


こんにちは。SB C&S の村上です。
この記事ではDCGM Exporterを用いたGPUの可視化について紹介します。
GPU可視化の必要性について
昨今生成AIの流行に伴い、GPUを搭載したサーバーの採用が増加しました。
GPUは高価で、一台を複数のユーザーやジョブで使い回す共有資源となり、利用効率・健全性・コストのどれかが崩れるとビジネスへの影響に直結します。
そのため運用では、GPUが不具合なく、最適なサイズ感で使われているかを継続的に確認する必要があり、その判断材料としてGPUのステータスの可視化が欠かせません。
可視化の方法としてまず思いつくものとして、nvidia-smiコマンドがあると思います。
これはNVIDIAのGPUドライバと合わせてインストールされるもので、GPUの利用率や温度などの情報を素早く確認することができます。
また、OSSのnvtopやgpustatといったCLI上で少しグラフィカルに確認することができるツールなども利用されると思います。
ただし、これらのツールは手元での確認は便利ですが、次のような観点では向きません。
- 複数台にわたるGPUの可視化
- 日/週/月の推移といった時系列での可視化
複数台ホストで実行しているジョブにてGPUでの処理が重い際にどのホストで負荷がかかっているかを素早く確認するには複数台をまとめて見られることが望ましいです。
また、最適なサイズの判断としてピーク時にどれくらいGPUが利用されているかのデータがある方が望ましいです。
こういった要件にも対応できる方法として、DCGM Exporterを用いた可視化方法を構築の流れを含めて紹介します。
DCGM Exporter とは
DCGM Exporterは、GPUの情報を収集し、Prometheusの形式で公開するNVIDIAのソフトウェアとなります。
公開されたGPUの情報をPrometheusで収集し、Grafanaで可視化させることで、複数台にわたってGPUの使用率などの情報を時系列でグラフィカルに表示させることができます。
- Prometheus:メトリクスを時系列データとして収集・保存するOSS
- Grafana:Prometheusなどのデータを見やすいダッシュボードで表示するOSS
イメージをもう少し具体化するために図を合わせて解説します。
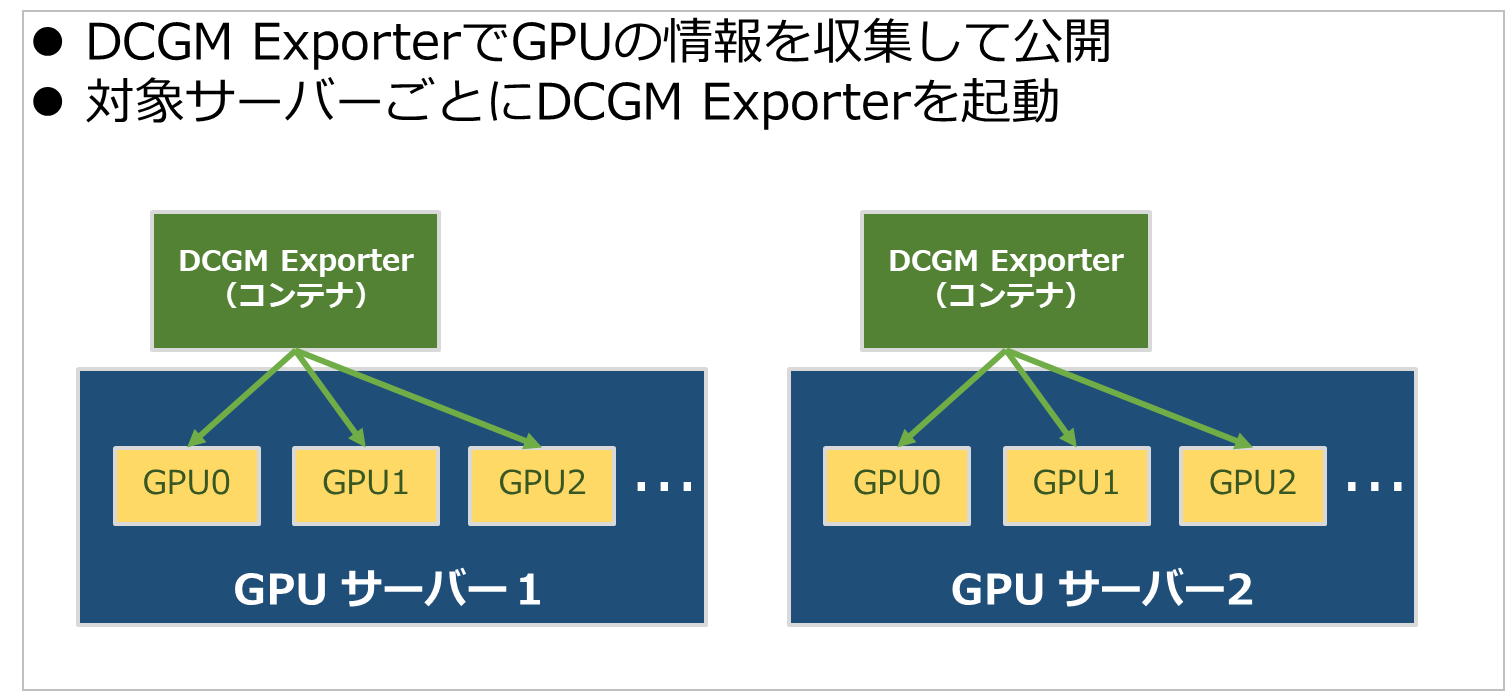
流れとしてまずDCGM Exporterは各サーバー上で動作しGPUの情報を収集し公開してくれます。
GPUサーバーが複数ある場合はそれぞれで起動を行います。
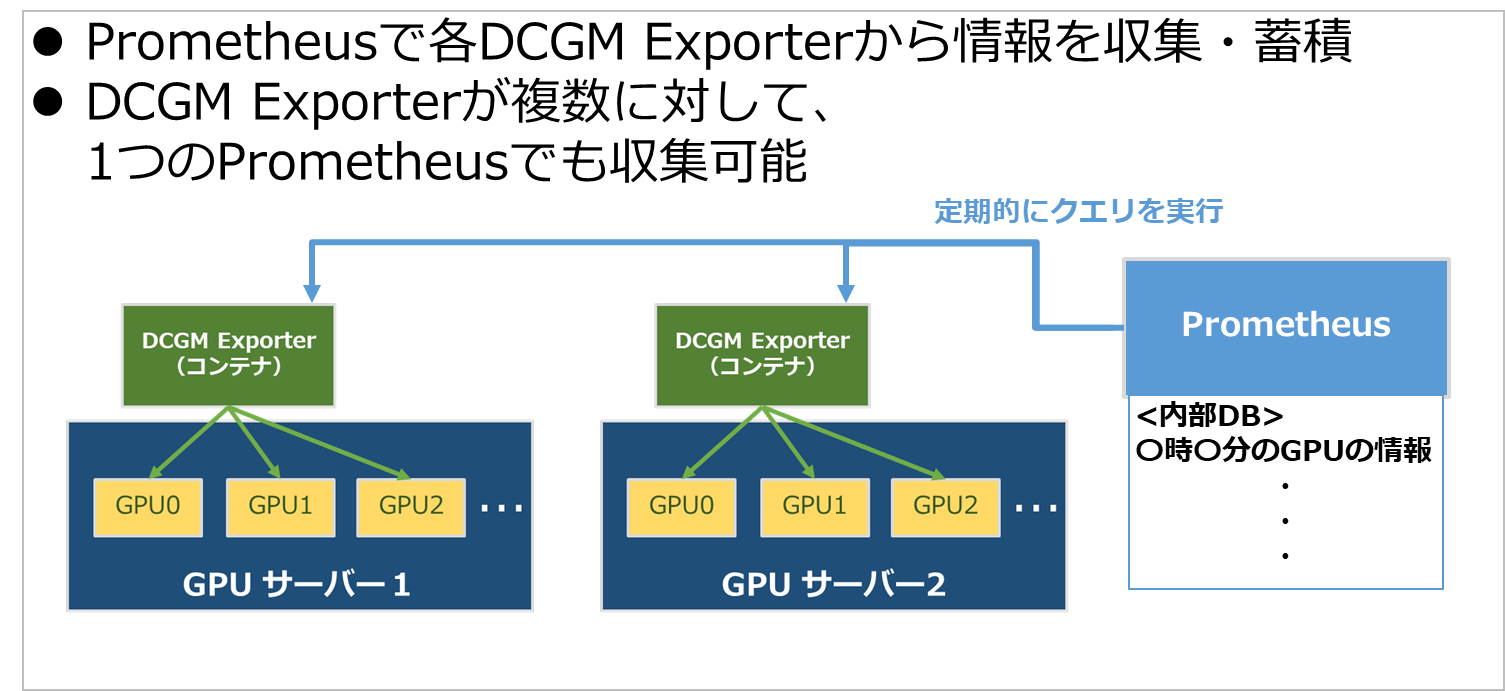
DCGM Exporterが収集・公開した情報はPrometheusにて収集し、随時蓄積していきます。
対象となるサーバーが複数ある場合でもそれらを収集可能です。
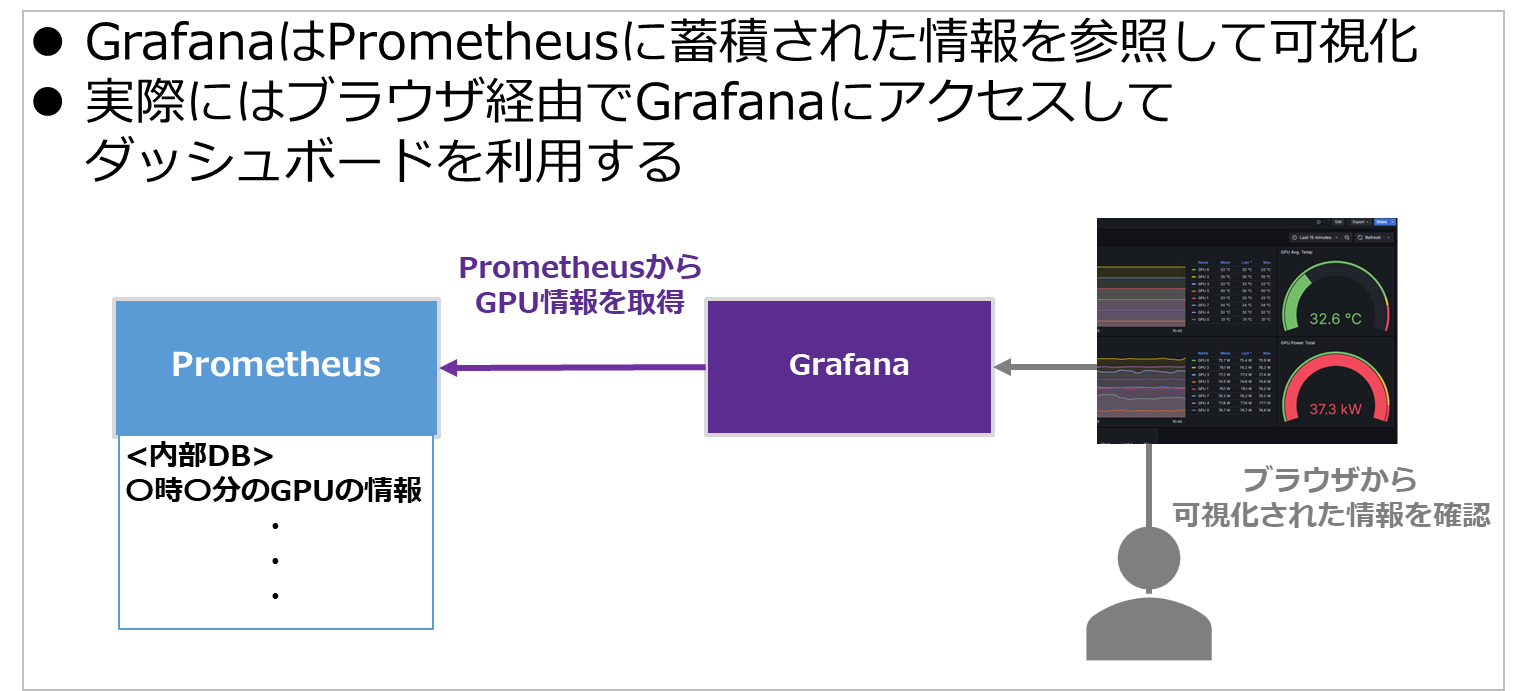
最終的にPrometheusの蓄積された情報をGrafanaでグラフィカルに可視化します。
実際にはブラウザからアクセスして利用することができるダッシュボードで可視化された情報を確認できます。
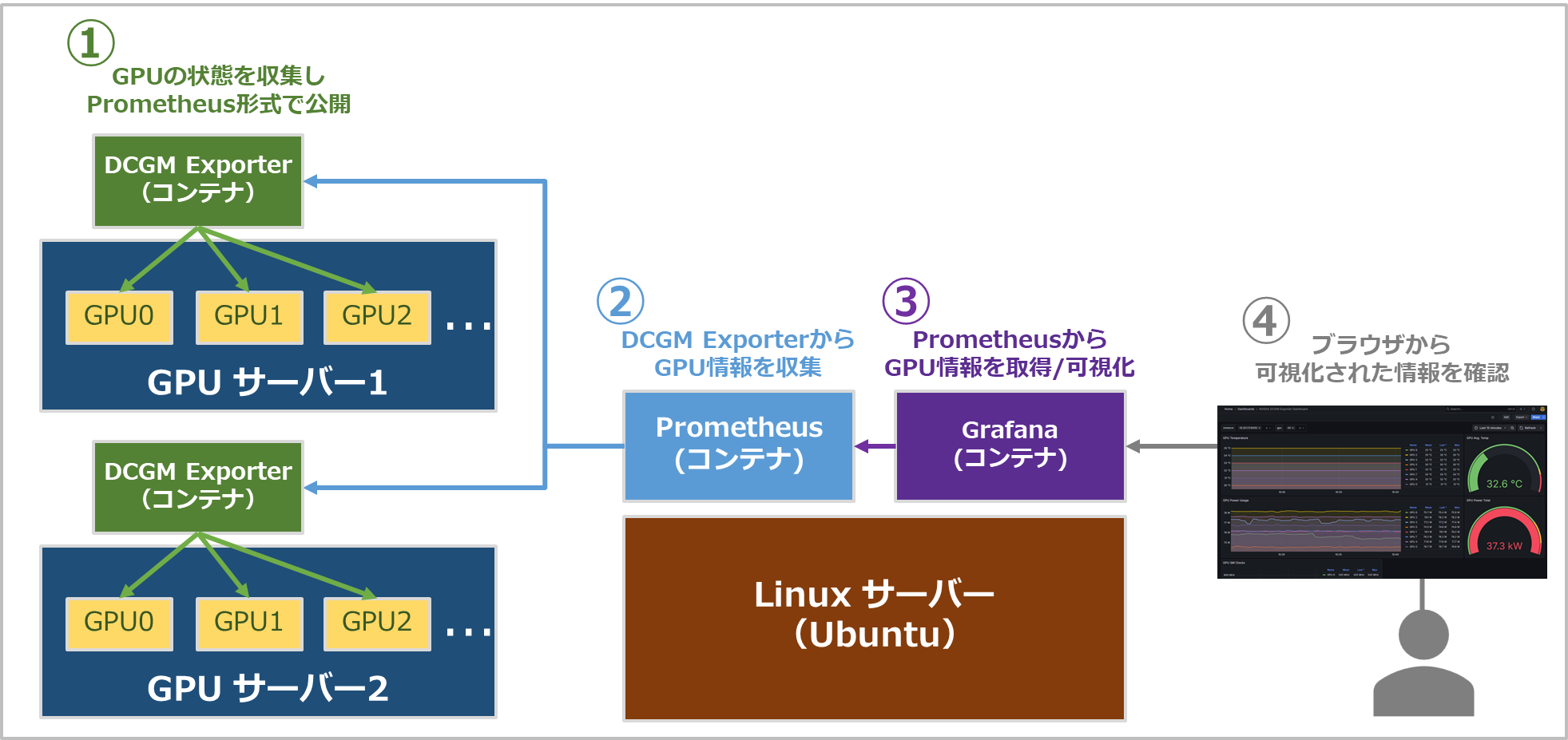
このようにDCGM ExporterとPrometheus、Grafanaを組み合わせて利用することで、複数台にわたってGPUの情報を時系列で取得・可視化させることが可能となります。
なお、DCGM Exporter自体はコンテナとして提供されています。
NVIDIAのGPUをコンテナで利用できる状態であれば、そのまま利用することができるものとなるため、追加ソフトウェアなどのインストールが不要になります。
構築例の紹介
それではDCGM Exporterを用いた可視化の構築を紹介します。
今回の構築では以下図のように2台のGPUサーバーにDCGM Exporterのコンテナを展開します。
PrometheusおよびGrafanaは別のLinux(Ubuntu)のマシン上にコンテナとして展開します。
今回利用する各マシンの前提条件としては以下となります。
- 可視化対象のGPUサーバー
- GPUコンテナが利用できる状態
- コンテナランタイム
- コンテナランタイム拡張 (NVIDIA Container Toolkit)
- GPUコンテナが利用できる状態
- モニタリング用のサーバー
- コンテナが利用できる状態
- コンテナランタイム
可視化対象側はGPUコンテナが利用できる状態、モニタリング用のサーバーはコンテナランタイムがあれば問題ないです。
DCGM Exporterの展開
それではまずDCGM Exporterの展開を行っていきます。
DCGM Exporterの展開は監視対象のマシン上にてコンテナを起動するのみとなります。
コンテナイメージはNVIDIAのNGC Catalogというサイト上から確認・取得することができます。
実際にNGC Catalogにアクセスすると以下画像のようにコンテナイメージのパスなどが取得でき、あとはDockerコマンドで実行することでそのまま利用できます。
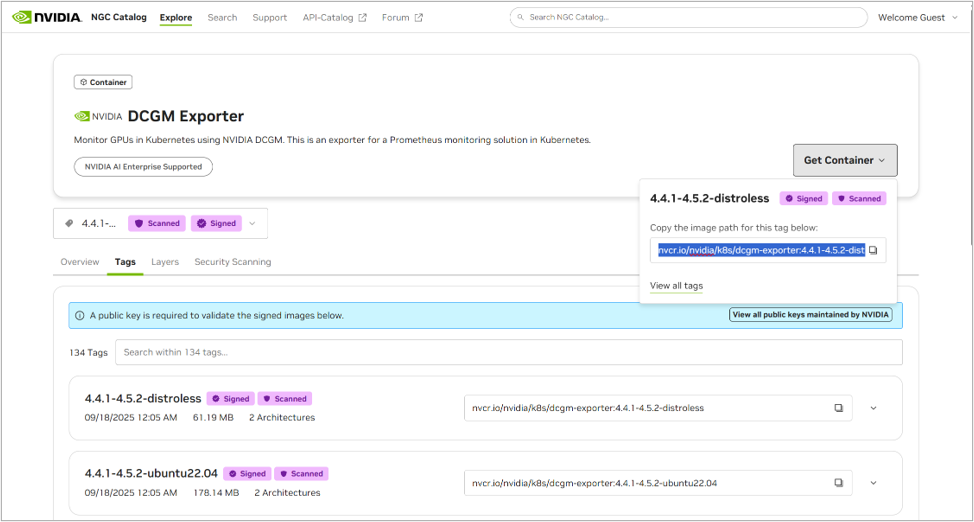
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/k8s/containers/dcgm-exporter
それでは早速コンテナを起動していきます。
コンテナを起動するコマンド例は以下となります。
docker run -d --rm \
--gpus all \
--cap-add SYS_ADMIN \
-p 9400:9400 \
--name dcgm-exporter \
nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04
dockerコマンドのオプションの説明は以下です。
- gpus all: GPUをコンテナに割り当て(収集の対象とするGPUは少なくとも必要)
- cap-add SYS_ADMIN: GPUドライバに対する操作が行われるため、特権をコンテナに付与
起動後は<マシンIP>:9400/metricsに対してリクエストを行うと、GPUの情報が取得できます。
一度動作確認のため、curlコマンドを用いてリクエストを実施します。
なお、そのままだと出力が多いため、今回は以下コマンドでGPUのメモリ使用状況に絞って表示します。
curl -s 10.20.1.12:9400/metrics | grep DCGM_FI_DEV_FB_USED
出力例
# HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB).
# TYPE DCGM_FI_DEV_FB_USED gauge
DCGM_FI_DEV_FB_USED{gpu="0",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 973
DCGM_FI_DEV_FB_USED{gpu="1",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
DCGM_FI_DEV_FB_USED{gpu="2",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
DCGM_FI_DEV_FB_USED{gpu="3",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
DCGM_FI_DEV_FB_USED{gpu="4",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 19215
DCGM_FI_DEV_FB_USED{gpu="5",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
DCGM_FI_DEV_FB_USED{gpu="6",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
DCGM_FI_DEV_FB_USED{gpu="7",<~省略~>,DCGM_FI_DRIVER_VERSION="570.124.06"} 0
出力例の右側の数字がGPUメモリの使用状況(MB)になります。
例えば現在はGPU0は973MB、GPU4は19215MB、それ以外は利用されておらず、正常に動作していることが確認できます。
これにてDCGM Exporterの準備の流れは以上となり、あとは必要な台数分それぞれ同じ作業を実施しておきます。
補足
今回は利用しませんでしたが、DCGM Exporterは実行時にオプションで、GPUの情報を収集する頻度や収集する情報のコントロールなどが可能となります。
代表的なものは以下となります。
- $DCGM_EXPORTER_COLLECTORS (-f)
- 収集する情報をCSVファイルで設定
- デフォルト値は公式GitHubのCSVを参照
- $DCGM_EXPORTER_INTERVAL (-c)
- 収集する頻度の指定
- デフォルト値は30秒
その他オプションに関しては、以下公式ドキュメントをご参照ください。
https://docs.nvidia.com/datacenter/dcgm/latest/gpu-telemetry/dcgm-exporter.html#dcgm-exporter-customization
Prometheusの展開
続いてPrometheusの展開を進めていきます。
展開方法としては、公式のバイナリを使ってマシンで実行させる方法かコンテナとして展開する方法に大きく分けられます。
この記事ではコンテナとして展開を行っていきます。
※他の展開方法に関してはPrometheusの公式ドキュメントをご参照ください
https://prometheus.io/docs/prometheus/latest/installation/
利用するコンテナイメージはDocker Hubに公式から公開されているため、そこから利用します。
https://hub.docker.com/r/prom/prometheus
まず実行マシン上にPrometheus用のフォルダの作成を行います。
Prometheusは情報の収集と蓄積を行います。そのデータはマシン上に直接蓄積させるために、格納用のフォルダが必要となります。
また、設定ファイルもPrometheusに渡す必要があるため、設定ファイルを置いておくフォルダもここで準備しておきます。
今回は以下のようなフォルダを準備しておきます。
- 蓄積用フォルダ: /var/lib/prometheus
- 設定ファイル用フォルダ: /etc/prometheus
コマンドとしては以下のように実行しておきます。
sudo mkdir /var/lib/prometheus
sudo mkdir /etc/prometheus
ここで注意点としてPrometheusは非rootの権限でコンテナが起動し、nobody(UID:65534)のユーザーで実行されます。
そのため、Prometheusからデータの書き込みが発生する蓄積用フォルダに関しては以下のコマンドで所有者の変更が必要となります。
sudo chown -R 65534:65534 /var/lib/prometheus
続いて、Prometheusは設定ファイルをもとに情報の収集を行うため、ファイルの作成を行います。
今回設定ファイルに必要な内容として以下の2つを記載していきます。
- 情報収集の頻度
- 収集先のサーバーの指定 (DCGM ExporterのIP:ポート)
今回利用する設定ファイルは以下となり、/etc/prometheus/prometheus.ymlとして作成しておきます。
global:
scrape_interval: 30s
scrape_configs:
- job_name: 'dcgm-exporter'
static_configs:
- targets: ['<GPUサーバー1のIP>:9400']
- targets: ['<GPUサーバー2のIP>:9400']
情報収集の頻度に関しては、DCGM Exporterはデフォルトで30秒単位のため、合わせて30秒としています。
設定ファイル下部のtargetsのところには前手順で構築したDCGM Exporterのコンテナに接続するためのIPアドレスとポート番号を2台分指定しています。
それではコンテナの起動を行います。
起動コマンドのオプションに作成した設定ファイルとフォルダを指定する形で以下コマンドを実行します。
docker run -d --rm \
-p 9090:9090 \
-v "/etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro" \
-v /var/lib/prometheus:/prometheus \
--name prometheus \
prom/prometheus:v3.6.0
コンテナが起動したら、Prometheusはその段階から収集と蓄積を開始します。
PrometheusにはWeb UIも用意されているため、そこから取得できているかを確認します。
ブラウザからhttp://<モニタリング用マシンのIP>:9090にアクセスします。
すると以下のようなPrometheusの画面が表示されます。
ここでは収集したデータの項目を指定することで、その情報を参照することができます。
試しにGPUメモリの利用状態を確認します。
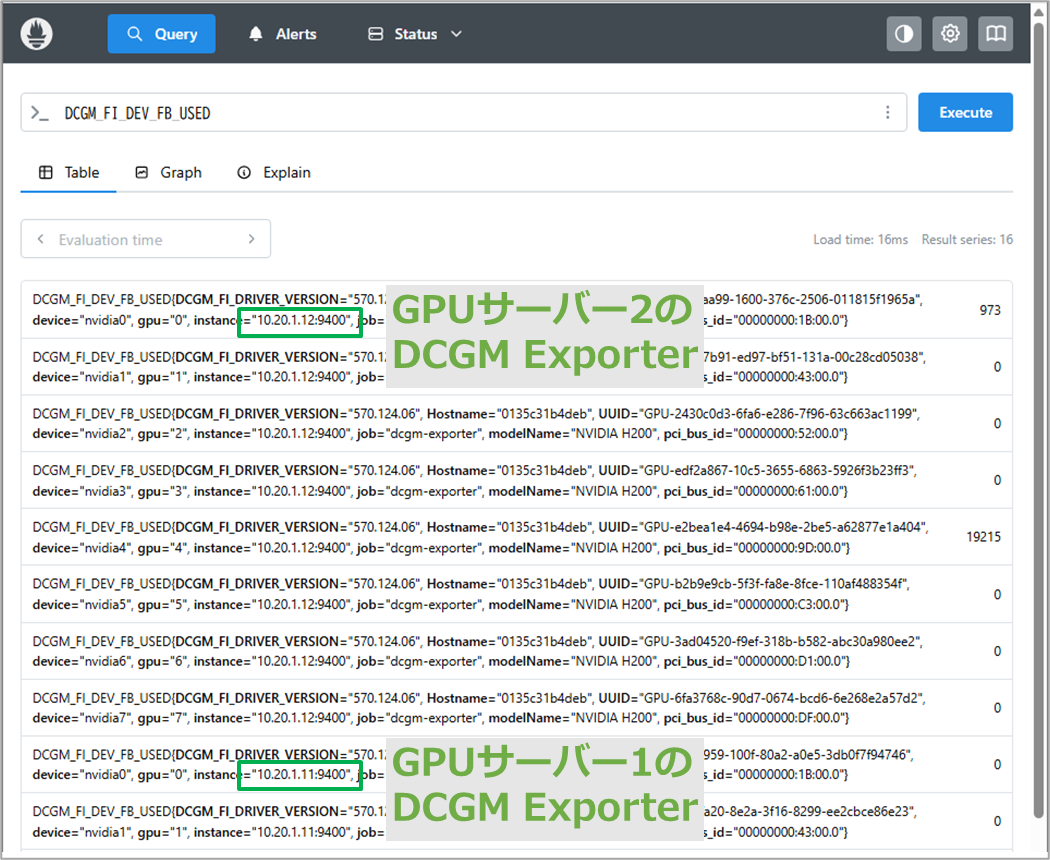
画面上部の入力欄にDCGM_FI_DEV_FB_USEDと入力してExecuteを選択すると、以下画面のようにGPUの情報が取得できます。
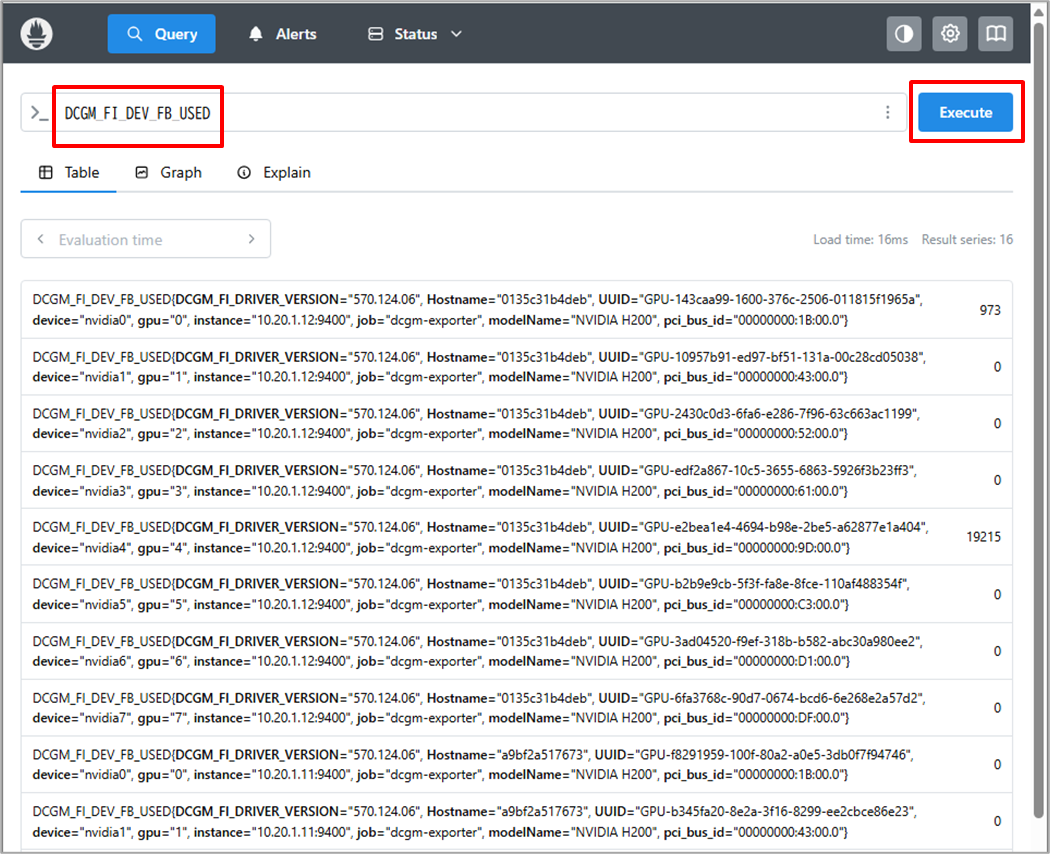
今回の設定ファイルでは、targetsで2台のGPUサーバーのDCGM Exporterを指定したため、2台とも取得できていることも見られます。
また、Graphを選択すると、以下図のようにPrometheusが起動したタイミングから時系列で取得できていることも確認できます。
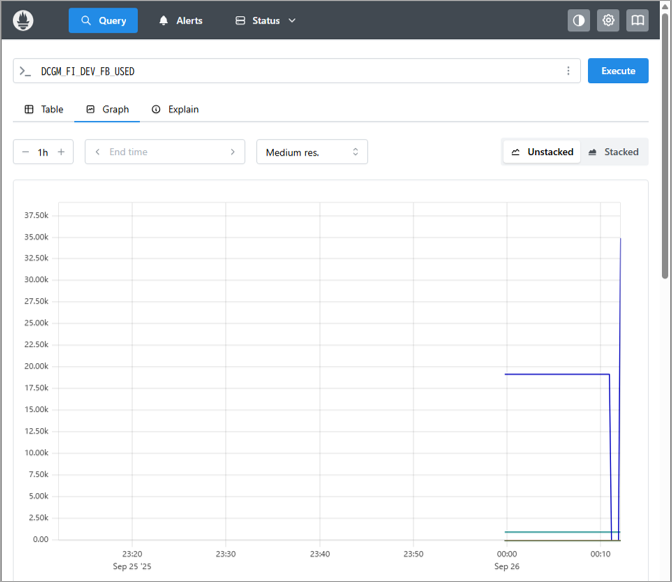
これにてPrometheusの準備は完了となります。
もちろんこれだけでも利用することは可能ではありますが、パラメータの指定が都度必要だったりするため、事前知識な部分があります。
また、PrometheusではタイムゾーンがUTCで固定となる点には注意です。
こういった課題に対してGrafanaを用いることで解消することができます。
Grafanaの展開
それでは最後にPrometheusで収集したデータをより簡単にグラフィカルに確認するために、Grafanaの展開を進めていきます。
展開方法としては、マシンに直接インストールさせる方式とコンテナとして展開する方法に分けられます。
この記事ではPrometheus同様にコンテナとして展開を行っていきます。
※他の展開方法に関してはGrafanaの公式ドキュメントをご参照ください。
https://grafana.com/docs/grafana/latest/setup-grafana/installation/
利用するコンテナイメージはDocker Hubに公式から公開されているため、そこから利用します。
https://hub.docker.com/r/grafana/grafana
まずPrometheus同様に、実行マシン上にGrafana用のフォルダを作成しておきます。
Grafanaは起動後Web UIからダッシュボードの作成などを行うことができ、そのデータを保管しておく必要があり、そのためのフォルダを作成します。
今回は以下のようなフォルダを準備しておきます。
- Grafana用フォルダ: /var/lib/grafana
コマンドとしては以下のように実行しておきます。
sudo mkdir /var/lib/grafana
ここで注意点としてGrafanaでもフォルダに対して権限の設定が必要となります。
Grafanaはgrafana(UID:472)というユーザーで動作し、書き込み等が行われるため以下コマンドで権限を設定しておきます。
sudo chown -R 472:472 /var/lib/grafana
それではコンテナの起動を行います。
起動コマンドのオプションに作成したフォルダを指定する形で以下コマンドを実行します。
なお、起動時に環境変数でGrafanaにログインするためのAdminユーザーのパスワードの設定が行えるため、合わせて指定しています。
docker run -d \
-p 3000:3000 \
-e GF_SECURITY_ADMIN_PASSWORD='<任意のパスワード>' \
-v /var/lib/grafana:/var/lib/grafana \
--name grafana \
grafana/grafana:12.2
そしてコンテナが起動したら、ブラウザからhttp://<モニタリング用マシンのIP>:3000にアクセスします。
ログイン画面が表示されますので、コンテナ起動時に指定したパスワードを用いてadminユーザーでログインします。
ログインが完了すると、GrafanaのWeb UIが表示されます。
このあとはこのWeb UI上にてPrometheusとの連携と可視化のダッシュボードの作成を行っていきます。
GrafanaへPrometheusを登録
続いてGrafanaにPrometheusの登録を行います。
Grafanaでは、Data sourceという項目でPrometheusに限らず様々な収集系ツールを登録することができます。
それらを登録したうえで、ダッシュボードを自由に作成していくようなツールとなります。
まず展開したPrometheusをData sourceに追加していきます。
GrafanaのUIにてData sourcesからAdd data sourceを選択します。
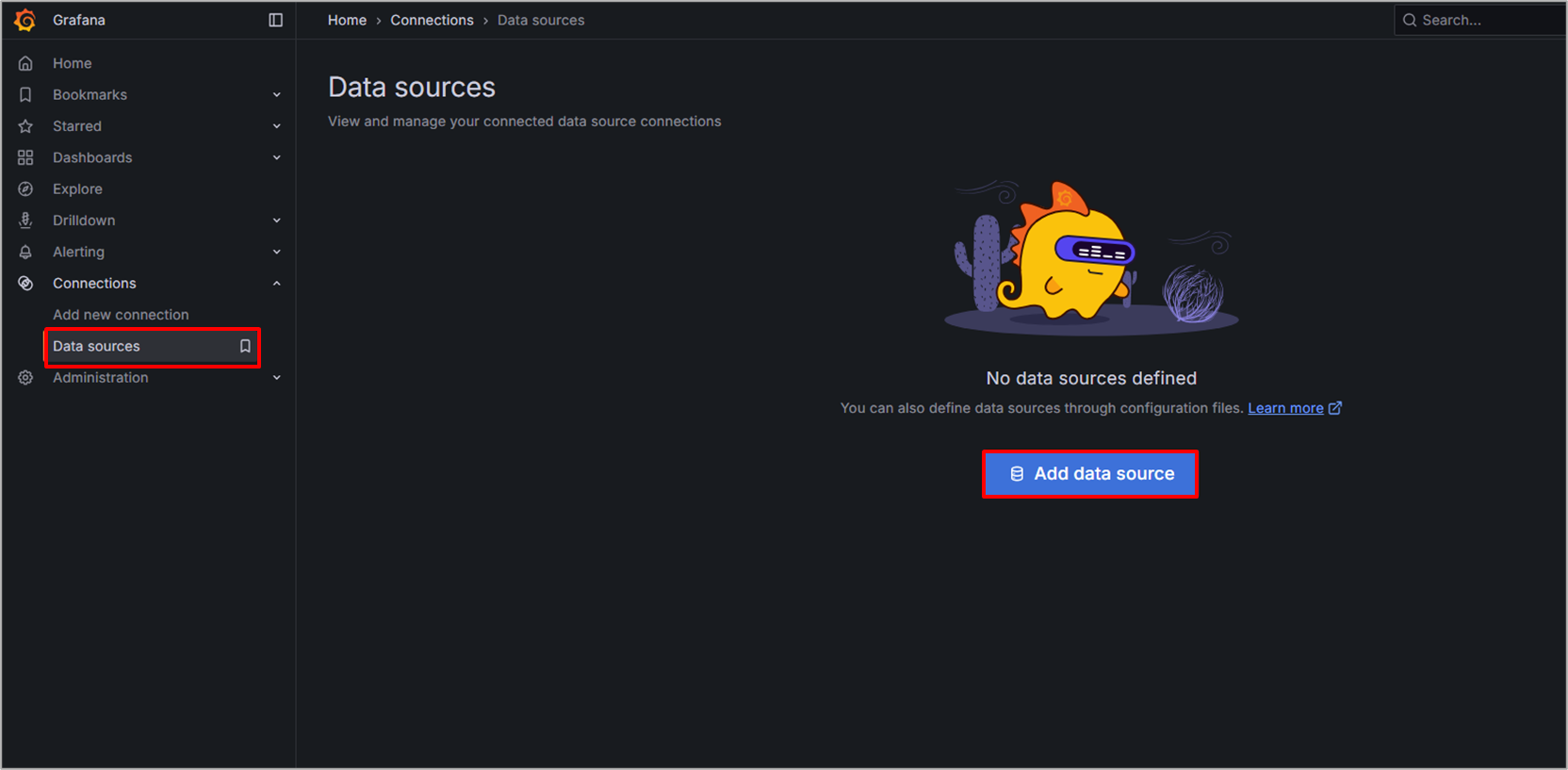
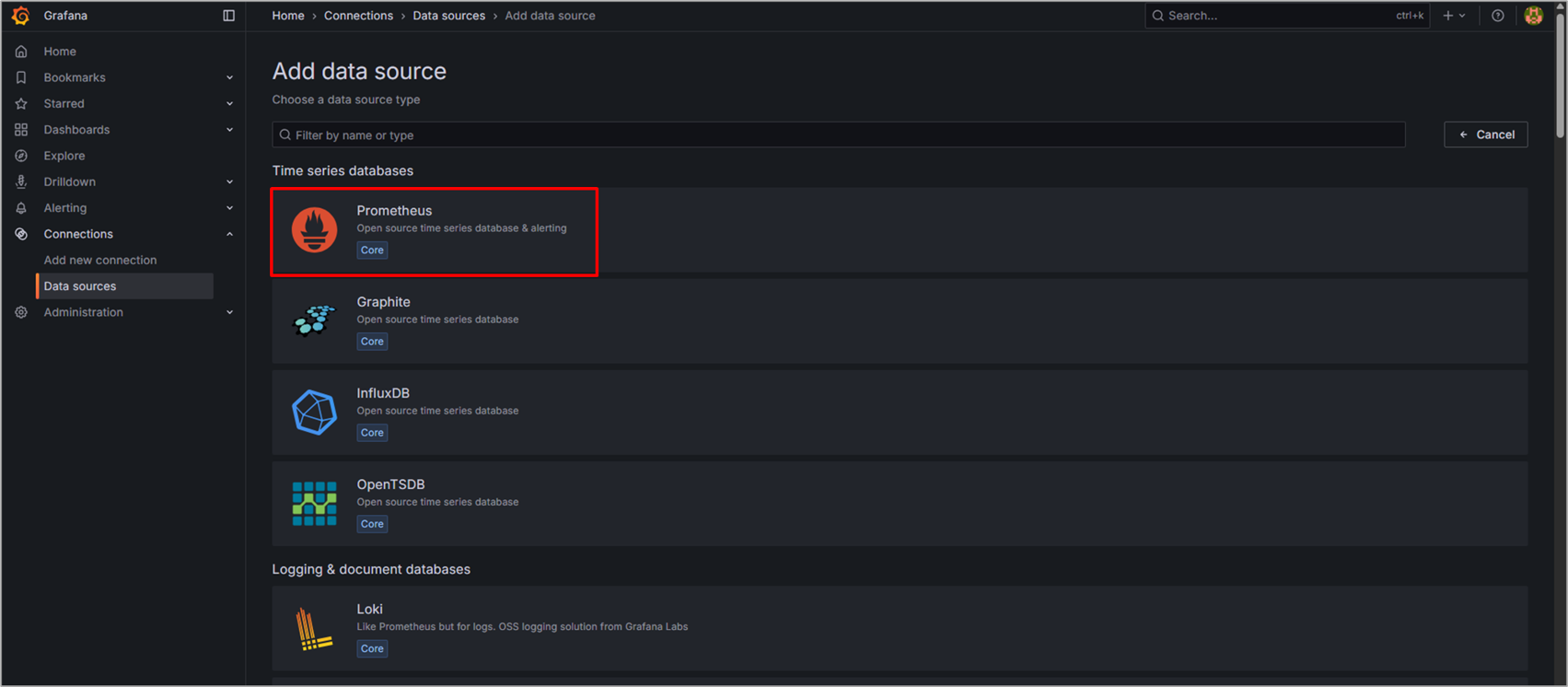
追加するData sourceを選択する画面が表示されます。
今回はPrometheusを選択します。
Prometheusのパラメータを設定する画面が表示されます。
Connectionの箇所にPrometheusのURL http://<モニタリング用マシンのIP>:9090を入力します。
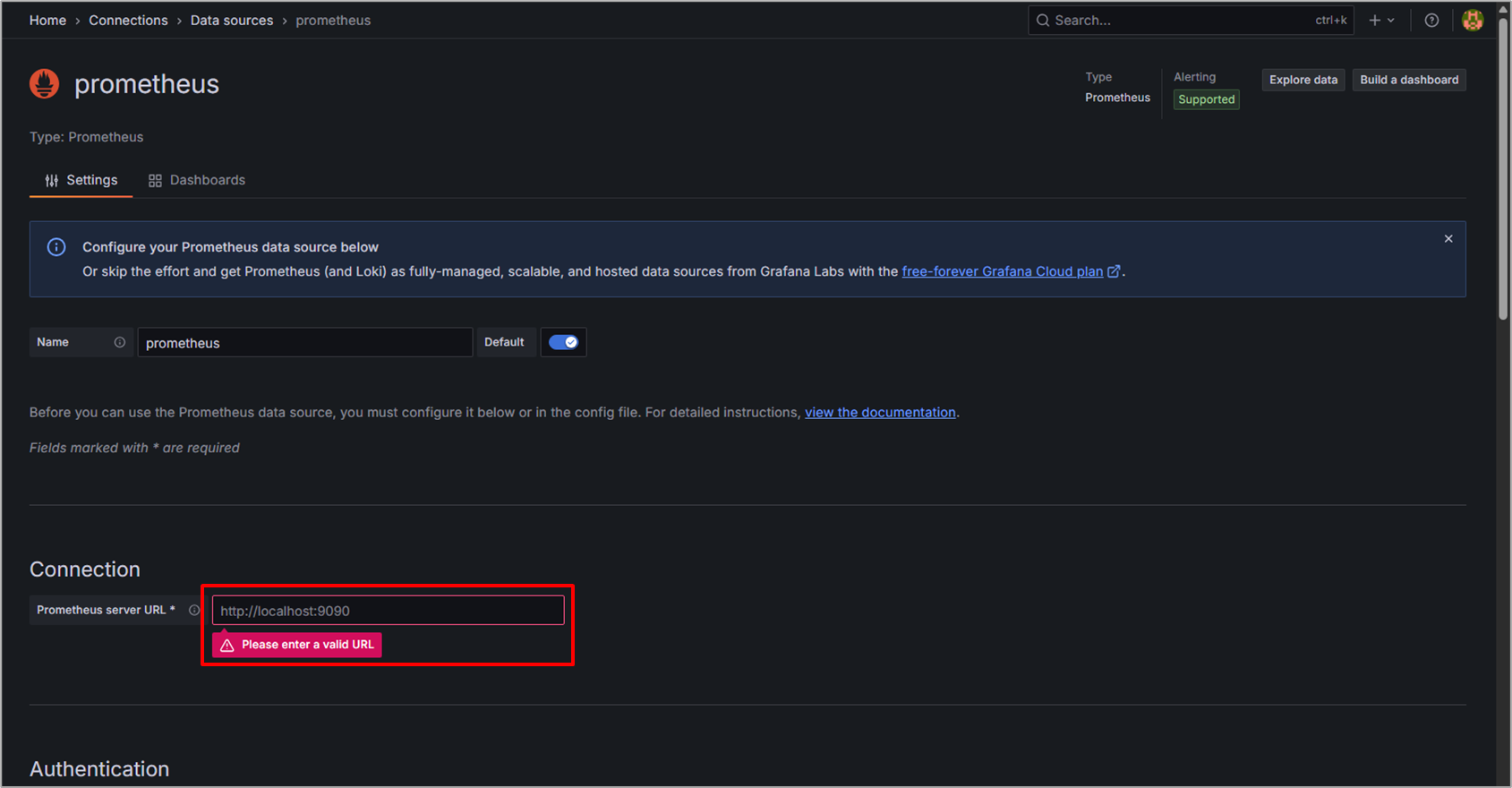
画面下部にスクロールして、Save&Testを選択し、Successfullyが表示されたら登録完了です。
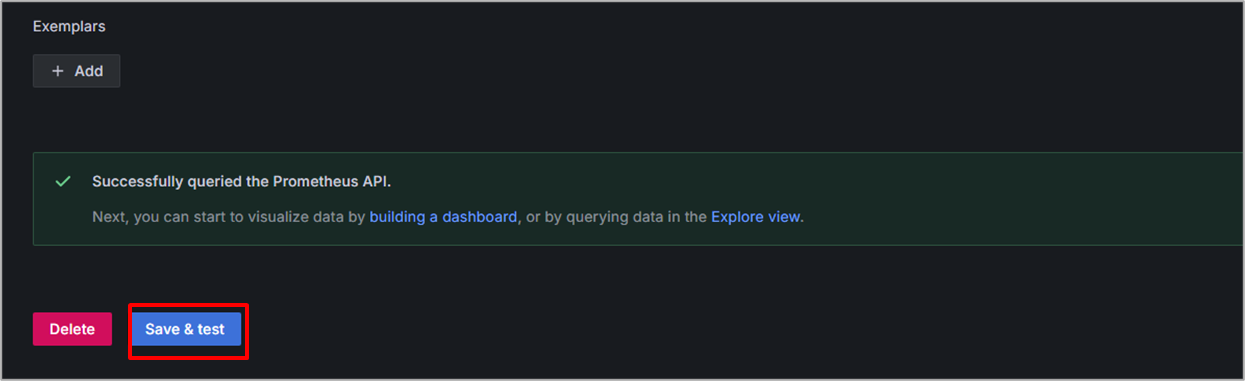
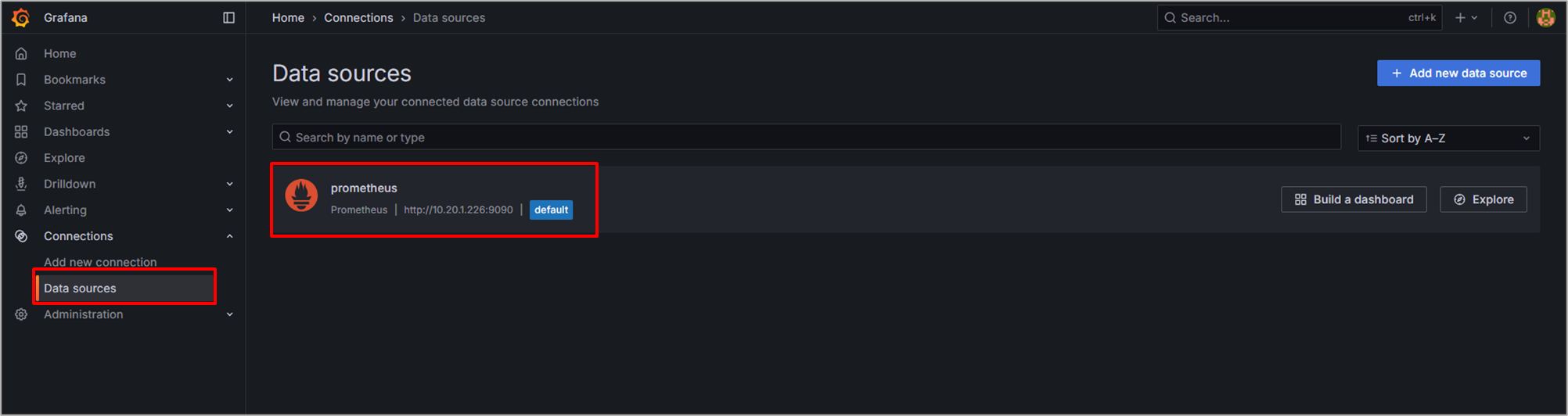
Data sourcesの画面に戻ると追加されていることが確認できます。
ダッシュボードの作成
それでは最後に登録したPrometheusのデータを表示させるためのダッシュボードを作成します。
Grafanaではダッシュボードを1から作成するパターンとテンプレートを用いて作成する方法があります。
今回はNVIDIAがDCGM Exporter向けに公開しているテンプレートがあるため、そちらを用います
https://grafana.com/grafana/dashboards/12239-nvidia-dcgm-exporter-dashboard/
GrafanaのWeb UIからDashboards内のImportを選択します。
インポート画面が表示されます。
インポート方法はいくつかありますが、今回はテンプレートごとのIDを登録する方法を利用します。
テンプレートのIDはGrafanaのサイトから確認することができ、今回のIDは12239となります
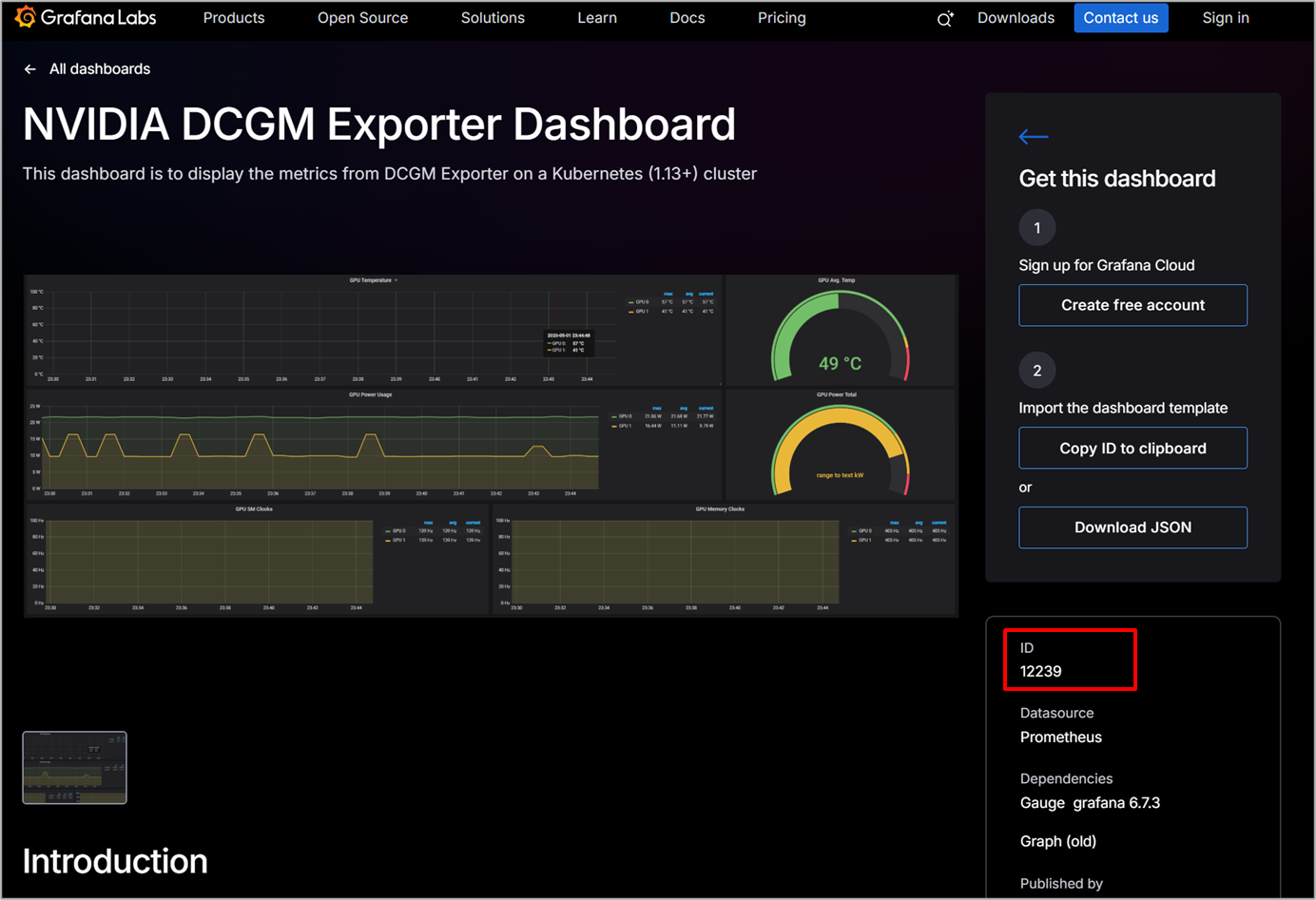
https://grafana.com/grafana/dashboards/12239-nvidia-dcgm-exporter-dashboard/
それではインポートの画面真ん中の入力欄にIDを入力して、Loadを選択します。
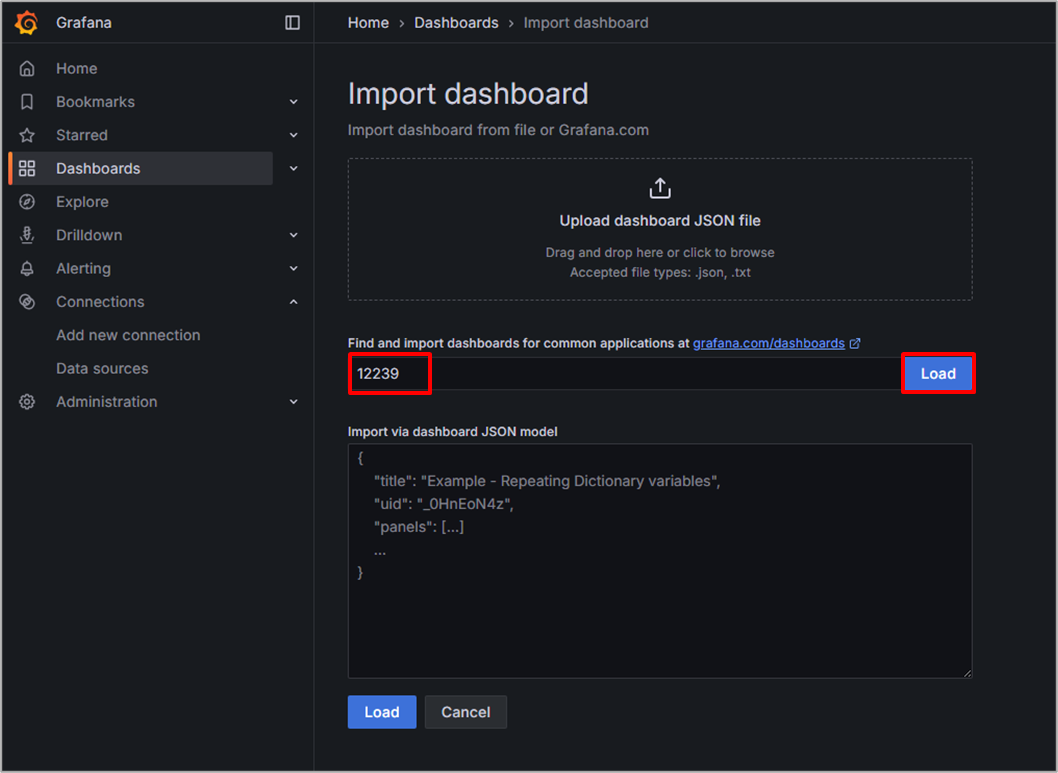
ダッシュボードの設定画面が表示されるため、Prometheusの欄を選択後、Importを選択します。
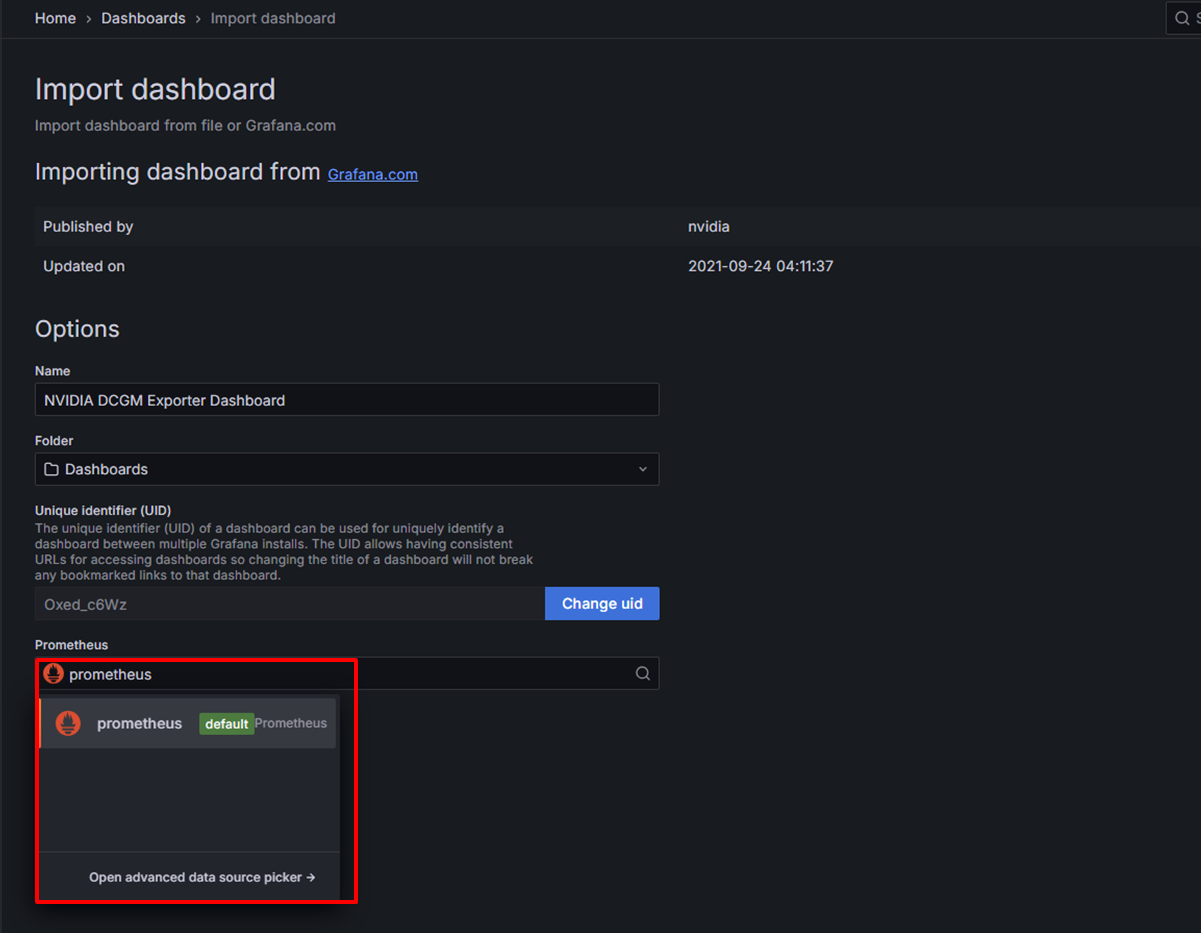
インポートが完了すると、ダッシュボードの作成が完了し、画面に表示されることが確認できます。
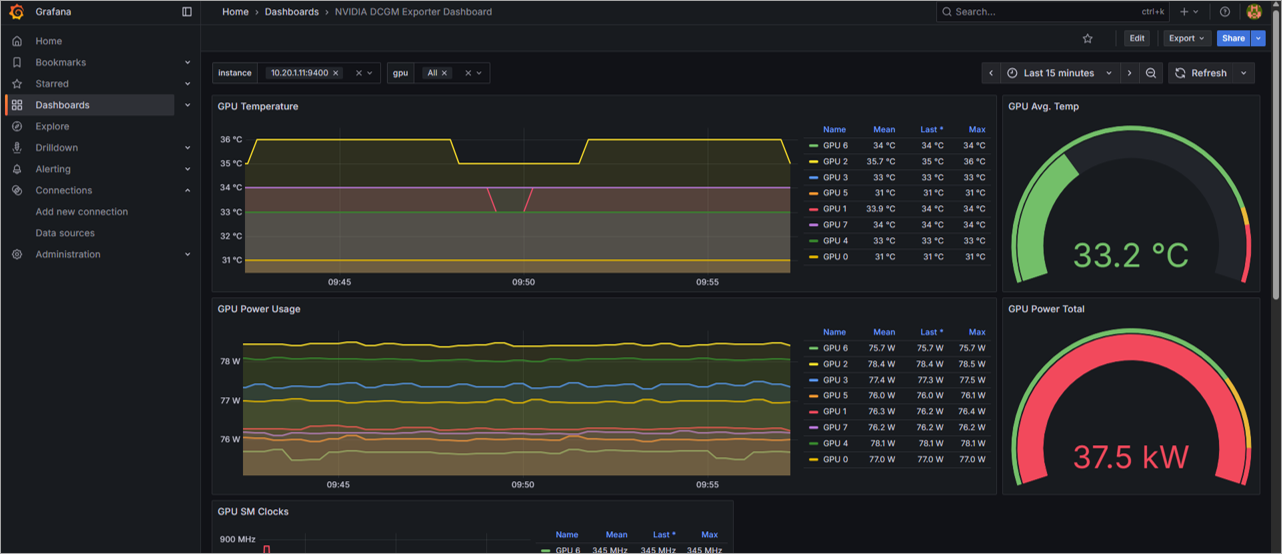
画面を確認すると時系列でGPUの温度やGPUのメモリ使用量など多くの情報を確認することができます。
また、今回PrometheusはGPUサーバー2台のDCGM Exporterを収集対象としています。
画面上部のInstanceから表示するGPUサーバーが選択でき、登録している2台から選べることが確認できます。
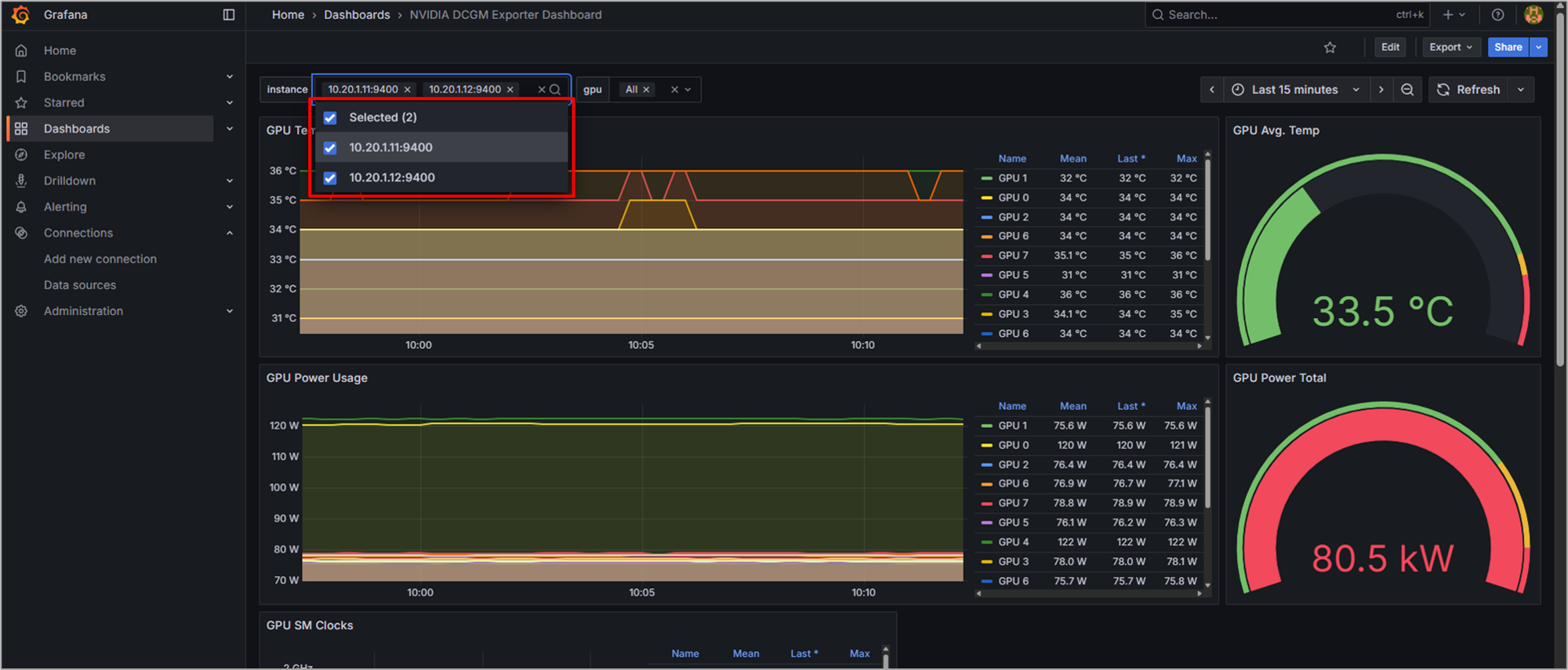
時系列のデータも確認すると、Prometheusのときとは異なり、日本時間で表示されていることも確認できます。これは、デフォルトではブラウザ側のタイムゾーンに合わせて表示時間が設定されるためです。
※ユーザーごとで自由にタイムゾーンを変更することも可能です。
以上で一連の作業は完了となります。
少し操作が多い部分もありましたが、難しい手順を踏まず、GrafanaでGPUの情報を表示できることが確認できました。
まとめ
今回はDCGM Exporterを用いたGPUの可視化について紹介しました。
生成AIの流行に伴い、学習だけでなく推論部分でも非常に多くのGPUが求められるようになった現在、このようにGPUを一括で可視化できるツールがあるととても助かる部分があると思います。
なお、今回は簡易手順としてテンプレートを用いたダッシュボード作成を行いましたが、自身の使いたいパラメータやデザインで作成することも可能なため、ぜひ色々活用いただけたらと思います。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
村上 正弥 - Seiya.Murakami -
VMware vExpert




