

皆様こんにちは。SB C&Sの下山です。
前編記事ではNVFP4の技術的な概要についてのお話をさせていただきました。本後編では実際にPlaybookの内容を試しながら、NVIDIA DGX Spark™上で既存のモデルをNVFP4精度へ量子化する流れを試していきます。
NVFP4 Quantization | build.nvidia.com
Playbookの流れ
ステップ1.dockerコマンドの設定(省略)
ステップ2.量子化後モデルの保存先ディレクトリの作成
ステップ3.Hugging Face認証用トークンの用意
ステップ4.TensorRT Model Optimizerコンテナの実行
ステップ5.量子化プロセスの観察(一部省略)
ステップ6.量子化後モデルが作成されていることの確認
ステップ7.量子化後モデルの読み込み
ステップ8.量子化後のモデルを読み込んだAPIサーバーの起動
ステップ9.環境のクリーンアップ(省略)
量子化手順の実践
ステップ2.量子化後モデルの保存先ディレクトリの作成
モデル保存のため、コンテナホスト上へバインドマウント先のディレクトリを作成します。
mkdir -p ./output_models
chmod 755 ./output_models
ステップ3.Hugging Face認証用トークンの用意
本操作を実行するには、事前にHugging Faceアカウントを作成し、Readタイプの認証用のトークンを取得しておく必要があります。この手順の詳細に関してはHugging Face公式ドキュメントのUser access tokensページでHow to manage User Access Tokens?セクションを参照してください。
上記の手順でReadトークンを取得した後、環境変数としてexportします。ダブルクオートを含めた"your_token_here"の箇所をご自身のトークンへ置き換え、コマンドを実行します。
# Export your Hugging Face token as an environment variable
# Get your token from: https://huggingface.co/settings/tokens
export HF_TOKEN="your_token_here"
NG例
ステップ4.TensorRT Model Optimizerコンテナの実行
ここでは、nvcr.ioからTensorLLMコンテナイメージを取得・起動し、コンテナ内部でModel Optimizerをセットアップしたうえで、モデルのNVFP4量子化を実行します。コンテナ内外のデータ連携には、バインドマウントしたディレクトリを利用します。
docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
-v "./output_models:/workspace/output_models" \
-v "$HOME/.cache/huggingface:/root/.cache/huggingface" \
-e HF_TOKEN=$HF_TOKEN \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c "
git clone -b 0.35.0 --single-branch https://github.com/NVIDIA/Model-Optimizer.git /app/TensorRT-Model-Optimizer && \
cd /app/TensorRT-Model-Optimizer && pip install -e '.[dev]' && \
export ROOT_SAVE_PATH='/workspace/output_models' && \
/app/TensorRT-Model-Optimizer/examples/llm_ptq/scripts/huggingface_example.sh \
--model 'deepseek-ai/DeepSeek-R1-Distill-Llama-8B' \
--quant nvfp4 \
--tp 1 \
--export_fmt hf
"
この一連のコマンドでは、
- TensorRT Model Optimizerコンテナに全GPUへのアクセス許可を与え、なおかつ最適化された共有メモリ設定で実行します。
- バインドマウントされたコンテナホスト上のディレクトリへ量子化後のモデルを出力し、モデルファイルを永続化します。
- モデルの再ダウンロードを回避するためにHugging Faceのキャッシュをマウントします。
- ソースからTensorRT Model Optimizerをクローンしインストールします。
- NVFP4を指定して量子化スクリプトを実行します。
ステップ5.量子化プロセスの観察
前項でTensorRT Model Optimizerコンテナを実行したことで、Hugging Faceからモデルがダウンロードされ、モデルの出力までが実行されます。
ステップ6.量子化後モデルが作成されていることの確認
./output_models/配下の内容を確認します。
# Check output directory contents
ls -la ./output_models/
# Verify model files are present
find ./output_models/ -name "*.bin" -o -name "*.safetensors" -o -name "config.json"
例
spark@spark01:~$ ls -la ./output_models/
total 12
drwxr-xr-x 3 spark spark 4096 Mar 18 18:00 .
drwxr-x--- 27 spark spark 4096 Mar 18 17:48 ..
drwxr-xr-x 2 root root 4096 Mar 18 18:09 saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf
spark@spark01:~$
spark@spark01:~$ find ./output_models/ -name "*.bin" -o -name "*.safetensors" -o -name "config.json"
./output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/model-00001-of-00002.safetensors
./output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/model-00002-of-00002.safetensors
./output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/config.json
spark@spark01:~$
model-0000X-of-0000X.safetensorsはモデル本体の重みを保持していて、出力例では2つに分割されている状態です。一方、config.jsonはモデルの構造を定義する様々な情報が書き込まれています。例えば、
- モデルのアーキテクチャ名
- 層数
- 実装クラス名
- 量子化アルゴリズム名
などが含まれます。
ステップ7.量子化後モデルの読み込み
export MODEL_PATH="./output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/"
docker run \
-e HF_TOKEN=$HF_TOKEN \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
-v "$MODEL_PATH:/workspace/model" \
--rm -it --ulimit memlock=-1 --ulimit stack=67108864 \
--gpus=all --ipc=host --network host \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c '
python examples/llm-api/quickstart_advanced.py \
--model_dir /workspace/model/ \
--prompt "Paris is great because" \
--max_tokens 64
'
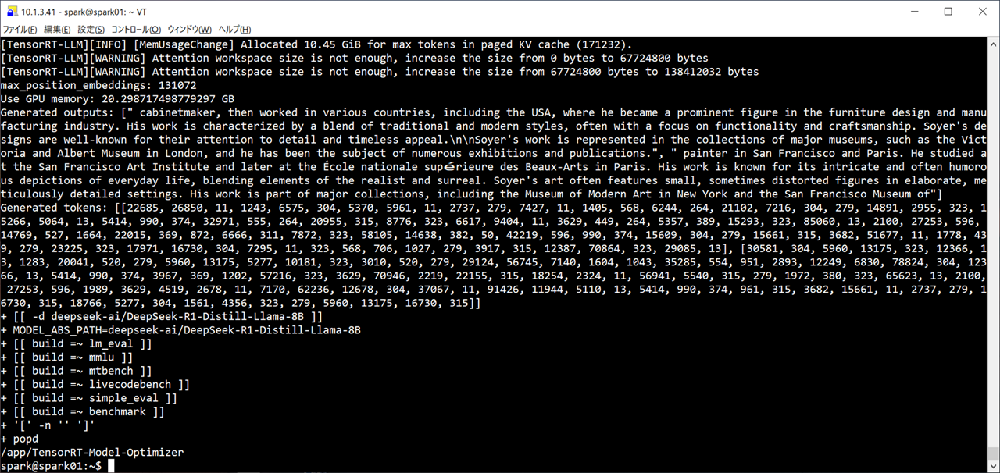
ここで実行しているquickstart_advanced.pyは、NVFP4量子化後のモデルを用いてプロンプト「Paris is great because(パリは素晴らしい。なぜならば)」に続く文を生成させています。結果は、
[TensorRT-LLM][INFO] [MemUsageChange] Allocated 11.53 GiB for max tokens in paged KV cache (188960).
[TensorRT-LLM][WARNING] Attention workspace size is not enough, increase the size from 0 bytes to 67724800 bytes
Processed requests: 0%| | 0/1 [00:00<?, ?it/s][TensorRT-LLM][WARNING] Attention workspace size is not enough, increase the size from 67724800 bytes to 138412032 bytes
Processed requests: 100%|█████████████████████████████████████████████████████████████████ Processed requests: 100%|█████████████████████████████████████████████████████████████████ ████████████████████████████████████| 1/1 [00:01<00:00, 1.65s/it]
[0] Prompt: 'Paris is great because', Generated text: " it's a city that's rich in history, culture, and art. It's also a hub for fashion and design. So, if you're planning a trip to Paris, you should definitely check out some of the city's famous landmarks, such as the Eiffel Tower, the Louvre, and the Arc"
spark@spark01:~$
と出力され、最終的には「Paris is great because it's a city that's rich in history, culture, and art. It's also a hub for fashion and design. So, if you're planning a trip to Paris, you should definitely check out some of the city's famous landmarks, such as the Eiffel Tower, the Louvre, and the Arc(パリは、歴史、文化、芸術に恵まれた素晴らしい都市です。また、ファッションやデザインの中心地でもあります。ですから、パリへの旅行を計画しているなら、エッフェル塔、ルーヴル美術館、凱旋門といった、この街の有名な名所をぜひ訪れてみてください。)」というテキストが生成されました。
NVFP4量子化後のモデルが正常に動作することを確認できたところで、モデル自体のサイズを比較してみましょう。
・今回題材として取り扱っているDeepSeek-R1-Distill-Llama-8B
root@4dd6fb13f0a5:/app/tensorrt_llm/TensorRT-LLM# ls -l /work/models/DeepSeek-R1-Distill-Llama-8B
total 15693080
-rw-r--r-- 1 root root 1064 Jan 7 09:26 LICENSE
-rw-r--r-- 1 root root 15994 Jan 7 09:26 README.md
-rw-r--r-- 1 root root 826 Jan 7 09:26 config.json
drwxr-xr-x 2 root root 4096 Jan 7 09:26 figures
-rw-r--r-- 1 root root 181 Jan 7 09:26 generation_config.json
-rw-r--r-- 1 root root 8667826246 Jan 7 09:26 model-00001-of-000002.safetensors
-rw-r--r-- 1 root root 7392730108 Jan 7 09:26 model-00002-of-000002.safetensors
-rw-r--r-- 1 root root 24240 Jan 7 09:26 model.safetensors.index.json
-rw-r--r-- 1 root root 9084480 Jan 7 09:26 tokenizer.json
-rw-r--r-- 1 root root 3071 Jan 7 09:26 tokenizer_config.json
・NVFP4量子化後のモデル
spark@spark01:~$ ls -l output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/
total 5903564
-rw-r--r-- 1 root root 2246 Jan 5 09:12 chat_template.jinja
-rw-r--r-- 1 root root 1680 Jan 5 09:12 config.json
-rw-r--r-- 1 root root 181 Jan 5 09:12 generation_config.json
-rw-r--r-- 1 root root 268 Jan 5 09:12 hf_quant_config.json
-rw-r--r-- 1 root root 4977188096 Jan 5 09:12 model-00001-of-00002.safetensors
-rw-r--r-- 1 root root 1050673280 Jan 5 09:12 model-00002-of-00002.safetensors
-rw-r--r-- 1 root root 88107 Jan 5 09:12 model.safetensors.index.json
-rw-r--r-- 1 root root 371 Jan 5 09:12 special_tokens_map.json
-rw-r--r-- 1 root root 50657 Jan 5 09:12 tokenizer_config.json
-rw-r--r-- 1 root root 17209530 Jan 5 09:12 tokenizer.json
spark@spark01:~$
このようにNVFP4量子化前のDeepSeek-R1-Distill-Llama-8Bでは、モデル自体のサイズが約15.6GB程度ありましたが、NVFP4量子化後は約6GBと大幅にコンパクトになっていることがお分かりいただけるかと思います。
ステップ8.量子化後のモデルを読み込んだAPIサーバーの起動
このステップでは、NVFP4量子化後のモデルを読み込んだAPIサーバーを用意し、そのサーバーにcurlリクエストを送信することで、モデルが問題なく動作するかを確認してみましょう。
# Set path to quantized model directory
export MODEL_PATH="./output_models/saved_models_DeepSeek-R1-Distill-Llama-8B_nvfp4_hf/"
docker run \
-e HF_TOKEN=$HF_TOKEN \
-v "$MODEL_PATH:/workspace/model" \
--rm -it --ulimit memlock=-1 --ulimit stack=67108864 \
--gpus=all --ipc=host --network host \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
trtllm-serve /workspace/model \
--backend pytorch \
--max_batch_size 4 \
--port 8000
docker runの実行後、「Application startup complete.」と出力されればAPIサーバーの起動は完了です。
[03/18/2026-09:53:04] [TRT-LLM] [I] Creating CUDA graph instances for 4 batch sizes.
[03/18/2026-09:53:04] [TRT-LLM] [I] Run generation only CUDA graph warmup for batch size=4, draft_len=0
[03/18/2026-09:53:04] [TRT-LLM] [I] Run generation only CUDA graph warmup for batch size=3, draft_len=0
[03/18/2026-09:53:05] [TRT-LLM] [I] Run generation only CUDA graph warmup for batch size=2, draft_len=0
[03/18/2026-09:53:05] [TRT-LLM] [I] Run generation only CUDA graph warmup for batch size=1, draft_len=0
[03/18/2026-09:53:05] [TRT-LLM] [I] Setting PyTorch memory fraction to 0.10752288304681674 (13.084484100341797 GiB)
/workspace/model
/workspace/model
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
それではhttp://localhost:8000へ向けてcurlリクエストを送信し、モデルの動作を確認します。
コンテナホストへ接続する新たなターミナルを立ち上げ、次のコマンドを送信します。
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [{"role": "user", "content": "What is artificial intelligence?"}],
"max_tokens": 100,
"temperature": 0.7,
"stream": false
}'
このリクエストでは、DeepSeekに対してAIとは何か?という質問を投げかけていますね。
リクエストが正常に処理された場合、APIサーバーを起動しているターミナル上には新たに"INFO: 127.0.0.1:XXXXX - "POST /v1/chat/completions HTTP/1.1" 200 OK"と出力され、curlリクエストを送信したターミナルには応答が返ってきます。
spark@spark01:~$ curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [{"role": "user", "content": "What is artificial intelligence?"}],
"max_tokens": 100,
"temperature": 0.7,
"stream": false
}'
{"id":"chatcmpl-11a7480100ef4121a27b94f00b03f371","object":"chat.completion","created":1773829085,"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B","choices":[{"index":0,"message":{"role":"assistant","content":"Okay, so I'm trying to understand what artificial intelligence is. I've heard the term before, especially with all the news about AI in technology and stuff. But I'm not entirely sure what it really means. Let me try to break it down.\n\nFirst, the term \"artificial intelligence\" sounds like it's about intelligence, but it's not the real kind, right? So, maybe it's something machines or computers do. I know that computers can do a lot of things, like","reasoning_content":null,"reasoning":null,"tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null,"mm_embedding_handle":null,"disaggregated_params":null,"avg_decoded_tokens_per_iter":1.0}],"usage":{"prompt_tokens":10,"total_tokens":110,"completion_tokens":100},"prompt_token_ids":null}spark@spark01:~$
内容の正誤はさておき、「Okay, so I'm trying to understand what artificial intelligence is. I've heard the term before~後略~」(さて、人工知能とは一体何なのか、理解しようとしています。この言葉は以前にも耳にしたことがあります。)と結果が返ってきました。モデルは問題なく動作し、APIリクエストに対する応答も正しく行われているようです。
まとめ
今回の検証では、NVIDIAが公開しているPlaybookに沿って、DGX Spark上で既存モデルをNVFP4精度へ量子化し、推論実行やAPIサーバーとしての動作確認までの手順を一通り試すことができました。量子化後はモデルサイズが大幅に小さくなり、扱いやすさの面でも大きな効果があることが分かります。
一方で、実際に試してみると、利用するコンテナイメージや関連コンポーネントのバージョン差異によって、想定どおりに進まない場面があることも確認できました。
NVFP4は、モデルの軽量化と実用性の両立を考えるうえで非常に興味深い選択肢です。本記事が、これからNVFP4量子化を試してみたい方や、GPU環境でのLLM活用を検討している方の参考になれば幸いです。
遭遇した問題に関するメモ
インターネット上を見る限り、私以外にも多くの方がこのPlaybookを試しており、その多くは問題なくテストできているようです。しかし、私が過去バージョンのイメージで本Playbookを試した際には、いくつかの問題に遭遇しました。そこで、その内容と対処方法を忘備録としてここに記しておきます。
・TensorRT Model Optimizer実行時に発生したエラー
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/app/TensorRT-Model-Optimizer/modelopt/torch/quantization/qtensor/nvfp4_tensor.py", line 84, in get_weights_scaling_factor per_block_scale = per_block_amax / (6.0 * weights_scaling_factor_2)
~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
エラー内容
「すべてのテンソルは同じデバイス上にあることが期待されるのに、少なくともcuda:0とCPUの2つのデバイスが見つかった」
TensorRT Model Optimizerでは、PTQ(Post-Training Quantization)を実行した後、その結果をexportする流れでモデルを処理します。ただし、元の重み(FP16やBF16など)を単純に4bitへ量子化すると精度が大きく劣化するため、量子化後の値を復元する際に用いるスケール(倍率)もあわせて生成する仕組みになっています。
このエラーが発生した際には、スケール生成時の計算に使用されるテンソルが複数のデバイスに分散していたため、処理を正常に完了できませんでした。具体的には、NVFP4量子化の実処理を担うTensorRT Model Optimizer内の/app/TensorRT-Model-Optimizer/modelopt/torch/quantization/qtensor/nvfp4_tensor.py84行目で定義されているNVFP4QTensor.get_weights_scaling_factor()において、per_block_scale = per_block_amax / (6.0 * weights_scaling_factor_2)という演算を実行しようとした際にエラーが発生しています。
原因
スケール生成に使用される、PTQ処理中に生成される一部の一時テンソルが、意図せずCPU上に作成されたままとなっていた(可能性があります)。その結果、モデルを保存用のHugging Face形式へと変換する最終的なexport処理において、本来同一デバイス上に存在すべきGPU上のテンソルとCPU上のテンソルが混在し、計算が成立せず処理が失敗しました。
対処
スケール生成の計算を行う直前に、CPU上に存在していたテンソルをGPUへ移動させる処理を追加しました。この対応は、NVFP4量子化の実処理を担うTensorRT Model Optimizer内の「/app/TensorRT-Model-Optimizer/modelopt/torch/quantization/qtensor/nvfp4_tensor.py」スクリプトを修正することで実現しています。詳しくは、NVFP4QTensor.get_weights_scaling_factor()内のコードを次のように変更しました。
変更前
per_block_scale = per_block_amax / (6.0 * weights_scaling_factor_2)
変更後
weights_scaling_factor_2 = weights_scaling_factor_2.to(per_block_amax.device)
per_block_scale = per_block_amax / (6.0 * weights_scaling_factor_2)
なお、同様の変更がTensorRT Model Optimizerのv0.39.0以降にも反映されていることを確認済みです。
・その他遭遇した不具合
- TensorRT-LLMとModel Optimizerのバージョン差異による依存関係の衝突
- NVIDIA Data Loading LibraryとPythonコアパッケージライブラリのバージョン差異による依存関係の衝突
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
下山 翔也 - Shoya Shimoyama -
NVIDIA社製品のプリセールス・エンジニア業務を担当。
GPUのほか、クラウドサービスやサーバー、ネットワーク機器についても取り扱う。




