こんにちは、山崎です。
UiPathの製品「UiPath Communications Mining」の基本的な使い方をハンズオン方式でご紹介するシリーズ記事をお届けしています。
この記事はその第7回目です。第1回目では基本的な概念について、第2回目では必要な環境準備について説明しました。また、第3回目ではAIモデルのトレーニング前のデータ準備やCommunications Miningへのセットの仕方を説明し、第4回目ではタクソノミーについて紹介しました。
第5回目では「発見」、第6回目では「探索」ページを利用してのモデルトレーニングを行いました。
今回の記事では「検証」ページで、モデルの改良を行います。
目次
1. 「検証」ページでのトレーニング
1-1. モデルのパフォーマンスを確認
1-2. パフォーマンスを更に向上させるために
1-2-1. ラベル
1-2-2. フィールド
1. 検証ページでのトレーニング
「検証」ページでは、モデルのパフォーマンスの状態を確認しながら、Communications Miningから推奨される作業を行うことによって、モデルの精度を高めていきます。
ここで定量的にモデルのパフォーマンスを可視化し、評価を行うことが、最終的にこのモデルを本番環境で使用することに問題がないかの意思決定にもかかわると思います。そういった意味でも非常に重要なフェーズです。
※UiPathアカデミーでは、「Refine: 改良と保守」フェーズとして紹介されていますので、より掘り下げたい方はこちらもチェックしてください。
UiPath Communications Mining モデル トレーナー
1-1. モデルのパフォーマンスを確認
それではモデルのパフォーマンスを確認する所から、開始していきましょう!
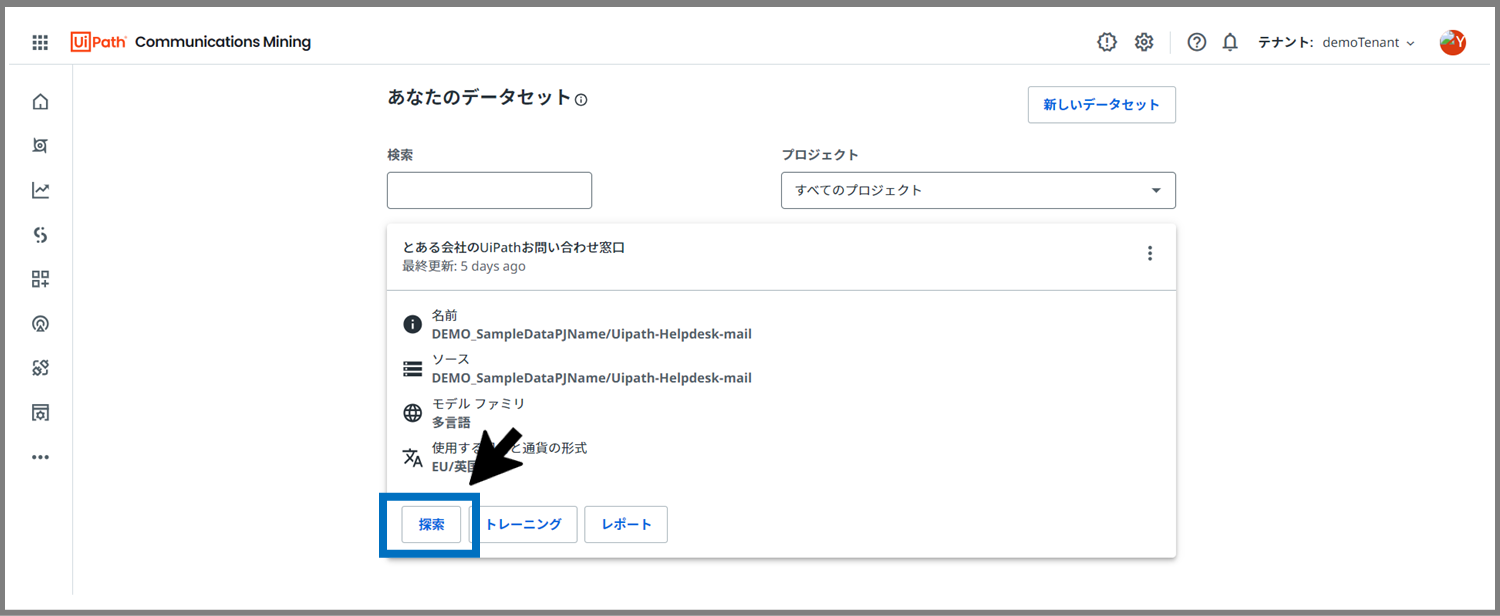
Communications Miningのトップページの「探索」ボタンをクリックします。
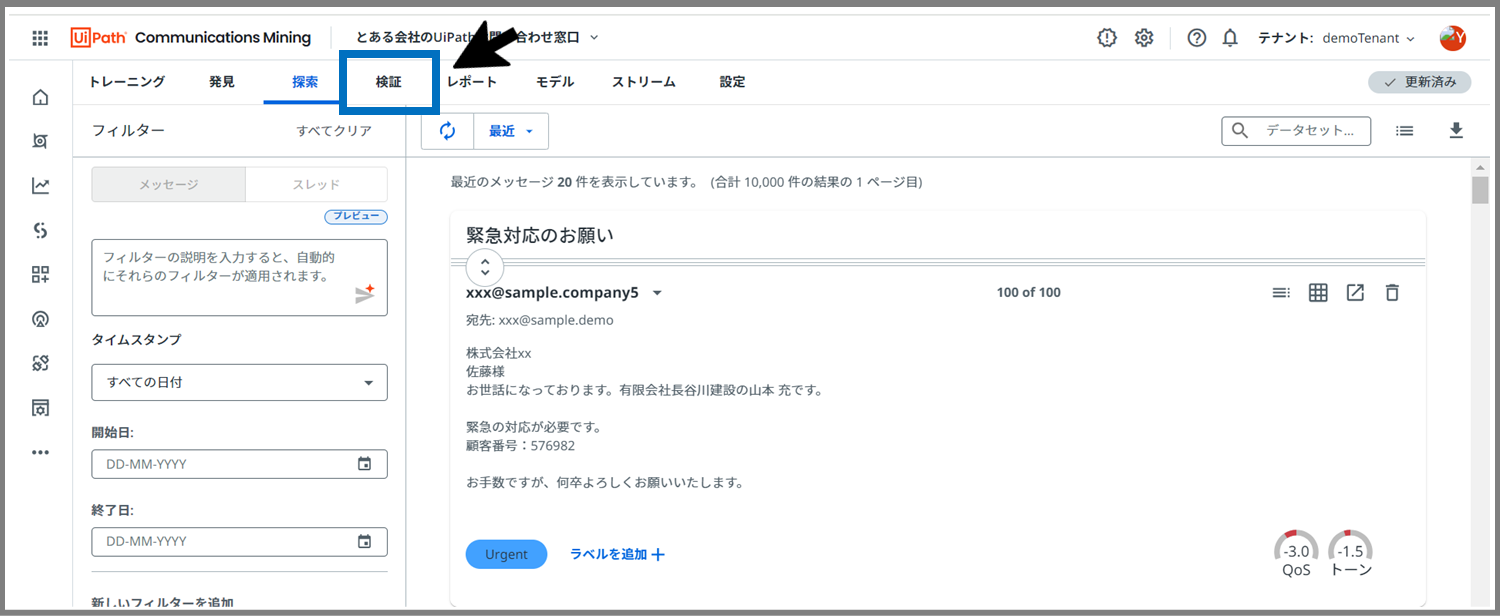
次に、「検証」タブをクリックします。
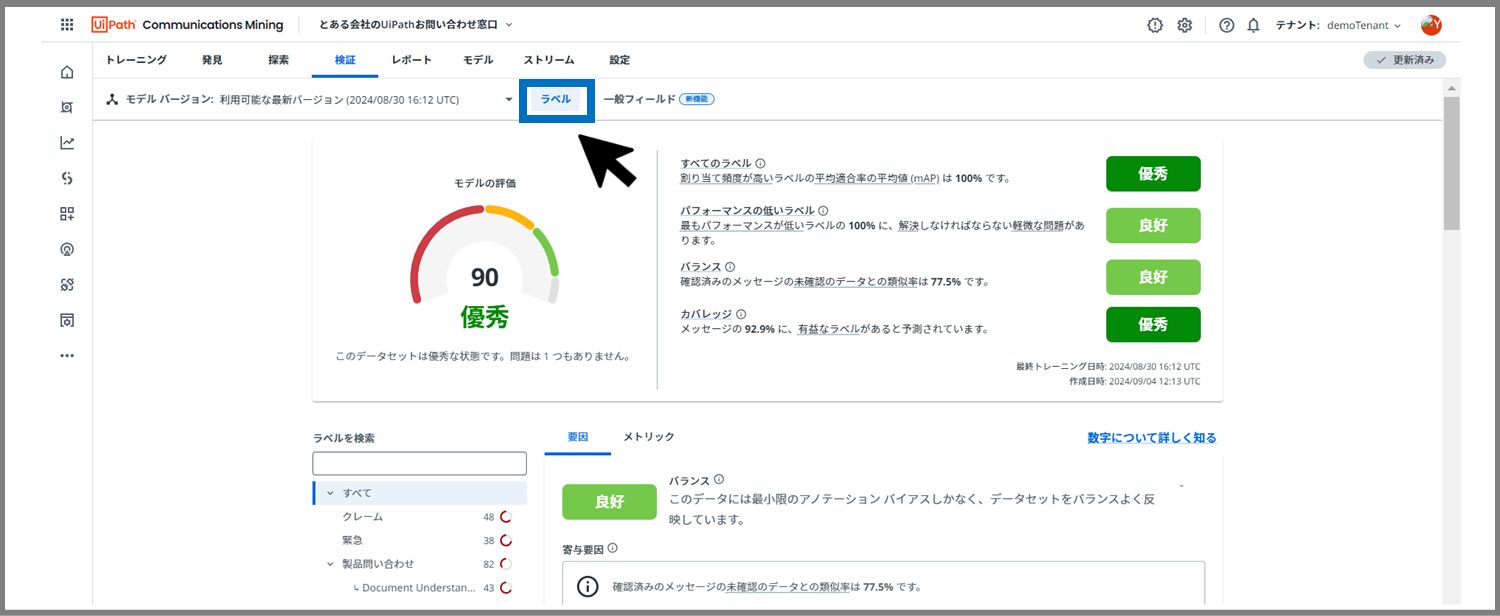
これが検証ページです。
デフォルトでは、「ラベル」のパフォーマンス確認ページが表示されています。
左上の、数値(この場合は90)と書かれている部分でパフォーマンスが数値化されています。
モデル評価は0 から 100 までのスコアで、「悪い」(0 から 49)、「平均的」(50 から 69)、「良好」(70 から 89)、または「優秀」(90 から 100) の評価となります。
自動化に使用するなら、「優秀」
分析に使用するなら、「良好」以上
のスコアまで上げていく必要があると考えて下さい。
※今回は比較的シンプルなデータを使用しているので、これまでのトレーニングで90となりました。実際の本番データは複雑なので、もう少しトレーニングを行う必要があると思います。
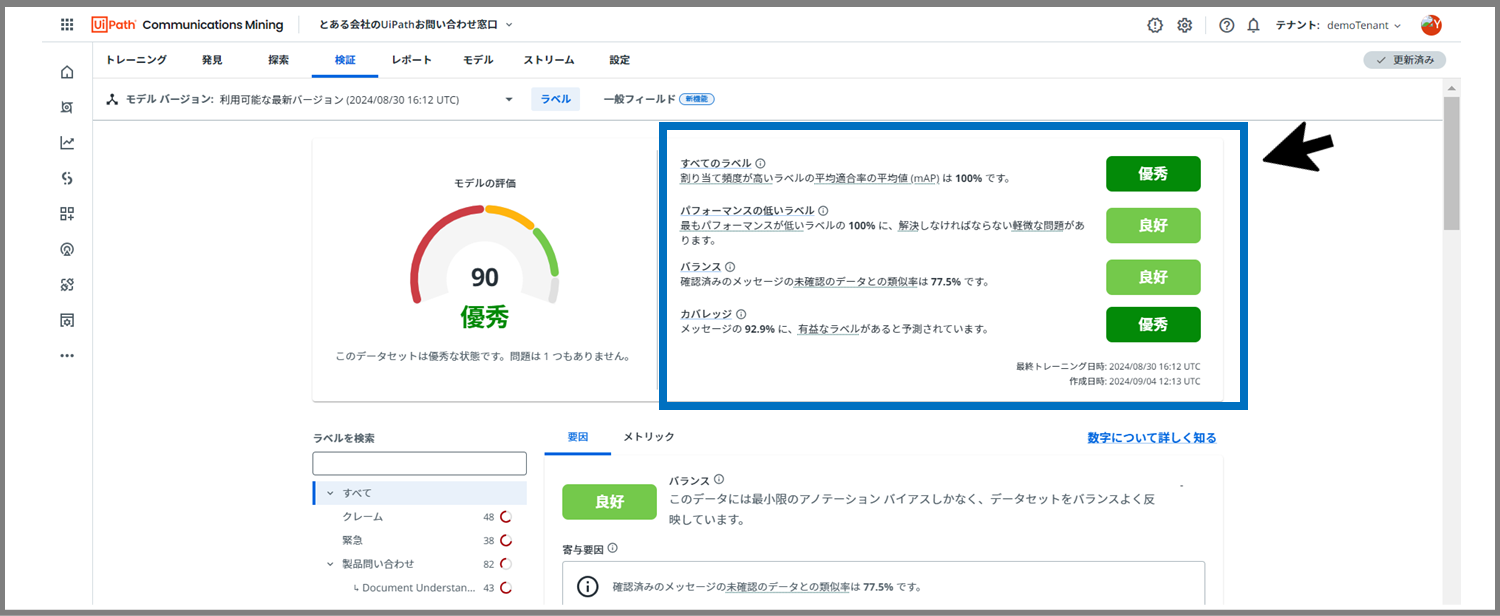
右側の4つの要素について、どういった評価がなされているかも注目です。
- すべてのラベル- プラットフォームが、タクソノミーのすべてのラベルをどれだけ適切に評価できるか
- パフォーマンスの低いラベル- プラットフォームが、タクソノミーの最もパフォーマンスの低い10%のラベルをどれだけ適切に評価できるか
- バランス- トレーニングされたデータが、データセット全体を効果的にバランスよく代表しているかどうか
- カバレッジ- 有益なラベル予測によって、データセット全体がどの程度適切にカバーされているか
また、一般フィールドのパフォーマンスについては、上の「一般フィールド」タブをクリックして切り替わるページから確認できます。
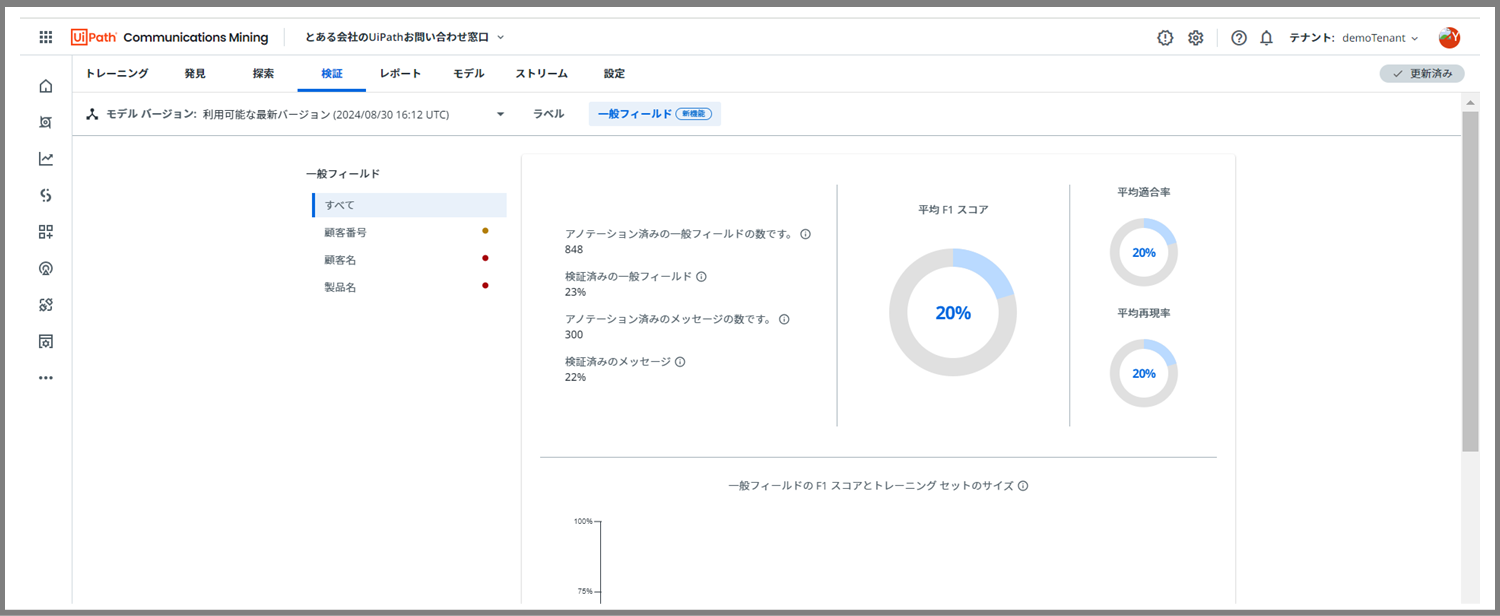
こちらが、一般フィールドのパフォーマンスを確認するページとなります。
低いですね...一般フィールドについては、もっとたくさんアノテーションしていく必要がありそうです。
★「アノテーション ]」とは
人間が、メッセージ内容に適したラベリングをしていくことをアノテーションといいます。ラベルやフィールドなどを付けていく事=アノテーションと覚えておいてください。
指標について、もっと詳しく把握したい場合は、下のドキュメントをご参考にどうぞ。
※Re:inferの公式ドキュメントです。
※英語ですが、ブラウザ翻訳で日本語になります。
Understanding and improving model performance
1-2. パフォーマンスを更に向上させるために
モデルのパフォーマンスを確認した所で、更に精度を上げていきたいと思います。
1-2-1. ラベル
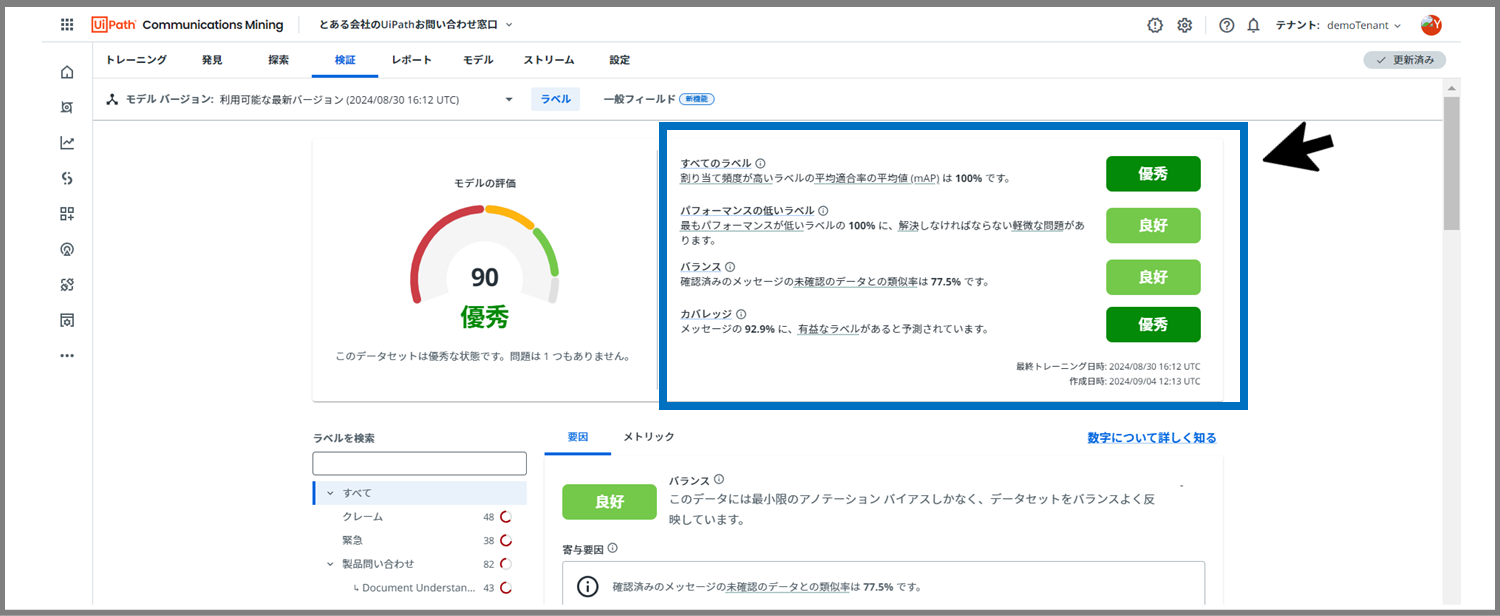
まずは「ラベル」のパフォーマンス向上をしていきます。
現在の評価で「良好」と評価されている部分を、「優秀」にしていきたいと思います。
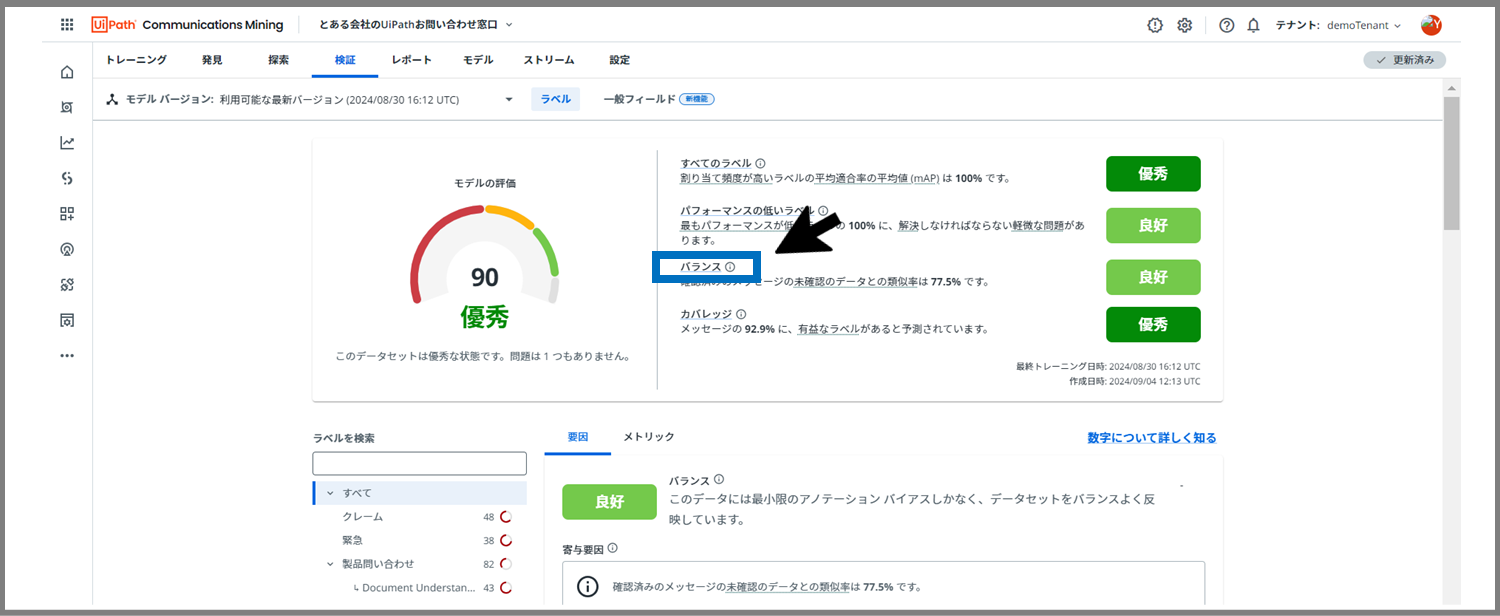
まずは、「バランス」から。
「バランス」の文字をクリックしてください。
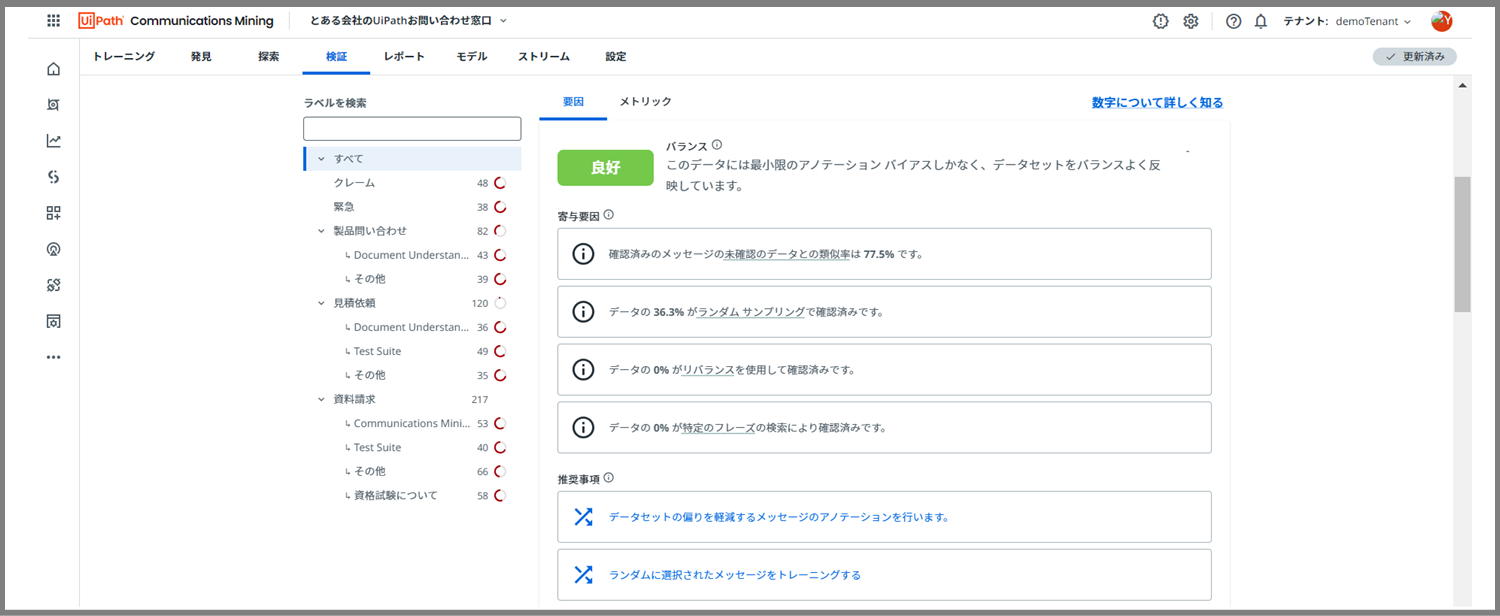
すると、画面が自動でスクロールダウンされ、「バランス」についてCommunication Miningから詳細に評価されているのが確認できます。
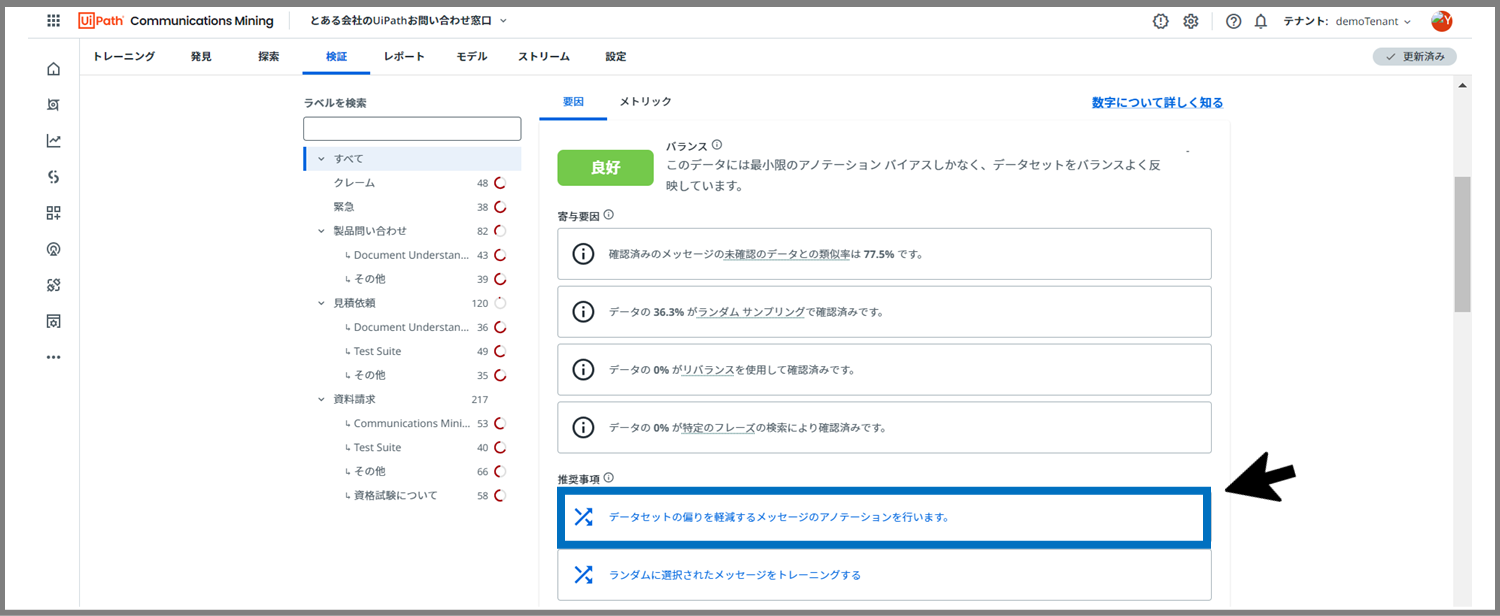
こちらの「推奨事項」という所に着目してください。
「データセットの偏りを軽減するメッセージのアノテーションを行います。」と書いてあります。こちらをクリックしてみます。
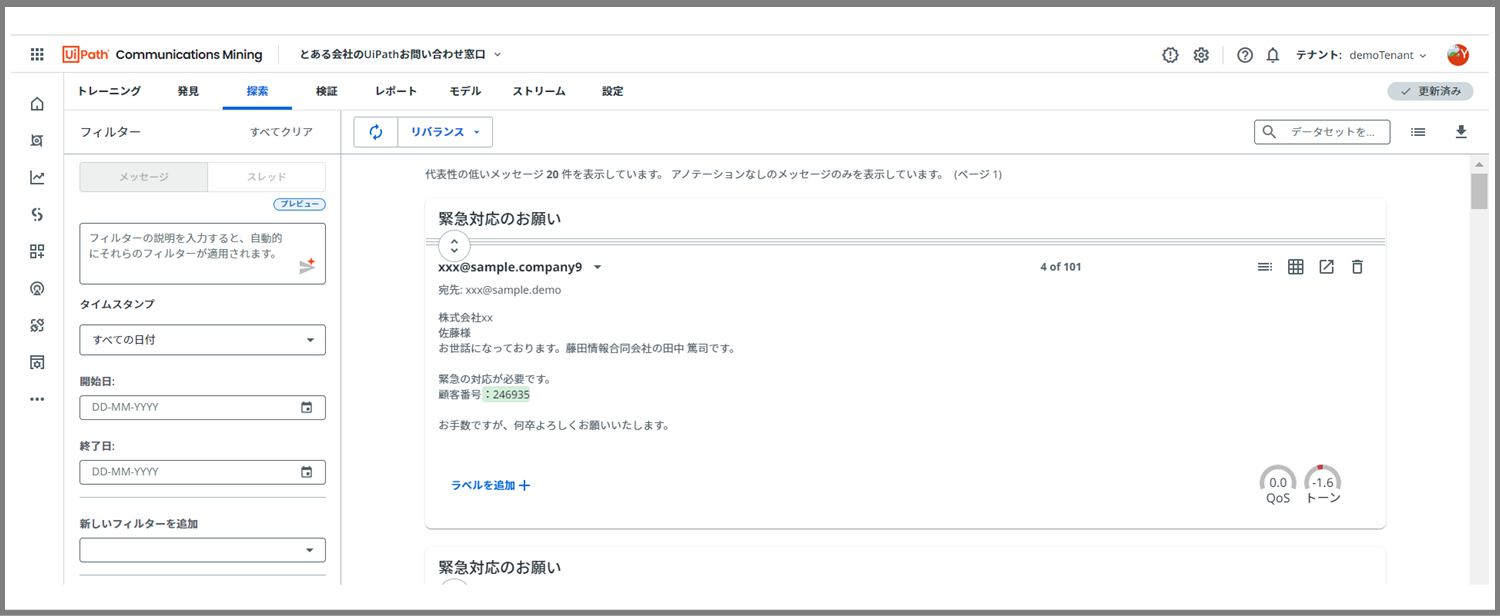
すると、「探索」ページの「リバランス」ページに飛びました!
ここでアノテーション(=ラベルをつけていく)作業をすることで、バランスを改善していけるという事ですね。
このように、評価が物足りない項目は推奨事項に従ってすすみ、表示されたぺージでアノテーションを繰り返すことでモデルのパフォーマンスの改善ができるという仕組みになっています。便利ですね!
ちなみに、20件ほどの「リバランス」メッセージにラベルを付けた後、再度「検証」ページを開くと下のようになっていました。
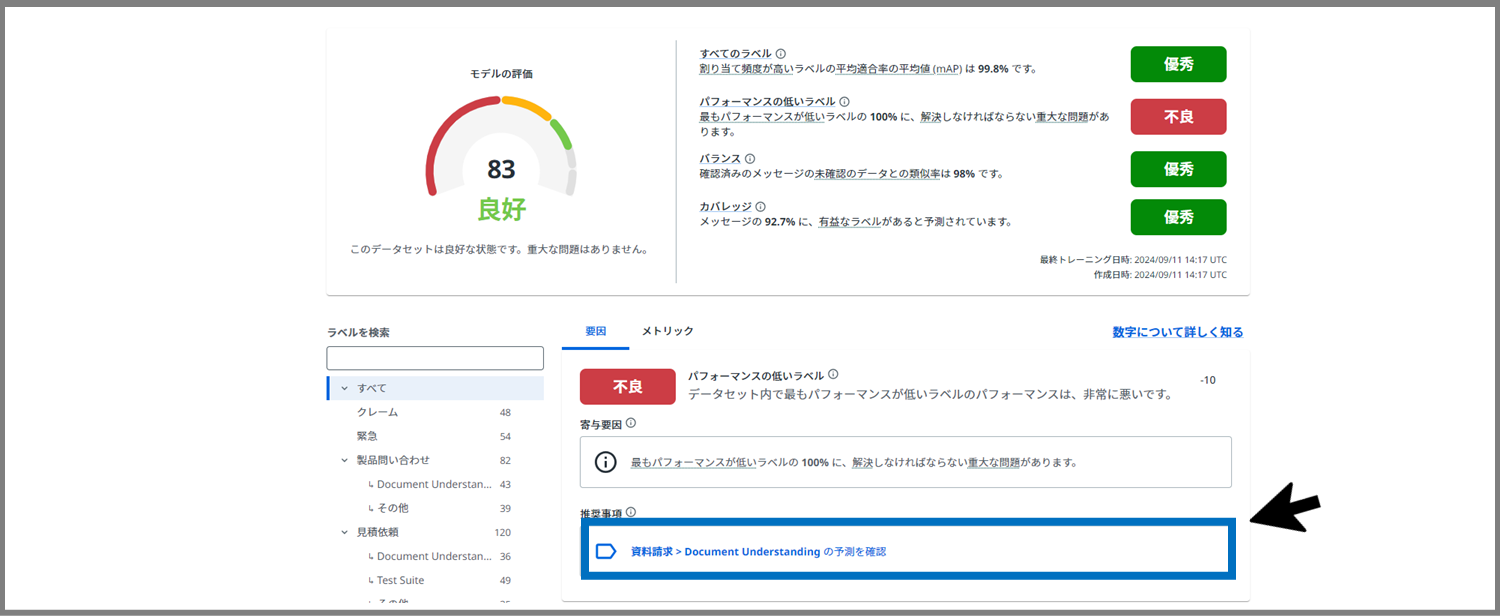
あれ...「バランス」は優秀になったけど...スコアが減ってる!!
ま、まぁこういう事もよくあります。焦らず、「不良」なってしまった所の推奨をこなしていきましょう。
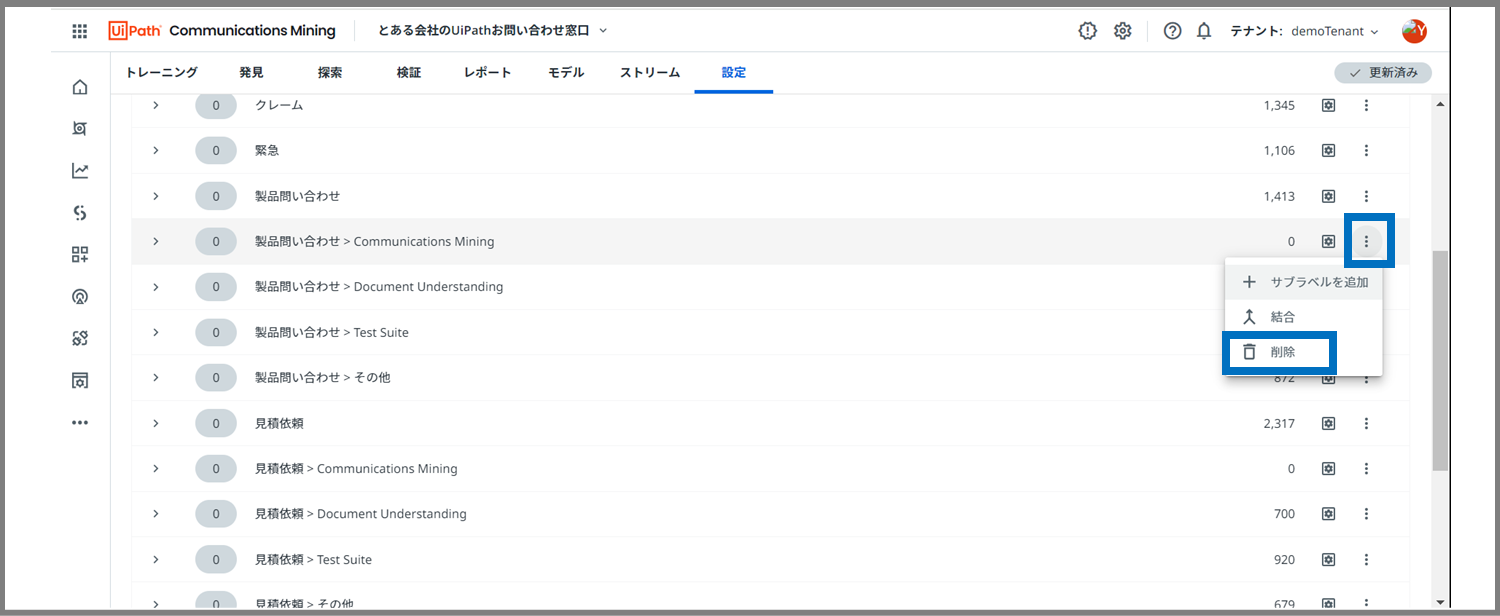
今回の場合は、
- 製品問い合わせ > Communications Mining
- 製品問い合わせ > Test Suite
- 見積依頼 > Communications Mining
の3ラベルにおいて、サンプルデータが不足していたことがモデルスコアに悪影響を及ぼしていたようです。
本番だったらサンプルデータを各30-40は追加したい所ですが、今回はあくまで練習なので、上記3ラベルは削除しました。
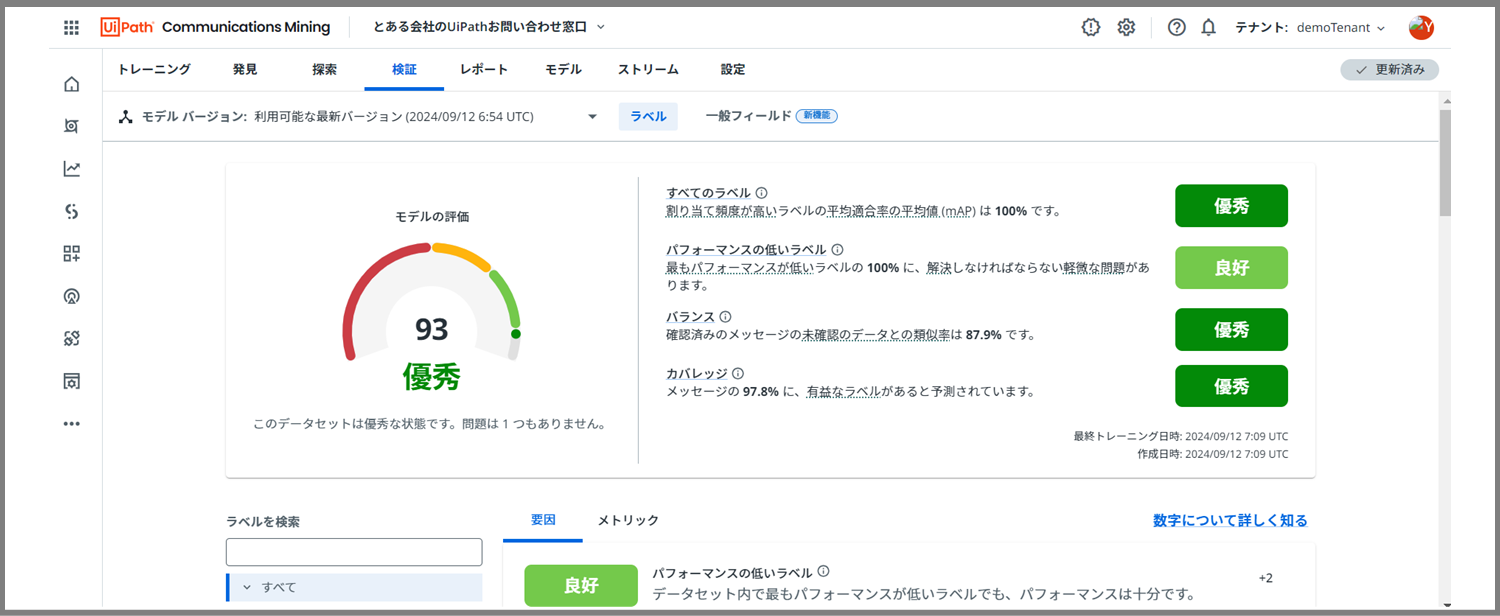
オッケー、オッケー。いい感じです。この感じで全部「優秀」になるまでアノテーションを繰り返します。
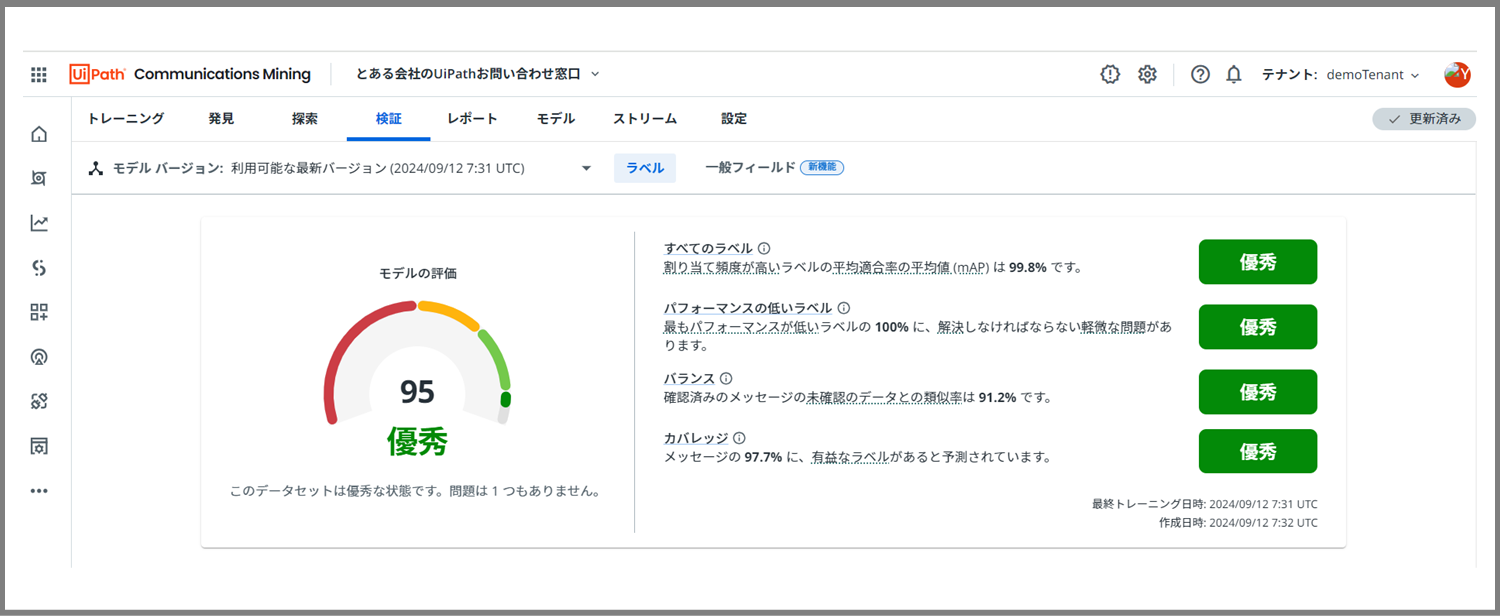
全部優秀になりました!
これで、少なくとも、現在サンプルデータとして参考にしているようなメッセージのラベルは、モデルがかなりの精度で自動的に付けられるようになったと言えるでしょう。
また、ラベルについては、下記ドキュメントの「ラベルのしきい値スライダーを理解する」もチェックすることを推奨します。
※英語ですが、ブラウザ翻訳で日本語になります。
Understanding the label threshold slider
1-2-2. フィールド
次は「一般フィールド」のパフォーマンス向上についてです。
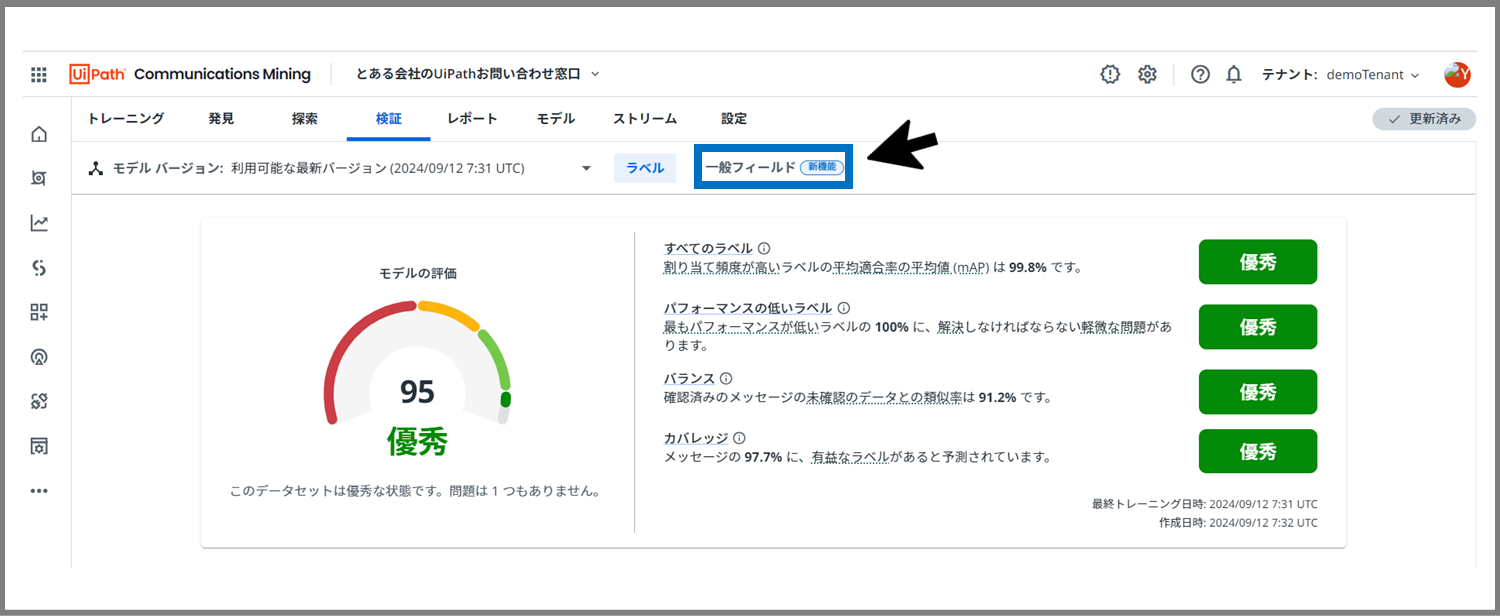
「一般フィールド」タブをクリックします。
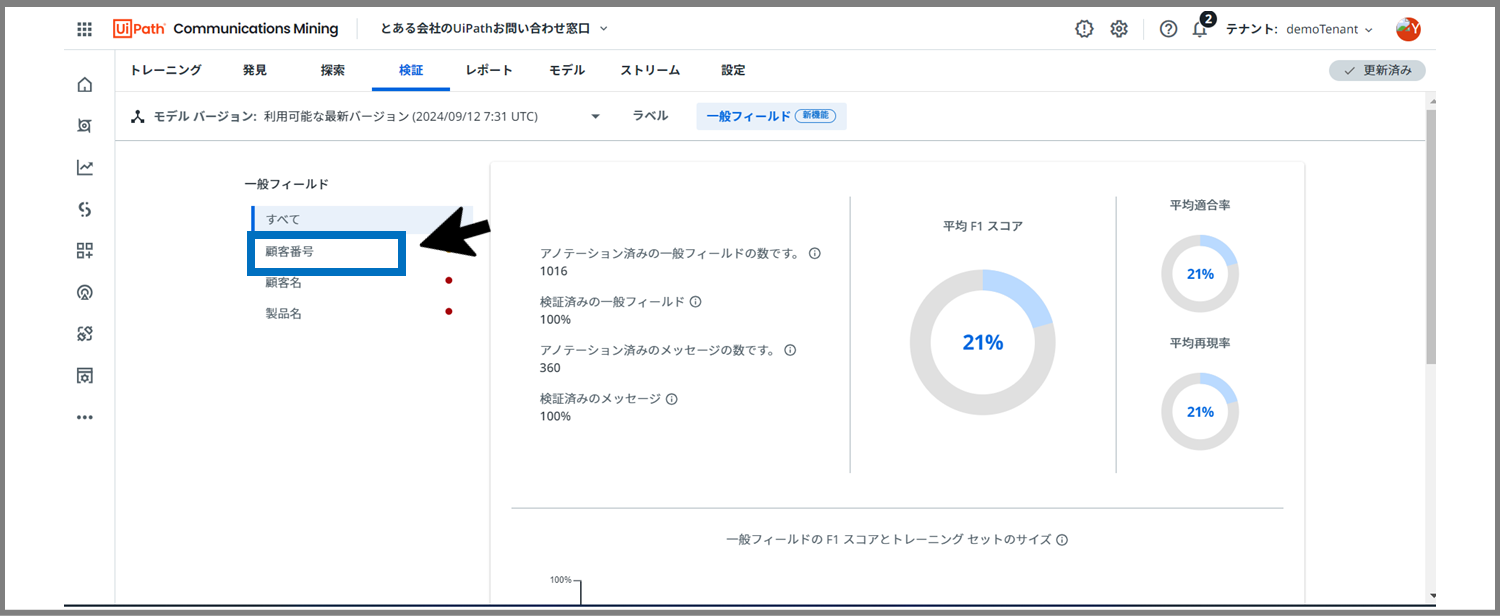
まずは、顧客番号から見ていきたいので、「顧客番号」をクリックします。
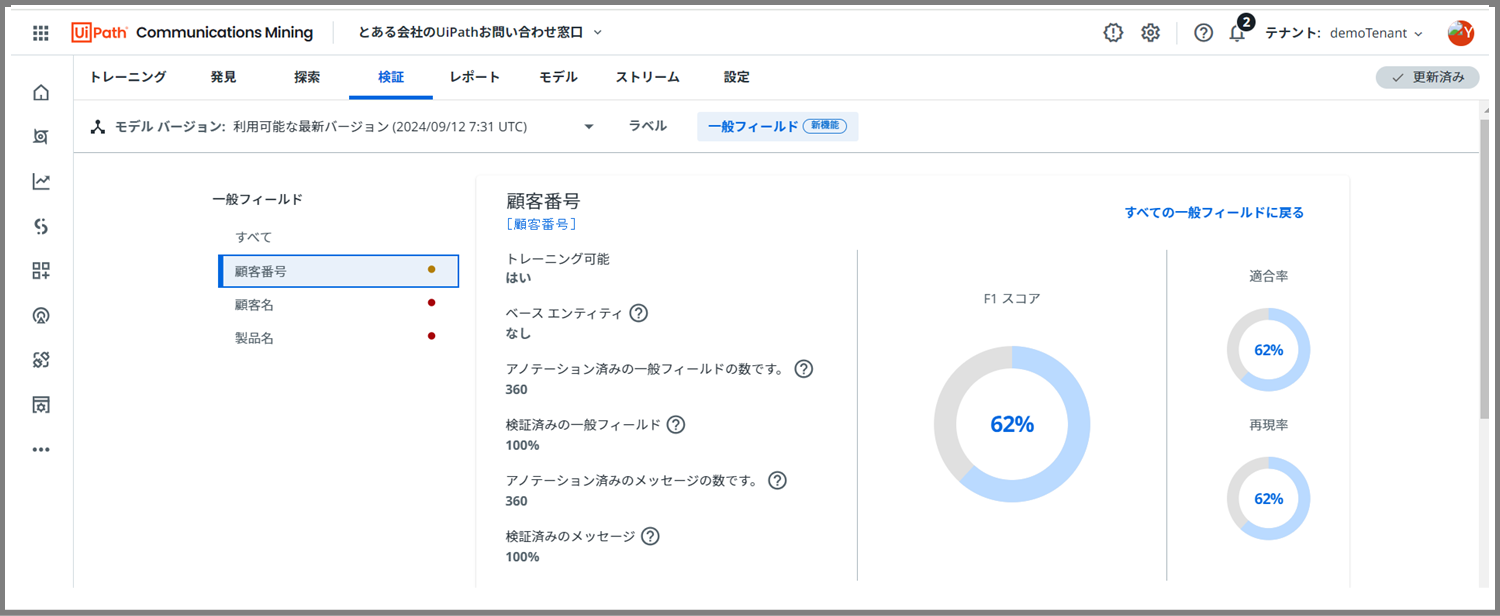
すると、「F1スコア」や「適合率」「再現率」などを確認することが可能です。
「F1スコア」とは、「適合率」「再現率」をバランス良く評価する指標のことです。
「適合率(Precision)」「再現率(recall)」については、下記ドキュメントを参考にしてください。
※英語ですが、ブラウザ翻訳で日本語になります。
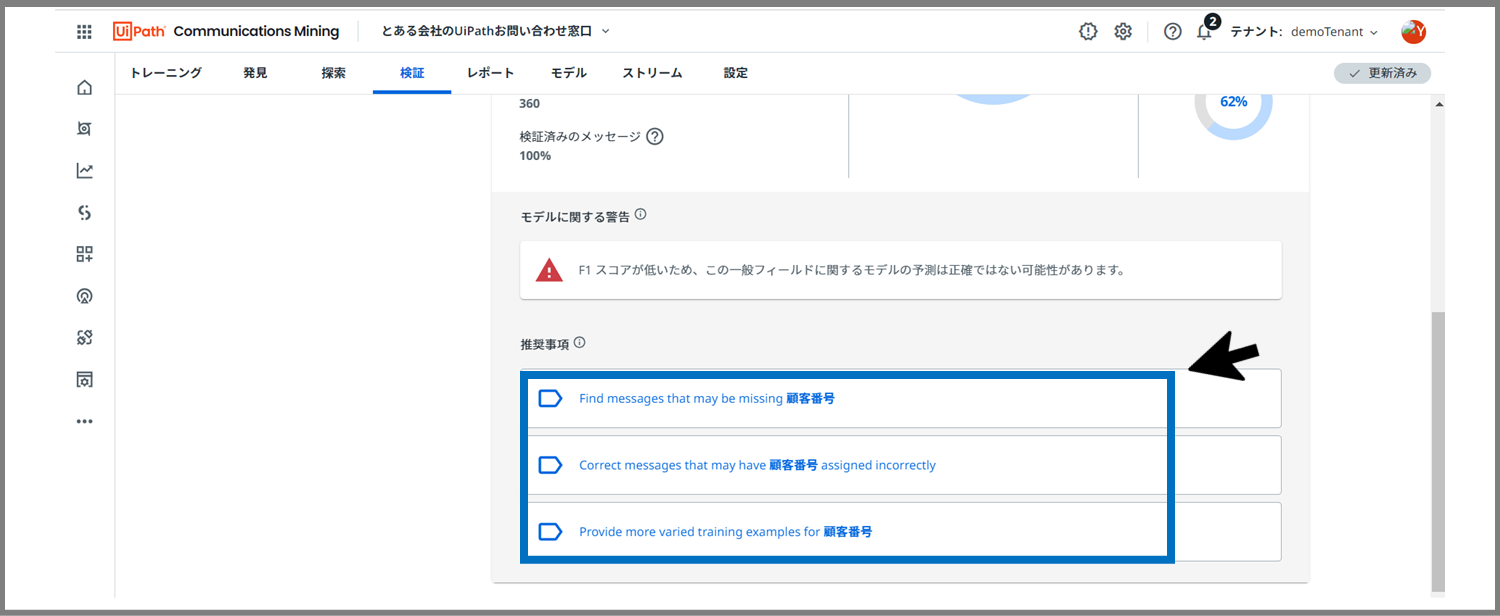
画面をスクロールダウンすると、ラベルと同様に「推奨事項」が表示されています。ここからはラベルと一緒ですね。
ここをクイックして、アノテーションをしていくことで、数値を改善していくことが可能です。
2. 最後に
以上が、UiPath Communications Miningの「検証」フェーズでした。
このフェーズで細かくチューニングして、満足のいく精度になったらモデルの完成です!とは言っても、その後も数か月ごとに精度を検証して、保守していく必要はありますが、そこまで保守に時間がかかる...という事はないそうです。
そして、モデルが完成したら、そのモデルで何をするのでしょうか?
分析や自動化です。
次回の記事では、簡単に分析をしていきますので、お楽しみに。
それでは、また、次回の記事でお会いしましょう。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 3課
ICT事業本部 技術本部 先端技術室 AI推進課
山崎 佐代子