

こんにちは。SB C&S の野木です。
本記事ではNVIDIA Multi-Instance GPUについて紹介します。
1. GPUリソースの分散手法
現在、GPUはゲーミングやクリエイティブ用途といった個人利用に加え、データセンター環境における企業向けGPUサーバーでも広く利用されています。GPUサーバーでは、GPUを複数のユーザーやワークロードで共有して利用するケースもあります。
ただし、1ユーザーや1ワークロードがGPUリソースを想定より多く利用した場合、他のユーザーやワークロードではGPUリソースを十分に活用できず、結果としてリソース不足への対応としてスケーリングなどの検討によりコストの増加につながる可能性があります。
特にAIや機械学習の分野では、推論や小規模なジョブが多数実行されるケースも多く、GPUリソースの効率的な分割・共有が重要です。
このような課題を解決するために、GPUリソースを分割・共有し、複数のワークロードで効率的に利用できる技術が求められています。
GPUリソースを複数のユーザーやワークロードで効率よく利用するために、NVIDIAはいくつかのGPUリソースの分割・共有手法を提供しています。
代表的なGPUリソースの分割・共有手法として、以下のようなものがあります。
・CUDA Multi-Process Service(MPS)
GPUコンテキストを共有することで、複数のプロセスによりCUDA®処理を同時に実行できるソフトウェアベースのGPU共有手法
・NVIDIA® Virtual GPU (vGPU)
物理GPUを仮想GPUとして複数の仮想マシンに割り当てることができる仮想化環境でのGPU共有手法
・Multi-Instance GPU(MIG)
1つの物理GPUを複数に分割し、それぞれを独立したGPUとして利用できるハードウェアレベルのGPU分割手法
本記事では、これらの技術の中でもハードウェアレベルでGPUを分割できるMIGに焦点を当てて紹介します。
2. MIGとは
MIGは、単一のGPUをハードウェアレベルで独立した複数のGPUに分割する機能です。
GPUの分割できる最大数は製品によって異なりますが、例えばNVIDIA Ampere世代のA100やNVIDIA Hopper™世代のH100であれば最大7つに分割可能で、NVIDIA Blackwell世代のNVIDIA RTX PRO™ 6000 Blackwell Server Edition(以下 BSE)であれば最大4つに分割可能です。
なお、BSEはRTXシリーズとして初めてMIGに対応した製品であり、従来はA100/H100などのデータセンター向けGPUに限定されていたGPU分割機能を、RTXシリーズでも利用可能にした画期的な製品です。
※以下はBSEにおけるMIGで4つに分割した際のイメージ図です。
ここからは、GPU内部を構成する3つの要素と、MIGを構成する2つの要素を紹介します。
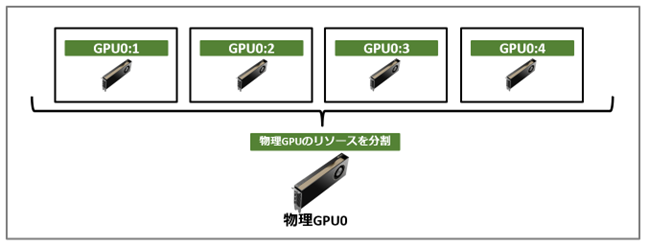
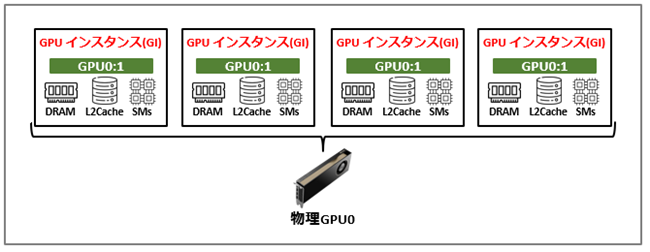
2.1 GPUインスタンス(GPU Instance、以下GI)
物理GPUをハードウェアレベルで分割した単位を指します。
専用のDRAM/SM/L2 Cacheを持ち、各インスタンスが独立したGPUとして動作します。
DRAM(Dynamic Random Access Memory)
・GPUメモリとして使用される主記憶領域
・モデルデータや計算用テンソルなどのデータを保存する際に利用
SM(Streaming Multiprocessor)
・GPU内部で並列計算を実行する演算ユニット
・CPUにおけるコアに近い役割
L2 Cache
・DRAMとSMの間に配置されるキャッシュ領域
・データアクセスを高速化するためのGPU共通キャッシュメモリの役割
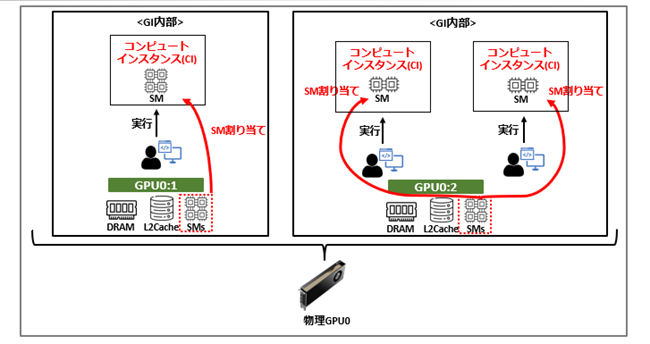
2.2 コンピュートインスタンス(Compute Instance、以下CI)
GI内部に作成される計算実行単位を指します。GI内のSMを割り当てて構成されており、アプリケーションのGPU計算処理はこのCI単位で実行されます。
また、以下図の右側のとおりGI毎に複数のCIを作成することも可能で、このCIはワークロード毎に並列実行が可能となっています。
3. MIGプロファイルの構成
GIやCIの分割は、MIGプロファイルと呼ばれる設定を指定することで構成できます。
MIGプロファイルでは、GPUメモリ容量やGPUスライス数などのリソースの割り当て方法を指定することができます。
GPUスライス数とは、GPU内部の計算リソース(SMなど)を一定の単位で分割したリソースを表します。
それでは、BSEを例にMIGプロファイルの構成例を確認していきます。
BSEは96GBのGPUメモリを搭載しており、最大4つのGIに分割できるGPUです。
GPUのモデルによって利用可能なMIGプロファイルは異なるため、BSE以外のGPUのプロファイルについては、以下のNVIDIA公式ドキュメントをご参照ください。
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/supported-mig-profiles.html
<例1>
96GBのGPUを4つに分割した構成例を以下に示します。
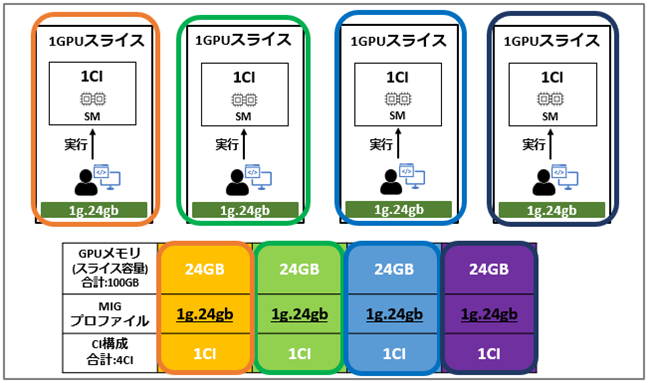
この例では、1つのGIに1GPUスライスが割り当てられています。
MIGプロファイルのそれぞれの意味は以下です。
・g:GPUをスライス単位で分割したリソースの割り当て単位
・gb:割り当てられるGPUメモリ容量
例1の場合、GPUを4つのGIに分割し、それぞれに1GPUスライスと24GBのメモリが割り当てられる構成となります。この構成は、小規模ワークロードなど24GBのメモリ構成でも動作するワークロードを複数並列で実行したい場合に適した構成です。
<例2>
96GBのGPUを2つに分割した構成例を以下に示します。
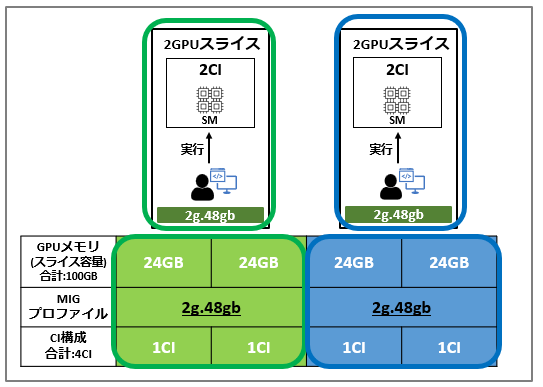
この例では、1つのGIに2GPUスライスと48GBメモリが割り当てられています。
また、CIを分割しないため、GI内のSMはすべて専有できる構成となります。
例2は、24GBの構成ではリソース不足となるワークロードなどを実行する場合に適した構成です。
<例3>
96GBのGPUメモリを2つに分割し、それぞれのGIで2つのCIを割り当てる構成例を以下に示します。
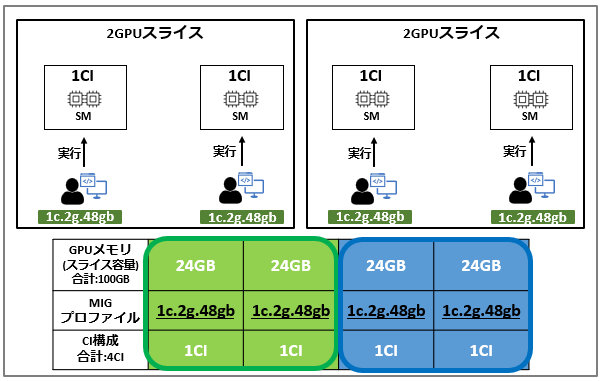
この例では、1つのGI内でSMを複数分割する構成となります。
これにより、GI内で複数のワークロードを分散して実行することができます。
なお、同一GI内にあるCIはGPUメモリを共有して利用します。
そのため、ワークロードを完全に分離したい場合はGI自体を分けて構成することを推奨します。
また、MIGプロファイルでは、1c、2c のように指定することで、GI内のCI数を設定することが可能です。
留意点としてCIの最大数はGPUスライス数と同じ数までしか作成できません。
例えば、
・2gプロファイルの場合:最大2CI
・4gプロファイルの場合:最大4CI
となり、GPUスライス数を超えるCIを作成することはできません。
※最小構成は1CIとなります。
ただし、例3のようなCIを分割する構成は、GIのみを分割する構成と比較すると利用されるケースは多くありません。
多くの環境では、例1や例2のようにGI単位でワークロードを分離する構成が採用されています。
一方で、1つのGI内で複数のプロセスやコンテナを独立した実行単位として動作させたい場合などに、CIの分割が利用される場合もあります。
4. MIGのユースケース
ここからは、実際にMIGを利用するユースケースを2つ紹介します。
ユースケース①:マルチテナント型のGPUサービス
GPUサーバーは、一般的なサーバーと比べて高価であり、設置環境にも一定の制約があります。
そのため、サービス事業者が自社でGPUサーバーを用意するのではなく、GPUサーバーを貸し出すクラウドサービス(GPU as a Service)からリソースを借りて運用するケースがあります。
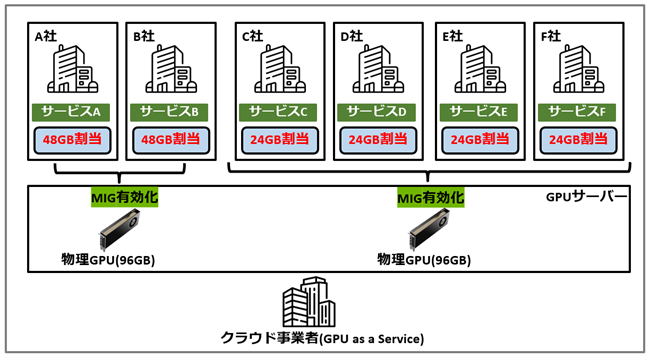
クラウド事業者は、自社のデータセンターに設置したGPUサーバーを各サービス事業者へ提供します。しかし、1GPU単位で1社に割り当てる場合、GPUサーバーの台数が増加する、あるいは利用者側でGPUリソースを使いきれないといった課題が発生することがあります。
そこでMIGを利用し、1つのGPUを複数のGIに分割して各サービス事業者へ割り当てることで、マルチテナント構成を実現することができます。
MIGを利用する利点として、クラウド事業者の視点では、データセンターのスペース効率を高めながら、GPUリソースの貸し出しメニューを柔軟に提供できるようになります。
また、GPUリソースがハードウェアレベルで分割されるため、顧客間のリソース干渉を避けた運用が可能です。
一方、サービス事業者の視点では、実行するワークロードの規模に応じてGIのサイズを選択できるため、GPUリソースを無駄なく利用でき、費用対効果の向上が期待できます。
ユースケース②:シングルテナント型の小規模ワークロード
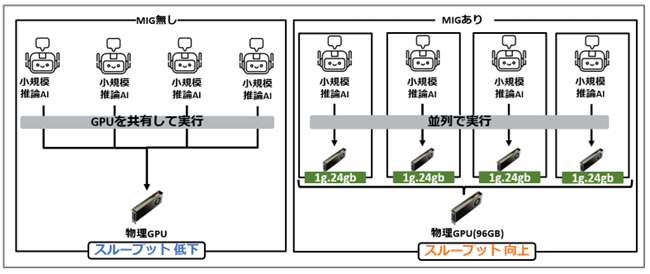
GPUサーバーを利用するシングルテナント環境において、社内または社外向けにAI推論サービスなどの比較的小規模なワークロードを運用する場合にも、MIGは有効な手段となります。
例えば、推論AIのような小規模ワークロードを1つの物理GPUでMIGを利用せずに実行する場合、複数のワークロードが1つのGPUリソースを共有する形となるため、同時に処理できるワークロード数が制限されることがあります。
一方で、このような環境でMIGを利用すると、1つの物理GPUを複数の独立したGIに分割することができます。
その結果、複数のワークロードを並列に実行できるようになり、スループットの向上が期待できます。
ただし、学習用途のAIワークロードのように多くのGPUリソースを必要とするジョブを実行する場合でMIGを利用する際は注意が必要です。
MIGを利用すると1つのGIに割り当てられるリソースが制限されるため、単一のジョブの処理性能が低下する可能性があります。
そういったケースではMIGを利用せずに1つの物理GPUを専有して利用したほうが、効率的に処理を行える場合もあります。
5. MIGとvGPUの違い
ここまでMIGの特性やユースケースについて紹介してきましたが、冒頭の説明の通りNVIDIAのGPU製品にはMIG以外にも複数のリソース分割・共有手法が存在します。
ここからは、その中でも比較対象に挙がりやすいNVIDIA vGPUとの違いについて説明します。
MIGとvGPUはどちらもGPUリソースを複数のユーザーやワークロードで利用するための技術ですが、優劣の関係ではなく用途に応じて使い分けられる技術です。
本記事では、MIGとvGPUの主な違いを以下の3つの観点から整理します。
・分割レイヤーの違い
・GPU処理方式の違い
・ライセンスの違い
それぞれの違いについて詳しく見ていきます。
分割レイヤーの違い
MIGは、GPU内部のハードウェアリソース(GPUメモリやSMなど)を分割し、1つのGPUを複数のGIとして利用できるようにする技術です。
一方、vGPUは仮想化環境においてハイパーバイザーを介してGPUリソースを仮想マシンに共有する技術です。
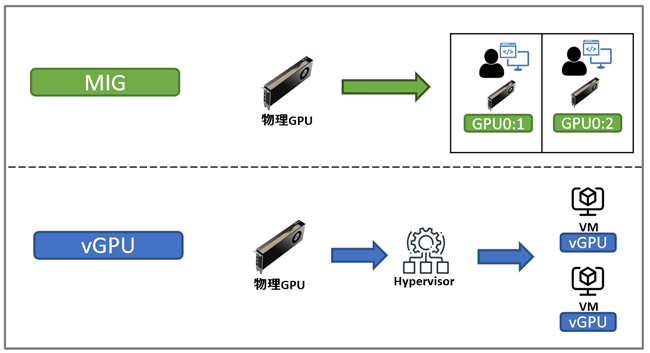
このように、MIGはGPU内部のハードウェアレベルでリソースを分割する技術であるのに対し、 vGPUは仮想化レイヤー(ハイパーバイザー)でGPUリソースを共有する技術という違いがあります。
GPU処理方式の違い
MIGはGPUを複数のGIに分割し、各ワークロードに専用のGPUリソース(GPUメモリやSMなど)を割り当てます。
そのため、複数のワークロードは互いに干渉することなく、独立した実行単位として並列に処理されます。
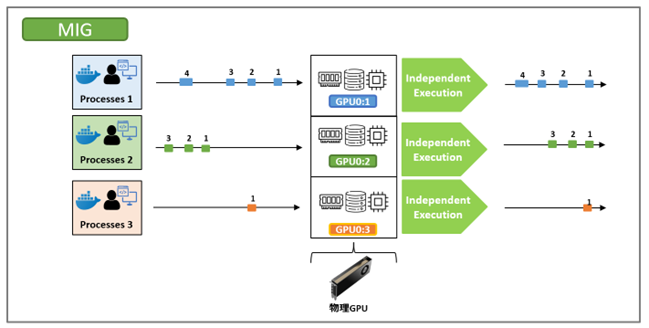
一方、 vGPUでは、複数の仮想マシンが1つの物理GPUをタイムスライスで共有して利用します。
タイムスライスとは、複数の仮想マシンのGPU処理を時間単位で分割し、高速に切り替えながら実行する方式です。
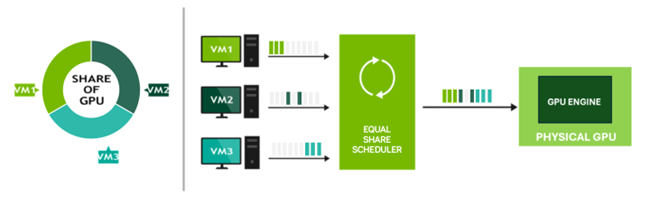
※出典:vGPU Features (Figure2 Best Effort Scheduler)
https://docs.nvidia.com/knowledge-base/latest/vgpu-features.html
NVIDIAのBest Effort Schedulingでは、ラウンドロビン方式によりGPUの計算処理の実行時間が各VMに順番に割り当てられる形で処理が行われます。
そのため、GPUの計算リソースは物理的に分割されているわけではなく、時間単位で共有される形になります。
このように、MIGはGPUリソースをハードウェアレベルで分割し、各ワークロードが独立して並列に処理されるのに対し、vGPUはGPUを時間単位で共有するタイムスライス方式で処理を行う点が大きな違いです。
ライセンスの違い
MIGはGPU内部のハードウェア機能として提供されているため、基本的に追加のライセンスを必要とせず利用できます。
ただし、MIGがサポートされているGPUはHopper世代以降(一部Ampere世代でもサポート)のため、MIGに対応したGPUであるかを事前に確認する必要があります。
一方、vGPUを利用する場合は、NVIDIA vGPUソフトウェアのライセンスが必要になります。
このライセンスは、GPUを仮想マシンで利用するための仮想GPU機能や、vGPUドライバ、管理機能などを利用するために必要となります。
なお、vGPUについてはMIGと比べてサポートされるGPUの世代が幅広く、Maxwell世代以降のGPUで利用可能である点も比較されるポイントです。
※本記事の投稿時点でMaxwell世代は2026年7月にvGPUソフトウェアメンテナンスが終了する発表がNVIDIAより公表されています。
https://docs.nvidia.com/vgpu/gpus-supported-by-vgpu.html
vGPUのライセンス方式については弊社の以下記事をご参照ください。
https://licensecounter.jp/engineer-voice/blog/articles/20230210_vgpu_5_license.html
以上、3つの観点からMIGとvGPUの違いについて比較してきました。
前述の通り、MIGとvGPUは分割するレイヤーが異なるため、互いに排他的な技術ではなく併用することも可能です。
例えば、MIGで分割したGIをvGPUとして仮想マシンへ割り当てることで、仮想環境でもハードウェアレベルでの分割技術を利用することができます。
6. まとめ
本記事では、NVIDIAのリソース分割手法のひとつである NVIDIA Multi-Instance GPU(MIG)の技術について紹介しました。
MIGはGPUのリソースをハードウェアレベルで分割し、各ワークロードへ専有リソースを割り当てる技術で、GPUリソースを効率的に活用する手段として有効な技術です。
第2回では、ベアメタル環境とコンテナ環境におけるMIGの設定方法を紹介します。
また第3回では、MIGとvGPUを組み合わせた技術についても紹介しますので、ぜひご覧ください。
他のNVIDIA関連記事はこちら
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
野木 空良 - Sora Nogi -
サーバー・ネットワークを中心として、AIインフラ全般のプリセールス業務に従事。




