皆様こんにちは。SB C&Sの下山です。
今回はNVIDIA DGX Spark™並びにGB10上で実行する「FLUX.1 Dreambooth LoRA Fine-tuning」のPlaybookについての記事になります。この前編記事ではDreamBoothやLoRA、拡散モデル特有の用語についても解説を加えていきつつ、後編でPlaybookの手順を追い、画像生成の初学者にもわかりやすい記事構成を目指していきます。
本記事は下記のPlaybook、並びにインターネット上の公開情報をもとに作成しました。
FLUX.1 Dreambooth LoRA Fine-tuning | build.nvidia.com
本Playbookについて
このPlaybookでは、DreamBoothとLoRAの機能を使って、FLUX.1-dev 12Bモデルを複数の概念(マルチコンセプト)を対象にファインチューニングする方法を解説します。
手順では、ファインチューニング前のベースモデルと、ファインチューニング後のモデルにそれぞれ同じプロンプトを与え、生成される画像がどのように変化するかを確認します。
ファインチューニングの必要性や難しさについての深掘り
そもそもの前提として、生成モデルは一般に、事前学習で十分に扱われていない概念や特定の個体を、自然言語だけで安定して再現することを苦手としています。たとえば、「黒い犬」や「寝そべった猫」のように、既知の概念を組み合わせた生成は得意です。一方で、モデルが知らない人物の顔や、○○社のマスコットのような未学習の対象を生成させようとしても、うまくいかないことが少なくありません。加えて、モデルにとって未知の概念を自然言語だけで正確に定義・指定すること自体が難しいという問題もあります。(これらの点は、後編で触れる手順のステップ4とステップ7で生成された画像を比較するとより明らかです。)
そうすると、単に「その概念の画像を追加して単に追加学習を行えばよい」と考えたくなりますが、いくつかの問題が発生します。筆者が思いついたものを順に挙げると、まず、言語と概念の衝突が挙げられます。たとえば、Aという特定の人物の外見をモデルに学習させる場合、それを「人間」という大きなくくりの中で学習させてしまうと、モデル内の「人間」という概念が、追加学習したその人物の外見に引っ張られるおそれがあります。すると、「Aさん」という固有の概念と、「人間」という一般的な概念が混同されてしまいます。その結果、本来は汎用的であるはずの「人間」という概念に「Aさん」の特徴が混ざり込み、モデル全体の汎用性が損なわれます。
次に、少数の画像をもとに学習した場合に生じる過学習の問題があります。たとえば、新たな人物や特定の個体の概念を数枚の画像から学習させると、ポーズ、背景、構図、服装といった本来は切り分けるべき要素まで一緒に学習してしまい、既存の概念を歪めるおそれがあります。とくに複数の概念を学習させるマルチコンセプトの場合には、「Aさんの外見はよく再現できる一方で、ほかの人物を生成した際にもAさんの要素がどことなく混ざってしまう」あるいは「個体の外見は学習できたものの、背景や構図まで固定化してしまう」といったケースが起こり得ます。
まとめると、新規要素の追加学習自体は可能であるものの、通常の方法で行うとモデル内の既存概念に影響を及ぼしやすい、そして、複数の概念間で混同が生じ得る、ということになります。
DreamBoothとLoRAについて
そして、タイトルにもあるDreamBoothとLoRAについても簡単に振り返っておきましょう。それぞれをよくご存じの方はこのセクションを読み飛ばしていただいても結構です。
DreamBoothとは
通常のモデルは、「犬」「猫」「人」「車」などの一般概念を十分に認識できます。しかし、「特定の犬」「特定の人物」「特定のキャラクター」といった固有の対象を、学習元の素材とは大きく異なるシチュエーションで再現することは、一般に不得意です。一方、DreamBoothは複数のテクニックを活用することで、少数の画像から特定の被写体に関する概念をモデルに学習させ、高い再現性を実現できます。
・テクニックその1
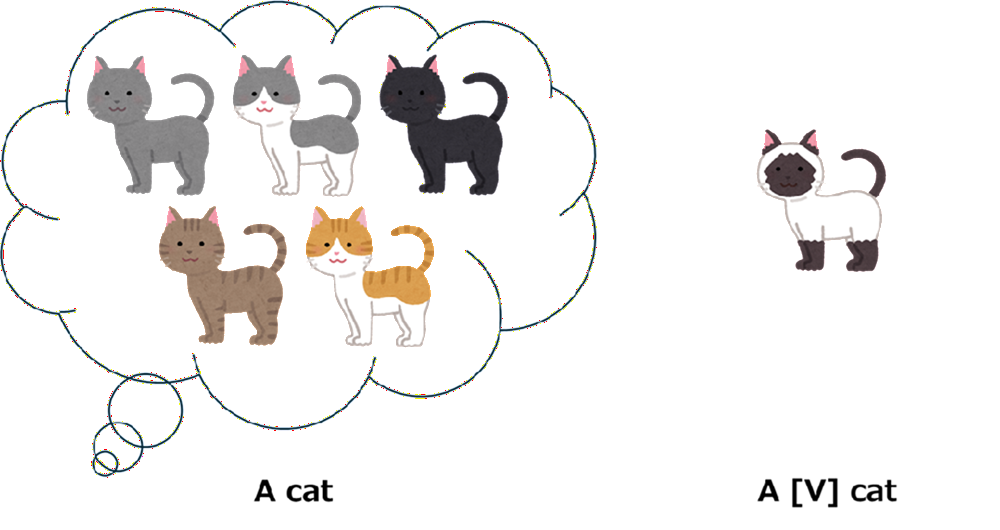
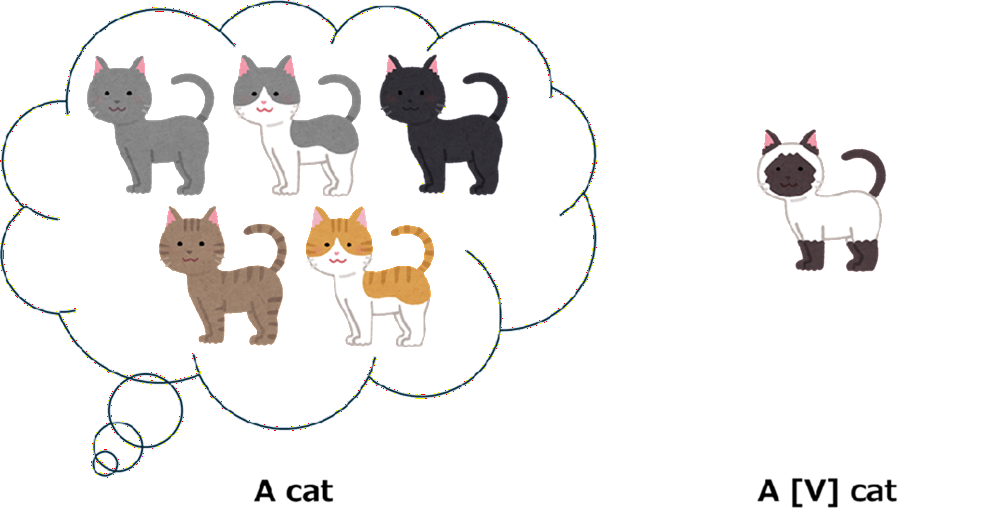
「固有の識別子を被写体に結び付ける」
例として、特定の猫を学習させる場合、単に"cat"として学習させるのではなく"[V] cat"のような形で「ユニークな識別子 + クラス名」を用います。これにより、モデルは「cat=一般的な猫」と「[V] cat=あの特定の猫」を区別することが容易になります。
・テクニックその2
「モデルの事前知識を壊しすぎないようにする仕組み」
少数の画像から特定の犬の個体を学習させる場合、学習元の画像に含まれる「背景」「ライティング」「犬の毛色」までを、"犬"という一般概念の一部として誤って学習してしまう恐れがあります。
そのためDreamBoothでは、class-specific prior preservation lossによって一般的な"犬"というクラスの性質も保つように学習させ、「特定の犬の個体らしさ」と「犬というカテゴリに共通する一般的な性質」の両立を目指します。
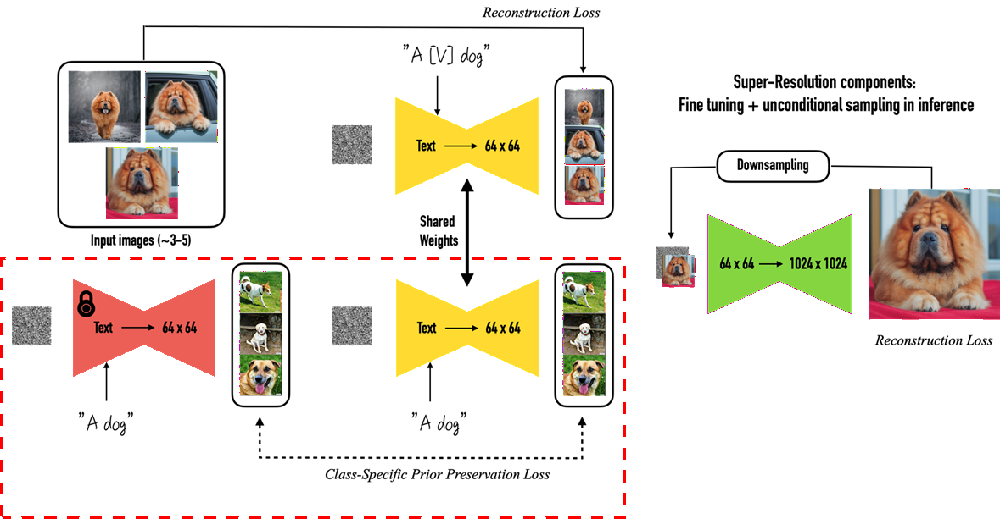
一方、学習した個体を高い精度で再現できる反面、論文で提案されたようなDreamBoothの初期の実装案では、モデル全体を微調整するため学習負荷が増大しやすいという欠点もあります。もっとも、実務ではLoRAなどと組み合わせて更新対象を限定し、軽量化する構成も一般的です。
LoRA(Low-Rank Adaptation:低ランク適応)とは
LoRAは、PEFT(Parameter-Efficient Fine-Tuning)と呼ばれるごく一部の追加パラメータのみを訓練することで、少ない計算リソースと時間でモデルを特定のタスクに適応させる手法の一種です。計算負荷を抑えながらも、モデルへ特定のキャラクターや画風、表現を追加学習させるのに適しています。フルファインチューニングと比べて調整対象となるパラメータ数が大幅に少ないため、必要なGPUメモリも比較的少なく済みます。
さらに、学習によって生成されるLoRAの重みファイルはベースモデル本体より大幅に軽量で、構成によっては数十MB〜数百MB程度に収まることが多く、保存や共有、管理がしやすい点も大きな特徴です。LoRAの重みには、ベースモデルに対する追加学習結果が含まれており、推論時にベースモデルへ適用することで、特定のキャラクター性やスタイルを反映した画像生成が可能になります。
DreamBooth LoRAとは
要するに、特定の被写体を高い再現性で学習するDreamBoothの考え方と、計算負荷を抑えながら追加学習を行えるLoRAを組み合わせたものであり、「DreamBooth型の対象学習をLoRAベースで軽量に実行する方法」と整理できます。
まとめ
本前編では、Playbookに登場する用語や技術の概要を解説しました。後編では、Playbookの手順を追いながら、実際にどのような画像が生成されるのかを順を追って確認していきます。
それではまた、後編でお会いしましょう。
次章の記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。