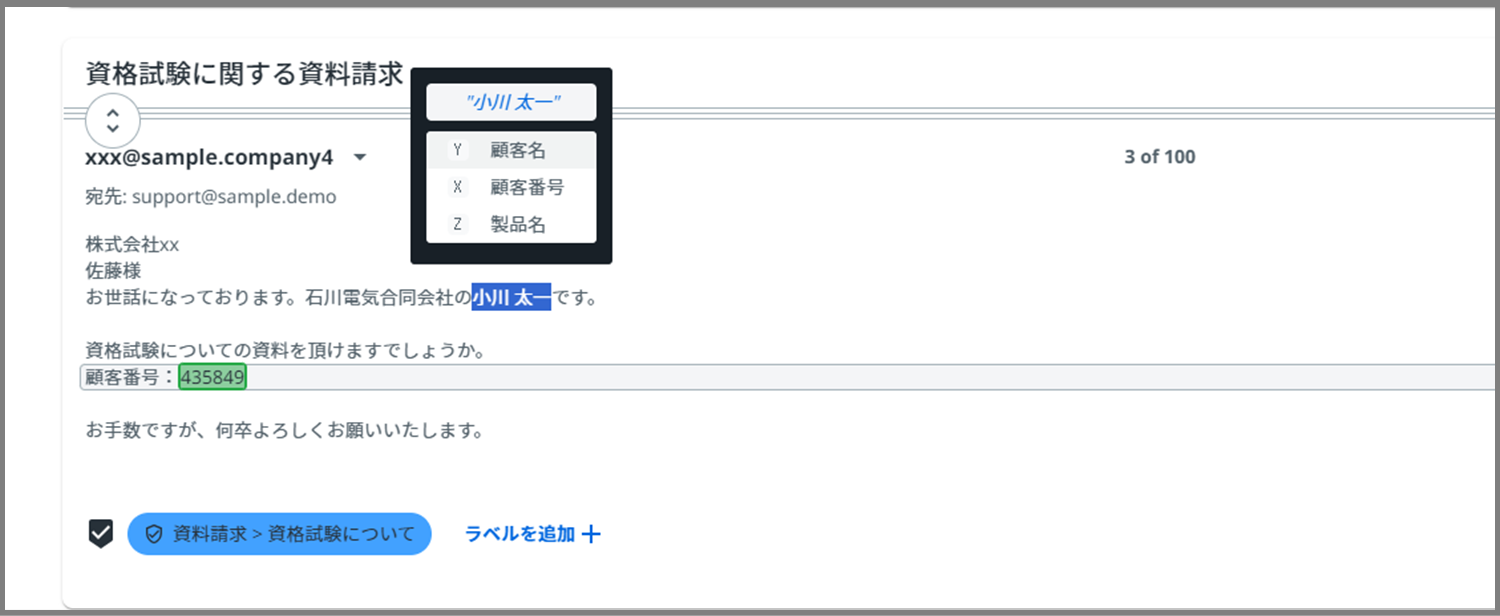
次は、顧客名(今回の場合は、小川 太一という名前)を、先ほどと同じようにカーソルをドラッグして選択します。
すると、上の画像のように、一般フィールドとして設定した項目が出てきます。
今回は、顧客名なので、「顧客名」をクリックしてください。
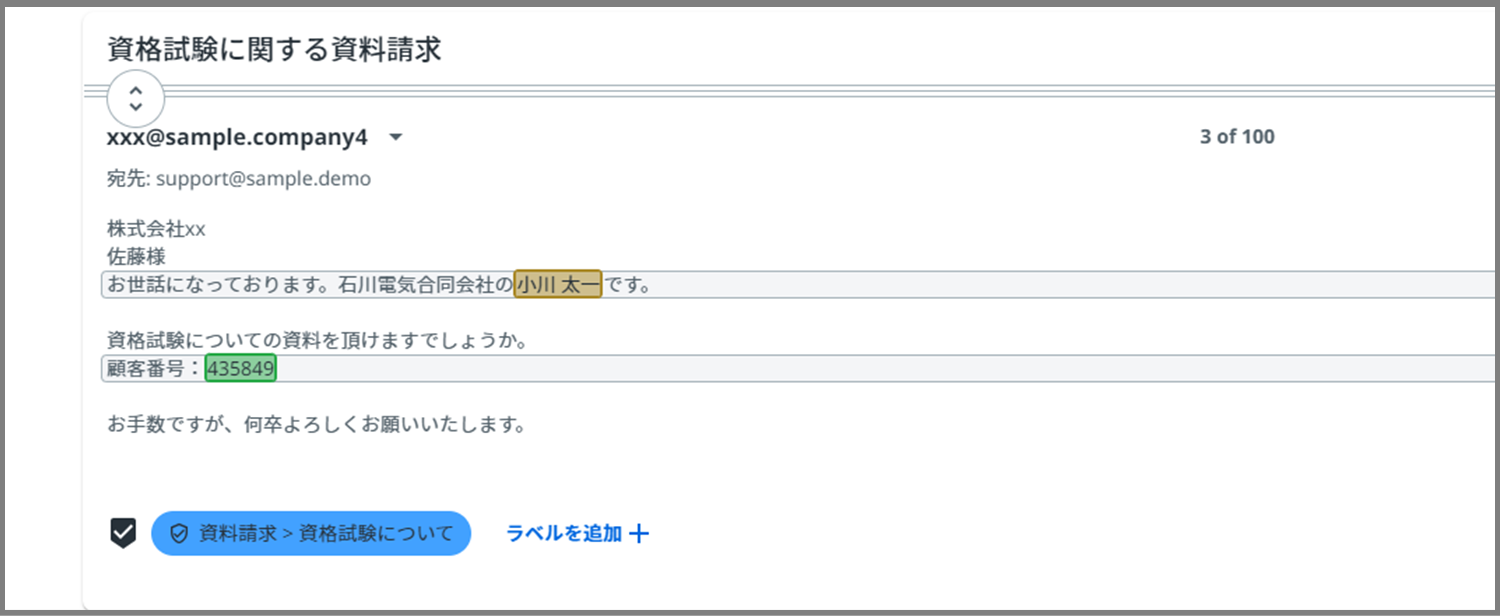
これで一般フィールドの適用も完了です!
※今回のメッセージに製品名は含まれていないので、これでラベル付けも一般フィールド適用も完了したことになります。
あとは、この作業を200メッセージ分繰り返しましょう。
もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
【公式ドキュメント】[シャッフル] を使用したトレーニング
1-2. 教える
200件の作業は終わりましたでしょうか?
次は「教える」モードを利用したトレーニングを行います。
「教える」は、探索フェーズの2番目の手順にあたります。
ここで表示されるメッセージは、モデルが判断するラベル確信度が50%くらいのものです。つまり、信頼性が高くも低くもない、モデルにとって判断に迷っているラベルや一般フィールドがついたメッセージが表示されます。
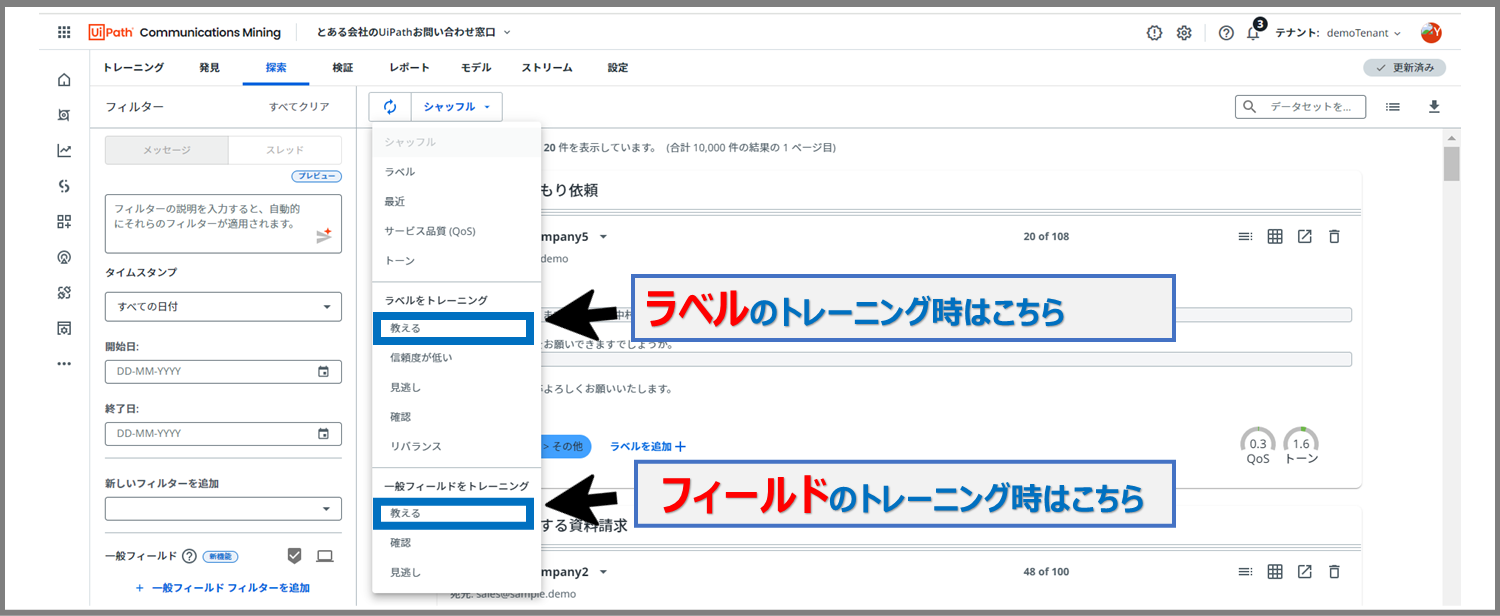
また、「ラベルのトレーニング時」と「一般フィールドのトレーニング時」で選択するページが違いますので、ご注意ください。
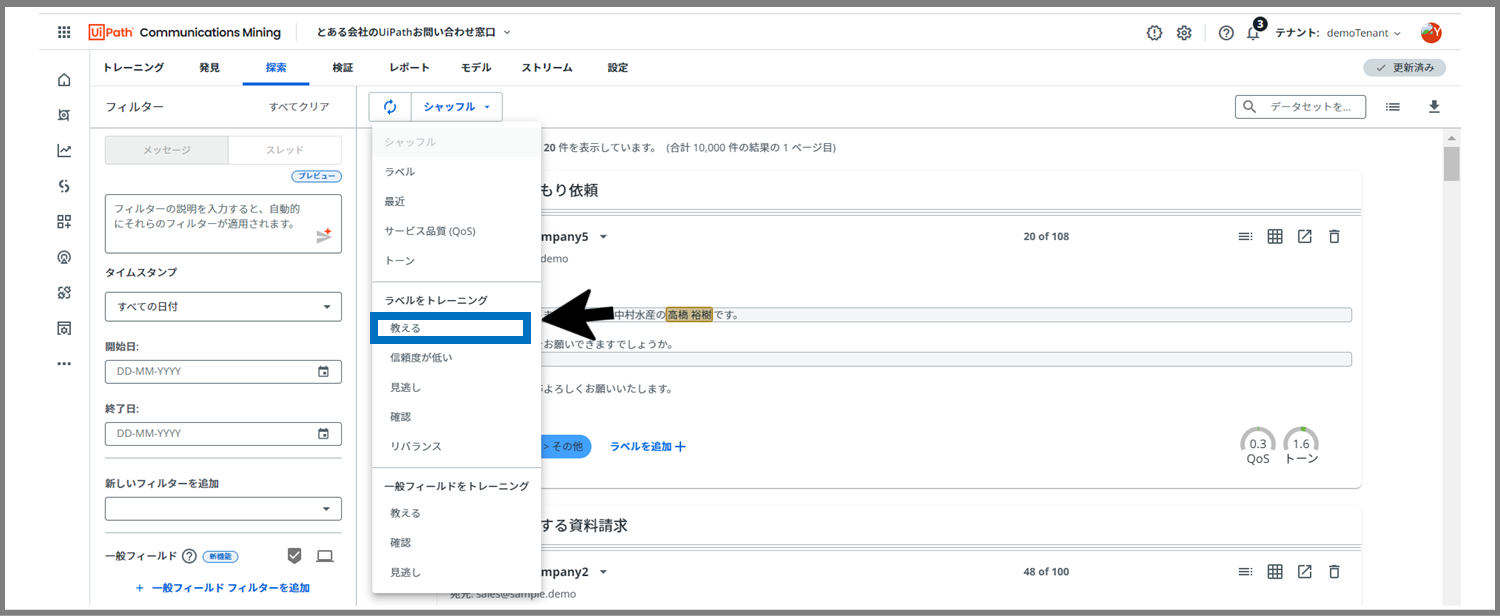
それでは、「教える」フェーズでの、「ラベルのトレーニング」から開始します。
まずは、先ほど「シャッフル」を選んだように、「教える」を選びます。
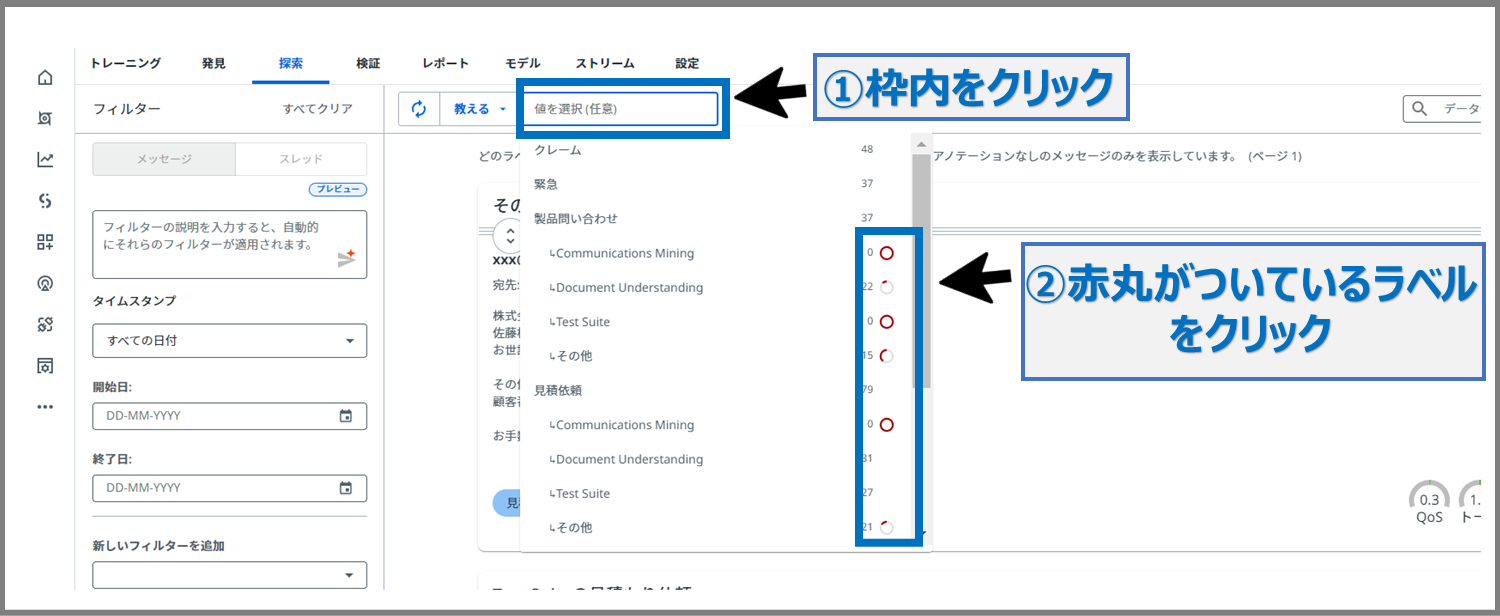
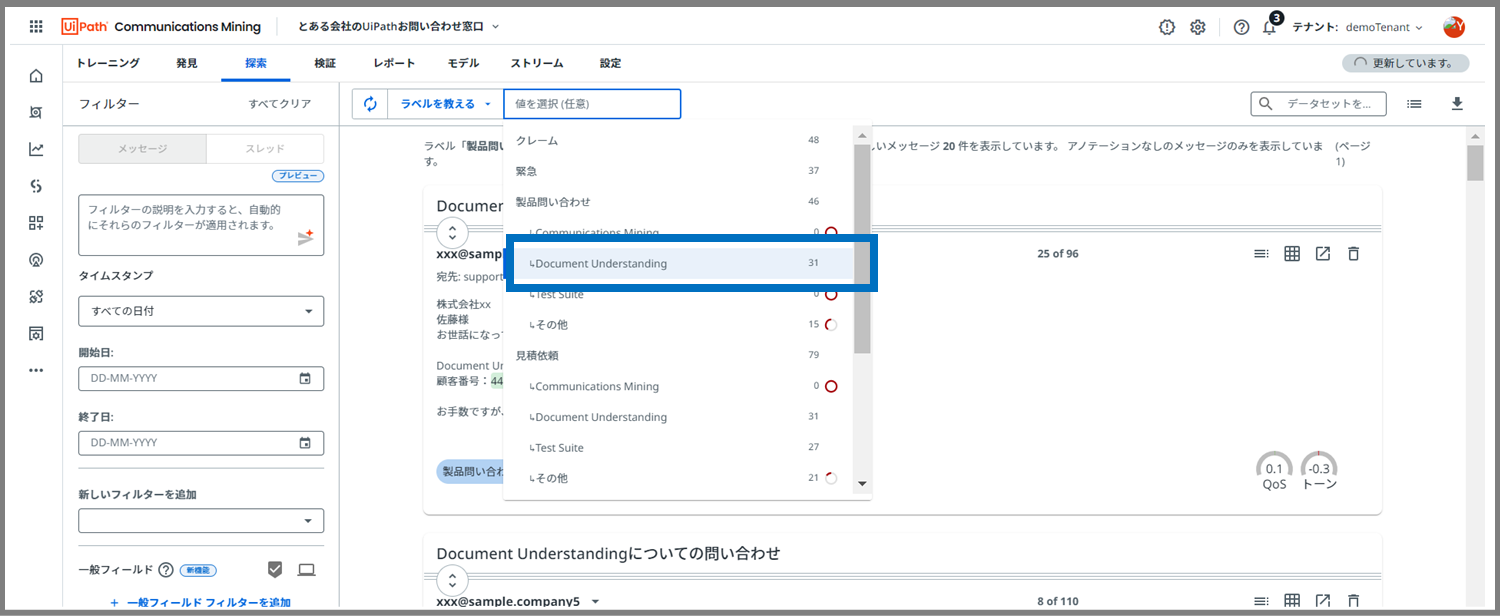
①「教える」の横に出てくる、枠内をクリックします。
すると、4回目で設定したラベルが出てきます。
ラベルの横に赤丸がいくつかついているのが確認できましたでしょうか?
赤丸がついているラベルは、まだ十分にラベル付けできていないラベルです。
1ラベル(または1フィールド)辺り、25件以上、人間の手によりメッセージと紐づける必要があります。
②次に、赤丸がついているラベルをクリックします。
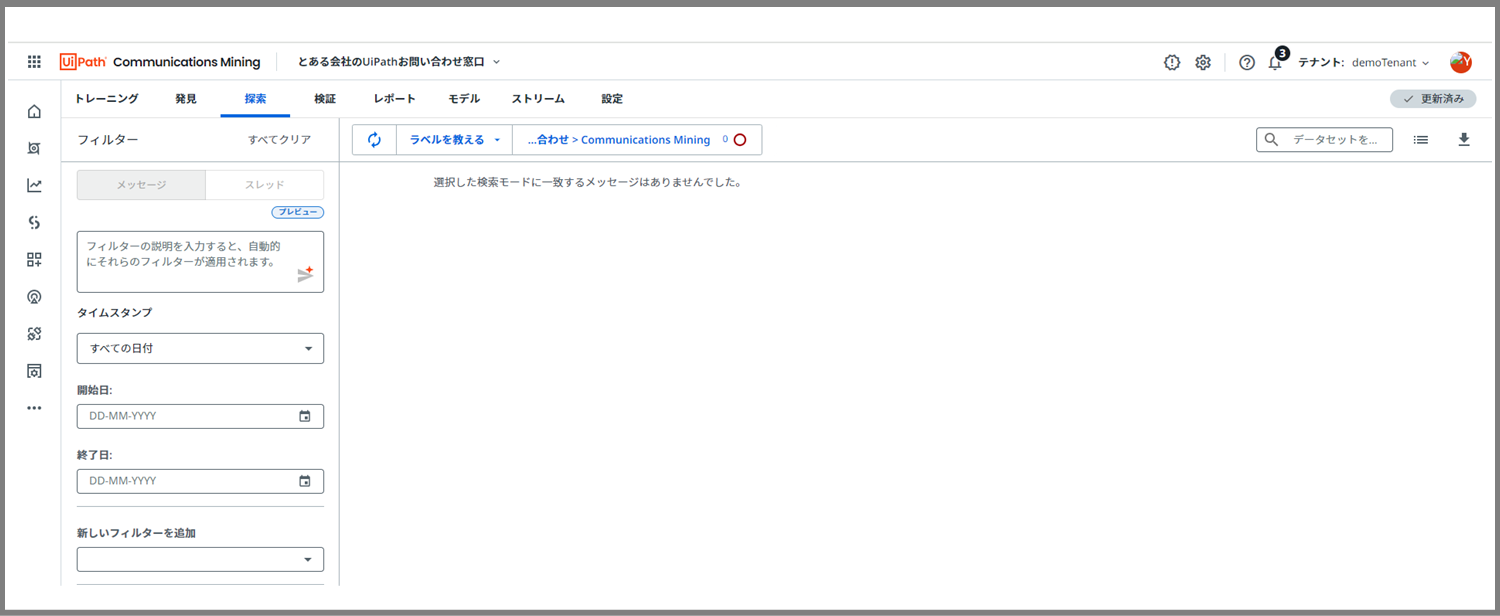
まず、1つ目に選択したラベルの中は空っぽでした。
これは、25件以上のラベルがまだついていないけれど、そもそものデータ自体がないものです。私が用意したデータサンプルに偏りがあったようですね。
ここは仕方ないのであきらめます。
※本番の場合は、足りないデータは足して学習させる必要があります。
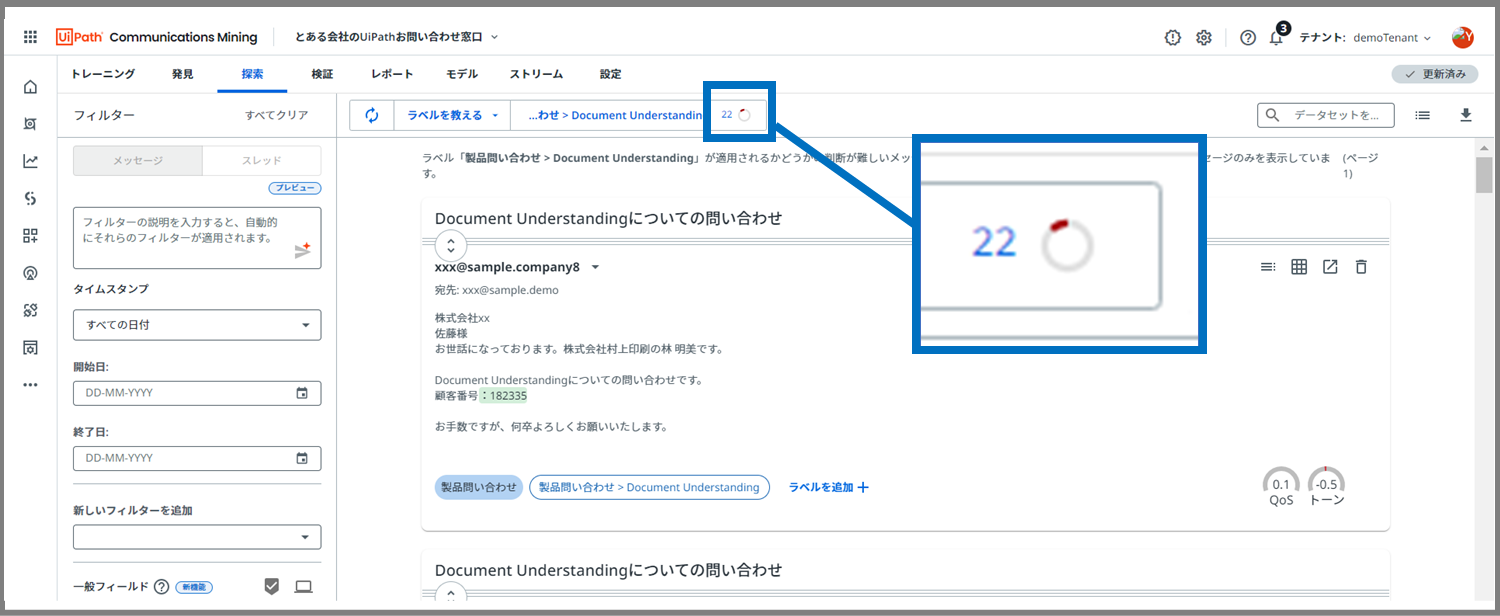
次に選択したラベルには、ちゃんと「教える」モードがお勧めしてくれるメッセージがありました。
上部に22という数字がでています。
これは、必要とされる25件のラベルのうち、22件はラベルがつけられているということです。あと3件、表示されたメッセージにラベルをつければ赤丸が消えるはずです。
1-1-1. ラベルの適用 の手順と同様に、ラベルの適用をしていきましょう。
いくつかラベルを付けたら、赤丸が消えたことが確認できました。
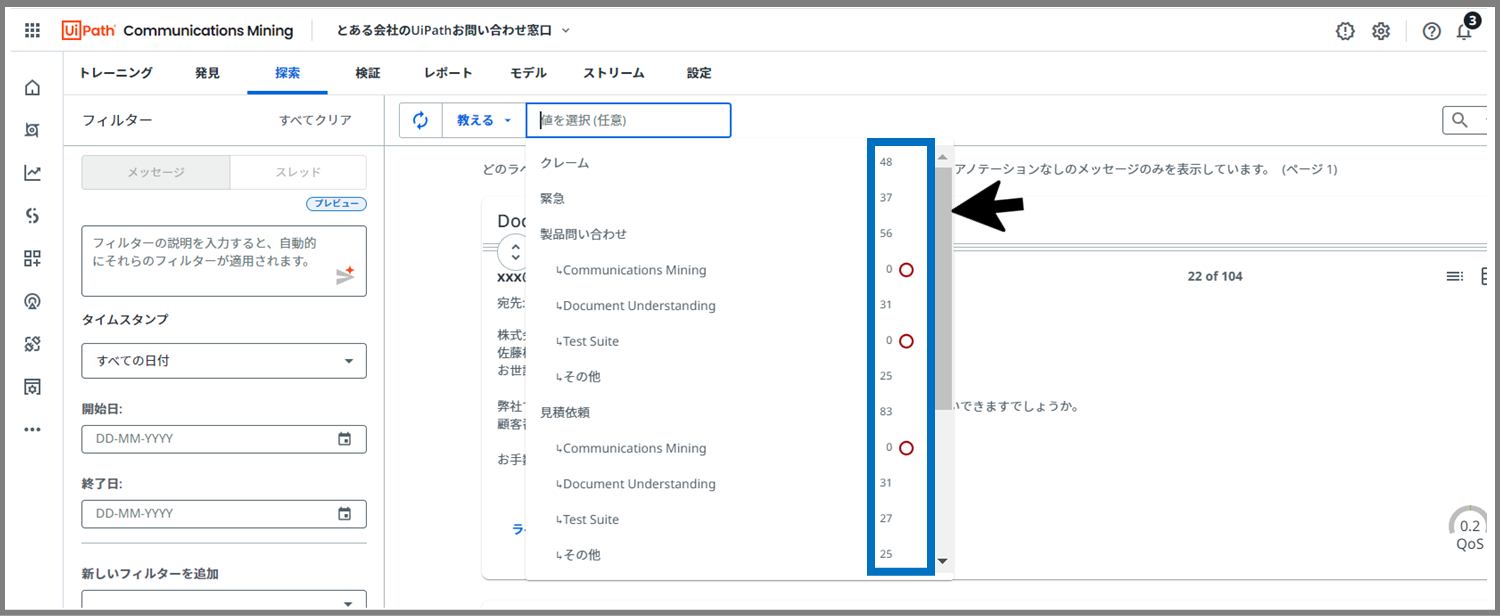
そもそものデータ自体がないもの以外はすべてラベルを適用し、赤丸が消えたら「教える」モードでのラベルのトレーニングは終了です!
もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
【公式ドキュメント】[ラベルを教える] を使用したトレーニング (探索)
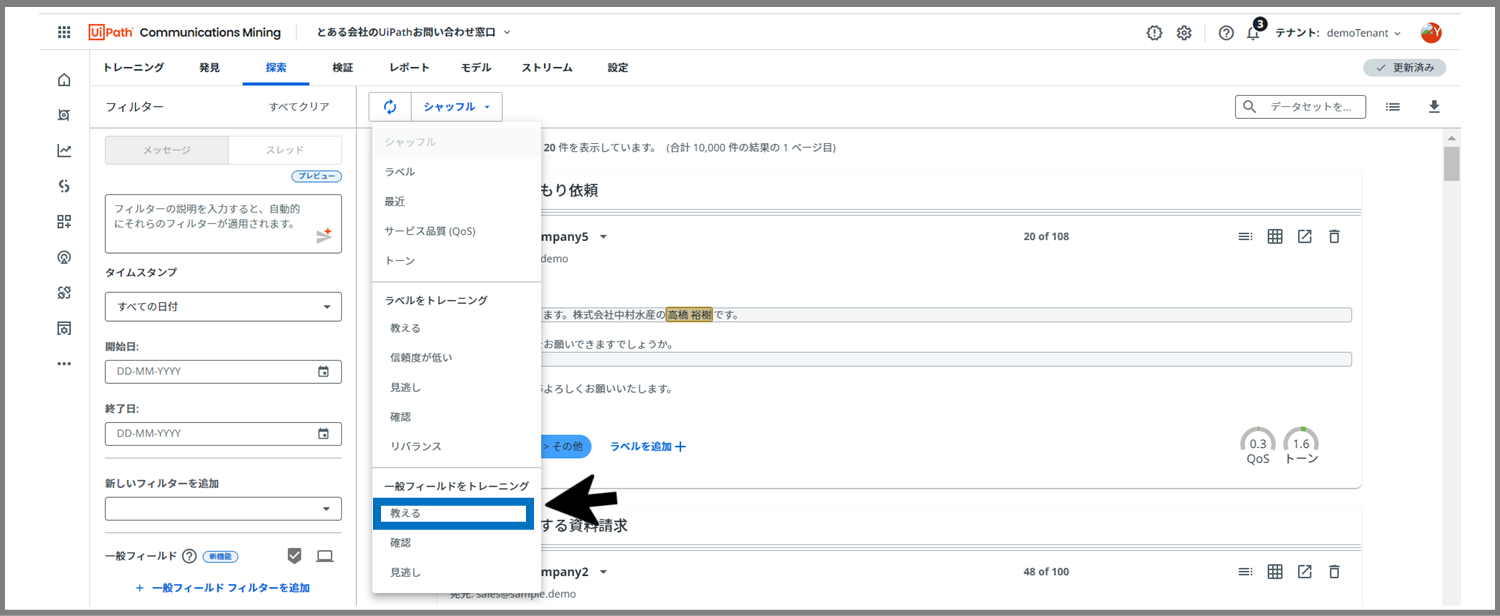
「教える」フェーズでの「ラベルのトレーニング」が終了したら、次は「一般フィールドのトレーニング」も行います。
ここでも、モデルの確信度50%程度のメッセージが表示されますので、それに対して一般フィールドを適用していきます。
今回のハンズオンシリーズを一緒に手を動かしながら行っている方は、ここは飛ばして大丈夫です。
※1-1. シャッフル の時に200件bの一般フィールドを適用したので、数は十分な状態になっているため。
それでは、次にいきましょう。
1-3. 信頼度が低い
最後は、「信頼度が低い」モードを利用したトレーニングを行います。
「信頼度が低い」は、探索フェーズの 最後の手順になります。
ここでは、モデルにとってラベル予測確信度が低いメッセージが表示されます。モデルの全体的なカバレッジ(網羅率)を向上させる上で有用なメッセージとなります。
これまでと同じ手順で、「信頼度が低い」を選びます。
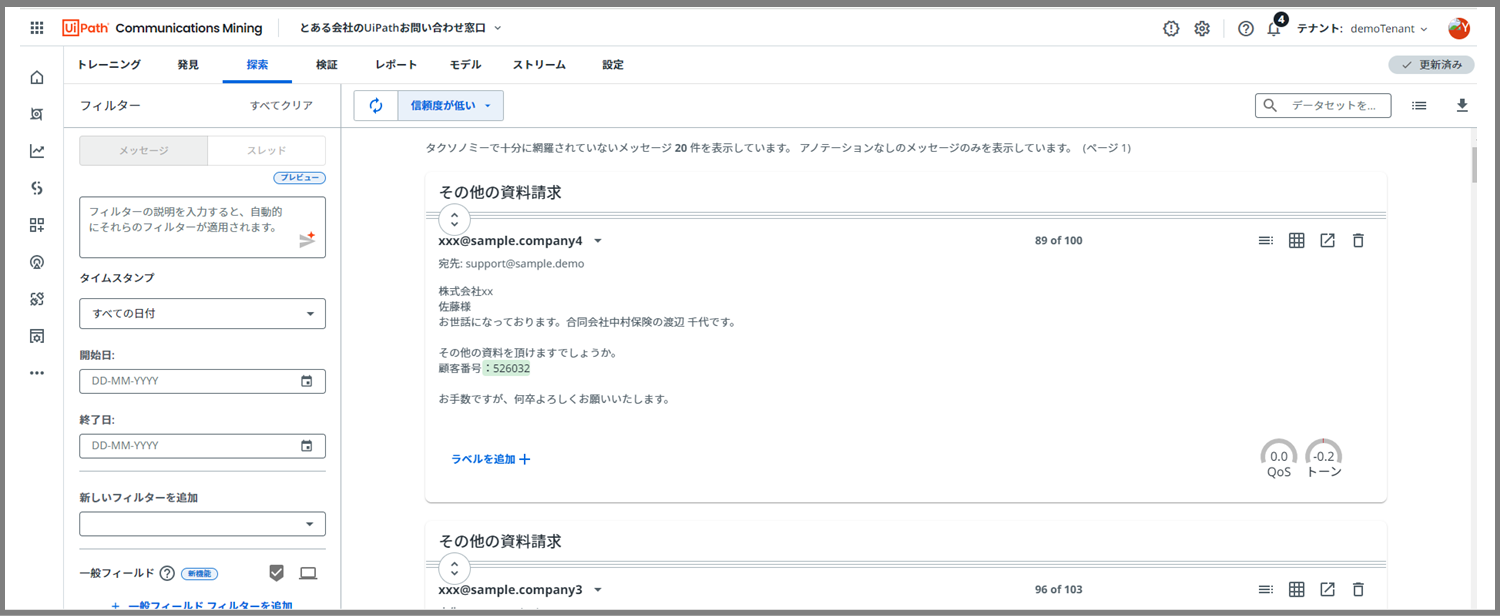
信頼度が低いラベル予測のメッセージが表示されました!
これから、100件のメッセージのラベル・一般フィールド付けをしていきます。
※「信頼度が低い」モードでの推奨ラベル付け件数は、公式では少なくとも100件と言われています。ここも、データの規模や複雑さによってはもっと必要となると思います。
ラベルや一般フィールド適用の手順は今までと同じです。
1-1-1. ラベルの適用 や 1-1-2. フィールドの適用 の手順と同様に、作業をしていきましょう。
もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
【公式ドキュメント】[信頼度が低い] を使用したトレーニング
2. 最後に
以上が、UiPath Communications Miningの「探索」フェーズにおけるトレーニングでした。
このフェーズでは、「シャッフル」「教える」「信頼度が低い」以外にも、様々なメッセージ表示方法がありますが、最初の段階としてはこの3つを網羅して頂ければ大丈夫です。
次回の記事では、「検証」ページで精度を確認したり、更なる向上のためのトレーニングをしていきますので、お楽しみに。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子