


みなさんこんにちは。
以前のブログ記事でAzure AI Searchの基礎的な内容をご紹介いたしました。
簡単なデータを使ってAzure AI Search入門(1) - サービスの概要
簡単なデータを使ってAzure AI Search入門(2) - ベクトル検索(前編)
簡単なデータを使ってAzure AI Search入門(3) - ベクトル検索(後編)
「簡単なデータを使ってAzure AI Search入門(1) - サービスの概要」でアナライザーについてご紹介しましたが、今回は言語アナライザーの違いを簡単に見比べてみたいと思います。
(おさらい) Azure AI Searchのアナライザー
以前のブログ記事でのご説明と重複いたしますが、型(データ型)が「Edm.String」かつ「検索可能」にチェックが入っているフィールドに関してはアナライザーの設定が存在します。 アナライザーはフルテキスト検索のために文章を小さな単位に分割したり、重要でない文字を削除したりします。(アナライザーの詳細についてはこちらをご参照ください。)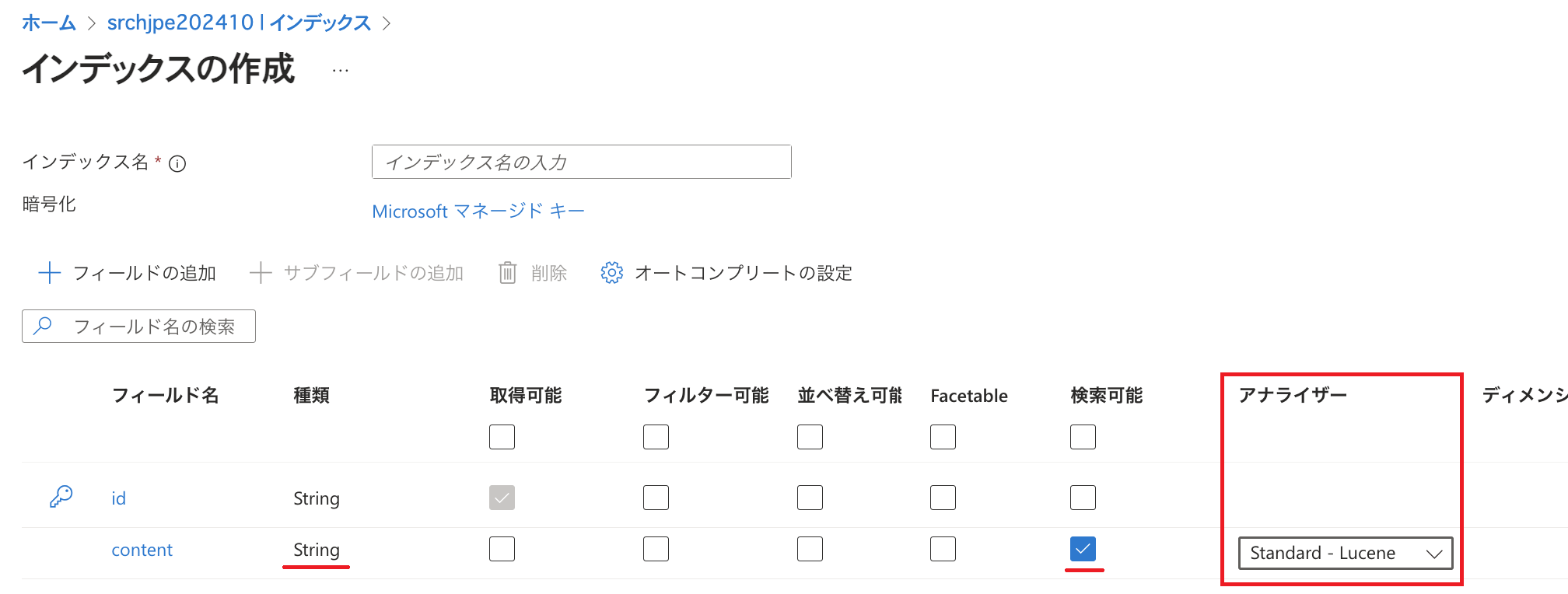
既定では「標準 - Lucene」(Standard - Lucene)というアナライザーが設定されますが、ある言語の特性を考慮した分析を行ってほしい場合は言語アナライザーを利用することが可能です。
例として日本語と英語を比べると分かりやすいかと思いますが、英語は単語と単語の間をスペースで区切って記述するのに対し、日本語は基本的に単語を続けて記述します。 ある一文から単語を抽出するという処理だけでも、言語によってやり方を変える必要がありそうだということをなんとなく感じ取っていただけたのではないでしょうか。 このように各言語の特性を考慮した上で、テキストを意味のまとまりごとに適切な箇所で区切ってトークンとして扱ったり、重要でない文字を削除したりするなどの処理ができるよう言語アナライザーが用意されています。
このように各言語の特性を考慮した上で、テキストを意味のまとまりごとに適切な箇所で区切ってトークンとして扱ったり、重要でない文字を削除したりするなどの処理ができるよう言語アナライザーが用意されています。
日本語の言語的な特性を考慮した分析を行えるよう、日本語に対応した言語アナライザーとして「日本語 - Lucene」ならびに「日本語 - Microsoft」が用意されています。  Microsoft Learnに記載の通りLuceneとMicrosoftは機能が異なるため、可能であれば両方のアナライザーを比較するよう案内されています。 今回は簡単なテキストを使って「日本語 - Lucene」と「日本語 - Microsoft」、さらに既定の設定である「標準 - Lucene」のそれぞれでどのようにテキストがトークン化されるかを確認してみたいと思います。
Microsoft Learnに記載の通りLuceneとMicrosoftは機能が異なるため、可能であれば両方のアナライザーを比較するよう案内されています。 今回は簡単なテキストを使って「日本語 - Lucene」と「日本語 - Microsoft」、さらに既定の設定である「標準 - Lucene」のそれぞれでどのようにテキストがトークン化されるかを確認してみたいと思います。
テキストのトークン化を確認するための準備
Azure AI Searchではテキストがどのようにトークン化されるかを確認するため「Analyze API」が用意されていますので、今回はこちらを利用します。
※ Azure AI Search(データプレーン)のREST APIリファレンスについてはこちらをご参照ください。
利用するツール
今回はツールとしてVisual Studio CodeのREST Clientを使用します。(Analyze APIに関する資料ではありませんが、REST ClientによりAzure AI SearchのAPIを利用する方法についてMicrosoft Learnに記載がありますので参考情報としてご案内いたします。) 
レスポンスボディのUnicodeが日本語で表示されるよう、REST Clientの設定で「Decode Escaped Unicode Characters」を有効にしておきました。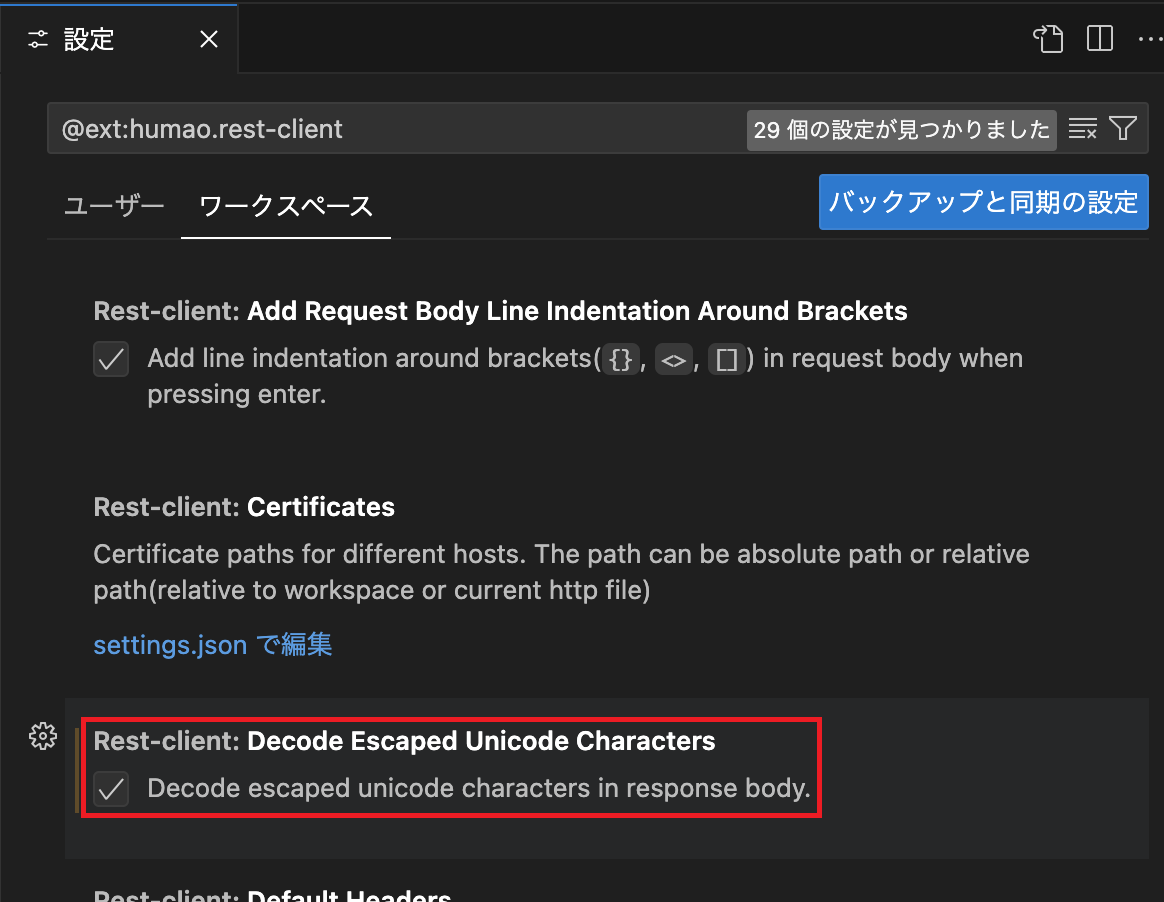
Azure AI Searchリソースの準備
APIを利用するにはAzure AI Searchリソースならびにインデックスが必要です。 リソース作成については以前のブログ記事でご紹介しておりますのでご参照ください。
今回は認証にAzure AI Searchの管理者キーを利用します。 キーはAzure AI Searchの「設定」配下にある「キー」で確認可能です。 Azure AI Searchのキーならびにキーにアクセスするためのアクセス許可などについてはこちらをご参照ください。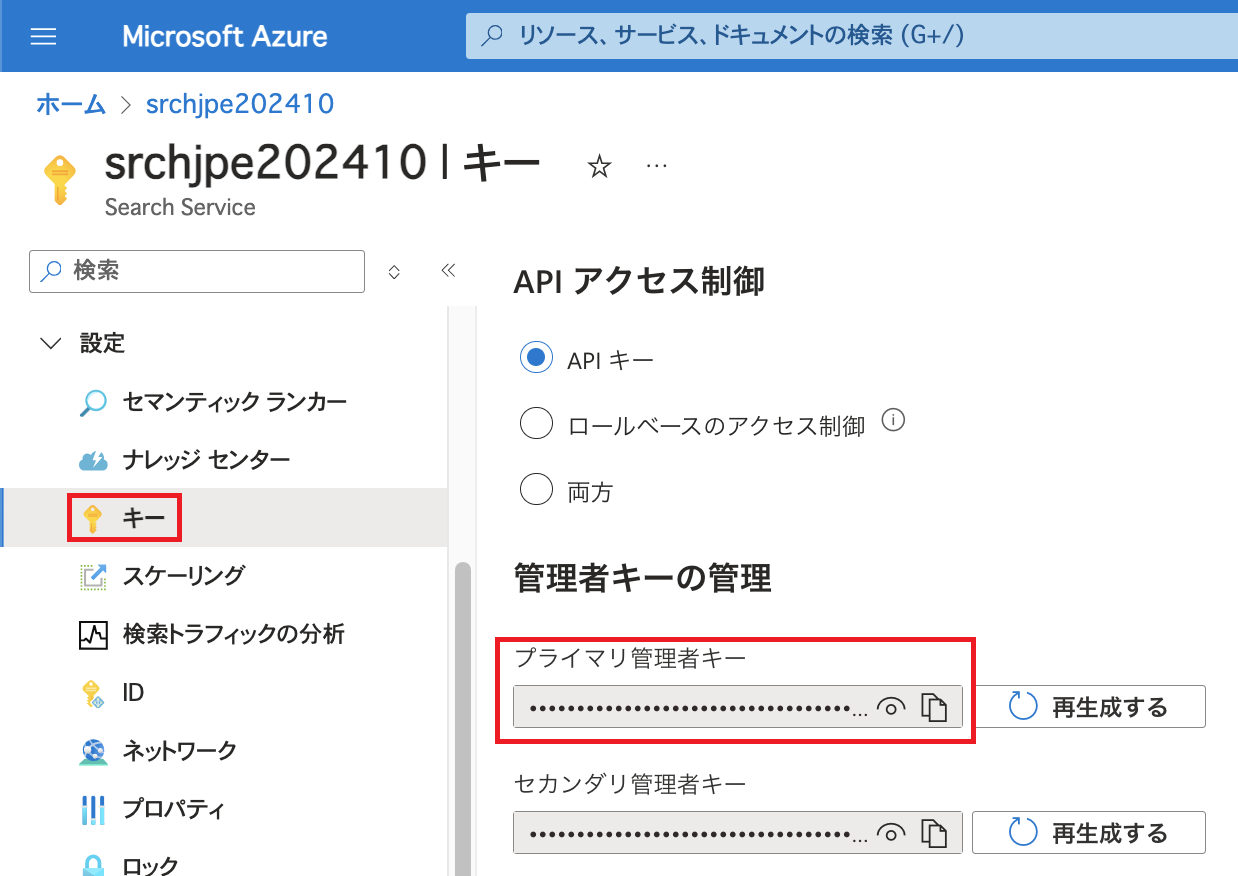
キーの取り扱いに関して
キーの取り扱いにはご注意ください。 不正利用やデータ漏えいを防ぐためキーは厳重に管理し、公開はしないようにしましょう。 Microsoft Learnのベストプラクティスもご参照ください。
変数の設定
「.env」ファイルを作成し、以下のように設定します。
SRCH_NAME=<Azure AI Searchのリソース名> SRCH_INDEX=<Azure AI Searchのインデックス名> SRCH_ADMINKEY=<Azure AI Searchの管理者キー>
次に拡張子「.http」のファイルを「.env」と同じディレクトリに新規作成し、以下のように変数を指定しました。
@text = <動作を確認するためのテキスト>

動作確認用のテキストについて、今回は「2024年7月のブログ記事では、架空のアイテムA3F6G7Hが含まれるデータを使ってAzure AI Searchのインデックス作成についてご紹介しました。」という一文にしました。 後ほどこのテキストに対する各アナライザーの処理結果を見てみます。 文中の「2024年7月のブログ記事」とはこちらのことですが、このブログ記事の中で扱った架空のアイテムID(ランダムな英数字の並び)や年や月の記載、さらに日本語だけでなく英単語がどのような扱いになるかといったことを確認するためこのようなテキストを用意しました。
リクエスト
先ほどの変数の指定の後に、Analyze APIのリファレンスを参考に以下のリクエストを記述します。
POST https://{{$dotenv SRCH_NAME}}.search.windows.net/indexes('{{$dotenv SRCH_INDEX}}')/search.analyze?api-version=2024-07-01
content-type: application/json
api-key: {{$dotenv SRCH_ADMINKEY}}
{
"text": "{{text}}",
"analyzer": "<アナライザー名>"
}
"text"でアナライザーの動作を確認するためのテキストを指定し、"analyzer"でアナライザーを指定します。 アナライザー名の指定についてはこちらをご参照ください。 例えば「日本語 - Lucene」であれば「ja.lucene」と指定します。
今回はアナライザーごとにリクエストを記述しました。ここでは「###」でリクエストを区切り、コメントを記載しています。 上から順に「日本語 - Lucene」「日本語 - Microsoft」「標準 - Lucene」をそれぞれ指定しています。
レスポンス
"Send Request"をクリックするとリクエストが送信され、画面右側のようにレスポンスが表示されます。どのようにトークン化されたかをJSON形式で確認できます。 以下は「日本語 - Lucene」を指定してリクエストを送信した画面です。
※今回はアナライザーごとにリクエストを分けて記述していますので、別のアナライザーについて確認したい場合は当該リクエストの"Send Request"をクリックします。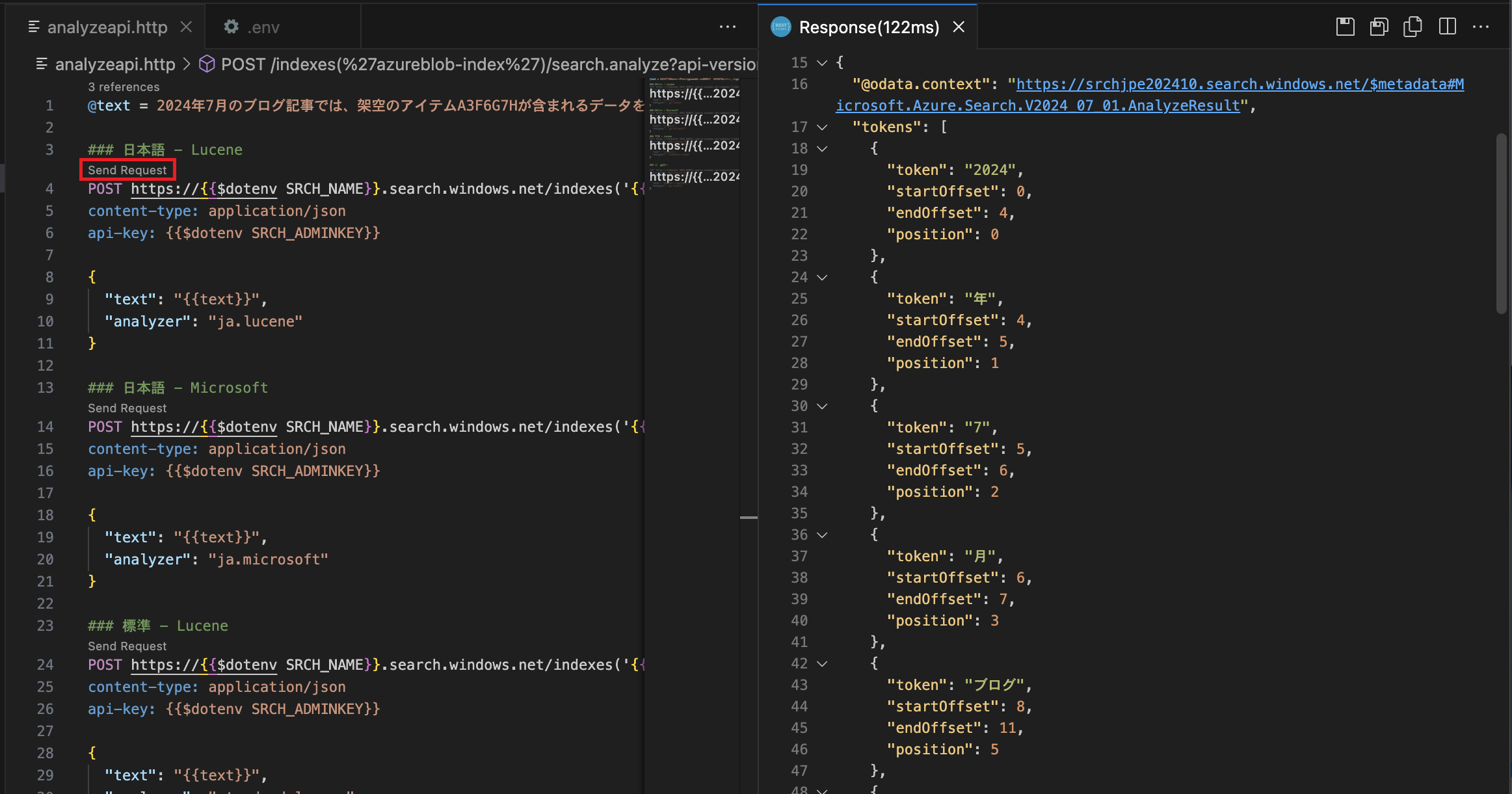 JSON形式では行数が多く少々見づらいかと思いますので、各アナライザーでどのようにトークン化されたかを表にしました。(リクエスト送信時にはテキストを1行で記述していましたが、以下の表ではスペースの都合上テキストを前半後半に分けて記載しています。)
JSON形式では行数が多く少々見づらいかと思いますので、各アナライザーでどのようにトークン化されたかを表にしました。(リクエスト送信時にはテキストを1行で記述していましたが、以下の表ではスペースの都合上テキストを前半後半に分けて記載しています。) 3点のアナライザーの結果を見比べてみると、句読点を除去する、アルファベット大文字を小文字にする、"azure"のような英単語をひとつのトークンとするといった共通点もありますが、処理の差異も見受けられます。 この表では特徴的な部分をいくつかピックアップしてマーキングしています。
3点のアナライザーの結果を見比べてみると、句読点を除去する、アルファベット大文字を小文字にする、"azure"のような英単語をひとつのトークンとするといった共通点もありますが、処理の差異も見受けられます。 この表では特徴的な部分をいくつかピックアップしてマーキングしています。
青: 年と月
「日本語 - Microsoft」では「2024年」と「7月」というように年と月の単位でトークン化されています。 「日本語 - Lucene」と「標準 - Lucene」では数字と「年」「月」を分けてトークンにしています。
黄: アイテムIDを模したランダムな文字列
「日本語 - Lucene」では一文字ずつトークンになっており英数字の連続性が失われた一方、「日本語 - Microsoft」と「標準 - Lucene」ではひとまとまりでトークンになっています。
緑: 動詞の活用形
「日本語 - Lucene」では「含む」、「使う」といったように動詞の活用形が変えられた上でトークンになっています。
紫: 単語の分割
「標準 - Lucene」では「ブログ」「アイテム」などひとつのトークンとして扱っている言葉もあるものの、ひらがなや漢字の1文字を1トークンとしてしまう傾向が見受けられます。 「記事」や「架空」などが分かりやすい例ではないでしょうか。(マーキングしてはいませんが「ついて」「しました」なども1文字ずつトークンになっています。)
灰: 重要性の低い言葉の扱い
「標準 - Lucene」ではスペースや句読点は除去されているものの、「が」「の」「を」などのトークンが除去されずに残っています。 なお、これとは反対に「日本語 - Lucene」では助詞を中心に重要性の低い言葉が除去される傾向が強く見受けられました。(「日本語 - Microsoft」においても重要性の低い言葉の除去は見受けられますが、「日本語 - Lucene」の方がより多く除去した結果になりました。)
オレンジ: 複数の表記
「日本語 - Microsoft」では「インデックス」という言葉に対し「インデッキス」というトークンも作成されました。 APIのレスポンスでは以下のような形式で表記されています。 Analyze APIのリファレンスを見ると、アナライザーによってはシノニムなどトークンが同じ位置に来ることがあるようです。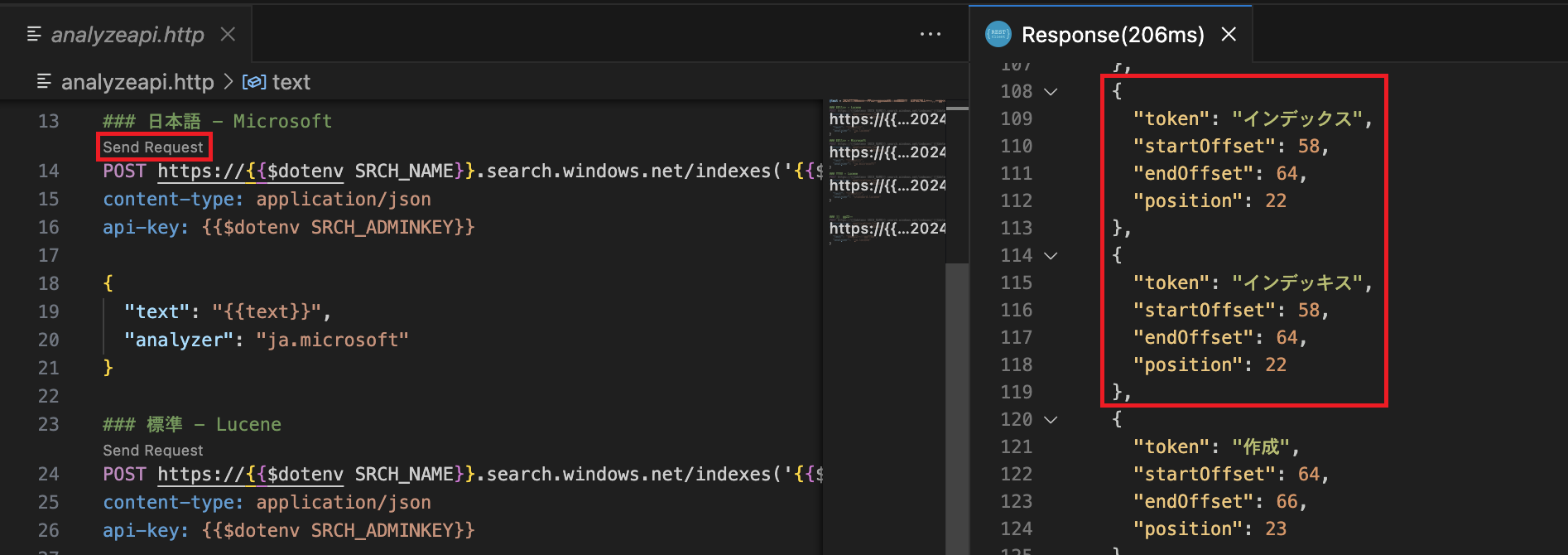
【補足】レスポンスに含まれる startOffset / endOffset / position について
レスポンスにはJSON形式で、tokenの他にstartOffset / endOffset / positionという項目が存在します。検索結果が期待したものと異なるような場合の調査にAnalyze APIが役立つこともあるかと思いますので、これらの項目の意味について補足いたします。
以下は「日本語 - Lucene」を指定したサンプルです。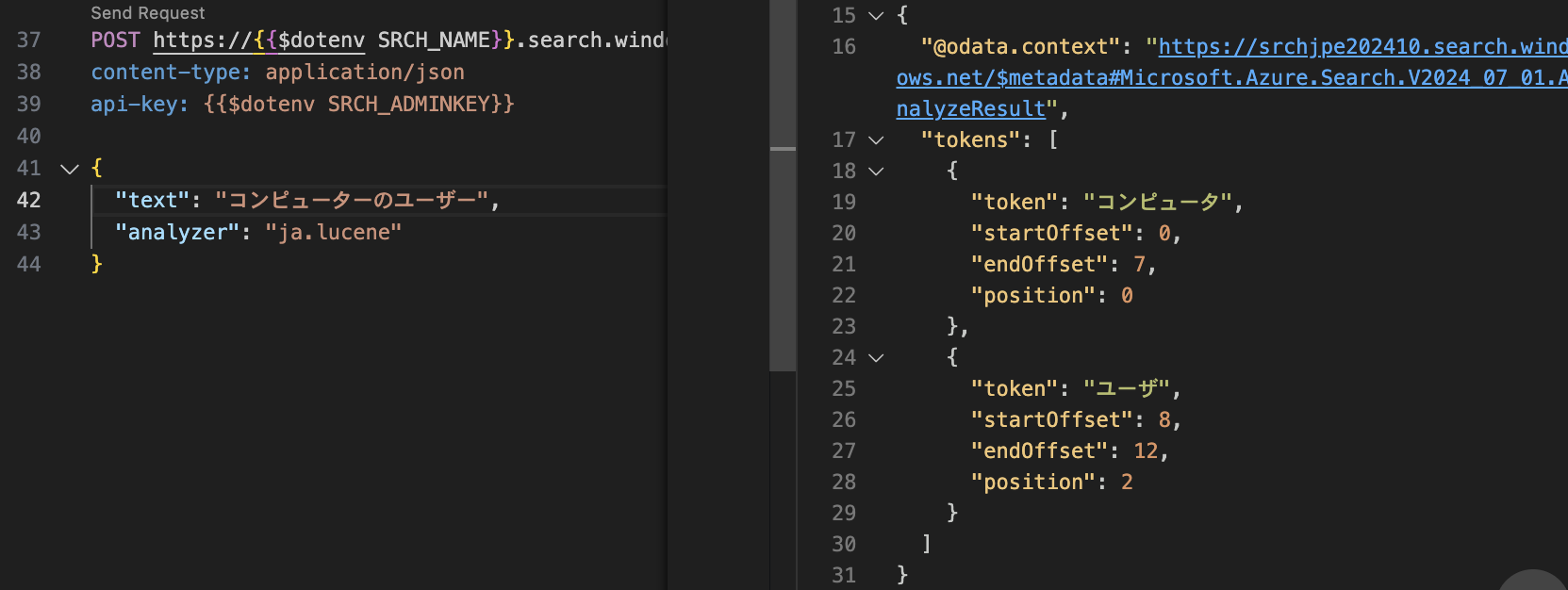 startOffsetは入力されたテキストにおける開始位置、endOffsetは終了位置を示しています。 テキストの先頭を0としてカウントします。 例えば 「コンピュータ」のトークンは、入力テキストの位置0から7に対応していることが分かります。
startOffsetは入力されたテキストにおける開始位置、endOffsetは終了位置を示しています。 テキストの先頭を0としてカウントします。 例えば 「コンピュータ」のトークンは、入力テキストの位置0から7に対応していることが分かります。
positionは入力されたテキストにおいていくつめのトークンかを示します。 こちらも先頭を0としてカウントします。 今回の例では「コンピュータ」は0番目のトークンです。 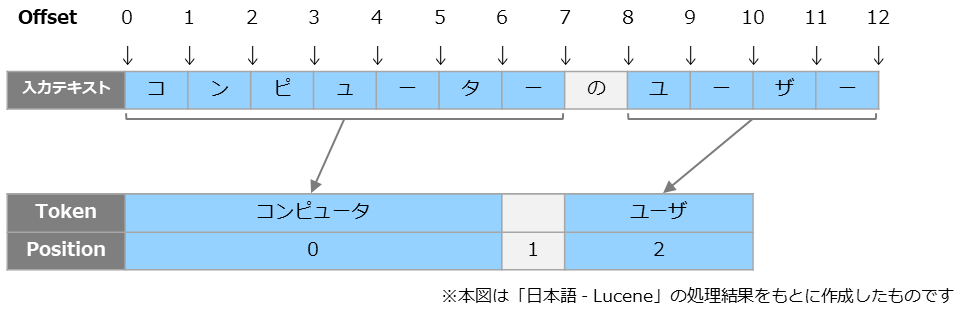
まとめ
今回はAzure AI Searchの言語アナライザーの処理結果を簡単に比較してみました。 結果を並べてみるとアナライザーごとの違いが分かりやすくなるかと思います。 同じ日本語向けのアナライザーであってもLuceneとMicrosoftでは処理が異なっている様子が見て取れます。
また、今回は日本語の言語アナライザーだけではなく「標準 - Lucene」の結果も併せてご紹介しました。 結果を並べてみると、日本語のテキストに対して言語アナライザーを利用することの意義が分かりやすくなるかと思います。 先の表において、特に紫と灰の部分に注目いただくと言語アナライザーの価値を感じられるのではないでしょうか。
Azure AI Searchで扱うデータはお客様ごとにさまざまかと思います。 今回は簡単な一文をサンプルとしてご紹介しましたが、別のテキストをAnalyze APIでお試しいただくと、また新たな言語アナライザーの特徴や特性が見えてくるかもしれません。 お客様で扱われる文書の特徴や傾向を鑑み、どのアナライザーを利用するかご検討いただければと思います。 なお、Microsoft Learnではアナライザーによってインデックス作成の所要時間が変わる場合もあることが言及されていますのでご留意ください。
Azureを取り扱われているパートナー企業様へ様々なご支援のメニューを用意しております。 メニューの詳細やAzureに関するご相談等につきましては以下の「Azure相談センター」をご確認ください。
Azure相談センター
https://licensecounter.jp/azure/
※ 本ブログ記事は弊社にて把握、確認された内容を基に作成したものであり、サービス・製品の動作や仕様について担保・保証するものではありません。サービス・製品の動作、仕様等に関しては、予告なく変更される場合があります。
Azureに関するブログ記事一覧はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 技術統括部 第2技術部 2課
中原 佳澄
