こんにちは。SB C&Sの幸田です。
この記事では、AI基盤のネットワークにおいて採用されるケースが多い InfiniBand について、その概要をご紹介致します。
なお前回 (第1回) では、AI基盤において求められているネットワークがどのようなものかを解説しておりますので、よろしければそちらもご覧ください。
InfiniBand の成り立ち
InfiniBandは、1999~2000年ごろに規格が策定され、利用され続けてきた実績ある通信規格です。
元々はコンピューター内部のデータ転送に利用するための規格としてその原型が開発されはじめましたが、コンピューターの外部 (複数のコンピューター間) を接続する用途の規格として普及し、スーパーコンピューター等のHPC (High Performance Computing) 領域、特に多数のコンピューターを接続して並列演算するクラスタリング環境でのネットワークとして使われるようになり、現在でも広く採用されています。
また、一般的なエンタープライズITシステムにおいても、「低遅延・高信頼・高速」といった要素を高水準に要求されるシステムでは採用されるケースがあります。
一時期は、高帯域幅のネットワークを Ethernet で実現しようとするよりも、InfiniBandによって同程度の帯域幅を実装した方がコストメリットを出せるということで注目を集めていたと記憶しております。
そして近年、最大手のMellanox社をNVIDIAが買収し、AIプラットフォームの極めて重要な要素技術として進化を加速させたことで、InfiniBandには未だかつてないほどに注目が集まっています。
現在、InfiniBandは業界団体の IBTA (InfiniBand Trade Association) によって業界標準の規格として運営されています。
本記事の執筆時点(2025年4月)では、米国企業を中心に62社がメンバーとして名を連ねており、運営委員は Hewlett Packard Enterprise, IBM, Intel Corporation, そしてNVIDIAの4社となっています。
InfiniBand のユースケース
前述のとおり、InfiniBandはHPC領域のクラスタリング(複数のコンピューターを1つに束ねて利用する)環境において多用されますが、近年ではAI基盤において特に盛んに利用されています。
第1回 の記事でご紹介した「AI基盤においてネットワークに求められる要件」を満たしているため、クラスタリング環境におけるコンピューター間の接続=データセンターのEast-Westのネットワークに採用されているわけです。
この用途において、InfiniBandは最適、かつ最速の選択肢といえます。
AI基盤におけるEast-West通信は、ノード間、さらに言えばGPU間の接続であり、演算性能に大きな影響を及ぼします。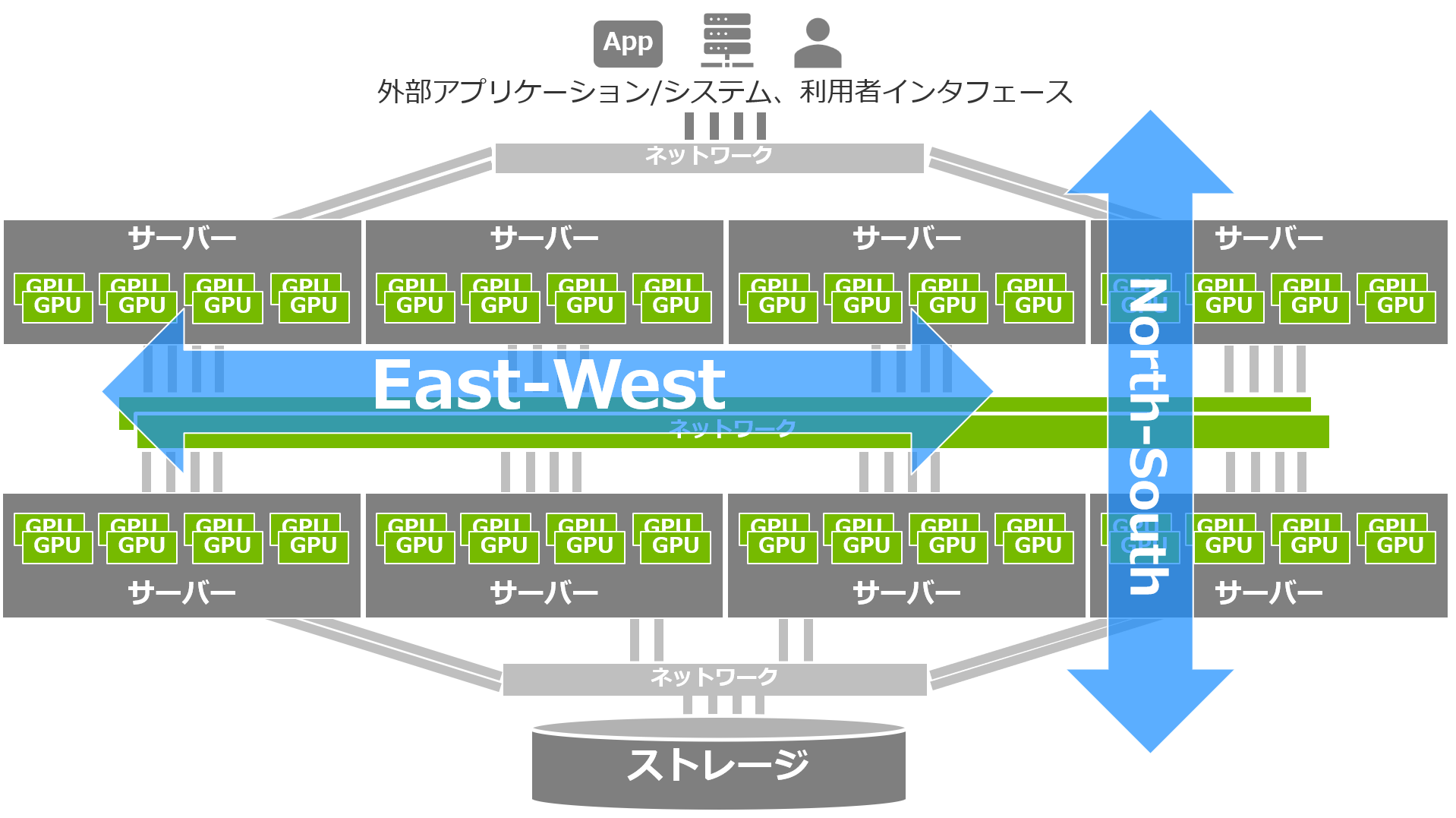
なお前述のとおり、通常のエンタープライズITの領域においてもInfiniBandが利用されるケースは存在します。
具体的には、金融サービス、大規模なeコマース、多量のトランザクションを捌く必要のあるデータベース、またアプリケーションを問わない大規模な仮想環境などです。
InfiniBand の特長
まずはInfiniBandの特長をリストアップしてみます。
この中で、技術開発をリードしているNVIDIAのInfiniBandならではのポイントについても触れられればと思います。
1. ロスレス=パケットの損失が生じない
2. Latency (遅延) が極めて低い
3. Adaptive Routingによる最適な経路選択
4. NVIDIAのInfiniBandにおける輻輳制御の特長
5. RDMAを利用可能
6. サブネットマネージャーでの管理
7. SHARPによるMPI演算オフロード
以下、一つずつ詳しくご紹介してまいります。
1. ロスレス=パケットの損失が生じない
通常、ネットワークの通信においてパケット(送受信されるデータ)が大量に送信され、輻輳が発生した (通信経路や受信する側が溢れかえってしまい受け取り切ることができなかった) 場合、パケットはロス=損失してしまいます。
複数のノード・GPUが協調的に動作して演算を行うAI基盤では、パケットロスが演算の失敗に直結します。長時間かけて進めた演算が一瞬のネットワークの輻輳によって失敗してしまえば、作業される方々の時間や労力、そして消費電力など非常に大きな無駄が発生してしまうこととなります。
InfiniBandは、送信する側のノードが受信する側のバッファ(受信したパケットを一時的に保存する領域)の状況を常に監視しており、空きがあるタイミングでのみデータを送信する仕組みになっています。
このため、輻輳によるパケットロスが原則として発生しない仕組みとなっています。この特長をもって、InfiniBandは "ロスレス" であると評価されています。
2. Latency (遅延) が極めて低い
InfiniBandは、EthernetでいうところのMACアドレス(48bit)にあたるネットワークインターフェースの識別子に、LID - Local Identifier(16bit)を利用します。
スイッチが処理するデータ量が小さいことで、処理にかかる時間がごく短くなるため、遅延が少なくなるというわけです。
なおInfiniBandの通信を行うネットワークインターフェースは別途、GUID - Global Unique Identifier(64bit) を持っていますが、サブネットを越える通信が行われない限り、このGUIDは通信に利用されません。
3. Adaptive Routing による最適な経路選択
パケットロスが生じないにしても、データの転送量が多い場合、圧迫される通信経路が生じるケースがあります。
そのような経路を自動的に避けてデータ転送を行うAdaptive Routingと呼ばれる機能を、InfiniBandは持っています。
なおNVIDIAのInfiniBandプロダクトでは、Fat tree, Dragonflyなどネットワークトポロジーごとに最適なAdaptive Routingのアルゴリズムをオプションで選択できるようになっており、そのガイドも用意されています。
Adaptive Routing - InfiniBand Cluster Bring-up Procedure
4. NVIDIAのInfiniBandにおける輻輳制御
ここで、NVIDIAのInfiniBandスイッチならではの優位点についてもう一歩踏み込んで触れておきます。
NVIDIAのInfiniBandスイッチは、ハードウェア自体に組み込まれた輻輳制御 (congestion control) のエンジンが動作するところに特徴があります。
InfiniBandは、通信のフローを制御するVirtual Lane(VL)を0~7+1つ持ち、データはこの0~7のVLを使います。
InfiniBandはこのVL毎にフロー制御の機能を持っており、1つの通信で発生した輻輳が他のVLに影響することがありません。
この点でInfiniBandは優れており、複数の異なる種類のアプリケーション(処理)が通信を発生させているクラスタ上で、特に大きな効果を発揮します。
特定のアプリケーションによって発生する通信が、他のアプリケーションの処理にも影響を与え、そのボトルネックが基盤全体に広がってしまう懸念への対処が可能といえます。
5. RDMA を利用可能
RDMA - Remote Direct Memory Access は、データ通信を行う際、OSとそのKernelを介さずに、メモリ間で直接データをやりとりすることができる機能です。
OS, Kernelでの処理のオーバーヘッドをキャンセルできるため、当然ながら通信は高速・低遅延なものとなります。
InfiniBandのHCAはハードウェア機能としてRDMAをサポートしており、当然ながらNVIDIAの展開するHCA(およびSmartNIC 次回以降で解説)も、RDMAに対応しています。
なおNVIDIAは、GPUのメモリ内のデータにこのRDMAのテクノロジーを適用する GPUDirect を展開しており、AI基盤で広く採用されています。
GPUのデータ転送の場合、従来はGPU内のメモリとシステムメモリ(コンピューター本体側のメモリ)との間でのデータコピーが発生し、そのオーバーヘッドも大きいものでしたが、GPUDirectを利用することでこのコピー処理をキャンセルし、劇的に低遅延・高速な通信、そしてその結果としての複数ノードを跨いだGPUによる高速な演算を実現できます。
複数台でのクラスターを構成するAI基盤の性能を十分に引き出すためには、もはや必須のテクノロジーといえます。
6. サブネットマネージャーでの管理
InfiniBandのネットワークを構成する際には、そのサブネットごとにサブネットマネージャーを実装します。
サブネットマネージャーは、InfiniBandネットワークのトポロジーを検出し、先述のLIDを割り当て、データ転送のための最適な経路計算を行うなど中核的な役割を果たします。
なおこのサブネットマネージャーを動作させるために、新たにサーバーを用意することは不要で、InfiniBandスイッチ自体のOS上にあらかじめ実装されているものや、InfiniBandのHCA (Host Chanel Adapter - Ethernetなど一般的なネットワークでいうところのNICにあたるもの) を搭載したノードに実装したものを利用することが一般的です。
またNVIDIAのUnified Fabric Manager (UFM 第3回記事で紹介) においても、サブネットマネージャーを稼働させることが可能です。
7. SHARP によるMPI演算オフロード
クラスター構成のAI基盤のように、複数のノード(サーバー)で演算を行う、つまり並列処理を行う場合、プロセッサー(CPUやGPU)を搭載するノード間で演算の結果や進捗状況のメッセージを頻繁にやりとりし、受け取ったメッセージを処理して協調動作する方式があります。
その標準規格である MPI - Message Passing Interface は並列計算のデファクトスタンダードとして広く使用されているのですが、上述のような処理の全てを各ノードが行うことはシステム全体に負荷を生じさせ、ノードの台数が多くなればなるほどその負荷は大きくなってしまいます。
このMPIの処理をネットワーク側にオフロードする仕組みが、SHARP - Scalable Hierarchical Aggregation and Reduction Protocol です。SHARPは、旧Mellanoxの時代からNVIDIAのネットワークプロダクトが開発してきた技術であり、広くAI基盤に実装されて大幅な性能向上を実現しています。
参考:Advancing Performance with NVIDIA SHARP In-Network Computing - NVIDIA Technical Blog
以上、今回はInfiniBandについての解説でした。
次の第3回では、NVIDIAが展開するInfiniBand製品の具体的なラインナップをご紹介したいと思います。
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第2技術部 1課
幸田 章 - Akira Koda -
NVIDIA製品を中心としたコンピューティング(グラフィックス, AI/HPC)とネットワーキング、VDI を含む仮想化、クラウド等のプリセールス・エンジニア業務に従事。
VMware vExpert 2015-2022