皆様こんにちは。SB C&Sの下山です。
前編記事ではDreamBoothやLoRAのざっくりとした解説をさせていただきましたが、この後編ではNVIDIA DGX Spark™上でPlaybookの手順を実際に試し、ファインチューニングがモデルに与える影響を観察してみましょう。
本記事は下記のPlaybook、並びにインターネット上の公開情報をもとに作成しました。
FLUX.1 Dreambooth LoRA Fine-tuning | build.nvidia.com
Playbookの流れ
ステップ1.dockerコマンドの設定(省略)
ステップ2.リポジトリのクローン(省略)
ステップ3.モデルのダウンロード
ステップ4.ベースモデルでの推論(画像生成)
ステップ5.データセットの準備
ステップ6.トレーニング(ファインチューニング)
ステップ7.ファインチューニング済みモデルでの画像生成
ステップ3.モデルのダウンロード
このPlaybookで使用するFLUX.1-devを利用するためには、予めHugging Face上で規約に同意しておかなければなりません。またアクセストークンの生成が必要なため、アカウントをお持ちでない場合はこの機会に作成してください。トークン取得の詳細に関しては公式ドキュメントに解説があります。
Read権限を含むトークンを取得した後、環境変数としてexportしましょう。"<YOUR_HF_TOKEN>"の箇所をご自身のトークンへ置き換え、コマンドを実行します。
export HF_TOKEN=<YOUR_HF_TOKEN>
cd dgx-spark-playbooks/nvidia/flux-finetuning/assets
sh download.sh
その後指定されたディレクトリへ移動し、シェルスクリプトを実行すると、FLUX.1-devモデルのダウンロードが開始されます。
ステップ4.ベースモデルでの推論(画像生成)
モデルにファインチューニングを施す前に、素の状態(ベースモデル)で画像を生成します。
# Build the inference docker image
docker build -f Dockerfile.inference -t flux-comfyui .
# Launch the ComfyUI container (ensure you are inside flux-finetuning/assets)
# You can ignore any import errors for `torchaudio`
sh launch_comfyui.sh
一つ目のコマンドで本Playbookの目的に即したdockerコンテナのイメージをビルドし、launch_comfyui.shで必要な設定とともにビルドしたイメージからコンテナを起動しています。シェルスクリプトの実行後はComfyUIのコンテナが起動するため、指示に従ってhttp://localhost:8188へアクセスします。
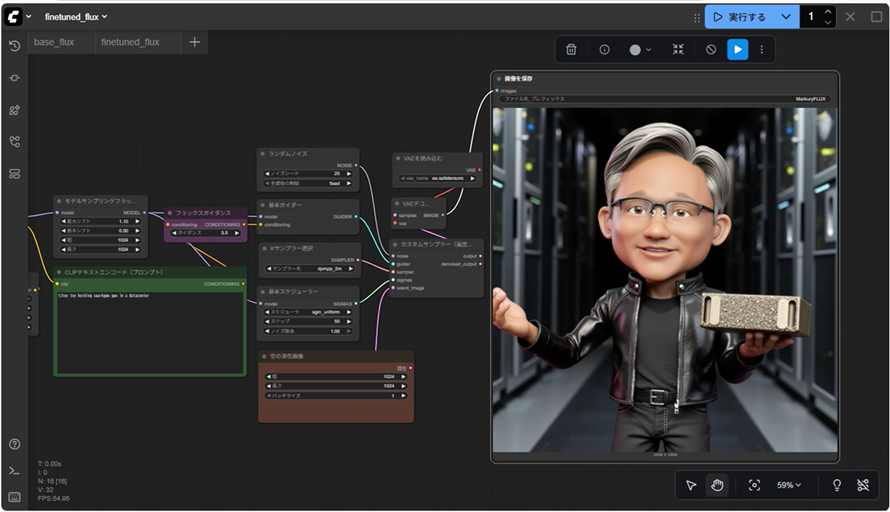
続いて、wキーを押下して表示されたワークフローセクションからbase_flux.jsonを選択しましょう。読み込まれたワークフローの中の「CLIP Text Encode (Prompt)」ブロックに「Toy Jensen holding a DGX Spark in a datacenter」と入力されていることを確認し、右上部分の「実行する」ボタンをクリックして画像の生成を開始します。(注:Toy Jensenとは、フィギュア調にデフォルメされたジェンスンフアン氏のイメージを指します。)
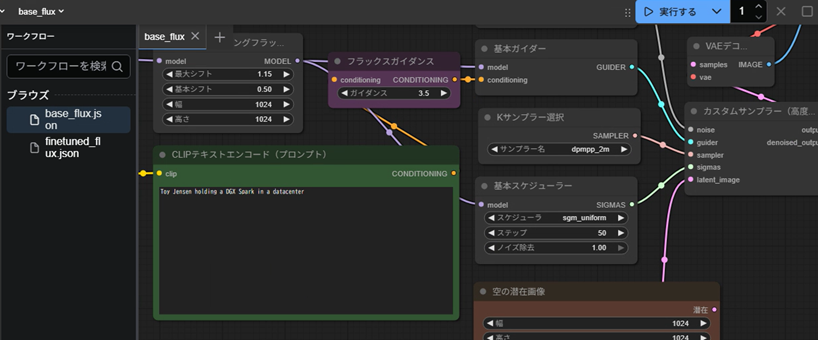
およそ3分前後で生成が完了し、画像が表示されました。
ベースモデルは"Toy Jensen"や"DGX Spark"の概念を学習していない為、生成結果の画像は入力したプロンプトから期待される結果には沿っていないことがお分かりいただけるかと思います。
ステップ5.データセットの準備
このステップでFLUX.1-devをトレーニングするためのデータセットを準備します。コンテナ内にはあらかじめいくつかのトレーニング用画像が用意されていますが、数枚の画像を追加してみるのもよいでしょう。データセットは「~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/flux_data」配下に保存されています。また、データセットは同ディレクトリ内のdata.tomlファイルの定義に従って取り扱われます。
data.tomlの内容
[general]
shuffle_caption = false
keep_tokens = 2
[[datasets]]
resolution = 1024
batch_size = 1
[[datasets.subsets]]
image_dir = "flux_data/tjtoy"
class_tokens = "tjtoy toy"
num_repeats = 1
is_reg = false
flip_aug = true
[[datasets.subsets]]
image_dir = "flux_data/sparkgpu"
class_tokens = "sparkgpu gpu"
num_repeats = 2
is_reg = false
flip_aug = true
このファイルの内容をかいつまんで説明すると、
・[[datasets.subsets]] image_dir = "flux_data/xxxxxx"
このフォルダ内に置かれている画像を学習に利用します。
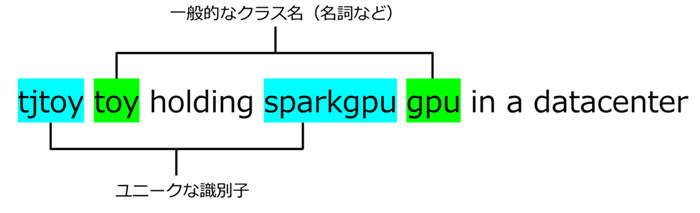
・[[datasets.subsets]] class_tokens = "[V] class_name"
このフォルダの画像群に対応するクラス語・識別子です。このdata.tomlのでは「tjtoyという固有識別子を持つtoy概念」や「sparkgpuという固有識別子を持つgpu概念」を学習させることを意図して記述されています。

ステップ6.トレーニング(ファインチューニング)
ステップ5で確認したデータセットをもとにファインチューニングを行います。
# Build the inference docker image
docker build -f Dockerfile.train -t flux-train .
# Trigger the training
sh launch_train.sh
Playbookには「90分ほど」と記載されていますが、写真を追加した筆者の環境で試行したところ、完了までに3時間強を要しました。いずれにせよ、このステップにはある程度まとまった時間を要するため、時間に余裕のあるときに実施するのがよさそうです。
完了後、チェックポイントファイルは~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/loras以下に保存されます。
ステップ7.ファインチューニング済みモデルでの画像生成
それではファインチューニングの結果を反映した画像生成を行って結果を確認しましょう。次のコマンドで再びComfyUIを起動します。
# Launch the ComfyUI container (ensure you are inside flux-finetuning/assets)
# You can ignore any import errors for `torchaudio`
sh launch_comfyui.sh
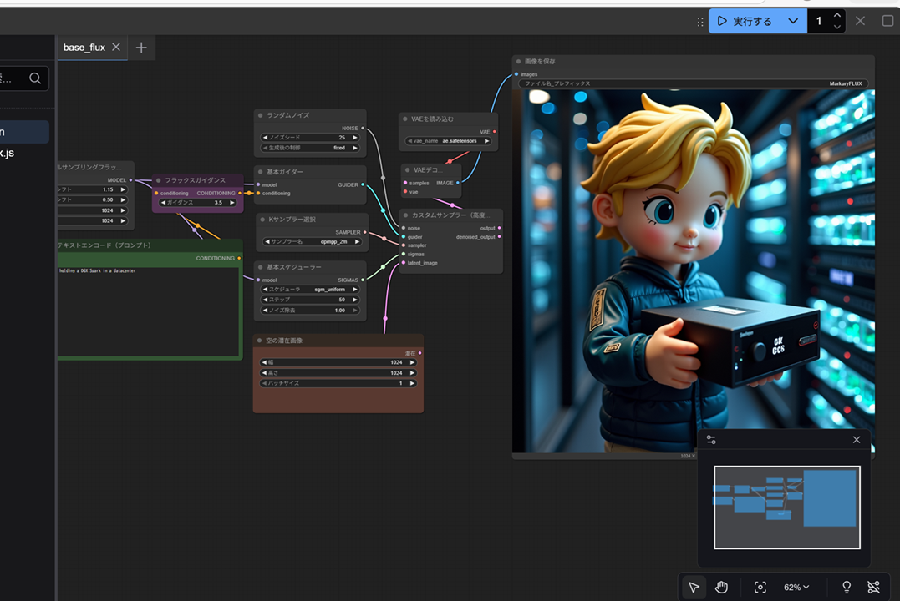
UIが表示された後、wキーを押下してワークフローセクションへアクセスし、今回はfinetuned_flux.jsonを使用します。「CLIP Text Encode (Prompt)」ブロックに「tjtoy toy holding sparkgpu gpu in a datacenter」と入力されていることを確認し、「実行する」ボタンをクリックしてください。3分弱の処理の後、処理結果の画像が確認できるはずです。
いかがでしょうか。
ステップ3でベースモデルに画像を生成させた場合と比べて、Toy JensenやDGX Sparkの再現度は大きく向上していることがおわかりいただけるかと思います。Toy JensenとDGX Sparkというそれぞれの概念を同時に学習させる、マルチコンセプトのファインチューニングがうまく機能している様子です。
また、ステップ3で使用したプロンプトと今回モデルに与えたプロンプトを比較すると、今回のプロンプトは文章としてはやや不自然であるものの、DreamBoothの様式に則った記法になっていることがわかります。
まとめ
この後編では、Playbookの手順を追いながら、ファインチューニングがモデルの出力に与える影響を実際にご覧いただきました。ファインチューニングは、モデルの表現力を用途に応じて拡張し、より意図に沿った生成結果を得るうえで有効な手法です。ベースモデルのみでは意図した画像の生成が難しい場合でも、ユーザーが目的に応じてモデルを拡張できる点は、大きな利点といえるでしょう。
発生する(かもしれない)エラーの例
・VAELoader Error while reading deserializeing header: header too large
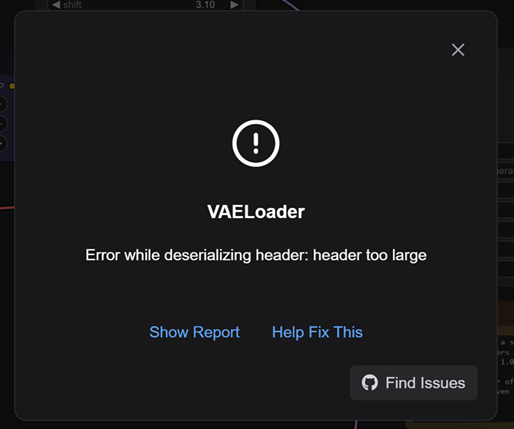
このエラーに遭遇した場合、ステップ3で実行した"download.sh"が意図したように完了していなかったため、ae.safetensorファイルが正しく取得されなかった可能性があります。この場合、ステップ3を再実行するか、次の手順でファイルの状況を確認してみましょう。
# モデルの配置先ディレクトリにae.safetensorファイルがあることを確認
ls -la ~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae
# ファイルが存在する場合、ファイルの冒頭を確認
head -c 100 ~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae/ae.safetensors
上記2つ目のコマンドでは、ファイルの冒頭100文字までの内容を確認しています。
OKの例:
spark@spark01:~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$ ls -lh
total 320M
-rw-rw-r-- 1 spark spark 320M Mar 6 16:00 ae.safetensors
spark@spark01:~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$
spark@spark01:~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$ head -c 100 ./ae.safetensors
0d{"__metadata__":{"modelspec.architecture":"Flux.1-AE","modelspec.title":"Flux.1 Autoencoder"spark@spark01:~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$
"0d{"__metadata__":{"modelspec~"のような文字列が出力された場合、モデルは正常にダウンロードされています。
NGの例:
spark@spark01~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$ head ./ae.safetensors
Please enable access to public gated repositories in your fine-grained token settings to view this repository.
spark@spark01: ~/dgx-spark-playbooks/nvidia/flux-finetuning/assets/models/vae$
この場合、指定したHugging Faceトークンに正しい権限が含まれていない為、リポジトリのモデルにアクセスできていません。再度トークンを生成し、ステップ3の最初から手順をやり直してください。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。